基于多源语料库的二语意义、句法饱和度构建分析
——以there be句型为例
2021-05-07秦琴丁研
秦琴 丁研
(北京交通大学 语言与传播学院, 北京 100044)
1.0 文献综述
饱和度的概念源自转换-生成语法,表示所生成语言意义和形式的完整性,包括意义饱和度与句法饱和度(Heim & Kratzer,2000:3)。作为当代认知主义理论的基础,生成语法的语义理论认为,语言中具有指谓功能的词所代表的是集合概念,本身不饱和,需要有其他成分提供限制域和辖域使其饱和(Chung & Ladusaw,2004:8);意义饱和的基础是谓词+论元饱和,完整的概念与意义的形成是饱和的谓词结构不断进行组合扩张的过程(Kearns,2011)。对意义饱和度的讨论多见于跨语种的语言现象分析和特定语言现象饱和度构建与表达效果的研究,如Primus(2011)对不同语种被动结构主语论元饱和度的探讨,以词汇为核心的意义饱和度构建对表达效果的影响分析(Depraetere & Salkie,2017),以及动词意义网络构建与意义饱和度生成的研究等(Zafari & Hourali,2019)。
生成语法认为,在不考虑语用因素的条件下,句法饱和与意义饱和是并行的,具有同质性,谓词+论元饱和结构是意义、句法的接口(Chung & Ladusaw,2004)。谓词作为句子成分使用时,自身会带有价位(valence),决定论元的个数和位置,价位的填充是句法饱和度的形成过程(Plank & Lahiri,2015)。近年来针对句法饱和度的研究从之前的谓词论元层面逐渐转移到句子整体层面,如Wetta(2015)对句法片段饱和的研究,Scontras(2014)句内连接标记饱和的提出,Walker(2017)对关系从句饱和原则的分析等。在Ackerman & Webelhuth (2019)最近的研究中,提出了谓词论元饱和、所属标记饱和与修饰语饱和等相关参数和投射组合原则。
上述研究从跨语种和语用实践等视角,对意义和句法饱和度的构建途径和形态以及表达效果进行了分析,为转换-生成语法的研究开辟了更为广阔的视角,扩展了这一理论的研究深度和范围,但也存在一些不足。上述研究对象或为某一意义功能和句法范畴的跨语言对比分析,或是针对本族语语料库进行的意义、句法饱和度研究,对基于本族语者和二语学习者语料库的对比研究几乎没有,而作为一个语言生成概念,针对本族语者和二语学习者意义、句法饱和度构建的对比应当是二语习得研究不可缺少的环节。
当代二语习得的认知理论肯定了生成语法的组合观,在扩展后者语言官能理论的同时,提出语言输出过程包括概念化、意义组合和句法生成三个核心阶段(Skehan,2014),并认为与本族语者意义、句法体系相互促进的线性发展模式不同,二语学习者意义、句法体系的发展是相互制约、螺旋式上升的双相模式。针对上述观点,代表性的研究层出不穷,如二语学习者概念、意义与句法发展之间的代偿现象(Robinson,2005;Skehan,2014),概念信息复杂度与句法构建折损(Bunger et al.,2013)等。尽管上述学者针对意义和句法体系发展的研究或多或少都借鉴了生成语法和组合理论的相关原则与方法(如二语学习者意义成熟度和句法成熟度的比较),但直接针对本族语者和二语学习者意义、句法饱和度构建的对比研究几乎没有。李芝与戴曼纯(2009)的研究指出,在转换-生成语法视角下,二语习得与一语习得的状态、习得过程也必然大不相同。在这样的背景下,从意义、句法饱和度入手对本族语者和二语学习者的目的语生成规律进行挖掘和分析,是对生成语法和二语习得理论的有益探索。
综上所述,本研究以转换-生成语法和二语习得的认知理论为基础,从多源语料库提取there be句型为研究对象,通过标注、统计和自然语言处理模型,对英语本族语者和中国二语学习者输出文本中意义、句法的饱和度进行对比分析,并对其背后的深层作用机制进行探讨,具体回答以下问题:
(1)二语学习者输出文本中there be句型的句法饱和度与本族语者有无差异?
