基于决策树技术对学生未报到原因的分析
2015-12-06傅振南
傅振南
(福建教育学院,福建 福州 350025)
近年来随着我国高等教育改革的不断深化,高校招生规模不断的扩大,招生政策也发生了很大的变化,特别是政策取消了对已录考生不报到但不要求其承担任何责任且可参加下次高考基本不作任何限制,随之而来的问题是已录取新生报到率显著降低,特别是对于高职高专院校。这不仅会浪费国家教育资源且浪费学校的招生计划,增加学校招生成本甚至严重影响学校正常教学秩序。有效分析学生未报到原因并采取针对性措施,提高新生的报到率已成为高职高专院校迫切需要研究和解决的问题,下面利用决策树工具对学生未报到原因进行分析。
决策树和决策规则是解决实际应用中分类问题的成熟数据挖掘方法。决策树工具能够创建一个模型用于预测一个离散的字段(类),可以用一个树型结构描述产生的模型,同时可以从模型中提取重要的规则,分析对分析领域产生影响的重要原因。

图1 决策树数据挖掘过程
一、决策树数据挖掘过程
图1显示了决策树数据挖掘的完整过程。研究表明在整个数据挖掘项目中,数据预处理步骤约占整个项目时间预算的60%到80%,因为现实世界中数据大体上都是不完整,不一致的脏数据,无法直接进行数据挖掘,或挖掘结果差强人意,在预处理阶段,必须根据分析的实际情况选择高质量的数据才能够进行有效的数据挖掘,以便得到有用的信息。此过程采用数据挖掘中的 ID3决策树算法对录取学生的未报到原因进行建模,以找出学生被录取但未报到的原因,以采取相应的措施降低未报到率,提高学校的办学竞争力。
二、ETL(Extract-Transform-Load)过程
(一)选择相关的字段
根据决策树分析的需求,从作者所在高校的近年普通高职录取数据库中抽取相关的数据,包括录取考生的投档单表、专业计划代码表、名称表等。另外整理了作者所在高校自己的招生统计数据(以学生为实验单元的数据集)。从录取学生的数据集中抽取一下字段的数据:考生类别名称、地区名称、考生奖励或处分、成绩、录取专业名称、第一志愿专业名称等6个字段。另外根据招生统计数据中的各个专业投档计划人数和计划招生人数的比例来粗略衡量该专业的热度,产生专业热度代码表。同时清除地区名称中三条值为NULL的记录。
(二)产生衍生字段
根据分析目的的需要,本方案从选择的6个字段衍生出新的符合分析的字段。最终的衍生字段为所在地区、综合素质、是否第一志愿录取、成绩、应届还是往届、农村还是城镇、录取志愿的相对热门度、是否报到等8个字段。具体的衍生过程如下:将地区名称离散成具有本地和外地两个属性值的所在地区字段;由于收集数据的欠缺,粗略地通过考生奖励或处分字段(都是保存奖励的情况)评估综合素质;对成绩连续型属性值进行离散成高,中,低三个属性值;从考生类别衍生应届还是往届、农村还是城镇两个字段;通过比较录取专业名称和第一志愿专业名称来衍生是否第一志愿录取字段;从(一)中专业热度代码表中获取专业的热度,并将其离散化。以上的几个字段都是非类别属性,由于决策树等分类算法必须具有一个类别属性,在本方案中采用是否报到属性作为类别属性,来评估考生是否报到的情况,主要从未报到的学生考生号来确定学生的报到情况。
具体的操作,可以通过SQL存储过程来完成,代码如下,文字部分为注释:
CREATE PROCEDURE stu AS
--声明衍生字段变量名
DECLARE @kslb_yw VARCHAR(50)--应届还是往届
