提取标准与统计方法对二语词块研究的影响
2021-05-11严恒斌
严恒斌
(广东外语外贸大学 外国语言学及应用语言学研究中心双语认知与发展实验室, 广州 广东 510420)
1.0 引言
词块(Lexical Bundles)是自然语言中高频、反复出现的多词表达式(Biber et al.,1999)。语言习得研究发现,作为一种程式语,词块有着重要的结构、语篇和语用功能,其整存整取的处理优势,能提高语言表达的效率、流利度和地道性,因此在语言习得过程中有着重要作用,也是衡量语言使用者语言能力的一个重要指标(Lewis,2008;Stengers et al.,2011;张凌岩、陈莹,2011;Conklin & Schmitt,2012)。近年兴起的语料库驱动的词块研究范式(Biber et al.,1999,2004)基于频率和分布指标,从大规模语料中提取真实语境的词块使用样本,有效克服了传统短语学研究范式效率、客观性和代表性方面的不足,因而成为词块研究的主流。然而,目前二语词块研究所采用的提取标准和统计方法缺乏统一性和严谨性(del & Erman,2012),降低了结论的可信度和可比性(Paquot & Granger,2012),导致词块研究文献中出现对相同问题的不同、甚至相悖的结论。本研究从学习者水平和词块输出数量的关系出发,参照主流提取标准和统计方法,利用ETS标准化考试语料进行实验对比,探讨不同标准和方法所带来的定量差异及其对分析结果的影响。
2.0 文献综述及研究问题
2.1 词块提取标准概述
Biber(1999)首先提出语料库驱动的研究范式,根据频率和分布标准提取词块,但该范式对词块的界定并没有统一标准。Biber et al.(2004)和Biber & Barbieri(2007)提出使用较为“保守”的频率(每个词块至少每百万词出现40次,即40次/MW)和分布标准(出现于5个不同文本),但同时承认该提取标准的设定较为“随意”(arbitrary)(Biber et al.,2004)。国内学者许家金、许宗瑞(2007)亦指出,这种标准是基于经验得出的,并没有统计学的依据。实际操作中,研究者会根据提取的词块数量是否足够少、便于人工分析来反推所选用的标准(Appel & Wood,2016;Chen & Baker,2016)。因此,不同研究采用的提取标准常有较大差异。表1总结了近年国内外二语习得领域词块研究所采用的频率和分布标准。
