基于MapReduce框架的一种并行大数据算法的研究
2021-04-04冯占伟



摘 要:为了在社交媒体数据中找出相应内容,可以通过大数据挖掘的算法对社交媒体数据进行处理。文章提出了一种处理Twitter数据挖掘的大数据算法,为保证可扩展性,基于MapReduce框架提出并行数据挖掘的大数据算法。通过实验证明了该算法是高效的,在计算上,尽管数据集大小增加,执行速度仍然可以显著增加,并且加速比随着数据集大小的增加和数据节点数量的增加而增大。
关键词:社会媒体;数据挖掘;大数据算法;推特数据;MapReduce
中图分类号:TP311 文献标识码:A 文章编号:2096-4706(2021)18-0031-04
Abstract: In order to find out the corresponding content in the social media data, the social media data can be processed through the algorithm of big data mining. This paper proposes a big data algorithm for Twitter data mining. In order to ensure the scalability, we propose a parallel big data algorithm based on MapReduce framework. Experimental results show that the algorithm is efficient. Although the size of the data set increases, the execution speed can still significantly increase, and the speedup ratio increases with the increase of the size of the data set and the number of data nodes.
Keywords: social media; data mining; big data algorithm; twitter data; MapReduce
0 引 言
最近的一些研究表明,在社交媒体上表达的舆论可能与各种社会问题相关。为了找出在社交媒体数据中实际发现的内容,通过数据挖掘可以处理大量数据,称为大数据算法[1,2]。本文中提出了一个处理Twitter数据挖掘的大数据算法。此外,为了保证可扩展性,采用Map Reduce框架来并行化所提出的算法。在过去十年中,随着Web 2.0技术和通信工程的快速发展,社交媒体的普及和扩展已经相当惊人[3]。社交媒体产生的大量数据有可能为市场和消费者行为提供一些新见解。这同样适用于政治、环境、娱乐业、股票市场等其他社会学问题。数据挖掘的关键功能是从数据中提取知识,而社交媒体就像一个广阔的未曾触动过的而充满价值的数据土地,在这块土地上使用数据挖掘技术有一个明显的动机,例如,作为社交媒体的典型例子,Twitter是一个微博应用程序,允许感兴趣的用户对其他用户的想法或生活中的某些事件实时跟踪和评论。作为最受欢迎的社交媒体之一,每天有数百万用户发布超过1.4億条推文。这种情况意味着Twitter数据是一种把有价值的数据作为一种集体知识的语料库,最近引起了各个领域的研究者的广泛关注。
在数据挖掘领域,已经有一些优秀的作品通过不同的兴趣点对Twitter数据进行了分析。这包括预测票房收入和工业平均指数的走势等[4-7]。他们的研究表明,嵌入在社交媒体中的数据有很大的力量,确实可以用来做出准确的预测。与人工专家系统不同,来自社交媒体的庞大数量的信息代表了挖掘数据的极好机会,以提取具有特定结果预测的知识。这种社交媒体数据可以用来建立模型,以汇总来自集体社区的意见,并获得一些有用的针对他们的行为的洞察,这可以用来预测未来的趋势。此外,它可以用来收集人们对特定产品的评论信息。可以证明这些评论的分析对于营销和广告活动的设计非常具有价值。
通过对过去社会化媒体数据挖掘工作的评估,我们发现社会化媒体数据挖掘最迫切需要解决的研究问题是准确地学习能够揭示情感的观点。在社交媒体上发布的大规模模糊和非结构化内容,具有快速处理社交媒体中大数据的能力。本文提出了一种大数据算法,同时也提出了一种并行算法,以处理大数据,从大量的Twitter数据中挖掘有用的见解。
1 本文提出的大数据挖掘算法
1.1 情感词的情感分类
首先给出以下定义,使问题形式化:
定义1:(记录集LD)设LD={d1,d2,…,dn}是收集的社会媒体文本数据的集合,由m个句子组成。
定义2:(同义词集列表SL)设SL={a1,a2,…,am}是媒体环境中的同义词集列表,由m标记的单词数组成。
定义3:(情绪值集SV)设SV={x1,x2,…,xm}是同义词集列表SL的每个元素的情感价值的收藏品,由m个分类数或数值或向量组成。
