基于LSTM的移动对象位置预测算法*
2019-01-17江国华秦小麟王钟毓
高 雅,江国华,秦小麟,王钟毓
南京航空航天大学 计算机科学与技术学院,南京 210016
1 引言
随着以全球定位系统(global position system,GPS)为代表的定位技术的日趋成熟和普及,通过移动定位设备获取到的移动对象轨迹数据越来越多。位置信息是用户最为重要的上下文信息之一,可为各类服务和应用提供重要支持,如智能交通系统(intelligent transport system,ITS)、智能导航系统、路线规划、推荐系统[1]、公共设施规划[2]和公共安全[3]等。大规模可用性极高的数据和基于位置服务(location based service,LBS)的应用的发展,使移动对象的轨迹信息逐渐成为研究热点。其中,位置预测是基于位置的服务的重要组成部分,提出有效方法以分析和预测移动对象位置具有重要意义。例如,在导航系统中,通过用户的车载GPS记录其历史轨迹信息,挖掘其运动模式并预测用户的目的地,推荐不拥堵的最优路线或尚有空位的停车场。在交通系统中,对城市车辆轨迹的位置预测有助于了解市民的出行规律,提前预知某一时段某一路线的交通状况。在基于位置的信息投递中,通过用户的手持移动设备获取用户的历史签到数据,分析并预测用户下一步的位置,手机应用中的广告推送功能可用此对其进行相关的广告投放。
移动对象位置预测的方法的实现步骤一般为:首先,抽象化真实数据,将地理位置信息和时间信息以易于处理的方式表示;然后,对抽象化后的轨迹数据建模,进一步挖掘其运动模式[4];最后,对当前用户的输入轨迹,根据习得的运动模式,预测该用户下一步最可能到达的位置。
基于移动对象轨迹数据的位置预测问题得到了广泛的研究,其中,应用较为广泛的方法有:马尔可夫链(Markov chain,MC)模型、轨迹频繁模式挖掘和循环神经网络(recurrent neural network,RNN)等。马尔可夫模型通过计算用户位置之间的转换概率建立转移矩阵,以推测下一步最可能到达的位置[5-6]。轨迹模式挖掘通过挖掘频繁模式找出典型运动模式[7]。循环神经网络通过隐藏层神经元的连接性处理序列数据以学习运动模型[8]。
虽然上述方法已经在一些应用场景中得到了很好的效果,但它们针对的都是短时间轨迹序列,没有考虑到过长的历史信息会带来的维数灾难,不能解决长序列轨迹的位置预测问题。用户的轨迹数据会随时间的增长而变多,GPS的采样周期短,收集到的数据多且连续,在学习预测模型前,应对位置序列进行预处理,通过网格化和分布式表示的方法,降低位置向量的维数。并且,传统的方法如轨迹频繁模式挖掘,普遍都是先将原始轨迹按密度聚类,将轨迹线段划分到不同的类簇中,以聚类序列表示轨迹。这虽然能在保证划分意义的前提下缩短序列长度,但基于密度的聚类方法不仅时间复杂度大,而且会忽略聚类区域之外的离散轨迹。
轨迹数据是有时间顺序的时空数据,而神经网络被证明在处理时序数据的数据挖掘和预测方面效果最佳。但历史信息具有时效性,考虑失效的历史信息会产生梯度消失或梯度爆炸问题[9],而忽略有效的历史信息会导致模型精确度下降。长短期记忆网络(long short-term memory,LSTM)[10]被证明是这一问题很好的解决方法。但LSTM也要求输入低维度的向量,否则循环神经网络隐藏层和输入层的神经元之间的全连接属性会导致严重的维数灾难,增大开销,降低模型的学习效率。
针对上述问题,为了对移动对象的时空数据进行更精确的建模从而进一步预测其未来位置,本文提出了位置分布式表示模型(location distributed representation model,LDRM),将难以处理的高维位置onehot向量转化为包含移动对象运动模式的低维位置嵌入向量。在LDRM模型基础上,与基于LSTM的位置预测算法结合为LDRM-LSTM移动位置预测算法。该算法在考虑移动对象行为具有相似性和时效性的基础上,对历史轨迹位置向量进行降维,从而有效提高了预测模型的效率和精确度。
