PLRD-(k,m):保护链接关系的分布式k-度-m-标签匿名方法*
2019-01-17张晓琳何晓玉张换香李卓麟
张晓琳,何晓玉,张换香,李卓麟
内蒙古科技大学 信息工程学院,内蒙古 包头 014010
1 引言
随着互联网技术的快速发展,社会网络分析在众多领域获得广泛关注和应用。社会网络分析需要将网络数据发布给第三方,由于社会网络数据包含用户的隐私信息,如何在发布数据的同时保护用户的隐私信息成为研究的热点。社会网络通常被表示成简单图,图中的节点和边分别对应社会网络中的个体以及个体间的联系,个体的属性信息,如年龄则表示成节点的标签,如图1所示。

Fig.1 Social network graphG图1 社会网络原始图G
重识别(re-identification)攻击[1],是指攻击者通过与攻击目标相关的背景知识(如度、邻居子图等),从网络中识别出目标的过程。为了抵抗重识别攻击,研究者提出了不同的社会网络图匿名化技术,通过修改图结构防止隐私信息泄露,如k-degree匿名[2]。现实中,攻击者能够很轻易地获取到与目标相关的多种背景知识,简单地通过修改图结构并不能很好地保护个体的隐私。
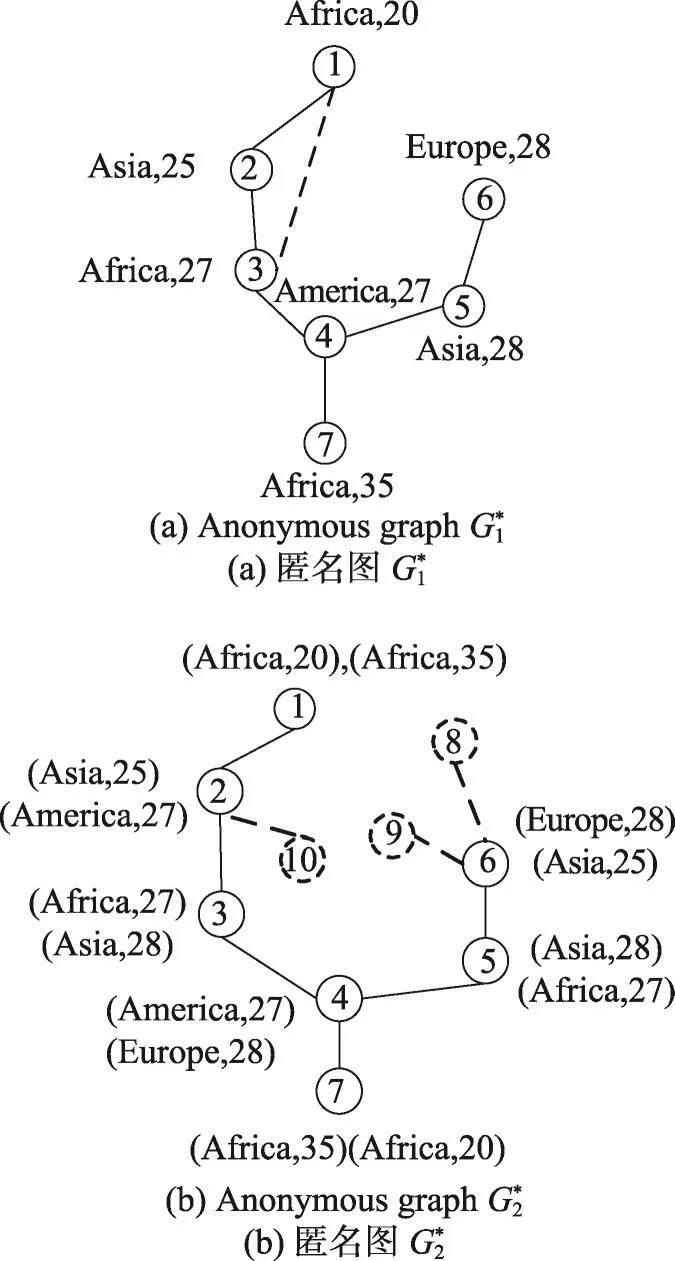
Fig.2 Two anonymized versions forG图2 图G的两个匿名图
为此,提出一种分布式社会网络匿名方法,目的是在提高处理大规模社会网络效率的同时,得到匿名图,如图2(b)所示。在图中,即使攻击者获知节点的度和标签,也无法准确推测出被攻击者的身份及链接关系。例如攻击者获知Bob在社会网络中拥有3个朋友,27岁且来自America,图中节点2和4均符合条件,则攻击者准确识别出Bob的概率不大于1/2,且由于节点2和4不存在链接,攻击者也无法推测出Bob的链接关系。
2 相关工作
随着在线社会网络的发展和普及,社会网络隐私信息的安全性成为研究学者关注的热点,并提出了多种保护方法。文献[4]引入属性-社交网络模型将属性信息视作节点,通过分割节点属性链接和社交链接保护用户隐私。文献[5]提出一种基于kdegree匿名的隐私保护模型SimilarGraph,采用动态规划的方法对节点进行最优簇划分,在保护隐私的同时保持社会网络图结构性质。文献[6]提出一种kweighted-degree匿名方法,在匿名图中,对任意节点,至少存在(k-1)个其他节点与其度相同且在阈值t范围内具有相同的权重序列。文献[7]提出一种utilityaware匿名方法,在进行k-degree匿名时同时考虑最短路径和邻居节点重叠程度,提高了匿名图的数据可用性。文献[8]指出即使个体的身份信息被有效隐藏,攻击者仍能推测出个体的链接关系,为此设计了一种L-opacity匿名模型,通过opacity矩阵在保护个体身份的同时保护链接关系。文献[9]将用户交互社会网络抽象成二分图模型,通过为用户产生一个标签列表的方式抵抗重识别攻击。文献[10]针对敏感链接关系设计一个LinkMirage模型,模糊社会网络图中的社交拓扑结构并提供带有模糊社交关系视图的不受信任的外部应用,从而抵抗重识别攻击。文献[11]提出添加伪节点,并在真实节点和伪节点间添加边的k-degree匿名方法。文献[12-13]提出了基于社区的图匿名模型,在k-degree匿名的同时,提高匿名图的数据可用性。文献[14]提出一种基于单变量微聚合的k-degree匿名方案,通过建立差矩阵Mp×2提高数据的可用性。文献[15]提出了基于SMC(secure multi-party computation)模型的隐私保护方案,“数据代理”通过分布匿名协议实现标签属性和存储位置的l-diversity匿名。文献[16]提出一种基于SMC模型的semi-honest的交换加密技术,保护隐私信息。文献[17]提出基于MapReduce模型的隐私保护方案,通过两个阶段实现k-匿名。文献[18-19]则利用Map-Reduce框架在大规模图中检索同构子图。
可以看出,目前的隐私保护技术多关注匿名数据的可用性,忽略了攻击者可能具有多种背景知识的情况。此外,现有的分布式隐私保护技术针对的是关系型数据,未考虑个体在社会网络中的图性质特征,不能很好地保护个体的隐私,并且MapReduce将中间结果存放于磁盘,处理过程中需要反复迁移数据,并不适合处理图数据。为此,提出一种分布式匿名方法 PLRD-(k,m)(distributedk-degree-m-label anonymity with protecting link relationships),该方法基于GraphX系统[20-21],在保护隐私的同时提高算法的执行效率。
