垃圾博客自动识别及检测技术研究
2022-04-11王赫楠
王赫楠
(辽宁中医药大学)
一、研究的背景
进入数字时代以来,全球的数据量呈爆炸式增长,各个机构或企业的服务器都积累了海量用户数据和行为数据。如此大规模的数据早已超过了专家人工分析的能力范畴,利用计算机自动挖掘、分析海量数据成为了学者们关注的课题。在此背景下,数据挖掘领域应运而生。数据挖掘是指通过计算机算法搜索隐藏在海量数据中的有价值信息。文本分类[1-4]是数据挖掘中的常用技术,根据输入文本的内容自动将其划分到预定义的类别中。博客分类是文本分类技术的典型应用。
博客继电子邮件(E-Mail)、即时通信(IM)、网络论坛(BBS)之后,以其方便、快捷、具有共享价值的特点收到公众的广泛使用。2002年至2009年期间,博客用户数呈现大规模增长的趋势,如图1所示。博客具有的三大特点吸引了大量用户:一是以“自由、开放、共享”为理念,提供新形式的人际交流平台;二是个性化的信息管理模式;三是改变了传统的文化初版模式,以独立的媒体传播形态凸显用户生活和工作的方方面面。
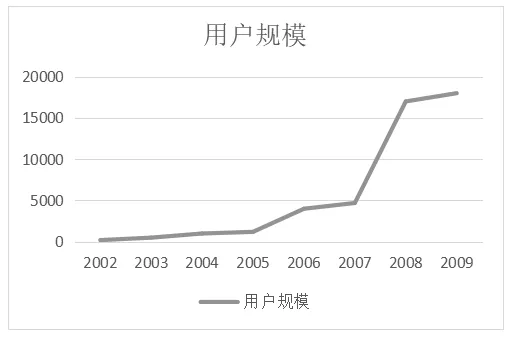
图1 用户规模
在博客蓬勃发展的同时,垃圾博客 (Spam Blog or Splog)[5-9]这种不良产物随之而来,严重拉低了博客内容的检索质量,破坏博客的网络生态。Umbria[2006]进行了为期一周的博客内容调查,统计发现,2030万篇博客中270万篇为垃圾博客,占比超过13%。在用户数较多的三种博客网站检索发现,平均100篇博客中44篇为无价值的垃圾博客。垃圾博客带来的主要问题有两点,一是导致信息检索质量的下降,二是严重浪费网络和存储资源。垃圾博客的检测和识别对实时性和提前性要求很高,不能带有任何主观偏见,且需要保证误判率低,是一项富有挑战性的工作。
随着博客对公众的吸引力与日俱增,博客网络世界也承受了巨大压力:恶意评论、刷好评、营销引流等垃圾博客激增,严重降低了博客有价值内容的检索速度和效率,影响博客用户有效使用博客中蕴含的大量资源。如果不对垃圾博客进行控制,那么未来网络博客世界将成为毫无价值的垃圾场。因此,自动过滤垃圾博客迫在眉睫。不仅如此,垃圾博客的存在严重影响了市场调研领域调查结果的准确性。市场调研的前提是数据的真实有效,因此必须首先识别出垃圾博客并进行自动过滤,为进一步的统计分析奠定基础。
二、垃圾博客自动识别及检测技术
近年来,垃圾博客的数量和种类明显增加,如表1所示的各种垃圾博客的占比量。垃圾博客检测领域受到学者们的广泛关注,但仍处于起步阶段。垃圾博客检测与垃圾邮件检测任务类
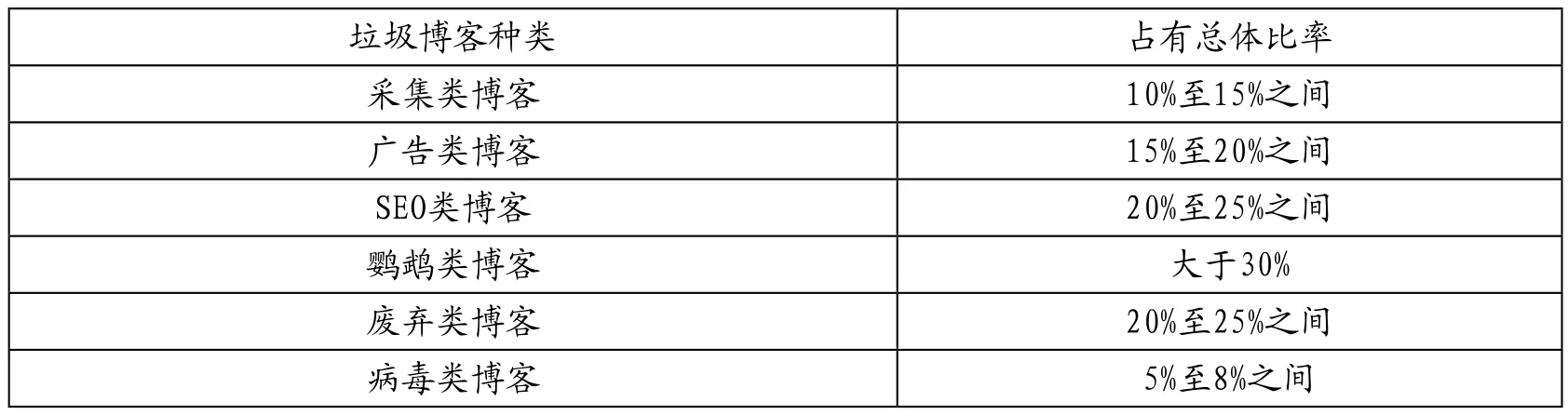
表1 垃圾博客的占有比率
似,都是基于文本内容进行的识别,但邮件有固定的格式、主题等,更具规律性,而垃圾博客由于其个性化的特点,识别难度更大。GyÖngyi and GarciaMolina(2005)首次提出垃圾邮件分类任务,为处理互联网存在的其他垃圾提供思路,同时提出对网络垃圾邮件的处理问题[10-11]。GyÖngyietal(2006、2004)首 先构建了一个种子页面,在此基础上设计了信任分数,从而实现垃圾邮件的判断。而内容分析是识别垃圾邮件的另一重要方法,可以自动检测与垃圾邮件页面链接相关的页面或关键词条。Fetterly和Ntoulas在2006年通过研究发现,传统垃圾邮件通过手动添加链接或复制静态页面实现,但随着科技发展,目前,一定数量的垃圾邮件由机器自动生成。Fetterly研究了通过拼接高搜索量关键词自动生成的垃圾邮件网页的特征。Urvoyetal从超文本标记语言的源代码入手,基于相似度识别垃圾电子邮件。
