基于多元高斯模型的跟驰轨迹评价方法研究
2021-05-13高建设柏海舰
高建设,柏海舰
(合肥工业大学 汽车与交通工程学院,安徽 合肥 230009)
由于机器学习的快速发展,机器学习模型已被应用在很多领域,如自然语言处理、机器翻译、语音识别、手写识别及视频标记等模型中[1~4]。在跟驰模型研究中,有较多学者使用NGSIM数据集[5]训练模型,通过学习人的驾驶行为去再现真实交通流现象,然而评价模型的方法仍比较传统和单一,如轨迹层面的均方误差对比等方法。传统的评价方式是将学习到的模型进行单一轨迹仿真,与真实轨迹在空间位置维度上使用均方误差进行对比,进而比较模型的优劣。该模型存在的问题主要有两个方面:首先,原始轨迹不一定是一条值得学习的轨迹,由于人的行为具有一些随机因素在其中,单个个体的驾驶行为也很难一直保持不变;其次,驾驶行为也不能单纯地使用位置偏差来评判,应结合速度或加速度进行综合评判。
Parham[6]使用支持向量回归方法,采用加速度的相关系数(R)和均方误差(MSE)作为评价标准,仿真发现SVR模型得出的跟驰反应时间和轨迹数据更接近真实数据。Alireza[7]建立人工神经网络模型,并将驾驶员的瞬时反应时间加入到输入端,输出后车的加速度,使用平均绝对百分比误差(MAPE)、均方根误差(RMSE)、标准差(SDE)与真实数据进行对比。Gao[8]使用逆强化学习,通过建立R函数的方式使车辆可以进行一系列连续的控制过程。M. Zhu[9]使用真实跟驰数据校准深度强化学习模型,学习人类的驾驶行为,并使用均方根百分比误差(RMSPE)进行速度及位置上的误差分析。Daniel Meyer-Delius[10]使用隐马尔可夫模型,证明了后验概率作为选择两个竞争情境模型标准的有效性。Z. He[11]使用K近邻模型去学习真实数据集,在位移上使用相对误差(RE)进行对比,验证了该模型可使用在交通流仿真中。YANG[12]结合了Gipps模型去除轨迹中的不安全行为,不断完善数据集去训练随机森林模型,使用平均绝对误差(MAE)和平均绝对相对误差(MARE)来对比速度误差。M. Zhou[13]建立了最经典的循环神经网络模型去学习人类驾驶行为数据,得出的模型比IDM等模型更接近真实轨迹,比照方法为均方误差(MSE)。X. Huang[14]使用LSTM神经网络得出的模型,验证模型可以再现走走停停的交通现象,使用的轨迹评价标准包括相关系数(R)和速度与车头间距的均方误差(MSE)。上述学者在进行仿真轨迹评价时大多使用了轨迹层面的误差分析,和原始轨迹进行加速度、速度及位置上的对比,但此评价方式存在两方面的问题:一是原始轨迹不一定值得模型去学习;二是考虑的因素单一且独立,无法全面评价一条轨迹的驾驶行为。以上问题的存在使得该模型效果不显著。
采用机器学习模型来学习跟驰数据,学到的是多数人的行为,所以模型的仿真轨迹应当更大众化。本文提出使用多元高斯模型来评价模型的轨迹仿真效果,将车头间距和前后车相对速度作为自变量,计算每一时刻的车头间距和相对速度在全体样本中出现的概率值,并以此概率值作为轨迹优劣的评判标准。
1 多元高斯模型
多元高斯模型常被应用于异常识别[15-16],在跟车行为中,每一个驾驶员主要根据自身和前车的距离、与前车的相对速度来采取相对应的动作,所以本文将车头间距和相对速度作为评判驾驶员驾驶行为的标准。因此,建立的多元高斯模型自变量就是车头间距和相对速度,并未将跟驰车辆的速度考虑在内,速度的大小主要取决于车流是否拥堵,不能反映驾驶人的跟驰行为。多元高斯模型需要自变量都服从高斯分布,两个自变量的频率分布如图1所示,从图1可以看出,相对速度比较符合高斯分布的特点,车头间距的数据将其取对数后,使用高斯分布进行拟合。

