基于语义和结构的XML文档相似度的计算方法
2012-06-29吕晓琳
宋 玲,吕 强,邓 薇,吕晓琳
(1. 山东大学 控制科学与工程学院,山东 济南 250061;2.国网技术学院 电网检修培训部,山东 济南 250002;3. 山东科技大学 基础课部,山东 泰安 271021;4.天津财经大学 商学院,天津 300222)
1 引言
个性化推荐是对用户的信息需求、兴趣爱好、检索行为和决策方式的理解基础上,针对用户个性行为进行的推荐,其目标是提供智能的个性化推荐系统;个性化推荐中协同过滤的基本思想是在相似的用户间进行推荐,设计有效的算法来寻找相似用户,并将相似用户感兴趣的信息资源推荐给目标用户。XML语言具有自描述性、树形结构、结构嵌套等特点,是W3C推荐的标准语言,目前越来越多的应用领域已经将其作为主要的数据存储和交换格式,用XML描述信息资源、用户信息等,因此XML文档相似度计算问题是个性化推荐与信息检索中的一个重要的问题。由于XML文档可扩展性和高度结构化的特点,XML文档之间相似度比较至少要涉及两个层次: 结构的比较以及内容的比较。本文综合考虑XML的结构和内容特点,提出了一种新的计算XML文档相似度的方法,为个性化服务、XML信息检索、数据挖掘等应用提供理论基础。
2 相关工作
XML文档可以被模型化为有序标签树,树中有三类节点: 元素节点(内部节点)、属性节点(内部节点)和值节点(叶子节点),树中的边表示元素、属性、值之间的关系。一棵XML文档树T是一个二元组(N,E),其中N是节点集合(包括元素节点、属性节点和叶子节点);E是N×N的一个二元关系,是边的集合,(u,v)∈E,当且仅当u,v∈N,并且满足以下条件之一: (1)u,v是元素,且v直接嵌套在u中;(2)u是元素,v是u的属性;(3)u是元素或者属性,v是u的取值。
为了便于文中的描述,文中要用到的术语: (1)节点。包括元素节点、属性节点和值节点;(2)XML文档的路径。其 DOM树中从根节点到内容节点所经由的节点组成的串(以“/”作为节点之间的分隔符);(3)XML文档的路径集。对应一个XML文档的所有路径组成的集合。
虽然XML文档之间的相似度可以使用传统的信息检索技术,例如,向量空间模型中的余弦相似度来计算[1]。针对XML的结构特点,很多研究通过树的编辑距离来衡量XML文档之间的相似度[2],树之间的编辑操作主要有三种: 插入、删除和替换。节点比较计算相似度的方法主要根据两个XML文档中公共节点个数与这两个XML文档中所有节点个数的比值的百分数来衡量它们之间的相似度[3-4]。基于拥有相似的路径集合则XML文档相似的假设,文献[5-6]基于路径集合的比较研究了XML文档之间的结构相似度。文献[7]提出利用树同构思想测量文档语义相关度,在计算过程中通过为节点赋予不同权重反映匹配节点的位置重要性,对于未匹配节点则提出利用影响因子针对不同情况做适当区分。
