针对Paxos算法的全局唯一自增ID的生成方法
2021-07-15黄振业
黄振业

摘 要:Paxos算法是被广泛使用的分布式一致算法,为了保障Paxos算法的正确性和高性能,需要配合使用高性能、高可用、全局唯一自增序列号的生成系统。为此,该文提出了一种全局唯一自增ID的生成方法,该方法以物理机器时钟频率不会产生大波动的特性为前提,并在实现上采用多种高性能、高可用技术。最后构建了测试环境,通过实验证明了该方案在正常态和异常态时,都能正确产生全局唯一自增ID,同时整个系统也达到了预期的高性能要求。
关键词:一致性 唯一自增ID生成 高性能 高可用
中图分类号:TP301 文献标识码:A文章编号:1672-3791(2021)03(c)-0001-06
Generation Method of Global Unique Auto Increment ID Generation for Paxos Algorithm
HUANG Zhenye
(School of Information Technology, Zhejiang Financial College, Hangzhou, Zhejiang Province, 310018 China)
Abstract: Paxos is a protocol for solving consensus in a distribution system. Paxos can work in a network with fail-ures, and all processors in the network could be unreliable. While Paxos protocol has a precondition step: generat-ing the unique version numbers for Paxos protocol. This paper proposes a method to generate the unique version numbers for Paxos protocol. And this method should be high available and should have high performance. Aiming to this object, the method utilizes the stability of machine timestamp, and uses high available techniques on imple-mentation. Finally, a test environment is constructed. Experiments show that the method can generate the unique version numbers correctly in normal and abnormal conditions, and the whole system also achieves the expected high performance requirements.