(2)二语学习者输出文本中there be句型的意义饱和度与本族语者有无差异?
(3)影响本族语者和二语学习者意义、句法饱和度构建的深层认知原因是什么?如何产生影响?
2.0 研究方法
2.1 参数设计
出于数据统计经济性的考虑,本研究先行处理句法饱和度。在存在句研究领域,较多学者认同的是there be句型的基本结构包括空主语there,表存在的系动词be和由NP构成的支柱词结构,具备上述三者的存在句称为独立存在句(bare existentials),支柱词之后还有根据需要而存在的结构,统称为尾部结构(coda),而对there be句型谓词结构的确认是长期争论的问题。本研究采用最新相关理论,认为支柱词位置的非限定性广义量词结构是谓语,系动词和支柱词之间的是修饰成分,尾部结构是谓词的隐性论元(Francez,2010;Mcnally,2016)。根据Ackerman &Webelhuth(2019)的研究,常用的句法饱和度参数包括谓词论元饱和、所属标记饱和与修饰语饱和三种。结合上述学者的研究与存在句本身的非限定特征,本文舍弃所属标记饱和,设定谓词论元饱和与修饰语饱和两个主体参数来表征there be句型的句法饱和。谓词论元饱和包括基础结构饱和与深层结构饱和两个参数,其中基础结构饱和包含四个因子:空主语、系动词、支柱词与可选尾部结构。每个因子均包括0与1两个值,任一句子若包含上述某一因子,该因子值即为1,否则为0。深层论元结构饱和因子为尾部结构长度,修饰语饱和参数统计因子为支柱词前修饰语长度。参照Charlene(2017)的研究,本文采用there be句型的T单位长度做为基础比较变量,并对二语学习者的句法正确率进行随机抽样检测,考查其there be 句型输出的句法相对饱和度。
在Heim & Kratzer(2000)和Kearns(2011)等人的研究中,意义是由性质(property)和关系(relation)构成的。表示性质的词即广义上的谓词,代表具备某种性质的个体集合,如普通名词、动词、形容词和副词等。关系的来源有两个,即词汇与句法结构。本研究讨论的是单一的there be句型,因此舍弃句法关系,采用表示关系和性质的词汇做为意义饱和度统计因子。本文对意义饱和度的分析包括两部分,通过谓词+论元结构中性质与关系词汇的统计分布和深层意义模型的析取,来表征句子内部词语意义之间的分配关系和意义组合扩张的过程。
2.2 数据处理
依据体量对等的原则,本研究在对多个语料库的容量进行对比考查后,选择BROWN、FLOB、FROWN、LOB、LOCNESS做为本族语料来源,选择WECCL和CLEC做为二语学习者语料来源,并使用兰卡斯特大学开发的标注软件claws7对所选语料库进行整体标注,在此基础上用课题组自行开发的软件Hooks对所有标注为EX0的句子进行提取,并将提取结果导入Eviews 数据库。本族语语料库提取there be句型共计7863个,二语学习者语料库提取there be句型共计9642个。课题组对所提取的句子进行了初步的筛选,剔除严重错误影响解读的句子,最终得到本族语者there be 句型7456个,二语学习者there be句型7559个,生成两个子库。选择这七个语料库为数据基础的原因是上述语料库均为封闭语料库,有一定的稳定性。为了保证研究的科学性,本研究选用COCA语料库2012-2017子库做为对比语料库,随机提取there be句型8000个,用于统计数据的对比。
