基于AlphaPose的行人重识别姿态评价方法
2023-09-07刘立名马传香
刘立名,马传香,2
(1.湖北大学计算机与信息工程学院,湖北 武汉 430062;2.湖北省高校人文社科重点研究基地(绩效评价信息管理研究中心),湖北 武汉 430062)
0 引言
随着我国社会和经济的持续高速发展,各类社会问题逐步显露出来,尤其是公共安全问题.为了保障国民的生命财产安全等基本权利,大量的监控摄像机部署在公共场所,例如公园、商场、火车站等.同样,随着科技的发展,可疑人员的追踪检索也由以前的人力接替检索逐步转变为智能检索,例如行人重识别(person re-identification)技术就广泛的应用于智能安防、刑侦工作等领域.
行人重识别,又名行人再识别,其概念由Gheissari等研究者在2006年的国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)上首次提出[1],其旨在给定目标行人的信息,在不同时间段内的另一个或多个无重叠摄像区域检测到该目标行人,该信息可以是图像、视频序列,甚至是文字描述.虽然随着深度学习的发展,行人重识别的工作取得了较大的进步,但在实际应用场景中,行人遮挡[2-4]、姿态[5-7]、衣服[8-10]、光照条件[11,12]、视角变化[13-15]等变化都给行人重识别任务带来了巨大的挑战.其中,针对行人遮挡问题,文献[2]中提出了遮挡感知掩模网络(occlusion-aware mask network,OAMN),使现有的注意力机制能够不受遮挡的影响,精确地捕捉身体部位;文献[3]中提出了空间区域特征(spatial region feature completion,SRFC)模块,利用非遮挡区域的上下文特征来预测遮挡区域的特征;文献[4]中提出了一种基于transform的姿态引导特征分离(pose-guided feature disentangling,PFD)方法,利用姿态信息对人或关节部分进行拆分,选择性地匹配非遮挡部分.针对姿势变化问题,文献[5]中首次提出在CNN框架中考虑人体结构信息,从而提高特征学习;文献[6]中证明了精细的和粗糙的姿态信息对重识别都很重要;文献[7]中提出利用姿态转移生成更多丰富姿态变化的新样本,以此增强训练的鲁棒性.
由上述文献的实验结果可以看出,不论是从行人遮挡的角度还是姿态变化的角度出发,都可以有效提高重识别的准确率,其中,姿势的变化也可能会导致行人存在局部信息互相遮挡的问题.目前的研究大多通过改进重识别算法来提高准确率,但在实际工作中,如若对检测范围内的所有图像进行检测,部分存在严重遮挡而导致无法识别的图像或不存在目标的图像只会消耗大量的检测时间,降低重识别检测效率.
针对上述问题,本研究的主要工作包括:1)提出在重识别实际应用场景之前,先对行人姿态进行量化分析,对其姿态进行评分,以姿态评分作为图像的质量分数,筛选出利于重识别的高质量图像;2)提出了一种基于AlphaPose的姿态评价算法,剔除存在严重遮挡的冗余图像.本研究在重识别公开数据集DukeMTMC-reID、Market1501上进行多次实验,结果表明,本文中算法能有效区分存在严重遮挡的图像,提高重识别检测效率,同时重识别准确率也有所提高.
1 相关工作
1.1 图像质量评价图像质量评价(IQA)的目的是建立一个可以代替人类对图像质量进行准确评价的模型,该模型将任意图像作为输入,将质量分数作为输出,主要包括全参考(full reference,FR)、减少参考(reduced reference,RR)和无参考(no reference,NR)图像质量评价三类.其中无参考图像质量评价方法旨在建立一个计算模型,在不需要额外信息的情况下,准确自动地预测人类感知的图像质量,其主要方法有Brisque[16]、RankIQA[17]、DIQA[18]等.Brisque方法将利用局部归一化亮度系数量化估计图像中由于失真而造成的损失,从而得到图像的质量分数.
1.2 人体姿态估计人体姿态估计是计算机视觉面临的一个基本挑战.其原理是根据算法定位人体关键点,即人体的关节点,例如肩部、手腕、脚踝等,然后将各个关键点进行连接重构出人体的主要骨骼结构,从而得到该人体的姿态.
