一种相关话题微博信息的筛选规则学习算法
2012-07-09刘盛华程学旗
莫 溢,刘盛华,刘 悦,程学旗
(中国科学院 计算技术研究所,北京 100190)
1 引言
随着Web2.0的发展和信息传播手段的进步,微博这种以短文本形式出现的信息得到了迅猛发展,逐渐成为一种社会新媒体。2011年上半年,我国微博用户数量从6 311万快速增长到1.95亿[1],Twitter的注册用户总数已经超过三亿。自2010年8月以来,相比于传统搜索引擎,人们更愿意在社会媒体上花更多时间,微博成为了人们日常生活不可缺少的部分,以及实时信息的重要获取媒介。微博中的博文或推文(Tweets),本文统一称为微博信息,包含了丰富多样的话题,涉及政治、经济、军事、金融、生活、娱乐等各个领域。微博信息的实时性和时效性,给人们的生活带来便利的同时,也因其更新的速度远远地超越了人们的利用效率。以新浪微博为例,一般当关注人数超过几百以后,用户浏览信息的速度已经赶不上信息产生的速度。此外,随着移动智能终端技术的不断发展,人们更愿意在移动终端上使用社会媒体。而移动终端每次浏览信息更少,因此从大量微博信息中根据所有用户感兴趣的话题即时筛选,越来越引起学术界和工业界的广泛关注。TREC 2011新增的微博任务,就将给定话题的微博信息筛选列入了其备选任务之一。
如何根据给定话题筛选微博信息,可以借助于文本分类的技术。针对传统长篇文档分类的研究取得了长足的发展,并已经广泛应用于业界。然而由于微博信息篇幅极短、包含的信息和特征少等特点,传统的文本分类技术不再适用,尚没有成熟的理论和技术。Web2.0时代用户产生的信息有以下特点: 首先,微博信息具有不可控的词汇、含义模棱两可和缺乏规范性等特点[2];其次,信息通常不重要或稀疏,难以提取有效特征;最后,信息有时可能是完全错误或误导,通常由人的错误导致。为了解决以上问题,文献[3]提出了一种简单的基于规则的提取词干的算法,算法能从错误拼写或者修改过的词中提取出正确的词干,并专门用于垃圾邮件的检测。文献[4]提出了一种通过维基百科来丰富用户稀疏的短文本信息从而提高短文本聚类的精确度,实验证明算法相比于传统的词袋表示能提高聚类的精确度。Sriram等人[5]针对推文特征稀疏等问题,提出了使用提取用户信息和文本作为特定域特征的方法,在新闻、交易、事件等分类问题中达到了很好的效果,克服了传统“词袋”作为特征进行分类的限制。
手机客户端的普及使公众可以随时随地发布微博到互联网上,在线用户亦可实时看到更新的微博,其数量异常庞大。根据Twitter公司透露,截至2011年6月,Twitter一天增加博文数目约为两亿条;根据国内新浪微博的统计,截至2010年10月底平均每天增加超过2 500万条博文。一位来自微软的项目经理评价微博说“在Twitter阅读最新的推文”就像“就着消防栓喝水一样”。Twitter是实时的,当信息超过一天或者几个小时后,价值也就下降了。正是由于微博所具有的不可控、缺乏规范性的词语,信息特征稀疏,人为的错误和误导以及实时性等特征,给面向微博话题的信息筛选带来了挑战。
本文针对给定话题的微博信息筛选问题,考虑了微博信息语言不规范、特征稀疏、实时性等特点,采用了基于规则的分类方法进行筛选,并提出基于信息熵的规则学习算法。通过实验,与SVM分类算法相比,基于规则的本文算法和CPAR算法分类效果均比SVM算法效果好(新浪微博数据中,F值分别为98.01%,97.77%,96.61%),同时本文算法学习出的筛选规则取得了更好的效果。最后,在TREC 2011官方标注的关于“BBC World Service staff cuts”话题约3 000条数据上的实验,本文算法同样取得了较高的F值。
2 相关工作
近年来,学术界针对Twitter微博信息内容的研究不断地涌现出来。一方面,针对微博信息的情感分析[6-7]和垃圾信息过滤[8-9]进行研究。文献[6]针对德国联邦选举的话题进行推文的政治情感分析,结果表明Twitter上的信息有效反映了政治情感和离线的政治格局。文献[7]提出了一种对推文情感自动分类的方法,文章结果显示机器学习算法在使用带表情符号的数据训练后能达较高准确度。文献[8]首先选定了几个微博信息话题类别,通过调研“有用”或“无用”的特征,提出了一个可用于从实时的社会媒体中抽取有用信息的模块。文献[9]在七个月时间内使用60个“蜜罐”系统收集到36 000个Twitter上的内容污染者,并评价了识别自动内容污染者的广泛特征。