基于联邦学习的教育数据挖掘隐私保护技术探索
2020-12-06李默妍


[摘 要] 近年来,人工智能在教育领域发挥着日益重要的作用。但随着隐私泄露问题的凸显,如何在保护学习者隐私的基础上,使用来自多方的数据以提升人工智能应用的性能,成为智能时代亟待解决的问题。为此,文章引入了人工智能领域新兴的联邦学习概念,分析了联邦学习的定义、系统模型与训练过程、隐私保护技术,并将联邦学习与教育数据挖掘的各类算法相结合,以解决教育数据挖掘中可能存在的隐私保护问题。研究发现,联邦学习方法能够从原理上保障数据隐私,且容易整合到现有的教育应用中;在保护隐私的基础之上,运用联邦学习能够最大程度地提高模型精确度;将联邦学习与教育数据挖掘相结合,既能最大化地发挥利益相关者的作用,又能满足各利益相关者的需求。联邦学习将为教育的信息化与智能化发展开辟全新的路径。
[关键词] 联邦学习; 教育大数据; 教育数据挖掘; 隐私保护; 机器学习
[中图分类号] G434 [文献标志码] A
[作者简介] 李默妍(1995—),女,山东广饶人。博士研究生,主要从事教育政策与比较教育研究。E-mail:moyan.li@zju.edu.cn。
一、引 言
教育数据的收集与使用是人工智能时代智慧教育得以持续发展的重要驱动力。然而,对教育数据的深度挖掘,却产生了泄露学习者隐私、侵犯人格尊严的风险[1]。因此,如何在充分利用教育数据的过程中保障学习者隐私,成为备受关注的研究课题。现有研究文献探究了教育数据隐私保护的部分举措。例如,有研究者从数据治理层面出发,认为需重构数据治理的制度伦理规范、提升教育决策主体的数据治理能力[2],有研究者从技术层面出发,详细阐述了信息安全技术[3]、区块链技术[4]在教育数据隐私保护中的应用。但是,即使实施了上述措施,在数据挖掘过程中依然需要对教育数据进行收集与传输,难以规避各个环节中可能发生的隐私泄露问题。如今,学习者对于教育隐私保护的需求以及智能时代对于教育数据共享的需求之间的矛盾,已经成为影响人工智能技术在教育领域发挥作用的重要矛盾。
为了解决在各行各业中均出现的数据隐私保护问题,谷歌公司于2016年提出了联邦学习(Federated Learning,FL)方法。联邦学习是一种新兴的机器学习方法,通过这一方法,参与者无须上传原始数据,机器学习过程在中央服务器的协调下于每个参与者本地进行,并且仅交换模型特征,如参数、梯度等[5]。与其他隐私保护技术相比,联邦学习方法无需集中收集原始数据,也就没有后续的数据传输与公开共享等环节,能够在根本上解决数据挖掘中的隐私保护问题。如今,联邦学习已成为人工智能的热门研究主题,在智慧医疗、智慧城市建设等领域内获得关注,但在充满潜力的教育领域却鲜有研究。因此,本文试图对联邦学习方法进行介绍,并初步探究联邦学习与教育领域可能的结合点与应用前景,为学界和业界的深入研究与应用提供一定的启发与参考。
二、联邦学习的基本内容
(一)联邦学习的定义
定义N个参与者P={p1,…,pN},每位参与者拥有一个私人数据集{D1,…,DN}。传统的机器学习方法将每位参与者的数据集统一到一个数据湖D=D1∪…∪DN,再训练模型MSUM。而在联邦学习方法中,每位参与者pi在中央服务器的协调下于本地训练模型{M1,…, MN}及其参数{w1,…,wN},将模型M_N的参数wN传回中央服务器,由中央服务器整合为全局模型MFL。
若将模型MFL、MSUM的精确度分别定义为VFL、VSUM,这两个数值应该是非常相似的。将δ定义为一个非负的实数,若|VFL-VSUM|<δ,则认为联邦学习算法具有δ-精度损失[6]。
(二)联邦学习模型的系统模型与训练过程