本文的主要贡献如下:
(1)提出了一种位置分布式表示模型LDRM,将难以处理的高维位置one-hot向量转化为包含移动对象运动模式的低维位置嵌入向量。在不忽略移动对象运动规律的同时,有效降低了位置序列数据的维数,提高了训练模型的效率。
(2)考虑轨迹数据的时效性和移动对象行为的相似性,采用LSTM模型作为训练模型,学习一个全局的位置预测模型,提高了长序列轨迹数据的预测精度。
(3)实验所用的GPS轨迹数据为微软亚洲研究院提供的真实数据集Geolife,并使用一系列量化指标来评估预测得到的结果。实验结果证明,与现有的算法相比,提出的LDRM-LSTM算法的预测精度得到了明显提升。
2 相关工作
随着基于位置的服务的发展,移动对象位置预测的工作逐渐成为研究的热点,国内外研究者针对移动对象位置数据挖掘与预测已经展开了相关研究。在移动对象位置预测中,通常的方法是通过移动对象历史数据,预测移动对象的位置。
Koren等人[11]提出了基于矩阵因子分解的方法,通过分解包含地理位置信息的用户行为矩阵判断用户最可能访问的位置。Xiong等人[12]改进了这一算法,通过张量分解(tensor factorization,TF)的方式,同时考虑历史轨迹信息中的地理位置信息和时间信息。上述算法都基于对移动对象历史访问记录的挖掘,没有考虑当前移动对象位置及轨迹,得到的预测精度不高。
Monreale等人[13]提出了WhereNext方法,从历史轨迹数据中提取对象的轨迹模式,借此预测用户频繁访问的位置,同时利用T-pattern tree查询最佳匹配轨迹。Ying等人[14]提出了基于地理和轨迹的语义特征预测移动对象下一时刻位置信息的方法,该方法通过挖掘同类用户的常见行为特性来预测其未来位置。Morzy[15]采用改进的Apriori算法来生成关联规则,并在后来的研究中利用改进的PrefixSpan算法[16]通过移动轨迹序列频繁项集来预测移动对象的位置[7]。然而,频繁轨迹挖掘算法效率低下,数据每次更新都要重新挖掘频繁轨迹,使预测效率降低。
马尔可夫链(MC)模型利用移动对象的历史轨迹预测位置,考虑轨迹的顺序特征,使用马尔可夫链描述移动对象在位置之间的转移概率,Rendle等人[17]提出一种用因式分解转移概率矩阵的方法扩展了MC模型,在时空数据的位置预测上取得了很好的效果。Mathew等人[18]使用隐马尔可夫模型(hidden Markov model,HMM)计算移动轨迹序列中的隐状态来计算移动对象概率最高的下一个位置。但多阶MC模型尤其是高阶MC模型,当数据增加时状态会呈爆炸式增长,转移概率矩阵规模的膨胀增加了预测的复杂度。
近年来,神经网络在数据挖掘与预测中的应用逐渐广泛。在神经网络模型中,RNN最适用于时序数据的预测。Liu等人[8]提出了ST-RNN(spatial temporal-RNN)算法,用移动对象历史时空数据训练RNN网络,预测用户在某个时间点的位置。Al-Molegi等人[19]改进了该算法,其提出的STF-RNN(spatial temporal featured-RNN)算法获得了更好的预测准确率。
然而传统的RNN无法处理大量历史数据的轨迹序列,过多的历史数据会导致参数训练时的梯度消失、梯度爆炸和历史信息损失等问题,改进的LSTM则可以解决这些问题。LSTM在很多领域已经获得了一定的成果,如机器翻译[20]、信息检索[21]和图像处理[22]等方面。Sutskever等人[20]提出了基于LSTM的神经网络语言模型,并运用于自然语言处理方面,实现序列到序列(sequence to sequence)框架用于机器翻译。Malhotra等人[23]将LSTM模型运用于时序数据异常检测领域,解决了无监督环境下采集到非传感器数据从而导致时间序列不可预测的问题,在对不可预测的时间序列和长时间序列的异常检测中,取得了很好的效果。