尽管目前XML文档相似度的研究已经取得很多进展,但大部分研究对下列三个问题缺乏综合考虑: (1)XML文档树中的节点标记语义。节点标记含有丰富的语义信息,不同的XML文档中节点的标记可能不同,但表达的含义相同,例如, “author”和“writer”。由于XML标签命名的灵活性,可能不同的用户将“客户名”定义为“cusname”或“custom-name”;(2)路径层次关系。对于XML的DOM树来说,其路径表示一种层次结构,即父子节点之间存在着一种上下位关系,这种关系具有自反性、非对称性以及传递性,是一种偏序关系。比较两条路径的时候,如果说两条路径精确匹配,那么必须要求这两条路径的所有的节点标记名相同,并且他们的上下文相对次序也必须完全相同。但在文档树中存在这样一种情况,尽管两条路径不完全相同,但如果一条路径是另一条路径的子路径,且其中的节点标记满足偏序关系,这两条路径也具有一定的相似性,例如,“articles/author/Febio”和“articles/article/author/Febio”,这种情况应该得到充分考虑;(3)XML文档中节点或有向边的重要程度。文档树层次对结构具有很大的影响力,越靠近树的根的节点或有向边,对结构的影响应该越大。
通过对这些已有研究方法的分析,本文提出了一个面向个性化的XML文档相似度的计算方法,融合了半结构化的特性以及节点标记的语义内容特征。
3 一种新的基于语义和结构的XML文档相似度计算方法
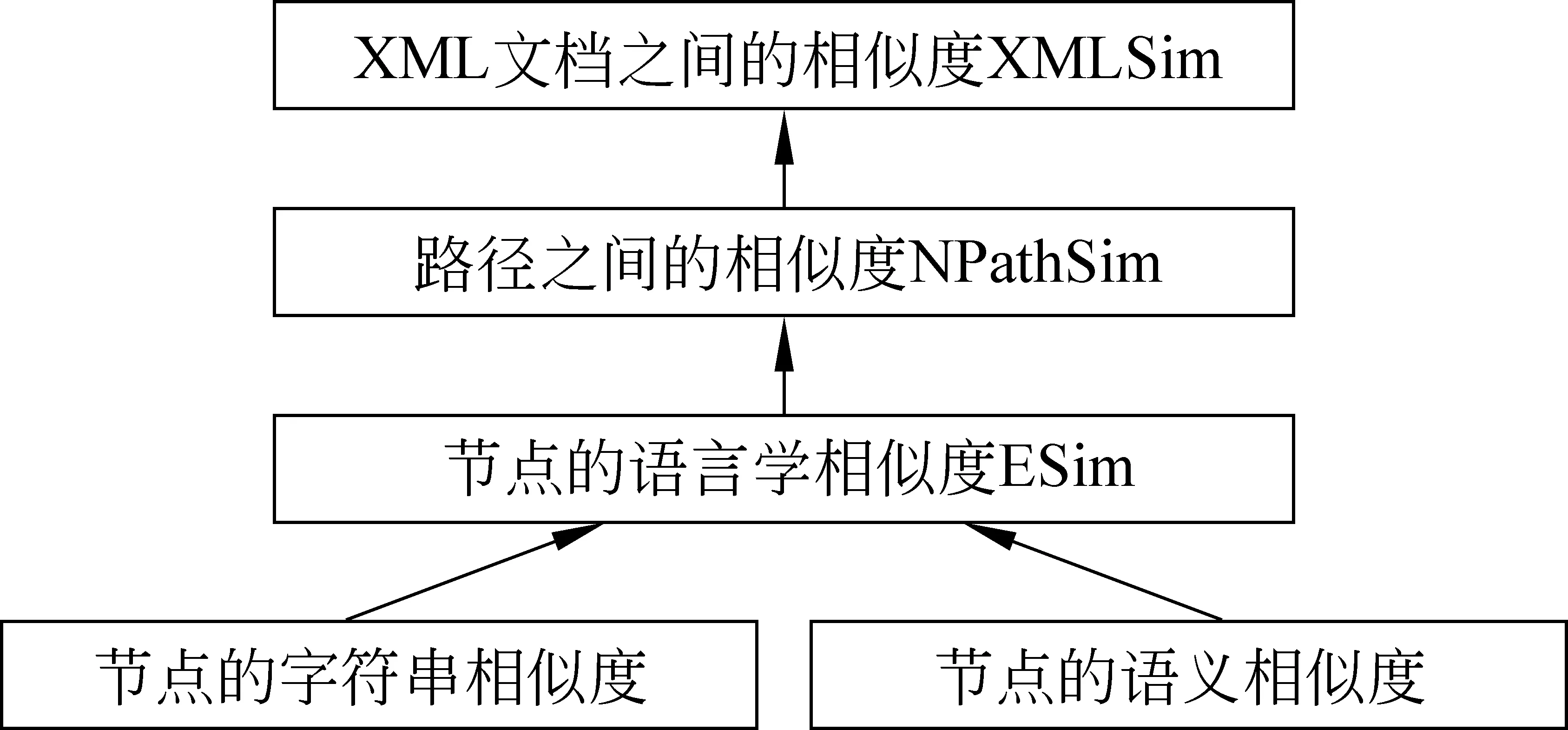
图1 XMLSim算法
首先将XML文档解析成标签树,然后将标签树分解为从根到叶子节点的路径集合,那么XML文档相似度的计算就转换为路径集合之间相似度的计算。如图1所示,本文提出的XMLSim算法主要包括以下三个方面: (1)综合考虑节点标记的语义模糊相似度和字符串编辑距离,得到节点之间的相似度ESim; (2)在分析路径的结构具有偏序关系的基础之上,使用动态规划计算路径之间的相似度NPathSim;(3)基于路径相似度计算文档之间的相似度XMLSim。
3.1 节点之间的相似度计算-ESim
本文在文献[8]的基础之上,提出了将语义相似度和编辑距离结合起来计算两节点的相似度的方法,如算法1所示。
算法1: 节点之间的语言学相似度。
输入: 两个节点
输出: 节点之间的语言学相似度
{ Step 1: 计算两节点名称之间的编辑距离,从而得到其字符串相似度。
Step 2: 对节点进行预处理: 利用用户词典进行替换,除去节点中的分隔符得到词集。
Step 3: 基于WordNet计算出两个词之间的语义相似度,进而计算出两个节点之间的语义相似度。
Step 4: 取两节点的字符串相似度和语义相似度中的最大值做为两节点的语言学相似度。}
3.1.1 节点之间的编辑距离
两节点的字符串相似度基于对两字符串编辑距离的计算。Levenshtein提出利用动态规划计算两个字符串之间编辑距离d(s,t)的方法[9],本文利用式(1)将编辑距离转换为相似度公式并将值归一化到区间[0, 1]中:
3.1.2 节点之间的语义相似度
3.1.2.1 词汇之间的语义相似度