DECLARE @kslb_nc VARCHAR(50)--农村还是城镇
DECLARE @dq VARCHAR(50)--所在地区
DECLARE @zhsz VARCHAR(50)--综合素质
DECLARE @sfdizylq VARCHAR(50)--是否第一志愿录取
DECLARE @lqzyrd VARCHAR(50)--录取志愿的相对热门度
DECLARE @cj_l VARCHAR(50)--成绩
DECLARE @sfbaodao VARCHAR(50)--是否报到
--声明中间变量名
DECLARE @ksh VARCHAR(50)
DECLARE @kslbmc VARCHAR(50)
DECLARE @cj FLOAT
DECLARE @dqmc VARCHAR(50)
DECLARE @ksjlhcf VARCHAR(50)
DECLARE @pcmc VARCHAR(50)
DECLARE @klmc VARCHAR(50)
DECLARE @lqzy VARCHAR(50)
DECLARE @zy1 VARCHAR(50)
DECLARE @baodao INT
--声明训练集的数据表
DECLARE @stu TABLE
(
kslb_yw VARCHAR(50),
kslb_nc VARCHAR(50),
dq VARCHAR(50),
zhsz VARCHAR(50),
sfdizylq VARCHAR(50),
lqzyrd FLOAT,
cj VARCHAR(50),
sfbaodao VARCHAR(50)
)
--声明获取基本学生数据的游标,shsj为学生数据表
DECLARE cursor_shsj CURSOR FOR SELECT ksh,kslbmc, dqmc, cj, ksjlhcf, pcmc, klmc, lqzy, zy1 FROM shsj
--打开游标
OPEN cursor_shsj
--获取每条记录的各个属性值
FETCH NEXT FROM cursor_shsj INTO @ksh,@kslbmc,@dqmc,@cj,@ksjlhcf,@pcmc,@klmc,@lqzy,@zy1
WHILE (@@FETCH_STATUS=0)
BEGIN
--应届还是往届/农村还是城镇
SET @kslb_yw = RIGHT(@kslbmc,2)
SET @kslb_nc = LEFT(@kslbmc,2)
--离散地区字段
IF LEFT(@dqmc,2)=’福州’
BEGIN


--生成专业热度
DECLARE @lqzyrd_l FLOAT
SELECT @lqzyrd_l= tdlq FROM ZYRD WHERE zymc=@lqzy and pcmc=@pcmc and klmc=@klmc

--生成类别属性:是否报到字段,ksh表保存的是未报到考生的考生号

INSERT INTO @STU VALUES (@kslb_yw,@kslb_nc, @dq, @zhsz, @sfdizylq, @lqzyrd, @cj_l,@sfbaodao)
--获取下一条记录
FETCH NEXT FROM cursor_shsj INTO @ksh,@kslbmc,@dqmc,@cj,@ksjlhcf ,@pcmc ,@klmc ,@lq zy ,@zy1
END
CLOSE cursor_shsj