Key Words: Consensus; Unique auto increment ID generation; High performance; High available
目前,有很多分布式一致性算法來解决分布式系统的一致性问题,而Paxos算法是其中重要的一种算法,它已经被应用到多种系统中[1]。Paxos算法又分为Basic Paxos算法和Multi-Paxos算法[2]。在这两种算法之上又有一些改进的算法[3-6],但这些算法都需要有一个机制来生成全局唯一自增ID。如果不能保障生成全局唯一自增的ID,就不能保障Paxos算法的正确性。
该文提出了一种新的全局唯一自增ID的生成方法,同时会涉及工程上实现的细节。首先,简单介绍Paxos算法,其中着重说明全局唯一自增ID的生成的必要性;其次,列举其他一些常用的全局唯一自增的ID的生成方式以及它们的不足;最后,重点介绍新的全局唯一自增ID的生成方法及实验结果。
1 Basic Paxos
Paxos算法分为Basic Paxos算法和Multi-Paxos算法,而全局唯一自增ID的生成方法对两者并无区别,该文就以Basic Paxos算法作为例子来说明Paxos算法。
Paxos算法中的进程有3种身份:proposer、acceptor、learner。Paxos算法又分为两个阶段:准备阶段与批准阶段[2,7]。
1.1 准备阶段
proposer选择一个全局唯一递增的ID,n作为本轮的版本号。群发版本号为n的prepare请求给一个acceptor的多数派,即超过半数的acceptor。
每个acceptor会存储曾经批准过提案中最大版本号的提案,其中w+max_version,w为提案内容,max_version为最大的提案版本,具体请参考批准阶段的详细叙述。
每当acceptor接收到一个版本号为n的prepare请求。当n>max_version时,那么把最大版本号的提案返回给proposer,如果之前没有批准过任何提案,则返回“空”给proposer;当n<=max_version时,那么proposer不对这个版本号为n的prepare请求做出响应,并承诺今后不会批准版本号小于n的任何提案,即版本号大于等于n的提案才会被批准。
1.2 批准阶段
proposer从acceptor的多数派获得prepare请求的响应,并从这些响应中挑出版本号最大的提案内容,假设该内容为w。proposer群发一个批准请求(版本号为n,内容为w)给一个acceptor的多数派。如果proposer获得的所有响应都为空,那么群发的提案可以是任何内容。
每个acceptor接收到一个批准请求(版本号为n,内容为w),如果它不违反之前的承诺,即n>=承诺过的最大版本号,那么该提案才会被批准,并返回批准响应给proposer;否则,对这个批准请求不做回应。如果最后某个proposer没有从一个acceptor的多数派获得prepare的响应,这个proposer需要重新生成一个全局唯一递增的版本号,重新从准备阶段开始启动算法。
Paxos算法本身的证明可以参阅参考文献[7]。其中整个算法中的proposer每次必须生成一个全局唯一递增的ID作为该轮算法的版本号。此版本号必须满足两个条件:全局唯一和自增。全局唯一就是两个独立的proposer不能生成相同的版本号,而自增则是每个proposer每次生成的版本号必须是递增的。