3.0 数据分析
3.1 句法饱和度
在Eviews环境下,本研究将两个子库置入根据成分功能设定空位的数据库,在支柱词前后赋空位值,然后以句子为单位将所有单词按结构顺序入位,并进行特征统计,得出描述性结果如下:在本族语子库中,9.6%的句子为独立存在句,即空主语、系动词和支柱词位为非空,尾部结构为空。这一类型在二语学习者子库中占比为11.3%,经Z检验确认,二者没有显著差异。本族语there be句型的90.4%和二语学习者的88.7%尾部结构均为非空位,没有显著差异。由此可见,本族语者和二语学习者在基本结构的使用频率上没有显著差异,均表现为下述句法结构的饱和态。
[空主语] [系动词][支柱词](尾部结构)
对句子结构数据进行统计显示,本族语子库there be句型的T单位平均值为15.96,支柱词前修饰语非空位的平均值为4.93,尾部结构非空位的平均值为10.68;而二语学习者子库的上述值分别为10.76、3.76和6.31,COCA语料库随机提取there be句型的上述值分别为14.93、4.78和9.85。经Z检验,本族语者和二语学习者T单位长度差异性显著,前置修饰语差异性不显著,尾部结构长度差异性显著。图1是尾部结构长度序列和出现频率的柱形图。图中显示,本族语者和二语学习者尾部结构非空位序列的交叉点出现在8的位置,即尾部结构长度是8个词位以下的there be句子数量,二语学习者使用频率高于本族语者,峰值出现在3和4附近;尾部结构长度是8个词位及以上的,本族语者使用频率高于二语学习者,峰值出现在10和11附近。
经统计,本族语子库中尾部结构长度是8个词位及以上的句子数量占比为59.8%,8个词位以下的句子数量为30.6%;而在二语学习者子库中,尾部结构长度是8个词位以下的句子数量为62.5%,8个词位及以上的句子数量为26.2%。可以看出,本族语者和二语学习者there be句型的主体句式在尾部结构非空位的长度序列上,几乎呈现倒置的比例,二语学习者尾部结构的句法饱和度显著低于本族语者。

图1 CODA长度序列和出现频率
上述分析显示,本族语者和二语学习者在基本句法层面饱和度没有显著差异,在深层结构层面,二语学习者尾部结构的句法饱和度显著低于本族语者。
3.2 意义饱和度
本文将Claws标注后的句子置入Eviews表格,每词一格,并对所有表示性质和关系的词汇进行分类提取,非空位的词汇共提取出133个细分类。参照Kearns(2011)的研究,本文根据词性与功能将所有细分归结为19个大类,其中表示性质的八类,表示关系的十类,其他词汇一类。表示性质的包括形容词、数词、名词、人称代词、表性质的副词、实义动词谓语、实义动词的现在分词和过去分词形式;表示关系的包括定冠词、不定冠词、不定代词、并列连词、从属连词、疑问代词、介词、表关系的副词、不定式标志和助动词;其他类包括存在句标志EX0和无分类标志词汇等等。
通过Eviews对所有分类统计显示:在基本结构层面,空主语、系动词、支柱词和前置修饰语位置上词汇的性质和功能分布差异不显著,而支柱词后尾部结构中表性质与关系的词汇分布差异显著。本文分三步对尾部结构即深层论元意义饱和度进行对比。
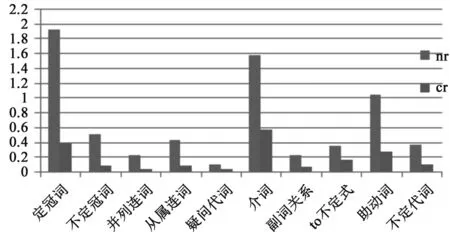
图2 表关系的词汇频率平均值

图3 表性质的词汇频率平均值
