随机森林算法在中医药院校贫困生认定预测中的应用研究
2017-07-01唐燕王苹
唐燕+王苹

[摘要] 中医院校的贫困生认定工作是非常重要的,但是目前的认定方法还存在着不科学不公正等问题。为完善贫困生的认定工作,本文基于随机森林分类算法,对贫困生的认定进行研究。在相同的数据集中,分别使用决策树算法和随机森林算法对贫困生进行分类,决策树算法的平均正确率为74.43%,而随机森林算法模型的平均正确率为85%,并进一步对两种算法进行比较。实验证明,随机森林算法分类正确率较高,适合贫困生的认定工作。随机森林为贫困生的认定提供了一种新方法。
[关键词] 贫困生认定;随机森林;决策树;机器学习
[中图分类号] R-3 [文献标识码] A [文章编号] 1673-7210(2017)05(b)-0164-05
[Abstract] It is an important task to identify the poor students in traditional Chinese medicine colleges and universities, and there are uneconomical and unjust problems in the current methods. In order to improve the identification of poor students, this paper based on the random forest classification algorithm to study the identification of poor students. In the same data set, the decision tree algorithm and the random forest algorithm are used to classify the poor students. The correct rate of decision tree algorithm is 74.43%, while the accuracy rate of the random forest algorithm model is 85%, and further comparison of the two algorithms. Experiments show that the classification accuracy of random forest algorithm is high, which is suitable for the identification of poor students. Random forest provides a new way for the identification of poor students.
[Key words] Poor students identification; Random forest; Decision tree; Machine learning
近年来,随着中医药类高校不断扩大招生人数,在读贫困生人数也明显增加。所谓贫困生是指家庭收入低,完成学业有经济困难的学生。数据显示,2015年,全国高校在校家庭经济困难学生比例超过40%,政府、高校及社会等各类政策措施共资助高校学生4141.58万人次,资助总金额847.97亿元[1]。可以看出,贫困生所占比例较大。但高校中也不乏出现为领取助学金而谎报为贫困生的情况。因此,如何精准地认定在校贫困生,更好的通过助学金帮助他们完成学业是一项非常重要而又意义深远的工作。目前,贫困生的认定工作人为因素较多,缺乏科学性和合理性,如何科学、公正、合理、高效的认定贫困生是亟待解决的问题。