2 现有方案的缺陷
生成的全局的唯一自增ID要满足以下几点需求。
(1)保证生成的ID全局唯一,且每个进程生成的ID自增。
(2)生成的ID最好不大于64位。
(3)生成ID的速度有要求。例如:在一个高吞吐量的场景中,需要每秒生成几万个ID。
(4)整个服务没有单点。
如果没有以上的几点需求,那么可以有很多简单的实现方案。
2.1 利用数据库的自增ID方案
利用数据库的自增ID的方法实现简单,可以保证全局唯一,但是它依赖中间节点,而且每个节点都需要访问一次数据库才能得到ID值,这样就出现了整个系统的单点问题。同时,由于数据库本身的性能限制,也不能满足高吞吐量的需求。
2.2 利用数据库的其他变种方案
利用多个写库来解决单数据库自增ID方案的单点问题:使用多个写库,每个写库的自增初始值不同,步长值不一样。假设利用3个写库:A、B、C。其中A库的ID序列为0、3、6、9,B库为1、4、7、10,C库为2、5、8,11。多写库的方案避免的单点问题,但性能还是会受到数据库性能的限制,不满足高性能需求。
另外,还有使用数据库MyISAM+Replace Intro模式的方案。这个方案由Filcker提出,采用了MySQL自增ID的方法。数据库中只存放单条记录,每次利用replace into,然后通过select LAST_INSERT_ID获取最后一个插入的ID值。该方案可以扩展为多台数据库,也可以使用不同的初始值和步长值增加可用性,但是同样不满足高性能的要求。
2.3 利用中心服务器生成ID方案
利用一个中心服务器来统一生成unique ID,但是这种方案可能存在单点问题。例如:利用开源软件Redis的原子操作方式来获取递增ID序列[8]。由于Redis具备高性能,该方案解决了数据库方案性能受限的问题,但引入了Redis同样增加了整个系统对Redis的强依赖,出现了单点问题,而且引入Redis后要保证Redis系统的高可用性与高可靠性,在工程上有很大的挑战,实现难度较大。
2.4 Twitter Snowflake方案
Twitter Snowflake方案是Twitter推出的一种算法[9],其目的是为了满足每秒能分配上万个唯一ID的需求,满足分布式环境的需求。其算法核心如下:Snowflake生成的unique ID,从高位到低位分別为:41位的时间戳、10位的节点ID和12位的序列号。为了避免保障机器号重复,每个进程启动时都需要从Zookeeper集群获取机器号。Snowflake的优点是算法简单、性能高、保持自增。但是Snowflake的实现带来了的风险:依赖Zookeeper来解决单点问题。但Zookeeper工程上运维代价过高,面对高并发,Zookeeper的性能较差。一旦proposer所在机器时钟故障,时钟被回拨,就不能保障全局唯一且递增。同样由于机器时钟可能存在的故障,有可能发生proposer宕机后恢复导致非递增ID生成的极端情况。
以上列举的几种方案,都存在一定的局限或风险,不能很好的满足Paxos算法的需求。其中Snowflake是最接近高性能需求的方案,该文重点针对其进行优化,以达到高可用和高可靠的目标。
