高维非概率样本数据的神经网络推断方法研究
2023-09-07刘展李若菡潘莹丽
刘展,李若菡,潘莹丽
(湖北大学数学与统计学学院, 湖北 武汉 430062)
0 引言
随着大数据的发展,现代社会在网络和信息技术方面不断取得突破和进展,人们对数据及数据样本的需求正趋于多样化,大数据背景下的抽样也逐渐成为热点话题.在大数据与计算机技术的相互促进下,网络调查因其成本低、效率高、周期短等特点被广泛应用于不同的领域,成为当下一种非常流行的调查方法.然而,大多数网络调查样本为非概率样本,其入样概率未知,利用其对总体进行推断存在一定的困难.与此同时,大数据背景下调查所收集的数据变得更加复杂,很有可能产生高维数据,即协变量个数大于样本量.那么,对于高维非概率样本数据,如何进行统计推断,成为网络调查中迫切需要解决的问题之一.
一般来说,由于非概率样本的入样概率未知,常建立倾向得分模型对非概率样本的入样概率进行估计.以往建立的倾向得分模型如Logistic回归模型,通常适用于协变量或混杂变量较少的情况,当协变量或混杂变量增多,甚至为高维数据时,该模型可能就不再适用,那么如何建模来估计倾向得分就成为一个新的问题.事实上,倾向得分起源于因果推断,而机器学习中有关因果推断的新方法如神经网络,可以被引入网络调查中进行探索.因此,结合机器学习中神经网络的降维特点,考虑构建神经网络对高维非概率样本数据进行统计推断.该研究无疑是一种新思路与新方法,补充了非概率抽样推断的理论,为网络调查样本得到准确推断结果起到重要作用,也为今后探索更多样化的非概率样本推断方法提供了一个方向,具有一定的理论价值.同时,该研究有利于促进网络调查的进一步发展,也为高维数据的处理提供了一定的参考.
1 国内外研究现状
针对非概率样本的推断问题,国内外学者已经做了大量的研究.Elliott[1]将概率样本与非概率样本结合,对非概率样本构造伪权数,并利用两个样本数据对总体进行推断.Valliant和Dever[2]提出将倾向得分估计的逆作为调整权数,根据倾向得分估计分组在每组中求倾向得分估计均值的逆,作为非概率样本的调整权数等方法来估计总体.事实上,倾向得分是由Rosenbaum和Rubin[3]为了在因果推断的观察性研究中,控制对照组和实验组的差异而提出的,其定义为给定协变量,单元接受处理的条件概率,随后被引入抽样调查中作为无回答问题、非概率抽样偏差等的处理方法之一.Brick[4]采用了先分层后建模的方法来对非概率样本的倾向得分进行估计,从而推断总体.Elliott与Valliant[5]提出两种非概率样本的推断方法:准随机方法与超总体模型方法,准随机方法基本思想就是对非概率样本的入样概率或倾向得分进行估计来推断总体,超总体模型方法就是对非概率样本建立超总体模型来估计总体.Chen等[6]针对非概率样本的推断问题,提出将准随机方法与超总体模型方法结合的双重稳健估计.在国内,刘展[7]针对自选式网络调查样本(非概率样本),利用Logistic回归估计被访者的回答概率(倾向得分),并利用估计的倾向得分进行加权调整,从而实现非概率样本的估计.刘展和金勇进[8]针对非概率抽样提出了先利用倾向得分匹配法选择匹配样本,再采用3种不同的方法对匹配样进行调整,以实现对目标总体的推断.金勇进和刘展[9]提出通过抽样方法、权数的构造与调整、估计三种方法来解决非概率抽样的统计推断问题.刘展与金勇进[10]针对网络访问固定样本(非概率样本),提出建立Logistic回归模型估计网络访问固定样本的倾向得分,为其构造权数,再将网络访问固定样本与概率样本结合进一步调整权数,最终利用两个样本数据估计总体.刘展[11]提出根据具有嵌套结构的非概率样本数据,构建多层回归模型对倾向得分进行估计,从而估计总体.刘展和潘莹丽[12]基于网络调查样本,建立广义线性超总体模型,构造网络调查样本的伪权数,并将网络调查样本与概率样本结合为一个样本,进一步调整权数,最终获得总体的估计.刘展和金勇进[13]针对候选者数据库网络调查样本,提出基于贝叶斯公式构造网络调查样本的伪权数,并将网络调查样本与概率样本结合为一个组合样本,利用组合样本数据来估计总体.刘展等[14]提出将非概率样本与概率样本混合,分别对两个样本建立模型估计倾向得分和对混合样本建立模型估计倾向得分的两条思路来估计总体.然而,以上非概率样本的推断研究大多建立Logistic 回归模型对倾向得分进行估计,从而推断总体.当协变量或混杂变量增加,甚至出现协变量个数多于样本量即高维情形时,以上方法可能并不适用.
