使用社区结构信息的子图匹配算法优化方法*
2019-01-17楼昀恺王朝坤
楼昀恺,王朝坤
清华大学 软件学院,北京 100084
1 引言
随着图在社交网络等领域的广泛应用,如何在图上高效地实现介数中心度查询[1]、连通分量查询[2]等常用查询成为学术界和工业界的研究热点。其中子图匹配作为图上的一种基础而重要的查询方式,以其方便、直观的特点成为一个备受关注的研究问题。子图匹配问题的定义[3]如下:给定网络图G=(V,E)和模式图P=(Vp,Ep),找到G中所有与P同构[4]的子图。通过子图匹配的查询方式,用户可以直观地从图中获取想要的信息。
目前常见的子图匹配算法,如VF2[5]、R-Join[6]等,存在如下不足:一方面,这些子图匹配算法的运行效率依然不高;另一方面,虽然研究者提出了不少针对特定子图匹配算法的改进策略,但很少有对多种子图匹配算法均通用且有效的优化方法。本文尝试解决这两方面的不足。
作为图的一种重要属性,社区结构反映了图中结点间联系的紧密程度[7]。同一社区内结点间联系比较紧密,而不同社区的结点间的联系则比较松散。自社区的概念被提出以来[7],涌现出各种各样的社区发现算法[7-17],并已广泛应用于蛋白质功能预测[18]、商品推荐[19]、反恐[20]等诸多方面。本文尝试基于社区结构对子图匹配过程进行优化,其基本想法在于社区结构本质上将结点按照边的密集程度进行了划分,通过利用两端点属于不同社区的边的数量较少的特点,能够对子图匹配算法进行高效剪枝,进而加快子图匹配的速度。
同时,模式图中包含了大量的信息,而这部分信息在现有的子图匹配算法中很少被用到。例如以四完全图作为模式图P在网络图G上进行子图匹配时,根据四完全图的性质,每当在G中得到P的1个匹配结果(包括G中的4个结点)时,通过交换这4个结点即可直接得到另外的23种正确匹配结果,在后续匹配过程中不必再进行相应计算,减少了匹配过程中的计算量。据此,考虑通过分析模式图的结构特征来减少子图匹配的计算量,从而降低时间开销,优化匹配过程。
结合上述两种优化策略,本文提出一种基于社区结构的子图匹配算法优化方法,对子图匹配算法进行上述两方面的优化。
本文的主要贡献包括:
(1)提出了子图匹配中全等点、对称点和匹配等价的概念。在子图匹配算法中通过分析模式图的结构,从中找出全等点对和对称点对,计算得到匹配等价的模式图子图,并基于此减少子图匹配过程的计算量,加快匹配速度。
(2)提出了一种基于社区结构的子图匹配算法优化方法(community structure based subgraph matching optimization method,CSO),结合模式图信息和社区信息对子图匹配算法进行加速。CSO方法将子图匹配流程划分为社区内子图匹配和社区间子图匹配两个过程。对于社区内子图匹配,通过并行化减少时间开销;对于社区间子图匹配,依据模式图分析的结果减少计算量,并在匹配的过程中结合不同社区的结点间的边数信息进行剪枝,达到加速匹配的目的。
(3)以VF2[5]算法为例,使用CSO方法对它进行优化得到AVF2(advanced_VF2)算法。在真实数据集和合成数据集上对AVF2算法与VF2算法的效率进行了比较,并进行了可扩展性实验和参数敏感性分析。实验结果表明,CSO方法能有效加快子图匹配算法的速度,同时具有较好的可扩展性。
本文其余部分组织如下:第2章介绍子图匹配和社区发现领域的相关工作;第3章给出若干基本概念;第4章提出全等点对、对称点对的查找算法以及模式图中匹配等价的子图的查找算法,并进行理论分析;第5章提出CSO方法并给出示例;第6章给出并分析实验结果;第7章总结全文。
2 相关工作
2.1 子图匹配算法
子图匹配是图上常见且实用的一种查询,它的优点在于用户可以通过构造模式图的方式方便地在图上进行查询。子图匹配问题是NP完全问题[5],因此如何在实际的图数据库中高效地进行子图匹配已经成为一个重要问题。
现有的子图匹配算法可以按是否使用索引进行分类。子图匹配的经典算法,如Ullmann[21]和VF2[5]算法,不使用索引结构。Ullmann算法借助矩阵变换的思想进行子图匹配,最优情况下时间复杂度为Θ(N3),最差情况下时间复杂度为Θ(N!N2);VF2算法通过在深度优先的搜索过程中进行高效剪枝方法实现子图匹配,最优情况下时间复杂度为Θ(N2),最差情况下时间复杂度为Θ(N!N)。这类不基于索引的方法的时间复杂度是超线性的,因此在较大规模的数据集上的时间开销很大。
与上述方法相比,基于索引的方法能减少子图匹配的时间开销,其中常见的几种方法包括R-Join算法[6]、GraphQL[22]算法、基于 SPath 索引的方法[23]、TurboISO算法[24]等。R-Join算法[6]构造了基于聚合的R-Join索引;GraphQL[22]对图中每个结点,为到它距离小于等于r的结点构成的子图建立索引;Zhao等[23]提出了SPath索引的概念,对每个结点v,将和v之间距离小于等于给定值k的结点的标签编码为一个签名,随后对v与它的签名间建立索引。在网络图上构造索引的方法存在索引占用空间较大的问题,并且对数据量较大的图而言,构造索引也有较大的时间开销。TurboISO[24]算法解析模式图中具有等价关系的结点生成邻域等价类树(NECtree),使用树中信息指导匹配过程中的剪枝。Bi等[25]通过推迟笛卡尔积的计算和引入紧凑路径索引的数据结构的方式优化TurboISO[24]算法。TurboISO算法对模式图进行了解析,但解析仍不完全,且未充分利用得到的信息,仍有较大的提升空间。
2.2 社区发现
社区结构是复杂网络的重要属性之一,受到学术界和工业界广泛关注。社区结构是由网络中联系紧密的若干结点构成的。社区内的结点满足与本社区中其他结点联系紧密,与其他社区的结点联系松散的特点。
社区的概念最早是由Girvan和Newman[7]提出的,他们认为社区结构与小世界属性、幂律分布和传递性一样,也是网络图的重要属性。自此之后,出现了多种社区发现算法,包括基于最优化模块度的方法、基于标签传播的算法、矩阵分块方法[8]、图嵌入方法[9]等。
基于最优化模块度的方法是一种常见的社区发现方法。Newman和Girvan[10]在2003年首先提出使用模块度(modularity)来评估网络中的社区结构。Newman[11]在2004年提出了在G-N算法[7]基础上以最优化模块度为目标进行社区发现的贪心算法。同年,Clauset和Newman[12]再次对此方法进行改进,提出了CNM方法,进一步提升了社区发现的效率。Blondel等[13]于2008年提出的Louvain算法是一种层次化的贪心的基于最优化模块度的算法,它通过社区间的合并自下而上地进行社区发现,将时间复杂度减小为O(nlbn)。
另一种常见的策略是通过标签传递方法进行社区发现。Raghavan等[14]于2007年提出使用标签传递算法LPA(label propagation algorithm)来进行社区发现。该算法首先给每个结点设置不同的标签,随后在异步更新的每步中将当前结点的邻居结点中出现次数最多的标签设置为当前结点的标签,通过多次迭代进行标签的传递,最终将有相同标签的结点划分进相同社区中。2008年Leung等[15]在LPA的基础上增加了标签跳变衰减和结点的标签偏好的概念,提出了新的社区发现算法HANP(hop attenuation and node preference)。
目前社区发现仍是一个重要的研究问题,近几年来出现了许多重要的研究成果。例如,Wang等[16]提出了一种社区发现方法的通用框架来对社区发现方法进行深入分析与准确评估;为了高效处理大规模的网络数据,乔少杰等[17]提出了基于Spark的并行的社区发现算法DBCS(discovering big community on Spark);Fortunato等[26]对图上的社区发现方法进行了分类和总结。
3 基本概念
给定一个复杂网络图G=(V,E,C),V是结点集合,E是边集合,C是G上的社区列表,有C={c1,c2,…,ck},其中,ci是G上的社区i中包含的所有结点构成的结点集合在G上对应的导出子图。G上的社区信息可以由数据集本身提供,也可以在G上使用社区发现算法(例如LPA)计算得到。与网络图类似,用户给定的模式图用P=(Vp,Ep)表示,Vp是P中的结点集合,Ep是P中的边集合。子图匹配的过程即是在G中找到所有与P同构的G的子图。
下文中提到的社区,如不作特殊说明指的是社区中所有结点在图上对应的导出子图。
定义1(对称点)给定模式图P=(Vp,Ep),vi,vj∈Vp,若vi与vj的拓扑结构对称,则称vi与vj互为对称点。结点vi与vj拓扑结构对称的定义是:若图上存在一个非平凡自同构,该自同构对应的双射g满足g(vi)=vj,g(vj)=vi,则称结点vi与vj拓扑结构对称。
定义2(对称子图)给定模式图P=(Vp,Ep),令Psub1=(Vp1,Ep1)和Psub2=(Vp2,Ep2)为P的两个子图,对于这两个子图,若存在表示对称关系的双射f:Vp1→Vp2(简称为对称双射),对于其中的每个映射f(u)=v,均满足结点u与v互为对称点,则称Psub1和Psub2互为对称子图。称上述双射f为Psub1关于Psub2的对称双射。
显然,若有Psub1关于Psub2的对称双射f,定义双射g,满足对于f的每个映射f(u)=v,相应地有g(v)=u,则g为Psub2关于Psub1的对称双射。

为了便于叙述,用h({v1,v2,…,vk})表示对结点集合{v1,v2,…,vk}中各结点应用映射h后得到的结果构成的新集合,即h({v1,v2,…,vk})={h(v1),h(v2),…,h(vk)}。
定义4(全等点)给定无向模式图P=(Vp,Ep),v1,v2∈Vp,用Neigh(v)表示结点v的邻居结点集合。称v1和v2互为全等点,若满足:(1)|Neigh(v1)|=|Neigh(v2)|;(2)Neigh(v1)-{v1,v2}=Neigh(v2)-{v1,v2}。对于有向模式图,用OutNeigh(v)表示结点v的出邻居结点集合,用InNeigh(v)表示v的入邻居结点集合,称v1和v2互为全等点,若满足:(1)|OutNeigh(v1)|=|OutNeigh(v2)|且OutNeigh(v1)-{v1,v2}=OutNeigh(v2)-{v1,v2};(2)|InNeigh(v1)|=|InNeigh(v2)|且InNeigh(v1)-{v1,v2}=InNeigh(v2)-{v1,v2} ;(3)v1∈OutNeigh(v2)且v2∈OutNeigh(v1),或v1和v2间不存在边。