以上针对微博信息内容的相关研究大多是关于情感分析及垃圾信息过滤等方面。然而,微博情感的分析依赖于所在话题的范畴,不同的话题有其特定的情感特征,同时针对话题的微博信息筛选一定程度上减少了垃圾信息的影响。因此,如何基于话题对微博信息进行筛选是微博内容挖掘和处理的重要前提,尤其是考虑话题域的微博内容情感分析。另一方面,文献[10]研究了如何通过微博信息的内容来预测真实世界的结果,通过对推文进行语义分析、文本分类等挖掘技术建立了预测电影票房的模型。文献[11]利用微博信息的时效性,通过对Twitter中实时事件的研究,基于支持向量机提出了基于关键词、微博信息数目和上下文的分类模型,来监测特定的事件——地震,并建立概率时空模型来发现震心。文献[6]和[7]的研究利用了微博信息的数据来进行特定话题或事件的预测,而对于如何定位属于指定话题的微博信息却没有能深入进行研究。因此,本文主要解决的问题是针对指定话题的微博信息筛选。
文本分类技术方面,通过短短几年的研究,从理论到应用都取得了许多可喜进展,许多基于统计机器学习的方法应用于其中。决策树归纳算法是通过跟踪一条由根到叶节点的路径来分类,叶节点存放着元组的分类预测;朴素贝叶斯分类基于贝叶斯定理,预测元组属于具有最高后验概率的类;支持向量机算法[12]建立在VC维理论和结构风险最小原理基础上,将原数据映射到较高的维,再搜索最佳分离超平面,通过最佳分离超平面来进行分类;logistic回归[13]本质上是线性回归,在特征到结果的映射中加入了一层函数映射,然后使用函数来进行预测。基于规则的分类通过一组由多个关键词逻辑与组成的规则来进行分类,常用生成规则算法有FOIL[14]、CPAR[15]等。FOIL和CPAR通过贪心地选取费用增量较高的规则,利用迭代的方法挖掘分类规则集。
其中,规则是表示信息或少量知识的好方法。分类规则表示直观、可读性强,因此利于用户的反馈和修改。易于实现的增量式规则挖掘机制,使得微博信息的筛选,能随着话题内容的演变,而即时更新。本文的算法是基于规则生成算法FOIL和CPAR的思想: 对训练文本顺序归纳得到规则;同时提供多个候选词,形成分支生成多条规则。不同的是,FOIL 和CPAR 均是基于贪心思想的算法。FOIL算法每次总是选择收益值最高的作为下一个待添加的规则词;CPAR算法选择那些收益值与最大收益值相差很小的几个词均作为候选词,然后形成多条分支,继续向下生成规则。上述算法均是从值高的词开始选择,算法过于贪婪,导致可能不一定能选到合适的词。因此本文算法采用了基于模拟退火的随机概率策略来选择规则词,使算法不至过于贪婪,避免了只针对训练数据集的类别分布进行学习,提高了训练出的规则的泛化能力,有助于提高算法的召回率。
3 基于规则信息熵的微博信息分类
本文提出了一种利用规则的信息熵度量模型和模拟退火的随机选择策略,进行规则学习的算法。本文的规则是由若干单词组合而成,不带有先后顺序的关系,规则中的词互相不相同,并且相互之间不存在子串关系。同时本文针对短文本,词频和出现位置的信息变得毫无意义,因此规则中的词不包含词频和出现的位置信息。
3.1 研究动机
FOIL算法通过区分正样例和负样例来学习规则,是一种贪心的算法。其中正样例是用于学习规则的样例,其余样例均为负样例。在算法中,重复搜索当前最好的规则词,移除那些包含当前最好规则的正样例,直到数据集中所有的正样例都被规则覆盖。
在FOIL算法中通过一个收益值FG来衡量生成规则词W的好坏。
由上式可以看出,FOIL算法每次添加的规则词都尽量做到多覆盖正样例和少覆盖负样例。当每次选择词加入到当前规则时,FG值被用来衡量加入该词到当前规则后产生的信息增量。利用贪心的思想,算法认为每次加入FG值最大的词能生成最好的规则。
在关联分类中,关联规则挖掘被用于生成候选的规则,候选规则中包括所有满足支持度阈值的词。从该候选规则中选择一个子集,组成新规则,大小为n,则该规则是由全部样例生成的最好的n级规则。但这需要在规则生成中做穷举的搜索。
在FOIL算法中,每条规则都是由剩下的数据集生成的。假设剩余数据集中的一条样例t被一条新生成的规则r覆盖,那么我们无法确定规则r是否是该样例t的最佳规则。因为1)r是由贪心算法生成的,而贪心算法在某些情况下结果不一定是正确的;2)r是由剩余的数据集生成的而不是全部的数据集。