1 高校贫困生认定研究
当前,很多高校的贫困生认定主要方式为:学生主动填写《普通本科高校国家助学金申请表》《普通本科高校国家励志奖学金申请表》等各类助学金申请表,各个班根据申请同学家庭情况、日常消费等情况做出初步评定。班级上报院系后,院系根据学校给定名额进一步评定,最后确定最终贫困生人选。这种认定方法掺杂人为因素,在贫困生的评选过程中很难做到公平公正、科学合理。
也有高校根据一卡通消费数据情况给出贫困生认定的一些限制条件[2],例如通过学生就餐、日常刷卡消费情况,给定学生最低生活保障线,由此确定贫困生。这种做法主要根据数据统计分析得出,有一定的科学性,但是认定指标过于单一,认定指标不够全面,存在片面性。
在贫困生认定问题上,很多学者应用数据挖掘和机器学习算法进行了一些有益的尝试。曹路舟[3]提出使用FP-growth算法找出贫困生数据之间的关联规则,为认定贫困生提供参考。陈晓等[4]提出基于加权约束的决策树方法建立贫困生认定决策树,通过决策树认定贫困生。杨知玲[5]和张建明[6]提出使用决策树算法构建贫困生认定决策树,从而提高贫困生认定的准确性和精度。马幸飞等[7]提出采用新距离标准的K-means算法对学生的三餐消费等情况进行聚类分析,从而为贫困生的认定提供依据。通过国内相关文献可以看出,在贫困生认定中,使用决策树模型进行分析的学者较多,还没有找到随机森林算法的相关研究文献。
本文结合申请表信息和一卡通消费数据,通过问卷调查获取数据,使用随机森林算法对贫困生的认定进行分析。通过实验,随机森林極大提高了认定的正确率,非常适合贫困生的认定工作。
2 随机森林算法
随机森林(random forest,简称RF)是2001年由美国科学院院士Breiman教授提出的,结合了Bagging和Random Subspace的思想一种算法。随机森林是由多个决策树而形成的一种集成分类器模型[8-9]。随机森林在Bagging基础上进行了改进,但是训练效率常优于Bagging[10]。随机森林算法执行效率较高,并且明显的提升了预测精度,被称为当前最好的算法之一。
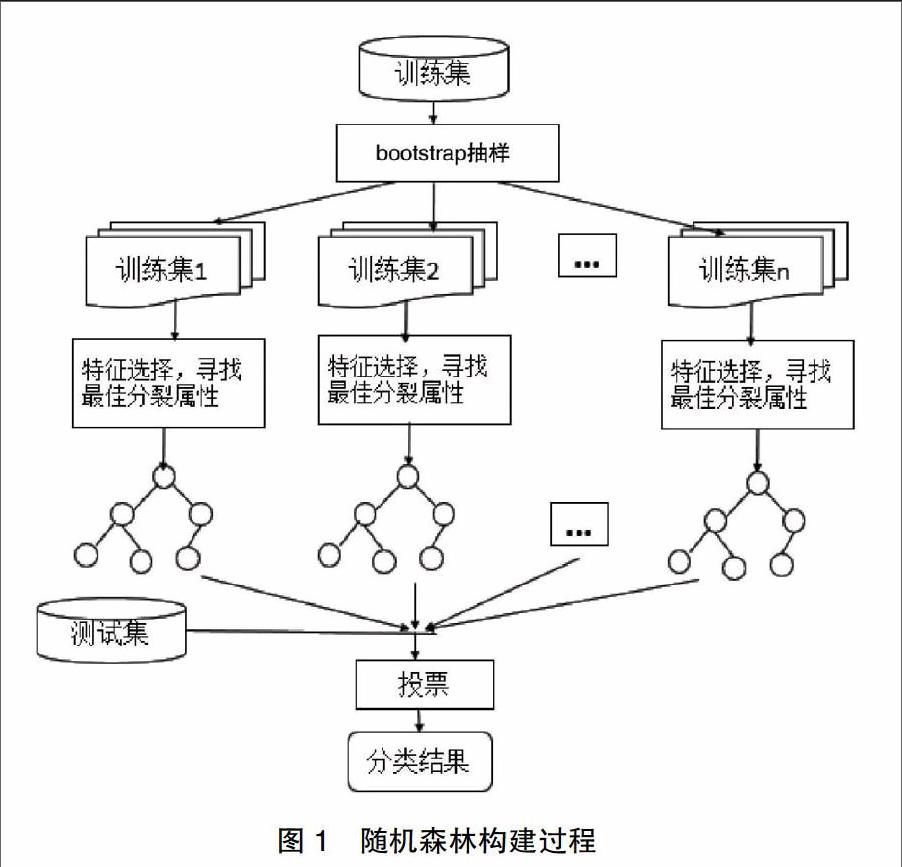
随机森林算法是由多棵决策树作为基学习器,利用Bagging生成不同的训练集,在单棵树的训练过程中引入随机属性选择,训练多次,得到多棵不同的决策树,将这些树组合成随机森林分类器。在分类时通过投票或取平均决定未知样本的类别。随机森林的构建过程见图1[11]。
随机森林的构建过程中关键步骤包括:随机生成训练集、生成多棵决策树、通过投票实现算法。随机森林算法的步骤描述如下:
①从数据集中利用bootstrap抽样法有放回地随机抽样,选取每棵树的训练样本集。初始训练集中,有些数据重复出现,有些从未出现。在训练过程中,每次抽样约有63.2%的样本被抽中,作为自助样本集,用来作为训练数据构建一棵决策树;剩余的36.8%的样本称为袋外数据,可作为测试集,测试分类误差[12]。
