基于网络关注度的旅游客流量预测研究
2021-08-04王亮
王 亮
(三亚学院 财经学院,海南 三亚 572022)
随着人们物质生活水平的提高,旅游成为人们休闲活动的一种重要方式。国内知名旅游城市、景点客流量逐年攀升。特别是在重要节假日,不少旅游景点出现交通拥堵、客流量超景点承载能力的情况。2012年“十一”黄金周期间,陕西华山旅游景区甚至因此暴发了轰动全国的伤人事件, 引起了社会广泛关注。2013年,“十一”黄金周期间,四川九寨沟景区发生游客滞留事件。如何科学规划旅游资源,及时对客流量进行预警,避免因游客过载对自然资源造成破坏,促进景区可持续发展显得尤为紧迫和重要。
一、文献综述
用网络搜索数据预测疾病疫情的暴发是最早应用网络搜索关注预测社会经济行为的研究。金斯伯格(Ginsberg)等发现谷歌(Google)中与流感相关的部分关键词搜索量与美国疾病控制和防治中心发布的流感看诊量数据有很强的相关性,由此构建了基于搜索数据的监测模型,该模型能比传统监测方法提前两周测算出流感的暴发趋势。[1]此后,国内外学者基于谷歌和百度搜索指数在个人消费、人们对旅游目的地城市的搜索行为、销售行业、酒店入住需求、博物馆客流量等进行研了诸多研究,尤其在旅游需求预测研究方面,发展迅速,成果突出。
杨扬等运用加权谷歌趋势指数预测了旅游目的地的客户需求,发现增加了谷歌趋势变量的移动自回归模型更具有稳健性。[2]崔贤英、范星安(Choi and Varian)用美国商品零售、汽车销售和房地产行业Google趋势数据建立时间序列模型,发现搜索数据对未来具有预测作用。[3]Pan等用目的地营销组的网络流量数据来预测酒店的需求,得到了较好的预测效果。[4]王玉霞、王静通过VAR(向量自回归)模型验证了基于百度网络搜索数据的网络关注度对首都博物馆客流量的前兆效应, 但首都博物馆的客流量对网络关注度的影响却并不显著。[5]张玲玲等指出,百度指数的某类关键词搜索趋势对旅游消费市场变化具有超前指示作用,只有这类关键词才具有预测能力和价值,通过建立不同回归模型分析得出,加入历史数据与搜索关键词指数的预测模型拟合度高于仅使用历史数据和仅用搜索指数的预测结果。[6]
总体上来看,国内外基于网络关注度的旅游预测相关研究的框架已较为完善,已形成了关键词数据处理、模型设置、结论分析的较为系统的流程处理方式。刘鹰等详细地介绍了一种基于时差相关系数和K-L距离(K-L distance)的搜索关键词指数合成方法CLSI(composite leading search index)。