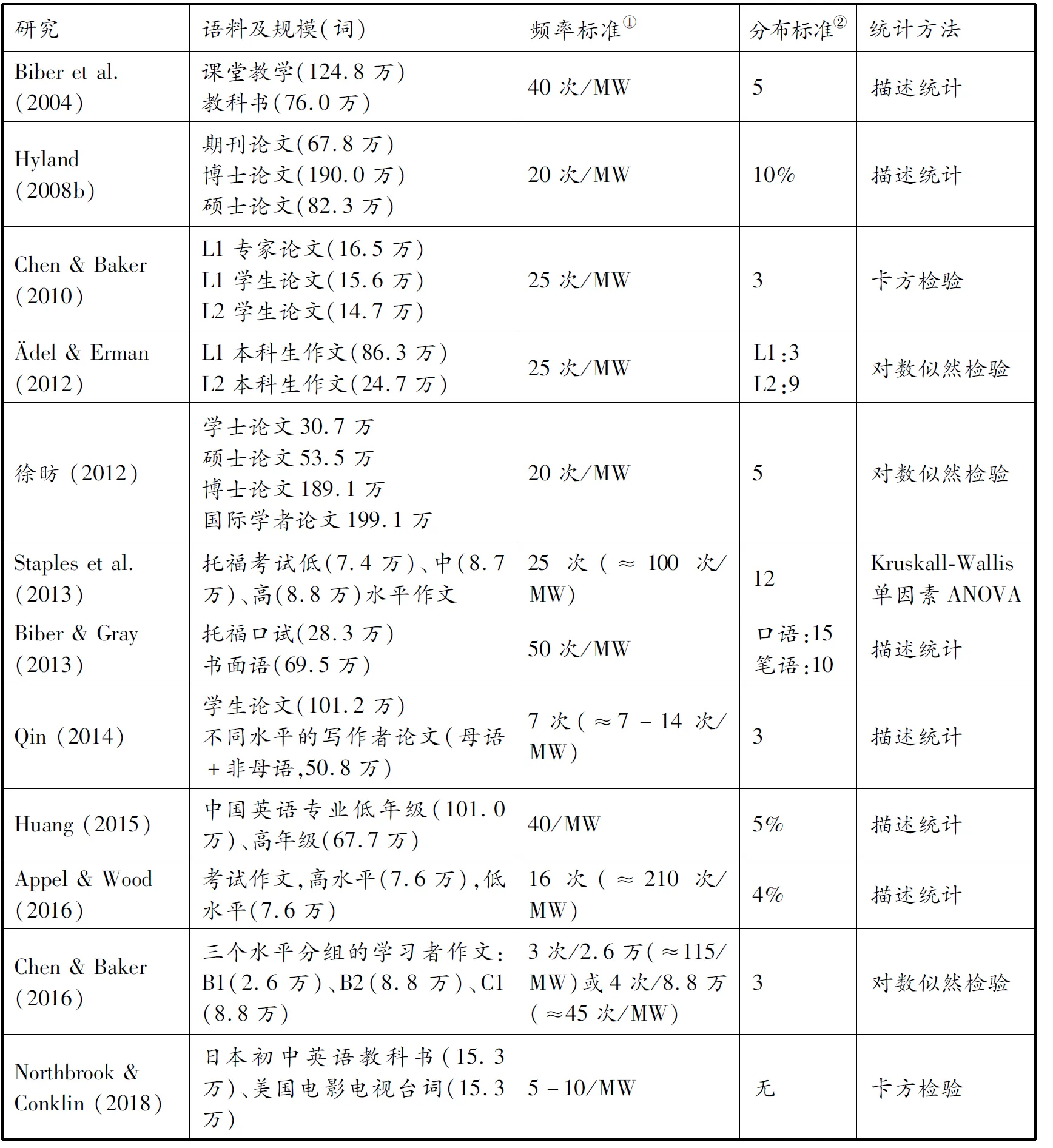
表1 主流二语词块研究的词块提取标准和统计方法
从表1可见,主流词块研究所设定的词块提取标准并不统一。大部分研究考虑了语料库大小对词块频率的影响而对词块频率进行了标准化,即计算每百万词出现次数,但也有三分之一左右的研究采用了原始频数。具体频率标准从5次/MW到210次/MW不等,主流是Biber et al.(2004)提出的40次/MW。上述结果总体上与Bestgen(2018)对不同领域的词块研究的调查结果相近。词块分布标准方面,约三分之二的研究采用固定的文本数量,3-15个文本不等。另有三分之一根据语料库总文本数量设定比例,4%-10%不等。此外还有个别研究只设定频率标准而不考虑分布标准。
2.2 统计方法
近年来,词块研究者逐渐意识到推断统计方法在词块研究中的重要作用。目前,词块研究普遍使用的推断统计方法如卡方检验(Chen & Baker,2010),对数似然检验(del & Erman,2012;徐昉,2012;Chen & Baker,2016)等,多为词袋模型,其重要假设是语料库中所有单词相互独立。但近年统计学相关研究(Lijffijt et al.,2016;Gablasova et al.,2017)发现,由于同一个文本中的单词并非相互独立,上述错误假设会导致过高估计差异的显著性,因此不适用于语料库样本的统计,而应采用t检验、ANOVA、Wilcoxon Rank-Sum检验等以文本为独立测量单位的统计方法。
遗憾的是,目前国内外的词块研究中,基于文本样本的推断统计方法尚未成为主流。为了解不同统计方法对词块计量分析的影响,我们将传统描述统计方法和推断统计方法同时应用于相同语料,并对比分析两者结果的异同。
2.3 学习者语言水平与词块输出