显然,全等点关系是特殊的对称点关系。全等点关系具有传递性,所有互为全等点的结点组成的结点集合称为一个全等点组。
定义5(邻域范围)给定无向模式图P=(Vp,Ep),对于结点v∈Vp,其邻域范围N(v)={t|t=vort∈Neigh(v)}。对于有向模式图,分别定义出邻域范围Nout和入邻域范围Nin:Nout(v)={t|t=vort∈OutNeigh(v)},Nin(v)={t|t=vort∈InNeigh(v)}。
定义6(邻域范围规则)给定无向模式图P=(Vp,Ep),Psub1和Psub2是P的两个子图,且它们互为对称子图,令Psub1关于Psub2的对称双射为f,Psub1关于Psub2的扩展对称双射为h。对于Psub1和Psub2,邻域范围规则指的是下述两条规则:规则1,Psub1中的每个结点p的邻域N(p)与p在Psub2中的对称点q=f(p)的邻域N(q)满足h(N(p))=N(q);规则2,Psub1中的每个结点p与它在Psub2中的对称点q=f(p)互为全等点。若Psub1和Psub2满足上述两条规则中的至少一条,则称Psub1和Psub2满足邻域范围规则。对于有向模式图P=(Vp,Ep),关于互为对称子图的Psub1和Psub2的邻域范围规则为:规则1,Psub1中的每个结点p的出邻域Nout(p)、入邻域Nin(p)与p在Psub2中的对称点q=f(p)的出邻域Nout(q)、入邻域Nin(q)分别满足条件h(Nout(p))=Nout(q)与h(Nin(p))=Nin(q);规则2,Psub1中的每个结点p与它在Psub2中的对称点q=f(p)互为全等点。其中,f是Psub1关于Psub2的对称双射,h是Psub1关于Psub2的扩展对称双射。若Psub1和Psub2满足上述两条规则中的至少一条,则称Psub1和Psub2满足邻域范围规则。
定义7(匹配等价)给定无向或有向模式图P=(Vp,Ep),Psub1和Psub2是P的两个子图,且它们互为对称子图,记Psub1关于Psub2的对称双射为f,Psub1关于Psub2的扩展对称映射为h。若Psub1和Psub2满足邻域范围规则,且Psub1和Psub2同构,则称Psub1和Psub2匹配等价。
定义8(社区边界出/入结点)给定有向网络图G=(V,E,C),c1,c2∈C是G中两个不同的社区。对于c1中的某个结点vi,若vi到c2中某结点有一条出边,则称vi是c1关于c2的社区边界出结点。本文用commOutBoundary(c1,c2)表示c1所有关于社区c2的社区边界出结点构成的集合,集合内结点按照它到社区c2中结点的出边总数从小到大排序。社区边界入结点与出结点相似,区别在于不统计出边而统计入边。用commInBoundary(c1,c2)表示c1所有关于c2的边界入结点构成的集合。对于无向网络图可将每条无向边替换为对应的两条方向相反的有向边,得到社区边界结点集合。
定义9(社区边界出/入结点度数表)给定网络图G=(V,E,C),c1,c2∈C是G中的两个不同社区。用degreePosOut表示社区边界出结点度数表,用degreePosIn表示社区边界入结点度数表。其中,degreePosOut(c1,c2,d)表示c1与c2的边界出结点集合commOutBoundary(c1,c2)中第一个到c2中结点的出边总数大于或等于d的结点的在集合中的位置。社区边界入结点度数表与出结点度数表相似,不再赘述。对于无向网络图可将无向边替换为对应的两条方向相反的有向边后计算得到度数表。
4 模式图解析算法
模式图的解析主要分为三步,分别是全等点对的查找、对称点对的查找以及匹配等价的子图的查找。本章分别给出这三步的算法并进行相关理论分析。本章中给出的算法均是针对有向图的,对于无向图,可以将它转换成对应有向图后应用本章的算法进行计算。
4.1 全等点对查找算法
定义10(全等点对)给定模式图P=(Vp,Ep),vi,vj∈Vp,若vi和vj互为全等点,则称(vi,vj)为一个全等点对。
根据全等点的定义(定义4),给出算法1(见附录)来查找模式图P中所有的全等点对。
算法1查找P中所有的全等点对,并将结果存储在equalNodes中。由于每个结点与它自己互为全等点,算法第1、2行将P中每个结点与它自己组成的全等点对存入equalNodes中。随后根据全等点的定义对每个结点在除它自身外的结点集合中找全等点(第3~8行)构成全等点对。算法为每个全等点组定义一个组号,存储在patternEqualClass中(第10~15行)。这些组号将被用于计算模式图中互相匹配等价的子图。
例1如图1(a)所示,结点v2和v3有相同的出边数和入边数,但OutNeigh(v2)={v4},OutNeigh(v3)={v5},因此OutNeigh(v2)-{v2,v3}≠OutNeigh(v3)-{v2,v3},故v2和v3不互为全等点,即(v2,v3)不是全等点对。如图1(b)所示,结点v1和v2有相同的出边数和入边数,OutNeigh(v1)={v2,v3},OutNeigh(v2)={v1,v3},满足OutNeigh(v1)-{v1,v2}=OutNeigh(v2)-{v1,v2}={v3},InNeigh(v1)-{v1,v2}=InNeigh(v2)-{v1,v2}={v3},且v1∈OutNeigh(v2),v2∈OutNeigh(v1),因此v1和v2互为全等点,(v1,v2)是全等点对。图1(b)经过算法1的处理后得到的返回值为equalNodes={(vi,vj)|1≤i,j≤ 3},patternEqualClass={v1:0;v2:0;v3:0;}。
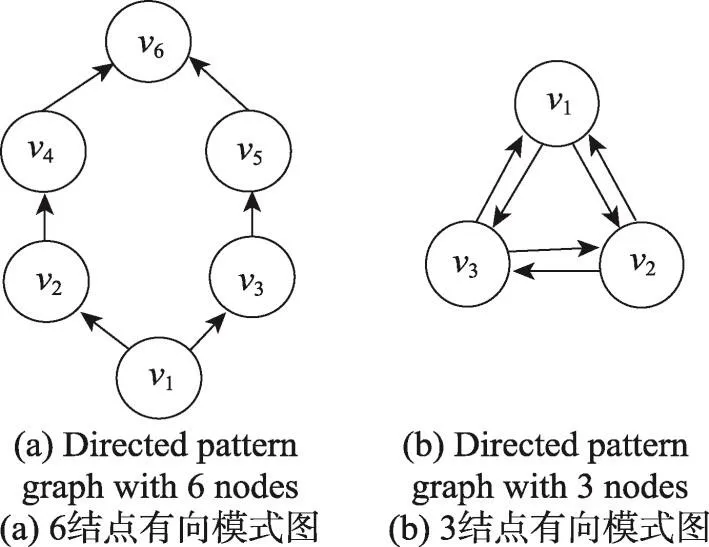
Fig.1 Two examples of patterns图1 两个模式图的例子
定理1算法1(getEqualNodes)返回的equalNodes中存储的是P中所有的全等点对。
鉴于篇幅所限,略去本定理及余下定理的证明过程。
定理2算法1(getEqualNodes)的时间复杂度为,Np是模式图P中的结点数。
4.2 对称点对查找算法
定义11(对称点对)给定模式图P=(Vp,Ep),vi,vj∈Vp,若vi和vj互为对称点,则称(vi,vj)为一个对称点对。
因为找到模式图中所有对称点对的时间复杂度是指数级的,所以本节给出的查找算法是一个贪心算法,它查找图中非全等点对的对称点对。算法2(见附录)和算法3(见附录)给出了在模式图中查找对称点对的具体方法。其中,算法2查找模式图中的对称点对,它调用算法3递归地计算对称点关系。
若要判断模式图中任意两个结点组成的点对(vi,vj)是否是非全等点对的对称点对,则其需要满足如下三个必要条件:(1)(vi,vj)不是全等点对(算法3第1、2行);(2)之前未判断过(vi,vj)是否是对称点对(算法3第3、4行);(3)vi的出度与vj的出度相等且vi的入度与vj的入度相等(算法3第5~7行)。如算法3所示,一旦这个点对不满足上述三个条件中的任意一个,则退出算法3,否则继续执行,将vi和vj加入到结点集合used中。其中,used中存储的是当前正在判断的若干点对中的结点。
验证得到vi和vj满足上述必要条件后,先对它们的出邻居进行判断。算法3第9行将vi的不在used中的出邻居结点存储在unusedNeighs1中,即unusedNeighs1中存储的是vi的出邻居结点中不在任何一个当前正被判断的点对中的结点。第10行将结点vj的不在used中的出邻居结点存储在unusedNeighs2中。
若得到的unusedNeighs1和unusedNeighs2均为空,则认为vi和vj的出邻居满足要求,可以直接判断它们的入邻居。否则使用递归的方法尝试找到IunusedNeighs1(unusedNeighs1在模式图中对应的导出子图)关于IunusedNeighs2(unusedNeighs2在模式图中对应的导出子图)的对称双射。若unusedNeighs1和unusedNeighs2中包含的结点个数不同,则不可能找到这样的对称双射,因此vi和vj不可能互为对称点,可以直接设置symm中对应值为False,并从used中删除vi和vj(第11~14行),表示完成了对点对(vi,vj)的判断。若unusedNeighs1和unusedNeighs2中包含的结点个数相同,则用枚举的方式尝试找到一个IunusedNeighs1关于IunusedNeighs2的对称双射(第15~25行)。若无法找到这样的对称双射,说明结点vi和vj不互为对称点,故(vi,vj)不是对称点对,在symm中记录此关系,将symm[vi][vj]和symm[vj][vi]设置为False(算法3第23~25行),并结束对vi和vj的判断;若在vi和vj的出邻居结点集合在模式图上的导出子图间构造出了满足要求的对称双射,则可以开始对结点入邻居进行判断。对结点入邻居的判断方法与出邻居类似(第26行)。若入邻居对应的unusedNeighs1和unusedNeighs2为空,或对于入邻居找到了IunusedNeighs1关于IunusedNeighs2的对称双射,则表明结点vi和vj互为对称点,即(vi,vj)是一个对称点对,设置symm[vi][vj]和symm[vj][vi]为True(算法3第27行)。完成判断后,将vi和vj从used中删去,表示完成了对于点对(vi,vj)是否是对称点对的判断(算法3第28行)。
最终,对于所有symm[vi][vj]为True的情况,将点对 (vi,vj)加入symmetryNodes(算法2第7~10行)。symmetryNodes中存储的点对即是算法2找到的所有对称点。
