面向SSD寿命优化的访问序列折叠缓存替换算法*
2019-01-17王吉磊柴云鹏
唐 琪,王吉磊,柴云鹏
中国人民大学 信息学院,北京 100872
1 引言
长期以来,硬盘因具有容量大、价格低、性能稳定的特点而成为最主流的存储介质,新型的瓦记录磁盘进一步提升了磁盘的存储密度和性价比。随着大数据时代的到来,对于存储的性能也提出了越来越高的要求。利用缓存机制来加速硬盘访问的性能也已成为一项愈加重要的技术。
有企业直接将基于闪存芯片的固态硬盘(solid state drive,SSD)作为存储介质。但SSD的写操作的次数是有限制的,如果针对某些单元进行过10万次写操作(SLC(single-level cell)),甚至仅5 000~10 000次(MLC(multi-level cell))[1-2],后续这些单元的写入可能会失效,即闪存的写入的耐久性有限。而且闪存芯片内部固有的写放大现象(即由于擦除和读写操作单位的不匹配引发的额外的数据搬移操作)也加剧了芯片磨损的速度,实际写入大小很可能比用户写入的要大很多[3]。另一方面,并非所有数据都会被经常访问,甚至有些数据可能几乎不会被访问,SSD作为存储介质的高成本很难带来相匹配的收益。
但是在缓存设备方面,SSD相对于DRAM来说,容量更大、成本更低、功耗更低,且具有非易失性,是新一代的缓存介质。将读能力出色的SSD作为磁盘读缓存,是一个加速效果非常明显的方案。将一些会被频繁访问的数据写入SSD缓存,减少CPU进行磁盘I/O访问的次数,以提高硬盘的性能[4-7]。
因此以硬盘作为存储介质,SSD作为其缓存的存储模式是很多大数据存储系统较为理想的选择。但多数缓存算法需要频繁地缓存数据更新,也会导致写入耐久性有限的SSD遇到使用寿命缩短的问题。目前主流的企业级SSD产品,假设预期5年使用寿命,每日只能写入1.38~10.05倍自身容量的数据[8],这对于需要频繁更新缓存数据保持高命中率的缓存来说,是远远不够的。
现有的传统缓存替换算法(如LRU(least recently used))多数基于时间局部性设计,这类方法倾向于选择短期热门数据进行缓存,因此在保证高命中率的同时往往需要频繁的数据更新,会缩短SSD的使用寿命。也有一些改进算法能够减小一部分SSD缓存的写入量,主要的方法随机地禁止一部分数据进入SSD(如L2ARC(level 2 adjustable replacement cache)[9]),或者去掉部分时间局部性差的数据(如LARC(lazy adaptive replacement)[10])。这些方法只是在LRU 等缓存短期热门数据的传统方法基础上,减少一部分数据写入SSD,并没有在数据选择方法上做出本质上的调整,从根本上改善SSD缓存中数据的质量,进而从根本上保持高命中率和减少写入量。