3 背景知识及问题定义
社会网络表示成节点带标签的简单无向图G=(V,E,L,δ),其中节点集V代表社会网络中的用户,E是边集合代表用户间的联系,社会网络中个体的属性信息用节点标签L表示,函数δ表示节点与标签之间的映射δ:V→L。
定义1(标签链接泄露)已知G*是社会网络图G=(V,E,L,δ)的匿名图,C是攻击者通过标签信息得到的一组节点,对∀u∈C,∀v∈C,若攻击者能以一定概率推测出u、v存在链接,则称C存在标签链接泄露。
以图2(a)为例,攻击者通过目标27岁,得到节点3和4,此时,能推测节点3和4存在链接,因此{3,4}存在标签链接泄露。
定义2(PLR-(k,m)匿名)已知G*是社会网络图G=(V,E,L,δ)的匿名图,若图G*是PLR-(k,m)匿名,则满足:
(1)图G*是k-degree匿名图,即攻击者通过节点的度,识别出目标节点的概率不大于1/k。
(2)图G*是m-标签匿名图,即攻击者通过节点标签,识别出目标节点的概率不大于1/m。
(3)匿名图G*不存在标签链接泄露。
定义3(最大缺失值)已知社会网络图G=(V,E,L,δ),Ci(i=1,2,…,k)是包含k个节点的分组,且Ci∧Ci+1=∅ ,Δi是分组Ci内节点度最大值与最小值的差,若M是最大缺失值,则M=max{Δ1,Δ2,…,Δi,Δi+1,…,Δn}[11]。
以图1为例,若分组C1={3,5,1,7},C2={4,2,6},则此时最大缺失值M=max{(2-1),(3-1)}=2。
定义4(无向完全图)若图G={V,E}是无向完全图,则满足条件:
∀u∈V,∀v∈V⇒(u,v)∈E
4 分布式隐私保护算法PLRD-(k,m)
GraphX是Spark上用于图和并行图计算的处理系统,编程模型上遵循“节点为中心”模式,计算过程由若干顺序执行的超级步(superstep)组成,在超级步S中,节点汇总从超级步(S-1)中其他节点传递过来的消息,改变自身的状态,并向其他节点发送消息,消息经过同步后,会在超级步(S+1)中被其他节点接收并做出处理。同时,GraphX引入了扩展自Spark RDD的属性图,并提供了一组基本功能操作,如图构造操作、图反转等,以及优化的PregelAPI。
4.1 分布式节点分组算法FUG
为了满足定义2中的条件(3),提出一个节点安全分组条件SGC(safety grouping condition)。若设C是包含k个节点的分组,若分组C满足SGC,则对∀u∈C,∀v∈C,两节点的最短路径长度应满足dist(u,v)≥2。
定理1已知社会网络图G=(V,E,L,δ),C是节点集V中k个节点构成的分组,dist(u,v)表示节点u、v的最短路径长度,若∀u∈C,∀v∈C,满足dist(u,v)≥ 2,则分组C不存在链接。
证明反证法。假设分组C存在链接,则分组C内必存在节点u、v满足条件dist(u,v)=1,这与∀u∈C,∀v∈C,满足dist(u,v)≥2相矛盾,假设不成立,故定理1成立。
基于定理1和模块化社区发现的思想[22],提出一种分布式节点分组算法FUG(fast unfolding of group),基本步骤如下:
(1)初始化,为节点添加分组信息groupid,将节点划分在不同的分组。
(2)节点搜索2-hop邻居,并修改groupid合并分组。
(3)构建新图,新图中的节点是步骤(2)产生的不同分组。
重复步骤(2)和(3),直至构建的新图是完全图,程序结束。FUG算法分为两个阶段(phase),如图3。图3中,圆圈内数字是groupid,花括号内数字是分组所包含的节点(nodeid)。

Fig.3 Fast unfolding of group图3 FUG算法
由图3可以看出,在Phase1阶段,节点搜索2-hop邻居,并修改groupid合并分组,而Phase2阶段则构建新图并进入下一轮迭代。
定理2已知社会网络图G=(V,E,L,δ),对 ∀u∈V,∀v∈V,dist(u,v)表示节点u和v的最短路径长度,v满足v∈{s|s∈V∧dist(u,s)=1},w∈V且w∈{z|z∈V∧dist(v,z)=1},若w是u的2-hop邻居节点,即dist(u,w)=2,则节点w满足:
w∈{g|g∈V∧g≠u∧dist(u,g)≠ 1}
证明反证法。假设节点w不是节点u的2-hop节点,则u、w的关系分为三种情形:(1)dist(u,w)≥2;(2)u=w;(3)dist(u,w)=1。若情形(1)成立,由题设v∈{s|s∈V∧dist(u,s)=1},则dist(v,w)>1,这与w∈{z|z∈V∧dist(v,z)=1}矛盾,故情形(1)不成立;若(2)和(3)成立,则与w∈{g|g∈V∧g≠u∧dist(u,g)≠1}相矛盾,故(2)和(3)不成立。综上所述,假设不成立,节点w是节点u的2-hop邻居节点。□
基于定理2,利用GraphX系统通过两次迭代,节点便能搜索到2-hop邻居节点。第一次迭代,节点向邻居节点发送groupid,收到消息的节点生成1-hop邻居列表;第二次迭代,节点将1-hop邻居列表发送给邻居节点,收到消息的节点遍历列表,依据定理2生成2-hop邻居列表,具体如算法1所示。
算法1搜索2-hop邻居
Input:messages.
Output:The list of 2-hop neighborhood of vertexu.
1.THNList;//初始化2-hop邻居节点列表
2.longstep=getsuperstep();//取出超级步
3.ifstep==0 then
4.for each vertexudo
5.sendMessToNeighbors(vertext.groupid);//超级步为0时,节点发送groupid给邻居节点
6.else ifstep==1 then
7.longneighborhoodlist=getValue(messages);//取出消息,生成1-hop邻居节点列表
8.sendMessToNeighbors(neighborhoodlist);//发送1-hop邻居列表给邻居节点
9.else ifstep==2 then
10.for each message do//处理所有1-hop邻居节点列表
11.if the groupid in messages meet the conditions{groupid≠u.groupid}∧{groupid∉u.neighborhoodlist}
12.THNList←groupid;//添加2-hop邻居列表
13.returnTHNList;
以图1为例,算法1如图4所示。为了便于表述,图中省略了nodeid,仅标出了groupid。
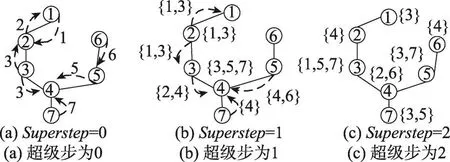
Fig.4 2-hop neighbor search图4 2-hop邻居搜索
当superstep=0时,节点向邻居节点发送自己的groupid,如图4(a);当superstep=1时,节点收到消息后生成1-hop邻居列表,并将列表转发给邻居节点,例如节点2根据消息1和3,生成列表{1,3},并将{1,3}转发给邻居节点,如图4(b);当superstep=2 时,收到消息的节点遍历所收到的列表,依据定理2产生2-hop邻居列表,例如节点4收到列表{2,4},{4}和{4,6},依据定理2,排除1-hop列表{3,5,7}和自身groupid=4,则THNList={2,6},如图4(c)。
从图4(c)可以看出,若随机修改groupid,可能无法合并分组。以3、5、7为例,若3修改为5,5修改为7,7修改为3,此时分组未发生变化。为此,提出一种W&N(will-negotiation)策略。在W&N策略中,节点是邻居节点的“调解人”,如图5(a),节点4是节点3和5的“调解人”,思想是:
(1)节点u从2-hop邻居列表中选出最小的groupid,连同自身groupid以(u.groupid,u.min)形式发送给“调解人”。
(2)若消息存在节点u和v满足:u.groupid=v.min∧v.groupid=u.min,则“调解人”返回(u.groupid,v.groupid)给节点u、v。
(3)节点u、v收到消息后,将自身groupid修改为(u.groupid,v.groupid)中最小的值。
具体如算法2所示。
算法2Group merge
Input:messages.