联邦学习的系统模型由中央服务器与数据拥有者或参与者组成,如图1所示。中央服务器一般由发起联邦学习任务的公司、组织或研究者的私有云服务器或租用的公有云服务器承载。根据任务的不同,数据拥有者的类型可以是多样的。例如,当教育机构内部需要使用学生的教育数据训练模型时,数据拥有者就是存储教育数据的学生自有客户端如手机、电脑、平板電脑等移动设备。当教育机构之间借助各自存储的数据合作进行模型训练时,数据拥有者就是各机构的私有服务器。数据拥有者需于本地安装联邦学习相关的训练组件,一般而言,组件是与任务发起者提供服务的软件组装在一起的。参与联邦学习过程的数据持有者于本地存储数据需要经过一段时间的积累。如果没有积累足够的数据,就不能入选为参与者。数据拥有者需要通过以太网络或蜂窝网络与中央服务器连接与通信。
在此基础上,联邦学习模型最常用的算法为联邦平均算法(Federated Averaging Algorithm),训练过程展示在算法1中(如图2所示)。
训练过程主要包括以下三个步骤:
(三)联邦学习的隐私保护技术
为参与者提供个人隐私保护是联邦学习显著的特点,参与者仅共享模型参数,而不共享原始数据,从根本上解决了参与者的数据泄露问题。但有研究表明,通过参与者共享的模型参数也能推断出参与者的部分粗略信息,如性别、职业、地理位置等[7],因此,为了防止恶意参与者或者恶意服务器通过共享参数来反推其他参与者的敏感信息,联邦学习可以使用多种隐私保护技术,为参与者的个人隐私提供全方位的保护。运用于联邦学习的隐私保护解决方案有以下三种:
1. 基于差分隐私(Differential Privacy)的解决方案。该解决方案主要针对恶意参与者,其核心思想是在将参与者共享的参数发送至中央服务器之前,利用高斯机制(Gaussian Mechanism)等差分隐私保护随机机制在参数中添加噪声(Noise),使得恶意参与者无法使用共享全局模型的参数来推断其他参与者的信息。同时,参与者不断计算恶意参与者利用共享参数反推信息的可能性,一旦达到预先设定的阈值,就终止模型训练过程[8]。
2. 协作训练(Collaborative Training)解决方案。该解决方案的核心思想是参与者不将其本地训练后产生的完整参数集上传中央服务器,也不将整个全局模型更新至本地,而是有选择地上传与下载,根据情况确定共享的参数数量。研究表明,即使参与者没有上传完整的参数集,最后训练出来的全局模型与拥有完整参数集的全局模型的准确性仍旧相近。例如,对于MNIST数据集,当参与者同意共享10%的参数时,全局模型的准确度达到99.14%,当参与者仅共享1%的参数时,准确度也达到了98.71%[9]。
3. 基于加密(Encryption)的解决方案。此解决方案的核心思想是,在将参与者的训练参数发送到服务器之前,使用同态加密技术对其进行加密。加密是有效且较为常用的隐私保护方法,也可以与其他解决方案混合使用。有研究提出了基于加密与差分隐私的混合解决方案,在将参与者的参数发送到服务器之前,使用加法同态加密机制并添加故意干扰原始参数的噪声以保护参与者的隐私[10]。
三、联邦学习在教育领域的应用
(一)教育数据挖掘中的隐私问题
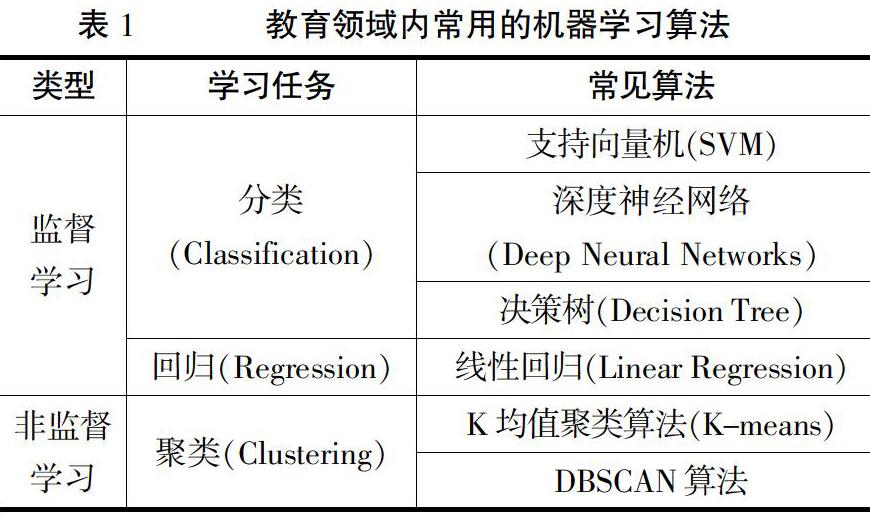
根据数据类型的不同,教育大数据挖掘领域内常用的机器学习算法主要可以分为监督学习(Supervised Learning)、非监督学习(Unsupervised Learning)两类:监督学习是指用有标签(Label)的数据来训练模型,使得模型能够产生正确输出;非监督学习是指模型从没有标签的数据中挖掘其隐含的关系与结构[11],见表1。
不同的算法具有各自的优缺点,教育研究者根据其具体的学习任务以及收集的数据类型来选择实现算法。但各类算法都需要相关教育数据的支持,都有可能存在隐私泄露的问题。
当研究者希望对数据进行分类且具有明确的类型时,就可选择支持向量机、深度神经网络等监督学习中的分类算法。支持向量机具有结构化风险最小、泛化错误率低等优势,在教育领域多用于进行教学质量评价、学习过程评价等。在使用支持向量机建立教学质量评价体系时,研究者常使用专家评价以及学生评教的各項数据对模型进行训练,评价指标包括教师的教学态度、教学内容、教学方法等[12]。学习过程评价模型训练需要学生的自我评价与教师评价数据,评价指标包括出勤率、学习态度、作业正确率等数据[13]。若这些数据被公开共享,对教师与学生都是不利的。