因此有人提出了CPAR算法,该算法是穷举和贪心算法的折中。和FOIL算法一样,CPAR算法通过依次添加词来组成规则,然而,CPAR不是只保留最好的词,忽略其他所有的词,而是同时保留那些次好的词或者更多。通过这么做,CPAR可以同时选择更多的词,然后生成多个规则。
本文算法是基于规则生成算法FOIL和CPAR的思想: 对训练文本顺序归纳得到规则;同时提供多个候选词,形成分支生成多条规则。不同的是,FOIL和CPAR均是基于贪心思想的算法。FOIL算法每次总是选择FG最高的作为下一个待添加的规则词; CPAR算法会选择那些FG值与最大FG值相差很小的n个词均作为候选词,然后形成n条分支,继续向下生成规则。上述算法均是从值高的词开始选择,算法过于贪婪,导致可能不一定能选到合适的词,因此本文算法采用了随机概率策略来选择规则词,使算法不至于过于贪婪。另一方面,规则是通过逐步添加词的方式生成的,随着规则中词数的增加,所含信息就越来越明确,接受新添规则词的概率减小,因此我们采用模拟退火的迭代框架来刻画该特点。
3.2 算法概览
我们定义规则训练的语料中,属于指定话题的微博信息所组成的集合为生成规则的正类,记为P;否则,不属于该话题的集合为负类,记为N;词库W包含了话题可能涉及的关键词。算法步骤如图1所示,首先建立词库W的字典树,词库W基于一个逐渐积累的基础词库,对于语料中出现而在基础词库中没有的词,若该词在语料中频繁出现,则将其加入到词库W中,通过这样做便能发现语料中出现的新词;通过步骤3~10的迭代步骤,在当前的正类P下生成新的筛选规则R*,删除P集合中被新规则R*覆盖的微博信息,并将新规则R*添加至规则集R。当P集合为空或者当次生成新规则R*为空时这种顺序覆盖的规则的迭代终止。

图1 算法总体流程
3.3 规则的信息熵
信息熵由信息论的创始人香农提出,研究指出,信息量的大小取决于包含信息内容的不确定性程度。在统计学中,不确定性是用概率描述的,所以信息量的大小应该也能用概率来表示。信息熵表示如式(2)。
“熵”与“信息”紧密相联。熵越小,此时含的信息量越大;相反,熵越大,含的信息量就小。因此规则信息熵是某条规则能包含的信息量的大小,即表示该规则所能表示的类的信息量的大小。本文中涉及为二分类问题,即P类和N类,若某规则对应P类,若其规则信息熵越小,则表示其包含P类的信息量越大,也就是其越能代表该类的特点;若规则信息熵越大,表示其包含P类信息量就小。式(2)变为:
其中P(xp)为规则匹配中正类P的概率,P(xn)为规则匹配中负类N的概率。在算法学习过程中,利用规则在P集合命中的微博信息数目与总命中数目的比例来估计P(xp),同样,P(xn)也利用在N集合中命中微博信息的数目比例估计。本文目的主要是对P类生成规则,因此在生成规则时只考虑P(xp)大于0.5的规则,然后计算规则对应的信息熵,以此作为算法挖掘规则的重要标准。
3.4 规则迭代学习
规则迭代学习GenRules依次从当前剩余的P集合中通过顺序覆盖方法生成一次迭代的覆盖规则;生成规则的过程是逐步添加规则词的过程,我们采用了模拟退火的迭代框架,以一定概率接受候选规则词。如图2所示,R*是算法要生成的规则集,ante为当前已生成的规则前件,P′、N′为被ante覆盖的文本集合。
首先利用P′和N′在字典树中匹配,记录下每个词在P′和N′中出现的文本的数量(步骤2)。在选择词时,我们采用信息熵信息增益ΔH来衡量词的好坏(步骤3)。
其中R′为规则R添加规则词W后形成的新规则,H值由式(2)给出。

图2 GenRules函数过程
算法随后通过基于模拟退火算法的迭代框架随机选择出若干规则词(步骤4)。算法步骤如下: 对词库中的词按照信息熵增益从小到大依次进行如下步骤: 若该词信息熵增益小于零,则该词直接添加到规则词集合cand中;否则按式(5)计算该词被选中到规则词集合cand中的概率。
其中ΔH为式(4)计算的结果,MAX_RULE_LEN为规则最大长度的参数,crl为当前已学习的规则前件ante的大小。
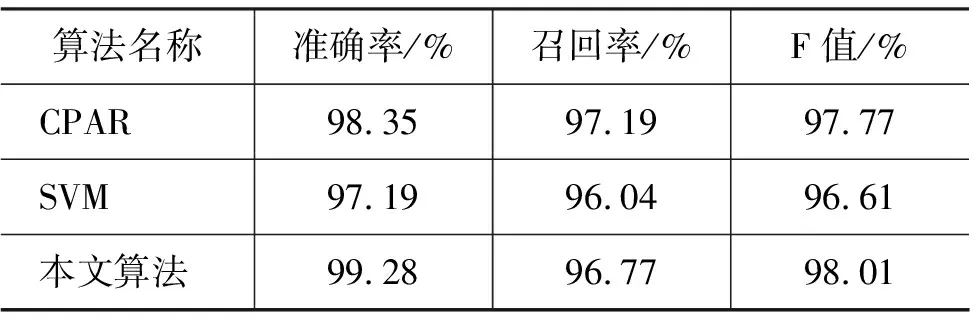
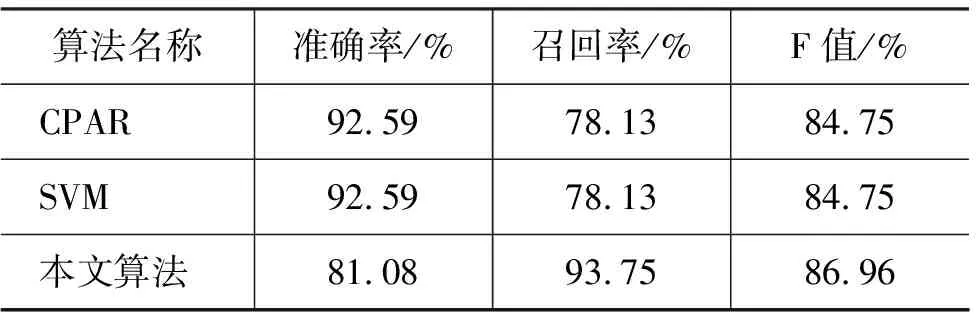