WordNet[10]将单词按照其意义组成一个“单词的网络”。在WordNet中一个词往往有多种词义(sense)。本文将两个词的语义相似度定义为两个词之间各种语义比较的最大值。在以往的研究中,我们提出了一种计算WordNet中词汇之间的语义模糊相似度方法SFSBC(Semantic Fuzzy Similarity Between Concepts)[11-12],本文利用该方法可以计算词汇之间的语义相似度。
3.1.2.2 节点标记之间的语义相似度
将两个节点标记e1和e2分割成两个词集E1和E2,将E1和E2的词对之间的最大语义相似度的平均值作为两节点标记之间的语义相似度,公式描述如式(2):
|E1| 和 |E2|是e1和e2所含的词汇的个数。
3.1.3 节点之间的语言学相似度
定义节点之间的语言学相似度为节点之间的编辑相似度和语义相似度的最大值,如式(3)所示。
表1利用式(3)计算路径Pa和Pb之间所有节点对之间的相似度,其中Pa=“Conference/symposium/topic/arcticles/arcticle/title/Data Mining”,Pb=“Journal/arcticles/arcticle/title/DataBase System”。阈值α越大,对相似的要求越严格。当两个节点的相似度大于α时,就认为节点相似,否则相似度忽略为0。表1中设定α=0.3。
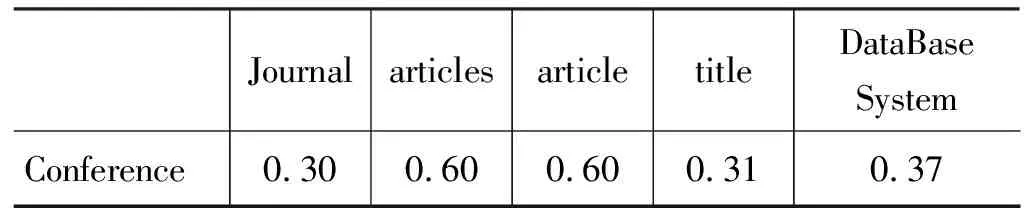
表1 Pa和Pb两个序列的语言学相似度矩阵(α=0.3)

续表
3.2 路径之间的相似度计算-NPathSim
路径相似度的计算需要考虑两个方面因素: (1)反映出分别位于两路径中的相似节点之间的相似度;(2)反映出分别位于两路径中的相似节点在各自路径中的上下文信息。综合考虑以上两个因素,下面提出最大相似子序列问题。
目前,已有研究[42]结果提示,S1P可通过与不同受体结合偶联炎症和凝血反应。因此,平衡S1P在炎症和凝血反应中的作用可能成为治疗脓毒症的新途径。
3.2.1 最大相似子序列(Maximal Similar Subsequence, MSS)问题
序列Z={z1,z2, …,zk}是序列X={x1,x2, …,xm} 的子序列,当且仅当
(4)
定义1(最大相似子序列MSS) 有两序列X和Y,X={x1,x2, …,xm},Y={y1,y2, …,yn},序列Z={z1,z2, …,zk} 和 序列W={w1,w2, …,wk}分别是X和Y的相似子序列。最大相似子序列就是Z和W中最大相似度子序列。
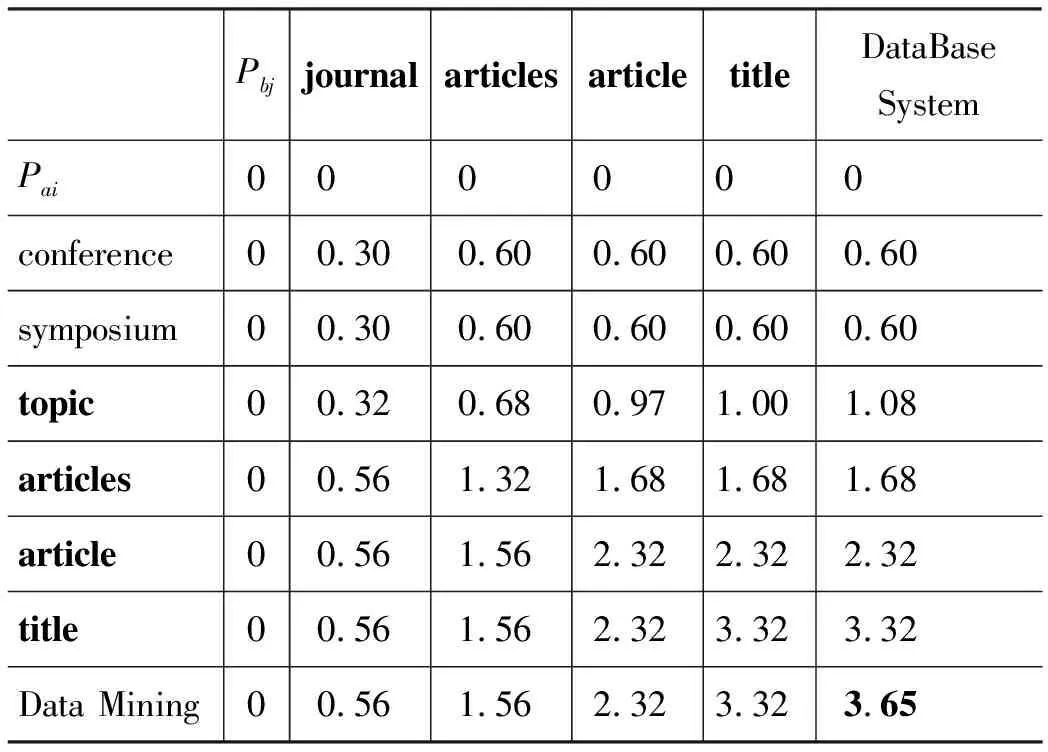
表2 路径Pa和Pb最大相似度(α=0.3)
利用式(4)计算3.1.3节中Pa和Pb的路径相似度,结果如表2所示。从表2可以看出,Pa和Pb两路径的最大相似度值为s′[7,5]=3.65,最大相似子序列为: “topic/articles/article/title”和“journal/articles/article/title”。
3.2.2 路径相似度NPathSim