3 全局唯一自增ID生成
Snowflake的主要缺陷就是对本机时钟有依赖,一旦本机时钟故障导致时钟回拨,就不能正确的工作;同时由于对Zookeeper服务强依赖,整个系统较为复杂。该方案的重点就是在Snowflake的基础上针对时钟问题进行改进,其核心思想就是引入一个可靠的时钟服务器,本机定时从外部时钟服务器获取到准确的时间,而时钟服务的工程实现比Zookeeper等开源系统简单可靠,从而克服了其对外部一致性服务依赖的弊端以及机器时钟回拨的问题,能很好地满足Paxos算法的需求。同时,该方法只需要定时和时钟服务器同步时间戳,确保系统具有高性能。
Snowflake生成的UniqueID的结构是一个64位的int类型数据,具体情况见图1。其中第一部分共1位,往往不使用;第二部分共41位,用来记录时间戳,以毫秒来表示;第三部分共10位,用来记录分布式节点ID,包括5位的datacenter ID和5位的worker ID,最大可部署1 024个节点;第四部分共12位,用来记录不同ID同一毫秒时的序列号。
3.1 方案改进
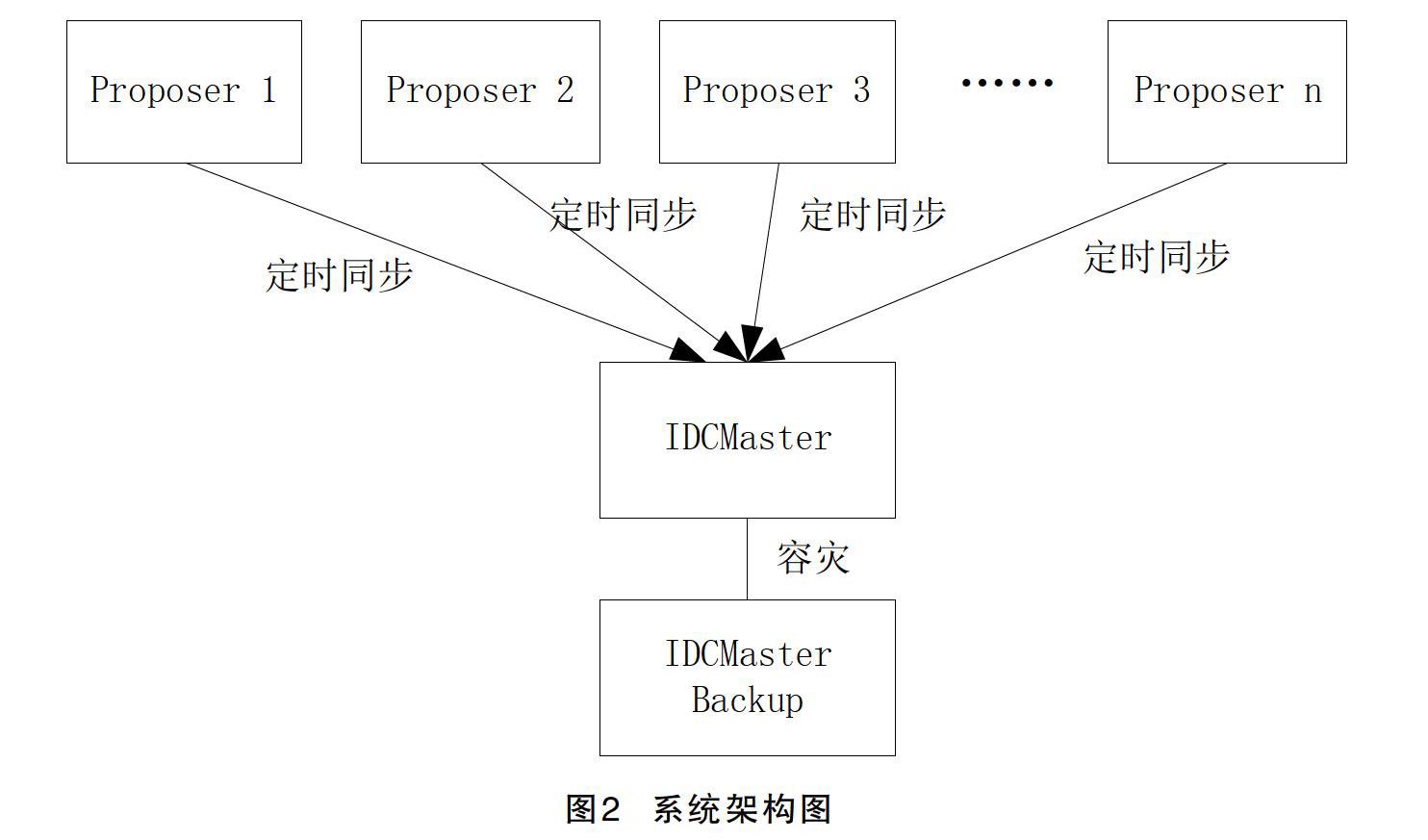
相对于Snowflake方案,该系统的关键改进为引入一個节点ID分配服务(后续简称为IDCMaster),每个datacenter有一个IDCMaster,IDCMaster也同时作为时钟服务器,向所有的节点提供时钟同步服务。
用于组装UniqueID的时间戳并不是proposer所在机器的时间戳,而是使用IDCMaster的时间戳来生成UniqueID。这样所有的proposer全部以IDCMaster的时间为准,不存在由于proposer本地时间戳不对而导致的各种不一致问题。同时,IDCMaster只是一个简单的保证时间正确的服务,相比Zookeeper,实现和运维十分简单,易于实现高性能、高可用。整个系统架构见图2。
3.2 计算方法
proposer启动时会先连接所在datacenter的IDCMaster,获取当前proposer唯一的workerID。IDCMaster保证分配出来的workerID在datacenter范围内唯一。proposer会定时从IDCMaster获取到IDCMaster的时间戳并计算出proposer所在机器的时间戳相对IDCMaster的时间偏差并存放在本地,该时间偏差值设为diff_time。
当提交prepare提案时,每个proposer不直接用本机的时间戳作为UniqueID的时间戳,而是用diff_time对本地时间戳作一个修正后来生成UniqueID。所以虽然本地时间戳可能不准确,但可以通过diff_time来修正本地时间戳,保持每次生成ID时使用的本地时间戳和IDCMaster的时间戳一致。同时,由于本地时钟频率可由硬件保证,就算出现了时钟故障导致机器时间被回拨,只需定时和IDCMaster同步,获取到diff_time就可以保证生成ID唯一递增的正确性,并具有高性能。
3.3 注意事项