Wu等人[24]提出了一种基于LSTM的时空语义算法(spatial-temporal-semantic neural network algorithm,STS-LSTM)对移动对象进行位置预测。该算法提出一种特征提取的方法将路网轨迹转化为离散位置点并用LSTM模型进行位置预测,较传统算法精确度有了明显的提升,但该算法并没有考虑到长时间序列的数据压缩问题。
针对以上不足,本文提出一种基于LSTM的移动对象位置预测方法,利用LSTM模型解决长序列的位置预测问题,在学习预测模型前,先对历史数据进行了预处理,使轨迹的时空数据转化为具有上下文信息且维数较低的神经网络输入向量。摆脱了传统位置预测算法的弊端,有效提高了预测精度和效率。
3 算法描述
LDRM-LSTM算法整体框架如图1所示,算法由三部分组成,即用于将轨迹数据转化为位置序列的预处理部分,对高维位置向量进行降维处理的位置分布式表示模型LDRM部分和基于LSTM的根据历史位置序列学习运动模式的预测模型部分。下面将用3节对这三部分进行详细的说明。
本章所用的轨迹数据的符号表示及说明如表1所示。

Table 1 Description of symbol definition表1 符号定义说明
3.1 轨迹数据预处理
移动对象轨迹数据通常由GPS采集。考虑轨迹数据的结构,经过采样生成的一条轨迹可以表示为一系列的位置点的集合。由于采集的点的序列,在时间空间上相对紧密,难以从中挖掘出其运动的模式。如图2中的两条轨迹P(实线轨迹)与P′(虚线轨迹),很难从中发现明显的普遍特征,那么对于大量的如此表现形式的轨迹,就更难挖掘出其中的模式进行预测。因此在移动对象位置预测之前,必须对原始轨迹数据进行预处理。
网格化是研究移动对象轨迹常用的方式,其核心思想是将移动对象所在平面划分为网格,将精确但冗余的经纬度信息转化为抽象的网格信息,以便对移动对象轨迹进行预测。如图2右图所示,通过网格将复杂的轨迹P与P′转化为相同的轨迹L1→L2→L4→L3,更能抽象地表示移动对象的运动过程。
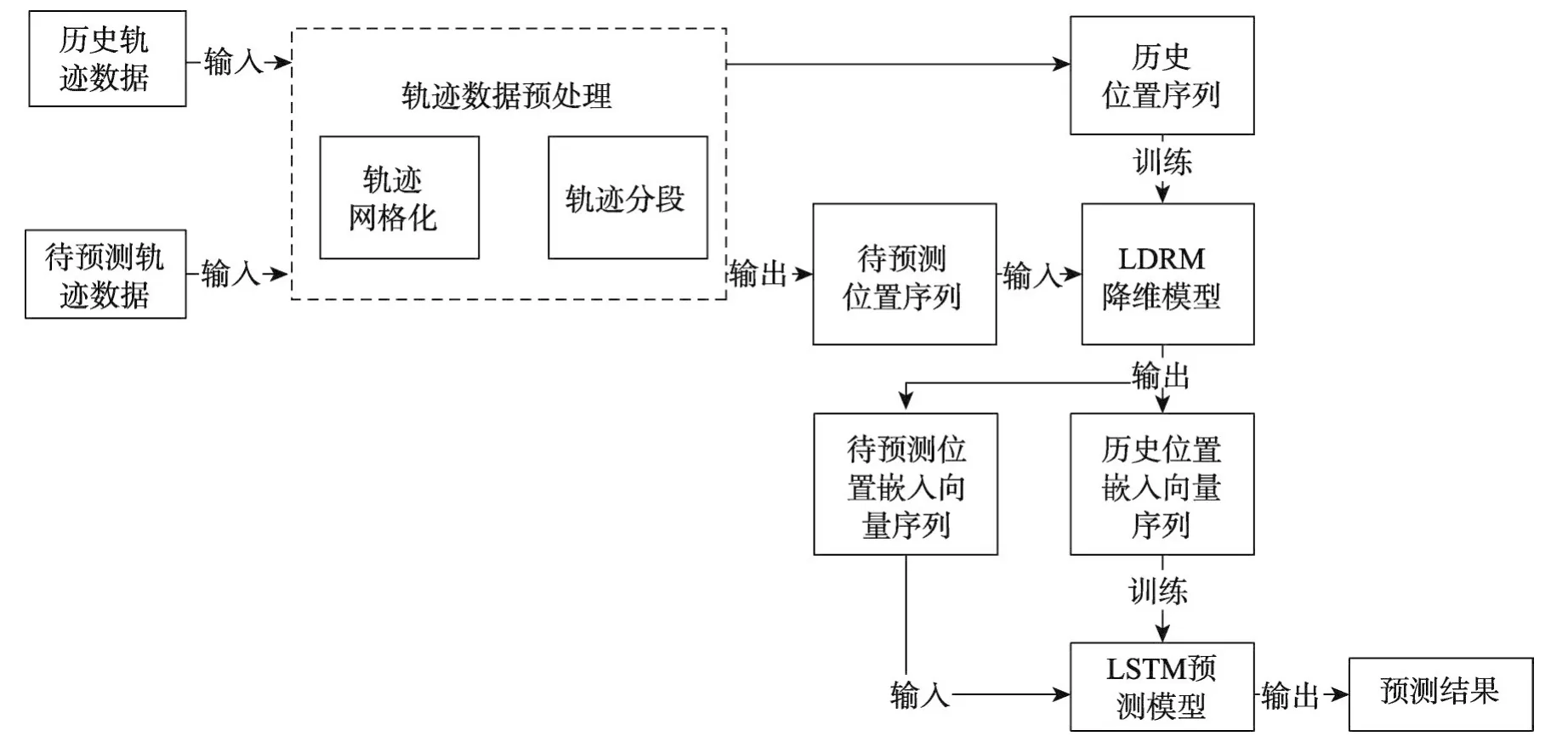
Fig.1 Overall framework of LDRM-LSTM图1 LDRM-LSTM算法整体框架

Fig.2 Trajectory data gridding图2 轨迹数据网格化
采用Geohash编码对轨迹进行网格化。Geohash由Niemeyer提出,最初用于geohash.org服务中,目的是为地球上每一个位置提供一条短URL作为唯一标识[25]。Geohash编码的基本原理是将地球视为二维平面,把该平面沿经度和维度的方向递归二分为更小的子平面,使平面被网格化为子平面的集合,每个子平面在一定经纬度范围内拥有相同的Geohash编码。根据Geohash编码方案,其编码具有唯一性,即Geohash的每个单元网格在地球表面均有唯一空间区域与之对应,这种特性便于对轨迹数据进行无歧义的网格序列化。
使用Geohash编码将轨迹所在地区分为n个网格,第i个网格编码为Li(1≤i≤n),每个网格代表一个位置。由于GPS数据采集的时候可能有误差,有些网格只有极少数轨迹点存在其中,需要将其作为离群点剔除。因此,设计算轨迹经过编号为Li的网格的轨迹点个数为,若大于网格最小有效轨迹点数δ,则将该网格编码Li与来到该网格的时刻ti构成的二元组加入带时间属性的位置序列T,如式(1)所示。

根据式(1),将原始轨迹数据转化为带时间属性的位置序列T。然而,GPS轨迹采集过程通常是连续很长一段时间,导致T过长,并且其中有些二元组之间的时间间隔过大,对位置预测有较大影响。因此,需要通过时间阈值将位置序列T分段。设第k段带时间属性的位置序列Tk={<Lk,tk>,<Lk+1,tk+1>,…,<Lk+l,tk+l>},其中存在时间点ti,有ti+1-ti>γ,则将位置序列Tk分为Ta和Tb两个子序列,用时间点ti分割原序列,分割后的两个子序列Ta={<Lk,tk>,<Lk+1,tk+1>,…,<Li,ti>},Tb={<Li+1,ti+1>,<Li+2,ti+2>,…,<Lk+l,tk+l>},其中,k<i<l。
