一种基于深度学习的交通标志识别算法研究
2022-04-09谢豆石景文刘文军刘澍
谢豆 石景文 刘文军 刘澍
摘要:针对当前在真实环境中交通标志呈多尺度分布,且图像背景复杂、天气光照多变等多种因素造成识别精度低、识别速度慢等情况。提出了一种基于深度学习神经网络的交通标志识别的设计与实现。首先从公开数据集TT100K中选取出现次数最多的45类交通标志进行识别,接着对图像进行mosaic等图像增强及图像处理。然后在深度学习神经网络中的YOLOv4网络结构上进行改进,使用聚类划分需要检测的目标框尺寸和CIOU对预测结果进行优化,最后使用迁移学习对模型进行训练。通过对模型的评估发现,与现有的方法相比,该模型的识别精度更高,识别速度更快。
关键词:深度学习;目标检测;交通标志检测;YOLOv4
中图分类号:TP393 文献标识码:A
文章编号:1009-3044(2022)06-0116-03
开放科学(资源服务)标识码(OSID):
1 概述
近年来,交通标志识别作为智能驾驶中一个重要的组成部分,引起了人们的广泛研究。准确快速地识别出各种交通标志能帮助驾驶员规范行驶,从而能够提高出行效率,降低交通事故的发生。
传统的交通标志识别方式主要采用基于计算机视觉和机器学习模型的方法 [1-2]。如Nandi等人[1]通过图片的不同色彩空间进行识别、对交通标志的形状及轮廓进行分割提取交通标志、融合交通标志的形状与色彩特征和采用深度学习中的神经网络进行识别。Gao等人[2]根据每个交通标志的颜色和形状的不同来区分。采用色彩模型CIECAM97和形状模型提取出不同的交通标志进行判别。这些研究方法需要对图像做复杂的图像处理,减慢了检测速度。且灵活性弱,不能应用在多种不同的应用场景下。
当前基于深度学习的交通标志识别逐渐成为研究的主流[3-5]。张传伟等人[3]使用目标检测模型YOLO构建交通标志识别模型,魏龙等人[4]则采用改进的YOLO模型进一步优化交通标志识别的效果。基于神经网络识别交通标志的优势是在不对原始图像进行过多的图像处理的情况下,满足在差异性大的环境中正确识别交通标志的需求。
当前的目标检测算法主要分为两类:一阶检测算法和二阶检测算法。二阶检测算法将分开进行的检测步骤合二为一,具有更好的实时性。一类代表性的为YOLO系列[6-7]。本文提出的一种基于改进的深度学习的交通标志识别算法研究。对传统的YOLOv4模型进行改进,并采用迁移学习进行模型训练。在大大缩短训练时间的情况下,保证了模型精度的提升。
2 检测算法设计
2.1 准备数据集
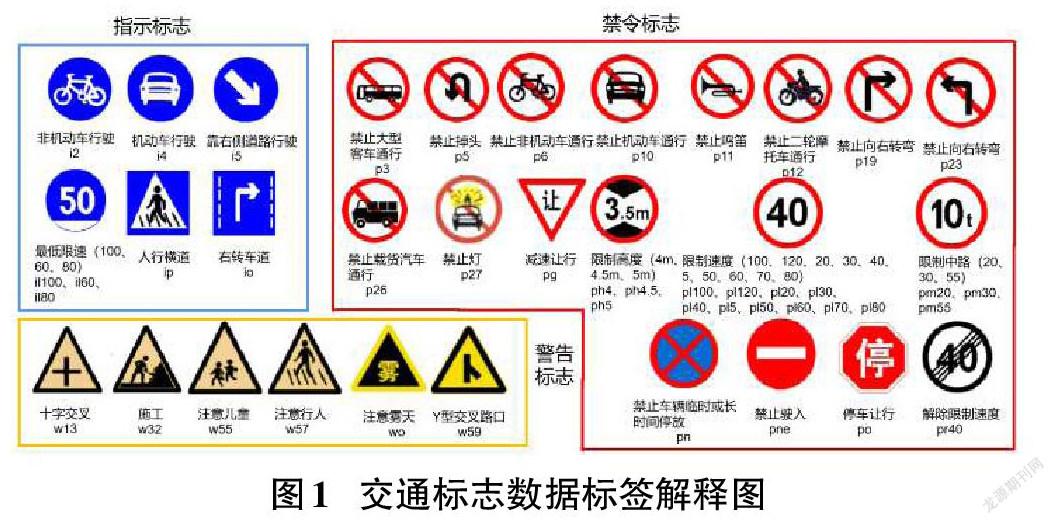