该方案尽管不同于物理机器的时间戳可能有偏差,但由于物理机器的时钟频率由硬件保证,极大情况下时钟只会正向流逝。同时,即便是时间出现回拨,也通过和IDCMasterde定时同步获得正确的时间戳,快速恢复工作,并不会影响唯一自增ID的生成。这样既保证了正确性,又保证了高性能。
proposer每次定时更新本机和IDCMaster的偏差 diff_time时,必须保证修正后的时间戳单调递增。proposer只是定时访问IDCMaster,所以IDCMaster的高可用方案比较容易实现。比如可以简单地利用较成熟的IP地址漂移技术实现。利用IDCMaster Backup作为IDCMaster的备用机器,当IDCMaster宕机时,IDCMaster对外的IP地址漂移到IDCMaster Backup。当IDCMaster宕机恢复后,proposer会重连上IDCMaster,恢复更新本机和IDCMaster的时间戳的偏差即可。而且IDCMaster做的工作及其简单,只是提供一个时间戳,性能极高。当然也需要保障IDCMaster Backup的时间戳保证和IDCMaster的时间戳一致。
该方法最大的限制就是本机时钟硬件故障。但只要时钟流逝是正向的,不出现大幅时钟回拨的故障的情况下,就不会破坏整个方案的正确性,即生成唯一自增ID。因此,只需要本机proposer在每次生成ID时确认新生成的ID比上次生成的ID大。如果一旦检测到新生成的ID较小的情况,就说明这次生成的ID不正确,直接抛弃掉,直到下次和IDCMaster同步后就又能生成正确的自增ID。
当某个proposer下线后,再有一个新的proposer连上IDCMaster的场景,如果IDCMaster分配了原先的节点ID给新连上来的proposer,IDCMaster要保证同步给新proposer时间戳大于之前的下线的proposer的时间戳。
4 实验
为了验证该方案的性能及唯一ID的产生,构建了以下测试环境:10台位于同一物理机房的物理机,其规格均为4核8G。实验中逐步加大测试并发量,压测每台物理机,直到单机每秒吞吐量达到5万以上,同时也会记录下平均的延时和系统负载。测试过程中,会分别测试正常态下和异常态下系统的性能及产生ID的唯一性。
实验进程如下:初始状态为1台物理机连接上IDCMaster,并开始消耗唯一ID,然后每间隔1 min新增一台物理机连接到IDCMaster;终态为10台物理机同时连上IDCMaster进行工作,然后逐步增大工作并发量直到单机每秒吞吐量达到5万。
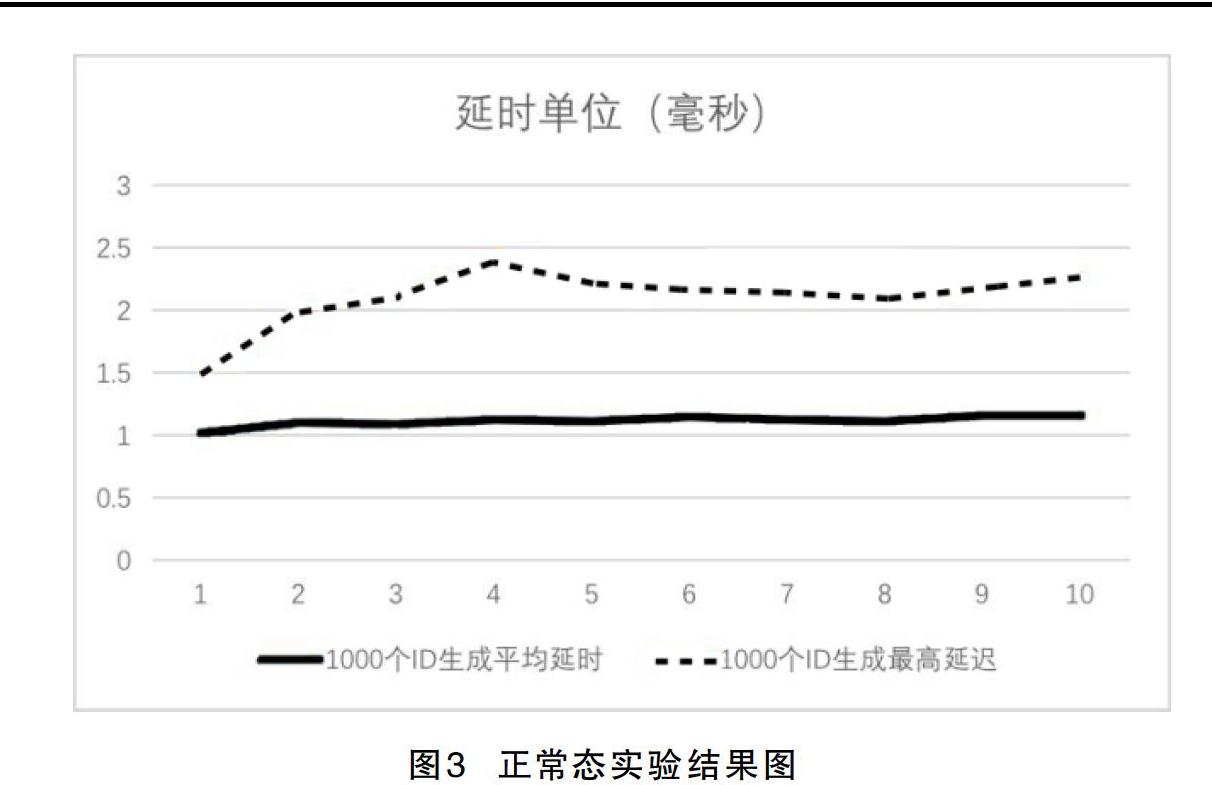
记录正常态的实验过程中每次和IDCMaster同步的延时(系统设置为每分钟和IDCMaster同步一次diff master),以及节点平均产生唯一ID的延时和最高延时,并记录实验产生的所有ID。正常态实验结果见图3。
实验结果显示,单个ID生成的耗时小于0.02 ms,生成1 000个ID的耗时在3 ms以内。同时测试单机的平均吞吐量为5万ID/s,并且在测试过程中,机器的负载很小:单机CPU利用率小于10%,单机LOAD小于0.5。同时,验证了所有升级的ID,满足无重复递增的要求。通过正常态测试,验证了该方案能满足分布式高吞吐量场景的正确性。