[7]袁庆玉等基于百度整体指数数据,利用时差分析的相关系数法合成了我国流感疫情指数,预测结果显示,流感疫情指数可提前一个月预测流感疫情暴发,并且平均绝对百分误差小于11%。[8]杨欣等利用时差分析的相关系数法合成了海南省旅游量的谷歌和百度指数,并比较了两种搜索引擎在客流量预测上的差异。[9]关键词数据处理是影响模型预测结果的重要因素,它分为获取基准关键词、关键词扩展、关键词合成三个步骤,但现有研究多集中于对引入了网络关注度的时间序列模型与传统时间序列模型预测能力的对比之上,而对关键词本身的数据处理过程的相关研究很少。本文拟比较关键词合成的CLSI和K-L距离法在模型预测准确性方面的差异,希望推进基于大数据旅游预测有关研究和实践。
二、数据来源
(一) 客流量数据
考虑到数据的可得性和完整性,本研究采集了海南省国内过夜旅游客流量月度数据,时间跨度为72个月,数据来源于海南省海南旅游发展委员会官方网站的“旅游统计”信息公开栏目。
将海南2013年1月至2018年12月的月度国内过夜旅游客流量按照年分类后,按照月度展开,得到其时间分布图,如图1所示。
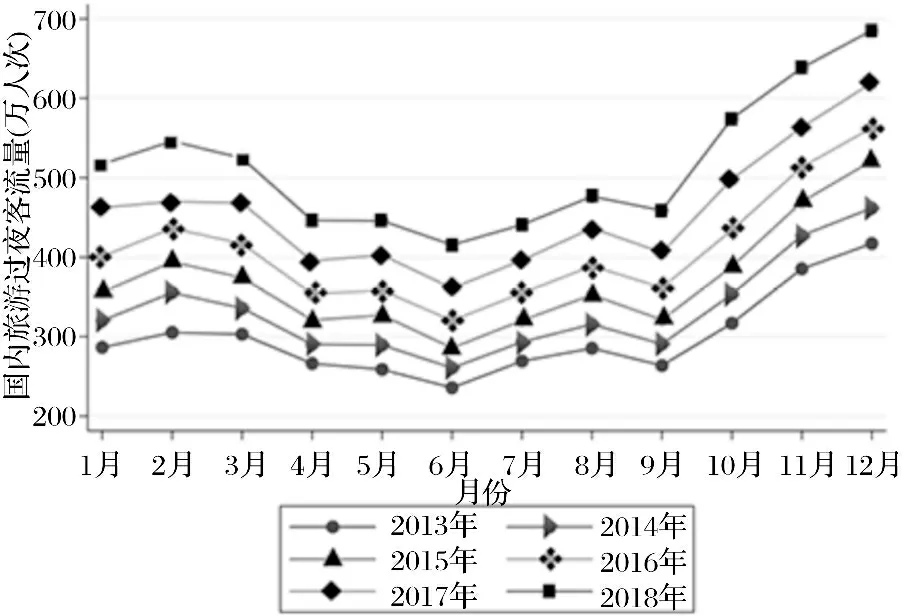
图1 海南国内过夜旅游客流量时间分布
在这6年中,国内过夜旅游客流量表现出了一致的时间趋势性和季节效应特点,整体呈现波动增长特征。一年之内 ,共有4个波峰,分别是2月份、5月份、8月份和12月份,国内过夜旅游客流量在12月份出现最大值。与此对应,一年之内,共有4个波谷,分别是1月份、4月份、6月份和9月份,国内过夜旅游客流量在6月份出现最小值。从各年的客流量水平来看,海南国内过夜旅游客流量呈现出较强的周期性变化特点。第四季度是旅游旺季,国内过夜旅游客流量从9月份开始回升。第二季度是旅游淡季,国内过夜旅游客流量从2月份开始减少。从年度整体水平来看,这6年间,国内过夜旅游客流量有连续性稳定增长趋势。
(二)百度搜索数据
百度指数是以百度网页和百度新闻数据为基础的数据分享平台,是当前互联网乃至整个数据时代最重要的统计分析平台之一。它是以网民在百度的搜索量为数据基础,以关键词为统计对象,科学分析并计算出各个关键词在百度网页搜索中搜索频次的加权和,并以曲线图的形式展现; 该指数反映了每个关键词在过去一段时间“用户关注度”的变化态势和网民需求。[10]
为了能够尽可能准确地反映旅游者的需求,我们利用百度指数平台的“需求图谱”功能对搜索关键词进行了挖掘。具体步骤如下。