对于高维非概率样本的推断,Mercer等[15]以控制选择性偏倚为目的,从样本补充、样本获取和事后调整三方面对非概率样本的估计方法进行了综述.Chen等[16]提出采用Adaptive LASSO变量选择方法对非概率样本进行模型辅助校准估计.Chen等[17]采用LASSO进行变量选择,对非概率样本进行模型辅助校准估计,其中对于未知的协变量的总体总量,利用一个概率样本对其进行估计.Yang等[18]基于超总体模型方法与准随机方法,提出将概率样本与非概率样本结合的双重稳健推断方法,并采用SCAD进行变量选择与模型参数估计.相对于国外,国内关于高维非概率样本的推断相对较少,刘展和潘莹丽[19]针对网络调查样本(非概率样本),建立广义Boosted模型对非概率样本的倾向得分进行估计来推断总体,该模型对高维非概率样本数据比较适用,研究表明提出的方法估计效果较好.可见,对于协变量较多的非概率样本数据,如何建立模型进行推断,还具有较大的探索空间.
机器学习的某些算法如神经网络(neural network)会优于经典统计技术,尤其是在处理高维数据时(Breiman)[20].早在19世纪末人类就已经开始了对神经网络的研究,神经网络的算法结构也随之诞生.神经网络是一种算法数学模型,由输入层、隐含层和输出层组成,每个输出层包含通过有向加权边连接到下一层中每个结点的多个节点,每一层的节点都与下一层相关联,采用Back-Propagation (BP)算法的多层前馈神经网络是迄今为止应用最广泛的神经网络.BP神经网络算法由Rumelhart等在1986年提出,由正向和反向两个传播阶段组成,他们已经从证明的角度验证了算法的正确性,使该算法有了理论基础和依据[21].BP算法也称为多层前馈神经网络的学习算法,20世纪90年代中后期,一些学者发现了非线性模型的复杂性,并企图通过该神经网络方法来解决这些问题.Miller等[22]在小脑模型关节控制器的基础上提出了非线性系统控制方法,但这种方法有时会出现精度不够的问题.当数据维数较高时,Hinton等[23]提出了自编码器(autoencoder)的深度网络,通过中间层来重构高维输入信号,训练一个多隐层的神经网络来学习,将高维信号转化为低维信号,取得了明显优于传统方法的约简效果.Omurlu等[24]已在一系列模拟中发现,非线性的情况下神经网络方法对倾向得分的估计有着比Logistic回归更小的偏差.与Logistic回归相比,神经网络至少具有两个优点:第一,神经网络能够处理高维数据,虽然每一组数据仅有可能对分类结果产生微小的影响,但据此进行的微小调整却能得到更加准确的分类;第二,足够复杂的神经网络(即有足够内部节点)可以逼近任何平滑的多项式函数,而不用管多项式的阶数或交互项的数量,这两个优点使得神经网络成为计算倾向得分的有效方法.事实上,神经网络已经被用于因果推断中倾向得分的估计并经过了检验,应继续被引入网络调查样本或非概率样本推断中进行探索[4].
综上所述,目前国内外关于非概率样本的推断已有一定的理论基础和解决方法,对于协变量较多或高维非概率样本数据,一些学者已从模型辅助、倾向得分建模等方面进行了相关讨论,但通过神经网络估计非概率样本倾向得分以推断总体的研究还比较少见,是一种比较新颖的思路.基于高维非概率样本数据维数较高、协变量个数较多的特点,本研究构建神经网络估计倾向得分,从而对高维非概率样本进行推断.
2 倾向得分方法
由于非概率样本的入样概率未知,传统基于设计的推断方法无法使用,一种常用的解决方法就是对非概率样本的入样概率进行建模估计.事实上,非概率样本的入样概率本质上就是倾向得分.以下对倾向得分及其建模进行阐述.