多项研究表明,词块输出是衡量学习者语言水平的重要指标(Lewis,2008;Stengers et al.,2011)。然而,对于学习者词块输出数量是否随着语言水平提高而增加的问题,学界至今仍未达成一致共识。多项研究对水平分组的学习者语料进行了对比,调查组间的词块输出异同。Chen & Baker(2016)、Huang(2015)、Qin(2014)对学习者学术写作语料的研究显示,学习者词块输出数量总体上随语言水平提高而增加。然而,Staples et al.(2013)和Appel & Wood(2016)对比不同水平分组的学习者作文后却得到相反结论,即低水平学习者总体上倾向使用更多的词块。除水平分组对比外,多个研究把本族语者(L1)作为理想的高水平语言使用者与学习者(L2)的词块输出进行对比,得出了类似的矛盾结论(Chen & Baker,2010;Hyland,2008a;Römer,2009;徐昉,2012;del & Erman,2012)。
2.4 待解决问题
Paquot & Granger(2012)指出,由于词块界定标准差异等因素,自动提取的二语词块结果难以直接比较。黄开胜、周新平(2016)推测,文献中关于二语词块输出数量的矛盾结论很可能是由于研究对象或词块界定标准的差异而造成的。另一方面,描述统计方法在精确性等方面的不足可能进一步降低了不同结论的可比性。随着词块应用日益广泛和深入,如能为不同研究之间的分析和对比提供更明晰可靠的标准和方法,将对该研究范式有重大意义。然而遗憾的是,目前仍没有研究对词块界定标准和对比方法进行过深入研究。本研究从学习者语言水平与词块输出之间的关系出发,对词块提取标准和统计方法进行探讨,以填补这个空白。为此,我们提出以下研究问题:
(1)不同的词块提取标准(频率和分布)是否会影响不同水平分组间词块数量的比较结果?
(2)相对于传统描述统计,基于文本样本的推断统计方法能否提高组间比较结果的稳定性和精确性?
3.0 研究设计
3.1 语料
本研究所采用的语料来自ETS非母语书面英语语料库(ETS Corpus of Non-Native Written English)(Blanchard et al.,2013)。该语料库包含11个不同母语背景的英语学习者的托福考试作文,每个母语收集1,100篇作文,共12,100篇。每篇作文由至少两名ETS专家进行水平评分,分成高、中、低三个水平分组。由于语料库中三个分组的文本数量不平均,为确保可比性,在保证母语背景、写作题目的数量平衡的前提下,从语料库中的每个水平组随机抽取了400篇作文,共1200篇。每个分组的作文数量及形符数见表 2。