本文提出的访问序列折叠(folded access sequence,FAS)算法能够通过很低的开销识别出长期稳定被访问的数据,通过提高缓存数据的质量来同时减小SSD写入量和保持高命中率。具体来说,FAS算法通过抽样统计的方法,将较长时间内的访问记录在若干个连续的时间窗口内,并通过折叠窗口的方式,统计对各个数据块的访问在多个窗口中出现的次数占总窗口数的比例,将高于一定比值的数据筛选出来。这些数据在一定概率筛选的前提下仍然在多数时间窗口内出现,说明这些数据是比较稳定的长期热门数据,将其写入FAS的白名单中。在白名单中的数据块再次访问时会被允许进入SSD读缓存,反之不在白名单的数据不允许被缓存,这样既避免了频繁的数据更新,也能让高质量的长期热门数据较稳定地保持在SSD缓存中,从而用较少的SSD写入就能达到较高的缓存命中率。
通过一系列基于仿真系统的实验,将FAS算法与一些典型的缓存算法进行比较。FAS算法相对于传统LRU算法可减少90%的写入量,而命中率损失仅不到10%。与SieveStore[11]算法相比,在命中率相当的情况下写入量可减少50%~75%。在命中率高于L2ARC[9]算法的情况下,写入量至少可以减少50%,在局部性较好的情况下,写入量甚至可以减少90%。实验结果表明提出的访问序列折叠算法可有效地提高缓存数据质量,减少SSD的写入量,从而延长其使用寿命。
本文的第2章将介绍现有的相关研究;第3章将介绍访问序列折叠算法的原理;第4章将给出实验结果与分析;最后在第5章进行简要的总结。
2 相关工作
作为硬盘缓存部分的SSD的容量通常较小,需要有高效的替换算法来保证系统的性能。从传统磁盘概念上讲,缓存替换算法主要关注访问的命中率,如LRU、FIFO(first input first output)、LFU(least frequently used)、MQ(multi queue)[12]等。这些算法更倾向于缓存一些短期内访问量较高的数据,当然无法保证缓存的是长期热门数据,因此需要频繁地更新缓存数据。但对于写入耐久性有限的SSD缓存来说,频繁的数据更新会导致SSD寿命缩短,对于存储系统的可靠性和企业运维成本来说都是一项严峻的挑战。
现有的几种针对SSD读缓存的寿命改进的缓存算法主要包括Solaris ZFS所使用的L2ARC[9]算法、LARC[10]算法,以及SieveStore[11]算法。这些算法虽然通过过滤掉部分数据来减少写入量,但并没有提高缓存中的数据质量。下面将分别进行详细的分析。
2.1 L2ARC算法