在深度神经网络快速发展之前,传统的思路可以分为两种,一种是将人体姿态估计问题视为一个分类或者回归问题,如随机树(randomized tree[19])和稀疏概率回归(sparse probabilistic regression[20]),但此种思路检测精度一般,且不适合背景复杂的场景;另一种思路是使用图结构模型,例如在图结构模型(pictorial structure model[21])基础上进行改进强外观和空间表达模型(strong apperance and expressive spatial models[22])和一种行人检测及姿态估计的通用模型[23].随着DeepPose[24]的提出,人体姿态估计开始从传统方法转向深度学习方法,其中以沙漏模型及卷积神经网络为代表在单人人体姿态估计上取得较大进步.但是在实际场景中,更多的是多人人体姿态估计,目前,多人姿态估计算法根据步骤的执行顺序可大致分为两大类:一类是自顶向下的识别方法,该方法首先检测出各个人体的位置,再针对各个单人进行关键点识别,其检测精度与人体定位的准确率息息相关,该方法的算法包括AlphaPose[25]、Crowd Pose[26]、OASNet[27]、ASDA[28]、TransPose[29]等;另一类是自底向上的识别方法,该方法首先检测出图像中所有的关键点,然后再根据算法将关键点进行分组聚合,从而得到各个单人姿态,其识别速度较快,但精度通常不如第一种方法,本方法代表的算法包括OpenPose[30]、DeeperCut[31]、Simple Pose[32]、PifPaf[33]、HigherHRNet[34]等.本研究对比不同姿态估计的输出结果,利用AlphaPose进行姿态检测,得到不同关键点的置信度,当关键点存在遮挡时,其置信度较低,故利于该置信度作为关键点检测的可靠度,有利于区分关键点是否存在遮挡.
