多粒度拓展语言层级群组DEMATEL改进方法*
2019-01-17孙永河
韩 玮,孙永河
1.昆明理工大学 管理与经济学院,昆明 650093
2.昆明理工大学 城市学院,昆明 650051
1 引言
20世纪70年代,日内瓦研究中心的Gabus和Fontela两位教授提出决策试行与评价实验室方法(decision making trial and evaluation laboratory,DEMATEL)[1-2],应用表格和图表对系统因素间的因果关系进行刻画,可广泛用于复杂系统因素分析。近年来因方法的普适性和机理简洁性而倍受国内外学者的关注,并在管理科学诸多领域得以大量推广应用[3-6],例如医院服务质量[7]、钢铁企业管理[8]、应急管理[9]和绿色供应链的供应商选择[10-11]等问题。
传统群组DEMATEL方法要求专家按照统一指定的标度给出因素间影响关系的偏好判断信息。事实上,专家很可能在知识结构、背景、认知等方面存在差异,也就是在评价标度选择中,可能倾向于用不同粒度的评价标度来反映知识的精细程度,从而给出更符合自身偏好的判断。因此探讨多粒度评价标度下的群组DEMATEL问题具有实际研究价值,而现有文献尚未发现相关研究。
对于多粒度群组决策问题,其核心处理环节是数据归一化[12]。为了解决这一问题,近年来涌现了一系列相关研究。Herrera等[13]提出基本语言术语的概念,利用模糊集的算法,将多粒度评价标度下的不同粒度评价信息以基本语言术语进行归一处理;Chen和Ben-Arieh[14]对模糊集算法的归一环节进行改进,提出一种无需基本语言术语,即可在任意两种评价标度下的术语间转换映射的方法。Jiang等[15]、Fan和Liu[16]、Zhang和Guo[17]将多粒度标度的评价信息在语义基础上转换为模糊数,实现归一化和集成。而这些模糊集算法均存在计算结果精确性欠佳等缺陷,为此Herrera等[18]提出一种基于二元语义的语言层级模型,定义了一一映射的转换函数概念,构建了在不同层级、不同粒度的语言评价标度术语间进行转换的函数,且不存在转换过程中的信息损失。根据Herrera的对比研究,用二元语义来表示模糊语言偏好具有以下三方面的独特优点:(1)在语言偏好信息的描述上,它在自然语言术语的基础上增加一个符号平移数,既表达专家对偏好的定性描述,又加入对定性描述的定量补充;(2)二元语义表示的模糊语言偏好信息能避免群体决策信息处理和计算过程中的信息丢失问题;(3)用二元语义表示模糊偏好更容易得到群体意见的一致性。但Herrera等提出的语言层级存在代表域方面的不足,语言层级中的评价标度术语有严格的限制。为此,Espinilla等[19]对语言层级方法进行改进,以新增层级构建拓展语言层级模型,运用桥梁层次作为转换中介,从而能更加灵活地对多粒度评价标度信息进行归一化处理,实现多粒度评价标度下偏好判断信息的归一化。
Espinilla等[19]提出的拓展语言层级模型,在设置语言评价术语集粒度时更为灵活,适合群组DEMATEL方法的评价标度表达方式。因此,本文基于拓展语言层级模型,应用二元语义信息表达,对多粒度评价标度群组DEMATEL的系统因素分析问题提出了改进方法。
本文后续部分安排如下:第2章介绍DEMATEL方法、二元语义表示模型、语言层级模型的相关概念,为后续建模提供知识基础;第3章针对多粒度评价标度群组DEMATEL方法,给出数据归一和集成的具体方法和改进DEMATEL方法的步骤;第4章将方法运用于具体案例,说明方法的可行性和适用性;第5章给出本文结论。
2 预备知识
2.1 DEMATEL方法的基本步骤
DEMATEL方法是为了解决现实生活中复杂的社会、经济问题而提出的,确切地说是为现实社会中零散和对立的问题寻求一种整体解决方案,进而探索问题的本质。方法的基本步骤如下:
步骤1对系统A={a1,a2,…,an},专家按照指定标度对因素间影响强度进行判断并按大小依次赋值,构造初始直接影响矩阵R=[rij]n×n,其中rij为因素ai对aj的直接影响程度,rii=0,i=1,2,…,n。
步骤2按式(1)对初始直接影响矩阵进行规范化处理,得到规范化直接影响矩阵X。
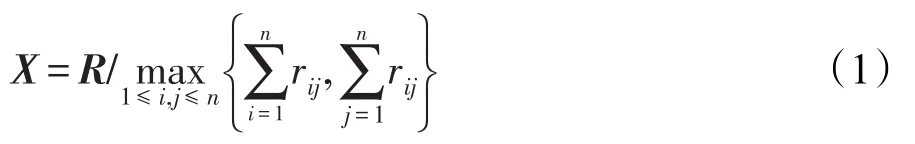
步骤3以hij反映因素ai对aj的综合影响程度,I为单位矩阵,按式(2)构造反映因素间直接影响和全部间接影响的综合影响矩阵H:

步骤4按式(3)计算H的行和fi与列和ei,即因素ai的影响度与被影响度:

进而得到中心度fi+ei(表征相对重要程度)和原因度fi-ei(区分因素的因果关系性质),进行系统分析。
2.2 二元语义表示模型
由于现实世界存在诸多模糊和不确定因素,在系统分析和决策过程中定性描述的语言评价信息往往比使用数值评价信息更为直接和便利。语言评价中的语言术语集(linguistic term set,LTS)是有一定语义的语言术语集合[20],记为S={s0,s1,…,sδ},粒度δ+1为正整数,是集合中的术语个数,取值不能太大或太小。语言术语si满足有序性(si≥sj当且仅当i≥j),且存在逆算子:neg(si)=sδ-i。
Herrea等[21]提出二元语义表达模型来进行模糊语言偏好的表示和处理,运用一组二元变量(s,α)表达语言信息,其中s是语言术语变量,α是代表语义转换的象征性数值。具体定义如下:
定义1[21]设S={s0,s1,…,sδ}是LTS,β是S中的元素符号集结运算的结果,且β∈[0,δ],设i=round(β)和α=β-i,则α∈[-0.5,0.5),则称α为si的符号平移。
其中round是取整函数,符号平移α是位于[-0.5,0.5)之间的数,表示S中的元素集成运算后得到的β与语言术语集S中最贴近元素si之间的差别。与β相对应的二元语义可以由以下函数得到:

定理1[21]设S={s0,s1,…,sδ}是LTS,且 (si,α)是一个二元语义,则存在逆函数Δ-1将二元语义转换成相应数值β∈[0,δ],即:
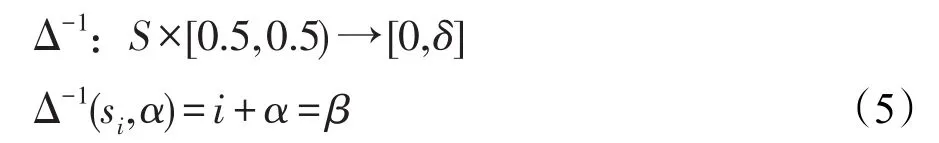
根据定理1,任何一个数值β∈[0,δ]都可以用相应的一个二元语义(si,α)来表示;任何二元语义(si,α)都可以用与之等价的一个数值β来表示,二者之间存在一一映射的关系。S中的任何语言术语变量si都可以表示为一个二元语义,只需要增加0作为符号平移即可,即si∈S⇒(si,0)。
2.3 语言层级模型
在群组决策中,因专家知识背景不同可能产生对语言评价标度的不同偏好,表现为不同专家选择LTS粒度δ+1的差异。为了对多粒度语言评价集进行建模,Herrea等提出了语言层级[13](linguistic hierarchies,LH)模型,并在群组决策领域得到广泛应用。语言层级的定义如下:
定义2[13]一个语言层级LH是所有层级t的并集,即LH=∪tl(t,n(t)),t=1,2,…,m,其中t表示LTS所在层级,n(t)表示在第t层的LTS的粒度,则l(t,n(t))是位于第t层,粒度为n(t)的LTS,记为。
Herrea等在构建语言层级LH时,要求符合两条基本规则[18],且较高一个级别的语言层级t+1可以通过式(5)得到:
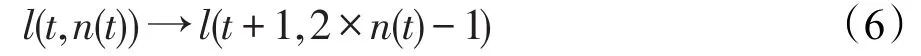
随着层级t的增加,LTS的粒度增大,则基于该层级的语言评价趋于精细化。
然而,在语言层级LH的模型中,LTS的选择具有局限性。例如对粒度分别为3、5、7的3组LTS构成的评价框架,t=2,n(t)=n(2)=5,则t+1=3时,n(t+1)=2×n(t)-1=n(3)=9,而不是n(t+1)=n(3)=7,建模的灵活性受到限制,具体表现为需要预先建立LH,并指定不同层级的若干LTS让群组专家进行选择。