深度神经网络具有多层人工神经网络,在图像识别、语音识别、文本识别等方面表现优异。在教育领域,深度神经网络的典型应用为构建学习资源推荐系统。研究者收集学习者于在线学习平台上留下的历史学习数据与个人信息,如学习类型、学习数量、学历、所处行业等,以及学习资源中包含的信息,从而为数据集训练模型[14]。深度神经网络的另一大应用为通过对学生的人脸识别以及语音识别进行情感计算,分析学生上课时的专注程度、理解程度等,从而促使教师提高课堂教学质量,帮助学生提高学习效率[15]。此类深度神经网络模型需要收集多视角的课堂录像,利用其中包含的大量图像数据与语音数据进行训练。图像、语音与文本数据中包含的信息、内容、情感都构成了参与者的隐私,若发生泄露,不仅威胁学习者的个人隐私安全,还可能产生侵犯肖像权、知识产权等法律风险。
回归算法是一种经典的机器学习预测模型,具有结构简单、原理易懂的优势。当数据点围绕主轴上下波动时,就可以选择线性回归算法构建模型。例如,有研究者利用多元线性回归的算法构建了以数学成绩预测学生其他计算机科学课程成绩的模型[16]。在这一模型中,学生的数学成绩数据将存在隐私风险。
当研究者希望将数据集中相似的数据聚集到一类,但并不知道具体有几个类别时,就可以选择K均值聚类、DBSCAN等非监督学习中的聚类算法。聚类算法在教育领域的应用比较广泛,学生成绩预测、学生行为分析、教学质量评价等都有涉及。例如,有研究者使用K均值聚类算法分析大学生进行的课程评价以及他们在相应考试中的成绩之间的关联性,以建立一个利用学生评教预测学生考试成绩的模型[17]。在这一模型中,研究者预先收集的学生评教数据以及学生的学业成绩数据存在隐私风险。
(二)联邦学习在教育数据挖掘中的应用案例
当使用传统的机器学习方法训练模型时,研究者需要收集大量的教育数据样本,集中进行数据处理以训练模型。在这一过程中,数据的收集、传输、存储、使用等环节都有可能造成数据泄露而侵犯隐私。而在联邦学习中,机器学习过程均在参与者的本地进行,无须收集与传输数据,与中央服务器的通信内容仅限于加密后的参数,能够有效地保护参与者的隐私。几乎所有应用于教育领域的机器学习模型都可以使用联邦学习方法进行训练,为教育数据挖掘过程中的个人隐私保护问题提供有效的解决方案。在解决数据隐私问题的同时,联邦学习也能够最大化地保证机器学习模型的准确性。本文以基于支持向量机的教学质量评价、基于深度神经网络的学习资源推荐、基于K均值聚类算法的学生成绩分析三个实例说明使用联邦学习的方法与流程。
1. 联邦学习在支持向量机中的应用
使用支持向量机进行教学质量评价模型训练的基本原理是求解能够正确划分教学评估数据类别且几何间隔最大的超平面。与需要收集数据进行统一运算的传统支持向量机不同,基于联邦学习的支持向量机算法要求运算过程在参与者的本地进行,不进行数据收集或传输等过程。其基本流程如图3(1)所示:首先,中央服务器将教学质量评价分类任务初始化,确定任务需要的数据,如学生与专家对课程或教师进行的打分等,选取具备这些数据的参与者,并决定参数传输过程中的加密方式。之后,中央服务器决定支持向量机模型种类,如使用高斯核函数(RBF)的支持向量机模型等,并向各参与者下发初始参数。每个参与者于本地进行支持向量机运算,根据本地存储的教学评估结果计算数据点与超平面的距离,计算梯度,优化更新本地参数并将其传回中央服务器。中央服务器将各参与者上传的本地参数进行求平均运算,并将运算结果再次下发至参与者,参与者再次进行本地的优化更新,如此循环直至达到T轮,损失函数收敛。中央服务器将最后一轮本地参数求平均,输出教学质量评价模型,进行测试验证。
[参考文献]
[1] 庞茗月,胡凡刚.从赋能教育向尊崇成长转变:教育大数据的伦理省思[J].电化教育研究,2019,40(7):30-36,45.