1.3 姿态数据集及标记方法不同的数据集对姿态的标记方式有所差别,此处对MPII及MSCOCO数据集进行介绍.MPII数据集是评估人体姿态估计的先进基准,采集自YouTube视频,标记了16个人体关键点信息,采用PCKh评价指标对模型进行评估;MSCOCO数据集则是标记17个人体关键点信息,部分关键点标注采用18个关键点标注方式,与之相比多了一个双肩中心点,即图1(b)图像关键点 5-Lshoulder、6-Rshoulder的中心点,本数据集的检测结果通常使用mAP评价指标对模型进行评估.两者标记方式如图 1所示.
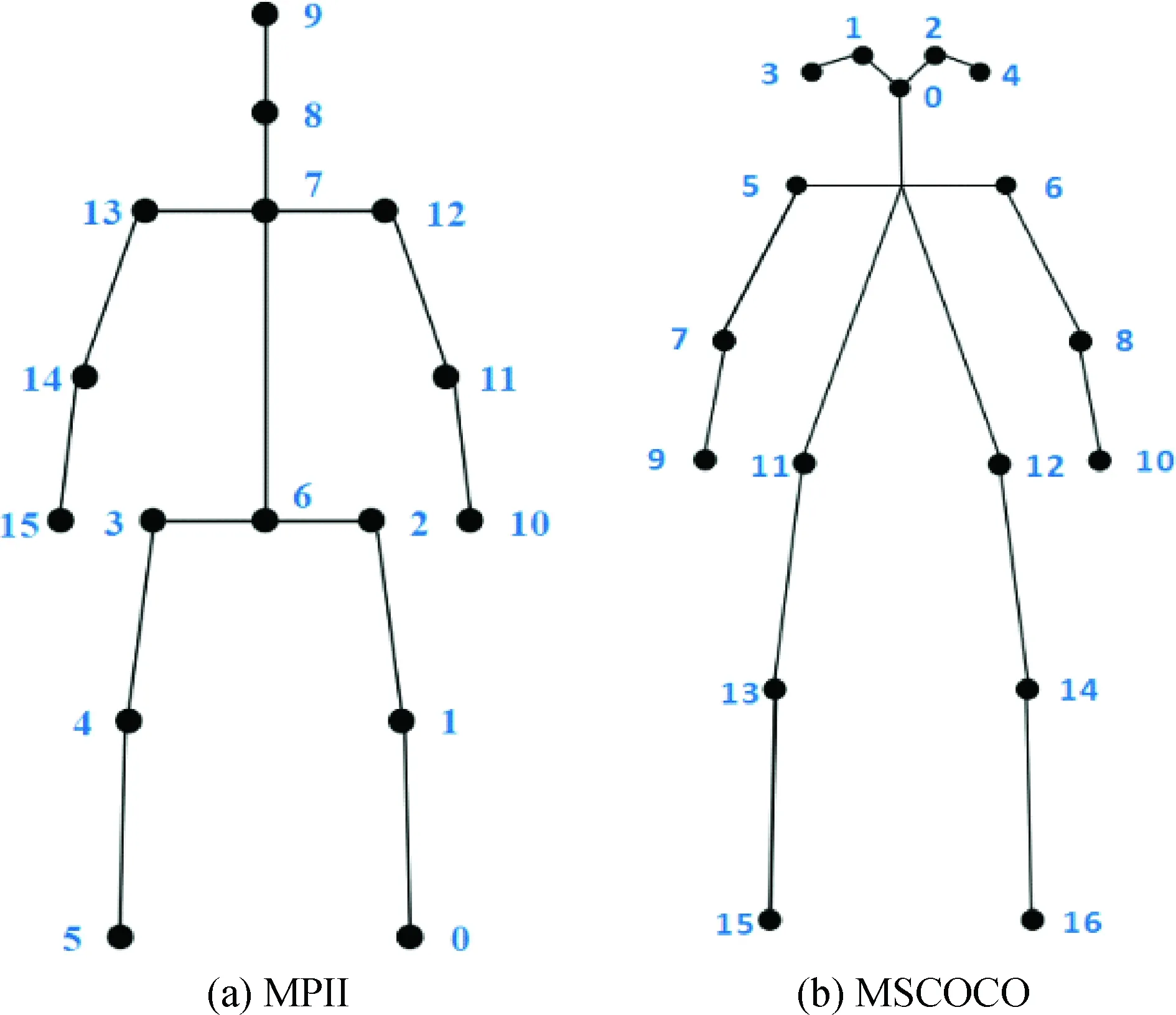
图1 人体关键点标注(MPII):0-Rankle, 1-Rknee, 2-Rhip,3-Lhip,4-Lknee, 5-Lankle, 6-Lankle, 7-thorax,8-upper neck,9-head top,10-Rwrist,11-Relbow, 12-Rshoulder, 13-Lshoulder,14-Lelbow, 15-Lwrist;(MSCOCO):0-nose, 1-Leye, 2-Reye, 3-Lear, 4-Rear, 5-Lshoulder,6-Rshoulder, 7-Lelbow,8-Relbow, 9-Lwrist,10-Rwrist,11-Lhip,12-Rhip,13-Lknee,14-Rknee,15-Lankle,16-Rankle
本研究参考不同姿态估计算法在数据集MPII上的实验结果,将关键点分为7个区域进行分析处理,分别为Head、Shoulder、Elbow、Wrist、Hip、Knee、Ankle.本研究参考MSCOCO数据集的标注方式,Head包含0-nose、1-Leye、2-Reye、3-Lear、4-Rear 5个关键点;Shoulder包含5-Lshoulder、6-Rshoulder 2个关键点;Elbow包含7-Lelbow、8-Relbow 2个关键点;Wrist包含9-Lwrist、10-Rwrist 2个关键点;Hip包含11-Lhip、12-Rhip 2个关键点;Knee包含13-Lknee、14-Rknee 2个关键点;Ankle包含15-Lankle、16-Rankle 2个关键点.