定义3[19]{Sn(1),Sn(2),…,Sn(m)}为LTS的集合,其中LTS的粒度为奇数,则新增层级t*=m+1的LTSl(t∗,n(t∗))最小粒度为:
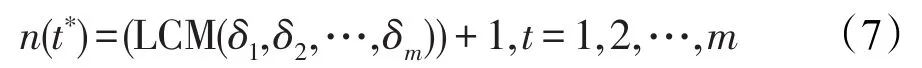
其中,LCM为最小公倍数,且δt=n(t)-1。
3 多粒度评价标度群组DEMATEL决策方法
3.1 问题描述
为了便于分析,首先给出多粒度评价标度下群组DEMATEL决策问题的描述。
系统A记为A={ai|i=1,2,…,n,n∈N,n>2},采用DEMATEL方法分析系统A中n个因素间的相互影响关系,直接影响矩阵为R=[rij]n×n。群组专家E={ek|k=1,2,…,K}分别对直接影响关系rij的强度进行判断及赋值。
因专家知识背景和对系统问题认知差异,采用多粒度评价标度给出评价信息,即评价标度粒度不同。记专家ek使用的语言评价标度为,其中表示的粒度,专家ek基于给出因素间影响关系强度的判断。需要注意的是,根据拓展语言层级模型的构建要求,的粒度为奇数。
在群组DEMATEL方法中,一个必要的环节是将个体专家意见集成为群组统一的意见,进而分析系统因果关系。因此,这里需要解决的问题是,如何基于多粒度评价标度下的评价信息,得到群组专家的集成意见。
3.2 多粒度评价信息的归一化和集成
多粒度评价标度信息的归一化环节,需要对使用不同粒度LTS所表达的信息进行归一,即构建不同语言层次间的转换功能[18]。按照二元语义拓展语言层级模型的构建规则,需要对群组中K个专家选择的m(m≤K)个不同的LTS,按照粒度递增顺序构造语言层级LH=∪tl(t,n(t)),t=1,2,…,m,并按定义3新增层级t∗=m+1层l(t*,n(t*)),构造扩展语言层级ELH=∪tl(t,n(t)),其中位于t层、粒度为n(t)的LTS记为。
为了应用ELH进行多粒度评价标度信息的归一化,先要将群组专家的偏好判断信息转换为二元语义表达,构建二元语义直接影响矩阵,定义如下:
定义4令系统A={ai|i=1,2,…,n,n∈N,n>2},根据群组专家评价标度构建的扩展语言层级为ELH=∪tl(t,n(t)),δt=n(t)-1,为定义在ELH上l(t,n(t))的二元语义,则对任意i,j∈n,当直接影响关系rij以二元语义表示时,称为系统A的二元语义直接影响矩阵。
进而,运用语言层级模型中的转换函数进行多粒度评价标度信息的归一化处理。具体定义如下:
定义5[18]令LH=∪tl(t,n(t)),且其中的LTS为,语言术语的表达方式为二元语义。从层级t的语言术语向层级t′的语言术语无损转换的转换函数定义为:
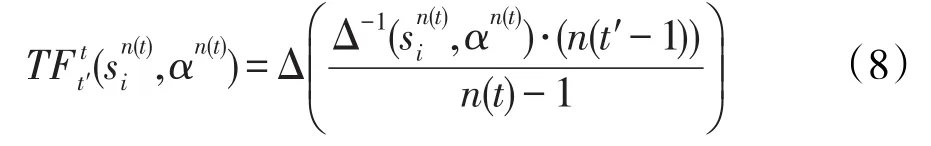
在拓展语言层级模型中,为了避免不同层级间转换过程的信息损失,将新增的t*=m+1层作为桥梁层级,先通过转换函数将信息统一到t*层,进而构建任意两个层级t和t′之间无损转换的转换函数,定义如下:
定义6[18]设t和t′是ELH上的任意两个层级语言,t*为ELH的m+1层,l(tm+1,n(tm+1)),则拓展转换函数定义为:

为了得到代表群组专家共识信息的群组直接影响矩阵,需要对归一化的专家个体二元语义直接影响矩阵进行集成。这一过程可以通过二元语义平均算子完成,具体定义如下:
定义7[22]设 (s1,α1),(s2,α2),…,(sn,αn)为一组要集结的n个二元语义,则二元语义的平均算子ξ定义为:
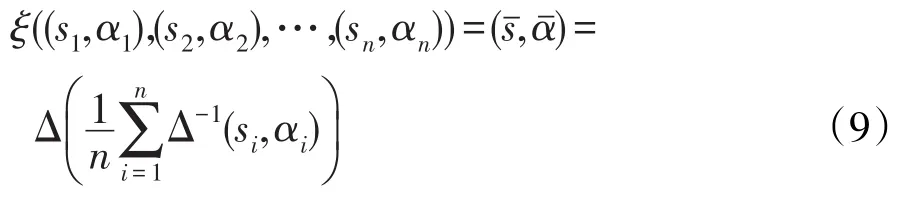
3.3 新方法步骤
为了分析多粒度评价标度下复杂社会经济问题,本节给出改进群组DEMATEL方法的思路和步骤。
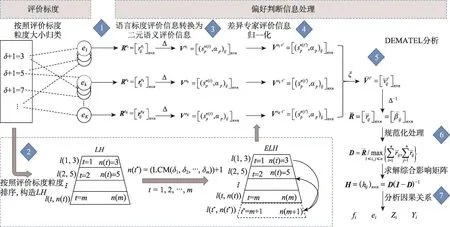
Fig.1 Flowchart of 2-tuple multi-granular group DEMATEL method图1 基于二元语义的差异评价标度群组DEMATEL方法流程图
如图1所示,对于群组专家多粒度评价标度下的直接影响关系偏好判断信息,首先分析专家选用的语言评价标度粒度,按递增顺序构建ELH;再以二元语义表达直接影响关系,指定目标标度t′,通过转换函数对评价信息进行归一,得到l(t′,n(t′))下的二元语义直接影响矩阵;然后运用二元语义平均算子,集成个体意见得到群组二元语义直接影响矩阵,并通过符号平移的逆运算转换为由β表示的数值信息,构造可运算的群组直接影响矩阵;在此基础上,按传统DEMATEL方法的步骤进行系统分析。具体步骤如下:
步骤1评价直接影响关系:个体专家ek(k=1,2,…,K)基于自身偏好选择语言评价标度,对系统A={ai|i=1,2,…,n,n∈N,n>2},独立给出因素间两两比较直接影响关系的语言评价意见,其中。
步骤2构建拓展语言层级:构建ELH,根据专家给出的语言评价标度(k=1,2,…,K),将按粒度归为m个类别,以粒度递增的顺序排列,并新增t*=m+1层,得到ELH=∪tl(t,n(t)),t=1,2,…,m+1。
步骤3差异专家评价信息转换为二元语义:将个体专家ek的,按照ELH中不同层级的语言评价术语,转换为二元语义,得到专家ek的二元语义直接影响关系矩阵。
步骤4差异专家评价信息归一化:在ELH中指定目标层级t′,用拓展转换函数,计算专家ek的归一化二元语义直接影响关系矩阵。
步骤5群组专家评价信息集成:根据定义6的二元语义平均算子,集成专家个体意见Vek∙t′(k=1,2,…,K),从而得到群组二元语义直接影响矩阵。再以二元语义逆算子Δ-1,计算得到以表示的群组直接影响矩阵。
步骤6求解综合影响矩阵:按式(1)对群组初始直接影响矩阵进行规范化处理,再按式(2)构造综合影响矩阵H。
步骤7分析影响因素:计算因素的影响度、被影响度、中心度和原因度,并提出相应管理建议。
4 案例应用
本章以中国汽车零部件再制造内部障碍分析的算例(改编自文献[23]),说明改进方法的可行性和有效性。
4.1 应用背景
随着我国汽车工业的发展和工业清洁生产战略的实施,汽车零部件再制造行业以其较高的财务收益、社会和环境回报,以及增加就业、降低成本、保护稀缺资源的优势,逐步引起广泛的关注。为了更好地发展汽车零部件再制造行业,有必要对行业发展的内部障碍及其因果关系进行分析,抓住关键因素,促进行业发展。根据文献研究和企业调研,得到我国汽车零部件再制造行业的内部障碍因素有15项,系统因素可以记为A={a1,a2,…,a15},如表1所示。因系统因素之间不独立且存在相互影响关系,用改进群组DEMATEL方法分析因素间的因果关系,进而提出管理建议。