由于在XML文档中,层次高的节点(离根节点更近的节点)往往比层次低的节点(离根节点较远的节点)更能反映文档的结构信息,在计算相似度时,必须把节点所处的层次考虑在内。为了反映这一特点,本文对路径中各个节点赋不同的权值,越靠近根节点,被赋予的权值越大,也就意味着对路径相似度的贡献越大。有权路径就是对路径中的每个节点都赋给一个非负数的权值。路径p的最大深度为h,对于节点x位于第m层(从叶子节点到x的路径长度),那么x的权重就被赋值为γh-m(0<γ≤1),其中γ为一参数。
文献[13]提出一种计算路径相似度的方法PathSim,但是该方法没有考虑节点的语义信息。本文基于MSS问题求解路径相似度问题,定义路径相似度如下。
定义2对于路径Pa={ea1/ea2/,…/eam}和路径Pb={eb1/eb2/,…/ebn},s′[i,j]被定义为子序列Pai和Pbj的路径相似度,则Pa和Pb的相似度值为s′[m,n],式(5)递归地求解路径之间相似度。

(5)
由于参数γ的设置,使得相似的节点越靠近根节点,最后路径之间的相似度值越大。式(6)将式(5)归一化到区间[0, 1]。
3.3 XML文档之间的相似度计算-XMLSim
对于A,B两个XML文档,pA和pB分别是文档A和B的路径集。显然pA和pB中相似的路径数目越多,则两文档越相似。将pA中每条路径与pB中每条路径都进行相似度计算,然后取最大相似度的平均值,作为两个XML文档之间的相似度XMLSim,其公式描述如式(7):
其中|pA|和|pB|分别是pA和pB中的路径个数,相似度值在[0-1]之间。
如果两个XML文档树中的节点个数分别是m个和n个,则XMLSim的时间复杂度为O(mn)。
例计算XML文档A和B之间的相似度,其中pA和pB的路径集如表3所示,计算结果如表4所示。

表3 文档A和文档B的路径集pA和pB
最后利用式(7)计算文档A和B的相似度为XMLSim(A,B)=0.71。
4 实验
基于内容过滤的个性化推荐系统为每个用户建立兴趣模型(Profile),利用XML文档和用户兴趣模型之间的相似性来进行信息过滤和推荐。为了测试本文提出的相似度方法,我们实现了文献[6]中提到的相似度方法SchemaSim。XML实验数据集来自于 (Niagara, http://www.cs.wisc.edu/niagara/data/) 和 IBM XML generator (http://www.alphaworks.ibm.com/tech/xmlgenerator),共有1 200个文档。为了测试XML文档的语义和结构,从1 200个文档中拷贝了600 个文档,将这600个文档通过标签名或内容语义替换或结构删除的方式进行了改变,共得到1 800个文档。用户兴趣模型通过五个在校大学生获得,首先给用户一些包含在XML文档中的内容信息的一些例子,这些信息没有结构,要求用户从这些例子中生成兴趣模型,自由选择结构和标签名,通过XML文档来描述得到的40个用户兴趣模型。计算用户兴趣模型和数据集中XML文档的相似度,最后给出top-10 的XML文档推荐列表。为了得到用户对推荐结果的满意度,我们请用户对基于两种不同方法的推荐结果按自身满意程度打分,打分范围限定在 0-1分之间。