在正常态实验的基础上,进行异常态测试。在实验过程中,手工回拨单台物理机的本机时间,关闭NTP服务,验证服务器时钟故障的场景下ID生成的正确性。异常态测试结果如图4所示。
通过实验验证了该方法可以适应时钟回拨的故障,不影响生成ID的自增属性。当时钟回拨时,生成节点可检测到时钟问题,停止分配ID,避免了错误的ID生成,直到1 min后再次和IDCMaster同步时间戳后,能够继续分配正确的自增唯一ID。
5 结语
该文介绍了一种可应用在Paxos算法實现中的全局唯一自增ID生成方法。该方法基于Snowflake方案,但解决了Snowflake在物理机器时间戳不一致场景下不能保证生成的ID唯一自增的缺陷。该方案的核心思想是利用机器时钟频率变化不会过大的特性来实现分布式的自增ID的生成;同时也针对各种极限情况作了保障,使得即使发生特殊异常,也不会破坏整个Paxos算法的正确性。下一步工作是进一步提升生成自增ID的TPS,并探索在云主机环境的适应性,使该系统能适用于更大规模的场景。
参考文献
[1] Chandra TD,Griesemer R,Redstone J.Paxos made live:an engineering perspective[C]//twenty-sixth acm symposium on principles of distributed computing.acm,2007:398-407.
[2] Saksham Chand,Yanhong A.Liu,Scott D.Stoller.Formal Ver-ification of Multi-Paxos for Distributed Consensus[C]//International Symposium on Formal Methods,2016:119-136.
[3] 胡创,马文韬,王文杰,等.CC-Paxos:整合广域存储系统的一致性和可靠性[J].计算机工程与设计,2017,38(3):626-632.
[4] 杨革,徐虹.Paxos算法的研究与改进[J].科技创新与应用,2017(7):25-26.
[5] 赵守月,葛洪伟.MEPaxos:低延迟的共识算法[J].计算机科学与探索,2019,13(5):866-874.
[6] 王江,章明星,武永卫,等.类Paxos共识算法研究进展[J].计算机研究与发展,2019,56(4):692-707.
[7] Lamport L.Paxos made simple[J].ACM SIGACT News, 2001,32(4):51-58.
[8] Yao Kan,Ni huxuan,wang yuan,et al.Low Cost and High Concurrency ID Mak-er in Distributed Environment[C]//ITM Web of Conferences,2017:03003.
[9] Jim Bumgardner.Tracking Twitter's Growth after Snow-flake[EB/OL].[2019-05-12].https://www.jbum.com/papers/TrackingTwittersGrowthAfterSnowflake.pdf.