例2如图1(a)所示,判断结点v2和v3组成的点对(v2,v3)是否是对称点对。此时,由于正在对点对(v3,v4)进行判断,因此used中包含结点v2与v3。算法3中要求判断v2对应的unusedNeighs1(即{v4})在图1(a)上的导出子图I{v4}与v3对应的unusedNeighs2(即{v5})在图1(a)上的导出子图I{v5}间是否存在对称双射f。尝试建立v4与v5间的映射,即先判断点对(v4,v5)是否是一个对称点对。此时,得到v1对应的unusedNeighs1与v2对应的unusedNeighs2相同,都等于{v6}。因此,存在对称双射f6:{v6}→{v6},满足f(v6)=v6,故出邻居满足要求。开始对v4和v5的入邻居集合进行判断,此时入邻居集合对应的unusedNeighs1和unusedNeighs2均为空,因此,(v4,v5)是一个对称点对。故找到了I{v4}关于I{v5}的对称双射f:{v4}→{v5},满足f(v4)=v5。对于v2和v3的入邻居采用相同的方法也能找到对称双射。因此,(v2,v3)也是对称点对。
定理3给定模式图P=(Vp,Ep),算法2找到的所有对称点对均是P中非全等点对的对称点对。
由定理3容易证明本节给出的对称点对查找算法(算法2)的正确性。
定理4算法2的时间复杂度为,Np为输入中模式图P中的结点数。
4.3 匹配等价的子图的查找算法
本节给出在模式图P=(Vp,Ep)中查找匹配等价的子图的方法(算法4,见附录)。由于查找对称点对的算法(算法2)是一个贪心算法,因此所要查找的与P的一个子图Psub匹配等价的所有P的子图,是指在算法2找到的所有对称点对的基础下能找到的与Psub匹配等价的P的子图,可能不完全包含所有满足此条件的子图。
具体来说,本方法调用算法5(见附录)遍历P中结点所有可能的组合方式,对每种组合方式在P中生成对应的导出子图,并找到与每个导出子图同构的其他子图。同时,算法6(见附录)对每个导出子图寻找与它满足邻域范围规则的子图。最终,算法4根据得到的同构的子图和满足邻域范围规则的子图找到模式图中所有匹配等价的子图。
算法4首先通过调用算法5遍历P中结点的所有组合方式(算法4第2行),对于每种组合方式生成P上对应的导出子图,寻找互相同构的导出子图并将同构关系存储在isomap中,同时找到互相满足邻域范围规则的子图,在matchEq中对每个子图存储所有与它满足邻域范围规则的子图。随后通过isomap中存储的子图同构关系信息,对matchEq中的每个子图判断与它满足邻域范围规则的子图是否与它同构,将不与它同构的子图删除(第3~7行)。对每个子图处理完毕后,matchEq中存储的即为与P的各子图匹配等价的所有P的子图。
算法5可以分为两部分:(1)遍历P中结点的组合方式,生成对应导出子图,并找到与每个导出子图匹配等价的P的子图;(2)对于每个导出子图,找到与它同构的模式图子图。
关于第1部分,使用current存储模式图结点当前的组合方式,算法第24行向current添加新结点vpos获得一种新的组合方式。第25行递归调用算法5自身继续寻找新的结点组合方式,第26行将新加的结点删除,进行回退。对于每种结点组合方式current,生成其对应的导出子图Icurrent(算法第2行),第6行调用算法6找到与Icurrent满足邻域范围规则的所有子图,并存储在matchEq[Icurrent]中。
对应第2部分,算法5第7~20行判断Icurrent是否与之前遍历到的某个子图同构。对于模式图P,定义它的子图Ic的特征字符串为Sc。特征字符串Sc的构造方法为在P中找与Ic同构的P的子图,对找到的每个子图,将子图中的结点ID升序排序,以空格为分隔符连接排序后的结点ID形成字符串,将各字符串分别按字典序排列后得到的最小的字符串即为Ic的特征字符串Sc。由同构的性质易知,P的两个子图同构当且仅当它们具有相同的特征字符串。matchedModel中存储的是元组(Si,Ii),其中,Si是所有处理过的子图的特征字符串,Ii是处理过程中特征字符串为Si的第一个子图。对于matchedModel中的每一个元组(Si,Ii),若Icurrent与Ii同构,则将Icurrent加入记录所有特征字符串为Si的子图的数组isomorphicList[Si]中(第12行),并在记录每个子图的特征字符串的字典isomap中添加对应项(第13行)。若matchedModel中的所有元组(Si,Ii)中的Ii均不与Icurrent同构,则得到的Icurrent的特征字符串Scurrent不与之前处理过的任何子图的相同,因此将(Scurrent,Icurrent)插入到matchedModel中(第18行),剩余操作与前面类似。处理完所有可能的子图后,isomap中记录了所有子图的特征字符串。
算法6查找所有与Icurrent满足邻域范围规则的模式图子图。同样可以将它分为两个阶段:(1)计算得到每个与Icurrent互为对称子图的子图It;(2)判断Icurrent与It是否满足邻域范围规则,将与Icurrent满足邻域范围规则的It存储到matchEq[Icurrent]中。第一阶段主要通过算法6第13~26行实现。算法第13~19行将current中的某结点替换为它的一个全等点,第20~26行将current中某结点替换为它的一个非全等点的对称点,通过对current中每个结点进行如上替换操作,并尝试每种替换方式,得到所有满足如下条件的结点集合t:t在P上的导出子图It与current在P上的导出子图Icurrent互为对称子图。而上述所有It即为Icurrent的所有对称子图。当满足算法第1行的条件时,说明得到了一个满足条件的结点集合t,使得It与Icurrent互为对称子图。
第二阶段对于每个满足条件的结点集合t进行处理。算法6第2行分别构造current和t在P上对应的导出子图Icurrent与It。第3行计算得到Icurrent关于It的扩展对称映射。第4行判断hasSymm的值,若为True,说明在由current构造出t的过程中使用了非全等点的对称点关系进行替换,因此Icurrent和It不满足邻域范围规则中的规则2,需要判断Icurrent和It是否满足邻域范围规则中的规则1(算法6第5行);否则,若hasSymm为False,则说明由current构造出t的过程中只用了全等点关系进行替换,因此Icurrent各结点与替换后It中对应的结点互为全等点,即Icurrent与It必满足邻域范围规则中规则2的要求,故Icurrent与It满足邻域范围规则。为了避免重复存储,对于使用了非全等点的对称点进行替换的情况,第6行判断Icurrent与It包含的结点是否相同:若不同,则只有当t中结点的ID升序排列时,才将It存入matchEq[Icurrent]中(第7、8行);若相同,可以直接将替换后的结果存储入matchEq中。对于只使用了全等点关系进行替换的情况,若t中属于相同全等点组的结点的ID均升序排列,则存储当前结果(第10、11行)。
上述算法得到P中与每个子图匹配等价的所有子图,并存储在matchEq中,用于后续算法中对社区间子图匹配过程进行加速。
例3以图1(a)所示的模式图为例说明上述过程。记此模式图为P=(Vp,Ep),其中Vp={v1,v2,v3,v4,v5,v6},则算法retrivalNodes依次得到结点组合方式{v6},{v5},{v5,v6},{v4},{v4,v6},{v4,v5},{v4,v5,v6},{v3},{v3,v6},{v3,v5},{v3,v5,v6},{v3,v4},{v3,v4,v6},…,{v2,v4},…,{v1,v2,v3,v4,v5,v6}。当处理由{v2,v4}对应的导出子图I{v2,v4}时,先调用函数getAllMatchNodes找与它互为对称子图的P的子图,并验证它们是否满足邻域范围规则。因为v2和v3互为对称点,v4和v5互为对称点,所以得到的与I{v2,v4}互为对称子图的P的子图包括I{v2,v4},I{v2,v5},I{v3,v4},I{v3,v5}。通过验证,得到I{v2,v4}和其中的I{v2,v4}满足邻域范围规则(规则2),I{v2,v4}和I{v3,v5}也满足邻域范围规则(规则1),因此存储结果得到matchEq[I{v2,v4}]={I{v2,v4},I{v3,v5}}。在这之后,还需要计算和存储同构信息。计算得到I{v2,v4}的特征字符串为“12”,因为I{v5,v6}的特征字符串也是“12”,并且它在I{v2,v4}之前被处理过了。因此,matchedModel中已经存在元组("12",I{v5,v6}),因此算法5中第11行能找到I{v2,v4}与I{v5,v6}同构,故只需将I{v2,v4}加入到isomorphicList["1 2"]中,并存储isomap[I{v2,v4}]="1 2"即可。完成所有子图的处理后,有isomorphicList["1 2"]={I{v1,v2},I{v1,v3},I{v2,v4},I{v3,v5},…}。当完成retrivalNodes函数的计算后,对所有满足邻域范围规则的子图进行同构的验证,如对于matchEq[I{v2,v4}],由于isomap[I{v2,v4}]=isomap[I{v3,v5}],因此不用删除元素,找到的与子图I{v2,v4}匹配等价的子图包括I{v2,v4}和I{v3,v5}。
定理5算法4所述匹配等价的子图的查找算法是正确的。
定理6匹配等价子图的查找算法(算法4)的时间复杂度为,其中Np为模式图P的子图个数,θ(Np)为子图匹配算法在结点数为Np时的时间复杂度,Nsub为由模式图P的子图能构成的最大的集合的大小,满足集合中各子图互不同构。
当模式图中结点较少时,定理6给出的算法4的时间复杂度近似等于Ο(θ(Np)),即约等于子图匹配算法的时间复杂度。
当模式图中结点较多时,可以通过只对模式图中部分子图找与它匹配等价的子图的方法减少这部分的时间开销。如只对结点数不超过Nd的子图找与它互相匹配等价的子图,则此时算法的时间复杂度为。例如当Nd=12时,算法的时间复杂度就降为Ο(212×(Nsub×θ(Np)+212×122))。
5 子图匹配算法优化方法
本章详细介绍基于社区结构的子图匹配算法优化方法CSO。为了便于描述,将CSO方法中涉及到的子图匹配算法记作Λ。在使用CSO方法对具体的子图匹配算法(如VF2[5]算法)进行优化时,只需将下述各算法中的Λ算法替换为该子图匹配算法即可。其中,在社区间子图匹配的算法说明中具体给出基于社区结构进行剪枝的方法。