表2 ETS非母语英语书面语语料库数量及形符数
3.2 提取标准
本研究关注词块提取的频率及分布标准(自变量)对从不同分组中提取的词块数量(因变量)的影响。我们以Biber et al.(2004)提出的提取标准作为自变量的基准,即以出现频率每百万词40次、分布在5个或以上的不同文本作为词块提取的门槛。在其中一个自变量维持和基准相等的前提下,通过调整另一个自变量的值(从低到高)来观察其对提取结果及水平分组间对比的影响。在参考主流词块文献的标准后,我们设定了两个变量的具体赋值区间。词块频率设定为出现10-100次/百万词之间,每次实验递增10次/百万词,而分布标准设定为出现在2、3、 4、 5、 8、10、15个和5%不同文本。
在按照上述标准提取的候选词块基础上,进一步去除重叠词块和内容词块。重叠词块是指两个或以上的被某个更长的词块所包含的词块。Chen & Baker(2010)指出,相互重叠的词块会导致频率被重复计算,影响频率的准确性。内容词块也叫上下文相关词块,是指由于某个特定的语境(如某个作文题目)和使用者背景(如所在地)而出现的词块。多个研究(Staples et al.,2013;Huang,2015)表明,移除内容词块与否会影响词块频率比较的结论。为保证词块统计的准确性,我们按照Chen & Baker(2010,2016)所述方法对两者进行过滤。
3.3 统计方法
3.3.1 描述统计
我们首先按照Biber et al.(1999, 2004)范式,利用描述统计方法测量组间的词块频率的分布和趋势。在计算每个分组的词块数量时,记录该分组的词块类符总数。评定两个分组的词块输出高低一般通过词块类符数量及其组间相对排名的直接比较,但对判断组间差异是否显著并无明确标准(Biber et al.,2004;Qin,2014;Appel & Wood,2016)。在利用描述统计进行组间比较时,可观察不同提取标准下每个分组提取的词块数量及其相对排名。若三个分组相对排名保持不变,可认为提取标准的改变不影响基本结论,否则可认为对结论构成影响。
3.3.2 基于文本样本的推断统计
