SanssouciDB应用列式存储和内存数据管理研究
2021-04-04范晶

摘 要:内存数据管理和列式存储与内存数据库的结合是解决海量数据实时查询的可行方案之一,其代表之一是SAP的HANA内存数据库。SanssouciDB作为HANA的原型内存数据库是一个很好的研究对象。文章将从内存数据管理、内存中数据存储布局(包括行式和列式存储布局)、日志机制等方面研究SanssouciDB如何实现存储优化,查询优化。文章还将通过计算来对比列式和行式扫描的性能。最后分享实际工作中使用内存数据库所遇到的问题。
关键词:内存数据库;内存数据管理;列式存储
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)18-0013-05
Abstract: The combination of memory data management, column storage and memory database is one of the feasible solutions to solve the real-time query of massive data. One of its representatives is SAPs HANA memory database. As the prototype memory database of HANA, SanssouciDB is a good research object. This paper will study how SanssouciDB realizes storage optimization and query optimization from the aspects of in memory data management, in memory data storage layout (including row and column storage layout), logging mechanism and so on. It will also compare the performance of column and row scanning through calculation. Finally, the problems encountered in using memory database in practical work are shared.
Keywords: memory database; memory data management; column storage
0 引 言
传统数据库已经无法应付实时分析和海量数据的这对矛盾,尤其是大型制造业。虽然市面上有不少解决方案如ApacheHive,Spark SQL,这类方案依赖底层的分布式系统,其本质不是分布式数据库,数据分析的能力有限。另一种是基于MPP搭建的数据。SanssouciDB作为内存数据库在设计阶段就已经包括了要通过列式存储和内存数据管理来加速查询,目标是能达到企业对于海量数据的实时处理和查询的需求。
1 现代企业计算的新需求
传统OLTP系统是数据积累和企业电子化的基础。随着时间的推移,数据变得越来越大,对于现代企业来说如何有效的利用他们变成了新的挑战。需求则从“积累数据”变为“数据导向”。传统数据库虽然在性能上一直在努力的追赶,但现代企业更需要创新性产品在原理和架构上重构。從而对现有的数据库提出二大需求:
(1)整合:将不同数据源的数据整合到单一的数据库管理系统中。
(2)快速:越来越多的数据需要实时采集、分析,更快更全面的给予决策者支持。
SanssouciDB是具有统一分析和事务处理的原型数据库系统。接下来我将逐一介绍其内存数据管理,内存中的数据布局,日志机制以及基于内存数据库的应用开发最佳实践。
2 内存数据管理
对于传统数据库,持久化层是硬盘。而内存数据库则将主存作为持久化层,同时CPU能够从内存直接读取数据并计算,大大降低了磁盘访问量。由于内存不像磁盘可以几乎无限的扩展,内存大小是新的瓶颈。SanssouciDB[1]所要面对的就是如何更高效的使用内存从而处理更大的数据量。SanssouciDB使用了字典编码、压缩、差分缓冲区等。由于内存大小是个绕不来的坎,我们首先可以通过访问尽量少的列的数据,只有需要的属性才会被查询。另一个方法是通过减少表示数据的位数。从而同时减少对内存的消耗和访问内存的次数。第一个办法通过列式存储来解决,下一节我会重点介绍。而另一个则可以通过字典编码来解决。