定义的隶属函数的输入应该是数字值或数字矢量,并且应该相对地包含语言术语的实际含义。情感同义词列表中用于隶属函数条目初始情感值已经通过SentiWordNet 3.0查询[8]。在所提出的方法中,模糊分区被定义为[正+,正,中,负,负-],也被定义为语言术语{l1,l2,…,ln}。通过这种方式,可以使用这些模糊分区来定义和确定具有清晰数值的隶属函数。由于输入数据的性质和定义的语言术语经常会产生符合高斯分布的随机情感组合,所以如式(1)所示的高斯函数被用于定义隶属函数。在同义词集列表的基础上,可以选择特定同义词集的初始情感值作为定义的隶属函数的输入,并且对于不同的语言学术语,高斯函数的参数根据选择的同义词集标签被不同地定义。
特殊语言术语li的隶属函数μFsi(x;μi,σi)可以定义为式(2):
在上面的定义式中,参数σi是高斯分布的标准偏差,它被定义为固定值[0.25,0.15,0.125],以符合情感值的理论平均分布。
1.2 Twitter数据集转换为矩阵
为了充分表示社会媒体中确定的非结构化和嵌入的观点,使用2.1节计算出的模糊值向量。本节提出了一种使用矩阵操作的新方法,将采集到的数据集转换成多级矩阵。
首先,介绍了增加维度的过程:
定义4:(顶层属性)设:UA=是通用属性集,它总结了描述社交媒体数据的所有属性。设子集Ec={Ec1,Ec2,…,Ep},Ec∈UA是社会媒体数据本质特征的顶层属性集。
定义5:(中间分层属性)设子集E′=,E′∈UA是直接构成和补充Ec元素的中间分层属性集。
定义6:(底部分层属性)设子集E={E1,E2,…,En},E∈UA是底层属性集,间接描述E′的每个元素的特性。
使用上述定义,所提出的方法的总体思想遵循了增加维度的过程。它将嵌入在社交媒体中的所有关系定义为一个图形,顶层属性是要分析的目标属性,例如“苹果公司”,中间层属性是属于顶层属性的属性,例如目标公司生产的“iPhone 5s”等产品,与目标直接相关。定义底层分层属性来描述中间层的属性,以丰富目标的隐藏信息。例如,诸如“电池”等术语是产品的特征。结合直接和间接的划分操作,所提出的维度提升过程可以显著地测量目标对象丢失和隐藏的信息,它明显优于其他现有的直接社交媒体挖掘方法。
1.3 定义数据集和LDij数据块作为矩阵
整个收集社交媒体数据可先初步转化为多级矩阵的子矩阵,并进一步给出了以下定义:
定义7:(数据块)假设记录集可以划分为m×n数据块LDij,使用底部分层属性集E={E1,E2,…,En}作为列;使用一组有序的序列对象S={S1,S2,…,Sm}作为行。
因此,对于LD中的任何数据块,LDij表示与属性Ei相关的数据记录,并按对象Sj进行分类。
然后,根据定义(4)中,记录集的任何元素都可以表示为dj=a1×X1+a2×X2+…ag×Xg。为了更好地从每个数据块LDij分组记录,一个补充的信息因子ξi被定义为适合社交媒体数据中重复和不完整的信息,目的是降低后期矩阵操作的计算代价。
定义8:(补充信息因子)设ξ={ξ1,ξ2,…,ξn}为补充信息因子,根据每条记录将所有出现的同义词信息记录为矩阵。
ξj可以测量任何一个补充信息,比如它在句子中的顺序,或者它的出现时间是1。因此,例子中的语言情感极性[P+,P Ne N N-]的定量矢量对每个特征是唯一的,与特征的值相同,因此对每个记录依次使用每个特征的这些定量向量来构造数据块LDij的数据矩阵是合理的,如下所示,一个示例性描述中假设在LDij中存在一定数量的p记录与许多K补充信息因子:
从上面的数据矩阵可以看出,行数等于数据记录的数量,说明它是一个相当巨大的矩阵。从前面的例子可以看出,在真实的社交媒体环境中,所定义的特征与例子中的情感词汇一样重复。此外,为了将选择的数据块的问题进行分类为几个类别,仅关注测量预定义的特征就足够了,但是不一定要將每个数据记录进行分类并全部包括在数据块中,因此,从上面开始,一种应用二进制系统的方法被提出,它显著地减少数据矩阵中的行数,这可以降低数据矩阵的复杂度和计算成本。
首先,该方法对所有数据块中的特征向量进行了归纳,删除其他相同的特征,构造出整个数据集的归纳特征集,例如,这个归纳特征集可以包括在记录集LD中找到的所有情绪词汇。然后,由于不需要顺序地保留数据矩阵的所有记录,下一步是确定每个数据记录中是否存在特定特征。二进制数字系统用于标记每个数据记录中的每个特征。在二进制系统中,计数只使用两个符号0和1,当数字达到1时,增量将其重置为0,并且还向左增加下一个数字。
在发现感兴趣的模糊关联规则的基础上,通过度量所有相关规则,将该算法扩展到目标预测中。更具体地说,任何模糊规则lq-lc的置信度可定义为:
2 实验分析与结果