2 基于AlphaPose的重识别行人姿态评价算法

图2 姿态评价流程图
2.1 整体思路本研究的整体思路为:首先利用AlphaPose对图像的行人进行姿态估计,得到各个关键点的置信度C,然后通过分析主流的单人姿态估计算法在MPII数据集上的测试结果,确定各个关键点的权值β,接着根据各个关键点置信度与权值得到其姿态评分Sc,最后根据不同阈值tn将原始测试集分成不同的测试集进行多次实验分析.姿态评价流程如所示. 完整的算法流程如下所示:
算法1 基于AlphaPose的重识别行人姿态评价算法
输入:行人图像测试集test、MPII数据集单人姿态测试结果
输出:筛选后的测试集testn
1. begin;
2.输入MPII单人姿态测试结果;//包含Head、Shoulder、Elbow、Wrist、Hip、Knee、Ankle 7个部分准确率及整体正确率Total,分别表示为Ah、As、Ae、Aw、Ah、Ak、Aa、At
3.At=β0+β1Ah+β2As+β3Ae+β4Aw+β5Ahi+β6Ak+β7Aa;//将上述数据代入此公式,求解出β0为常数项,β1、β2、β3、β4、β5、β6、β7为回归系数,以下视作各部分的权值
4.输入行人图像测试集test;
5.逐一读取test文件夹下的图像;
6.利用AlphaPose对test进行检测得到17个关键点的置信度C;//Cn,CLe,CRe,CLea,CRea,CLs,CRs,CLel,CRel,CLw,CRw,CLh,CRh,CLk,CRk,CLa,CRa
7.Sc=β1·avg(Cn+CLe+CRe+CLea+CRea)+β2·avg(CLs+CRs)+β3·avg(CLel+CRel)+β4·avg(CLw+CRw)+β5·avg(CLh+CRh)+β6·avg(CLk+CRk)+β7·avg(CLa+CRa);//当图像中存在多个行人产生多个姿态分数时,该图像姿态分数取其中的最高分数
8.tn=0.4;//初始化tn
9.testn=’’;//定位testn文件夹位置
10.ifSc>tn;
11.shutil.copy(test, testn);//如果Sc大于阈值tn,则将图像从test文件夹复制到新的文件夹testn中
12. end
2.2 AlphaPose姿态检测AlphaPose采用自顶向下的方法,首先利用目标检测算法检测人体,然后通过单人姿态估计(single person pose estimation, SPPE)算法对检测到的人体进行姿态估计,针对定位错误和产生冗余检测结果两个主要问题,添加了3个模块,一是对称空间变换网络(symmetric space transformation network,SSTN),自动调整检测框使检测结果更准确;二是姿态引导的样本生成器(pose-guided proposals generator,PGPG),对已有数据进行姿态引导扩充,达到数据增强目的;三是姿态非极大值抑制器(parametric pose non-maximum suppression,PPNMS ),定义姿态距离,计算姿态相似度,从而消除冗余的检测框.
本研究利用该模型对重识别测试数据集进行姿态检测,参考MSCOCO数据集的标注方式,得到17个姿态关键点的信息(x,y,C),其中,x,y分别为关键点的横纵坐标,C为关键点检测的置信度,又称可靠度,它反映该关键点检测结果的可靠度,其取值范围在0~1之间,越趋近于1时表示该关键点检测结果越可靠,反之,越趋近于0时表示该关键点检测结果越不可靠.