②每个自助样本集用来构建一棵决策树或条件树。假设每个样本有M个属性,在构建决策树时,每次随机选择m个属性(m ③每棵决策树的每一个节点都按照步骤②进行选择。使得每个节点的纯度最高,即Gini指数最小的属性作为最优划分属性,直到节点不能分裂为止。建立CART决策树。将上述过程重复多次,构建多棵决策树,形成森林[17]。 ④在测试集中,计算未知样本x分类为c的概率:P(c|x)=(1/nTree)·Σhj(c|x),采用多数投票法、平均法等结合策略确定类别。如果应用多数投票法确定类别,则c通过arg max P(c|x)得出[18-20]。 随机森林的构建过程中有两次随机,即样本的随机选择和属性的随机选择。这两次随机使得每棵树的构建过程中即使没有进行剪枝也不会出现过拟合情况。 3 实验分析 3.1 数据采集及数据整理 当前,很多高校依然通过学生填写贫困生申请表,班级评选确定贫困生。本文根据申请表填写的信息,结合学生每月消费情况和三餐消费情况,通过问卷调查采集4个平行班级的180条记录。数据涉及学生家庭信息、家庭经济状况、学生个人消费情况等方面。 采集到的数据包含12个属性,分别为:性别(X1)、城市/农村户口(X2)、家庭每月收入(X3)、家庭是否有残疾/危重病人(X4)、学生每月支出(X5)、每天生活消费(X6)、早餐消费(X7)、午餐消费(X8)、晚餐消费(X9)、是否有当地低保(X10)、来自省市(X11)、是否认定贫困生(Y)。 数据剔除缺失严重记录和异常数据,最后收集169条记录。根据4各班级评议结果,合并特别困难、一般困难为困难,用1表示,不困难用0表示。统计得出,困难64人,不困难105人。 为比较随机森林模型和决策树模型的分类预测效果,将数据集中的连续数据离散化。例如:将家庭每月收入分为<2000、2000~4000、4001~6000、>6000四个等级,分别记为1、2、3、4。 3.2 决策树和随机森林实验结果 3.2.1 决策树实验结果 针对文献中很多学者使用决策树对贫困生进行认定,试验中使用决策树中的ID3算法对数据进行分类,并进一步使用随机森林算法进行比较。实验使用python语言分别编写决策树分类算法程序和随机森林分类程序。 ID3算法的核心思想是在决策树的每一个非叶子节点划分之前,先计算每一个特征向量所带来的信息增益,选择最大信息增益的特征向量作为当前节点进行划分。因为信息增益越大,区分样本的能力就越强,越具有代表性,ID3算法是一种自顶向下的贪心策略。 决策树的构建过程是递归的过程,一般情况下,决策树深度越小,预测的正确率越低。当决策树的深度不断增加,叶节点不断增加时,预测的正确率会不断增高。但是,如果决策树深度过深,叶子结点太多,往往会导致过拟合,使得泛化能力变差。因此,需要通过剪枝在树的大小和正确率之间寻找平衡点。 和决策树相比较,随机森林通过两次随机,有效避免了过拟合的情况,并且有很好的抗噪能力,即当数据集中有缺失数据时对预测精度影响不大。随机森林在构建单棵树时,只选择部分特征属性(m=log2M,或者m= ),使得随机森林单棵树和决策树相比,特征属性远远小于决策树。构建的单棵树是不经修剪的完全树,树的深度较小,规模较小,树的结构比较简单。随机森林正是由多棵简单的决策树构成,预测时通过投票,以少数服从多数等方式显示结果。随机森林的单棵简单的决策树预测能力比较弱,属于弱分类器。但是,当很多棵树形成随机森林时,体现了集体的力量,预测效果优于单一决策树。因此,随机森林树的棵树越多,预测正确率越高,表现越稳定。 在实验中随机选择80%的数据作为训练数据,其余20%数据作为测试数据。当决策树的深度为3时,正确率最高。实验中生成的决策树见图2。 