Table 1 List of internal barriers for automotive parts remanufacturers in China表1 我国汽车零部件再制造行业内部障碍因素列表
4.2 计算过程
按照本文提出的多粒度评价标度改进群组DEMATEL方法计算如下:
步骤1评价直接影响关系:来自不同专业领域的8个专家,记为E={e1,e2,…,e8},分别基于自身偏好,选择合适的评价标度对因素间影响关系作出独立的判断,专家选用的语言评价标度如表2所示。限于篇幅,这里仅列出专家e5给出的因素间影响关系的强度判断,如表3所示。

Table 2 Multi-granular LTS of group experts表2 群组专家选用的多粒度语言评价标度
步骤2构建拓展语言层级:根据专家选用的LTS粒度,可分为4类,则m=4。按粒度递增的顺序构建排列,并新增t*=m+1层,其中:n(t*)=LCM(δ1,δ2,δ3,δ4)+1=LCM(2,4,6,8)+1=24+1=25构建ELH=∪tl(t,n(t)),t=1,2,…,m+1,如表4所示。

Table 3 Evaluation of direct influence of expert e5表3 专家e5给出的因素间直接影响关系判断

Table 4 Extended hierarchical linguistic model表4 拓展语言层级
步骤3专家评价信息转换为二元语义:以专家e5为例,因,则e5给出的语言评价信息在ELH中层次为t=3,语言评价术语为l(3,7),转换为二元语义,可得二元语义直接影响关系矩阵,如表5所示。

Table 5 2-tuple direct influence matrixVe5 of experte5表5 专家e的二元语义直接影响关系矩阵Ve5?
步骤4差异专家评价信息归一化:指定t′=4作为语言评价标度的目标层,应用拓展转换函数进行归一化计算,以专家e5,t=3为例:


步骤5群组专家评价信息集成:根据定义7的二元语义平均算子,集成专家个体意见Rek∙4,k=1,2,…,K,从而得到群组二元语义直接影响关系矩阵,见表7。通过二元语义逆算子,得到以表示的群组直接影响矩阵,见表8。
步骤6求解综合影响矩阵:按式(2)对初始直接影响矩阵进行规范化处理,得到规范化直接影响矩阵X,见表9。按式(3)计算综合影响矩阵H,见表10。
步骤7分析影响因素:基于综合影响矩阵H,计算系统各因素的影响度、被影响度、中心度和原因度,见表11,并对系统因素进行分析。系统因素分析图如图2所示。
从上述图表可以看出,15个因素按照原因度可以分为原因组和结果组两个类别。原因组的因素包括:a1、a3、a14、a7、a2、a8、a4,其中a1缺少研发资金;a3行业利润低是我国汽车零部件再制造行业的内部障碍主要的原因因素,这与行业发展阶段有密切关系;a14可循环使用的引擎数量不足;a2扩大生产规模资金不足也是影响汽车零部件再制造行业发展的重要因素。结果组的因素包括:a15、a9、a6、a5、a12、a13、a10、a11,这些因素对汽车零部件再制造行业发展的影响较小。按照中心度对系统因素进行排序的结果是:a9>a3>a8>a1>a6>a7>a14>a15>a2>a10>a5>a4>a12>a11>a13。其中,因素a9的中心度最高,表示先进的再制造技术能提高废旧引擎的利用效率,降低产品成本,提高再制造引擎的质量,从而提高再制造零部件的竞争力。相比较而言,a13再制造产品生产计划与其他因素的关联度较低。
Table 7 2-tuple direct influence matrix 4 of expert group表7 二元语义群组直接影响矩阵4
因素a1a2a3a4a12a13a14a15a1(s9 0,0)(s9 1,0.083)(s9 5,-0.292)(s9 3,0.166)(s9 1,0.333)(s9 0,0.250)(s9 3,-0.334)(s9 5,-0.417)a2(s9 5,-0.334)(s9 0,0)(s9 6,0)(s9 4,-0.417)(s9 3,0.166)(s9 4,0)(s9 5,-0.167)(s9 4,0.250)a3a4⋮(s9 5,0.083)(s9 6,-0.125)(s9 0,0)(s9 3,-0.209)(s9 3,-0.209)(s9 3,0.166)(s9 5,0.208)(s9 5,0.333)(s9 4,-0.417)(s9 6,0)(s9 1,0.083)(s9 0,0)(s9 0,0.125)(s9 3,-0.084)(s7 7,0.291)(s9 2,-0.500)⋮⋮⋮⋮⋮⋮⋮⋮a12a13a14a15(s9 1,-0.417)(s9 1,0.083)(s9 1,0.333)(s9 0,0)(s9 0,0)(s9 4,-0.250)(s9 0,0)(s9 3,-0.334)(s9 0,0.250)(s9 1,0.083)(s9 1,0.333)(s9 2,-0.167)(s9 1,0.333)(s9 0,0)(s9 4,-0.292)(s9 0,0.416)(s9 1,0.333)(s9 4,-0.167)(s9 8,-0.500)(s9 5,-0.042)(s9 3,0.416)(s9 5,-0.167)(s9 0,0)(s9 5,-0.500)(s9 1,0.333)(s9 1,-0.167)(s9 5,0.167)(s9 1,0.083)…………… …………(s9 4,0)(s9 1,0.083)(s9 4,-0.417)(s9 0,0)
Table 8 Direct influence matrix of expert group表8 群组直接影响矩阵
因素a2a3a4a5a6a7a8a9a10a11a12a13a14a15a1a10a2a3a4a5a6a7a8a9a10a11a12a13a14a15 4.667 5.083 3.583 2.917 4.292 3.750 4.583 3.708 1.333 0 0.583 0.250 1.333 1.333 1.083 0 5.875 6.000 1.333 2.667 2.792 0.250 6.625 0.125 0 1.083 1.083 3.833 0.833 4.708 6.000 0 1.083 1.208 1.333 3.875 6.917 4.458 1.333 0 1.333 1.333 7.500 4.833 4.583 4.250 5.333 1.500 1.333 1.333 4.000 4.000 4.000 4.000 0 2.667 0.417 4.500 0 3.167 3.583 2.792 0 6.000 0.583 3.167 0.583 2.792 0 0 0 7.542 1.083 4.458 0.583 2.667 4.500 4.833 7.042 4.583 0 0.250 4.917 0.250 3.167 0.417 0 3.750 4.833 7.333 5.208 1.208 1.333 3.167 2.792 0.125 1.083 4.417 3.542 4.000 5.083 1.333 0 0 1.833 4.958 1.083 3.167 3.167 2.792 4.458 0 4.000 4.542 1.333 4.583 0.250 0 1.333 4.000 4.000 1.333 5.833 4.125 4.583 1.083 2.000 0 4.292 2.917 4.958 3.750 2.917 4.167 1.083 4.000 4.000 4.583 1.083 4.000 0.583 1.208 5.500 0 5.500 3.875 4.000 3.417 2.667 0 2.917 1.083 8.000 0.417 6.792 0 1.333 6.000 6.917 0 5.083 5.083 0.250 0.583 0 1.333 4.000 7.333 4.417 6.500 1.083 2.500 6.250 5.083 7.583 0 4.125 4.583 2.917 1.208 4.000 5.083 0 0 4.250 4.000 0 0 0 0 4.000 1.333 3.417 4.000 0.250 4.000 3.167 2.917 3.875 2.792 0 1.333 4.583 0.250 0 3.750 0 4.833 1.083 2.667 4.833 5.208 7.292 1.333 0 2.167 2.667 3.583 0 0.833 0 3.708 0 3.583