1.longstep=getsuperstep();//取出超级步
2.ifstep==0 then
3.for each vertexudo
4.longu.min=getMinValue(THNList);//选择最小groupid
5.sendMessToNeighbors((u.groupid,u.min));//节点u发送(u.groupid,u.min)给“调解人”
6.else ifstep==1 then
7.longmergerlist=getValue(messages);
8.if IsExist(u.groupid=v.minandv.groupid=u.min)IN mergerlist then
9.sendMessToNeighbors(u.groupid,v.groupid);//“调解人”返回消息给邻居节点
10.else ifstep==2 then
11.u.groupid=min{u.groupid,v.groupid};//修改groupid
以图1为例,算法2如图5所示。当superstep=0时,节点从2-hop邻居列表中选出最小groupid,并以(u.groupid,u.min.groupid)的形式发送给“调解人”,如图5(a);当superstep=1时,“调解人”判断是否转发消息,例如节点2满足算法第8行,则转发{(3,1)(1,3)}给节点1和3,如图5(b);当superstep=2 时,算法执行第11行,节点3将自身groupid修改为groupid=1,节点4修改为groupid=2,如图5(c)。
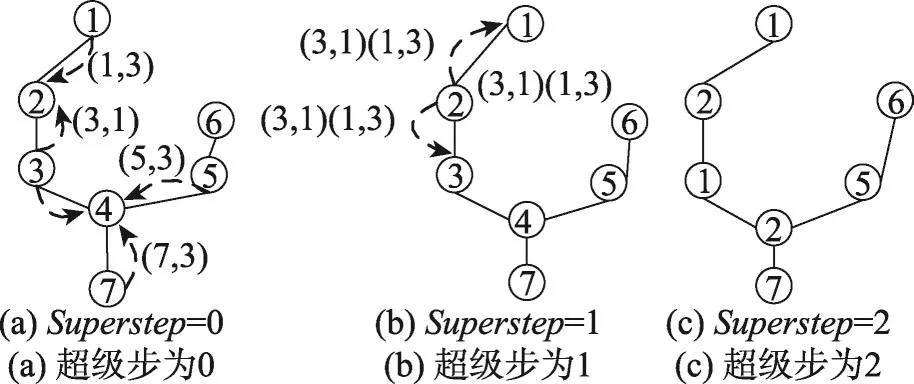
Fig.5 Grouping merged图5 分组合并
由图3可知,在Phase1结束后,FUG算法转入Phase2阶段构造新图,使用RDD(resilient distributed datasets)很方便实现。FUG算法将当前图的边信息<srcid,dstid>保存在edgeRdd。节点的nodeid和相应的groupid信息,以 <nodeid,groupid>的形式保存在groupRdd,然后执行两次leffOuterJoin操作得到新图的边信息,最后通过GraphX系统的Graph.fromEdge-Tuples从新图的边信息后构建出新图,首次构建的新图如图3(c)所示。
如此,经过3次循环迭代,图G的最终分组结果为:group1={1,3,5,7}和group2={2,4,6}。
4.2 分布式k-degree匿名
为了不向分组引入链接,k-degree匿名采用添加节点和边的方式实现,并要求添加的边(u,v)满足条件:u∈V∧v∈V*,其中V*是添加的节点集,而V*中节点的数目可以通过式(1)得出[11]。

其中,k是分组中节点数目,M是最大缺失值。
定理3FUG算法收敛,且当算法收敛时,构建的新图Gn是无向完全图。
证明反证法。(1)假设Gn是无向完全图时,FUG未收敛。根据定义4,在图Gn中,任意节点u和v,满足dist(u,v)=1,由算法1,此时节点u和v转变为InActive状态,FUG算法收敛,假设不成立。(2)假设FUG算法收敛时,图Gn不是无向完全图,由定义4可知,此时图Gn中,存在节点u和v满足dist(u,v)≥2,节点仍处于Active状态,FUG算法会继续执行,未收敛,假设不成立。综上所述,定理3成立。
由于Gn是完全图,节点彼此间可以通信,因此通过GraphX可以很容易地计算出最大缺失值M。节点分组时,FUG算法并未考虑参数k。因此,计算M值时,首先要对4.1节产生的分组进行分割,方法是:将分组节点按度值降序排列,每k个节点划分成一个子分组(subgroup),若最后一个子分组节点数目不足k,则与前一个子分组合并。计算最大缺失值M的步骤如下:
(1)初始化,分组划分成若干子分组,子分组计算subi=|dmax-dmin|,即节点度最大值与最小值的差,令M=max{sub1,sub2,…,subn} 。
(2)superstep%2=0时,发送M值给邻居节点。
(3)superstep%2=1时,节点将消息对比自身M值。若大于自身值,则更新为收到的M值,保持Active状态,否则转为InActive状态。
(4)重复(2)(3),直至节点处于InActive状态。
具体如算法3所示。
算法3Computing max deficiency
Input:messages,k.
Output:Max deficiencyM.