2.3 姿态关键点权值确定为较为客观地确定各个关键点权值,本研究对MPII 数据集上的姿态检测结果(1)http://human-pose.mpi-inf.mpg.de/#results进行分析,同时为了仅考虑不同关键点本身的检测难度,忽略其他因素对姿态的影响,选择单人姿态的检测结果作为权值的参考依据.其中部分测试结果如表1所示,表中数据分别表示该部分检测准确率,Total表示整体检测准确率,以便更为清晰地分析不同关键点的检测难度将其绘制成如图 3所示的折线图.

表1 MPII数据集上部分单人姿态检测结果 %
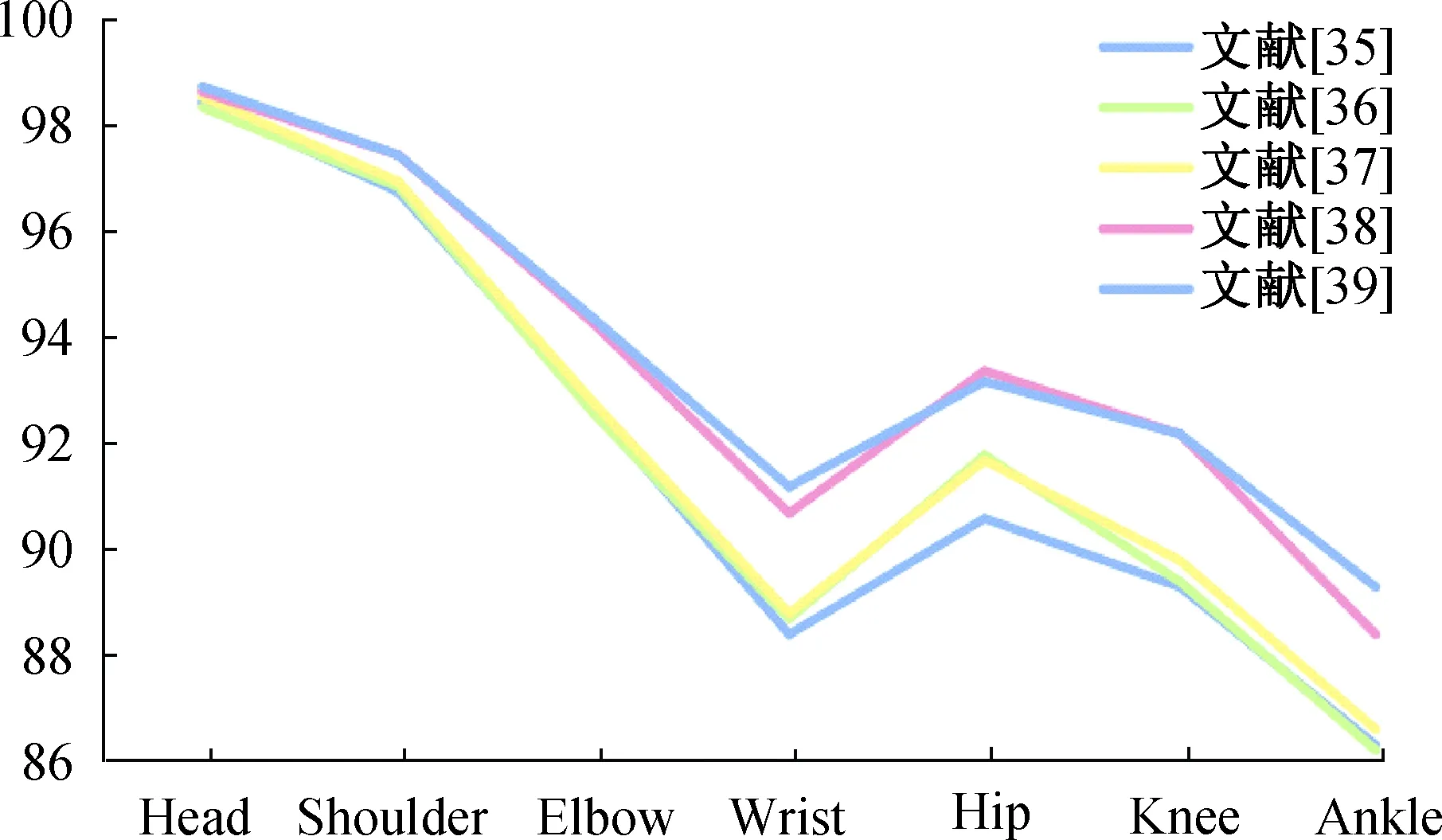
图3 MPII数据集上单人姿态检测结果折线图
根据图表显示,不难看出,Ankle的识别准确率明显低于Head、Shoulder等关键点,其次是Wrist,侧面反映出Ankle的识别难度要高于Head、Shoulder等关键点.本文中权重设置标准依托于检测难度,具体表现为检测难度越高,权值越高,但从数据显示,只能大概判断Ankle的权值高于Head,无法准确赋值.因此,本研究引入多元线性回归模型,利用多元线性回归得到各个关键点回归系数,从而将其视作各个关键点的的权值,计算其姿态评分.
多元线性回归模型可以用来描述一个因变量与多个自变量之间的相关关系,本文中因变量为Total检测准确率,自变量为Head、Shoulder、Elbow、Wrist、Hip、Knee、Ankle各部分检测准确率,将上述数据代入多元线性回归模型中求解出各个部分的回归系数.该回归模型可表示为:
At=β0+β1Ah+β2As+β3Ae+β4Aw+β5Ahi+β6Ak+β7Aa
(1)
其中,At表示整体准确率,Ah表示Head准确率,As表示Shoulder准确率,Ae表示Elbow准确率,Aw表示Wrist准确率,Ahi表示Hip准确率,Ak表示Knee准确率,Aa表示Ankle准确率,β0为常数项,β1、β2、β3、β4、β5、β6、β7为回归系数.
2.4 姿态评分根据AlphaPose的检测结果,将17个关键点分别并入Head、Shoulder、Elbow、Wrist、Hip、Knee、Ankle 7个区域进行分析.其中,Head包括5个关键点的信息,分别为0-nose、1-Leye、2-Reye、3-Lear、4-Rear,Head整体置信度取5个关键点的平均置信度;Shoulder包括 5-Lshoulder,6-Rshoulder 2个关键点信息,Shoulder置信度取两者平均置信度;Elbow、Wrist、Hip、Knee、Ankle依次类推,取各左右关键点平均置信度.将回归系数视为姿态评分的权值,可以将姿态评分模型定义为:
Sc=β0+β1Ch+β2Cs+β3Ce+β4Cw+β5Chi+β6Ck+β7Ca
(2)
其中,Sc表示图像中的行人姿态分数,Ch表示Head的置信度,Cs表示Shoulder的置信度,Ce表示Elbow的置信度,Cw表示Wrist的置信度,Chi表示Hip的置信度,Ck表示Knee的置信度,Ca表示Ankle的置信度,β0为常数项,β1、β2、β3、β4、β5、β6、β7为各个部分的权值.