Table 9 Normalized direct influence matrix X of expert group表9 群组规范化直接影响矩阵X
4.3 方法对比分析
将本文改进方法和文献[23]的方法进行对比分析(表12),可以看出:文献[23]只有单一评价标度,本文方法中专家可以根据自身偏好选用不同粒度评价标度,偏好信息表达更加灵活;文献[23]运用灰数描述专家语言的评价信息,新方法引入二元语义表达专家偏好信息,比灰数表达方式更容易理解,且可以通过拓展语言层级模型实现群组专家信息的归一和集成;文献[23]为群组专家赋予不同的灰数权重,新方法假设群组专家具有相同权重。本文新方法的案例运算过程清晰,说明方法具有合理性和可行性;从运算结果来看,两种方法得到的中心度排序、原因组和结果组的划分一致,验证了本章所提改进群组DEMATEL方法的有效性。
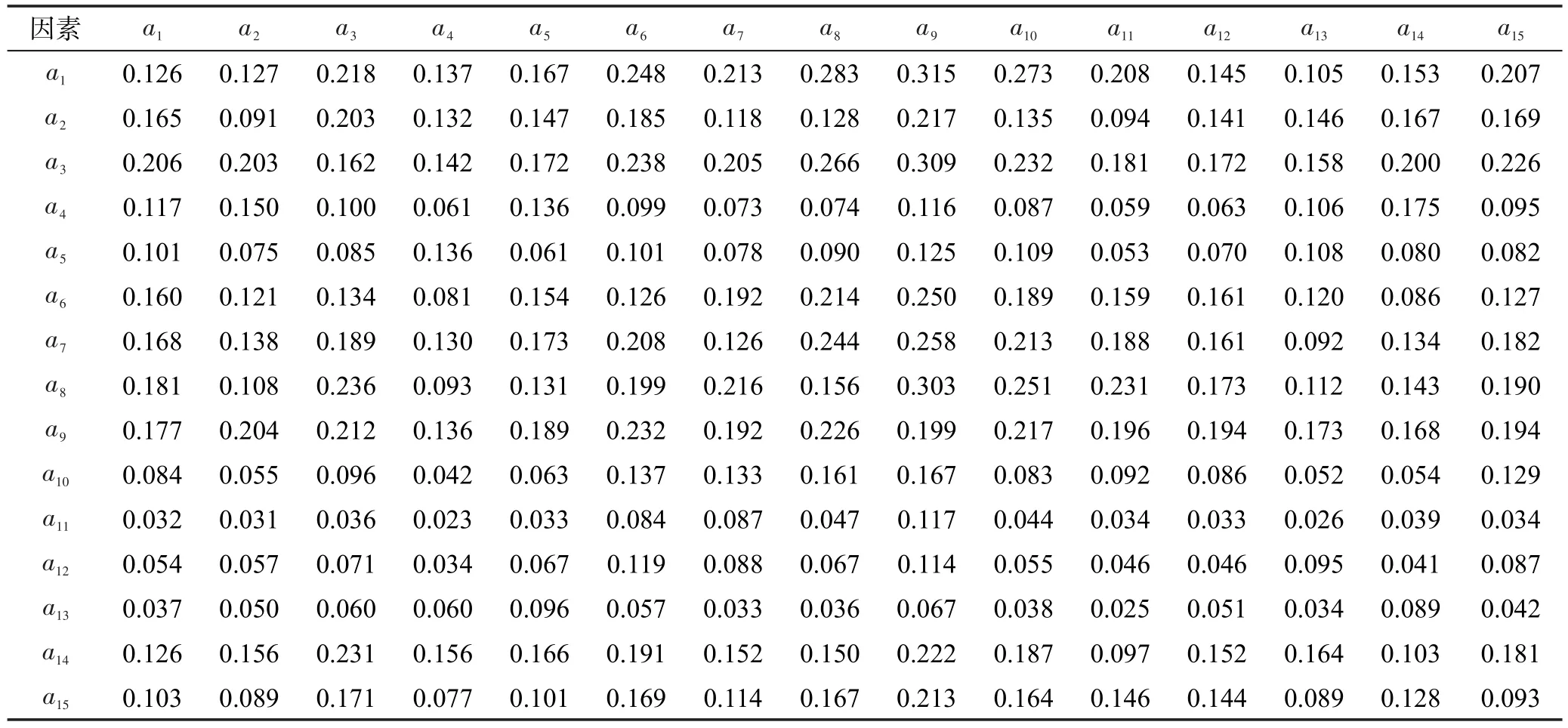
Table 10 Total influence matrix H of expert group表10 综合影响矩阵H