1.Initialization;//初始化,将group划分成若干subgroup,并计算M值
2.longstep=getsuperstep();//取出超级步
3.ifstep%2==0 then
4.sendMessToNeighbors(M);//发送M给邻居节点
5.ifstep%2==1 then
6.longValue=getValue(messages);//取出M值
7.ifValue>M;
8.setM=Value;//更新自己的M值
9.else
10.voteToHalt();//转为InActive状态
11.returnM;
以4.1节产生的分组{5,3,1,7}和{2,4,6}为例,并假设k=2,算法3如图6。初始化时,分组{5,3,1,7}被划分为子分组{5,3}和{1,7},并计算sub1={5,3}=0,sub2={1,7}=0,因此分组{5,3,1,7}相应的M值为0,同理{2,4,6}的M值为2。当superstep=0时,节点处于Active状态并向邻居节点发送值M,如图6(b);当supertep=1时,节点将消息对比自身M值,若大于自身值则更新并保持Active状态,反之转为InActive状态,如图6(c),节点1将M值更新为2,并保持Active状态,而节点2转为InActive状态。最终,得出最大缺失值M=2。
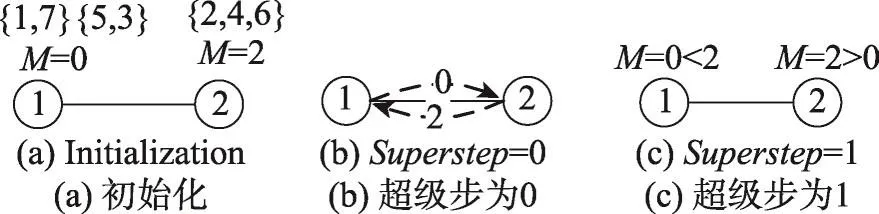
Fig.6 Computing max deficiency图6 计算M值
分组内节点不存在链接,不能通过传递消息确定目标度。因此,为分组创建相应的虚拟节点作为“中枢”,其邻接节点是分组内的各个节点,如图7(a)所示。分组节点与虚拟节点构成二分图结构,两者通过消息传递,经过3个superstep完成k-degree匿名,基本步骤如下:
(1)superstep=0时,分组节点为Active状态,并发送(nodeid,degree)给虚拟节点,其中nodeid是节点的编号,degree是节点的度。
(2)superstep=1时,虚拟节点为Active状态,对分组节点按度降序排列,并令最大度为目标度,计算Δdi和num,Δdi是节点vi要添加的边的数目,num是节点vi前i-1个节点添加边的总数目,发送(vir.id,Δdi,num)给分组节点,vir.id是虚拟节点的编号(vir.id=0,1,2…)。
(3)superstep=2时,分组节点收到消息后,利用参数vir.id、Δdi、num以及k、M添加伪边。方法是:利用式(1)计算添加节点数目N;然后建立Δdi×2的矩阵,矩阵的第0列是节点的nodeid,第1列按行依次写入pesudo[(vir.id+num+X)modN],其中X={1,2,…,Δdi};最后以(nodeid,pesudo[i])的形式将矩阵存入edgeRDD。

Fig.7k-degree anonymity图7 k-degree匿名
具体如算法4所示。
算法4Generate pseudo edge
Input:messages,k,M.
Output:the pseudo edge list ofu.
1.PseudoedgeList←∅ ;
2.longstep=getsuperstep();
3.ifstep==0 then
4.for each vertexudo
5.if isLeft()then
6.sendMessToNeighbors((vertext.nodeid,vertext.degree));//节点发送消息给虚拟节点
7.if step==1 then
8.if notisLeft()then
9.longList=getValue(messages);//取出消息
10.Set max degree as target degree;//设置目标度
11.for every nodeuin List
12.ComputingΔdi、num;//节点计算Δdi、num
13.sendMessToNeighbors(virid,Δdi,num);
14.ifstep==2 then
15.if isLeft()then
16.Add pseudoedge(nodeid,pesudo[i]);//添加伪边
17.returnPseudoedgeList;
以算法3产生的分组{1,7}、{5,3}、{2,4,6}为例,算法4如图7所示。当superstep=0时,分组节点向虚拟节点发送nodeid和度,如图7(a)。当superstep=1时,虚拟节点找出目标度,并为节点计算Δdi和num。以虚拟节点1为例,并假设节点降序排列为{4,2,6},则目标度为3,节点2前一个节点是节点4,则Δdi=(3-2)=1,num=0,故返回消息(1,1,0),同理节点6,Δdi=(3-1)=2,num=0+1=1,故返回消息(1,2,1),如图7(b)。当superstep=2时,分组节点根据消息以及N添加伪边,以分组{4,2,6}为例,节点 2消息为(1,1,0),则(vir.id+num+X) modN=(1+0+1)mod3=2,添加边(2,pseudo[2]),节点6根据消息(1,2,1),依次添加伪边(6,pseudo[(1+1+1)mod3]),即伪边(6,pseudo[0])以及伪边(6,pseudo[(1+1+2)mod 3]),即(6,pseudo[1])。
添加的伪边信息被保存到edgeRDD中,然后通过Graph.fromEdgeTuples操作从edgeRDD构建出包含N个伪节点的匿名图,用8、9、10替换pseudo[i](i=0,1,2),匿名图如图2(b)所示,并且N个伪节点的度为d或(d+1),具体证明请参考文献[11]。
4.3 分布式m-标签匿名
m-标签匿名采用统一标签列表匿名[9],其生成的方法是:假设C是由算法3产生的含有k个节点的分组,p={p0,p1,…,pm-1}是整数序列{0,1,2,…,k-1}的子集,其大小为m(m≤k),对 ∀v∈C,u表示节点v的标签列表,则其统一标签列表由式(2)产生:

以分组{2,4,6}为例,其相应的标签列表分组为{u2,u4,u6},并假设m=2,p=(0,1),则经过式(2)统一列表为:u2={u2,u4},u4={u4,u6},u6={u6,u2}。
分析式(2)可知,利用4.2节的方法很容易实现分布式m-标签匿名,方法步骤如下:
(1)superstep=0,分组节点发送消息(nodeid,labellist)给虚拟节点。
(2)superstep=1,虚拟节点收到消息,根据式(2)为分组节点产生统一标签列表,并将匿名结果返回给分组节点。
(3)superstep=2,分组节点收到消息后,将原有标签列表修改为范化标签列表。
算法5Generate lable list
Input:messages.