作为与描述统计的对比,我们按照相关统计学研究(Lijffijt et al.,2016;Gablasova et al.,2017)的建议,采用推断统计方法对组间差异进行检验。在提取每个分组符合标准的词块后,分别计算每个文本所含词块的频数,然后应用推断统计方法进行组间对比。由于词块输出频数和文本长度之间存在一定的相关性(在不同提取标准下r≈0.2-0.34,p<0.001,即文本越长,文本所含词块越多),对学习者水平主变量的单因素考察难以揭示其对词块输出频数的真正影响,因此我们采用ANCOVA(协方差分析),在对文本长度进行统计控制的情况下,考察学习者水平的效应。
4.0 结果与讨论
根据研究设计设定的频率及分布标准,我们对三个水平分组中的词块进行了提取,并分别利用描述统计和推断统计两种方法对提取结果进行对比分析。
4.1 描述统计
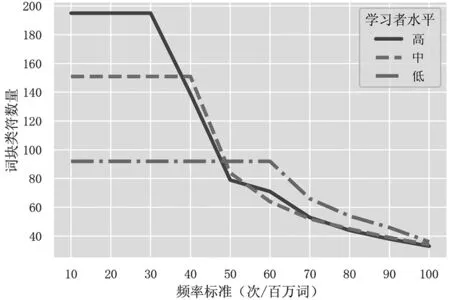
图1 三个水平分组在不同频率标准下的词块类符数量
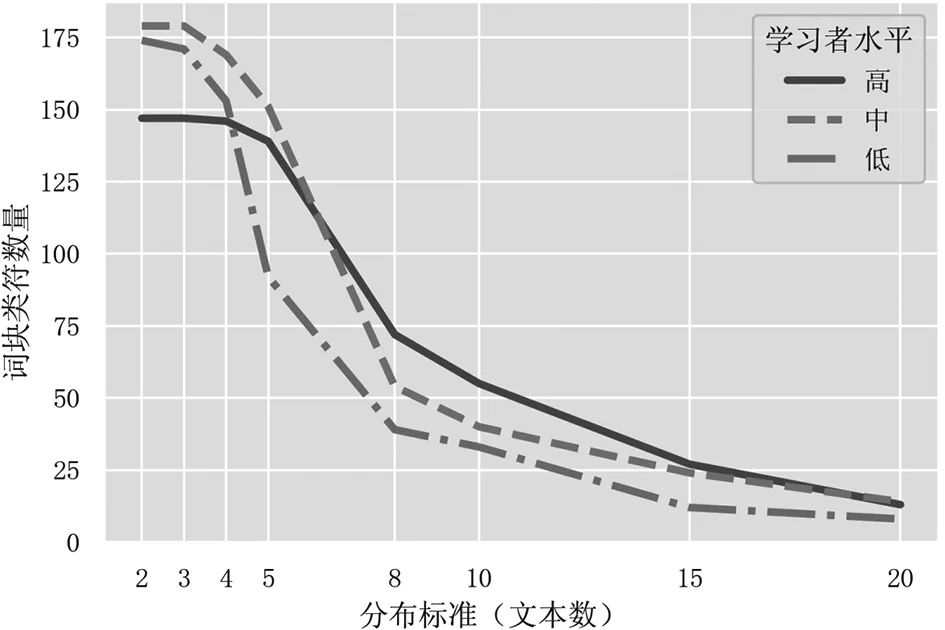
图2 三个水平分组在不同分布标准下的词块类符数量
如图1和图2所示,随着频率和分布标准的提高,提取的词块类符数量总体呈下降趋势,但三个水平分组的下降幅度存在差异,导致三个分组的相对位置在不同标准下发生改变。以频率标准为例,当提取标准为10次/MW时,三个分组的词块数量按高、中、低排列,且差异明显,高水平组比中水平组高约30%,而后者则比低水平组高约60%。值得注意的是,当频率标准低于30次/MW时,三个分组的词块数量保持不变。这是因为当分布标准按基准设为5个不同文本时,根据分组语料库的实际大小进行标准化后的实际频率门槛为34次/MW到60次/MW之间,若该门槛高于频率变量当前值,则成为事实上的频率标准。由此可见,两个变量的实际效果受语料库大小的影响,存在互相竞争的关系。当门槛为40次/MW时,高、中水平分组之间差距急剧缩小,中水平分组首次反超高水平分组。50次/WM和60次/MW时相对排名连续发生变化。而与此同时,低水平词块数量因受分布标准制约而保持不变。70次/WM之后,三个分组差异趋平稳,低水平分组处于相对高点,而中高水平分组无明显差别。
4.2基于文本样本的推断统计
