基于BERT-Encoder和数据增强的语法纠错模型
2023-09-07黄国栋徐久珺马传香
黄国栋,徐久珺,马传香,2
(1.湖北大学计算机与信息工程学院, 湖北 武汉 430062; 2.湖北省高校人文社科重点研究基地(绩效评价信息管理研究中心),湖北 武汉 430062)
0 引言
语法纠错要求对于一个可能含有语法错误的句子,自动检测并纠正句子中出现的错误.下面是一个语法纠错的示例:
输入:零晨1点才到.
输出:凌晨1点才到.
将含有错误的句子看作源句子,将改正的句子作为目标句子,语法纠错任务可以被看作机器翻译任务.机器翻译通常采用Encoder-Decoder结构,机器翻译发展早期广泛采用RNN作为Encoder-Decoder的网络结构,RNN使用序列信息,能够把握字词间的长距离依赖关系,但是不能并行化处理.CNN可以捕捉局部上下文信息,并且可以并行计算,但长距离特征捕获能力较弱.并且两者都认为句子中每个字词具有同等重要性,无法进行有选择性的关注.基于self-attention机制的Transformer模型[1]可以使得源序列和目标序列中的每一个词和序列中其他词计算相似度并提取必要的关联特征,而且可以并行计算,在机器翻译任务中取得了最佳性能.所以本研究选择Transformer模型作为语法纠错模型.
但基于机器翻译的中文语法纠错模型所需的平行语料过少,导致模型无法充分训练,首先引用Zhao和Wang提出的动态掩蔽方法[2],不需要增加训练集就可以获得更多的平行语料.其次,随着基于Transformer双向编码器表征(BERT)[3]的发展,许多自然语言处理任务的性能都得以改善,Kaneko等[4]证明了BERT有利于提高英语语法纠错任务的性能,按照Wang和Kurosawa等的方法[5],利用BERT来初始化Transformer的encoder使得模型的性能获得进一步提升.
1 相关工作
常见的文本纠错方法有:基于规则的纠错方法、基于统计的纠错方法和基于神经网络的纠错方法.早期,针对文本纠错问题,通常采用基于规则的方法[6-7],这种方法只能修改特定的错误类型,这对于语法多变的中文语法纠错取得的效果尤其不好.基于统计的纠错方法通常含有N-gram[8]和统计机器翻译方法.N-gram通常结合混淆集使用,可以很好地解决拼写错误.Brockett等[9]首次提出将语法纠错任务看作统计机器翻译任务.Junczys-Dowmunt等[10]开发的结合了大规模平行语料Lang-8的统计机器翻译架构Moses[11].Felice等[12]将基于规则、统计机器翻译和语言模型结合的方法可以纠正多种类型的错误.
如今,深度学习技术已经被广泛应用到语法纠错任务中.有道团队[13]采用组合模型,将语法纠错分为三步:首先,使用SIGHAN 2013 CSC Datasets中提供字音、字形相似表召回候选,基于N-gram模型解决表面错误(如拼写错误);其次,将语法纠错视为机器翻译任务,用Seq2Seq模型解决语法错误,最后将上述模型组合得到最优纠错候选并通过N-gram选择困惑度最低的作为纠错结果.阿里团队[14]融合了基于规则的模型、基于统计的模型(使用了LM+噪声信道模型+beam search挑选候选解)以及基于神经机器翻译模型(encoder-decoder各两层LSTM),若模型输出结果不同,则针对冲突应用5种解决方案,选出最优的结果最为纠错结果.北京语言大学团队[15]将分词后的输入都利用Subword算法[16]拆分子词单元,并考虑到语法纠错大多数与临近词有关,而CNN能够更好的捕捉临近词的关系,使用了基于CNN的Seq2Seq单一模型.王辰成等[17]提出一种动态残差结构,动态结合不同神经模块的输出来增强模型捕获语义信息的能力,并结合单语料腐化的方法获得更多平行语料.孙邱杰等[18]利用BART噪声器[19]来破坏源句子来提高模型的泛化能力.Zheng等[20]将语法纠错视作序列标注问题,利用长短时记忆网络结合条件随机场进行语法错误诊断.
使用基于深度学习技术的方法受限平行语料库的大小,目前广泛使用的数据量最大的Lang-8数据集也仅包含120万条数据,无法满足参数比较多的中文语法纠错模型,有效的数据增强方法可能大幅度提高模型的性能.另外,经过大规模语料预训练过的BERT模型,提取其参数来初始化模型可能比随机初始化获得的效果更好.
2 本研究方法介绍
2.1 用BERT的参数初始化Transformer的EncoderTransformer模型是一种基于多头注意力机制的序列生成模型.模型将输入序列用词嵌入编码并与位置编码相加作为输入,编码器将输入编码为含有整个输入语义信息的高维隐含语义向量,解码器从中解码隐含语义向量,并通过softmax函数得到输出.其中,编码器由多个相同层组成,每层包含两个子层:Multi-head Attention和Feed Forward,解码器也是多个相同层组成,每层包含三个子层: Multi-head Attention、Feed Forward以及Masked Multi-head Attention.
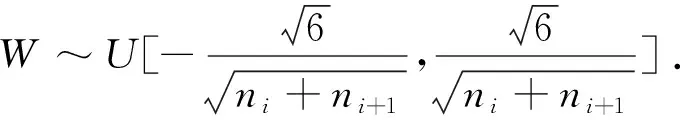