图4 测试集部分图像
依据上述姿态评分模型,可以客观地对图像进行区分,如图 4所示,第一行图像是筛选出的姿态评分较低的图像,行人普遍存在明显遮挡,不仅有环境遮挡,同时也存在姿态引起的部分关键点遮挡,且大多为侧面图像;第二行图像为姿态评分较高的图像,基本不存在环境遮挡,图像大多为正面图像,甚至部分图像脸部信息也较为清晰;第三行图像为存在多人信息的图像,利用AlphaPose进行检测时,会检测出多个人的姿态信息,得到多人姿态分数,针对这种情况,我们在同一张图像中取评分最高的那个姿态作为该图像的姿态分数,因为正确身份的行人边界框会大于其他干扰行人,同时正确身份的行人会处于图像的中心.
3 实验及结果分析
3.1 数据集及评价指标本研究分别在重识别公开数据集DukeMTMC-reID、Market1501上进行对比实验.
DukeMTMC-reID数据集采集自Duke大学的8个摄像头,共采集到1 812个行人的36 411 张图像.其中,训练集bounding_box_train包含702个行人,共16 522张图像;测试集bounding_box_test包含702个行人及408个干扰行人,共 17 661 张图像;查找集query 包含测试集中的 702 个行人,在每个摄像头中为 702 个行人随机选择一张图像,共有 2 228 张图像.数据集中的图像命名规则以 0002_c1_f0044158.jpg 为例进行介绍,0002表示行人ID编号、c1表示摄像头1、f0044158表示第44 158帧图像,即该图像可描述为编号“0002”的行人在摄像头1下的第44 158帧图像.
Market1501数据集采集自清华大学校园的 6 个摄像头,共采集到1 501 个行人的32 668张图像.其中,训练集bounding_box_train包含751个行人,共有12 936张图像;测试集bounding_box_test包含750个行人及前缀为0000和-1的6 617张干扰图像,共有19 732张图像;查找集query包含测试集中的750个行人,在每个摄像头中为750个行人随机选择一张图像,共有3 368 张图像.数据集中的图像命名规则以0002_c1s1_000451_03.jpg 为例进行介绍,0002表示行人ID编号、c1表示摄像头1、s1表示第一个录像段、000451表示第451帧图像、03表示第三个检测框,即该图像可描述为编号“0002”的行人在第一个摄像头的第一个录像段下第451帧图像中的第三个检测框图像.
评价指标使 用 累 积 匹 配 曲 线(cumulative match characteristic,CMC)和 平 均 精 度 均 值 (mean average precision,mAP)作为评价标准.其中,CMC曲线主要由Rank-n值构成,其横坐标取n值,纵坐标取rank-n值,本文中使用rank-1,rank-5,rank-10,rank-20代表CMC曲线,rank-n值表示在排序最靠前的n张图片中正确结果的比率.mAP是平均精度(average precision,AP)的均值.其计算公式如下所示:
(3)
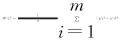
(4)
其中,mAP为查找集中所有查询目标的AP(i)之和求平均,Q表示待查询目标的总数.
3.2 实验结果及分析本研究利用torchreid[40]重识别框架在DukeMTMC-reID、Market1501数据集上进行对比实验,总共分为两组对照实验.第一组对照实验,设置不同姿态评分阈值tn,将姿态分数Sc大于阈值的图像筛选出来构成不同的测试集testn,此时各个测试集的大小是不同的;第二组对照实验,在行人ID及摄像头s编号同时相同时,分别筛选姿态分数Sc排名前/后m名的图像构成测试集test-topm、test-lastm,此时两个测试集大小相同.在两组对照试实验中,DukeMTMC-reID、Market1501数据集中的干扰项分别按以下标准进行分配:1)DukeMTMC-reID数据集中,干扰行人图像与待查询行人图像按照同样的姿态评分筛选条件进行筛选;2)Market1501数据集中的干扰项按照test集中干扰项占比进行随机分配,即干扰项在不同测试集中占比保持在0.335.