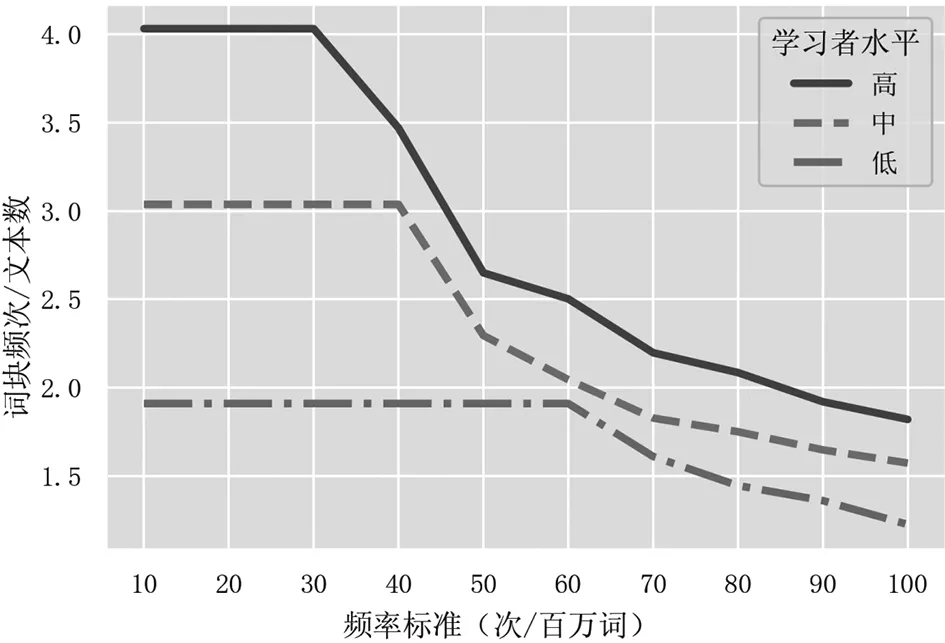
图3 三个水平分组在不同频率标准下文本平均词块频次数
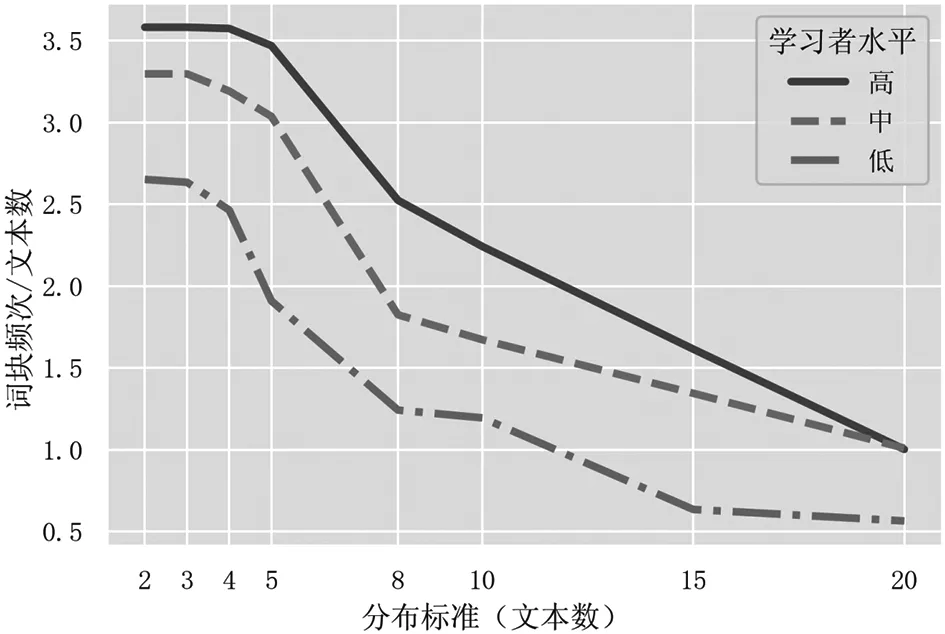
图4 三个水平分组在不同分布标准下文本平均词块频次数
图3和图4显示,若基于文本样本对文本平均词块频次进行统计,则不同水平分组的词块频次在不同标准下的相对位置保持恒定。三个分组的平均词块频数按高、中、低水平依次排列,即高水平语料中平均每个文本词块输出最多,中水平次之,低水平最少。这似乎符合我们的直觉:如果词块输出数量是学习者水平的反映,在水平保持恒定的前提下,即使提取标准变化,每个分组所对应的词块数量理应也保持相对恒定。但是,不同水平语料的词块仍可能受文本长度和采样误差等偶然因素影响。为查明各水平分组之间的差异是否显著,须对频次均值进行方差分析检验。
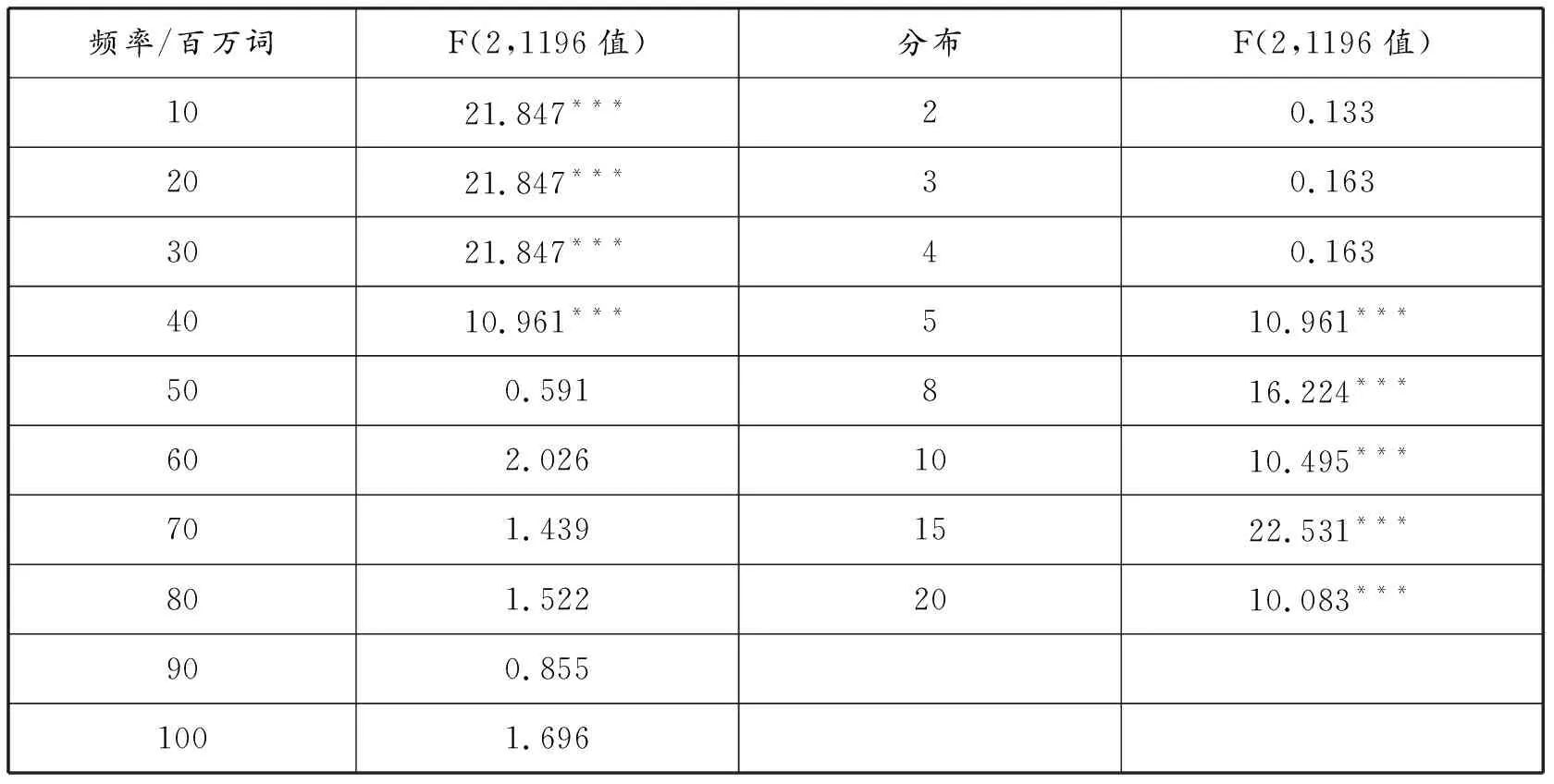
表3 不同标准下的水平分组ANCOVA检验结果
我们以学习者语言水平为自变量,作文文本长度(单词数量)为协变量,文本输出词块数量为因变量进行协方差分析(ANCOVA)。正态性检验显示,词块频次数据不符合正态分布③。为确保ANCOVA的功效④,使用Permutation(置换)检验⑤(5000次随机排列)进行ANCOVA的统计显著性检测。ANCOVA分析结果表明,在控制文本长度的因素后,三个水平分组的词块频次差异在不同标准下呈现不同的显著性。当频率标准为50次/MW以下时,不同水平分组的词块输出差异高度显著(p<0.001)。当标准提升至50次/MW及以上时,差异显著性消失。另一方面,当分布标准为4个文本或以下时,水平分组之间的词块数量差异不显著,而在5个文本或以上时变得显著(p<0.001)。
4.3 讨论
上述结果显示,提取标准的改变会导致水平分组间词块数量相对排名发生变化,而统计方法对排名的稳定性有直接影响。在采用描述性统计方法时,依照主流词块研究方法所提取的词块数量在不同标准下有较大波动,而这种波动会导致分组的相对排名发生变化,从而影响数据分析结果乃至整个研究结论。尽管词块常被定义为以大于偶然的概率共现的多词单位(Crossley & Salsbury,2011),但由于词块提取的频率和分布标准的设定没有统计学依据,所以无法准确衡量词块的出现频次是否大于偶然概率。