基于RoBERTa-wwm-ext与混淆集的中文文本校对模型
2023-09-07徐久珺黄国栋马传香
徐久珺,黄国栋,马传香,2
(1.湖北大学计算机与信息工程学院,湖北 武汉 430062;2.湖北省高校人文社科重点研究基地(绩效评价信息管理研究中心),湖北 武汉 430062)
0 引言
中文文本自动校对技术是自然语言处理领域的主要任务之一,随着互联网技术的高速发展和普及,各种文本信息的存储、传输以及检索发生了翻天覆地的变化,海量的文本校对任务与有限的人力和物力之间的矛盾日益加深[1],研究高效准确的文本校对方法已经十分迫切.
国外文本校对研究起步较早,从20世纪60年代到如今发展出了以下几类方法:基于机器学习[2]的方法、基于语义[3]的方法和基于概率统计[4]的方法.其中基于机器学习的方法主要有决策列表法[5]和贝叶斯分类法[6],这两种方法需要依靠预先定义的混淆集,该集合是由容易发生拼写错误的单词组成,通过学习获得混淆集中每个词语上下文特征,然后再判定在特定上下文位置中混淆集中哪个词语更为适合.这类方法最大的弊端就是只依赖于混淆集,对于混淆集中未出现的单词无法进行替换校对.基于语义的方法主要有语义分析方法[7]以及WordNet方法[8],这两种方法的特点是都不需混淆集,只基于正确的词语与其周围词语满足一定的联系,而错误的词语不满足该联系.WordNet方法在该基础上引入词与词之间语义距离的联系,如果词与上下文词语语义距离过远,则该词语是错误的,但是这类方法的准确率只有15%~25%.基于概率统计的方法主要是N-gram统计语言模型法[9-11],该方法是基于使用大规模的语料来统计词的N-gram序列,通过N-gram概率找到真词错误.这类方法的优点是不需要依靠预先定义的混淆集,但是缺点在于需要大规模的语料来训练N-gram模型,而且无法获得长距离的词语之间的语义联系.而中文文本校对没有像英文文本校对那样严格划分“非词错误”与“真词错误”,中文文本校对在进行纠错分析时,必须依赖于中文语言理解的相关技术,通过对上下文分析进行校对,上述一些英文校对方法对于中文文本不太适用.
目前,中文文本校对方面主要分为3种方法,分别是基于上下文语言特征的校对方法[12]、基于规则的校对方法[13],以及基于统计的校对方法[14].微软中国研发出一种基于多特征的中文文本校对方法[15],该方法利用上下文特征对词语对应混淆集中的词语进行选择,该方法的困难点在于将中文文本转化为多元特征序列和选择有效的混淆集.北京师范大学易蓉湘采用了一种校正文法规则[13]对中文文本进行校对,该方法利用校正文法规则把相应字词标记为错误,但是基于有限的规则,很难预测大量的不同类型的错误文本.张照煌提出一种统计语言模型评分的方法[16],该方法通过预先整理好近似字替换集合,然后替换待校对句子中的每个汉字,产生候选字符串,然后使用统计语言模型对候选字符串进行评分,通过对比评分最高的字符串与代校对文本的句子,可以发现错误之处并提出修改建议,但是这类方法无法对多字、漏字、易位等错误进行校对.
以上中文文本自动校对方法都是建立在自然语言理解技术之上的,如基于上下文语言特征、规则、概率统计的中文文本校对方法,这些方法的错误召回率与准确率都比较低,给出纠错建议的有效率也比较低,与用户的使用需求还存在着较大差距.
针对中文文本中字粒度级别错误,本研究提出了一种基于RoBERTa-wwm-ext[17]与混淆集的中文文本校对模型.该模型通过使用transformer 结构中的encoder部分读取待校对文本序列,利用全词掩码策略对文本序列进行掩码,然后通过softmax函数计算输出文本中每个字的权重,通过比较该字的权重与词汇表中权重最高值发现文本序列中的错别字,最后在纠错过程中引入混淆集来利用错误字词本身的信息,给出修改意见,完成纠错任务.
1 相关工作
1.1 全词掩码全词掩码[18](whole word masking, wwm),是谷歌在2019年5月发布的基于BERT的一个改进版本,主要更改了原预训练阶段的训练样本的生成方式.最初基于WordPiece[19]的分词方式是把一个完整词语切分成若干个子字词,在生成训练样本时,对这些子字词进行随机掩码.在全词掩码模型中,如果一个完整字词的部分子字词被掩码,则同属该字词的其他部分也会被掩码.掩码样例如表1所示.