为了评价所提出的大数据算法是否可以处理社交媒体数据的大规模收集,采用MapReduce框架并行化,以提高处理速度。实验中使用的Twitter数据集是由OACM设计的网络爬虫系统Twitter.com收集的数据[9],它包括2015年3月至2016年3月的所有推文,其中包含了超过5亿条文本记录。实验的环境是Intel i7 3720QM和2 GB RAM的CPU;操作系统是Ubuntu12.04 X86_64 GNU/Linux;以及SUN Java jdk 1.7.0_25。Hadoop集群由4个节点组成,端到端TCP套接字的带宽可达100 MB/s,对于每个NodeData,最大线程数为8。
2.1 基于并行化的大数据算法的MapReduce框架
基于该算法的处理过程,本文设计了两个Map Reduce作业来有效地并行化作业,是生成候选属性作业和生成模糊规则作业。生成候选属性作业的目的是基于两个属性对之间的关系来推断多个属性之间的关系。使用生成候选属性作业的输出,生成模糊规则作业被设计为优化所识别的兴趣模糊规则并计算每个规则权重以训练分类模型。更具体地说,生成候选属性作业包含一个Map函数,其伪码在算法1所示。输入数据集作为<key,value>对的序列文件存储在HDFS上,其中关键字是将该记录从序列文件移动到起始点偏移量,并且该值是记录集LD的内容。整个社交媒体数据集LD被分割并广播到所有的数据节点,并被并行扫描。对于每个映射任务,输出<key’,value’>对,其中key’是候选属性的值,value’是具有模糊值VBi的相应属性矩阵。
算法1:生成候選属性作业<key,value>的Map函数
Input: the offset as key, the record set LD as value.
Output: <key’, value’> pair
1.Map<attribute, vector> map= split(value.toString());
2. for(attribute: map.getkey()){
3. take name as key’;
4.matrix=new SimpleMatrix(attribute.getFuzzySetSize(), aimAttr. getFuzzySetSize());
5. i=0;
6. for(double value : map.get(attribute)){
7.matrix.insertRow(i++,0,min(value,aimAttr.getFuzzy Vector()));}
8. take matrix as value’;
9. output <key’, value’>}
在同一个数据节点中,中间数据的处理不会涉及过多的通信成本。因此,根据映射函数的输出,组合函数也被用来组合相同数据节点的中间数据和属性的模糊度。Combine函数的伪代码如算法2所示,其输出<key',value'>对的序列文件,其中key’是候选属性之间的组合的名称,并且value’由属性矩阵与相同数据节点中的模糊值{VBi,VBi+1,…,VBi+m}组成。
算法2:生成候选属性作业(KEY, V)的Combine函数
Input: key is the name of combinations between candidate attributes, V is the list of according attribute matrix with fuzzy values assigned to the same DataNode.
Output: <key’, value’> pair
1. Initiation a new Matrix argument(outMatrix);
2. while(V.hasNext()){
3. Matrix m = V.next();
4. outMatrix = outMatrix.add(m);}
5. Take key as key’;
6. Take outMatrix as value’
7. output < key’, value’> pair;
合并动作完成后,使用约简函数对所有数据节点训练数据中同一属性的模糊度进行求和,生成所有候选属性关联,并存储在MongoDB中。
2.2 提出的大数据算法的评价
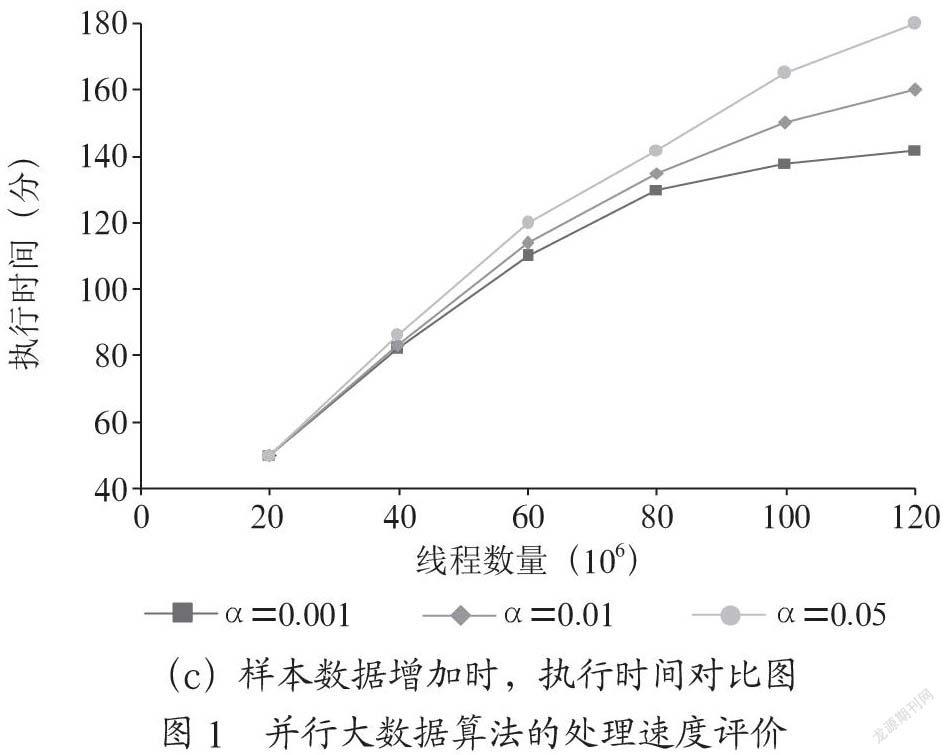
将所收集的Twitter数据集应用于所提出的并行大数据算法的实验表明,如图1所示,借助于Map Reduce框架,大量样本的处理速度远大于没有Map Reduce的版本,并且随着样本数量的增加,执行时间也逐渐增加,而非MapReduce版本的执行时间则迅速增加。增加数据集的大小说明代码的非通信部分占用更多的时间,因为有更多的I/O和事务处理。说明并行版本可以减少总体通信时间的百分比。当线程数量从8个变为32个时,另一个评估所提出的算法的性能的实验说明处理速度随着线程数量的增加而增加。此外,通过设置不同的卡方检验阈值来确定符合条件的候选人,与第一轮扫描相比,该算法在启动多属性挖掘过程时,可以显著减少扫描数据库所需的时间。