L2ARC[9]算法是Solaris ZFS中SSD读缓存所使用的缓存算法。所使用的算法是周期性地将内存缓存队列末尾的一部分数据抽样进入SSD读缓存,这些数据仍然属于短期热门数据,但是即将被内存缓存淘汰,因此提前转入容量更大的SSD缓存。抽样的选择方法可以控制和减少SSD的写入量。但在这个过程中,只是完全随机地去掉部分数据,并没有提高长期热门数据的比例。如图1所示,三角形表示按照LRU等景点算法写入SSD读缓存的数据总和,其中好、中、差表示数据的长期热度的高低。L2ARC算法由于是随机筛选数据,因此对于好、中、差数据不做区分,都有一部分进入SSD读缓存,写入情况如图1所示。L2ARC并没有提高好数据的比例,改善缓存数据的质量。

Fig.1 Written block selection of SSD cache under L2ARC图1 L2ARC算法对写入SSD缓存数据的筛选
2.2 LARC算法
LARC(lazy adaptive replacement)[10]算法主要思想是如果一个数据块在较短的时间内被连续多次访问,则被允许进入SSD读缓存;否则不允许进入。这样可以选择局部性最好的一部分数据进入SSD,减少SSD的写入量。LARC主要针对的是数据的时间局部性特征,即将局部热(短期内具有高访问量)的数据写入SSD缓存,写入情况如图2所示。

Fig.2 Written block selection of SSD cache under LARC图2 LARC算法对写入SSD缓存数据的筛选
这样的筛选机制可以在一定程度上提高高数据的比例,但连续两次较近访问只是好数据的一种特征,既不是充分条件,也不是必要条件,会受不同应用的特征影响使其在命中率和写入量减少上的表现差距较大,会遗漏很多长期热门数据,也会将一些短期热门但热度衰变较快的数据写入SSD缓存。
2.3 SieveStore算法
SieveStore[11]算法所采用的方式是设置数据块访问缓存缺失数阈值作为进入SSD缓存的门槛,即访问某数据块的缓存缺失数达到一定次数后运行进入SSD缓存,写入情况如图3所示。这样的机制只去掉了一部分最差的数据(访问次数最少的数据),但中等和最好的数据在这个过程中没有区分,还是有很大的SSD写入量,其中还是有很多较差数据。并且该方法为了记录每个数据块的访问情况,元数据的开销很大,甚至可能无法全部装入内存,需要放到外设中,导致其性能较低。
希望对缓存算法做出的改进是以一种低开销的方式通过对缓存替换设置一定的筛选机制,提高好数据的比例,选择那些长期具有高访问频率,而非短期热门的数据写入缓存数据,从而提高缓存中数据的平均质量。

Fig.3 Written block selection of SSD cache under SieveStore图3 SieveStore算法对写入SSD缓存数据的筛选
3 访问序列折叠
本章详细介绍所提访问序列折叠(FAS)缓存替换算法。
对于写入耐久性较差的SSD缓存来说,为了在保证命中率的同时减少写入量,最理想的情况是找出长期稳定的热门数据来写入SSD缓存,这样的数据热度能够保持较长时间,即访问序列较长,写入缓存后可以提高SSD内的数据质量,不需要频繁更新缓存数据就可以使SSD缓存保持较高的命中率。但是为了找出这些长期热门的“好”数据,需要长期跟踪访问记录来实现,一般来说存储和计算的开销都比较大,很难实际应用。