采用平均绝对偏差MAE (Mean Absolute Error)来评价推荐系统的推荐质量。MAE 通过计算预测的用户评分与实际的用户评分之间的偏差,度量预测准确性,MAE越小,推荐质量越高。计算参与实验的用户的MAE值,本文分别对用户推荐记录数为8个、16个、24个,32个和40个情况下的MEA进行了计算,结果如表5所示。
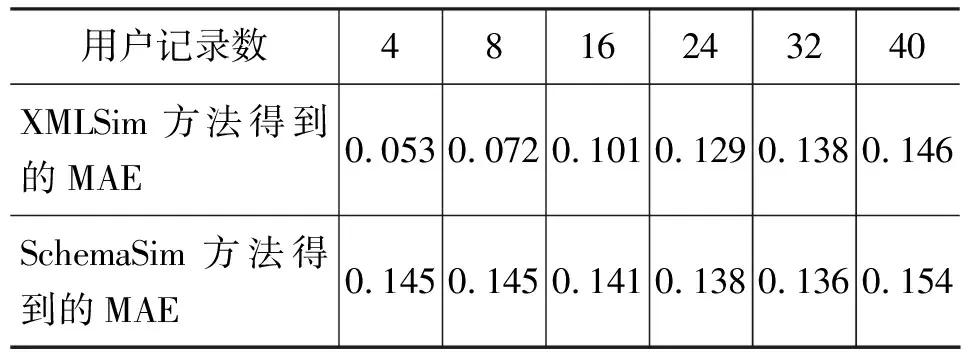
表5 两种相似度方法下不同记录数时的 MAE 对比表
表5 表示了随着用户记录数目的不同,两种相似度方法进行推荐得到的结果 MAE 值对照表,可以看出,与SchemaSim推荐结果的MAE值相比,本文提出的相似度方法XMLSim推荐结果的MAE值要小,即推荐的准确性提高。随着记录减少,与基于SchemaSim的MAE值相比,差值逐渐增加,说明基于XMLSim推荐的实时性要好于基于SchemaSim的推荐。
5 总结
个性化服务是指针对不同用户的不同特点,提供不同服务策略和服务内容的服务方式,个性化信息推荐服务中根据不同用户个性化的信息需求来提供不同的服务,以及信息服务的主动性提供都离不开用户之间相似度的计算,以及信息资源之间相似度的计算,随着XML被越来越多地作为描述信息资源和用户的主要数据存储和交换格式,计算XML文档之间的相似度成为一个非常重要的问题。
本文提出了一个通过比较路径集合之间的相似度来计算XML文档之间相似度的方法XMLSim。作为计算XMLSim的基础,在计算路径之间的相似度NPathSim的过程中,首先基于节点标记对之间的语义相似度和字符串编辑距离生成两路径的节点标记相似度矩阵,然后对路径中各个节点标记根据其在DOM树中不同位置赋予不同的权值。在分析了路径上的元素标记具有偏序关系之后,将路径之间相似度问题抽象为最大相似子序列MSS问题,利用动态规划通过对MSS问题的求解得到路径之间相似度NPathSim。最后通过路径集合之间的NPathSim最大相似度的平均值得到XMLSim。通过实验表明基于本文提出的XMLSim推荐的结果MAE值较小,即推荐的准确性提高,同时实时性推荐效果要好。
[1] 郑仕辉, 周傲英, 张龙. XML文档的相似测度和结构索引研究[J]. 计算机学报, 2003, (9) : 1116-1122.
[2] Zhang K, Statman R, Shasha D. On the editing distance between unordered labeled trees[J]. Information Processing Letters. 1992, 42(3): 133-139.
[3] Nierman A, Jagadish H V. Evaluating Structural Simi-larity in XML Documents[DB/OL]. 2002, citeseerx.ist.psu.edu,61-66.