在不同标准下任意多词单位都可能由于采样误差等偶然因素而被界定为词块,从而影响所在分组的词块数量。随着提取标准变得更加严格,提取的词块数量下降,但每个分组的下降幅度在偶然因素作用下有所不同,因此造成组间相对排名的变化。在实际研究中,词块提取标准设定的任意性(Biber et al.,2004)有可能导致在使用相同语料的条件下得到相反的结论。文献中学习者语言水平与词块输出数量之间之所以呈现相反的关系很可能是由于不同研究间提取标准和统计方式出现了差异。事实上,本研究所用语料严格控制了文体、样本数量等差异以减少分组差异带来的影响,而目前主流词块研究由于普遍没有采用相应控制手段,其波动幅度可能更加明显。
另一方面,如采用推断统计方法,分组间的比较结果在不同标准下保持了相对恒定。这可能是由于推断统计方法以文本样本为独立测量单位进行统计,纠正了词袋模型的错误假设,同时通过回归模型对每个文本的长度差异因素进行了控制,从而导致测量精度的提升。推断统计结果显示,学习者水平和词块输出数量总体呈正比关系,但这种正比关系并非在所有提取标准下都能成立。当频率标准为50次/MW以上时,不同水平分组的词块输出差异显著性消失,这可能意味着不同水平学习者间的差异不在于在最常见的高频词块,而在于中低频次的词块使用。当分布标准为4个文本或以下,水平分组之间的词块输出差异不显著,这似乎说明了低文本复现率模糊了有代表性的词块和少量学习者使用的词块的界限,从而导致无法有效区分水平。上述结果揭示了由于提取标准对词块所起的界定作用,在分析提取结果时不仅要比较数量的异同,更应关注当前标准下提取的词块所代表的特征和含义。
综上可见,推断统计方法相较描述统计方法在分析词块输出结果的稳定性和精确性方面有一定优势。首先,正如O’Donnell et al.(2013)所指出的,单纯的语料频次比较必然能发现某种差异,但主流词块研究采用的描述统计无法量化这种差异有多大概率是由采样误差等因素导致的偶然性引起,而推断统计则能推断差异在统计学上的显著性。此外,任何语言现象本质上都同时受多个因素影响(Paquot & Plonsky,2017),而个体输出的文本长度是影响词块数量统计的一个重要因素,因此应该通过统计方法对其加以控制。描述统计无法排除次要因素的干扰,从而影响结果的可靠性,而基于文本样本的推断统计方法通过把次要因素作为控制变量加以控制,最大程度上排除了偶然性因素的干扰,克服了描述统计和词袋模型假设等传统方法的局限,因此是更可靠的分析统计方法。
