基于改进YOLOv5的海珍品目标检测算法
2021-04-04马志强


摘 要:为掌握水下海珍品分布情况,本文结合YOLOv5s算法和注意力机制,得到一种新的轻量化目标检测模型——SE-YOLO模型。实验结果显示,相较于原YOLOv5s模型,该模型的准确率提升了1.1%、召回率提升了0.7%,并且在设计对比实验的过程中,发现传统图像增强算法并不具备提升目标检测准确度的可能。由此可见,本文提出的改进模型符合轻量化模型标准并兼具检测准确度高的优点,能够很好地完成对水下海珍品资源评估的任务。
关键词:深度学习;海珍品检测;YOLOv5
中图分类号:TP391.4 文献标识码:A 文章编号:2096-4706(2021)18-0080-06
Abstract: In order to master the distribution of underwater treasures, a new lightweight target detection model, SE-YOLO model, is obtained by combining YOLOv5s algorithm and attention mechanism. The experimental results show that compared with the original YOLOv5s model, the accuracy of the model is increased by 1.1% and the recall rate is increased by 0.7%. And in the process of designing the comparison experiment, it is found that the traditional image enhancement algorithm does not have the possibility to improve the accuracy of the target detection. It can be seen that the improved model proposed in this paper conforms to the lightweight model standard and has the advantages of high detection accuracy, and can well complete the task of evaluating underwater treasure resources.
Keywords: deep learning; sea treasure detection; YOLOv5
0 引 言
海珍品具有很高的營养价值和经济价值,有效获取海珍品具有重要意义。在获取海珍品的过程中,需要掌握海珍品的分布范围以及对海珍品进行资源评估。这些任务需要耗费大量的人力和物力。近些年来,深度学习[1,2]发展迅速,诞生了基于CNN(Convolutional Neural Networks)的目标检测算法[3-7]。目标检测算法能够定位图像中的目标,并且能够做到将目标分类。为此,目标检测算法在渔业与农业方面拥有广泛的发展前景[8-14]。使用目标检测算法对海珍品进行检测,能够有效地减少人力成本和时间成本。袁利毫等[15]使用YOLOv3算法对水下机器人采集的图片进行训练,实现对水下小目标的识别与检测。赵德安等[16]通过在投饵船上安装摄像头,使用YOLOv3对水下河蟹进行识别与检测。Cai Kewei[17]等使用YOLOv3算法实现对红鳍东方鲀的精确识别与计数。然而,为了准确地掌握水下海珍品的分布情况以及对海珍品进行资源评估,需要设计开发出检测精度更高、检测速度更快的目标检测模型。因此,本文在YOLOv5目标检测算法的基础上,提出一种检测精度更高的SE-YOLO网络结构作为目标检测算法。相较于原模型,本模型加入了注意力机制来优化其对目标关键特征的提取能力。实验结果表明,本文提出的模型不仅保持模型轻量化并且精确度更高。
1 海珍品检测框架
1.1 YOLOv5网络模型
YOLOv5目标检测算法是一种能够直接预测目标边界框和类别的端到端网络模型。该算法将图片分成S×S的网格,首先判断该网格内是否包含物体框的中心点,再预测该物体类别的置信度和边界框的坐标,最后通过真实标注框对预测框进行边框回归,实现对目标物体的检测。YOLOv5有四种网络结构,分别为YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,网络大小依次增大,其模型大小可通过宽度参数和深度参数来控制。宽度参数用来控制网络模型输出层的通道数,深度参数用来控制网络模型中卷积层的层数。
1.2 SE-YOLO网络模型
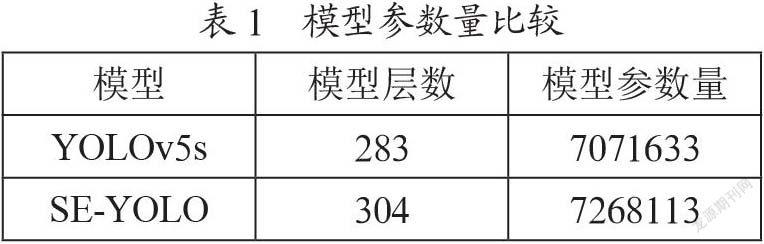