图1 车头间距对数和相对速度频率分布
建立的模型为
x=[ln (Δx),Δv]T.
(1)
式中:x为多元高斯模型自变量,Δx为车头间距,Δv为相对速度。
(2)

在仿真轨迹中每一个时间步都可使用此模型来计算概率值P(x)。
2 数据预处理
机器学习跟驰模型需要位置、速度及加速度信息,速度和加速度分别通过对位移进行一阶和二阶差分获得,由于差分次数越多误差越大,所以NGSIM数据集显得精度不足,需要对数据集进行平滑等方面的预处理。本文使用对称指数滑动平均方法进行轨迹数据平滑,数据的处理步骤如下。
步骤1:使用对称指数滑动平均(sEMA)平滑车辆轨迹沿前进方向的位移数据;
步骤2:分别使用一阶差分和二阶差分,获得车辆在每个时间步(0.1 s)的速度和加速度;
步骤3:通过步骤1和步骤2对数据的处理,发现处理后的速度和加速度会在首端和末端的小范围内产生突变,突变的原因是这部分数据平滑窗口比较小,所以要剔除每个轨迹第一秒和最后一秒的轨迹数据。
对称指数滑动平均(sEMA)公式为
(3)
其中
(4)
平滑宽度为
(5)

依照以上步骤处理的轨迹速度和加速度轨迹时空如图2所示,描述两条轨迹的时间-位移变化。图3为轨迹速度时间图,描述两条轨迹的速度随时间变化情况。图4为轨迹加速度时间图,描述的是两条轨迹加速度随着时间的变化情况。从图4可以看出,加速度的变化区间基本稳定在-4~4 m/s2之间,符合现实场景中的驾车数据。

图2 轨迹时空

图3 轨迹速度时间
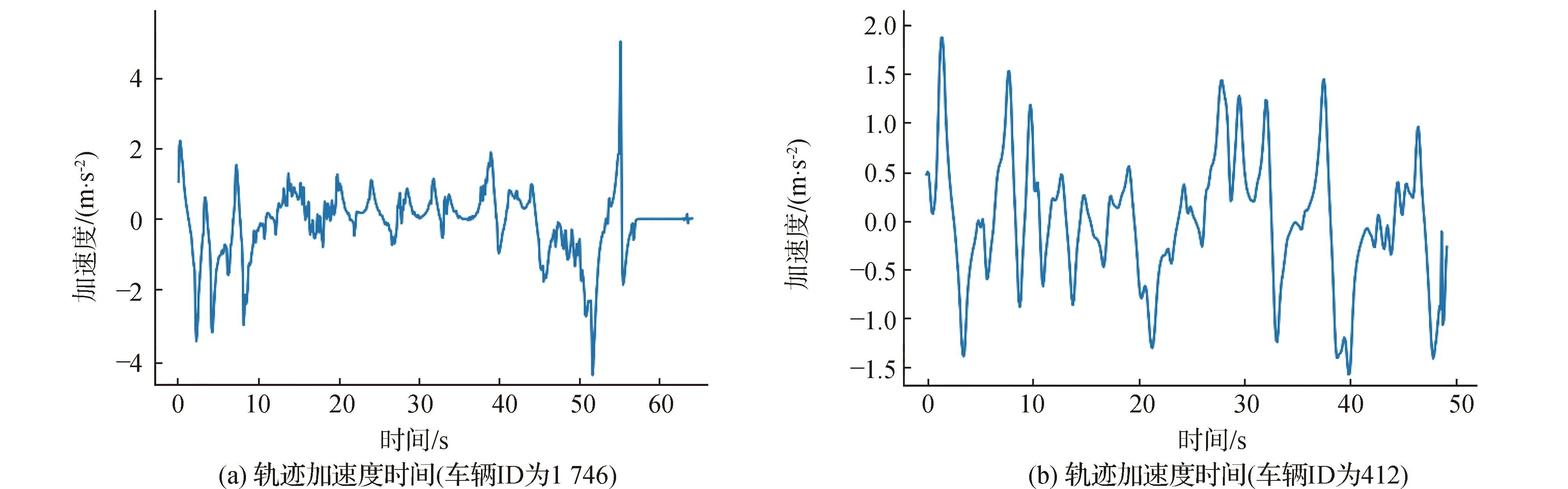
图4 轨迹加速度时间
3 KNN模型仿真
本文使用的机器学习模型为K近邻回归模型,该模型已被广泛应用于各种分类和回归任务[17-18]。将K近邻回归模型做简单介绍,样本总量为N,xi为样本中第i个样本的特征数据(输入数据),本文选择的输入数据有3个,分别为车头间距、相对速度和后车速度。yi为第i个样本的属性值(输出数据),本文的跟驰模型选择跟驰车辆下一个时刻的加速度作为输出数据。待预测样本为x,表示输出样本距离与之最近的K个样本属性的加权平均值。K近邻回归模型有3个超参数需要调节:k值的抉择,样本间距离的度量模式,样本距离的加权方式。k值选择测试集中均方误差趋于平稳值,样本距离度量方式选用欧式距离,样本属性值的加权方式采用样本间欧式距离的倒数进行加权,计算式为
xi=[Δx,Δv,v],
(6)
dij=‖xi-xj‖,
(7)
(8)