5.1 CSO方法概述
CSO方法用于对子图匹配算法进行加速。它将子图匹配流程划分为社区内子图匹配和社区间子图匹配两个过程,在这两个过程中分别并行地进行子图匹配相关计算。CSO方法采用了模式图解析和基于社区结构的剪枝两种策略对子图匹配算法进行优化,以提升子图匹配算法的效率。下面先给出本节用到的几个概念,然后具体讲解CSO方法。
定义12(结点可重复的子图匹配)给定网络图G和模式图P,若子图匹配过程中允许P中不同结点与G中的相同结点相匹配,则称该子图匹配为结点可重复的子图匹配。
定义13(分配方案)给定网络图G=(V,E,C)和模式图P=(Vp,Ep),G中各社区构成的集合C={c1,c2,…,ck}。划分Vp得到由m个结点集合构成的集合w(w={vlist1,vlist2,…,vlistm},w中各结点集合间互不相交且vlist1∪vlist2∪…∪vlistm=Vp,m≤k)。称映射fs:C′→w为P关于C的一种分配方案,如果满足:(1)C′⊆C且|C′|=m;(2)fs是一个双射。
给定模式图P关于G中社区的一个分配方案fs,若有fs(ci)=vlistj,则称vlistj中各结点被分配到社区ci。
定义14(等价的分配方案)给定网络图G=(V,E,C)和模式图P=(Vp,Ep),G中各社区构成的集合C={c1,c2,…,ck}。令fs1:C1→w1和fs2:C2→w2为P关于C的两个不同的分配方案,则fs1与fs2是等价的分配方案,若:(1)C1=C2;(2)∀ci∈C1,fs1(ci)与fs2(ci)在P上的导出子图匹配等价。用AFS(fs)表示所有与分配方案fs等价的分配方案(含fs)。
为了便于描述,对于满足fs(c1)=vlist1,fs(c2)=vlist2,…,fs(ct)=vlistt的分配方案fs,将它简记为fs={c1:vlist1;c2:vlist2;…;ct:vlistt}。
定义15(等价方案映射)给定网络图G=(V,E,C)和模式图P=(Vp,Ep),G中各社区构成的集合C={c1,c2,…,ck}。令fs1:C1→w1和fs2:C2→w2为P关于C的两个不同的分配方案,且fs1和fs2等价。定义映射esf:Vp→Vp,称esf是fs1关于fs2的等价方案映射,若esf满足:(1)∀ci∈C1,记fs1(ci)在P上的导出子图关于fs2(ci)在P上的导出子图的对称双射为f,则∀v∈fs1(ci),esf(v)=f(v);(2)esf是双射。
例4以图2(a)为网络图,图2(b)为模式图,记红色社区为c1,绿色社区为c2,蓝色社区为c3,可以得到的分配方案包括:fs1={c1:{va};c2:{vb,vd};c3:{vc}},fs2={c1:{vd};c2:{vc,va};c3:{vb}}等。fs1和fs2的定义域都是{c1,c2,c3},且有fs1(c1)={va},fs1(c2)={vb,vd},fs1(c3)={vc},fs2(c1)={vd},fs2(c2)={vc,va},fs2(c3)={vb}。记结点集合{v1,v2,…,vk}在模式图上对应的导出子图为I{v1,v2,…,vk}。因为图2(b)上I{va}与I{vd},I{vb,vd}与I{vc,va},I{vc}与I{vb}分别匹配等价,所以fs1和fs2是等价的分配方案。fs1关于fs2的等价方案映射esf满足esf(va)=vd,esf(vb)=vc,g(vc)=vb,esf(vd)=va。
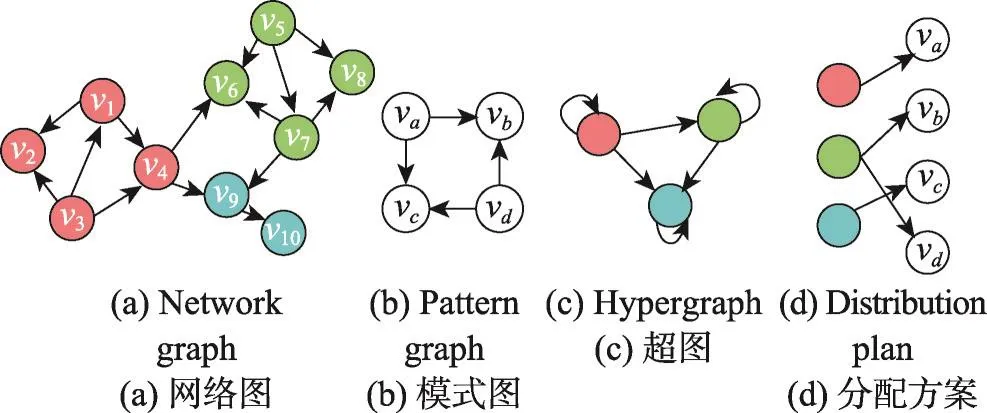
Fig.2 Diagrams for explainingAdvanced_Λ algorithm图2 Advanced_Λ算法说明用图
定义16(同社区结点一跳共同邻居分布表)给定网络图G=(V,E,C)和模式图P=(Vp,Ep),c1,c2∈C是G中两个不同的社区,vpi,vpj∈Vp。将P中的结点分配到各社区后,假设vpi与vpj被分配到c1。用oomessage(vpi,vpj,c2)表示vpi的出邻居中被分配到c2的结点组成的集合与vpj的入邻居中被分配到c2的结点组成的集合的交集的大小,用表示和的出邻居的交集中被分配到c2的结点的数量,用表示和的入邻居的交集中被分配到c2的结点的数量。称oomessage、oimessage和iomessage为同社区结点一跳共同邻居分布表。
例5如图3模式图所示,图中相同颜色的结点被分配到同一个社区。用c1表示红色社区,c2表示绿色社区,c3表示蓝色社区,则oomessage(v1,v5,c2)=1,oimessage(v1,v5,c2)=1,iomessage(v1,v5,c2)=0。

Fig.3 Pattern used by example 5图3 例5所用模式图
算法7(见附录)给出了使用CSO方法优化Λ算法后得到的新算法Advanced_Λ。
具体地,算法7第1、2行进行预处理。首先,第1行生成超图SuperG。以G中的社区作为超图中的结点,若G中两社区c1、c2间存在有向边,则为这两个社区在SuperG中对应的结点间也添加一条同向的有向边;若G中某社区内存在两个不同的结点,且它们之间存在有向边,则为这个社区在SuperG中对应的结点添加自环。接着,第2行根据第4.3节中给出的算法4(匹配等价的子图的查找算法),对模式图P中的每个子图Psub进行处理,得到P中与Psub匹配等价的所有子图,并将这些子图存储在matchEq[Psub]中。
第3、4行进行具体的子图匹配。在Advanced_Λ算法中,子图匹配过程分为社区内子图匹配(第3行)和社区间子图匹配(第4行)两部分。
5.2 社区内子图匹配算法
第5.1节给出的算法7中,第3行进行社区内的子图匹配。算法8(见附录)给出了社区内子图匹配的具体算法。
具体地,算法8依据网络图G的社区结构,通过并行计算同时在多个社区内使用Λ算法进行子图匹配,从而提升子图匹配的效率。
例6以图2中(a)为网络图,(b)为模式图进行子图匹配,则通过算法8的计算,在红色社区内得到的匹配结果为{va→v1,vb→v2,vc→v4,vd→v3},{va→v1,vb→v4,vc→v2,vd→v3},{va→v3,vb→v4,vc→v2,vd→v1},{va→v3,vb→v2,vc→v4,vd→v1},在蓝色社区中无匹配结果,在绿色社区中的匹配结果与红色社区中的结果类似,这里不再列举。

5.3 社区间子图匹配算法
在第5.1节给出的算法中,第4行进行社区间子图匹配,其具体算法如算法9(见附录)所示。
算法9通过在超图SuperG上用模式图P进行结点可重复的子图匹配,获得大量的模式图分配方案superMatch,并将这些分配方案存储在superMatchList中。每当superMatchList中存储的方案超过阈值batch_size时,调用算法10(见附录)对这些分配方案进行处理。算法9第2行使用的结点可重复的子图匹配算法可以通过扩展Λ算法得到。
例7图2(c)是图2(a)对应的超图SuperG,在此超图上对图2(b)表示的模式图进行子图匹配可以得到的分配方案包括(记红色社区为c1,绿色社区为c2,蓝色社区为c3){c1:{va};c2:{vb,vd};c3:{vc}},{c2:{va,vb,vc,vd}},{c1:{va};c2:{vb,vc,vd}},{c1:{va};c3:{vb,vc,vd}}等。图2(d)对应的是分配方案{c1:{va};c2:{vb,vd};c3:{vc}}。
算法9中调用算法10处理分配方案列表superMatchList中的各分配方案。
算法10并行地处理存储了大量分配方案的列表superMatchList(第2行)。superMatch是superMatchList中的一个分配方案,其中存储的是若干元组(ci,vlisti)。(ci,vlisti)表示结点集合vlisti中的结点被分配到社区ci,用vlisti在P中的导出子图与社区ci进行子图匹配。称可能与模式图结点v匹配的网络图结点为v的候选匹配结点,这些候选匹配结点组成的集合称为v的候选匹配结点集合。对于vlisti中的任意v,v的初始的候选匹配结点集合即为ci中包含的所有结点。
算法10首先获取离线计算得到的社区边界出结点集合、入结点集合及相关度数表commOutBoundary,commInBoundary,degreePosOut和degreePosIn(第1行),接着对一些无效的分配方案进行处理。若所有的模式图结点被分配到同一个社区,则不对该方案进行处理(算法第3、4行),这是因为这种情况下进行的是社区内子图匹配,在第5.2节给出的算法8中已完成这类计算;若分配方案中分配到某个社区的模式图结点数超过了该社区中的结点总数,则当前分配方案不可能成功匹配,可以直接处理下一个分配方案(算法第5~7行)。
CSO方法基于社区结构共进行了两类剪枝。第一类剪枝的方法由算法10第9~26行给出。对于superMatch中的每个元组(ci,vlisti),每次从vlisti中取出一个结点v,对于每个社区c′(c′≠ci),用outds[c′]记录v到被分配到c′的所有模式图结点的出边总数,用inds[c′]记录被分配到c′的所有模式图结点到v的出边总数。算法10第13~22行对于模式图中的每个结点v,关于每个社区c′(不包括v所在的社区),计算v对应的outds[c′]和inds[c′]。若网络图中某结点u到社区c′中结点的总出边数小于outds[c′],则v不可能与u匹配,由此,依据commOutBoundary、degreePosOut和outds可以从v的候选匹配结点集合中删除所有不可能与v匹配的结点(第24行)。对于inds也可以进行相应的剪枝(第26行)。将剪枝后得到的v的候选匹配结点集合存储到boundary[v]中。在使用Λ算法进行子图匹配时,对于每个结点v,可以只尝试将它与boundary[v]中结点进行匹配,从而减少子图匹配过程中不必要的计算,提升子图匹配的效率。