表1 掩码样例
全词掩码(wwm)策略使得预训练模型在训练掩码语言模型的过程中使用整个词语作为训练目标,而非使用部分子字词,从而解决了原生BERT模型掩码部分子词的缺点,进一步提升了BERT模型的中文文本的表示效果.
1.2 混淆集混淆集(confusion set)一般是由容易混淆的音似、形似和义似的汉字组成的集合,以键值对的形式保存,被查的字符为键,对应的相似字符为值.近年来,随着中文文本校对工作的发展需要,基于中文汉字的混淆集在中文文本校对模型中发挥着越来越重要的作用.
本模型使用的混淆集采取的是基于OCR和ASR方法[20]生成的混淆集.该混淆集的建立过程如下:首先将原始字符集中不常用字符过滤掉,再将需要生成混淆集的字符,转换成100*100像素的图片,然后使用模糊算法将图片中的部分区域随机模糊.最后识别被处理过的字符图片,一旦识别结果与原字符不同,就会被加入到混淆集.针对同音字、近音字混淆集,该方法先将文本转换成音频,再将音频转换成文本,将转换的文本与原文本进行比对,对生成的文本与原文本有长度、发音差别较大等情况的句子进行丢弃,然后将满足条件的字符加入混淆集.最后将形近字混淆集与同音字、近音字混淆集合并形成最后的混淆集.混淆集的存储样例如表2所示.
1.3 RoBERTa-wwm-ext模型RoBERTa-wwm-ext是一种改进的预训练掩码语言模型,该模型的结构是根据BERT[21]模型演变而来.BERT 模型使用多层双向transformer编码器作为模型的主要框架,使用MLM(mask language model)和NSP(nextsentence prediction)作为预训练目标.transformer是一种注意力机制,负责学习文本中单词之间的上下文联系,其结构包括两个独立的机制,一个是encoder负责接受文本作为输入,另一个是decoder负责对任务结果进行预测.MLM模型通过对输入语句中随机 15%的token进行选取,然后在训练中将所选取的token以80%的概率替换为[MASK],10%的概率替换为随机的词语,10%的概率保持原有词语不变,从而可以提高MLM模型对中文文本特征的泛化能力.NSP一般用于判断句子 B是否为句子A的下文,从而对句子之间的上下文关系进行建模.RoBERTa-wwm-ext模型结构如图1所示.

表2 混淆集存储样例
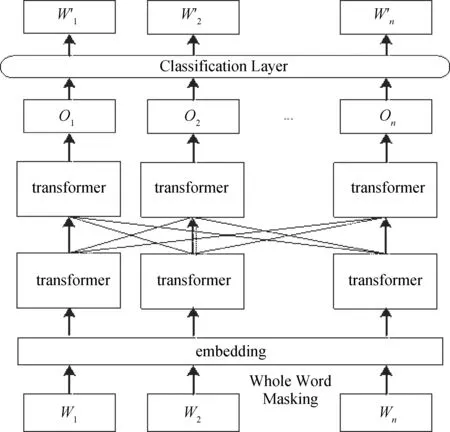
图1 RoBERTa-wwm-ext模型结构
RoBERTa-wwm-ext集成了RoBERTa与BERT-wwm的优点,对两者进行了自然的结合,该模型主要包含以下特点:1)预训练阶段把训练策略转变为全词掩码(wwm)策略,而没有使用动态掩码(dynamic masking)策略;2)取消Next Sentence Prediction(NSP)loss,提升了模型的建模效率;3)训练数据集的规模更大,增加更多的训练批次,直接使用max_len=512的训练模式.
2 基于RoBERTa-wwm-ext与混淆集的文本校对模型
针对现阶段中文文本中字粒度级别的错误对象,本研究提出一种基于RoBERTa-wwm-ext与混淆集的中文文本校对模型,既能发挥RoBERTa-wwm-ext提取待检错文本局部特征的优势与学习待检错文本上下文信息的特点,又能利用混淆集提供候选字符给出纠错建议.