计算词的ratio之后,同时生成一个随机概率Prandom,若Prandom 通过上述方法选择出若干候选规则词后,每个候选词分别添加到当前规则前件ante中,分别形成不同的分支递归调用GenRules(步骤5~14)。如图3 所示。 图3 候选词分支 若规则前件ante长度达到规则最大长度限制,则将ante添加到R*中,表示已生成一条规则,然后继续处理后续候选词。直到所有GenRules函数结束。 通过上述算法学习到规则集, 该规则集均对应于正样例文本对应的类,因此利用规则集去匹配文本从而获知未知文本对应的话题类。具体过程如下。 第一,将规则集中的每个规则词建立一棵Trie树,利用Trie树匹配待分类的文本语料,记录下每个规则词匹配的文本集合; 第二,进行规则解析,将规则集中规则词所匹配中的文本集合进行交或并操作,最终获得规则所匹配的文本,匹配文本所对应的话题类即为规则所对应的话题类。 实验中首先采用了新浪微博的数据,每条微博信息字数在140字以内,共采集了89 158条。针对处理后的短文本数据,按照世博会的话题进行人工标注,得到3 558条与世博会话题相关的短文本,剩余85 600条数据与世博会话题无关。从所有与世博会有关的短文本中随机选取2 847条(约80%)作为正类训练集P,同样从与世博会无关的短文本中得到68 480条(约80%)作为负类训练集N;剩余17 831条数据作为测试集,保持了训练集和测试集合具有相同的正负样例比例。此外,我们针对英文内容做了一组实验,语料来自TREC 2011官方标注的Twitter数据,选取关于“BBC World Service staff cuts”话题的标注数据,包含了64条正类微博信息和2 990条负类微博信息。并按照1∶1的比例选取了训练集和测试集。Baseline SVM算法选择开源包SVMLight进行训练,将文本语料转换成SVMLight的输入格式,参数均采用SVMLight的默认参数。 表1 新浪微博数据比较结果 表2 TREC 2011 数据比较结果 表1比较了本文算法、CPAR算法和SVM算法在新浪微博语料上的实验情况。结果表明本文算法在处理短文本语料时在准确率和召回率上都能达到较高要求(F值98%以上),在准确率上比CPAR算法高(准确率99.28%>98.35%),已能达到实际应用要求。由于微博信息的内容极短,支持向量中各个维度的词频大多数为0和1,又加上正负训练样例不平衡,使训练得到的支持向量对训练集更加敏感,从而SVM算法在处理本文语料得到的效果(准确率97.19%,召回率96.04%)没有CPAR算法和本文算法高,由此可见对于本文的短文本语料基于规则的分类更加有效。表2给出了TREC 2011数据上的比较结果,同样,本文算法在英文短文本语料上的整体实验效果要好于CPAR和SVM算法。 本文提出一种基于信息熵和模拟退火迭代框架的微博信息的筛选规则学习算法。该算法考虑了微博特征稀疏、用语不规范的特点,利用规则的方法消除词频的影响,直接从微博内容中学习规则,同时将不规范词作为规则的一部分。针对新浪微博和TREC 2011的“BBC World Service staff cuts”的标注语料的实验表明,该算法学习得到的筛选规则,使相关话题的新浪微博信息的筛选达到了较好的效果。由于互联网上存在海量的未标注微博信息,因此如何利用小部分已标注的文本语料进行半监督增量式的学习,将作为下一步的研究方向。 [1] 中国互联网络信息中心. 第28次中国互联网络发展状况统计报告[OL]. 2011.download.chinagate.cn/ch/pdf/hulianwang.pdf [2] A. Mathes. Folksonomies—cooperative classification and communication through shared metadata[J]. Tech. Rep., UIUC, 2004. [3] S. Ahmed, F. Mithun. Word stemming to enhance spam filtering[C]//Proceedings of CEAS, July 2004. [4] S. Banerjee, K. Ramanathan, A. Gupta. Clustering Short Texts using Wikipedia[C]//Proceedings of the SIGIR, ACM,2007:787-788. [5] B. Sriram, D. Fuhry, E. Demir, et al. Short text classification in twitter to improve information filtering[C]//Proceedings of the