(1) 在百度关键词主界面的搜索框中键入中心检索词“海南”,检索日期为2019年9月2日。点击“需求图谱”超级链接进入“需求图谱”界面,得到相关词若干。默认状态下这些相关词以周为时间跨度,显示过去一年以来中心检索词的相关词的变化趋势,与中心检索词关系越近相关关系越强。我们以周为时间跨度,获得了2018年9月至2019年9月一年以来,中心检索词“海南”的所有关键词,去除重复和与旅游主题不相关的关键词后,得到初始关键词21个,见表1。

表1 初始关键词
(2)分别用“站长之家”(http:∥s.tool.chinaz.com/baidu/words.aspx)和爱站网(https:∥ci.aizhan.com/6d775357/)的关键词挖掘工具,对初始关键词进行数据挖掘,去除重复、与本研究主题不相关的关键词后,得到在两数据挖掘工具中出现频率较高的关键词91个,见表2。
通过Python爬虫技术,我们得到了这91个搜索关键词的全国范围内的百度指数整体数据,时间跨度为2013年1月1日至2018年12月31日共2193天的。由于百度指数整体数据以天为单位发布,为了和旅游客流量的月度数据保持在同一量级水平,我们将初始爬虫数据按天加总成月度数据,得到了91个搜索关键词的月度指数整体数据,时间跨度为72个月。
表2 高频关键词
三、关键词的合成
(一)CLSI指数合成法
为了减少异常值和单位不同给预测准确性带来的影响,我们对客流量数据和百度指数整体数据取自然对数。按照CLSI指数合成法的原理,关键词的合成分为如下步骤。
步骤1: 设通过数据挖掘得到的91个关键词为indexi,旅游客流量数据为travelt,分别计算关键词与客流量间的0—6期提前期的时差相关系数,即每个关键词对应7个时差相关系数。
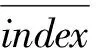
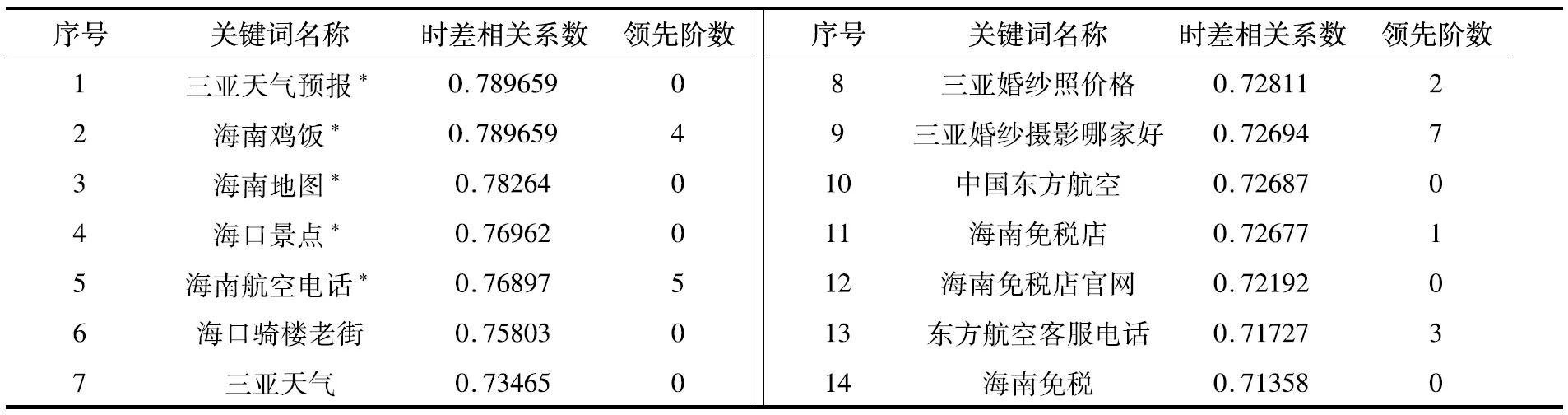
表3 部分关键词的时差相关系数排序
步骤2: 设合成指数为compj,定义
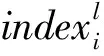
步骤3: 由于单个关键词对模型的拟合优度贡献是有限的,用
travel=α0+α1compj+ε
(1)
确定最终的关键词。具体做法是: 计算上述合成指数comp与旅游客流量travel的时差相关系数,对其从大至小进行排序,取时差相关系数最大的时间序列作为逐步回归的初始序列,用旅游客流量对其进行回归。按照关键词的最大时差相关顺序,依次向上述模型加入关键词,若按照时差相关系数由大至小的顺序依次进行回归,新加入的关键词的偏F统计量显著,则表明该关键词有助于提高模型的拟合优度。最终合成指数所需要的关系词,见表3中带*者。