基于RoBERTa-wwm-ext与混淆集的中文文本校对模型的校对过程分为两步:
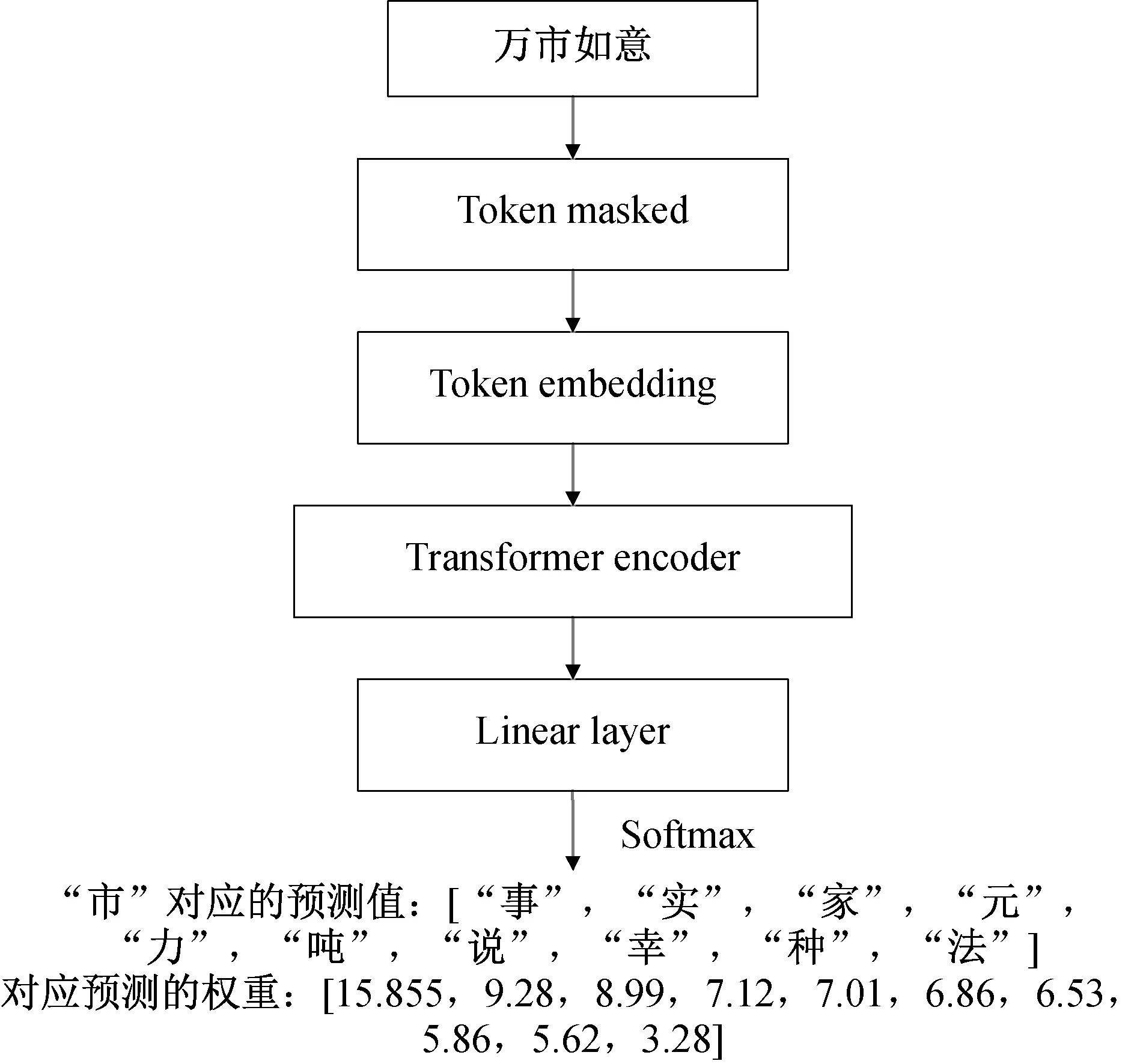
图2 文本检错
1)文本检错.首先,对于中文文本的检错部分,将输入的文本进行分词,然后,将分词后得到的散串依次进行遮挡,最后,输入到RoBERTa-wwm-ext掩码语言模型中,得到该位置字符的权重分布.如果待检查字的权重与掩码语言模型词表中权重最大值的差值要小于阈值L,则认为该位置的字是正确的,否则就是错误的.以错误语句“万市如意”为例,当检查到“市”这个字符时,文本检错示意图如图2所示.
2)文本纠错.对于中文文本校对中的纠错部分,由于RoBERTa-wwm-ext模型只能根据被遮盖字符的上下文对其进行预测,没有考虑到错字本身的信息.因此本研究在RoBERTa-wwm-ext结构的基础上,引入混淆集,提高模型的校对效果.具体方法是使用掩码语言模型计算“[MASK]”处对应字典的权重分布,并查找出混淆集中权重符合条件的字符.如果在混淆集中找到合适的字符,则将该字符作为纠正建议.否则,将权重分布中的最高值对应的字符作为修改建议.以错误语句“万市如意”为例,纠错流程如图3所示.