在训练深度学习目标检测模型之前,选择适合的数据集尤为重要。在交通标志数据集方面,当前公开且满足一定数量的数据集主要有五个。分别是针对美国交通的LISA数据集、针对比利时交通的BTSD数据集和针对德国交通的GTSDB数据集和TT100K数据集。本文选择针对中国交通的数据集TT100K数据集作为模型训练的数据集。如图1所示,从数据集中选出最常见的三类交通标志(包括禁令标志、指示标志和警告标志)。由于原始数据集数据巨大,本文從中选取在道路中出现次数最多的45类交通标志进行训练。
2.2 数据集标注
与进行图片分类的数据集不同,进行图片目标检测的数据集不仅需要给图片打标签,还要对图片中物体的位置信息进行标注。需要在标注文件中标明每张图片所在文件夹、图片名称、路径、大小(以像素为单位)、深度(图片通道数,通常为3)、特别是图中所出现的交通标志的标签、交通标志的坐标位置等。
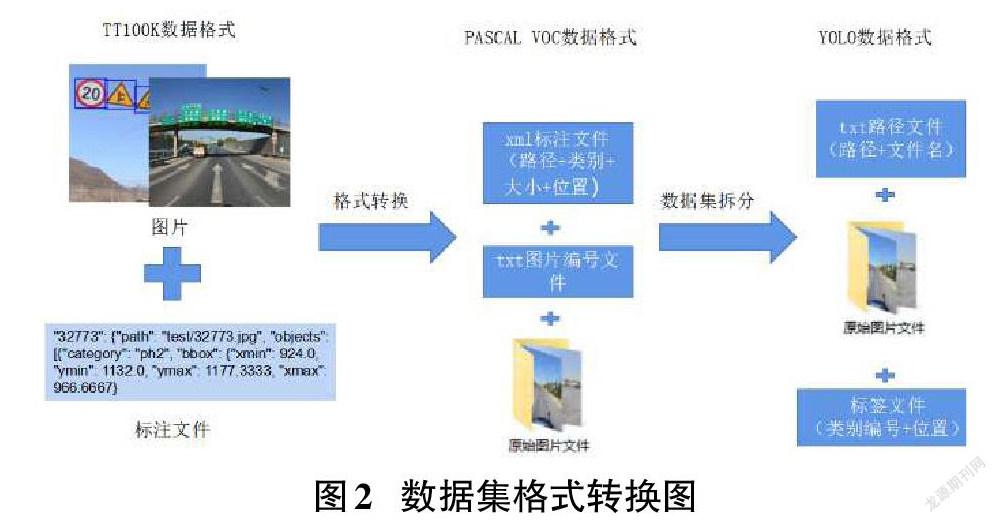
关于图片中物体位置的标注需先将原始数据集的格式转换为PASCAL VOC数据格式,再转换为YOLO数据格式,如图2所示。两种数据格式存在不同:PASCAL VOC数据包含了物体左上角横纵坐标和右下角横纵坐标。YOLO格式关于物体的位置信息则为目标的中心点横坐标与图片总宽度之比、目标的中心点纵坐标与图片总高度之比、目标框的宽度与图片总宽度之比、目标框的高度与图片总高度之比。
2.3 训练模型构建
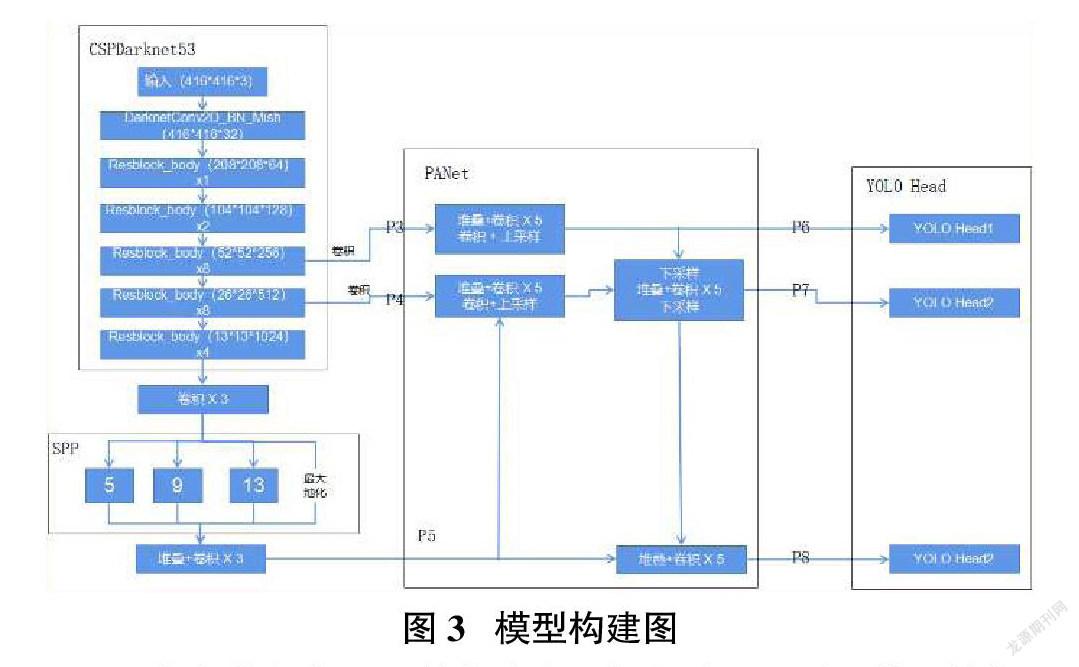
准备好数据集后开始构建交通标志检测所需的模型结构。如图3所示,本文使用模型的主要结构有4个,分别是CSPDarknet53、SPP、PANet和YoLoHead结构。CSPDarknet53负责对接收的图片数据进行初步的特征处理,接收的图片数据大小为416px*416px。使用连续堆叠的卷积能够提取更高维度的特征信息。SPP和PANet为特征金字塔,对不同大小的卷积输出进行差异化处理。
YOLOHead结构负责对接收的特征层进行分类检测。经过前面结构的特征提取后,会输出三类不同尺寸大小的卷积层。YOLOHead分别将这三类卷积特征换分成不同大小的网格。每个网格对类别进行预测,将最后得到的3个预测框与预先设置好的anchor尺寸大小进行NMS(非极大值抑制),保留尺寸最佳的预测框。最后,将预测框送入回归算法中进行分析,得出预测框的最终类别。
2.4 模型训练
模型参数设置是不断测试与调整的过程。经过多次训练调整,设置最优的模型训练参数。接收的训练图片格式为3通道、大小为416px*416px。每一批训练的样本数量为16,总共训练90000批次。学习动量为0.949、学习率为0.001,在训练批数达到1000次后采用余弦退火衰减的方式更新学习率。训练批数迭代到72000次和81000次时,依次在原来的学习率基础上衰减10倍。