5.0 结语
本研究从词块研究在二语习得领域一个尚有争议的问题出发,即二语学习者语言水平与词块输出数量之间的关系,探讨主流词块研究方法所存在的问题。我们首先梳理了文献中词块提取标准和统计方法,然后借助具有权威水平分组的学习者作文语料,在最大程度上确保分组间具有可比性的前提下,进行了初步的实验和对比分析。分析结果表明,受误差和个体差异因素影响,不同标准下提取的词块数量会产生波动,从而改变组间对比结果。由于传统描述统计方法的局限,无法对这些因素进行量化和控制,从而导致相同研究可能得到不同、甚至相悖的结论。为了保证词块测量的信效度,在进行不同语料的词块对比研究时,宜采用统一的提取标准和更严谨的基于文本样本的推断统计方法。
语料库领域正在经历一场方法论上的转变,从简单的频次统计,到基于词袋模型的统计检验,再到基于文本样本的统计检验,每一步都是对之前研究的规范化和严谨化。本文从词块研究的角度,证明和呼应这个转变的必要性,希望能为词块研究乃至语料库研究方法论带来新的思考。
注释:
① 括号内为本研究转化后标准。
② 出现于不同文本的数量。
③ 事实上,由于自然语言的特点,二语和语料库研究中语言频次数据违背正态性假设是常见现象(Mollet et al.,2010)。
④ 事实上由于本研究语料样本足够大(每个分组400个样本远大于主流统计学约30个样本的要求),即使违反正态性的假设,由于方差分析本身的稳健性(robustness),也不会对方差分析的结果产生严重影响(Brezina,2018;Gablasova et al.,2017)。
⑤ Permutation检验是一种具有稳健性特征的非参数检验方法,由于其不对样本的正态性作假设,因此能够有效克服参数检验存在的问题(Van Velzen et al.,2014)。目前Permutation检验在语料库领域已经得到一定程度上的应用(Gries,2006;Ning et al.,2014;Wiersma et al.,2011)。