通过上述算法,将移动对象原始轨迹数据转化为h个位置序列,构成位置序列集合H={T1,T2,…,Th}。同时,构建n个移动对象位置组成的集合S={L1,L2,…,Ln}。移动对象位置预测问题如定义1所示。
定义1(移动对象位置预测问题)设h个历史位置序列组成的历史轨迹集合H={T1,T2,…,Th},当前轨迹为T′={<Li,ti>},0≤i≤t,预测移动对象在t+1所在的位置Lt+1。
3.2 位置分布式表示模型LDRM
将移动对象轨迹数据转化为位置序列后,由于位置信息是离散的Geohash编码,无法直接进行训练,需要将编码转化为向量。通用的离散值转为向量的方法是one-hot编码,即对于n个位置的集合S={L1,L2,…,Ln},对于每一个位置Li,构建一个零向量,将其第i维赋值为“1”,即只有这一位有效,其他位均为“0”。如位置L1的可表示为:(1,0,0,0,…),这个稀疏的向量即为该位置的one-hot编码。这种编码将离散的位置编码转化为向量,解决了模型无法处理离散数据的问题。但是这种编码也存在着问题:(1)在数据量大、不同位置多的情况下,容易受维数灾难的困扰;(2)不能很好地描述位置之间的关系,也不能体现出移动对象的运动模式。
针对one-hot存在的问题,采取分布式表示(distributed representation)的方法,提出了位置分布式表示模型LDRM,将包含位置信息的one-hot编码通过神经网络转化为低维度的含有位置上下文信息的位置嵌入向量(location embedding vector,LEV),避免了由于位置过多带来的维数灾难问题。
移动对象的运动往往存在某种隐藏的规律,即某些移动对象序列会以较高概率出现。设一个长度为N的位置序列出现概率为P=(L1,L2,…,LN),在理想状态下,即移动对象出现在每个位置的概率相互独立时,计算公式如式(2)所示。
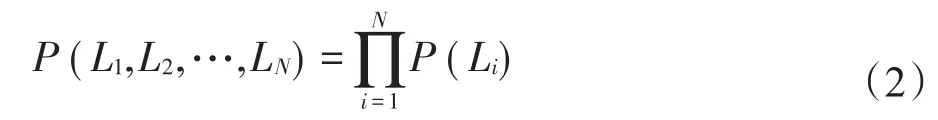
但这样的假设太过理想化,因为移动对象当前位置与其之前位置是相关的。假设在一段位置序列中,移动对象的位置和前t个位置有关,如式(3)所示。
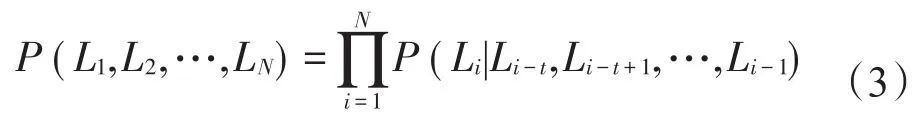
LDRM模型在对位置one-hot向量降维的同时,从轨迹未知序列中挖掘位置之间的关系,使得P(Li|Li-t,Li-t+1,…,Li-1)最大化,从而将序列中的运动模式隐含到位置嵌入向量中。
设移动对象位置序列共有n个位置,则每个位置构成一个n维的one-hot向量l,每个one-hot向量对应一个m维的位置嵌入向量。LDRM模型神经网络结构如图3所示。
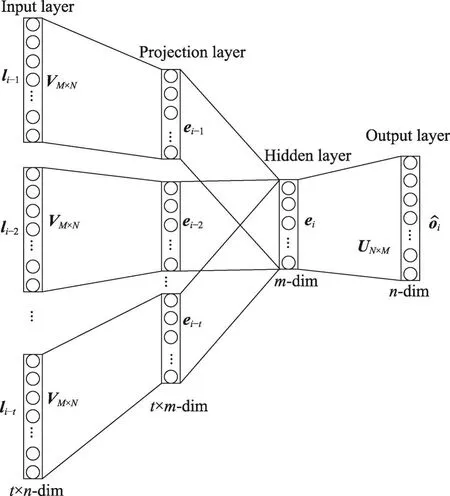
Fig.3 Structure of LDRM neural network图3 LDRM神经网络结构
设当前位置编号为i,对应的one-hot向量为li,和当前位置相关的位置为{li-t,li-t+1,…,li-1}。假设当前存在输入矩阵V∈Rm×n,根据式(4)可计算投影层每个位置嵌入向量{ei-t,ei-t+1,…,ei-1}。

在移动对象位置序列中,不同位置的重要程度不同,比如热门景点、商场、学校、医院等对下一个位置的影响要明显高于一般位置。故给每一个位置根据其在所有轨迹中出现的次数赋予一个权值wi,计算方式如式(5)所示。

将前i个位置的嵌入向量通过式(6)计算出当前位置的嵌入向量ei。

设输出矩阵U∈Rn×m,当前位置的嵌入向量经过输出矩阵的变换成为n维输出向量。输出层将嵌入向量转化为输出向量的计算方式如式(7)所示。