算法10第28~30行处理superMatch得到super-MatchMap。superMatchMap中对模式图中每个结点,记录它被分配到的社区。第31~34行获取当前分配方案对应的标志字符串,一个分配方案对应的标志字符串的计算方法为:将分配方案中包含的结点按照ID升序排列,依次获得各结点被分配到的社区的编号后,将这些编号用空格连接得到该分配方案对应的标志字符串。若当前分配方案的标志字符串在与它等价的分配方案中不是最小的,则结束当前分配方案的处理(第35行),这是为了避免重复计算。在第34行的处理中计算了所有与当前分配方案等价的分配方案,若当前分配方案的标志字符串是其中最小的,则将当前分配方案fs关于AFS(fs)中每个分配方案的等价方案映射存入newallmaps中(第36行)。
算法10第37行调用算法11(getTwoHopPattern-Pairs)获得模式图的同社区结点一跳共同邻居分布表。该表的作用如下:记结点t的属于社区c的出邻居结点组成的集合为OutNeighc(t),属于c的入邻居结点组成的集合为InNeighc(t)。在进行子图匹配的过程中,若对于被分配到c的模式图结点u,要在网络图中找到与它匹配的结点,而同样被分配到c的另一个模式图结点v已与网络图结点t匹配,对于尝试与u匹配的网络图结点s,若它满足下述任何一种情况,则u不能与s成功匹配:(1)存在社区c′≠c,|OutNeighc′(t)∩InNeighc′(s)|<oomessage(v,u,c′);(2)存在社区c′≠c,|OutNeighc′(t)∩OutNeighc′(s)|<oimessage(v,u,c′);(3)存在社区c′≠c,|InNeighc′(t)∩InNeighc′(s)|<iomessage(v,u,c′)。此时可直接将u与其他结点匹配。算法中通过上述方式使用此分布表对子图匹配算法进行加速。这是CSO方法基于社区结构进行的第二类剪枝。
算法10第38行,对于当前分配方案superMatch中的每个元组(ci,vlisti),使用Λ算法对每个社区ci与Ivlisti进行子图匹配。其中,使用Λ算法进行匹配时,从boundary[v]中选择结点尝试与v进行匹配,并且使用上述分布表进行加速。将每个社区ci上的所有匹配结果存储在maps[ci]中。算法10第42行调用算法12(test_subgraph_match)对maps中存储的各社区上的子图匹配结果进行合并和结构验证得到P与G的子图匹配结果,并将这些结果存入finds中。合并指的是对每个社区ci,从maps[ci]中取出该社区上的一种匹配结果,将取出的所有匹配结果合并得到P与G的子图匹配结果。因为合并可能会导致如下情况:存在vi,vj∈Vp,它们分别被分配到社区ci和cj,且vi和vj间有边,但是合并后得到的结果中,与vi匹配的结点和与vj匹配的结点间却没有边。这样的合并结果显然不是P与G的子图匹配结果。匹配验证即是要找到所有出现上述情况的合并结果,使得这些合并结果不被加入结果集finds中。
最后,算法10的第43行将finds中的所有子图匹配结果通过newallmaps中存储的等价方案映射进行转换,得到在与当前分配方案等价的分配方案下P与G的匹配结果,一并存储进outs中。
例8在图2(a)所给的网络图上对图2(b)所示的模式图进行社区间子图匹配,记红色社区为c1,绿色社区为c2,蓝色社区为c3。执行rematch函数时,得到了大量的分配方案,其中分配方案{c2:{va,vb,vc,vd}}由于将所有结点分配到了同一个社区,在之前的社区内子图匹配过程中已处理完毕,因而不用处理。分配方案{c1:{va};c3:{vb,vc,vd}}由于将3个结点分配到了蓝色社区,而蓝色社区中只有2个结点,因此不可能有匹配结果出现,因而不用处理。以分配方案{c1:{va};c2:{vb,vd};c3:{vc}}(图2(d))为例。先进行基于社区结构的剪枝。在计算boundary的过程中,根据模式图的结构,要求与结点va匹配的网络图结点在社区c2和c3中各有至少一个出邻居结点,并且与va匹配的网络图结点属于社区c1,因此网络图中满足此条件的只有结点v4,因而boundary[va]={v4},同理可得其余三个模式图结点对应的boundary为boundary[vb]={v6},boundary[vc]={v9},boundary[vd]={v7}。完成剪枝后,后续在社区c2上对子图I{vb,vd}进行子图匹配时,与vb匹配的结点只从集合{v6}中选取,与vd匹配的结点只从集合{v7}中选取,因而子图匹配的过程得到了加速。基于模式图解析的优化方面,如分配方案fs1={c1:{va};c2:{vb,vd};c3:{vc}}与分配方案fs2={c1:{vd};c2:{vc,va};c3:{vb}}等价,且fs1的标志字符串为“1 2 3 2”,是与它等价的所有分配方案中标志字符串最小的,因此当处理fs1时,fs1关于fs2的等价方案映射esf会被存入newallmaps中,其中esf(va)=vd,esf(vb)=vc,esf(vc)=vb,esf(vd)=va。完成了在分配方案fs1下的模式图与网络图的模式匹配后,{va→v4,vb→v6,vc→v9,vd→v7}是它得到的一个子图匹配结果,使用fs1关于fs2的等价方案映射esf对此匹配结果进行转换得到匹配方式{vd→v4,vc→v6,vb→v9,va→v7}。容易发现,这种匹配方式是在分配方案fs2下的模式图与网络图的一个模式匹配结果。
算法11(见附录)给出了计算模式图的同社区结点一跳共同邻居分布表的算法getTwoHopPatternPairs。对于模式图P中的每个结点v,记v被分配到的社区为c,先找到v的出邻居结点中所有被分配到的结点,对于其中的每个结点n,对它的每个出邻居结点n2进行判断,若n2≠v且结点v和n2被分配到相同社区(第9行),则将oomessage中存储的v和n2在c′中的共同邻居数加1(算法第10行)。对oimessage和iomessage的处理与此类似,算法11第11~13行计算oimessage,第14~20行计算iomessage。
定理8算法11(getTwoHopPatternPairs)的时间复杂度为。
算法12(见附录)给出了对maps中存储的匹配结果进行合并及结构验证的算法test_subgraph_match。maps[c]中存储的是被分配到社区c的模式图结点在模式图上的导出子图与c进行子图匹配的结果,comit是在网络图G=(V,E,C)的社区集合C上的迭代器,记迭代器当前所指社区为cit(第4行)。算法第5行声明了用match表示社区cit上得到的一种子图匹配结果。若一个社区对应的迭代器在区间[C.begin(),comit)中,则称该社区为处理过的社区。从各个处理过的社区中选出的匹配结果已成功互相合并,且合并结果存储在currentMap中。对于被分配到cit的每个模式图结点v(第6行),以及每个被分配到处理过的社区的模式图结点n,若n到v有出边而与n匹配的结点currentMap[n]到match中与v匹配的结点match[v]无出边,则意味着两个模式图结点间有边,但与它们匹配的网络图结点间没有边,因此合并的结果不可能是P与G的子图匹配结果,因此当前match无法通过结构验证(第8~10行),直接尝试合并该社区上的下一个匹配结果。对于v到n的出边的处理方法相同(第11~13行)。若当前match与currentMap可以合并,则将当前匹配结果match合并入current-Map中(第14行),随后开始尝试合并下一个社区的匹配结果(第15、16行),完成合并后回退,将match中的匹配从currentMap中删除(第18行),准备开始尝试合并当前社区的下一个匹配结果。当对于每个被分配了模式图结点的社区,均成功将该社区上的一个匹配结果合并入currentMap中时,currentMap中存储的即是P与G的一个子图匹配结果,将合并得到的匹配结果(currentMap)加入finds中(第1~3行)。
例9在图4所示网络图G=(V,E,C)上对图2(b)所示模式图进行社区间子图匹配,C={c1,c2,c3},其中c1对应红色社区,c2对应绿色社区,c3对应蓝色社区。对于图2(d)所示的分配方案,得到的maps中,有{va→v4}∈maps[c1],{vb→v5,vd→v7},{vb→v6,vd→v7}∈maps[c2],{vc→v9}∈maps[c3]。先尝试合并{va→v4}、{vb→v5,vd→v7}与{vc→v9}。comit首先指向红色社区,记录currentMap[va]=v4。完成红色社区的匹配后,comit指向下一个社区,即绿色社区。随后开始处理绿色社区,判断能否将{vb→v5,vd→v7}合并进currentMap中。首先看能否将结点vb与结点v5匹配,此时社区c1是已处理过的社区,因此作为c1中的结点va,由于模式图中存在一条从va到vb的出边,因此对于与va匹配的v4,也要求存在一条从v4到v5的出边,但是G中不存在这样一条边,因此无法通过结构验证,合并失败。而{va→v4}、{vb→v6,vd→v7}与{vc→v9}则能通过算法12的验证而成功合并,因此{va→v4,vb→v6,vd→v7,vc→v9}是一个正确的匹配结果。

Fig.4 Directed network used by example 9图4 例9所用有向网络图
定理9算法12(test_subgraph_match)的时间复杂度为,其中,M是模式图中结点经过基于社区剪枝后得到的候选匹配结点最多的结点对应的候选匹配结点集合的大小,Np是模式图中的结点数量。
显然,有M<Ncmax,其中Ncmax为结点数量最多的社区中包含的结点个数。在良好的社区划分下,属于不同社区的结点间的边数较少,使基于社区剪枝后各结点对应的候选匹配结点集合中元素个数较少,进而使得M值较小。
定理10社区间子图匹配算法(算法9)的时间复杂度为,其中θ(n)表示使用的子图匹配算法在结点数为n时的时间复杂度,NSuperG为超图中的结点数量,ns为对超图进行结点可重复的子图匹配得到的分配方案的总数,Ncmax为结点数量最多的社区包含的结点个数,M是模式图中结点经过基于社区剪枝后得到的候选匹配结点最多的结点对应的候选匹配结点集合的大小,是由并行化和模式图解析带来的时间效率提升,其中r2>1。
当Np较小时,定理10中给出的时间复杂度近似等于。