k值的选择使用均方误差作为评价标准,通过比较选取200个不同的k值得到模型的均方误差。从图5可以看出,均方误差随着k值的增加而降低,当k值大于100时下降趋势基本趋于平稳,所以本文中k值取100。

图5 MSE变化趋势
仿真轨迹的获得方法有两种:第一种方法是假设一直给出前车的轨迹,通过模型生成跟随者的轨迹;另一种方法是通过数据仅确定第一个前车和所有追随者的初始/边界条件,并通过模型计算一组后续车辆轨迹[21]。本文的轨迹仿真均采用第一种方法,仿真公式为
at+1=KNN(Δxt,Δvt,vt),
(9)
vt+1=vt+at+1·Δt,
(10)
xt+1=xt+vt·Δt+0.5·at+1·Δt2.
(11)
仿真效果如图6所示,1 732~1 739和503~538为原始数据中的前车与后车编号。图6(a)中的仿真轨迹更接近真实轨迹,说明相比图6(b)而言,图6(a)的轨迹更接近真实数据。跟驰模型要考虑的不仅有安全性还有效率,从图6(b)真实轨迹可以看出,后车与前车的车头间距较大,而且是在较低的车速下行驶,虽然安全性较高,但影响到整个交通流的效率,所以可认为该驾驶轨迹不是一个值得去学习的轨迹模型。图7中起点为轨迹中起点的车头间距和相对速度联合坐标,原始数据中心点为样本中车头间距和相对速度的均值点。图7(a)中仿真轨迹明显比真实数据偏离数据中心点多,而图7(b)中的仿真轨迹不断接近样本中心,真实轨迹不断偏离样本中心。从这个角度看,应该给图6(a)的仿真轨迹低于真实轨迹的评价,使图6(b)的仿真轨迹评价高于原始轨迹,但传统的均方误差和相关系数方法已经不再适用,所以需要使用前面介绍的多元高斯模型来重新评价轨迹。

图6 仿真轨迹

图7 轨迹在样本中趋势
使用多元高斯模型重新评估图6的两条轨迹,结果如图8所示,虚线代表的是真实轨迹在每一个时间步的多元高斯模型概率值变化曲线,实线代表的是K近邻模型的仿真轨迹在每一个时间步的概率值变化曲线。从图8(a)可以看出,在1 732~1 739的真实轨迹和仿真轨迹对比中,仿真轨迹的大部分时间步概率值要小于真实轨迹的概率值,说明仿真轨迹没有真实轨迹好。图8(b)503~538轨迹中虽然仿真轨迹偏离真实轨迹较多,但仿真轨迹的大部分时间步概率值都比真实轨迹高,说明仿真轨迹更接近样本中心。