2.1 字典编码
主要作用是通过长字节的值用简短的整数值来进行表示。一个列被拆分为字典和属性向量,如图1所示。
每一个字典存储着所有不同的值和他们对应的位置信息。这样的设计会带来2个好处。第一,所有操作都是通过属性向量完成,而属性向量仅包含整数,CPU最擅长处理数字而非字符。第二,由于企业数据的熵一般比较低,也就是列数据重复度大。在原始列数据中员工B和员工C出现了2次。在ValueID中我们可以看到有2个2和3,从而为压缩打下了好基础。举例,有一张包含80亿条记录的人口表,其中“性别”列只有2个值(m和f),占用1字节。在没有压缩前大小80亿×1 byte=7.45 GB。压缩后该列只需要1 bit,大小为80亿×1 bit=0.93 GB,字典额外需要2 bytes。总大小缩小近8倍。
字典编码是另外压缩技术的基础。对于属性向量,我们可以使用Prefix encoding、Sparse encoding、Run length encoding、Indirect encoding、Cluster encoding。gzslib2022040510472.2 差分缓冲区和在线合并
我们知道列存储和字典编码对于DML不是很友好。如插入一个元组,整个表将被强制重组;如果出现一个新的属性值,那么字典将被重新排序,这将大大影响性能。差异缓存的概念是将数据库分为主存和差异缓存。所有的DML都将先在差异缓存中进行,最后再合并到主存。由于差异缓存的大小远远小于主存,因此对于读性能产生的影响非常小。执行查询时,数据再逻辑上被分割为压缩主存区和差异缓存区,需要获取二部分的结果后再合并成一个整体结果反馈给用户。
在差异缓存中,我们始终保留面向列存储和字典压缩。目的是提高写入性能,但是字典没有排序,并且值存储依旧按照插入的顺序排列,所以在差异缓存中不会触发重新排序。
在差异缓存实现中,首先,我们需要保持一个列表中所有出现的数值和CSB+树,用于查询唯一值。而唯一值并不是按照特定顺序排序,因为它是在压缩的主分区中存储;CSB+树可以定义属性的排序准则,以执行在属性上的快速搜索。但是需要额外的空间用于存储树结构。由于读性能是企业应用的关键KPI,我们要确保差异缓存的大小始终保持尽可能的小。为此,SanssouciDB使用在线重组过程,周期性的将差异缓存中的数据合并到压缩的主存储区,从而形成一个新的压缩分区,既合并处理。
合并处理有二个显而易见的好处。首先,所有差异缓存中未被压缩的数据被合并到主存储并压缩,可以较少内存的消耗。其次,由于读优化的主存储中字典是排序的,因此合并二个数据结构可以提高整体的读性能。在企业应用中,合并处理有很多的挑战,可以归结为以下3点:
(1)异步执行。
(2)降低对于其它操作的影响。
(3)不能妨碍任何OLTP或OLAP的事务。
SanssouciDB[1]实现了异步在线合并,如图2所示。该模型通过在合并阶段引入第二个差异缓存,支持在合并阶段也能对数据做修改,但是为了保证数据的一致性,需要在切换数据存储的开始和结束之间加锁。例如在合并处理期间,针对有效元组的修改。在合并处理的最后一步,数据库会保存新主存储的一份快照,同时也就定义了发生故障时做日志重演的开始结点。
合并的过程由三个阶段组成:准备合并,属性合并,提交合并,如表1所示。
3 内存中的数据布局
关系型数据库的表是二维的,但主存是一维的。内存地址从0呈线性增长。传统的数据库在内存中用行式来解决。在SanssouciDB中,我们有行式、列式、混合布局。
3.1 步幅
在介绍数据布局前我想先讨论下内存访问中的步幅。参考《内存数据管理》[2]中8.1.1的步幅实验,我们可知内存访问开销和TLB之间的联系。内存的访问开销步幅正相关。当步幅小于64字节的时候,多个链表的元素位于同一个缓存中,所以加载多个元素的开销是线性的。当大于64字节时,随着步幅变大,也就意味着数组在内存中跨多页的概率变大,更多的TLB失效发生。
3.2 行式布局和列式布局
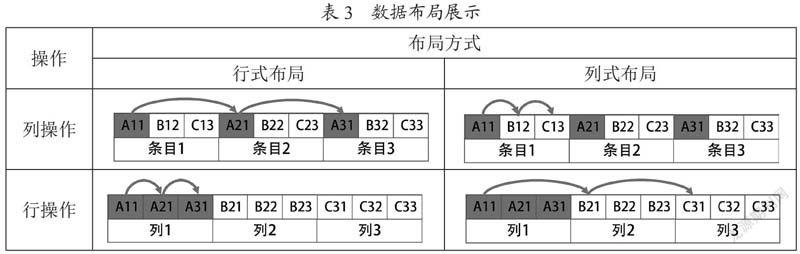
假设有如表2所示的一张数据表。
对应的行式布局和列式布局如表3所示。
3.3 列式的优点