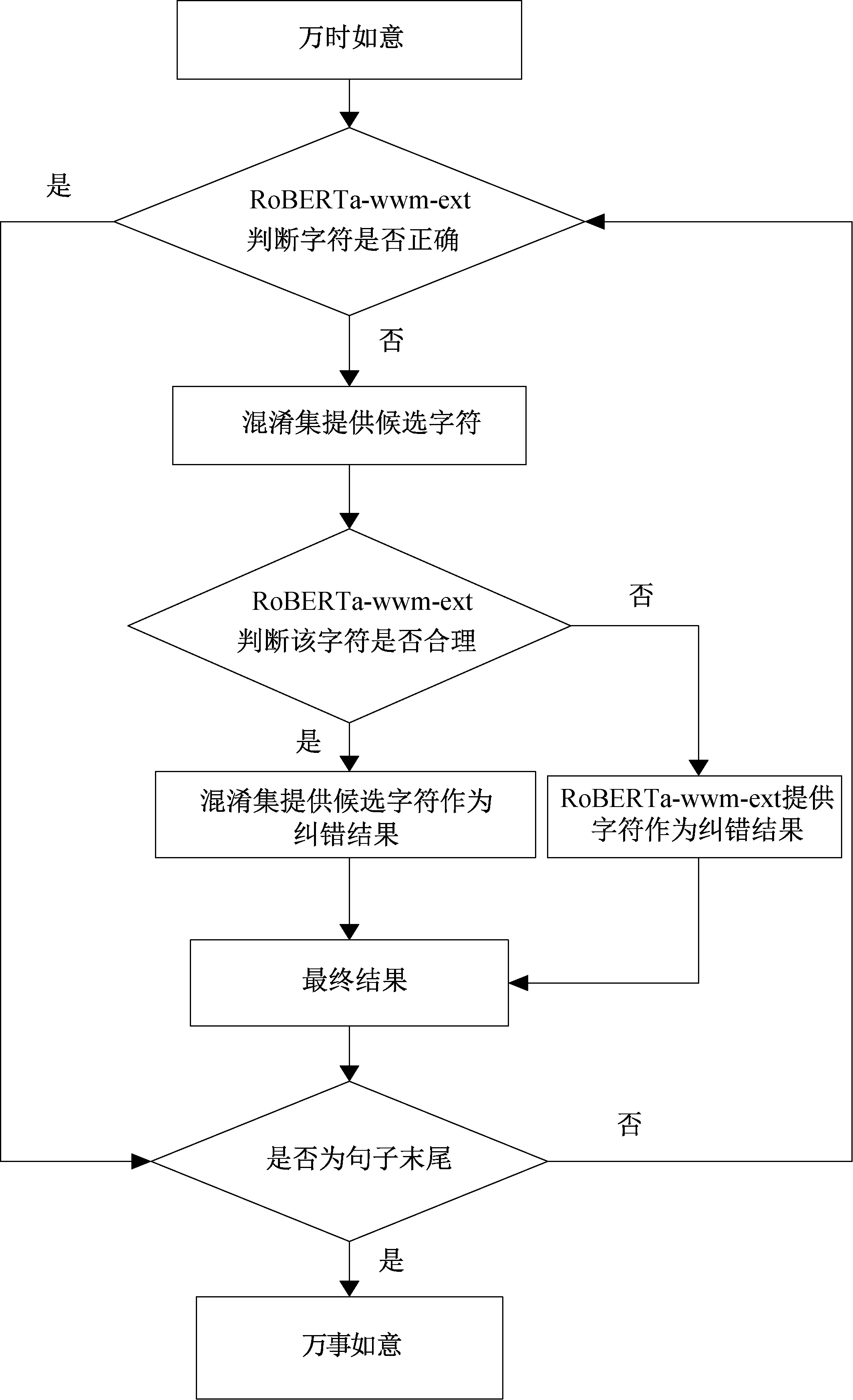
图3 文本纠错
完整的中文文本校对流程如下所示.