为了进一步提升目标检测模型的识别精度,本文提出SE-YOLO目标检测模型。SE-YOLO模型结合YOLOv5s网络结构和SE(Squeeze-and-Excitation Networks)[18]注意力模块,强化对检测目标有用特征的提取,以此来提升网络检测的精度,减少漏检和错检的概率。SE是通道注意力机制,它属于空间注意力机制。在卷积网络中每层都有卷积核,每一个卷积核对应一个通道,通道包含目标的一些特征。在SE注意力机制的作用下,主干网络会根据全局信息为这些富有特征的通道分配权重,重点关注对检测目标有用的特征,抑制与检测目标无关的特征。此外,SE的优点是其属于轻量化模型,不需要增加过多的计算量,在保证模型运算速度的同时提升模型的精度。如表1所示,加入SE注意力模块后,仅仅增加了少量的参数。
SE-YOLO在YOLOv5s中加入了SE注意力机制,它是由Backbone、Neck和Head三部分组成的。Backbone是SE-YOLO的主干网络,由Darknet53、CSPNet网络和SE注意力模块构成,用来提取特征图中的特征。Neck部分使用PANet[19]来生成特征金字塔。使用PANet不仅能够融合多层特征,增强模型对不同尺度对象的检测能力,还能在不受损失的情况下将浅层信息传递给深层,从而防止浅层的位置信息丢失过多。Head是模型的输出端,能够生成目标的边界框并预测类别。YOLOv5的检测头采取了多尺度输出,分别通过32倍下采样、16倍下采样、8倍下采样输出13×13、26×26、52×52三个尺度的特征图来检测大、中、小的目标。gzslib202204051155在SE-YOLO中,主干网络的作用是提取特征,SE的作用是分配特征,所以在SE-YOLO模型中,将SE模型加在backbone后面,使模型所提取到的特征信息在输入到Head之前,不会因为经过多次卷积而丢失,其结构如图1所示。其中U是特征图,C是特征图的通道,H和W是特征图的高和宽。
1.3 整体实验框架
本文的总体框架图如图2所示。SE-YOLO目标检测模型的输入端采用Mosaic数据增强的方法。Mosaic在对4张图像进行随机翻转、裁剪、排布后,再将它们拼接在一起,不仅使数据集更加丰富,还使模型在每次训练时都能够学习到目标的多样性,提升模型学习特征的能力。在数据增强之后,将图片输入到SE-YOLO网络结构中进行切片操作。切片操作即是在圖片中每隔一个像素取一个值,以此将图片分成四份并将这四张图片的通道拼接在一起,然后经过卷积后得到二倍下采样的特征图,这样大大减小了计算量使得模型更加轻量化。执行完切片操作后,特征图进入SE-YOLO的主干网络,主干网络由若干卷积单元、跨层单元和SE注意力模块构成,主要用来提取特征图的特征。跨层单元使用了CSPNet网络结构,将特征图分成两部分,一部分做卷积操作,另一部分与前一部分的卷积结果拼接并进行特征融合。在跨层单元后加入SE注意力模块。SE通过学习全局的特征信息,可为海珍品关键的特征信息分配更多的权重,避免在后续执行卷积操作时,出现丢失关键特征信息进而导致检测精度下降的问题。SE-YOLO延续了YOLOv5目标检测的方式,针对不同大小的目标,设置三个不同尺度的检测头对目标进行检测。因此,在SE-YOLO三个输出尺度前分别加入SE注意力模块,保证特征图在被输入检测头之前,不会因为卷积操作而损失关键特征信息。在目标检测时,尤其要注意小目标的检测,小目标在特征图的卷积操作过程中更容易丢失目标信息。所以加入SE注意力模块不仅能提升模型的精度,还能优化模型对小目标检测的性能。特征图经过主干网络提取特征后,SE-YOLO网络模型采取上采样和拼接的方式,将不同尺度的特征进行特征融合。在卷积网络中,特征图经过的卷积层数越多,包含的目标语义信息越多,但位置信息越少,因为像素点会随着卷积次数的增加而减少。相反,浅层的特征图像素点越多,其所包含的位置信息越多,语义信息越少。因此要使用多尺度的特征融合,使特征图既包含语义信息又包含丰富的位置信息。特征图经过三个尺度的特征融合后分别输入到52×52×225、32×32×225、16×16×225三个尺度的检测头中,分别对小目标、中目标、大目标做独立检测,最后得到三个尺度的输出结果。每个尺度的输出都携带了通道数、边框坐标、类别置信度以及目标类别数的信息。
2 实验方法与比较
2.1 数据集
目标检测模型需要大量的图像来进行训练,学习目标的特征。本文使用的数据集来自鹏城实验主办的全国水下机器人大赛——水下目标检测算法赛的官方数据集。该数据集涵盖了潜水员在水下用摄像机拍摄得到的数据(包含海参、海胆、扇贝以及海星四种目标的数据)。数据集的图像存储格式为JPG格式,图像高度为405像素、宽度为720像素。图片的标注信息储存在txt文件中,保存的内容包括目标的种类、检测框的X、Y轴中心坐标以及宽度和高度。数据集标注样例如图3所示。
2.2 模型训练
在本实验中,使用至强CPU、TiTanGPU以及两根16 GB内存条作为硬件设备,采用Windows10(64位)操作系统和Pytorch框架作为实验的运行环境。首先使用官方的YOLOv5s权重作为预训练模型来进行迁移学习,加快模型训练速度。训练过程中的训练集样本为6 737张图像,验证集样本为2 020张图像,在每轮的训练中进行分批次训练,每一批次训练16张图片,共训练200轮。为避免模型过早地发生过拟合现象,使用权重衰减以及对学习率热身的方法。学习率热身即首先让模型在开始训练时以很小的学习率来学习,熟悉模型后使用初始设置的学习率进行学习,经过多次训练后,学习率会慢慢减小,学习率变化呈现先上升到平稳再到下降的趋势。权值衰减速率设置为0.000 5,初始学习率设置为0.01。