设U为一个有限总体,其规模为N.SB为从有限总体U中抽取的一个非概率样本,其规模为m(m (1) 其中β=(β1,β2,β3,…,βp)T.假设Xi已经过中心化变换,将式(1)变形得到: (2) 可采用极大似然估计方法对Logistic回归模型的参数β进行估计. 设Ri的概率函数表示为: P(Ri)=P(Xi)Ri(1-P(Xi))1-Ri (3) 于是,R1,R2,…,Rm+n的似然函数为: (4) 对似然函数取自然对数得: (5) 将(2)式带入(5)式可得: (6) (7) 一般来讲,以上常用的Logistic回归倾向得分模型适用协变量较少的情况,当协变量较多,甚至多于样本量时,Logistic回归倾向得分模型的估计误差可能会较大,在此考虑神经网络来估计倾向得分. (8) 至此,神经网络的训练集与测试集构造完毕. 3.2 BP神经网络模型的建立 3.2.1 参数设置与模型形式 BP神经网络由信息的正向传播和误差的反向传播两个过程组成.其工作原理为:输入信号由输入层输入,通过作用函数依此向隐含层和输出层传播,若在输出层得到的结果与期望结果误差较大,则将结果输入反向传播,并自动修正各层的神经元间的连接权值,直到实际输出与其输出误差达到要求. 根据高维非概率样本数据的特点,建立神经网络模型来估计倾向得分.以三层BP神经网络模型为例(见图1),对于隐含层,各神经元的输入值为: 图1 三层BP神经网络注:h1,…,hb为隐含层神经节点. (9) 输出值为: hoh(k)=f(hih(k)) (10) 其中,h=1,2,…,b,k=1,2,…,m1+n1.对于输出层,其输入值为: (11) 输出值为: ro(k)=f(ri(k)) (12) 由于激活函数为Sigmoid函数f(x)=1/(1+e-x),因此输出层的输出值ro(k)∈(0,1).由于非概率样本的入样问题为二分类问题,因此可以选择0.5作为阈值.若ro(k)小于0.5则预测Rk=0;若ro(k)大于0.5,则预测Rk=1. (13) 若将该误差展开至隐含层,有: (14) 若此时隐含层输出向量ho与输入向量hi不存在其他运算,则可将上式进一步展开至输入层,有: (15) (16) =-(d(k)-ro(k))f′(ri(k))=-δo(k) (17) (18) 从而有 (19) 利用ωho、δo(k)、ho计算误差函数对隐含层b个神经元的偏导数δh(k): (20) =-δo(k)ωhof′(hih(k))=-δh(k) (21) (22) 从而有 (23) 接下来利用δo(k)和δh(k)对权值ωho和ωih进行调整,使这一BP神经网络模型在循环过程中能够使误差不断减小.由 (24) (25) 随着迭代次数的增加,有 (26) (27) 当训练集在神经网络中完成训练时,可得到一个构建完成的神经网络模型. (28) (29) 从而总体均值的估计为 (30) 4.1 模拟过程为了探究高维非概率样本神经网络推断方法的有效性和可行性,利用R代码产生数据进行模拟研究,过程如下: 1)产生总体. 首先生成一个规模为10 000(N=10 000)的有限总体.其中,总体协变量共有360个X1,X2,…,X360,即p=360,且X=(X1,X2,…,X360)服从均值为0(360×1)、协方差矩阵为Σ360的多维正态分布,其均值矩阵和协方差矩阵为: 目标变量由线性回归模型Y=Xβ+ε产生,其中ε~N(0,1),β=(β1,β2,…,β360)T,β1,…,β10,β21,…,β30均为0.1,剩余的回归系数均为0.其中cor(Xi,Yj)=ρ|i-j|,i,j=(1,2,…,360),ρ=0.1. 2)抽取样本. pi=1/(1+exp(-(0.3+0.1X2+0.1X3+0.1X15+0.1X25+0.1X40))). 该入样概率可以保证抽取的非概率样本样本量基本固定在m附近.对于概率样本,采用不放回的简单随机抽样抽取,其入样概率为n/N. 3)处理样本. 将非概率样本SB和参考样本Sr结合得到集合SA.为了划分训练集与测试集,首先对非概率样本和参考样本进行分割,将SB和Sr分别以7∶3的比例分割.然后,两两合并得到训练集train和测试集test两个集合,规模分别为0.7*(m+n)和0.3*(m+n).为了避免数据中的极端值对结果产生影响,对train和test进行去掉极大、极小值的处理,最终得到train_和test_作为神经网络最终的训练集和测试集. 4)模型构建与测试. 调取R中神经网络算法包neuralnet来构建神经网络.根据样本特征,设定神经网络输入层、输出层神经元个数分别为360个和1个,隐含层层数为4层,且4层神经元个数分别为45、40、30、20.将训练集train_输入设定好的神经网络模型中,得到一个训练完成的BP神经网络模型. 