1.longstep=getSuperstep();
2.ifstep==0 then
3.for each vertexudo
4.if isLeft()then
5.sendMessToNeighbors((u.nodeid,u.labellist));//节点向虚拟节点发送(nodeid,labellist)
6.ifstep==1 then
7.if notisLeft()then
8.longlist=getValue(messages);//虚拟节点取出消息
9.for vertextuin list do
10.new=(u.nodeid,u.genlabellist);//标签匿名
11.sendMessToNeighbors(new);//虚拟节点向用户节点返回新的标签
12.ifstep==2 then
13.if isLeft()then
14.longAnolabel=getValue(message);
15.setValue(Anolabel);//节点u修改自身标签
以图1为例,并假设m=2,p={0,1},为了便于表述,节点i的标签用ui来表示,则分组{1,7}、{5,3}、{2,4,6}对应的标签分组为 {u1,u7}、{u5,u3}、{u2,u4,u6}。当superstep=0时,分组节点向虚拟节点发送消息(nodeid,labelist),如图8(a);superstep=1时,虚拟节点利用式(2)为分组节点产生统一标签列表,并返回给分组节点,如图8(b);当superstep=2时,分组节点收到消息后,将自身的标签替换成统一标签列表,如图8(c)所示。
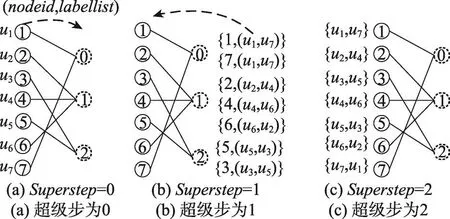
Fig.8 Label anonymity图8 标签匿名
5 扩展的PLRD-(k,m)方法
社会网络中,用户对隐私保护强度具有不同的需求,某些用户甚至不希望隐藏自己的身份,如公众名人[23]。基于同一标准对用户进行匿名保护,不仅会增加匿名成本,还将降低匿名数据的可用性。为此,对PLRD-(k,m)方法进行扩展,提出个性化匿名方法PLRDPA(protecting link relationships distributed personalized anonymity),为用户提供lv0~lv2不同的隐私保护级别。
lv0级:隐私保护级别为0,即对用户的信息不做任何匿名处理。
lv1级:隐私保护级别为1,能够抵抗攻击者通过度信息识别用户身份和链接关系。
lv2级:隐私保护级别为2,攻击者即使拥有节点的度和标签,也无法识别出用户身份和链接关系。
若通过FUG算法进行分组,不同隐私保护级别的节点可能被分在同一组。为此,提出个性化安全分组条件PSGC(personalized safety grouping condition)。设C是包含k个节点的分组,若分组C满足PSGC条件,则:
(1)∀u∈C,∀u∈C⇒u.lv=v.lv
(2)∀u∈C,∀u∈C⇒dist(u,v)≥2
条件1表明同一分组的节点具有相同的隐私保护等级;条件2表明同一分组的节点彼此间的最短路径长度dist(u,v)≥2。因此对算法2做出适当修改以满足PSGC条件,“调解人”判断的条件修改为:
(1)u.groupid=v.min
(2)v.groupid=u.min
(3)u.lv=v.lv
算法3计算M值时,隐私级别为lv0的分组将M值置为0。经过算法2和算法3,对隐私保护级别为lv1的分组利用算法4进行k-degree匿名;隐私级别为lv2的分组,只需要在lv1的基础上执行算法5即可。
6 PLRD-(k,m)方法的安全性分析
PLRD-(k,m)方法的目标是抵抗节点重识别的同时,抵抗标签链接泄露,对算法安全性的分析从这两方面着手。
定理4已知图G*是社会网络图G=(V,E,L,δ),由PLRD-(k,m)生成的匿名图,P是攻击者根据节点的度或标签从G*中识别出目标节点的概率,则概率P满足:1/k≤P≤1/m。