实验中,将决策树的深度从2递增到14,依次记录预测正确率为70.59%、82.35%、64.71%、73.53%、70.59%、73.53%、76.47%、76.47%、76.47%、76.47%、73.53%、76.47%、76.47%,平均正确率为74.43%。使用决策树进行分类测试,准确度不是很高。实验进一步使用隨机森林模型进行分类训练和测试。 3.2.2 随机森林实验结果 实验进一步在相同的数据集上使用随机森林算法进行分类。实验中继续随机选择80%的数据作为训练数据,其余20%数据作为测试数据。当给定树的棵树为20,树的最大深度为4时,运行程序10次,依次得到测试集的准确度为85.29%、88.24%、85.29%、91.18%、82.35%、85.29%、79.41%、88.24%、82.35%、82.35%,平均准确度为85%。随机森林算法的准确度明显高于决策树算法。
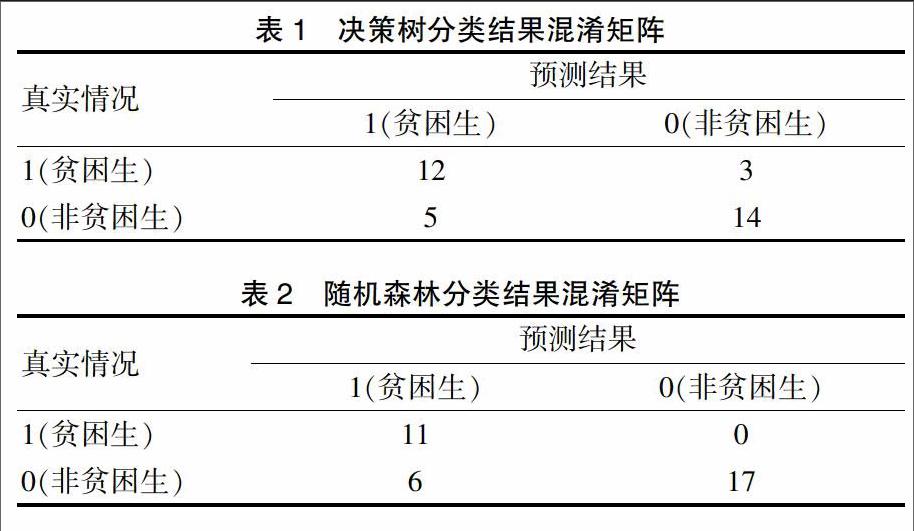
3.2.3 两种模型实验结果比较 本文中的贫困生认定是二分类问题,可以根据真实类别和学习器预测类别的组合划分为真正例TP、假正例FP、真反例TN和假反例FN。这4个值构成分类结果混淆矩阵。
当决策树的深度为5时,正确率为73.53%,与平均正确率最接近,此时决策树模型测试集的分类结果混淆矩阵见表1。
決策树模型认定贫困生的分类误差为0.2,认定非贫困生的分类误差为0.263。
选取随机森林模型某次程序运行结果准确度为82.35%时,测试数据集的真实值和与测试值,计算分类结果混淆矩阵见表2。
随机森林模型认定贫困生的分类误差为0,认定非贫困生的分类误差为0.26。可以看出,随机森林模型认定贫困生类别的准确度高于决策树,认定非贫困生类别与决策树相比略高一点。提示随机森林对贫困生类别的认定误差更低,更精确。
3.2.4 两种模型调整参数进一步比较 决策树算法中,树的深度有可能会影响预测的准确度,因此程序中将树的深度从2变化到15,计算不同深度时,决策树的预测正确率,并绘制曲线图。见图3。
随机森林算法中,设置树的最大深度参数分别为3、4或默认值None时,调整树的棵树从10变到50,计算测试集的正确率,绘制如图4所示的曲线图。
通过图3可以看出,决策树的深度较小时,正确率波动较大,当决策树深度不断增大时,正确率越来越稳定,但是正确率在0.7~0.8之间波动。从图4可以看出,随机森林单棵树的最大深度为3、4或默认值对正确率的影响不大。随机森林在树的数目较小时,正确率波动也较大,随着树的数目增大,正确率波动减小,始终在0.8~0.9附近变动。随机森林整体预测效果优于决策树。
4 小结
贫困生的认定工作在中医院校每年都要开展,这项工作对家庭困难的学子来说是至关重要,有可能影响他们的学业和前途。如何科学合理、公开公正的完成中医院校贫困生的认定工作是个非常值得研究的课题。本文根据贫困生认定中的常用数据指标和一卡通消费数据,使用数据挖掘的多种算法进行模型选择,经过试验,随机森林在贫困生的认定中表现突出,正确率大大高于决策树算法。并且随机森林算法模型训练速度快,不易产生过拟合,分类准确性较高。由此可以证明随机森林算法更加适合贫困生的认定工作,随机森林为贫困生的认定提供了一种新方法。此种方法可以在今后的中医药类院校贫困生认定工作中,与人为主观评定综合使用,提高中医药类院校贫困生认定工作的准确性与公正性。
[参考文献]
[1] 李书翔,赵裕慧,陈晓.数据挖掘在家庭经济困难学生精准识别中的应用研究[J].亚太教育,2016(30):292-293.