(二) K-L距离合成法
K-L距离,也就K-L信息量(K-L Divergence), 是20世纪中叶由Kullback和Leibler提出的,用于度量两个概率分布的相似程度,越相似即距离越近。
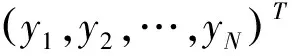
其中,pi和qi按照下式进行标准化:
当基础指标与备选指标完全一致时,K-L距离为零,基础指标与备选指标越接近,其值的绝对值越小。
为了与CLSI指数合成法对应,我们分别计算了91个高频关键词0—6阶提前期的K-L距离。部分关键词见表4。
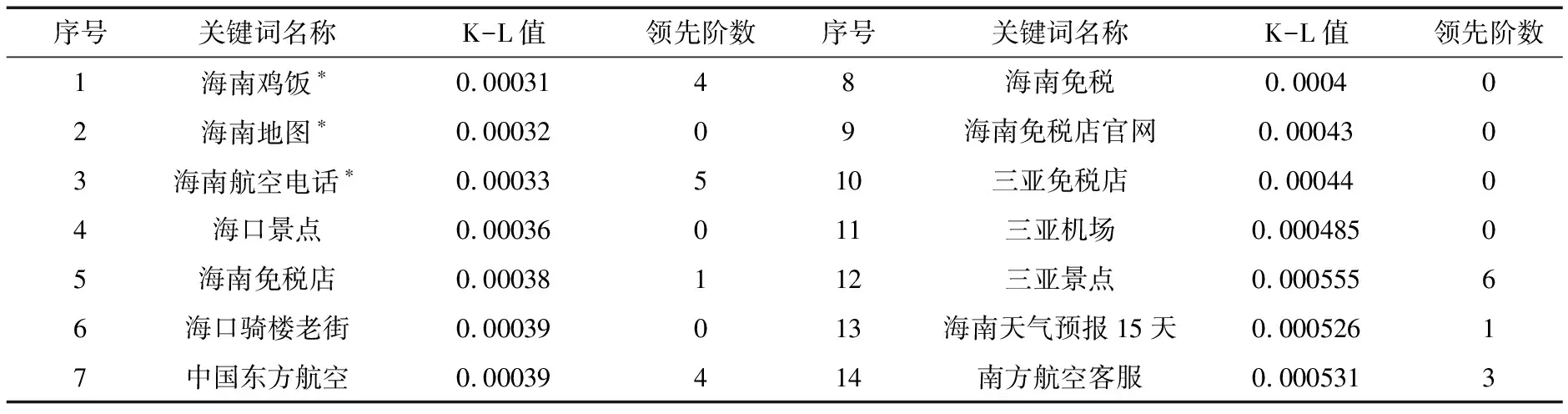
表4 部分关键词的K-L距离排序
同CLSI指数合成法类似,用 (1)式确定最终关键词。取K-L值最小的关键词index24作为逐步回归的初始关键词,依次加入其他关键词,通过偏F统计量确定该关键词能否增加模型的拟合优度。最终合成指数所需要的关系词,见表4中带*者。
四、实证分析
(一)模型设定
我们将百度关注度作为外生变量,引入到ARMAX(加入外部变量的自回归移动平均模型)中,
(2)
yt是自变量,xt是可包含滞后项的外生变量,如果β为零,该模型即为标准ARMA(m,n)自回归移动平均模型。ARMAX结合了经典时间序列预测和多元回归预测的方式和优点,能够探讨变量之间的相关性,提高经济预测的准确性。为了保证εt为白噪声,一般需要通过平稳性检验、ACF(自相关函数)图、PACF(偏相关函数)图,结合AIC(赤池信息)和BIC(赤池信息)准则等确定m和n的值。
考虑到因变量时间序列的季节性变化特点,我们引入滞后期为12的自回归模型作为基准模型,将CLSI指数合成法和K-L距离合成法作为对比模型。为了检验模型的预测能力,我们将2013年1月至2018年6月的时间序列数据作为训练集,将余下的6个月数据作为训练集。建立如下模型:
travelt=c+α1travelt-12+μt
(3)
travelt=c+α1compclsit+μt
(4)
travelt=c+α1compklt+μt
(5)
其中,travelt-12代表旅游客流量的满后12期项,compclsit代表t期CLSI指数合成法合成指数,compklt代表t期K-L距离合成法合成指数。
为了尽可能减少异方差对模型估计的影响,回归中使用了异方差稳健标准差。回归结果表明,所有模型参数均在1%显著性水平显著。三个模型的残差序列均平稳,表明了模型设置的正确性。为了进一步检验模型的预测能力,我们用预测集数据对各模型的预测准确性进行了分析。