为n维输出向量,理想状态下的输出向量oi应该和当前位置的one-hot向量相等,即oi=li。在这种情况下,该模型的损失函数交叉熵(cross entropy)的计算方式如式(8)所示。
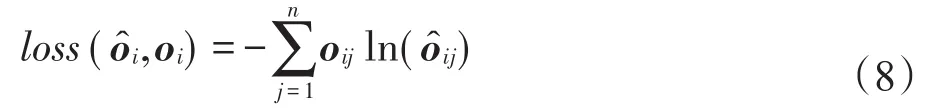
由于模型输出为离散的one-hot向量,若直接使用交叉熵作为目标函数,会造成模型泛化性严重下降。因此,定义该模型的目标函数如式(9)所示。其中,ui为输出矩阵U的第i行,表示li的输出向量。
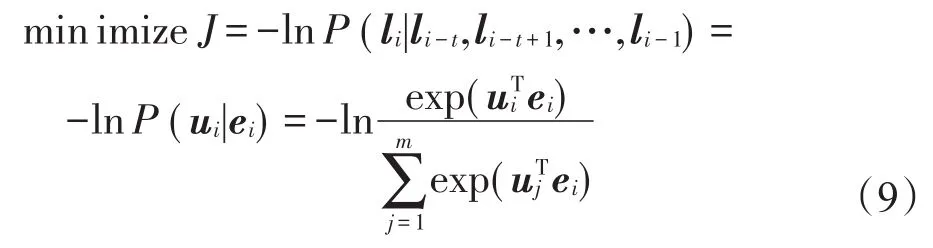
使用梯度下降的方法,计算ui和ei,即可得到矩阵V和U。通过公式e=Vl,即可计算每个one-hot向量对应的位置嵌入向量。位置嵌入向量的总体计算流程如算法1所示。
算法1LDRM算法
输入:每个位置one-hot向量集合Sonehot,轨迹序列集合Strajectory,相关位置数t。
输出:每个位置对应的位置嵌入向量构成的集合SLEV。
1.Trainingset=[];//构建训练数据集及其标签,初始值为空
2.For eachliinSonehot//遍历one-hot向量集合
3.For eachTjinStrajectory//遍历轨迹序列集合
4.IfliinTjand the order ofliisk//如果当前位置在当前轨迹序列中出现,且是当前轨迹序列中第k个位置
5.Thendata={li-t,li-t+1,…,li-1},label=li//当前位置的前t个位置为训练数据,当前位置为标签
6.add{data,label}intoTrainingset//存储训练数据与标签
7.Whileepoch<epochround//当训练未完成时
8.For each{data,lable}inTrainingset//遍历构建的数据集
9.Input{data,lable}into Nerual Network//将数据与标签放入神经网络
10.Calculate functionJ//计算目标函数
11.Backpropagation parameterUandV//反向传播调整参数U和V
12.For eachliinSonehot
13.ei=U∙li//对于每一个one-hot向量,计算对应的位置嵌入向量
14.AddeitoSLEV//存储计算结果
算法1计算了每个位置one-hot向量构成的位置嵌入向量。计算过程分为三个主要部分:首先通过遍历位置one-hot向量集合和轨迹序列集合构建训练集;然后使用该训练集训练LDRM神经网络参数U和V;最后通过该参数计算每个位置的位置嵌入向量。
3.3 基于LSTM的位置预测算法
LSTM模型是一种RNN的变型,由记忆单元(memory cell)和多个调节门(gate)组成。LSTM使用记忆单元的状态(state)来保存历史信息,使用输入门(input gate)、输出门(output gate)和遗忘门(forget gate)来控制记忆单元。利用调节门来选择信息,可表示为y(x)=σ(Wx+b),其中W表示权重矩阵,b表示偏移向量。由于传统的RNN展开后相当于多层的前馈神经网络,层数对应于历史数据的数量,过多的历史数据会导致参数训练时的梯度消失、梯度爆炸和历史信息损失等问题,在处理大量历史数据的预测问题上,LSTM被证明比RNN具有更好的表现。
LSTM的单元结构如图4所示,设xt、ht为t时刻的输入和输出数据,i、f和o分别为输入层、遗忘层和输出层,Ct为t时刻记忆单元的状态值。LSTM单元的更新可分为如下几个步骤。
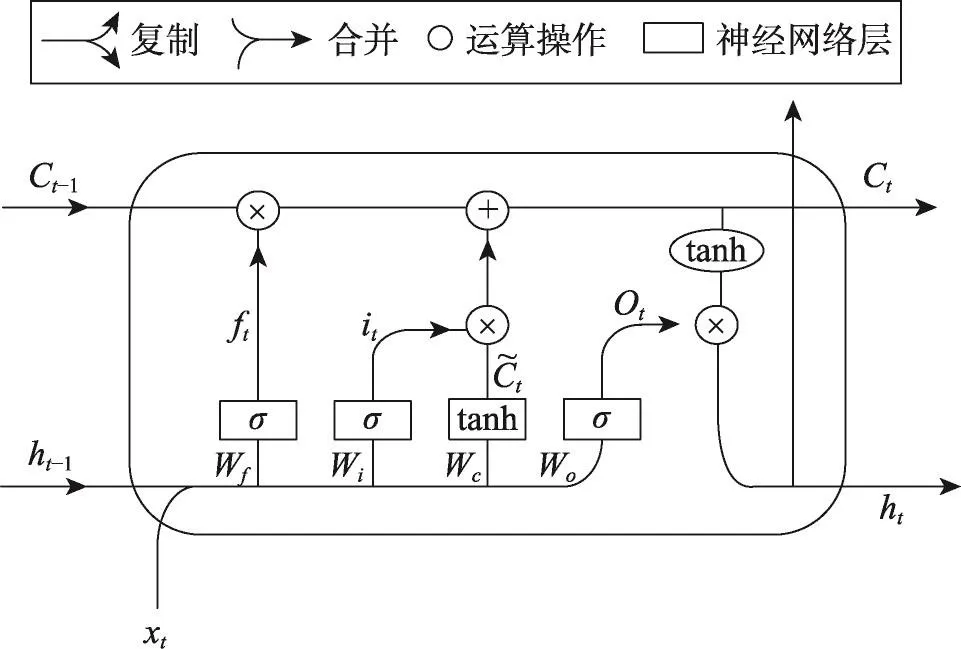
Fig.4 Structure of LSTM network图4 LSTM单元结构图