2.3 图像增强算法对比实验
海珍品大多生长在水下,与生长在陆地环境中不同,当光线射入水中时,光的红波波长最长、穿透能力最弱,会发生衰减,而蓝波和绿波波长较短、穿透能力更强,不会发生衰减,所以会导致水下图像呈现蓝绿色的情况。图像增强算法通过提升图像对比度、恢复或增强图像色彩等手段来提升图像的质量,以此来解决水下图像因光线在水中的衰减而产生的色偏现象。目前传统的图像增强算法有很多,如基于Retinex[20]原理的MSRCR算法、ICM[21]算法、RGHS[22]算法,其图像增强效果如图4所示。图4(a)、(b)、(c)、(d)分别为原图、MSRCR增强效果图、RGHS增强效果图、ICM增强效果图。仅凭肉眼是无法判断增强效果好坏的,还需要进行定量分析。本文使用PSNR和UIQM两种评价指标来评判图像增强算法的性能优劣。PSNR是一种图像的峰值信噪比,用以评价图像的客观标准,UIQM是一种水下图像质量评价指标。两种指标的值越高说明图像的质量越高,上述图像增强算法评价指标的值如表2所示。结合图和表可知,MSRCR图像增强算法各个指标的值均为最高,因此MSRCR图像增强算法的效果最好。
2.4 目标检测模型对比实验
通过上述图像增强效果比较可知,MSRCR算法的效果最优。为验证图像增强算法对目标检测精度的影响,并且验证本文提出的SE-YOLO目标检测模型性能的强弱,本文共设计三种模型来做对比实验。将原版YOLOv5s目标检测模型作为模型I,将结合了MSRCR图像增强算法的YOLOv5s目标检测模型作为模型Ⅱ,将本文提出的SE-YOLO目标检测模型作为模型Ⅲ。gzslib2022040511553 实验结果与分析
本文采用的评价标准是平均精度均值(Mean Average Precision)、准确率(Precision)和召回率(Recall)三个指标来评价模型。准确率P和召回率R的公式分别为式(1)和式(12):
其中,TP为模型正确检测出的正样本的个数;FP为模型错误检测出的正样本的个数;FN表示模型预测为负样本,但真实值为正样本的个数;AP是通过P和R的点组合后,所画出曲线的下面积,公式为:
平均精度均值是对所有类别的检测精度取均值,它能够更为直观地衡量目标检测效果的好坏,其值越高说明模型性能越强,简称mAP,公式为:
三组模型分别经过200轮的训练之后,得到mAP0.5、mAP0.95、Precision和Recall四个评价指标,最终评价参数如表3所示。
由图5可知,模型在经过100轮的训练后,mAP趋于平稳,不再有较大的提升,将100轮训练之后的结果图放大,得到图6。从图6中可以直观地看出,加入了SE注意力模块的模型Ⅲ的性能优于使用图像增强算法的模型Ⅱ和使用原版YOLOv5s的模型I。如表3所示,在mAP@0.5方面,模型I、模型Ⅱ、模型Ⅲ的值分别为83.7%、82.4%、84.3%,模型Ⅲ的mAP值最高。在准确率方面,模型I、模型Ⅱ、模型Ⅲ的值分别为86.0%、86.1%、87.1%,模型Ⅲ分别比模型I和模型Ⅱ提升了1.1和1.0个百分点。在召回率方面,模型I、模型Ⅱ、模型Ⅲ的值分别为77.1%、76.5%、77.8%,模型Ⅲ分别比模型I和模型Ⅱ提升了0.7和1.3个百分点。由此可见,加入SE注意力机制能够提高目标检测模型的性能。
通过上述实验分析可以看出,使用了图像增强算法的模型Ⅱ并没有取得良好的效果,甚至导致mAP下降,证明传统的图像增强算法对于目标检测算法并不奏效。但是加入了SE注意力模块的模型Ⅲ在各项评价指标中均得到了提升。如图7所示,使用训练好的权重模型对水下图片进行检测,模型Ⅲ能够检测出模型I和模型Ⅱ漏检的目标。这说明添加注意力机制能够提升目标检测算法的精度,对目标检测算法的性能有较大的提升,并且在几乎不改变模型大小和增加计算量的条件下,在使模型保持轻量化的同时,提升目标检测模型的性能,能够有效地对水下海珍品资源进行评估。
4 结 论
为解决水下海珍品检测的问题,本文提出了改进的YOLOv5目标检测网络框架。首先在输入阶段使用Mosaic数据增强来丰富数据集,提升模型的泛化能力,避免过拟合现象。然后在原YOLOv5结构中添加SE注意力机制,用以提升目标检测模型的精度,而在取得性能提升的同时,增加的计算代价几乎可以忽略不计。最后通过设置三组模型来做对比实验,不仅证明了改进的SE-YOLO模型优于YOLOv5s模型,还证明了传统的图像增强算法并不能提升目标检测模型的精度。综上所述,本文提出的SE-YOLO目标检测模型能够有效地检测水下海珍品,可有效降低人力成本和时间成本。
参考文献:
[1] AGGARWAL C C.Neural Networks and Deep Learning [M].Cham:Springer,2018.