表5 模型回归结果
(二) 模型预测
式(4)和式(5)的拟合结果如下:
travelt=2.736682+0.1449797compclsit+μt
ut=0.912936ut-12+εt+0.7235805εt-1
(6)
travelt=1.651482+0.144001compkl+μt
ut=0.9042669ut-12+εt+0.7280111εt-1
(7)
基准模型和两对比模型的拟合结果如表6所示。

表6 模型预测结果
我们用MAPE(平均绝对误差比)和RMSE(均方根误差)考察各模型的预测情况。相关结果见表7。
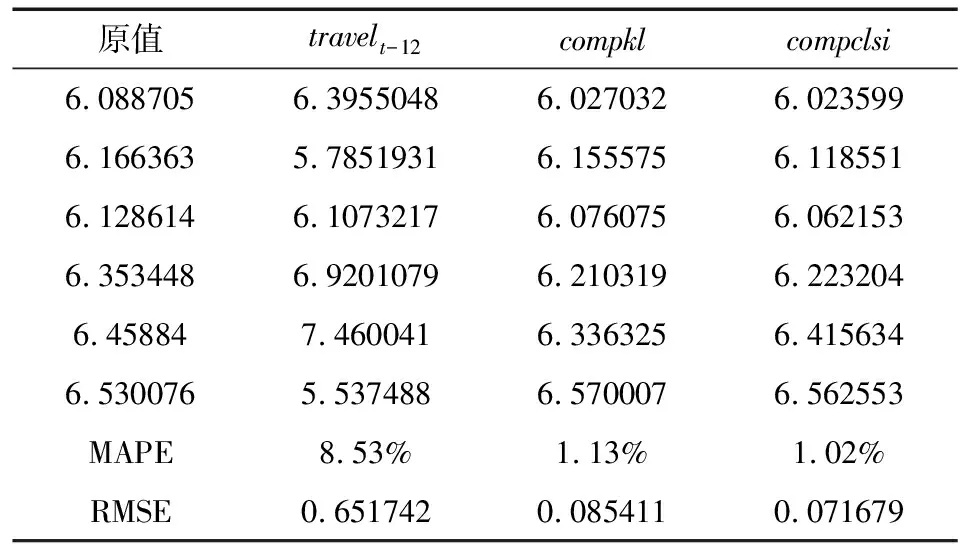
表7 模型预测误差
预测结果表明,CLSI指数合成法的MAPE和RMSE最小,K-L距离合成法的MAPE和RMSE介于基准模型与CLSI模型之间,基准时间序列的MAPE和RMSE最大。CLSI指数合成法、K-L距离合成法有助于提高旅游客流量的准确率,前者的预测准确性稍高于后者。
五、结论
本文利用引入了百度指数整体数据的自回归移动平均模型,比较了两种指数合成方法的预测效果。研究结果表明,CLSI指数合成法有助于提高旅游客流量的准确率,K-L距离合成法在提高旅游客流量预测准确性方面的作用不明显。利用网络搜索数据的旅游需求预测能够显著提高客流量预测的精度和时效性。
以往人们研究的数据主要是通过调查手段获得的结构化数据,碍于传统统计方法和手段,这些数据滞后性较强; 而大数据时代,互联网为我们提供了海量的图片、声音、文字等时效性较强的非结构化数据,这些数据为我们及时了解网民的行为方式、偏好和意愿,提供了更加丰富的信息。百度、谷歌的指数平台提供了大量的以天为单位的关键词指数信息,这些关键词指数信息反映了目的地旅游的潜在需求,因而,网络关注度与旅游客流量有正向相关关系。在实际应用研究中,关键词的选择对模型预测结果有重大影响,因此,需要通过其他技术手段,确定具有代表性的关键词。
大数据时代海量数据为我们及时了解广大网民的旅游需求提供了可能。基于网络关注度的旅游客流量预测尚处于探索阶段。在现实生活中,不是所有旅游者都通过百度平台获取旅游资讯,比如可用的资讯渠道还有其他搜索引擎服务商提供的搜索服务、微信和微博等社交媒体平台的信息交流,甚至是亲朋好友旅游后的口口相传等,因此,借助大数据技术,获得更加全面的旅游需求信息是我们下一步研究的方向 。