5)估计总体. 4.2 模拟结果在固定有限总体的情况下,经过500次重复后,最终模拟结果见表1. 表1 模拟结果 由表1可见,基于神经网络的总体均值估计的偏差与相对偏差的绝对值均显著小于基于Logistic回归模型的总体均值估计,表明提出的估计具有较好的精度.在方差方面,与基于Logistic回归模型的总体均值估计相比,基于神经网络的总体均值估计的方差更小,说明提出估计方法的可靠性较高.此外,基于神经网络的总体均值估计的均方误差比基于Logistic回归模型的总体均值估计的均方误差更小,说明提出的方法的估计效率高于基于Logistic回归模型的估计方法.无论是从偏差来看,还是从均方误差来看,提出的方法估计效果较好. 采用2015年行为风险因素检测系统调查数据(behavioral risk factor surveillance system,简称BRFSS),以及2015年皮尤研究中心(Pew research center,PRC)的调查数据,进一步验证提出方法的有效性.BRFSS由美国疾病控制与预防中心于1984年建立,是美国首要的健康相关电话调查系统,也是世界上最大的持续性的健康调查系统,每年可完成40多万名成人访谈.PRC的Online Nonprobability Landscape Study开展于2015年,是一项通过与多个不同供应商在线访谈而得到有关人与社区研究结果的调查.选取BRFSS数据库中Annual Survey Data模块的2015年数据,根据2015年该网站发布的BRFSS Overview可知,该调查通过引入一系列人口变量,采用迭代比例拟合对数据进行加权,使得样本总数等于各单元样本权数之和,该数据为概率样本,包含441 456个单元和330个协变量,将其作为参考样本.对于PRC数据,该调查属于网络调查,得到的样本为非概率样本,包含9 301个样本单元和56个协变量. 选取两个数据集中均存在的变量总体健康状况(GENHLTH)作为目标变量.经过对两个数据集的对比分析,最终选取两个数据集中均存在的16个变量作为协变量,并对选取的变量采取统一编码.同时,删除两个数据集中存在的缺失个案及无意义回答的个案,对数据进行整理后,最终可得到184 883个BRFSS样本单元和7 560个PRC样本单元.选取的所有变量说明和描述见表2. 表2 变量描述 表3 实证结果 从表3可以看出,基于神经网络的总体均值估计稍大于基于Logistic回归模型的总体均值估计,但均在3以上,估计结果较为一致,说明居民的总体健康状况较好.同时,与基于Logistic回归模型的总体均值估计相比,基于神经网络的总体均值估计的Bootstrap方差估计更小,说明提出的估计方法波动较小、可靠性较高.从实证结果可以看出,神经网络对于高维非概率样本数据的总体推断具有较好的估计效果. 当非概率样本数据的协变量较多,甚至为高维时,可建立神经网络模型估计非概率样本的入样概率或倾向得分,最终利用估计的倾向得分推断总体.在构建神经网络过程中,对非概率样本与参考样本分别进行一定比例的分割处理,从而得到训练神经网络的训练集与测试集.采用训练集对神经网络进行训练,利用BP神经网络正反馈+负反馈的特点,使其自动调节内部权数与参数,得到一个基本的神经网络模型.接着,利用测试集对构建的神经网络进行测试,计算误差并检验该模型对新样本的判别能力.最后,利用构建的神经网络对非概率样本的倾向得分进行估计,最终获得总体均值的估计.模拟和实证分析结果表明:在高维非概率样本情形下,基于神经网络的总体推断方法估计效果较好,且优于基于Logistic回归模型的总体估计方法.针对高维非概率样本的推断问题,考虑了在协变量较多的情况下,对非概率样本进行推断的方法,符合当今互联网时代发展的特点. 神经网络是一种较为有效的处理高维非概率样本推断问题的方法.然而,对高维非概率样本推断方法的研究绝不止于此,在未来的研究中机器学习的其他方法,如随机森林、支持向量机等,也具有降维的特点,可以考虑继续引入到非概率样本的推断中进行探索.此外,经典的变量选择方法,如LASSO、SCAD、MCP等方法,能有效处理高维变量选择与模型参数估计的问题,那么采用变量选择方法进行高维倾向得分建模值得进一步研究.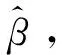
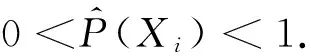
3 高维非概率样本的神经网络推断方法








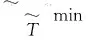

4 模拟研究
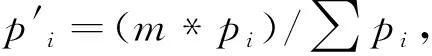
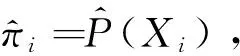


5 实证分析




6 总结与展望