(1)决定从上一状态中丢弃什么信息。遗忘门是用于控制历史信息对当前记忆单元状态值的影响的,因此通过遗忘门来计算ft,如式(10)所示。其中Wf表示遗忘门的权重矩阵,bf表示遗忘门的偏移向量。σ是logistic sigmoid激活函数,取值在(0,1)之间,1表示“全部保留”,0表示“全部丢弃”。

(2)决定什么信息被存入当前状态中。输入门是用于控制当前输入对记忆单元状态值的影响的,因此通过输入门来计算it,如式(11)所示。按照传统的RNN公式计算当前时刻的候选记忆单元值C͂t,其中函数tanh的取值范围在(-1,1)之间。
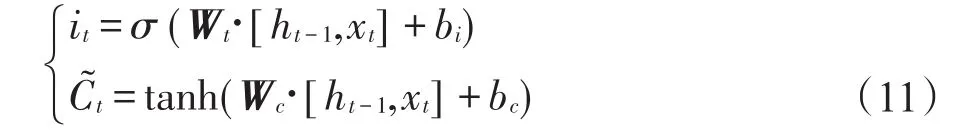
(3)决定好丢弃和更新什么信息后,执行记忆单元的更新,计算当前时刻记忆单元的状态值Ct,如式(12)所示,⊙是点乘运算。

(4)确定输出值。输出门用于控制记忆单元状态值的输出,用sigmoid函数计算决定输出的部分,如式(13)所示。将通过tanh函数处理的记忆单元状态与结果ot相乘,得到LSTM单元在t时刻的输出ht。
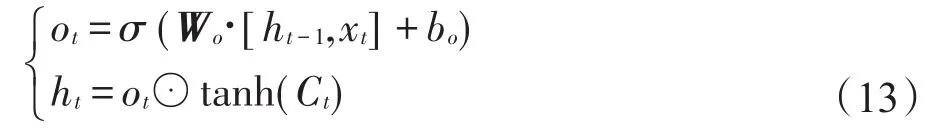
经过LSTM根据训练数据调整神经元之间的权重的学习过程[26],得到一个全局的位置预测模型。通过上述门控机制,LSTM解决了RNN处理长序列容易发生的梯度消失、梯度爆炸和历史信息损失等问题,在移动对象位置预测方面有更好的表现。
使用LDRM模型对位置序列进行降维后,难以处理的高维one-hot向量被转化为低维度的含上下文信息的位置嵌入向量,从而使得基于LSTM的位置预测算法可以更好地处理移动对象位置预测问题。
设降维后的位置嵌入向量集合为SLEV={e1,e2,…,en},则移动对象位置序列可以转化为由嵌入向量组成的序列。但放入LSTM模型中的每个序列的长度必须相同,因此采取滑动窗口的方式,将所有的轨迹转化为可训练的固定长度的输入与输出样本集,如图5所示。
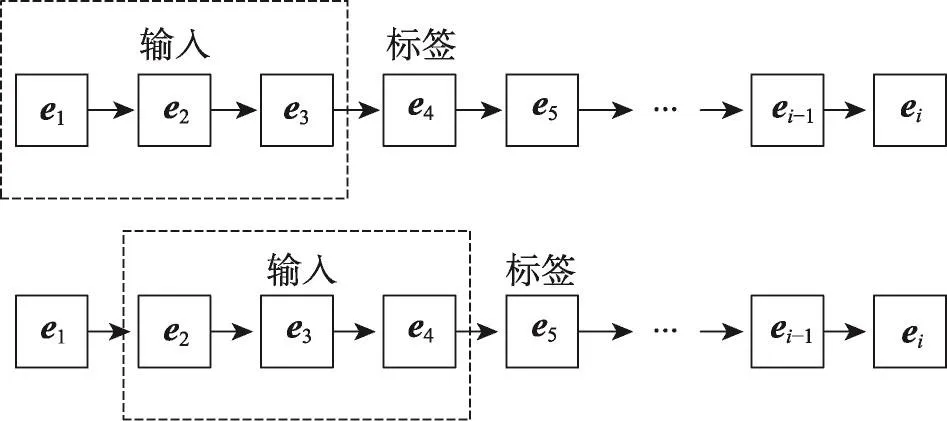
Fig.5 Generate sample set using sliding window method图5 滑动窗口法生成样本集
将经过LDRM模型降维的历史位置嵌入向量作为LSTM模型的输入,训练出针对移动对象位置预测问题的LSTM模型。将待预测位置嵌入向量序列输入模型得到输出向量eoutput,将eoutput与E中所有位置嵌入向量计算欧式距离,与eoutput距离最小的位置嵌入向量即为预测结果eresult。模型的位置预测结果即为eresult对应的位置one-hot向量lresult。
算法2LSTM位置预测算法
输入:位置嵌入向量集合SLEV,轨迹序列集合Strajectory,待预测位置序列Ttest。
输出:预测结果的one-hot向量lresult。
1.Trainingset=[];//构建训练数据集及其标签,初始值为空
2.For eachTiinStrajectory
3.For slide windowTs={la,la+1,…,lb}inTi//通过滑动窗口方式构建子序列
4.Extractdata={ea,ea+1,…,eb-1l},abel=ebfromTs//将子序列中one-hot向量转化为位置嵌入向量,并构建训练数据与标签
5.Add{data,label}toTrainingset//保存训练数据与标签
6.Whileepoch<epochround//当训练未完成时
7.For each{data,lable}inTrainingset
8.Input{data,lable}into LSTM neural network//将训练数据与标签输入LSTM网络
9.Calculate bias function of LSTM//计算误差函数
10.Backpropagation parameters//反向传播调整网络参数