ACM SIGIR 2010 Posters and Demos. ACM, 2010. [6] A. Tumasjan, T. O. Sprenger, P. G. Sandner, et al. Predicting elections with Twitter: What 140 characters reveal about political sentiment[C]//Proceedings of International AAAI Conference on Weblogs and Social Media, Washington, D.C., 2010. [7] Go A., R. Bhayani, L. Huang. Twitter sentiment classification using distant supervision[R]. Technical Report, Stanford Digital Library Technologies Project. 2009. [8] J. Hurlock, M. L. Wilson. Searching Twitter: Separating the Tweet from the Chaff[C]//Proceedings of AAAI, 2011. [9] K. Lee, B. D. Eoff, J. Caverlee. Seven Months with the Devils: A Long-Term Study of Content Polluters on Twitter[C]//Proceedings of AAAI, 2011. [10] S. Asur, B. A. Huberman. Predicting the Future with Social Media[J]. Arxiv preprint arXiv,2010. [11] T. Sakaki, M. Okazaki, Y. Matsuo. Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors[C]//Proceedings of WWW 2010: the International World Wide Web Conference, 2010: 851-860. [12] B. Boser, I. Guyon, V. N. Vapnik. A training algorithm for optimal margin classifiers[C]//Proceedings of Fifth AnnualWorkshop on Computational Learning Theory, ACM Press: San Mateo, CA, 1992: 144-152. [13] A. Genkin, D. Lewis, D. Madigan. Large-scale bayesian logistic regression for text categorization[J]. Technometrics.2007,49(3):291-304. [14] J. R. Quinlan, R. M. Cameron-Jones. FOIL: A midterm report[C]//Proceedings of 1993 European Conf. Machine Learning, Vienna, Austria, 1993: 3-20. [15] X. Yin, J. Han. CPAR: Classification based on predictive association rules[C]//Proceedings of 2003 SIAM Int. Conf. Data Mining (SDM’03), San Francisco, CA. 2003: 331-335. [16] C. Grier, K. Thomas, V. Paxson, et al. The underground in 140 characters or less[C]//Proceedings of ACM CCS’10, Chicago, IL, Oct. 2010.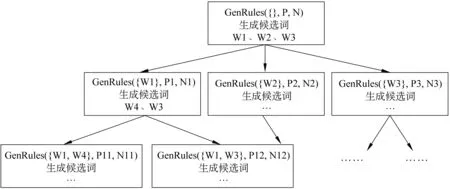
3.5 规则应用过程
4 实验及分析
5 结束语