[2] LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition [J].Proceedings of the IEEE,1998,86(11):2278-2324.
[3] REDMON J,DIVVALA S,GIRSHICK R,et al. You Only Look Once:Unified,Real-Time Object Detection [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016:8418.
[4] REDMON J,FARHADI A.YOLO9000:Better,Faster,Stronger [C]//IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6517-6525.
[5] REDMON J,FARHADI A. YOLOv3:An Incremental Improvement [EB/OL].[2021-09-02] http://alumni.soe.ucsc.edu/~czczycz/src/YOLOv3.pdf.
[6] LIU W,ANGUELOV D,ERHAN D,et al. SSD:Single Shot MultiBox Detector [C]//Computer Vision – ECCV 2016.Cham:Springer,2016:21-37.
[7] REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[8] 王柯力.深度学习在渔业图像识别中的应用研究 [D].上海:上海海洋大学,2018.
[9] 閆建伟,赵源,张乐伟,等.改进Faster-RCNN自然环境下识别刺梨果实 [J].农业工程学报,2019,35(18):143-150.gzslib202204051155[10] 易诗,李欣荣,吴志娟,等.基于红外热成像与改进YOLOV3的夜间野兔监测方法 [J].农业工程学报,2019,35(19):223-229.
[11] 李善军,胡定一,高淑敏,等.基于改进 SSD 的柑橘实时分类检测 [J].农业工程学报,2019,35(24):307-313.
[12] KAVETI P,SINGH H. Towards Automated Fish Detection Using Convolutional Neural Networks [C]//OCEANS - MTS/IEEE Kobe Techno-Oceans.Kobe:IEEE,2018:1-6.
[13] 郭祥云,王文胜,刘亚辉,等.基于深度残差网络的水下海参自动识别研究 [J].数学的实践与认识,2019,49(13):203-212.
[14] LI X,SHANG M,HAO J,et al. Accelerating fish detection and recognition by sharing CNNs with objectness learning [C]//OCEANS 2016 - Shanghai.Shanghai:IEEE,2016:1-5.
[15] 袁利毫,昝英飞,钟声华,等.基于YOLOv3的水下小目标自主识别 [J].海洋工程装备与技术,2018,5(S1):118-123.
[16] 赵德安,刘晓洋,孙月平,等.基于机器视觉的水下河蟹识别方法 [J].农业机械学报,2019,50(3):151-158.
[17] CAI K W,MIAO X Y,WANG W,et al. A modified YOLOv3 model for fish detection based on MobileNetv1 as backbone [J].Aquacultural Engineering,2020:91:102117.
[18] ROY A G,NAVAB N,WACHINGER C. Concurrent Spatial and Channel Squeeze & Excitation in Fully Convolutional Networks [C]//Cham:Springer,2018:421-429.
[19] LIU S,QI L,QIN H F,et al. Path Aggregation Network for Instance Segmentation [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:8759-8768.
[20] RAHMAN Z,JOBSON D J,WOODELL G A. Multi-scale retinex for color image enhancement [C]//.Proceedings of 3rd IEEE International Conference on Image Processing.Lausanne:IEEE,1996:1003-1006.
[21] KASHIF I,SALAM R A,AZAM O,et al. Underwater Image Enhancement Using an Integrated Colour Model [J].Iaeng International Journal of Computer Science,2007,34(2):239-244.
[22] HUANG D M,WANG Y,SONG W,et al. Shallow-water Image Enhancement Using Relative Global Histogram Stretching Based on Adaptive Parameter Acquisition [C]//Multimedia Modeling.Cham:Springer,2018:453-465.