但实际上,并不需要所有数据的精确访问记录,本文目标只是将图4中访问序列很长的长期热门的“好”数据和其他低质量的数据区分开。因此可以采用较为模糊的方式来维护数据块的访问记录,从而降低计算和存储的开销。

Fig.4 Access sequence distribution of data quality图4 不同质量的缓存数据对应的访问序列长度
具体来说,本文所提出的访问序列折叠算法就是这样一个用较低开销找出长期热门数据的方法。最核心的思想是通过访问序列折叠来用较低开销准确识别长期热门数据(3.1节),其次通过访问抽样方法来进一步减小算法开销(3.2节),并通过白名单机制来进行低频率的缓存数据更新,延长SSD寿命(3.3节)。最后,访问序列折叠算法的复杂度将在3.4节进行分析。
3.1 访问序列折叠思想
长期热门数据的主要特征是访问序列较长,因此会导致两个属性:一是访问总数较多;二是访问分布持续的时间长,在很多时间段上都会有访问。传统的LFU等算法就是抓住第一个特征识别热门数据,但是这样可能有一些短期热门的数据,在短期内有较高的访问量,与长期热门数据会混淆。因此所提出的访问序列折叠(FAS)算法就是利用长期热门数据的第二个特征。
如图5所示,FAS算法维护一个队列记录最近访问的数据块的ID,新来的访问直接写入队列的尾部,而不需要进行高开销的排序操作。当整个队列满了之后,会将其均分为几个时间窗口进行折叠,并统计其中每个数据块在几个时间窗口内出现。例如图5中所示的数据块a,在4个时间窗口中的3个出现,说明a的访问序列较长,覆盖较多的时间窗口,a是长期热门数据的可能性比较大。而数据块d、e、f等在4个时间窗口中只出现1次,说明长期热门数据的可能性比较小。
相对于LFU等算法,FAS算法不需要进行复杂的排序操作,而访问序列折叠这样的复杂操作会间隔较长时间进行一次,计算实时性要求也不高。存储空间则主要取决于记录访问数据块ID的队列长度,但并不需要很长的记录即可识别出长期热门数据。但是,FAS算法针对长期热门数据的第二个特征,更为准确,可以有效减小SSD缓存的数据更新频率,并维持较高的缓存命中率。
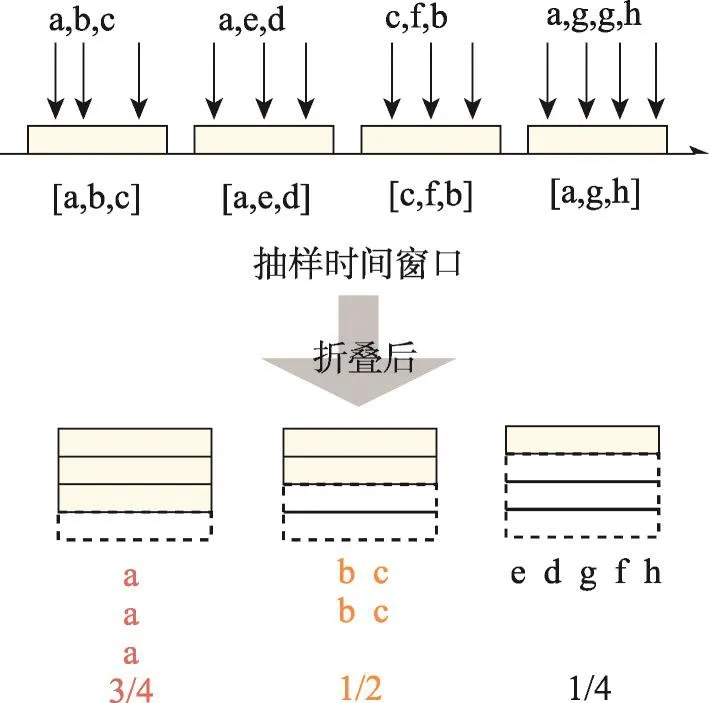
Fig.5 Principle of folded access sequence图5 访问序列折叠原理
3.2 访问抽样与抽样时间窗口折叠
为了进一步减小访问序列折叠方法的开销,数据块进入访问记录队列可以采用抽样的方法,即所有访问以概率p进入队列。这种情况下,可以理解为该队列包括若干个抽样时间窗口,如图6所示。这样可以用更小的空间开销覆盖更长的时间段,提高长期热门数据识别的效果。而长期热门数据由于热度较高,在一个时间窗口内会多次出现,即使进行抽样操作,也会有很大的概率被选中。