为了在提高模型精度的同时减少训练时间,采用特定模型预训练后进行迁移学习予以辅助。本文预训练为学习完COCO数据集后获得的模型。COCO数据集包含的数据种类多、且多为真实场景中的数据,与本系统模型要训练的数据集更贴合。
2.5 模型优化
要想使模型检测達到理想的精度,除了高质量的数据集和选择正确的神经网络结构还需要对模型进行不断的优化。常见的模型优化方法有变换激活函数、更换学习率、增加数据集多样性等。本文采用的模型优化方法有使用mish激活函数、采用masaic对样本进行数据增强、使用余弦退火衰减变换训练时的学习速率和在选择预测框时使用CIOU策略进行计算。
本系统中除了对图片进行自适应对比度变换还进行了masaic处理。masaic是一种可以完整进行图片数据增强的策略。如图4所示,在图中最左端的原始图像中,masaic对每一张图片随机进行方向上的转变、图片大小的调节和图片色域的变换,丰富图片类型。每张图片进行第一轮处理后会归为合适大小,由原来的四张图片合成为一张图片。如此一来,原本单一的图片背景将更加多样,模型从一张图片中学习到的信息也更多。在节省训练计算资源的同时也提高了模型的泛化效果。
2.6 模型评估
对模型进行评估有利于对模型进一步的优化,保障模型的质量。本文中的模型评估通过Map值、损失率、平均精确度等对模型进行多方位的考量。
如图5给出了模型评估实验,横坐标为模型训练的批次数,纵坐标为损失值与Map值。损失曲线用蓝色表示,Map值曲线为红色表示。
[AP=R∈(0,0.1...1)maxρ(R)] (1)
[Map=APC] (2)
如公式(1)所示,R为召回率(recall),召回率为正样本中预测正确的数量与所有正样本之比。准确率则为预测正确的数量与所有预测结果之比。一个模型中有多个召回率与准确率,为了使评价系数更全面,使用公式(1)将召回率与准确率结合运算得出平均准确率AP。将所有的召回率R平分为11个区间,每个区间内包含多个准确率。将这些在同一个区间内的准确率集合用表示。每个区间内最大的准确率用maxρ(R)表示。最后将得到的11个数值求得均值结果就是平均准确率。而Map值则可以用公式(2)得出。AP为平均准确率、C表示模型需要识别的类别数。平均准确率与类别数之比为Map值。在训练完成后,平均损失低至0.1774,Map值也达到了89.8%。效果良好,优于大多数预测模型。
将模型与训练相同样本的其他模型进行对比。如图6中与Fast-rcnn模型对比,柱形图表示Fast-rcnn模型的平均准确率、折线图表示本系统给出的模型平均准确率。横坐标为预测的标签名称,纵坐标为平均准确率数值。检测结果显示本系统模型的检测效果精度高,每类标签识别精度差距小且都优于Fast-rcnn模型。
3 系统实现