使用列式可以利用每列中数据的本地化来采用更适用的压缩技术。它利用存储在每列中数据的相似性进行高效压缩。在《基于SAPHANA的内存数据库应用研究》[3]中,实验验证了列数值的离散程度和压缩比有强关联。离散程度越平均,不一样的数值越少则压缩比越高。列式布局还可以快速的进行列数据扫描,顺序访问效率非常高,是实现实时在线聚合计算的基础。
3.4 混合布局
混合布局结合了二者的优点,属性将通过列式存储和行式布局相结合来存储。优化组合依赖于现实的数据库负载,可以通过布局算法来进行混合。但是混合布局也有新的问题,比如对于给定的负载如何找到一个合适且优化的布局,或者如何应对变化的负载需求。
3.5 列式和行式扫描的性能对比
在本节我将通过3个场景来比对列示存储和行式存储的性能。假设有数据表,其记录全世界人的基本信息,包括名字,性别等。共80亿条元组,元组大小为200字节,数据表的总容量为80亿×200字节=1.6 TB,表的属性字段都是固定长度,主存读取的性能为2 MB/毫秒/核,高速缓存行的大小为64字节,扫描操作时只考虑使用单核CPU。通过计算在不同的3个场景下计算该表中所有女性的数量。3个场景分别为行式布局中的全表扫描,行式布局中对选择的属性字段进行步长访问,列式布局中的全列扫描。
在场景1中,要计算出女性的数量,需要逐条扫描所有行记录并读取性别字段。CPU会从主存读取1.6 TB的数据,则全表扫描的响应时间为800秒。
在场景2中,不再是扫描整个表,而是直接访问需要的那部分字段。CPU每访问一个元组,都会读取64字节的数据。因此,在整个扫描过程中,从主存读取的数据总量为80亿×64字节=512 GB,单核处理的响应时间为256秒。上述结果相比场景1有所提升,但是响应时间仍然需要几分钟。
在场景3中,根据之前介绍的字典编码我们知道只需要一个数值位就可以实现对性别m和f的编码。所以,CPU从主存中需要读取的总数量为80亿×1比特=1 GB,单核处理的响应时间为0.5秒。场景3相比前2个场景有了数量级的提升。我们来分析下为什么同样的查询在不同的布局下会有如此大的区别。
当使用列式布局,同一属性的数据将被存储在主存中的一块连续区域。由于是连续存放,可以利用有效压缩算法来减少主存中的容量,相應地减少主存与CPU之间的传输量。综上所述,即只扫描目标字段和读取压缩后的值。从这方面入手可以减少CPU和主存间的传输量从而大大降低响应时间。在次基础上再考虑多核实现并行化的扫描操作,那么我们就可以进一步加速。gzslib2022040510474 SanssouciDB的日志机制
企业级应用需要提供持久性的保障,即ACID。同时系统要具备容错能力和高可用性。对于灾难或硬件故障发生时,系统可以从故障中恢复。日志是保障数据库可以恢复的标准做法。在日志和恢复机制的协作下,数据库可以恢复到故障前的最后稳定状态。谈到日志,一个关键的KPI就是性能。这不仅仅是日志的写入,还包括恢复时日志写回内存。
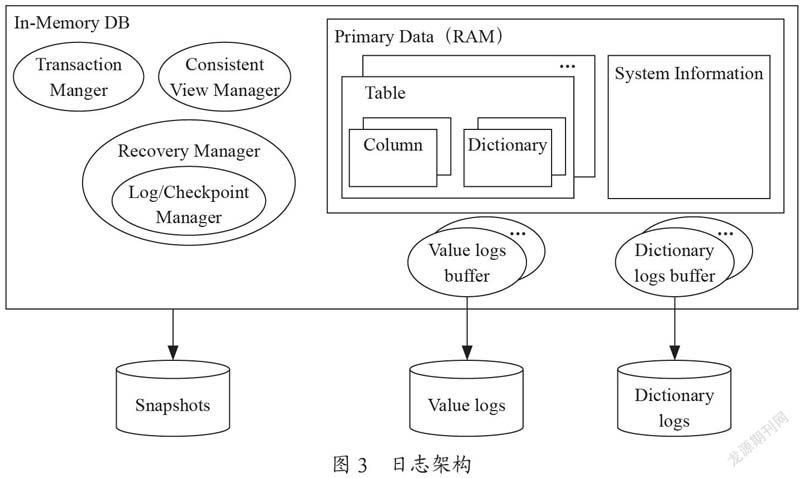
4.1 SanssouciDB日志的架构
从图3中我们可以看到写道磁盘的日志数据由主存储快照、值日志、字典日志。检查点(checkpoint)将在数据处于一致状态的某个时间点时创建数据库快照。由于时一致状态,其中包含了已提交的所有事务的处理结果。快照时读优化的主存储的拷贝,并会定期写到磁盘上。使用检查点的目的就是为了加快恢复处理的速度,因为只需要重演快照生成后的日志条目。由于快照不包括差异缓存区中的数据,这部分数据修改会记录在值日志和字典日志中。一旦事务提交,首先是字典缓存写入磁盘。这是为了避免引用这些值标识符的值日志无法恢复。然后,值日志写磁盘。最后,提交的事务日志会写入磁盘。值日志和事务日志存放在同一个日志缓冲区。
4.2 SanssouciDB日志架构的特性
和传统数据库不同,有以下特性:
(1)快照的格式:在每个检查点,主存储的快照以二进制格式写入磁盘,后续恢复时可以直接还原,快速且简单。
(2)检查点的触发:发起检查点的理想时机是差异缓存区相对主存储相对小的时候,即合并刚刚完成。
(3)存储元数据:为了加速恢复处理,会写入额外的元数据。在这些元数据可以告知数据库在加载前预先分配所需的内存空间。可以避免耗时的内存空间重新分配和数据的移动。
(4)值日志和字典日志的拆分:下节会详细讨论。
4.3 逻辑日志与字典编码日志
对于记录数据的更改,最直接的是逻辑日志。日志只是简单的在磁盘上写入SQL语句以及参数,如图4所示。