如图6所示,所有的缓存缺失,都将以一定概率p进入抽样时间窗口中。假设共有n个分布在时间轴上的时间窗口,每个时间窗口的长度相同,可以记录Lw个访问,每两个连续时间窗口之间的间隔为Ls个访问,即两个窗口之间的Ls个访问没有进入抽样时间窗口的机会,这样可以进一步延长所有抽样时间窗口覆盖的时间长度。
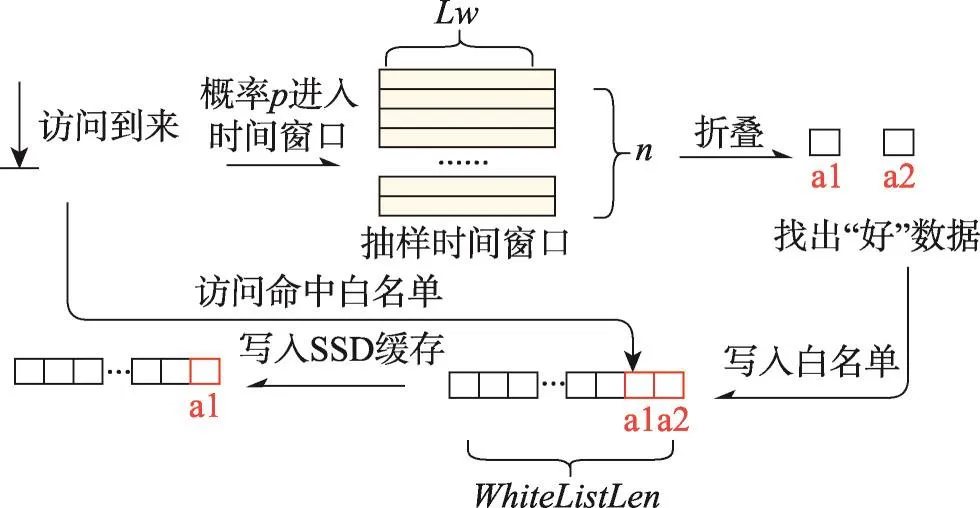
Fig.6 Principle of folded access sequence algorithm图6 访问序列折叠算法原理
假设,某个访问正处于第i个抽样时间窗口,那么它将以概率p进入窗口i。以此类推,对后续的访问进行相同操作直到窗口i填满即窗口中接纳进了Lw个访问,跳过后续Ls个视为在间隙中的访问后,开始下一个窗口的填充。
当一组时间窗口(假设为n个)全部填满后,对这n个窗口进行折叠,即统计出现过的数据块在所有窗口中出现的次数。如果次数达到预先设置的阈值,则视为符合长期热门数据的筛选条件,进入后续的白名单,即白名单中的数据都是被识别出来的长期热门数据。当后续访问命中白名单时,该数据块可以写入SSD缓存。这样既避免了频繁的数据更新,大大减少了SSD缓存的写入量,又保证了缓存中的数据质量和命中率。
总的来说,虽然本文进行了抽样,但由于长期热的好数据拥有高访问频率,进入时间窗口的机会更大,在连续多个窗口中重复出现的概率高。折叠窗口后便可将这些多次重复出现的长期热数据准确识别出来。而有些局部热数据,尽管短期内访问频率高,但由于每个时间窗口内的元素是不重复的,排除了短期内的多次访问的干扰,即差数据或局部热数据是很难在窗口折叠的过程中被筛选出来的。
3.3 低频率数据更新
将时间窗口折叠筛选出的好数据记录在一个长度有限的白名单中,白名单队尾的元素将会被淘汰。当新的访问命中白名单时,对应的数据将被写入SSD缓存,替换掉相对最差的数据。而SSD可以采用多种已有算法进行数据管理(如FIFO、LRU等),在更新数据时,淘汰掉队列尾部同等数量的数据即可。白名单的存在使得不需要产生额外的磁盘访问将数据加载到SSD缓存,而是等待在下一次访问缺失时自然加载。
炉壳采用焊接式钢结构框架,保证焊接的密封性。由于氢气密度小于空气,炉壳进气口设置在上部,排气口设置在下部,在排气口处有长明火咀,工作时将排出的废气点燃,确保设备和工作环境安全。炉口处有水冷套,炉门采用新型结构[2],保证了炉口的气密性。同时,出于安全考虑,在炉顶部设有防爆装置。
值得注意的是,白名单的长度是有限的,满了之后需要进行替换,用LRU算法进行管理。由于长期热门数据也会脱离活跃期,这样可以逐渐从白名单中脱离。