垃圾博客是垃圾电子邮件的一种特例,可以参考垃圾邮件的识别方法。Kolarietal、Lin等把每篇博客看作为单一、静态的页面,使用基于内容特征的词包和锚的方式,并结合链接特征进行垃圾博客识别。Salvetti和Nicolov通过研究发现垃圾博客中的一些短语是垃圾URL的组成部分,通过URL技术可以不读取博客内容实现初步过滤。Hanetal(2006)提出一种协同过滤方法,但该技术需要手动识别部分垃圾博客,同时需要保证信息共享机制的可信性。
Manually通过创建垃圾博客URL和IP的黑名单,并更新ping服务器,实现垃圾博客的过滤。Jindal 等基于二分类学习器分类垃圾博客评论[12-13],并通过计算重复性进一步过滤手工标注代价高的垃圾博客评论。Archana等人从博客内容相似度、句子个数、重复词语、锚文本数量、停用词比例等方面进行博客垃圾评论的特征统计,但由于中英文的差异,该方法并不能直接应用于中文博客。垃圾评论、垃圾电子邮件的内容呈现出静态化的特点,而垃圾博客是动态变化的,需要实时跟随热点话题,才能持续被搜索引擎排在前面,达到引流的目的。此外,垃圾博客可以利用自动框架生成。因此,只依靠博客文本的基本特征不能够满足检测要求,加入博客的动态时序特征可大幅提高垃圾博客的识别率。
目前国内在垃圾博客识别领域的研究成果有待完善,大部分学者着眼于博客文本的统计学特征,或链接中带有的垃圾标签特征构造识别模型,无法检测到隐秘性较强的垃圾博客,虽准确率很高,但召回率低,不能满足现有需求。刘纬、廖祥文等(2008)分析博客内容的统计特征,根据文本结构、词性差异、句子长短等角度选取特征,并综合各项统计特征构建垃圾博客检测算法[14]。何海江等人基于向量空间模型(VSM)计算博客相关度,从而判断该篇博客是否为垃圾博客[15],但这种方法存在缺陷, 若某篇博客没有使用正常博客中常出现的词语, 而是用近义词表达,这些词会被认为是其他词,从而被误判为垃圾博客。Kolarietal(2006)通过支持向量机分类器构建垃圾博客自动检测模型,但该方法严重依赖训练语料,人工标注成本高,实际运用困难。杨宇航(2007)主要在中文领域进行研究,分析中文特征,不需要任何先验知识和训练过程整合的基于多特征的作弊评论识别方法,实时性强,可在线识别博客,但由于其特征维度过高,大幅降低了识别速度,因此,如何有效提取文本特征是检测任务的关键。
三、总结
博客作为近年来较受欢迎的网络交流媒介,为公众提供了表达个人观点、交流思想和感情的社交平台。但是随着博客的受众面越来越广,以博客为载体的网络垃圾日益凸显,对网络生态造成负面影响。继垃圾邮件、垃圾短信之后,垃圾博客成为了数字化时代的第三大污染。目前对于垃圾博客还没有统一的定义,但本质上是指出于某种经济利益,通过未经授权复制他人文章等方式,提升带有某些关键字的博客在搜索引擎排名位置,插入垃圾链接或宣传盈利广告,导致用户的时间和大量网络资源的浪费。除此之外,博客中包含的海量信息对各个领域有重要意义,垃圾博客的泛滥降低了相关调查研究的准确性。因此,基于人工智能实现垃圾博客的自动识别和过滤具有重要意义。
对自动识别、检测垃圾博客的任务,常用的做法是使用机器学习中的二分类算法。对垃圾博客的识别,主要依靠分类器的识别功能。常用算法有支持向量机(SVM)[14](Sculley,2007;Datta,2008)、贝叶斯 (Datta,2008)、 决 策 树 (Decision Tree)(Ntoulas,2006; 刘,2008),集成学习之AdaBoost算法(Freund ,1995 )等单一的算法识别垃圾博客效果不够理想。