[2] 韩玉,施海龙,曲波,等.随机森林方法在医学中的应用[J].中国预防医学杂志,2014,15(1):79-81.
[3] 曹路舟.PF-growth算法在高职院校贫困生认定工作中的应用研究[J].西安文理学院自然科学版,2015,18(1):68-72.
[4] 陈晓,王树宝,李建晶,等.基于加权约束的决策树方法在贫困生认定中的应用研究[J].计算机应用与软件,2014, 32(12):136-139.
[5] 杨知玲.数据挖掘在高校贫困生评价中的应用研究[D].广州:华南理工大学,2015.
[6] 张建明.基于数据挖掘的高校贫困生认定系统设计和分析[D].南京:东南大学,2015.
[7] 马幸飞,李引.基于改进的K-means算法在高校学生消费数据中的应用[J].无锡商业职业技术学院学报,2016, 16(6):82-85.
[8] 马骊.随机森林算法的优化改进研究[D].广州:暨南大学,2016.
[9] 周志华.机器学习[M].北京:清华大学出版社,2016.
[10] 怀听听.随机森林算法的改进及其应用研究[D].杭州:中国计量大学,2016.
[11] 杨晓峰,严建峰,刘晓升,等.深度随机森林在离网预测中的应用[J].计算机科学,2016,43(6):208-213.
[12] 杨飚,尚秀伟.加权随机森林算法研究[J].微型机与应用,2016,35(3):28-30.
[13] 李婉华,陈宏,郭昆,等.基于随机森林算法的用电负荷预测研究[J].计算机工程与应用,2016,52(23):236-243.
[14] 程淼海,楼俏,王琼,等.基于随机森林算法的配网抢修故障量预测方法[J].计算机系统应用,2016,25(9):137-143.
[15] 向涛,李涛,赵雪专,等.基于随机森林的精确目标检测方法[J].计算机应用研究,2016,33(9):2837-2840.
[16] 卢晓勇,陈木生.基于随机森林和欠采样集成的垃圾网页检测[J].计算机应用,2016,36(3):731-734.
[17] 李磊,牟少敏,林中琦.随机森林在棉蚜虫害等级预测中的应用[J].安徽农学通报,2017,23(1):18-20.
[18] 张新佶,张天一,许金芳,等.随机森林倾向性评分方法及其在药品不良反应信号检测中的应用[J].中国卫生统计,2016,33(4):578-581.
[19] 巩亚楠,帕提麦·马秉成,朱登浩,等.随机森林与Logistic回归在预约挂号失约影响因素预测中的应用[J].现代预防医学,2014,41(5):769-772.
[20] 李斐,马千里.基于脑电信号特征提取的睡眠分期方法研究[J].计算机技术与发展,2016,26(12):177-181.
(收稿日期:2017-01-15 本文编辑:程 铭)