3.2.1 实验一 为分析不同阈值筛选下的测试集重识别的测试结果而设计实验一,DukeMTMC-reID、Market1501初始测试集test分别包含17 661、19 732张图像,由于DukeMTMC-reID数据集中的干扰项基本保留有完整姿态,所以姿态评分平均值是17 661张图像的评分平均值,平均值为0.48;而Market1501数据集中前缀为0000和-1的图像大多为行人局部图像,无法检测出17个关键点信息,因此此数据集的姿态评分平均值为剔除了干扰项,剩余13 115张图像的评分平均值,平均值为0.44.本研究首先设置一个阈值t1=0.4,接着根据两个数据集的平均值设置阈值t2=0.44、t3=0.48,根据阈值的大小进行筛选,DukeMTMC-reID、Market1501数据集中测试集test1、test2、test3分别为姿态评分大于阈值0.4、0.44、0.48的测试集.DukeMTMC-reID数据集中测试集test1、test2、test3分别占初始测试集test的74.0%、62.1%、44.5%,检测时间减少27~73 s,检测效率提高了18%~20%;Market1501数据集中测试集test1、test2、test3分别占初始测试集test的66.5%、56.0%、44.0%,检测时间减少了60~115 s,检测效率提高了33%~59%. 实验一mAP及rank测试结果如表2所示,其中epoch表示torchreid的迭代次数.
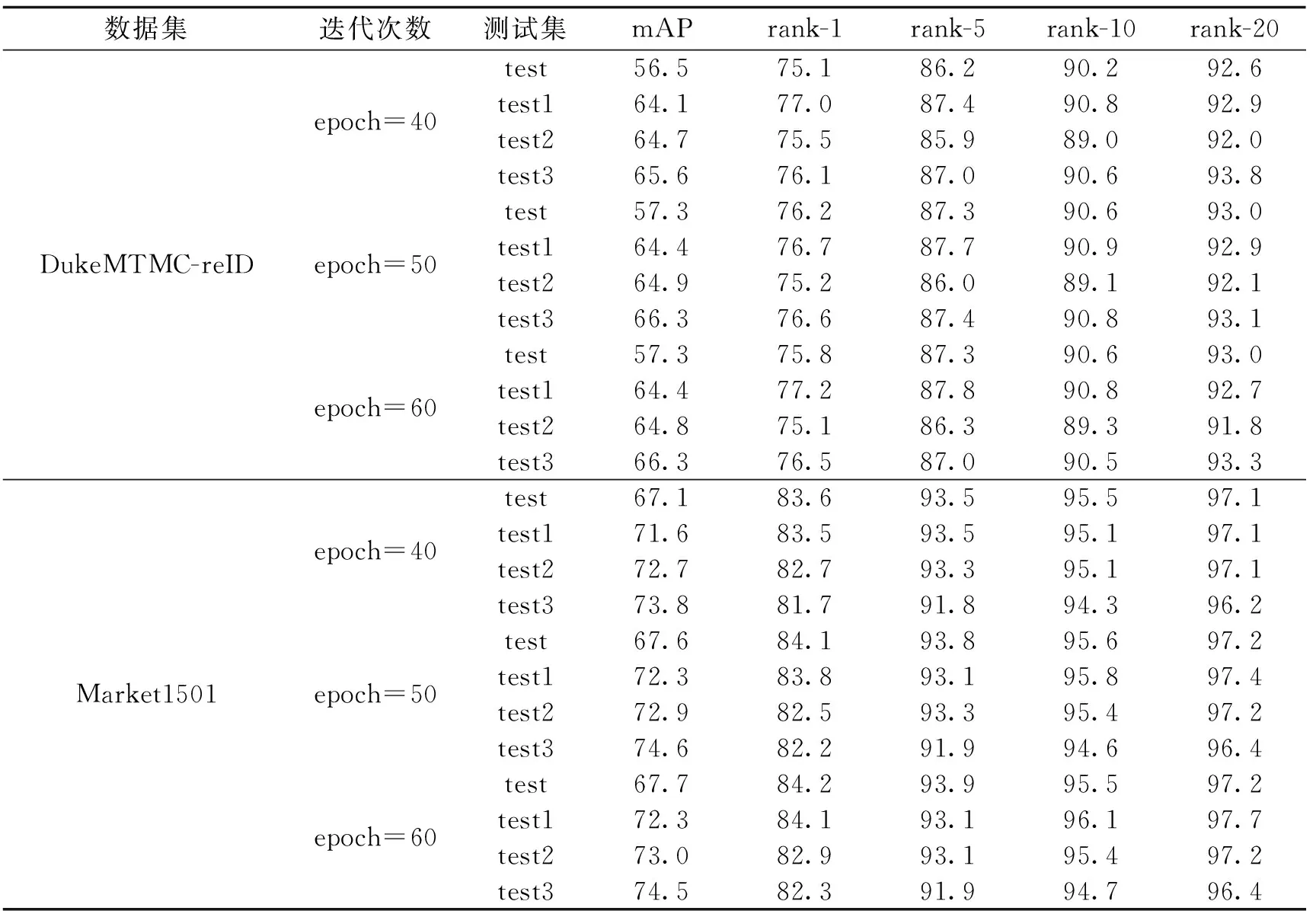
表2 实验一测试结果
根据DukeMTMC-reID及Market1501数据集测试结果可以看出,mAP随着低姿态分数图像拒绝比率的提高而逐渐提高,但是指标rank-n却没有呈现此种规律,甚至在Market1501数据集测试结果中呈现相反的趋势,初步考虑是由于在数据集中姿态评分分布不匀,即存在行人a的的姿态评分普遍较高,而行人b的姿态评分普遍较低,经过筛选之后,行人a的图像大量保留,行人b的图像保留数量较少,甚至没有产生漏检的情况,从而导致行人b的rank-n的值较低.为证实这一观点,设计了第二组对照实验,对每个行人采取定量的图像进行分析.