11.InputTtestinto LSTM Network get result embedding vectoreoutput//将测试数据输入网络得到输出的位置嵌入 向量
12.For eacheiinSLEV
13.Finderesult=ei,for which distance ofeiandeoutputis minimum//在位置嵌入向量集中寻找距离最近的向量
14.Output correspondinglresultoferesult//将距离最近的向量转化为one-hot向量并输出
LSTM位置预测算法的流程如算法2所示。首先通过滑动窗口将轨迹数据分割并转化为训练集。然后通过训练集训练LSTM神经网络,最后将待预测轨迹输入LSTM神经网络中,得到输出的位置嵌入向量,并筛选与该向量距离最近的位置嵌入向量,该向量对应的位置即为预测的位置。
由算法1与算法2可见,LDRM-LSTM算法采用了离线训练在线预测流程结构,即在预测前将模型参数训练完成,在预测时仅需要计算预测结果即可。这种方式的优点为将耗时操作在预测前完成,预测时的时间复杂度极低。本文中,LDRM降维模型和LSTM预测模型均由历史轨迹数据离线训练得出,在进行轨迹数据预测时只需将待预测轨迹数据进行预处理后输入模型即可得到预测结果,具有很强的实用性。
4 实验与分析
4.1 实验数据与环境
为了验证移动对象位置预测算法的预测准确性,使用微软亚洲研究院的Geolife project数据进行测试。该数据集包括182个用户5年间(从2007年4月到2012年8月)的运动轨迹数据。数据集覆盖中国、美国和欧洲的不同城市,大部分数据是在北京采集的。轨迹数据数量为18 670条数据,覆盖长达50 176 h的时间和1 292 951 km的距离。轨迹是通过带GPS功能的手机采集而来,每隔1到5 s采集一次位置数据。轨迹信息中包含经纬度、时间等信息。
实验操作系统为ubuntu14.04(64 bit),CPU为Intel Core i5-3470,内存为16 GB,显卡为NVIDIAGTX970,实验代码用python编程语言实现。
4.2 预测评价标准
定义2绝对预测精度(absolute precision,AP)即预测结果和真实结果的差距。设共有K个测试样本,第i个样本的预测结果为pli,真实结果为li。绝对预测精度分数ScoreAP如式(14)所示。

由于绝对预测精度的要求较为苛刻,无法对算法在预测不完全精确的情况下的预测结果优劣进行比较。因此实验同时使用相对预测精度来进行预测精度度量。
定义3相对预测精度(relative precision,RP)即在预测不完全精确的情况下,对预测偏离度进行量化度量的一种精度,计算方式如式(15)所示[27]。

由于每个位置是大小相等的网格,因此可以将每个网格视为坐标轴上1×1的单元格。故式(15)中的距离函数dist采用曼哈顿距离计算两个网格之间的距离。在预测结果非绝对精确时,设定相对预测精度可以通过其与真实位置的距离偏差来选择相对精确的预测点,ScoreAP越低,表示预测精度越高。
4.3 轨迹数据预处理与样本集生成
从原始数据中,提取出在北京的13 101条轨迹,使用6位Geohash编码对轨迹进行网格化(约600 m×600 m网格),共生成14 777个不同的位置。将经纬度轨迹转化为位置序列并分段,设分段时间阈值为30 min,位置包含最小有效轨迹点数为10。
通过上述方式,将原始轨迹转化为21 740条位置序列。对提取出的位置序列,使用滑动窗口的方式生成样本集。设滑动窗口长度len=8,滑动步长step=3,除去长度小于len的位置序列后,得到69 537个样本,随机取其中的5 000个样本作为测试集,其余数据作为训练集。轨迹预处理的参数选择总结如表2所示。
4.4 LDRM模型性能分析