第一步,对本族语者和二语学习者there be句型尾部结构表关系和性质的词汇数量进行比较,得出图2表关系的词汇频率平均值和图3表性质的词汇频率平均值。图2、图3显示,本族语者单位句子表关系和表性质的词汇使用频率平均值均高于二语学习者,其中前者定冠词、不定冠词和从属连词接近后者的5倍,介词和助动词接近后者的3倍;本族语者名词、数词、形容词、谓语动词的平均值是二语学习者的4到10倍。
第二步,对本族语者和二语学习者there be句型尾部结构意义分配的规律进行比较,得出关系类词汇分布和性质类词汇分布。为了节省篇幅,本文只列出支柱词后八位表关系类词汇分布。表1显示,在支柱词后的八个非空位中,本族语者表关系的十类词汇的出现频率半数以上高于二语学习者,随着非空位的向后延续,本族语者呈现相对稳定的波浪形增减或稳步减少的态势,而二语学习者除不定式之外,全部快速降低,二者差距迅速拉开。表现特殊的有:介词,疑问代词、助动词前一到三位二语学习者频率出现高于本族语者的情况,之后本族语者使用频率稳步增多;不定式,第一位至第五位二语学习者使用频率高于本族语者,从第六位开始,二者均缓慢下降。
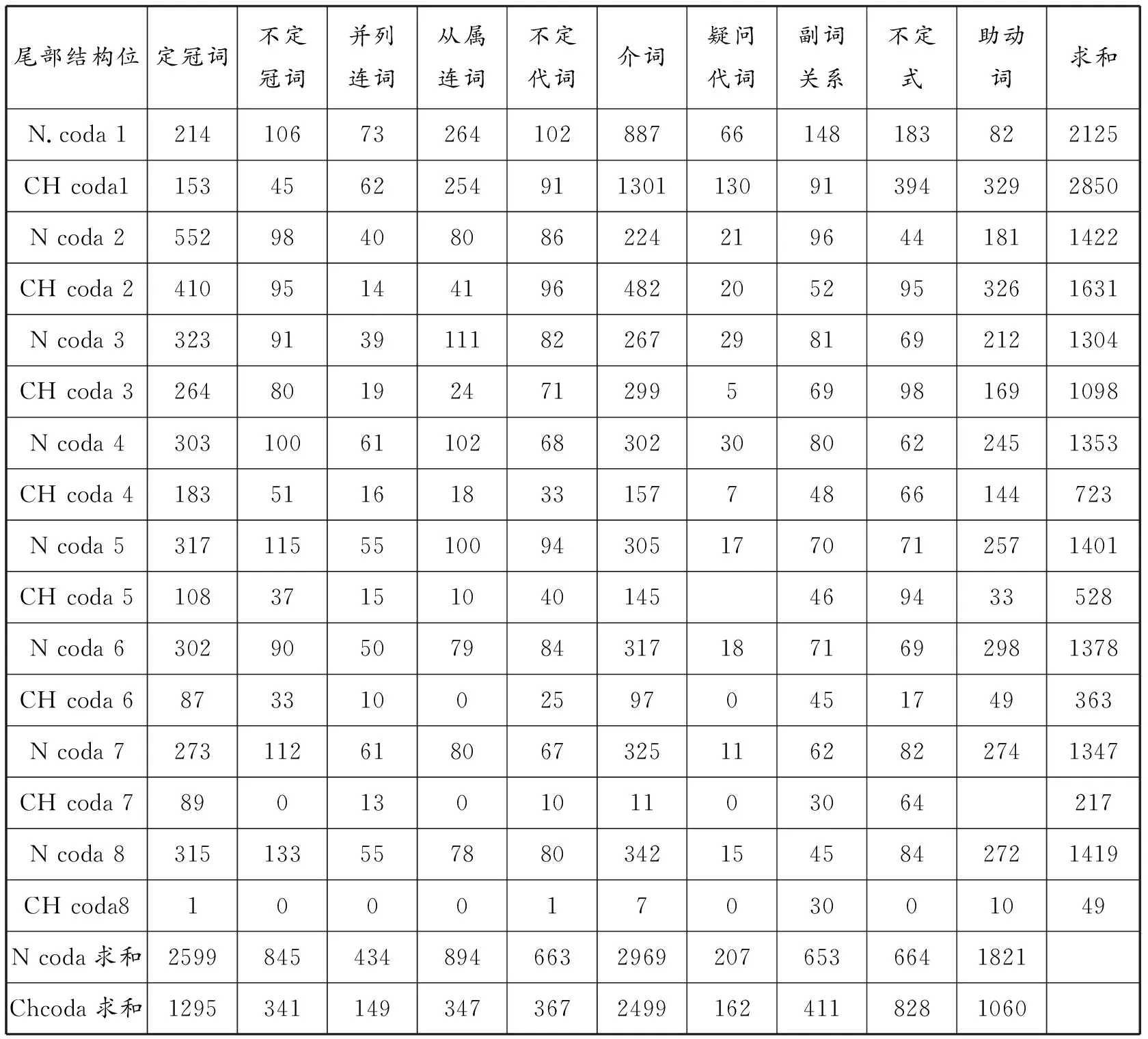
表1 关系类词汇分布
表性质类词汇分布显示,在支柱词后的八个非空位中,本族语名词、数词、表性质的副词和过去分词的出现频率始终高于二语学习者。随着非空位的向后延续,本族语上述词汇的使用频率表现出波浪型稳步下降或稳步上升的趋势,二语则表现为下降趋势。表现特殊的有:二语形容词、现在分词、谓语动词和人称代词第一位至第四位使用频率高于本族语者,之后本族语上述词汇使用频率稳步增加或保持不变,二语则快速下降。
总量求和显示,在第一和第二非空位,二语表关系和表性质的词汇总频率均高于本族语者,从第三位开始,本族语关系和性质词汇的使用频率高于二语且保持稳定,后者使用频率则急速下降。在后续表格中,本族语上述词汇分类表现出稳定的延续性,明显的下降趋势出现在19到21位之后。这表明本族语者倾向于将尾部论元的扩张铺陈于后续的非空位中,二语学习者则将意义集中于贴近支柱词的非空位。
第三步,本研究对二语学习者子库中there be句型的正确率进行了补充验证:以8个词位为界,随机抽取尾部结构8个词位以下的句子200个,连续抽取5次;再抽取尾部结构8个词位以上的句子200个,连续抽取5次。此项验证的目的是,考查在意义饱和度与本族语者接近的情况下,二语学习者能否进行正确的句法编码。结果显示:尾部结构8个词位以下的句子5次抽取的正确率分别为87.0%、65.0%、81.5%、93.5%和76.0%;尾部结构8个词位以上的句子5次抽取的正确率分别为23.5%、14.5%、28.0%、26.0%和18.5%。这一结果表明,部分二语学习者表现出了增加意义饱和度的趋势,进而写出了较长的句子,但是句法饱和度的增加是相对的,即填充了更多的位置,但同时导致了错误率的升高。
3.3 深层意义模型
本研究选择Francez(2010)和McNally(2016)的理论来构建存在句的原子概念,即支柱词本身是谓语,指谓广义量词结构,尾部结构是谓语支柱词的隐性论元,为广义量词提供辖域。近年的认知语言学和计算语言学研究均发现,认知模型和自然语言处理模型之间有着很强的联系,通过对自然语言成分进行模型算法构建,可以使句子和篇章的深层意义和概念得到清晰的表达,揭示传统研究方法无法发现的深层规律,如Kurdi(2017)和Fauconnier(2018)对DRS模型和谓词函数升级算法的运用。这些模型方法与转换-生成语法的逻辑函数有着天然的联系。本文沿用上述学者的模型架构理念,对二语学习者和本族语者的高频句式进行深层意义的提取。在前文描述性分析的基础上,本文分别从二语学习者和本族语者子库中尾部结构长度的最高频率聚集区间随机抽取句子进行比较分析。