定理11Λ算法经CSO方法优化后得到的新算法Advanced_Λ(算法7)的时间复杂度为是通过并行化和匹配等价带来的时间效率的提升,其中r>1。
CSO方法中采用了模式图解析与基于社区结构的剪枝两种策略对子图匹配算法进行优化。
下面具体分析这两种优化策略的优化效果的影响因素。模式图的解析利用匹配等价关系由计算得到的社区间子图匹配结果推断出其他一些社区间子图匹配结果,因此,对于给定的网络图和模式图,社区间子图匹配的能得到的结果越多,应用模式图解析的结果推断得到的结果很可能越多,从而使得模式图解析的优化效果越明显。另外,根据模式图解析的过程容易发现,模式图中找到的互相匹配等价的子图越多,能通过推断得到的匹配结果就越多,使得优化效果越明显。对于CSO方法的另一种优化策略,即基于社区结构的剪枝,当网络图相同时,模式图越稠密,模式图中结点对应的候选匹配结点就越少,即剪枝效果就越好。该优化策略的具体优化效果与原子图匹配算法Λ有关,例如,当模式图变得稠密时,Λ算法会尝试的错误匹配的数量变少,使其匹配用时减少。同时,由于模式图变得稠密,模式图中各结点对应的候选匹配结点减少,即剪枝效果变好,使Advanced_Λ算法尝试了更少的匹配方式,但由于Λ算法尝试的错误匹配的数量也减少了,因此减少的错误匹配的数量可能增加也可能减少,从而导致基于社区结构的剪枝的优化效果不稳定。因此,基于社区结构的剪枝的剪枝效果更好并不一定意味着其优化效果也更好。
对于CSO方法中使用的两种优化策略中模式图解析利用模式图上的匹配等价的子图,不计算可以推断出的子图匹配结果;基于社区结构的剪枝使用社区信息减少了子图匹配过程中错误匹配的次数。对于任意的子图匹配算法上述两种策略都能有效减少计算量,从而减少子图匹配的时间开销,因此CSO方法对任意子图匹配算法都是有效的。
上述Advanced_Λ的算法中,模式图的解析和基于社区结构的剪枝这两部分的优化算法与Λ算法之间是低耦合的,因此能方便地使用CSO方法对各种子图匹配算法进行优化。
5.4 CSO方法正确性证明
首先,可以证明在子图匹配过程中,对于互相匹配等价的两个模式图P1=(Vp1,Ep1)和P2=(Vp2,Ep2),若P1与网络图G=(V,E,C)进行子图匹配得到了若干匹配结果,在这些匹配结果上应用P1关于P2的对称双射f,得到的是P2与G的所有子图匹配结果。这里的“应用P1关于P2的对称双射f”指的是:记P1与G的一个匹配结果为match,定义match′为一个新的匹配结果。∀match[u]=v,其中u∈Vp1,v∈V,令match′[f(u)]=v,得到的match′即是对匹配match应用P1关于P2的对称双射f得到的新的匹配结果。因此,可以证得模式图解析的优化策略的正确性。
接着,根据基于社区结构的剪枝的具体策略容易证明该优化策略的正确性。
随后,证明将子图匹配流程分为社区内子图匹配和社区间子图匹配两个过程不会得到错误的结果也不会丢失任意一个正确的结果。
最后,综合上述的结论可以证明CSO方法的正确性。
定理12CSO方法是正确的。
6 实验
鉴于VF2[5]算法是影响最为广泛的子图匹配算法之一[27],本章用CSO对VF2算法进行优化。
6.1 实验准备
本实验使用了三个合成数据集(Opera_1000、Opera_10000和Opera_100000)与三个真实数据集(Email[28]、DBLP_5k[29]和 Friendster_5k[29])。其中,Email是email-Eu-core的简称,该数据集是一个欧洲大型研究机构人员的邮件往来数据,网络中的有向边表示边起点对应的用户给边终点对应的用户发送了至少一封邮件,相同部门的人对应的结点构成一个社区;DBLP_5k数据集中记录的是计算机科学领域研究论文的作者间的关系,每个结点代表一个人,若两人共同完成了至少一篇论文,则为他们对应的结点间添加一条边,在一种给定出版物上发表过论文的所有人对应的结点构成一个社区,从中选择质量最高的5 000个社区构成DBLP_5k数据集;Friendster_5k数据集描述的是人与人之间的好友关系,每个结点表示一个人,两个人互为好友则为他们对应的结点间添加一条边,将人自发形成的群组作为社区,选择其中质量最高的5 000个社区构成Friend-ster_5k数据集。
这些数据集的统计信息如表1所示。需要注意的是,在具体实验中,无向图中的每条边表示为两条对应的有向边。于是,表1中无向数据集的平均度数等于表格中数值的两倍。

Table 1 Datasets information表1 数据集的统计信息
实验中共使用了五种不同的模式图,分别为三完全图(图5(a),简记为K3)、四完全图(图5(b),简记为K4)、五结点稀疏图(图5(c),简记为P5sp)、五结点对称图(图5(d),简记为P5sy)和四结点对称图(图5(e),简记为P4sy)。
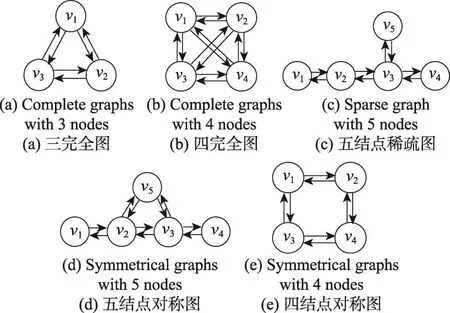
Fig.5 Patterns used in experiments图5 实验中使用的模式图
本文实验所有代码均为C++,开发工具是VS 2015,操作系统为Windows 7,CPU Intel Core i5 2.00 GHz,内存4GB。优化后VF2算法简记为AVF2(Advanced_VF2),参数batch_size的值设置为1 000 000。
6.2 性能对比实验
本节在多个数据集上对VF2算法与AVF2算法的性能进行了测试,并对测试结果进行分析。VF2算法和AVF2算法在不同数据集和不同模式图上的效率对比情况如表2所示。用优化率来衡量CSO方法对VF2算法的优化效果,优化率的计算方法是(原算法用时-优化后算法的用时)/原算法用时,优化率的上界是1,其值越接近1表示优化效果越好。

Table 2 Comparison between efficiency of VF2 andAVF2表2 VF2与AVF2效率比较
实验中VF2算法和AVF2算法在相同数据集上对相同模式图进行匹配时得到相同的结果,证明了CSO方法的正确性。
分析表2所示实验结果,对于算法VF2和AVF2能在24 h内完成的匹配任务,AVF2相比VF2用时普遍减少55%以上,其中在DBLP_5k数据集下用K3进行子图匹配时优化效果最明显,优化率达到了0.94。另一个优化效果明显的例子是在Email数据集上用P5sp进行模式匹配,VF2在此任务上的用时为21.5 h,而AVF2算法只用了1.6 h。
这些测试结果均表明,AVF2算法相比VF2算法时间开销大大减小,证明了CSO方法的有效性。
通过分析表2中三个数据集上的实现结果,可以发现与合成数据集上的优化效果相比,在真实数据集上的优化率提高了0.2以上。这是因为相比合成数据集,真实数据集对应的网络图稀疏得多,所以属于不同社区的结点之间的边更少,CSO方法中基于社区结构的剪枝效果更明显,因此子图匹配算法性能提升更大。生产生活中使用的网络图通常较为稀疏,这意味着本文的CSO方法在现实应用中能产生很好的效果,具有重要的现实意义。
在DBLP_5k数据集上使用模式图P5sp和P5sy进行实验时,VF2算法和AVF2算法在24 h内均无法完成匹配,这是因为AVF2算法是用CSO方法对VF2算法进行优化得到的,在AVF2中使用VF2进行社区内子图匹配。随着数据规模的增大和模式图的复杂化,VF2的时间开销大幅增加,使得AVF2算法的耗时随之增加。
上述实验证明了CSO方法的有效性,值得探究的一点是CSO方法中使用的两种策略各自有怎样的优化效果。下面结合具体实验比较基于社区结构进行剪枝和解析模式图两种策略对子图匹配算法的优化效果。从算法AVF2中将基于社区结构进行剪枝的相关优化删掉得到新的算法NC_AVF2,从算法AVF2中将模式图解析相关的优化删掉得到新的算法NP_AVF2。在Email和Opera_1000两个数据集上以模式图K3、K4和P4sy为例进行子图匹配,测试上述两种算法的用时,并将测试结果与AVF2算法进行比较。
由表3可以发现,在两个数据集上,NC_AVF2和NP_AVF2相比算法AVF2用时均有所增加,其中在Email数据集上删去任意一种优化策略均会导致用时增加40%以上,这表明CSO方法中使用的两个优化策略都是有效的。

Table 3 Comparison ofAVF2,NC_AVF2 and NP_AVF2 algorithm表3 AVF2算法、NC_AVF2算法和NP_AVF2算法比较
在Email数据集上,模式图解析的优化效果均达到40%以上,而在Opera_1000数据集上其优化效果却不明显,其原因在于,根据第5.3节中的分析,模式图解析的优化效果受社区间子图匹配结果数量的影响,而在Opera_1000数据集上的社区间子图匹配结果的数量远少于Email数据集,因此导致Opera_1000数据集上模式图解析的优化效果不明显。以模式图K4为例,在Email数据集上,共有1 498 656个社区间子图匹配结果,占总匹配结果数的82.3%,而在Opera_1000数据集上,仅有2 184个社区间子图匹配结果,占总匹配结果数量的0.02%,这就导致在Opera_1000数据集上模式图解析优化效果远不如Email数据集。
值得注意的是,模式图K4与P4sy上的实验结果验证了第5.3节中关于基于社区结构的剪枝的优化效果与模式图稠密程度的关系的分析。虽然K4比P4sy更稠密,使得在网络图相同的情况下,P4sy中的各结点对应更多的候选匹配结点,即基于社区结构的剪枝的剪枝效果更差,尝试了更多的匹配方式,但在模式图为P4sy时VF2算法尝试的错误的匹配方式也增加了,且增加的幅度更大,这使得基于社区结构的剪枝在模式图为P4sy时比模式图为K4时有更明显的优化效果。这验证了第5.3节中分析得到的基于社区结构的剪枝的剪枝效果更好并不代表其优化效果也更好的结论。
6.3 可扩展性分析
CSO方法的可扩展性体现在其优化效果随数据集规模增大的变化情况。在本实验中,CSO方法的可扩展性具体表现为随着数据集规模的扩大,AVF2算法相对VF2算法的优化率的变化情况。以模式图K3为例,在不同规模的数据集下的子图匹配用时如表4所示。

Table 4 Results of scalability tests表4 可扩展性测试结果