但是,逻辑日志有2个缺点。第一,日志和恢复无法并行。第二,逻辑日志直接写在磁盘上没有利用SanssouciDB[1]壓缩机制,数据量会非常大。SanssouciDB[1]使用日志结构,将编码过的字典数据从事务的上下文分离,称为字典编码的日志。这种方法允许并行恢复,并允许以任意的顺序来重演日志项。此外,由于使用了字典压缩,大大减少了日志占用的存储空间同时提高恢复的速度。
5 实际工作中使用HANA内存数据库遇到的问题和建议
HANA作为SanssouciDB的商业版本已经被众多企业肯定。在本节,我将分享在实际工作中使用HANA内存数据库所遇到的一些问题和解决方法:
(1)OLAP和OLTP混合使用下遇到的性能问题:曾多次在OLAP/OLTP混合使用的系统中遇到。现象是当有高负载的事务并叠加大的报表生成的时候,数据库性能会急剧下降,DML的时间会成倍增加。经过分析,主要原始是高负载的OLTP事务会对某些表造成很高的负载并且delta merge store会急速增加,当delta store和main store合并时再叠加save point就会造成巨量的IO和CPU的高负载。针对此类问题我们可以通过分析数据库的负载和业务人员的沟通可以获得系统的负载分布情况,通过调整业务作业的运行时间尽量避免OLTP和OLAP双高峰的重叠。同时,参考HANA维护手册[4]对相关大表进行分析并和业务充分沟通后找出适当的字段来对表进行分区用以提升delta merge的效率。
(2)单表条目数的限制问题:对于超过10亿条记录的大表,一定要尽快进行分析并通过分区或归档数据来控制。
(3)谨慎使用select…for update语句:select…for update语句使用不当会造成大量的Block Transaction.我们在SAP开发程序的时候一定要谨慎使用。
(4)在开发时要牢记确定最小数据集原则避免使用select *语句。
(5)上海交大研发的NVHT[5]和中科院研发的HiKV[6]都实现了利用DRAM和NVM混合存储并取得优异的性能。HANA在最近的版本也已经开始部分支持NVM,单限制较多,希望能在不久的将来提供更具性价比的架构和解决方案。
6 结 论
综上所述,SanssouciDB对于推进内存数据库的发展有着很大的作用,其中内存数据管理、列式存储功能的实现造就了HANA的成功,也让我们体验到了实时分析的魅力。但是内存数据库也有着明显的确定,比如严重依赖内存容量,仍然需要将数据和日志写回磁盘。近些年NVM硬件的出现让我们看到了突破口。相比DRAM,NVM可以方便的提高内存数据库容量的上限,NVM还可以替代磁盘/SSD作为数据库的持久化层。
参考文献:
[1] PLATTNER H. A Course in In-MemoryData Management The Inner Mechanics of In-Memory Databases [M].Berlin:Springer,2013.
[2] 哈索.内存数据管理教程 [M].程志国,曹乃刚,译.北京:清华大学出版社,2014.
[3] 庄辰弘.基于SAP HANA的内存数据库应用研究 [D].上海:上海交通大学,2013.
[4] BREMER R,BREDDEMANN L. SAP HANA Administration [M].Germany:Rheinwerk,2015.
[5] ZHOU J,SHEN Y,LI S,et al. NVHT:an efficient key-value storage library for non-volatile memory [C]//BDCAT '16:Proceedings of the 3rd IEEE/ACM International Conference on Big Data Computing,Applications and Technologies.New York:ACM,2016:227-236.
[6] XIA F,JIANG D J,XIONG J,et al. HiKV:a hybrid index key-value store for DRAM-NVM memory systems [C]//USENIX ATC '17:Proceedings of the 2017 USENIX Conference on Usenix Annual Technical Conference.Berkeley:USENIX Association,2017:349-362.