证明(1)若攻击者仅掌握了节点的度,由于G*是k-degree匿名图,对任意节点v存在(k-1)个其他节点与v的度相同,则节点v被识别出的概率为1/k。(2)若攻击者仅掌握了节点v的标签,由算法5,在匿名图G*中存在(m-1)个其他节点包含v的标签,故被识别的概率为1/m。(3)若攻击者同时掌握了节点v的度信息和标签信息,由概率组合知识可知,节点v被识别的概率为1/m。
定理5已知图G*是社会网络图G=(V,E,L,δ),由PLRD-(k,m)生成的匿名图,则图G*不存在标签链接泄露。
PLRD-(k,m)方法包括FUG、k-degree匿名以及m-标签匿名,分析可知,k-degree匿名和m-标签匿名均不会导致标签链接泄露。因此,只需证明FUG算法不会将链接引入分组。
证明每次迭代,FUG算法都要构建新图,用Gi表示第i次构建的图,Si表示图Gi中的节点,由算法1和算法2可知,节点Si是由图Gi-1中互为2-hop邻居的节点u、v形成的超级节点,故节点Si在Gi中的链接关系继承自节点u、v,即u、v在图Gi-1中的1-hop邻居节点,在Gi中转变为节点Si的1-hop邻居节点。因此,FUG算法不会将链接引入分组。
7 实验分析
实验对PLRD-(k,m)隐私保护方法进行性能分析和评价,采用真实社会网络com-Youtube图数据集。com-Youtube图数据集包含1 134 890个节点和2 897 624条边。由于PLRD-(k,m)方法涉及到节点标签而com-Youtube数据集不包含标签信息,因此实验中人工生成节点标签信息。节点的标签包括3个属性:国籍(80个国家)、性别(男或女)、年龄(15~75)。所有的值满足同一分布。为了进行对比,实验同时在单工作站环境实现了PLRD-(k,m)和PLRDPA方法,两种环境如下:
单工作站环境:Intel Core i7-2720QM,CPU 2.2 GHz,16 GB RAM;操作系统,Win 7 旗舰版;编程语言,Python。
集群环境:12台计算节点搭建的集群,Hadoop 2.7.2,Spark1.6.3;CPU 1.8 GHz,16 GB RAM,编程语言,Scala。
其中,PLRD-(k,m)和PLRDPA算法所对应的单工作站版本分别记作PLR-(k,m)和PLRPA。在实现PLRPA和PLRDPA时,实验从数据集中虚拟出10%的节点为lv0级,15%的节点为lv2级,剩余节点则将隐私级别设置为lv1级。
7.1 算法性能分析
7.1.1 运行时间
图9展示了算法随阈值m变化的运行时间对比结果。从图9可以看出,随着m值的增大运行时间随之增大,原因是m值越大,序列p={p0,p1,…,pm-1} 的范围越广,m-标签匿名消耗的时间越多。同时,从实验结果也可以看出,PLRD-(k,m)和PLRDPA算法的匿名开销要远小于PLR-(k,m)和PLRPA,所提出的算法在处理大规模数据上更具有优势。
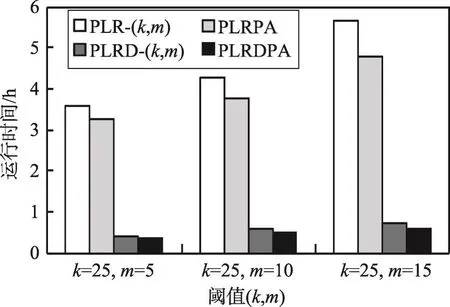
Fig.9 Comparison of run time图9 运行时间对比
7.1.2 加速比和规模可扩展性
相对加速比是指同一并行算法在单个计算节点上运行时间与在多个相同计算节点构成的处理系统上运行时间之比,其计算公式如下:

计算节点的数目从3逐步增加到12,并将数目为3时的运行时间作为T(1),结果如图10所示。可以看出,两种算法均具有良好的加速比,但不是理想的线性加速比,因为随着计算节点数目的递增,彼此间的通信量会随之增多,产生更多的额外开销。
实验通过固定计算节点数目,扩大数据规模并求处理时间比的方法评测算法的扩展性,可扩展性计算公式如下:


Fig.10 Speedup ratio图10 加速比
式中,DB是基础数据集,m×DB是m比例于DB的数据集,T(*)是处理数据集消耗的时间。实验将com-Youtube图数据集等分成5份,然后按1∶2∶3∶4∶5重新聚合成split1~split5,并将数据集split1作为基础数据集DB,然后在集群上处理5个数据集,实验对比结果如图11所示。根据式(4),理想状态下,Scalability的值应不大于比例m,但图12表明,处理split5时,Scalability的值却大于5,原因是受限于CPU的处理能力以及I/O消耗。