结合上文,本族语者和二语学习者there be句型呈现如下三种型态。
第一种,独立存在句。本族语者和二语学习者这一类型的使用频率没有显著区别,代表句子如There is a shop。该句的概念模型可以用下式表示:
[[There is a shop]]=λP(e,t)[a(λx)[shop(χ)],P)](D)
该模型式构建了如下意义结构:表达量词a所辖下普通名词集合shop与语境场P的交集,D是所有组成语境域的集合。广义量词表达的是集合的集合,语义类型为
式一:
λP(e,t)[Q(λx)[N(χ)],P)](D)
第二种,尾部结构简单的存在句,二语学习者的主体句式,尾部结构长度频率峰值出现在3到4,代表句型There are two volunteers in the hospital。该句概念模型如下:
[[hospital ]]@([[there are two volunteers]])=
the(λm[hospital(m)],λy[two(λn[volunteers(n)],λm[in(m,y)])])
该模型式表示量词two所辖下普通名词集合volunteer与语境场P的交集,P为与话语参照体hospital存在in关系的所有物体集合,在模型式中进行了λ还原运算,因为尾部结构中包含的定冠词the本身需要辖域,而在该句中the的辖域是开放的,依托的是更大的语境。这一类别所表达的意义可以用如下模型式概括:
式二:
(λm[N1(m)],λy[Q(λn[Np(n)],λm[R(m,y)])]
第三种,本族语者主体句式,尾部结构长度频率峰值出现在10到11,支柱词后为多个参照体—关系词构建的集合矩阵,代表句型There were no tracks in the snow that had drifted across the long doorstep。为了阅读方便,本文将模型式分层表达:
[[across the long doorstep]] @([[ that had drifted]] @([[ in the snow]] @([[there were no tracks]])))= ……
the[λv[doorstep(v)&long(v)],λu[across(u,w)])
λT((e,t)t)[a(λi[i⊆J],λj[(λq[drift(q),(j)])])]
λj((e,t))[the(λm[snow(m)]λq[that(q,j)])
该模型刻画了一个内部存在多个层次的意义结构:普通名词集合track与语境场P的交集构建no的辖域,P表述为与话语参照体snow存在in关系的所有物体集合,在模型式中进行了λ还原运算;第二级尾部结构为定冠词the和否定词no提供了辖域,表示第一级尾部结构所提供集合在某一时间段内所具有的性质(drifted),j为该性质存在的时间,J为该句子生成时的大时间域,第三级尾部结构引入新的参照体doorstep,通过across构建更大的集合s,进行λ还原运算λu[across(u,w)],限制第二级尾部结构并为之前的冠词和否定词提供辖域。集合s应当有一个更大的语境,此处在还原运算中省略。这种意义结构类型符合Francez(2010)所提出的累积效应(stacking effect),即多重尾部结构中,后续的尾部结构限制前一级尾部结构的语境场,同时为支柱词中的量词提供构成辖域集的条件。这一类型的模型可以概括为:
式三:λCn+1[Qn(λv[N(v)],……λy[Q0(λz[Np(z)],λu[R(u,y))])……
上述分析表明,本族语者和二语学习者there be句型的意义构建有着很大的差异:本族语者倾向于使用多个性质—关系词结构形成嵌套矩阵链,尽可能包含大的信息量,为谓语提供隐性论元,这一结论符合Francez(2010)提出的本族语者闭合语境场使用倾向;而在二语学习者的主体句式中,尾部结构论元与谓词是开放的线性关系,很少形成嵌套矩阵链,对广义量词辖域的限制信息较少,意义表达对更大语境的依赖度较高。也就是说,本族语者there be 句型深层意义的饱和度要高于二语学习者。
4.0 结果分析与讨论
综上所述,在基本结构层面,本族语者和二语学习者there be 句型的意义、句法饱和度构建没有显著差异;在深层结构层面,本族语者there be句型尾部论元意义、句法饱和度要高于二语学习者,前者尾部论元倾向于使用信息量较高的集合矩阵链,为支柱词位置的广义量词提供边界清晰的辖域,对大语境的依赖性较低,二语学习者倾向于使用开放的线性尾部论元,辖域边界模糊,对大语境的依赖度较高。随着意义饱和度的增长,二语学习者的句法饱和度会相对增加,但句法错误率也会升高。
上述结果可以通过认知关系的深层构建和前语言输出阶段的内化过程两个方面来分析。
首先,认知关系的深层构建是意义饱和度构建的基础。Culicover & Jackendoff(2012)的研究指出,相同表层语言现象的内核是同一种认知关系(cognitive relation),对同一认知关系的内部处理过程会产生类似的、程式化的语法输出结构。在对本族语者和二语学习者there be句型深层意义的模型构建中可以发现,二者对这一句式的内部关系认知存在差异:二语学习者倾向于表达的是世界集或者某一时间或空间集与支柱词参照体集合的关系,世界、时间与空间本身的其他特征在这一关系之外,属于更大的语境;而本族语者倾向于表达的是支柱词话语参照体与多个特征集合的关系,世界、时间与空间本身的关联特征是内部关系的组成部分。简而言之,二语学习者表达的是话语参照体的存在和存在性,而本族语者表达的是话语参照体以什么样的方式、在什么样的地方存在和与周边参照体的关联性。
本研究认为,这一差异源自本族语者和二语学习者母语和文化背景的不同。英语there be句型的概念核心是支柱词参照物与语境集合的关系,以及集合与更广域集合矩阵的关系,是其存在方式、性质或事件性和评论性趋向等与其他参照物的上述特征共同构成的概念网络(McNally,2016)。汉语存在句核心概念表达的是某地存在、发生或消失某物或某事,是由存在动词、参与者和地点构成的小句概念体系(何伟、王敏晨,2018),与语境相关的其他参照物信息多数处于存在句之外,与英语广义量词所引入的核心参照物及其限制域和辖域所构建的嵌套语境有着本质上的区别。
深层认识关系的不同使本族语者和二语学习者自然生成了差异化的语法结构,即二语学习者简化的尾部结构论元和本族语者嵌套的复杂尾部结构论元,进而使二语学习者there be 句型谓词论元的意义饱和度远低于本族语者。