根据实验结果可以看出,随着网络图规模的不断扩大,优化率逐渐提升,在Friendster数据集下,优化率接近1。这意味着随着网络图数据量的增大,CSO方法的优化效果越来越明显。因此,CSO方法具有很好的可扩展性。
6.4 参数敏感性分析
本节分析CSO方法的参数敏感性。在CSO方法中,batch_size是一个重要的参数,其用途是:当superMatchList中存储了batch_size个分配方案时,调用算法10(rematch)批量地处理这些分配方案。本实验中,CSO方法的参数敏感性体现在AVF2算法的子图匹配用时随batch_size的变化情况。
以在Email数据集上用模式图K4进行子图匹配为例测试CSO方法的参数敏感性。在Email数据集上使用AVF2算法进行子图匹配时,共能获得790 593种分配方案。在1到790 593的范围内选择若干值作为batch_size的取值进行实验,得到表5中的实验结果。

Table 5 Execution time of AVF2 with different values of batch_size表5 不同batch_size取值时AVF2算法用时
从表5可以看出,随着batch_size从小到大接近实际的分配方案数,子图匹配的用时逐渐减少,这表明当batch_size小于实际分配方案数时,更大的batch_size能通过减少rematch执行次数减少算法用时。另一方面,随着batch_size的增大,AVF2算法用时减少的幅度不断减小,当batch_size值接近实际分配方案数时,AVF2算法的用时基本不再随着batch_size的变化而变化。
需要注意的是,更大的batch_size值就意味着要在存储待处理分配方案的列表superMatchList中存储更多的待处理分配方案,因此会带来更大的内存开销。在选择参数batch_size的值时,需要权衡用时和内存开销,合理选择batch_size的值。
7 结束语
本文提出了一种基于社区结构的子图匹配算法优化方法CSO。CSO方法通过将子图匹配流程划分为社区内子图匹配和社区间子图匹配两个过程实现了匹配过程的并行化;通过解析模式图中的匹配等价的子图减少了子图匹配过程中的计算量;通过依据社区结构进行剪枝减少了匹配过程中错误匹配发生的次数。使用上述策略,CSO方法能大大提升子图匹配算法的计算速度。实验结果表明CSO方法具有高效性和很好的可扩展性。未来将尝试通过并行化方法同时进行社区内子图匹配和社区间子图匹配,进一步提升子图匹配算法的运行速度。
附录:
算法1模式图中全等点对的查找算法getEqualNodes
输入:P=(Vp,Ep)。
输出:equalNodes,patternEqualClass。
1.for each nodev∈Vp
2.将(v,v)插入equalNodes中
3.for each nodevi∈Vp
4.for each nodevj∈Vp-{vk|k≤i}
5.ifSize(OutNeigh(vi))≠
Size(OutNeigh(vj))or Size(InNeigh(vi))≠
Size(InNeigh(vj))
6.continue
7.ifOutNeigh(vi)-{vi,vj} ==OutNeigh(vj)-{vi,vj} andInNeigh(vi)-{vi,vj}==InNeigh(vj)-{vi,vj}andvi和vj间存在双向边或不存在边
8.将(vi,vj)、(vj,vi)插入equalNodes中
9.classNumber=0
10.for each nodev∈Vp
11.ifpatternEqualClass[v]≠NULL
12.continue
13.classNumber=classNumber+1
14.for each noden∈equalNodes[v]
15.patternEqualClass[node]=classNumber
16.returnequalNodes,patternEqualClass
算法2模式图中对称点对的查找算法getSymmetryNodes
输入:P=(Vp,Ep),symm。
输出:symmetryNodes。
1.for each nodevi∈Vp
2.for each nodevj∈Vp-{vk|k≤i}
3.if(vi,vj)∈equalNodes
4.continue
5.set<int>used//定义存储使用过的结点的集合used
6.symmetryTest(P,vi,vj,symm,used)
7.for each nodevi∈Vp
8.for each nodevj∈Vp
9.ifsymm[vi][vj]==True
10.将(vi,vj)插入symmetryNodes中
11.returnsymmetryNodes
算法3递归查找对称点对的算法symmetryTest
输入:P=(Vp,Ep),vi,vj,symm,used。
输出:isSymmetry。
1.if(vi,vj)∈equalNodes
2.returnTrue
3.ifsymm[vi][vj]≠NULL
4.returnsymm[vi][vj]
5.ifSize(OutNeigh(vi))≠Size(OutNeigh(vj))orSize(InNeigh(vi))≠Size(InNeigh(vj))
6.设置symm[vi][vj],symm[vj][vi]为False
7.returnFalse
8.将vi、vj插入used中
9.unusedNeighs1=OutNeigh(vi)-used
10.unusedNeighs2=OutNeigh(vj)-used
11.ifSize(unusedNeighs1)≠Size(unusedNeighs2)
12.设置symm[vi][vj],symm[vj][vi]为False
13.从used中删除vi和vj
14.returnFalse
15.for eachnode1∈unusedNeighs1
16.find=False
17.for eachnode2∈unusedNeighs2
18.ifsymmetryTest(G,node1,node2,symm,used)==True
19.find=True
20.从unusedNeighs2中删除node2
21.break
22.if find==False
23.设置symm[vi][vj],symm[vj][vi]为False
24.从used中删除vi和vj
25.returnFalse
26.仿照9~25行对结点的入邻居进行处理
27.设置symm[vi][vj],symm[vj][vi]为True
28.从used中删除vi和vj
29.returnTrue
算法4匹配等价的子图的查找算法handleMatchPattern
输入:P=(Vp,Ep),isomorphicList,isomap,matchedModel,matchEq。
输出:matchEq。
1.vector<int>current//声明了存储模式图子图包含的结点的向量current
2.matchEq=retrivalNodes(current,0,isomorphicList,isomap,matchedModel,P,False,matchEq)
3.for each(I,listI)∈matchEq
4.SI=isomap[I]
5.for eachIt∈listI
6.ifisomap[It]≠SI
7.从matchEq[I]中删除It
8.returnmatchEq
算法5遍历模式图结点能构成的所有子图并构造匹配等价的子图之间的映射的算法retrivalNodes
输入:current,pos,isomorphicList,isomap,matchedModel,P=(Vp,Ep),added,matchEq。
输出:matchEq。
1.ifadded==True
2.构造由current对应的模式图P的导出子图Icurrent
3.if Size(current)≥1
4.set<int>record//声明存储使用过的结点的集合record
5.vector<int>t//声明存储current通过对称点替换和全等点替换得到的新结点列表t
6.matchEq=getAllMatchNodes(P,current,0,t,record,False,matchEq)
7.succeed=False
8.for(Si,Ii)∈matchedModel
9.ifSize(Icurrent)≠Size(Ii)
10.continue
11.ifIcurrent与Ii同构
12.将Icurrent加到isomorphicList[Si]末尾
13.isomap[Icurrent]=Si
14.succeed=True
15.break
16.ifsucceed==False
17.计算Icurrent的特征字符串Scurrent
18.将(Scurrent,Icurrent)插入matchedModel
19.将Icurrent加到isomorphicList[Scurrent]末尾
20.isomap[Icurrent]=Scurrent
21.ifpos≥Size(V)
22.returnmatchEq
23.matchEq=retrivalNodes(current,pos+1,isomorphicList,isoMap,matchedModel,P,False,matchEq)
24.将vpos加到current末尾
25.matchEq=retrivalNodes(current,pos+1,isomorphicList,
isomap,matchedModel,P,True,matchEq)
26.弹出current最后一项
27.returnmatchEq
算法6计算所有与输入的图满足邻域范围条件的图的算法getAllMatchNodes
输入:P=(Vp,Ep),current,pos,t,record,hasSymm,matchEq。
输出:matchEq。
1.ifpos≥Size(current)
2.分别构造current和t在P上对应的导出子图Icurrent与It