Fig.11 Scalability图11 可扩展性
7.2 数据可用性分析
PLRD-(k,m)方法修改了图的结构和节点属性值,因此,实验通过计算图结构信息的损失和查询的准确性来评价算法在数据可用性上的表现。
7.2.1 图结构信息损失
实验通过平均最短路径长度和聚集系数的变化率来评测匿名图G*的信息损失。节点u的聚集系数是指其邻居节点中连接关系所占的比例。图结构信息变化率定义为|G-G*|/|G|,其中G和G*分别表示在原始图和匿名图中的测量值,Error值越小,数据的可用性越好。图12和图13分别显示了匿名图在平均最短路径长度、聚集系数的变化情况。从实验结果可以看出,随着分组中节点数目的增加,匿名后图结构信息的损失率也相对增加。
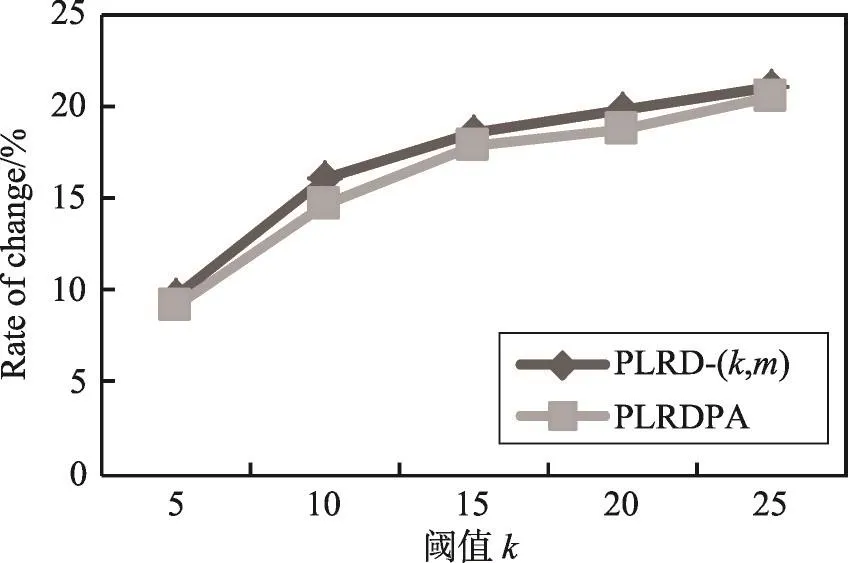
Fig.12 Change ratio of average shortest path图12 平均最短路径变化率
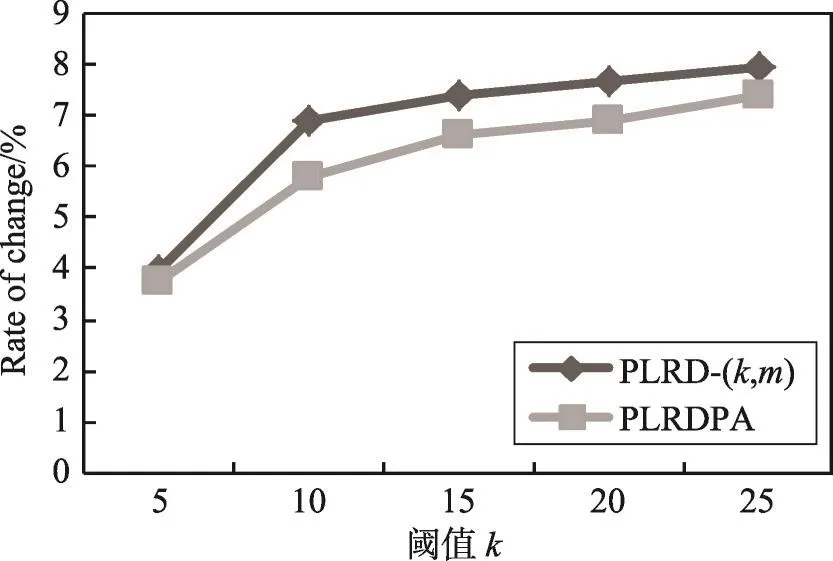
Fig.13 Change ratio of clustering coefficient图13 聚集系数变化率
7.2.2 查询准确性
实验采用文献[9]所提出的单跳查询和双跳查询评测查询准确性,并用相对误差率作为度量标准。相对误差计算公式为|N-N*|/N,其中N表示原始图数据上的查询结果,N*表示匿名图数据上查询结果。实验采用不同的属性进行多次查询,然后计算误差率取平均值。
实验通过单跳查询评测PLRD-(k,m)方法在查询准确性上的表现,并对比PLRDPA方法。实验提出的查询操作为:“在不同年龄段,A国用户和B国用户间存在多少朋友关系”。图14展示了不同阈值对算法PLRD-(k,m)和PLRDPA查询结果的影响。实验结果表明,在阈值参数相同的情况下,相比于PLRD-(k,m)方法,PLRDPA方法的查询误差更低,说明根据用户不同需求,提供个性化匿名保护能够更好地保护数据的可用性。

Fig.14 Relative error of query图14 查询误差率
图15和图16分别展示了参数k对单跳查询、双跳查询的准确性的影响。实验结果表明,随着分组中节点数目的增加,查询误差率随之增大,因为分组中节点数目越多,节点的候选标签数越多,因此导致查询结果的相对误差变大。同时表明,个性化匿名的查询误差率明显更低,能够更好地保护查询准确性。
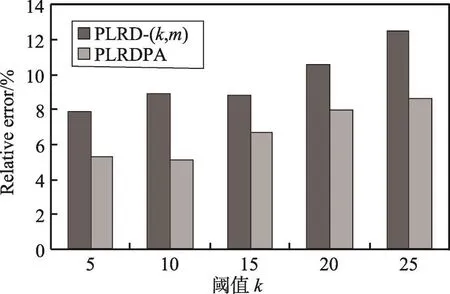
Fig.15 Relative error of single-hop query图15 单跳查询误差率
8 结束语
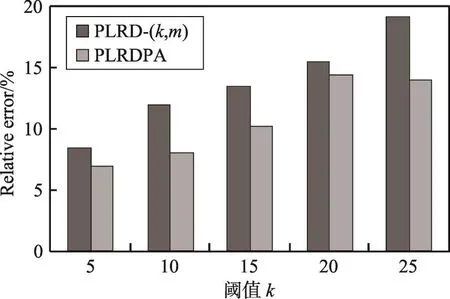
Fig.16 Relative error of dual-hop query图16 双跳查询误差率
目前的隐私保护技术仅针对某一种背景知识,并且随着社会网络规模的逐年递增已不能满足实际需求。为此,提出一种分布式匿名方法PLRD-(k,m),该方法基于GraphX“节点为中心”的特点,将互为N-hop邻居的节点分为一组,并对分组进行k-degree匿名和m-标签匿名,在抵抗重识别攻击的同时保护了链接关系。此外,为了满足个性化需求,扩展了PLRD-(k,m)方法,提出一种个性化匿名方案PLRDPA,允许用户设置不同的隐私级别并提供不同的保护。基于真实社会网络的实验数据表明,所提出的算法能够在提供隐私保护的同时,提高处理大规模数据的效率。
社会网络中,受限于身份的不同,用户在舆论传播过程中具有不同的影响力。匿名社会网络时,往往需要对图结构进行一定程度的修改,很可能导致匿名前后用户的影响力发生重大变化。因此接下来将考虑在匿名社会网络图的过程中保护节点的影响力。