Table 2 Parameters of trajectory preprocess表2 轨迹预处理参数
通过预处理与样本集生成,将原始Geolife数据转化为轨迹位置序列训练集与测试集。在进行预测之前,需要使用轨迹位置序列训练集对LDRM位置降维模型进行训练。由于数据集中存在14 777个位置,即输入的位置one-hot向量的维度n=14 777。设LDRM降维得到的位置嵌入向量的维度为m。位置嵌入向量维度m对预测结果有较大影响,过大的位置嵌入向量维度仍然会导致一定程度的维数灾难问题,过小的位置嵌入向量维度会造成大量的信息在降维中损失,都会导致预测维度下降。因此,将m的取值范围预设为50到500,步长为50。通过对训练集进行交叉验证计算绝对精度与相对精度,计算m的取值对LDRM-LSTM位置预测算法的效果的影响,实验结果如图6和图7所示。
由图6和图7可见,位置嵌入向量在100~150维之间时,预测结果与真实结果的绝对差距最小,相对偏离度最小,即绝对精度和相对精度均达到最佳,预测效果最好。由于绝对精度与相对精度相比更为重要,因此取绝对精度最高的100维作为降维后位置嵌入向量的维度。为了方便观察嵌入向量空间分布,将位置嵌入向量经过主成分分析(principal component analysis,PCA)降维到二维后,部分位置嵌入向量在二维向量空间中的分布如图8所示。每个位置点上的标签为各自的Geohash编码,图中越接近的两个空间向量,代表其在运动轨迹中越相关。
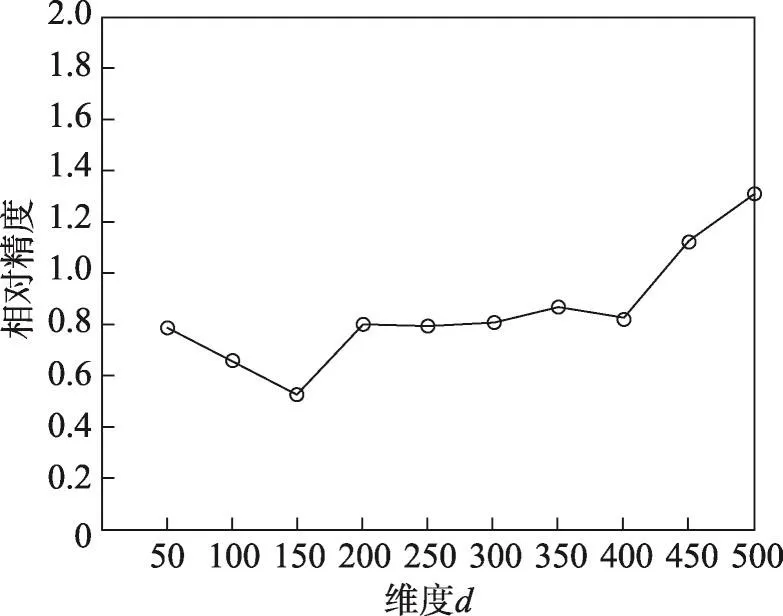
Fig.7 Relative precision of LDRM-LSTM in different dimensions图7 不同维度下LDRM-LSTM预测的相对精度

Fig.8 Graph of location embedding representation图8 位置嵌入向量空间分布示意图
4.5 LSTM位置预测算法结果与分析
在确定了最优的嵌入向量维度并在将训练集与测试集中位置序列均转化为位置嵌入向量序列后,使用训练集中降维后的位置嵌入向量序列对LSTM神经网络进行训练,再使用训练后的模型对测试集中的待预测的位置嵌入向量序列进行位置预测。将预测结果与真实值相对照,计算绝对精度与相对精度,并与HMM、MC、XGBoost(extreme gradient boosting)[28]、LSTM以及STS-LSTM等现有算法在同一样本集上进行对比。这些算法均为离线训练在线预测算法,离线训练时间和参数相关,在线预测时间复杂度几乎一致。实验结果如表3所示。

Table 3 Results of location prediction表3 位置预测结果
由表3可见,LDRM-LSTM算法的绝对预测精度和相对预测精度远远高于未采用降维算法的LSTM模型,证明LDRM降维模型较好地解决了维度灾难问题。同时,LDRM-LSTM预测绝对精度和相对精度均高于所列出的经典位置预测算法,说明在解决长序列位置预测的问题上,LDRM-LSTM算法可以克服现有算法存在的弊端,得到较好的预测结果。
5 结束语
移动对象位置预测与运动模式挖掘一直是研究的热点,可为各类基于位置的服务和应用提供重要支持,如智能交通系统、智能导航系统、路线规划等,具有很高的实用性和现实意义。传统的基于Markov概率模型的位置预测算法和基于神经网络的位置预测算法无法处理位置过多带来的维数灾难问题。提出了LDRM模型,通过神经网络挖掘移动对象轨迹数据中的隐含规律,将原始的高维one-hot向量转化为低维度的位置嵌入向量,再通过基于LSTM的移动对象位置预测算法进行位置预测。实验证明本文提出的LDRM-LSTM算法预测准确率高于经典的MC、HMM、RNN及XGBoost等算法。同时,算法采用离线训练在线预测的流程结构,使用历史数据训练的模型进行位置预测,在实际应用中有较高的价值。