在模型实验情况良好的情况下,为了将模型部署在终端中进行简单操作即可使用:运用PyQt5语言搭建桌面程序。终端程序包含三个主要功能:对图片进行交通标志检测、对视频进行交通标志检测和对摄像头进行交通标志检测。如图7所示,显示了终端进行视频交通标志检测的画面。当用户运行软件时,点击视频检测按钮即可选择对应的视频文件进行检测。与摄像头检测与图片检测相似,程序会将检测的原始画面与检测后的画面同时显示。并将检测到的交通标志截图放大显示。在文本框中,会显示对应的检测结果,显示顺序为交通标志对应的标签名和交通标志在画面中的坐标位置。程序还能够对检测信息进行保存与录像,大大方便了用户使用。
4 结论
基于目标检测YOLOv4模型,在TT100K数据集上进行训练,并且在经过模型训练、优化与评估后取得了Map值为89%的良好性能,实验表明,模型在速度与精度上具有较好的竞争力,通过PyQt对模型进行集成,给出了初步的应用系统方案,后续将深入对模型检测速度与精度的进一步提升。
参考文献:
[1] Nandi D,Saifuddin Saif A F M,Paul P,et al.Traffic sign detection Based on color segmentation of obscure image candidates:a comprehensive study[J].International Journal of Modern Education and Computer Science,2018,10(6):35-46.
[2] Gao X W,Podladchikova L,Shaposhnikov D,et al.Recognition of traffic signs Based on their colour and shape features extracted using human vision models[J].Journal of Visual Communication and Image Representation,2006,17(4):675-685.
[3] 张传伟,李妞妞,岳向阳,等.基于改进YOLOv2算法的交通标志检测[J].计算机系统应用,2020,29(6):155-162.
[4] 魏龙,王羿,姚克明.基于改进YOLO v4的小目标检测方法[J].软件导刊,2021,20(7):54-58.
[5] 何锐波,狄岚,梁久祯.一种改进的深度学习的道路交通标识识别算法[J].智能系统学报,2020,15(6):1121-1130.
[6] Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[7] Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection[J]. arXiv preprint arXiv: 2004.10934, 2020.
【通联编辑:梁书】