(1)
其中,p是在[0,1]区间均匀分布产生的随机数,f是替换函数.

图1 训练中生成噪声句对

不同的替换函数对模型性能的影响不同,按照Zhao等[2]的做法,介绍5种不同的替换策略:
1)填充替换:源句中每个字符都有一定的概率δ被替换成填充符号“pad”,通过减少错误的重复,从而减少模型对特定字符的依赖,提高模型的性能.
2)随机替换:源句中每个字符都有一定的概率δ被随机替换成词汇表V中的字符.被选中的字符以1/|V|的概率从词汇表中均匀采样,其中|V|是V的大小.采用随机替换方法让产生的源句更接近真实源句.
3)词频替换:通常,语法错误倾向于将高频词误认为低频词.因此,频率较高的词应该更频繁地出现在源句中作为替换.具体做法是统计目标句中每个字符出现的频次,将字符作为键,频次作为值,保存在字典中,构建词频字典,并根据词频进行替换.例如:“凌”出现3次,“晨”出现2次,则词频字典为:{‘凌’:3,‘晨’:2},则被选中字符被替换成“凌”的概率是0.6,被替换成“晨”的概率是0.4.
4)同音替换:汉字中存在大量同音字,它们同音但不同形、不同义.使用pypinyin2获取字符对应的拼音,然后根据拼音对目标句中的字符分类.将拼音作为键,同音字作为值,构建同音字典,再统计同音字中每个字出现的次数构建同(c)中的词频字典,把词频字典作为值更新同音字典,得到每种拼音类型单词的频次.训练时,按一定概率δ选择要替换的单词,并获取这个单词的拼音,根据拼音的频次进行同音替换.例如:拼音为“ling”的“凌”出现了3次,“零”出现了2次,构建的同音字典为{‘ling’:{‘凌’:3,‘零’:2}},则被选中的拼音为“ling”的字被替换成“凌”的概率为0.6,被替换成“零”的概率为0.4.
5)混合替换:每一轮训练过程中,按同样的概率选择以上4种方案或者空方案,得到更加多样的噪声对.本研究选择此方案作为数据增强方法.
完整的语法纠错模型流程如图2所示.

图2 中文语法纠错流程图
3 实验
为验证本研究提出的方法的有效性,在NLPCC2018共享任务2提供的Lang-8数据集上进行实验.实验环境如表1所示.

表1 实验环境
3.1 数据集及预处理Lang-8数据集中的平行语料是从lang-8.com网站收集的[21].lang-8.com是一个语言学习平台,平台中的文章由以汉语作为第二语言的学生撰写并由中文母语人士校对.数据集中一个不正确的句子可能包含多个更正版本,本研究将源语句和每个更正的语句一一结合来构建平行语料,得到了120万个句子对作为训练集.由于官方没有提供验证集,按照前人的工作[22],从训练集中随机获取5 000条句子对作为验证集.测试集是从北大汉语学习者语料库中提取的2 000个句子,该语料库是由外国大学生撰写的论文组成.另外,需要使用NLPCC2018提供的PKUNLP工具包对模型的输出作分词处理以供评估使用.所有数据统计如表2所示.

表2 数据集统计
3.2 参数设置Transformer模型超参数设置如下:编码器和解码器都由6个相同层组成,多头自注意力层有8个注意力头,前馈网络维度为2 048,源端和目标端的词向量维度都是512.在编码器和解码器上应用dropout操作,概率为0.1.模型采用Adam优化器,初始学习率为2,β设置为(0.9,0.98).使用Noam的学习率衰减方案,warmup_steps设置为4 000,添加ε为10-9的标签平滑.Batch_Size设置为128.选择验证集困惑度最低的模型作为最佳模型.数据增强策略中δ设置为0.3.
3.3 评价指标本研究使用MaxMatch scorer[23]作为评估模型.模型计算源句和模型更正后的句子之间所有可能的短语级编辑序列,并找到与标准编辑序列重叠程度最高的编辑序列,利用这个编辑序列{e1,…,en}和标准编辑序列{g1,…,gn} 计算准确率P、召回率R和F0.5值.公式计算如下:
(2)
(3)
(4)
其中ei和gi的交集定义为:ei∩gi={e∈ei|∃g∈gi,match(g,e)}.
中文语法纠错任务选择F0.5作为评价指标是因为该任务更加看重编辑的准确性而不是更多的编辑数量,所以把准确率权重设定为召回率的两倍[17].
3.4 实验结果及分析表3展示了在Lang-8数据集上做的四组实验结果以及在NLPCC2018共享任务2中表现最好的三个团队的结果.第一组实验仅用Transformer模型,F0.5得分为21.18,这与NLPCC2018中表现优异的系统存在很大差距.第二组实验利用BERT初始化Transformer的Encoder部分,可以看到,F0.5相比于第一组实验提升了1.08.第三组实验使用动态掩蔽的数据增强方法,F0.5获得了很大的提升,达到了30.08,超过了NLPCC2018共享任务2中获得第一的有道系统.将两者结合以后,F0.5达到最高的31.12,超过了BLCU的集成模型.这些实验结果表明了本研究方法在语法纠错任务上的有效性.