图8 多元高斯模型轨迹评价
表1中,MSEx代表位移的均方误差,MSEv代表速度的均方误差,Rv代表速度的相关系数,Ra代表加速度的相关系数,均方误差越小,相关系数越大,说明仿真轨迹越接近真实轨迹。从表1的数据可以看出,MSEx,MSEv,Rv和Ra4个指标都说明1 732~1 739轨迹的仿真结果更接近真实数据,但相比503~538,多元高斯模型计算出来的概率要更小。从整体数据角度看,轨迹的车头间距和相对速度越接近样本中心越好,因为更靠近大部分人的驾驶行为。可以发现,并不是与真实轨迹对比误差越小说明仿真轨迹就越好,原因是原始轨迹可能并不是一条值得模型去学习的轨迹,原始轨迹可能在效率和安全性方面没有做好平衡。

表1 多种评价方式对比
通过表2可以看出,部分仿真轨迹在全样本数据上的概率值比原始轨迹高,通过多元高斯模型的计算可知仿真轨迹比原始轨迹好。此模型可以将概率值比原始轨迹高的仿真轨迹重新加入样本数据,来扩充和优化数据集,部分学者在研究基于数据的跟驰模型时已经考虑到对于原始数据集的扩充和改进问题[22],如果使用该模型评价轨迹的优劣就可以将仿真概率大于原始轨迹的数据加入到原始数据中,并进行重新训练。

表2 多元高斯模型评价的仿真轨迹与真实轨迹平均概率值对比
4 数据集清洗
跟驰数据的清洗工作已经有学者研究,文献[23]将车头时距和速度差作为判断自由流和跟驰状态的依据。由于现实交通流中出现一些危险或者低效率的驾驶行为,但安全性和效率又是很难通过人为平衡的两个属性,在进行人为轨迹筛选时可根据车头间距来筛选去掉车头间距小的不安全行为和间距过大的低效率行为,标准难以界定。目前的大多研究将人的驾驶行为分为激进型、普通型和保守型[24-25],激进型驾驶风格具有高效率的同时也具有高风险,保守型驾驶风格在具有高度安全性的同时也牺牲了效率,所以也无法根据这种分类方法进行轨迹筛选。研究发现,将多元高斯模型应用于跟驰数据清洗的方法更具科学性,可通过设定轨迹概率阈值来筛选轨迹。图9为当阈值为0.1时进行轨迹筛选所得的车头间距-相对速度图,原始数据集共有1 030条轨迹,阈值大于0.1的轨迹有521条,小于0.1的轨迹有509条。从图9的展示结果看,轨迹的筛选工作已经不可以简单地使用车头间距这一指标进行轨迹筛选,因为轨迹数据已经出现较多交叉现象。
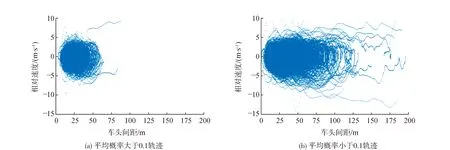
图9 平均概率轨迹
图10展示的是根据不同的阈值筛选剩余的轨迹数量;图11展示的是根据不同的阈值筛选后剩余轨迹的方差变化。从图11中可以看出,随着筛选阈值的增加,车头间距方差和相对速度方差都会不断减小,说明该筛选方法可使样本中驾驶行为越来越趋于稳定,证明该种筛选数据的方法更具有合理性。

图10 剩余轨迹数量随阈值变化

图11 方差随阈值变化
5 结 论
1)多元高斯模型的评价方法与传统均方误差等评价指标相比,主要有两个方面的改进:一是该模型从全样本数据集角度评价模型仿真轨迹的优劣;二是综合考虑了更多因素,加入了前后车的相对速度,能更详尽地描述驾驶行为。
2)该模型以单条轨迹概率作为评价指标,现实中部分驾驶员的驾驶行为属于异常轨迹,可使用该方法过滤数据集,选择一个概率阈值对原始数据集进行清洗,使得基于数据的跟驰模型避免学习到一些不安全或低效率的驾驶行为。