算法:基于RoBERTa-wwm-ext+confusion set的中文文本校对模型
输入:中文文本S=W1W2…Wn
输出:校对后的中文文本
1. Begin:
2.将输入的中文文本进行分词,基于wwm策略进行掩码,生成待校对语句;
3.使用掩码语言模型RoBERTa-wwm-ext计算被遮盖字符Wi处的权重Uwi以及该位置字符在字典中对应的权重Udist;
4.Uword=Utop-Uwi//Utop是Udist中权重最大值
5.if(Uword>L)//L是一个阈值
Wi是错误的;
else
Wi是正确的,继续检查下一个字符;
6.根据混淆集找到Wi对应的候选字符集dist[Wj]以及对应的权重分布Uwj;
7.计算出Uwj中权重最大值Umax以及对应的候选字符Mmax;
8.Ucor=Utop-Umax;
9. if(Ucor 10.将混淆集中的候选字符Mmax作为替换; 11.else 12.将字典中出现的最大权重值对应字符Mwi作为纠错结果; 13.end 3.1 实验环境、数据集及评价指标本研究的实验环境如下:实验运行操作环境为windows11操作系统,GPU为GeForce RTX 3060,内存为DDR4 8GB,深度学习框架为pytorch1.4.实验在公共数据集SIGHAN2014[22]与SIGHAN2015[23]上进行.使用SIGHAN2014与SIGHAN2015的测试集作为实验的测试语料.SIGHAN2014测试集中有1 062个段落,SIGHAN2015测试集中有1 100个段落. 本实验为了对中文文本校对模型的校对效果进行评价,采取召回率(Recall)、准确率(Precision)和F1值作为平估指标对实验结果进行评估.各指标定义如下所示: (1) (2) (3) 其中,TP(true positive) 在本实验中指被模型标记为错误或被纠正正确的数量;FN(false negative)指实际存在的错误被模型标记为没有错误的数量;FP(false positive)指实际不是错误被模型标记为错误的数量.Precision表示正确标记的错误量与检测出的错误总数之比;Recall表示正确标记的错误数量与实际错误总数之比;F1值用来综合考虑准确度和召回率,作为评价该模型好坏的指标. 3.2 实验设计与结果分析为验证本文中提出的基于RoBERTa-wwm-ext与混淆集的中文文本校对模型有效性,在数据集SIGHAN2014与SIGHAN2015上,基于N-gram、Bert-wwm、Ernie、RoBERTa-wwm-ext+Confusion Set等4个文本校对模型进行实验.实验结果如表3所示. 表3 文本校对实验结果 实验结果表明,在SIGHAN2014数据集中,基于N-gram的中文文本校对模型的准确度与召回率极为不平衡,可能是因为受限于N-gram模型自身的语言建模能力,导致对文本的泛化能力较弱.基于Bert-wwm与Ernie的中文文本校对模型的准确度与召回率相近,均在0.6以上,而基于RoBERTa-wwm-ext与混淆集的文本校对模型的召回率与准确度都达到了0.65以上,相较其余3个文本校对模型表现较好.同一个中文文本校对模型在不同的数据集下,有不同的表现,在SIGHAN2015数据集中,基于Bert-wwm与Ernie的中文文本校对模型的F1值相接近,而基于RoBERTa-wwm-ext与混淆集的中文文本校对模型对比其他三者表现更好,F1值在SIGHAN2014与SIGHAN2015数据集上均达到了0.69以上. 由于目前公开的中文文本字词错误检测的语料较少,本实验主要依赖于SIGHAN2014、SIGHAN2015中文拼写检查任务中的训练集,训练语料规模不大.但是,中文文本校对模型对训练语料的规模要求较高,从而限制了基于RoBERTa-wwm-ext与混淆集的中文文本校对模型在测试语料中准确率、召回率的进一步提升. 本研究针对中文文本字词校对的特点,提出一种基于RoBERTa-wwm-ext与混淆集的中文文本校对模型,该模型通过RoBERTa-wwm-ext模型深入学习文本的局部特征,然后基于transformer层获取文本上下文信息,最后基于混淆集提供的候选字符信息给出修改建议完成文本校对.在SIGHAN2014、SIGHAN2015中文拼写检查任务数据集上设计中文文本校对实验,对比模型性能.实验结果表明本文提出的中文文本校对模型的文本校对效果相较其他传统文本校对模型,在准确率、召回率和F1值上有较大的提升,能有效解决字粒度级别的中文文本校对问题.下一步工作将结合以词为单位的掩码语言模型来做词粒度的文本校对,并在其他领域的大型语料中进行继续预训练来提高文本校对效果.3 实验分析

4 结束语