由于填满每个抽样时间窗口需要较长时间,且每次窗口折叠也不一定都能产生很多符合条件的数据,整体上SSD缓存的数据更新并不频繁,低频率的更新能够明显较少写入压力。与此同时,访问序列折叠算法筛选出的数据有较大概率为长期热的高访问频率数据,因此能在低频率数据更新和低开销的前提下,保证较高的数据平均热度和缓存命中率。
3.4 复杂度分析
访问序列折叠算法无论是从时间复杂度还是空间复杂度来讲都满足作为缓存算法负载低的要求。
在时间复杂度方面,对每一个访问,额外的计算开销只是生成一个随机数并判断它是否小于等于给定的概率p值,如果符合便将其放入当前时间抽样时间窗口的集合中。这个操作非常简单,开销很低,时间复杂度为O(1),理论上不会对系统的读写速度产生额外影响。相对于LFU算法,访问序列折叠方法在每次更新缓存队列时不需要进行排序操作,因此能够降低这方面的计算复杂度。
而算法的主要开销是在周期性地进行时间窗口折叠时,这个阶段需要统计n个集合中每个元素出现的总次数,并只留下大于等于M的数据块,时间复杂度为O(Lw×n)。然而这个操作需要间隔很久才进行一次,即等待抽样时间窗口填满,并且没有明确的时间限制需要立即完成,因此可以接受其相对较高的复杂度。
在空间复杂度方面,主要的开销是增加n个抽样时间窗口的集合,集合中每个元素只需要记录访问数据块的编号,整体占用空间很小。此外便是白名单的空间开销,也同样只需要记录数据块的编号,开销同样很小。

4 实验与结果
4.1 实验环境设置
基于Erlang语言实现了一个支持内存缓存和SSD缓存的仿真模拟系统,用于评估访问序列折叠算法的性能,Erlang语言的优势是便于并行计算来提高实验评价的速度。
在系统中实现了多种具有代表性的缓存算法,包括传统的LRU算法,针对SSD写入耐久性改进的算法L2ARC和SieveStore。算法对比是在同样的环境配置下,SSD Cache的大小默认采用Trace覆盖容量的20%,使用SSD缓存的命中率以及SSD的写入量(单位为4 KB的数据块的个数)两个考察指标,来评估所提出的访问序列折叠(FAS)算法与已有算法的差异(实验结果见4.2节)。最后,通过调整访问序列折叠算法的参数来进一步评估该算法,包括窗口长度、折叠比例以及SSD缓存占Trace覆盖容量的比例等(实验结果详见4.3节)。
用于测试的磁盘访问记录如表1所示,其中as2来自UC Berkeley的Auspex文件服务器[13];metanodej和dslct均来自在BigdataBench[14]上运行Hive,其中metanodej为运行join操作时元数据节点上的I/O访问记录,dslct为运行select操作时数据节点上的I/O访问记录;websearch收集自搜索引擎[15]。

Table 1 Real-world traces used for evaluations表1 实验所采用的实际应用中的trace
4.2 缓存算法比较实验结果与分析