DEALLOCATE cursor_shsj
--生成训练集表
SELECT * INTO stu FROM @stu
GO
(三)ID3数据挖掘
经过数据预处理步骤后产生适合决策树 ID3算法的带有标签训练集合,部分训练集合数据见表1。
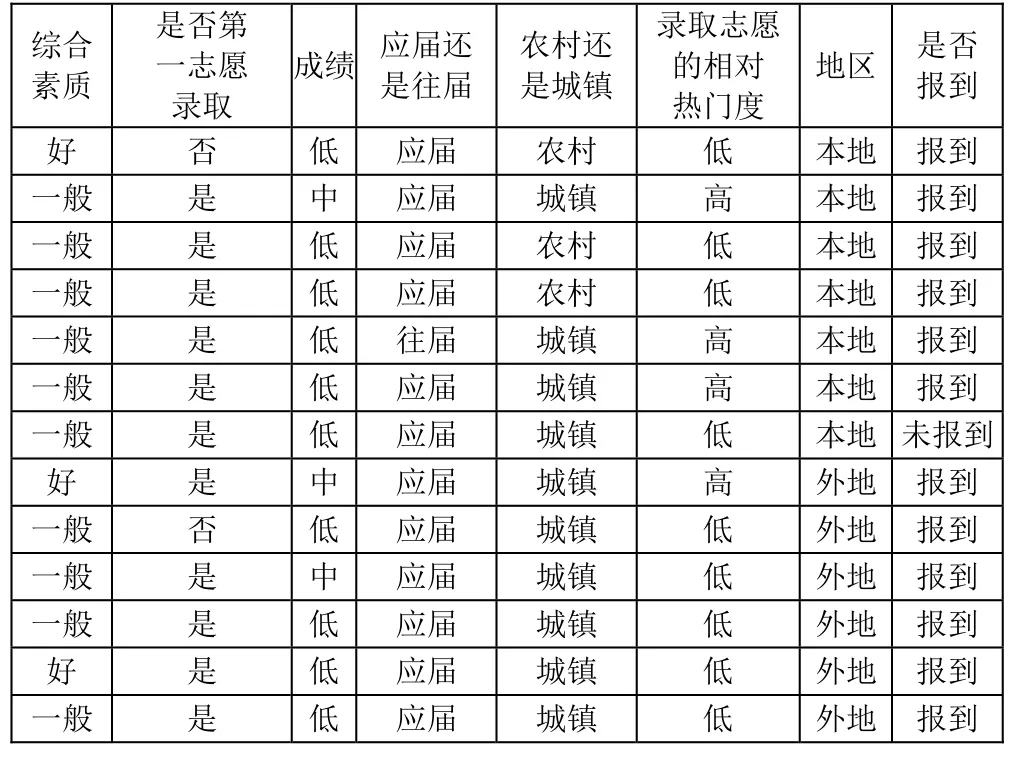
表1 部分的训练集数据
运用决策树算法 ID3对产生的训练集进行训练产生决策树,即检查所有属性的信息增益,选择信息增益最大的属性产生决策树节点,使决策树节点数最小,识别例子准确率最高,由该属性的不同属性值建立分枝,不断地对这些分枝的实例子集递归,并用该方法建立决策树的节点和分枝,直到某一个子集中例子属于同一类。
生成的决策树如图2:
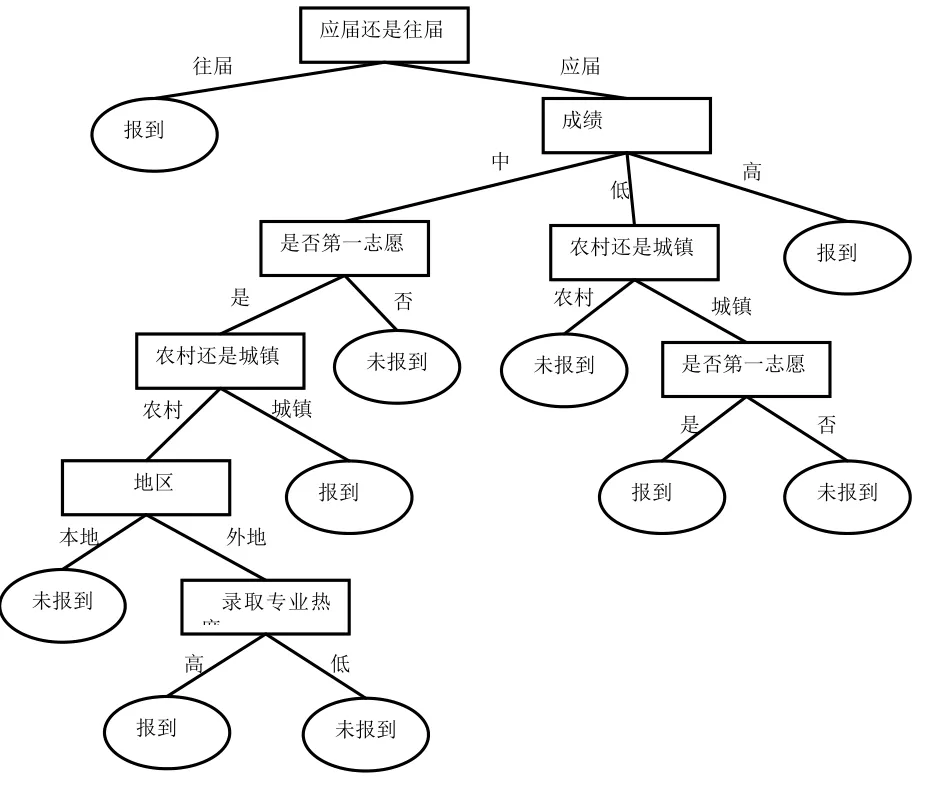
图2 决策树可视化
三、结果分析与应用
根据ID3算法可生成如图2所示的决策树,从决策树的根节点到叶子的每条路径可以提取为一条规则,可以用IF…THEN条件语句来表示。从图2可以发现几个重要的知识规则:
(1)IF往届THEN报到
(2)IF应届AND成绩高THEN报到
(3)IF应届AND成绩低AND农村THEN未报到
(4)IF应届AND成绩低AND城镇AND第一志愿录取THEN报到
(5)IF应届AND成绩低AND城镇AND非第一志愿录取THEN未报到
(6)IF应届AND成绩中AND非第一志愿录取THEN未报到
(7)IF应届AND成绩中AND第一志愿录取AND农村AND本地THEN未报到
(8)IF应届AND成绩中AND第一志愿录取AND农村AND外地AND志愿热度高THEN报到
(9)IF应届AND成绩中AND第一志愿录取AND农村AND外地AND志愿热度低THEN未报到
(10)IF应届AND成绩中AND第一志愿录取AND城镇THEN报到
从上面的规则可以看出,未报到的学生都是应届生,往届生如果被录取都会来报到,制定策略的时候可以重点放在应届生;从规则(3)可以看出如果是农村并且成绩低的考生未报到的可能性很大,主要原因是高职高专院校收费高,农村学生无力承担,另外农村考生由于就业压力的影响,使得考生在经济困难的情况下,宁愿复读也不愿报到,学校可以采取相应的扶贫助学的活动,在发送录取通知书的时候可以宣传针对贫困生的政府贷款制度以及学校的奖、助、补、减等多元化的资助体系,也可以加强宣传学校具体实际的就业优势;规则(7)可以发现成绩中等的且第一志愿录取的农村福州本地学生一般都是未来报到,这在一定程度上反映了学校忽略了在本地区宣传的力度,通常本地宣传更加有效经济,需要注意这些事项;学生是否自己第一志愿录取对于是否报到有一定的影响,可能对于录取专业不是很了解,或者不喜欢这个专业,但是通常学生对于一个专业的认识并不是很清楚,只是随大众,可以在宣传专业上加大力度;规则(8)表明成绩中等农村外地的学生第一志愿录取的专业不好,可能不来报到,学校可以在招生宣传中对专业的优势特别是在就业上的好处包括承诺突出强调。
本方案只是利用决策树技术对学生未报到的原因进行初步的分析,属于解释型的数据挖掘。当然也可以用决策树作为一个模型来判断一个学生是否来报到,但是可能要收集更加详细的数据。
[1]汪素南.智能技术在金融市场溢出效应和反洗钱中的应用研究[D].杭州:浙江大学,2007.
[2]沈莺莺,陈福生.数据挖掘在信用卡一级代理中的应用研究[J].计算机应用与软件,2006(3).