[2] 田贤鹏.隐私保护与开放共享:人工智能时代的教育数据治理变革[J].电化教育研究,2020,41(5):33-38.
[3] 刘梦君,姜雨薇,曹树真,杨兵.信息安全技术在教育数据安全与隐私中的应用分析[J].中国电化教育,2019(6):123-130.
[4] 杨兵,罗汪旸,姜庆,朱晓钢,郭强.基于联盟链的学习数据存储系统研究[J].现代教育技术,2019,29(8):100-105.
[5] HARD A, RAO K, MATHEWS R, et al. Federated learning for mobile keyboard prediction[EB/OL]. [2019-02-28](2020-06-25). https://arxiv.org/abs/1811.03604.
[6] YANG Q, LIU Y, CHEN T, et al. Federated machine learning: concept and applications[J]. ACM Transactions on intelligent systems and technology, 2019, 10(2): 1-19.
[7] MELIS L, SONG C, DE CRISTOFARO E, et al. Exploiting unintended feature leakage in collaborative learning[C]//IEEE. Symposium on Security and Privacy 2019. San Francisco: IEEE, 2019: 691-706.
[8] GEYER R C, KLEIN T, NABI M. Differentially private federated learning: a client level perspective[EB/OL]. [2018-03-01](2020-06-25). https://arxiv.org/abs/1712.07557.
[9] LECUN Y, BOTTOU L, BENGIO Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
[10] BONAWITZ K, IVANOV V, KREUTER B, et al. Practical secure aggregation for privacy-preserving machine learning[C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. Dallas: ACM, 2017: 1175-1191.
[11] GHAHRAMANI Z. Unsupervised learning[C]// BOUSQUET O, RAETSCH, G, VON LUXBURG U. Advanced lectures on machine learning. Berlin: Springer Verlag, 2004: 72-112.
[12] 劉伟,孙林.基于支持向量机的课堂教学质量评价[J].合肥工业大学学报(自然科学版),2010,33(7):968-971.
[13] 李候梅. 基于支持向量机的学习过程性评价研究[D].重庆:重庆师范大学,2015.
[14] 樊海玮,史双,张博敏,张艳萍,蔺琪,孙欢.基于MLP改进型深度神经网络学习资源推荐算法[J].计算机应用研究,2020,37(9):2629-2633.
[15] 李胜男. 基于人工智能技术的课堂教学行为的分析框架构建研究[D].北京:北京邮电大学,2019.
[16] OYERINDE O D, CHIA P A. Predicting students' academic performances—a learning analytics approach using multiple linear regression[J]. International journal of computer applications, 2017(4): 37-44.
[17] CAMPAGNI R, MERLINI D, VERRI M C. Finding regularities in courses evaluation with k-means clustering[C]//CSEDU. Proceedings of the 6th International Conference on Computer Supported Education, Setubal: Science and Technology Publications, 2014(2): 26-33.
[18] WANG S, TUOR T, SALONIDIS T, et al. Adaptive federated learning in resource constrained edge computing systems[J]. IEEE journal on selected areas in communications, 2019, 37(6): 1205-1221.
[19] CHANDIRAMANI K, GARG D, MAHESWARI N. Performance analysis of distributed and federated learning models on private data[J]. Procedia computer science, 2019(165): 349-355.
[20] 李春生,刘涛,于澍,张可佳.基于K-means算法的研究生入学成绩分析[J].计算机技术与发展,2019,29(2):162-165.
[21] SOLIMAN A, GIRDZIJAUSKAS S, BOUGUELIA M R, et al. Decentralized and adaptive K-means clustering for non-IID data using hyperLogLog counters[C]//Pacific-Asia Conference on Knowledge Discovery and Data Mining. Berlin: Springer, 2020: 343-355.
[22] ZHAN Y, LI P, QU Z, et al. A learning-based incentive mechanism for federated learning[J]. IEEE internet of things journal, 2020:1-9.
[23] KANG J, XIONG Z, NIYATO D, et al. Incentive design for efficient federated learning in mobile networks: a contract theory approach[C]// IEEE. 2019 VTS IEEE Asia Pacific Wireless Communications Symposium, Singapore: IEEE, 2019: 1-5.