3.2.2 实验二 实验一中,不同测试集中存在两个变量,一是测试集大小,二是图像姿态评分,为更清晰地确定图像姿态评分对实验结果的影响,实验二中将两个测试集大小保持一致.其筛选原理是:首先将数据集中行人ID及摄像头s编号同时一致时,视为一个比较组;然后在每一个比较组里分别取姿态评分前/后m名的图像构成测试集test-topm、test-lastm,若某个比较组中图像总数不超过m张时,则将该比较组的图像同时置于测试集test-topm和test-lastm.在DukeMTMC-reID数据集中取m值为5,构成测试集test-top5和test-last5,但由于Market1501数据集中大部分比较组中图像均不超过5张,导致当m值为5时,test-top5和test-last5测试集大部分数据均相同,测试差距较不明显,故在Market1501数据集中取m值为3,筛选出各个比较组中姿态评分前/后3名的图像,同时将干扰项按Market1501测试集test中干扰项的占比进行随机分配,一起构成测试集test-top3和test-last3.利用本文中姿态评价方法和Brisque方法筛选出不同质量的测试集,其测试结果如表3所示.

表3 实验二测试结果
根据上述结果表明,当测试集大小一致时,使用Brisque方法筛选出的test-topm、test-lastm测试集的mAP差距小于本文中方法,说明本文中方法更利于重识别图像的区分,且在DukeMTMC-reID数据集中,Brisque方法筛选出test-top5测试集的mAP小于test-last5测试集,说明该方法不适用于多种数据集.使用本文中姿态评分方法,筛选出的test-topm测试集不论是mAP还是rank-n值均高于test-lastm测试集,充分证明,本文中姿态评分算法可对图像进行有效区分.同时,实验二中,数据集由每个行人的姿态评分正/倒数排名构成,因此,可以保证query集中每个行人都进行定量检测,既避免姿态评分普遍较高而引起的冗余,也能避免姿态评分普遍较低引起的漏检,故在此种图像筛选条件下,test-top5/test-top3的rank-1值均高于其他测试集.
4 结论
本研究针对重识别的数据量庞大、数据中行人遮挡的问题提出在重识别检测之前引入姿态评价这一概念,继而提出一种基于AlphaPose的姿态评价算法,该算法通过利用姿态检测算法确定不同关键点的置信度,然后加权求和得到其姿态评分,从而将图像按照姿态评分分数进行区分,最后利用重识别算法进行测试.实验结果表明,按照不同筛选条件筛选高姿态评分的图像,其mAP、rank-n值均有所提高.充分验证该算法在重识别查询之前,对待查询图像进行筛选,可有效降低查询检测量,提高检测效率,同时也能提高查询准确率.下一步工作会将该算法应用在视频重识别数据集中进行测试,并将其应用在真实的视频监控行人重识别工作中进行验证.