表3 Lang-8数据集实验结果
另外,表4展示了利用本研究不同的替换函数对语法纠错模型性能的影响.从表4中的准确率、召回率和F0.5可以看出每一种替换方法对模型的性能都有提升.通过在每一轮训练中引入替换函数,减少了特定的字词及语法错误的依赖,有利于避免同样的训练语料重复可能带来的过拟合问题.其中,混合替换的准确率和F0.5最高,分别为36.87和31.12;词频替换的召回率最高,为19.80,但准确率最低,为27.17,说明采用高频词作为替换有利于模型找出错误,却会降低模型的准确率;中文文本中,同音字(近音字)出错占字词错误情况的77%[24],同音替换更符合真实的字词错误.模型的表现相比其他替换方式却不佳,可能是由于同音字的数量有限,导致产生不同的训练语料较少;结合表3和表4可以发现,本研究方法的召回率高于其他模型,准确率却比ALiGM、BLCU和BLCU(ensemble)要差,可能是因为动态替换过程产生过多的选词错误从而使模型将非选词错误改错而导致的.
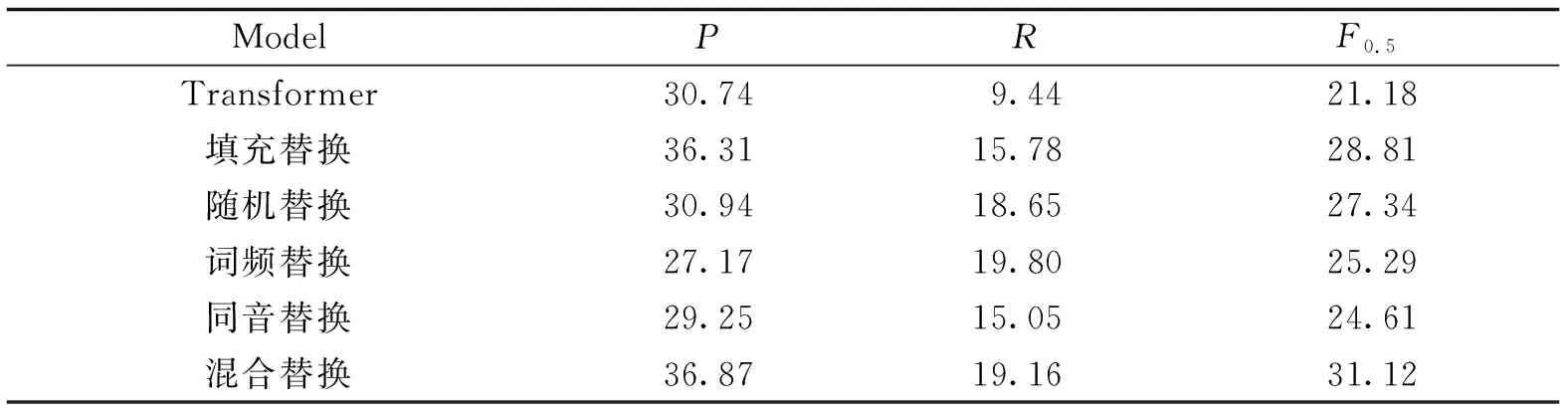
表4 不同替换方法对模型性能的影响
4 结束语
本研究将中文语法纠错任务视作机器翻译任务,构建了以Transformer为基线模型的中文语法纠错模型,利用预训练模型学习到的参数来初始化Encoder部分的参数,并结合动态掩蔽的数据增强方法,解决训练所需的平行语料不足的问题,大幅提升了基线语法纠错模型的性能.利用BERT初始化虽然能提高模型的性能,但是破坏了BERT的预训练表征,没有充分发挥BERT的性能.如何在中文语法纠错领域更好地利用BERT是我们下一步需要探索的.