第二,前语言输出阶段的内化过程决定了句法饱和度。Skehan(2014)的研究指出,二语输出要经过概念化、公式化、词元提取、再公式化和句法编码的过程。概念化即深层意义的构建,包括所表达时间和空间的构建、核心意象与参照体的数量选择、组织关系、运动与过程等(Fauconnier,2018)。做为语言化(verbalization)的前期阶段,深层意义构建会启动使用者的记忆存储,激活大脑中相关参照体、时间、空间和性质等意义节点(nodes)及其与词汇和表层句法工具的联系,推动句法编码的实现。
本研究认为,本族语者的隐性习得背景使其对事物的概念和规律具有强大的长期记忆存储,在输出阶段的内化过程中,能够激活大量的关联信息,并且迅速检索词汇存储,寻找与意义匹配的公式化句法编码工具,最终推动句法的饱和。二语学习者在输出过程中首先受到母语存在概念的影响,其意义构建时对信息的挖掘和关联模式具有局限性;同时,二语学习者目的语记忆存储有限,词汇的检索与公式化句法编码工具的匹配相对受限,只能生成较为简单的表层结构,句法饱和度较低。
最后,二语学习者尾部结构8个词位以上的句子正确率较低,表明当部分二语学习者所输出的there be句型在意义、句法饱和度上表现出与本族语者接近的趋势时,其句法的错误率就会上升,引发相对的句法不饱和,制约意义的表达。这一结论表明意义饱和度的构建一方面是句法饱和度的推动力,能够促进句子内部结构的扩张,但是会以降低相对饱和度为代价,增加句法的错误率。而对于本族语者,概念化、公式化、词汇提取等是线性生成的过程,意义的饱和度会直接驱动句法饱和度的发展。
5.0 结论
本研究以转换-生成语法和二语习得的认知理论为基础,从多源语料库提取there be句型为研究对象,通过标注、统计和自然语言处理模型,对英语本族语者和中国二语学习者输出文本的意义、句法饱和度进行对比,并对其背后的深层作用机制进行探讨,得出结论如下。
在基本结构层面,本族语者和二语学习者there be句型的意义、句法饱和度构建无显著差异。在深层结构层面,本族语者there be句型尾部论元意义、句法饱和度要高于二语学习者,前者尾部论元倾向于使用信息量较高的集合矩阵链,为广义量词及支柱词结构提供边界清晰的辖域,对大语境的依赖性较低;二语学习者倾向于使用开放的线性尾部论元,辖域边界模糊,对大语境的依赖度较高。本族语者和二语学习者意义、句法饱和度的差异性源自二者深层认知关系和内化过程的不同;关联性认知构建和广域的概念化推动意义和句法的饱和,是二者发展的源动力。Ortaçtepe(2013)认为,深层概念构建的相似性是二语学习者实现熟练目的语输出的必然途径,本研究结论与其相似。但是在这一过程中,二语学习者意义、句法饱和度的增加会以句法错误率的上升为代价。
本研究的意义在于将转换-生成语法和二语习得的认知理论相结合,通过对英语本族语者和二语学习者输出文本中意义、句法的饱和度构建和深层认知关系的作用机制进行分析,从新的视角对二语学习者表层句法输出的提高途径进行探索。当然,本研究也存在一些局限性,there be句型只是二语学习中众多值得关注的语言现象之一,还有其他内外因素会影响意义、句法体系的发展。随着相关理论和方法的不断更新,有关生成语法和二语习得的认知研究在微观和宏观层面都有着更加广阔和深入的探索空间。