如图7~图10所示,将访问序列折叠(FAS)算法与LRU算法、L2ARC算法和SieveStore算法进行比较。可以发现,LRU算法由于没有对写入量进行限制,命中率一般要好于改进型算法L2ARC和SieveStore;但从写入量上看,改进型算法的写入量与LRU相比却是量级上的差距。FAS与LRU在命中率上因不同的磁盘访问记录而异,最多相差17%,但此时的写入量只有LRU算法的1/10;命中率相差不足10%时,写入量是LRU的1/100,甚至在局部性比较好的访问记录(如metanodej)下,命中率相差不足1%时,写入量也减少到LRU算法的1/10,可见FAS能够在保证一定写入量的同时有效减少写入量。

Fig.7 Hit rates and SSD writes under trace as2图7 as2下各算法的命中率及写入量
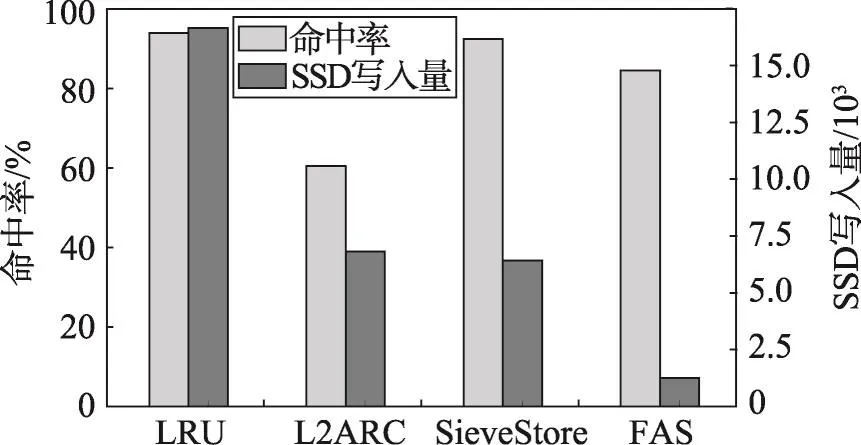
Fig.8 Hit rates and SSD writes under trace dslct图8 dslct下各算法的命中率及写入量

Fig.9 Hit rates and SSD writes under trace metanodej图9 metanodej下各算法的命中率及写入量
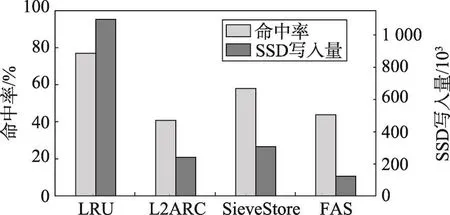
Fig.10 Hit rates and SSD writes under trace websearch图10 websearch下各算法的命中率及写入量
与改进型算法L2ARC相比,对L2ARC进行参数的调试之后发现,若想保持写入量在一个较低的水平,则需要大幅牺牲缓存命中率(30%左右),图7~图10中的结果是其命中率与其他算法相当时,写入量最低的结果。由于随机选择写入SSD的数据,好数据的比例在SSD中并不占优势地位,造成在局部性较好的访问记录中,写入量下降不明显且命中率也不理想的情况,而FAS算法在相同的环境配置下,无论是从命中率还是写入量,性能都优于L2ARC。写入量基本保持在L2ARC的1/10。对于数据读取更为随机的websearch,访问序列折叠算法的命中率略高于L2ARC,但写入量仍明显减小,仅有其1/2。
与改进型算法SieveStore相比,访问序列折叠算法在命中率方面多数情况下比较接近,但是写入量可以减少至少50%。这说明FAS算法选择数据的平均质量更高一些,长期保持热度方面更强一些,因此可以用很少的写入量达到接近的命中率。
4.3 FAS算法参数的影响
本节选用了metanodej和dslct两个用户访问记录,通过调节抽样时间窗口的长度、折叠方式以及SSD缓存的比例,来进一步分析访问序列折叠算法的性能。