3.用f表示Icurrent得到It过程中进行的所有替换,每个f(u)=v表示将Icurrent中的结点u替换成了v,对于未被替换的结点n,令f(n)=n。f即是Icurrent关于It的扩展对称映射
4.ifhasSymm==True
5.若Icurrent与It不满足邻域范围规则,returnmatchEq
6.ifIcurrent与It包含的结点相同
7.if is_sorted(t)
8.将It插入matchEq[Icurrent]中 //It是t在P上对应的导出子图
9.else 将It插入matchEq[Icurrent]中
10.else若t中属于相同全等点组的结点的ID均升序排列
11.将It插入matchEq[Icurrent]中
12.returnmatchEq
13.for each(current[pos],n)∈equalNodes
14.ifnnot inrecord
15.将n加到t的末尾
16.将n插入record中
17.matchEq=getAllMatchNodes(G,current,pos+1,t,record,hasSymm,matchEq)
18.弹出t的最后一项
19.从record中删除n
20.for each(current[pos],n)∈symmetryNodes
21.ifnnot inrecord
22.将n加到t的末尾
23.将n插入record中
24.matchEq=getAllMatchNodes(G,current,pos+1,t,
record,True,matchEq)
25.弹出t的最后一项
26.从record中删除n
27.returnmatchEq
算法7使用CSO方法优化L后得到的新算法Advanced_L。
输入:G=(V,E,C),P=(Vp,Ep),batch_size。
输出:子图匹配的结果。
1.根据G生成超图SuperG
2.找出P中所有互相匹配等价的子图,存储在matchEq中
3.ins←intraCommPatternMatch(G,P) //社区内子图匹配
4.outs←interCommPatternMatch(G,P,SuperG,batch_size,matchEq)//社区间子图匹配
5.returnins+outs
算法8并行的社区内子图匹配算法intraCommPattern-Match
输入:G=(V,E,C),P=(Vp,Ep)。
输出:ins。
1.parallel for ea ch communitycomminG
2.在社区comm中使用Λ算法对P进行子图匹配,将结果存储到ins中
3.returnins
算法9社区间子图匹配算法interCommPatternMatch
输入:G=(V,E,C),P=(Vp,Ep),SuperG,batch_size,matchEq。
输出:outs。
1.superMatchList=[]//声明存储分配方案的列表superMatchList
2.在超图SuperG上用模式图P进行结点可重复的子图匹配,将得到的分配方案superMatch插入superMatchList中,每当superMatchList内分配方案个数超过batch_size,执行算法第3行
3.rematch(G,P,SuperG,superMatchList,outs,matchEq)
4.若尚未完成结点可重复的子图匹配,清空superMatch-List并执行算法第2行
5.returnouts
算法10对算法9中得到的模式图分配方案列表super-MatchList进行处理的算法rematch
输入:G=(V,E,C),P=(Vp,Ep),SuperG,superMatchList,outs,matchEq。
输出:outs。
1.获取离线计算得到的commOutBoundary,commInBoundary,degreePosOut,degreePosIn
2.parallel for eachsuperMatch∈superMatchList
3.ifSize(superMatch)==1
4.continue
5.for each(c,vlist)∈superMatch
6.ifSize(c)<Size(vlist)
7.continue
8.unordered_map<int,vector<int>>boundary//声 明记录能与模式图中结点匹配的网络图G中的结点列表的字典boundary
9.for each(c,vlist)∈superMatch
10.for each nodev∈vlist
11.unordered_map<int,int>outds,inds//声 明记录模式图中结点v与被分配到各社区的所有模式图结点间的出边总数和入边总数的字典
12.hasOut,hasIn=False
13.for each(c′,vlist′)∈superMatch
14.ifc==c′
15.continue
16.forv′∈vlist′
17.ifhasedge(v,v′)
18.outds[c′]++
19.hasOut=True
20.ifhasedge(v′,v)
21.inds[c′]++
22.hasIn=True
23.ifhasOut==True
24.根据commOutBoundary、degreePosOut及outds缩小v的候选匹配结点集合,若候选集合为空,直接执行第一行
25.ifhasIn==True
26.根据commInBoundary、degreePosIn及inds缩小v的候选匹配结点集合,若候选集合为空,直接执行第一行
27.map<int,int>superMatchMap//声明记录模式图中每个结点被分配到哪个社区的字典superMatchMap
28.for each(c,vlist)∈superMatch
29.for each nodev∈vlist
30.superMatchMap[v]=c
31.mystr=""
32.Sort(Vp)
33.for ea ch nodev∈Vp
34.mystr+=to_string(superMatchMap[v])+""
35.使用matchEq找到与当前分配方案等价的分配方案,并比较它们的标志字符串,若mystr不是所有标志字符串中最小的,则结束匹配并执行第一行
36.将当前关于与它等价的分配方案的等价方案映射存储到newallmaps中
37.oomessage,oimessage,iomessage=getTwoHopPatternPairs(P,superMatchMap)
38.根据分配方案,对被分配了模式图结点的社区与被分配的结点集合对应的模式图导出子图使用Λ算法进行子图匹配,其中,模式图中各结点能与G中哪些结点匹配由boundary给定。匹配中使用同社区结点一跳共同邻居分布表进行剪枝。若匹配失败,则不再处理当前分配方案,并执行第一行,否则将各社区c上的匹配结果存储到maps[c]中
39.currentMap={} //声明用于记录已完成结构验证的匹配的字典
40.finds={} //声明用于存储完成合并和结构验证得到的模式图P在网络图G上的匹配结果
41.comit=C.begin() //C是G对应的社区集合,声明commit为C上的迭代器
42.test_subgraph_match(G,P,superMatch,maps,comit,currentMap,finds)
43.对newallmaps中存储的每种映射,将finds中的所有匹配结果通过映射得到新的匹配结果,并将得到的匹配结果存储到outs中
44.returnouts
算法11模式图的同社区结点一跳共同邻居分布表的计算算法getTwoHopPattern Pairs
输入:P=(Vp,Ep),superMatchMap。
输出:oomessage,oimessage,iomessage。
1.for each nodev∈Vp
2.cv←superMatchMap[v]
3.for each noden∈OutNeigh(v)
4.cn←superMatchMap[n]
5.ifcv==cn
6.continue
7.for each noden2∈OutNeigh(n)
8.cn2←superMatchMap[n2]
9.ifv≠n2且cv==cn2
10.oomessage[v][n2][cn]++
11.for each noden2∈InNeigh(n)
12.ifv≠n2且cv==cn2
13.oimessage[v][n2][cn]++
14.for each noden∈InNeigh(v)
15.cn←superMatchMap[n]
16.ifcv==cn
17.continue
18.forn2∈OutNeigh(n)
19.Ifv≠n2且cv==cn2
20.iomessage[v][n2][cn]++
21.returnoomessage,oimessage,iomessage
算法12对maps中存储的匹配结果进行合并及结构验证的算法test_subgraph_match
输入:G=(V,E,C),P=(Vp,Ep),superMatch,maps,comit,currentMap,finds。
输出:finds。
1.ifcomit==C.end()
2.将currentMap加到finds末尾
3.returnfinds
4.cit←C[comit]
5.for eachmatch∈maps[cit]
6.for each nodev∈superMatch[cit]
7.对被分配到处理过的社区的各结点n,记与它匹配的结点vn=currentMap[n]。
8.ifP.hasedge(n,v)
9.if!G.hasedge(vn,match[v])
10.执行第5行
11.ifP.hasedge(v,n)
12.if!G.hasedge(match[v],vn)
13.执行第5行
14.将match中的匹配加入currentMap中
15.comit++
16.test_subgraph_match(G,C,P,superMatch,maps,comit,currentMap,finds)
17.comit--
18.将match中的匹配从currentMap中删除
19.returnfinds