Table 11 Analysis of causal relationships表11 系统因素分析表

Table 12 Comparison of different DEMATEL methods表12 DEMATEL方法对比分析

Fig.2 Analysis of causal relationships图2 系统因素分析图
针对多粒度评价标度的群组DEMATEL问题,新方法之所以有效,是因为基于二元语义的拓展语言层级模型可以将多粒度评价标度信息进行无损的归一转换,从而适用于传统DEMATEL方法的信息输入。Espinilla等[19]已论证了拓展语言层级模型在不同层级的评价信息间实现无损映射的内在机理,并指出其具有精确性、包容性、灵活性的特征。在本文案例计算中,当目标层级变为t′=1,2,3,5时,可分别得到粒度为n(t′)=3,5,7,25语言评价标度下的二元语义群组直接影响矩阵,计算后的规范化影响矩阵完全一致。其内在原因是,直接影响矩阵的规范化处理是将原有评价信息规范到[0,1]区间,而不改变原有数据信息之间的相对大小关系,因此不会影响系统分析结果。
5 结束语
本文研究了多粒度评价标度下群组DEMATEL问题的改进方法。首先,针对群组专家差异性产生的多粒度评价信息,用二元语义表达语言评价信息,并通过拓展语言层级构建不同粒度语言评价信息之间的一一映射的无损转换关系,在此基础上,实现了多粒度评价标度信息的归一化和集成运算,得到以数值表示的直接影响矩阵,从而可以运用群组DEMATEL的方法进行系统因素分析。最后以案例说明了方法的可行性和有效性。
与现有的群组DEMATEL方法相比,本文提出的改进方法具有以下优点:
(1)在群组专家偏好信息表达方面,现有关于DEMATEL的文献中主要采用实数、模糊数、灰数描述专家给出评价信息,本文使用的二元语义表示模型作为一种模糊语言计算的方法,能更好地刻画专家的偏好信息,减少语言信息向数值信息转换过程中的信息损耗。
(2)与传统语言层级模型相比,拓展语言层级模型在构建过程中灵活度增加,无需预先指定专家可用的评价标度集,而是由专家自身选定合适粒度的评价标度,在建模时通过新增t*=m+1层和拓展转换函数,实现了不同粒度语言评价标度之间的信息无损一一映射关系,从而使多粒度评价标度信息的归一过程更为简洁清晰。
本文提出的改进方法不足之处在于,在群组专家信息的集成过程中,未考虑专家的权重差异,未来研究可从差异专家的知识背景、偏好信息精确度、决策情境等方面出发确定专家权重,提高群组专家信息集成的科学性和合理性。