如图11、图12所示,当其他参数保持不变,每个抽样窗口长度从10增加至50时,命中率有所提高,但写入量也随之上升。由于折叠方式(访问达到要求时出现频数占总窗口数的比例)不变,窗口长度越小,越难筛选出符合要求的数据块,写入量相对较小,而增加窗口长度后,越符合想要筛选出长期热数据的想法,因此命中率有所提升。搜索范围更广则能够筛选出更多符合要求的数据块,因此写入量也相应有所提升。
另外如图13所示,固定了目标数据块出现频数占统计窗口数的比例为2∶5后,增加统计的窗口数量发现,考察的窗口数越多会使命中率有一定下降,写入量也随之下降。但写入效率(SSD命中数/SSD写入量)随之提高,这是由于统计的窗口数越多,满足条件的数据块越符合长期热数据的特征,写入效率也随之上升。
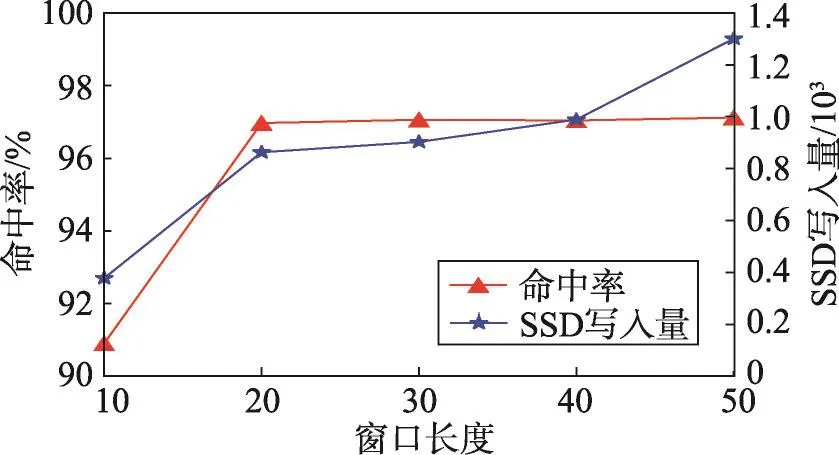
Fig.11 Impact of time window length under trace metanodej图11 metanodej下窗口长度的影响

Fig.12 Impact of time window length under trace dslct图12 dslct下窗口长度的影响
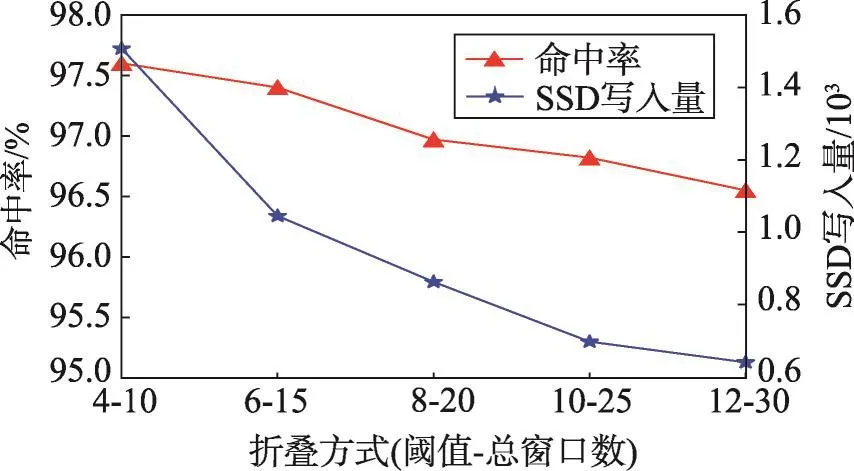
Fig.13 Impact of manner of folding access sequence under trace metanodej图13 metanodej下折叠方式的影响
图14给出了不同SSD缓存空间比例对FAS算法性能的影响,SSD缓存空间与访问数据空间的比例从5%变化到20%。由图14可知,随着SSD缓存空间的上升,命中率在上升,而由于缓存的增加,缓存缺失数目更少,虽然缓存的大小增加会导致SSD缓存在算法启动阶段数据写入增加,但缓存缺失的下降也会导致进入抽样时间窗口的请求变少,SSD内数据更新减小,使得虽然在中间过程中的写入量有所波动,但整体趋势上SSD的写入量会更低。
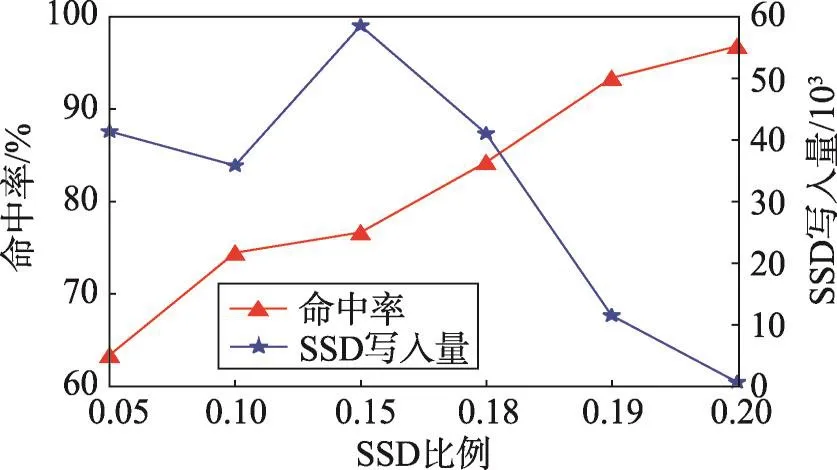
Fig.14 Impact of SSD capacity percentage under trace metanodej and SieveStore on FAS图14 metanodej和SieveStore下SSD缓存空间比例对FAS的影响
5 总结
本文提出了一种面向SSD寿命优化的访问序列折叠(FAS)缓存替换算法。不同于现有基于时间局部性设计的缓存替换策略数据更新过于频繁的缺点,FAS算法旨在以低开销来识别长期热门数据,从而提高缓存内数据的整体质量,在保证一定命中率的同时,减少SSD缓存的写入量。实验结果表明,本文提出的访问序列折叠算法在命中率方面与现有算法相差不大,而写入量的减少大大优于LRU等已有传统算法与L2ARC和SieveStore等面向SSD改进的算法。