一般而言,结果表明所提出的并行算法具有次线性性能,随着数据库规模的增大,程序实际上变得更有效率,这意味着所提出的大数据算法具有处理大型社交媒体数据集的能力。在Map Reduce框架的帮助下,将整个数据集划分为若干个按照数据节点处理的子集,以保存程序扫描数据集时的大小,并将算法过程生成的中间数据存储在HDFS中,以节约程序扫描数据集的时间。这些处理也可以提高所提出的算法的处理速度,并且可以通过实验结果来证明。
将所提出的大数据算法应用于收集到的Twitter数据,通过计算Twitter消息中表达的情感来挖掘社交媒体的观点。
3 结 论
通过对近期社交网络舆情挖掘的最新评价,本文已确定并强调了最引人注目的研究问题,即准确地了解可能揭示在社交媒体上发布的大量模糊和非结构化内容的观点,并具有处理社交媒体大数据的快速处理能力。通过提出的大数据算法,通过提出的大数据算法,本文研究得到高效的实验结果。为了确保可扩展性,采用Map Reduce框架来并行化所提出的算法,通过使用社交媒体数据集,可以证明该算法的潜力。在计算上,尽管数据集大小增加,但是执行速度可以显著增加。事实上,随着数据集大小的增加以及数据节点数量的增加,加速比也随之增加。
参考文献:
[1] KAPLAN A M,HAENLEIN M. Users of the world,unite! The challenges and opportunities of Social Media [J].Business Horizons,2010,53(1):59-68.
[2] WANG F Y,CARLEY K M,ZENG D,et al. Social Computing:From Social Informatics to Social Intelligence [J].IEEE Intelligent Systems,2007,22(2),79-83.
[3] ULICNY B,KOKAR M,MATHEUS C. Metrics for monitoring a social political blogosphere:A Malaysian case study [J].IEEE Internet Computing,2010,14(2),34-44.
[4] JOSHI M,DAS D,GIMPEL K,et al. Movie Reviews and Revenues:An Experiment in Text Regression [C]//HLT'10 Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Los Angeles:Association for Computational Linguistics,2010:293-296.
[5] BOLLEN J,MAO H N,ZENG X J. Twitter mood predicts the stock market [J]. Journal of Computational Science,2011,2(1):1-8.
[6] ZHU F D,SUN H,YAN X F. Network mining and analysis for social applications [C]//KDD'14:Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.New York:Association for Computing Machinery,2014.
[7] LI J,QIN Q M,HAN J W,et al. Mining Trajectory Data and Geotagged Data in Social Media for Road Map Inference [J/OL].Transactions in GIS,2014,19(1):1-18.[2021-06-16].https://onlinelibrary.wiley.com/doi/10.1111/tgis.12072.
[8] BACCIANELLA S,ESULI A,SEBASTIANI F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining [J/OL].LREC,2010,10:2200-2204.[2021-06-16].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.180.4108.
[9] CHAN K C C,WONG A K C,CHIU D K Y. Learning Sequential Patterns for Probabilistic Inductive Prediction [C]//IEEE Transactions on Systems,Man,and Cybernetics,1994,24(10):1532-1547.
作者簡介:冯占伟(1981—),男,汉族,黑龙江巴彦人,讲师,硕士,研究方向:软件工程。