[4] Nayak R. Investigating Semantic Measures in XML Clustering[C]//Proceedings of IEEE/WIC/ACM International Conference on Web Intelligence, 2006: 1042-1045.
[5] Joshi S, Agrawal N, Krishnapuram R, et al. A bag of paths model for measuring structural similarity in Web documents[C]//Proceedings of Knowledge Discovery and Data Mining. Washington, D.C., ACM Press, 2003: 577-582.
[6] Nayak R, Iryadi W. XML schema clustering with semantic and hierarchical similarity measures[J]. Knowledge-Based Systems. 2007, 20(4): 336-349.
[7] 赵嫣, 马军, 李森. 一种计算结构化文档相关度的方法[C]//第二届中国分类技术及应用学术会议.郑州: 20070527. 350-355.
[8] Jeong B, Lee D, Cho H, et al. A novel method for measuring semantic similarity for XML schema match-ing[J]. Expert Systems with Applications. 2008, 34(3): 1651-1658.
[9] Levenshtein V. Binary codes capable of correcting deletions, insertions, and reversals[J]. Soviet Physics Doklady. 1966, 10(8): 707-710.
[10] Princeton University. WordNet[DB/OL]. 2011, http://wordnet.princeton.edu/.
[11] Ling Song, Jun Ma, Jingsheng Lei, et al. A Fuzzy Approach for Measuring the Semantic Similarity Between words in WordNet[J]. Journal of Information & Computational Science,2009,6(3): 1673-1680.
[12] Song Ling, Ma Jun, Lian Li, et al. Fuzzy Similarity from Conceptual Relations[C]//Proceedings of 2006 Asia-Pacific Services Computing Conference,2006: 3-10.
[13] Alexander R. Vinson,Carlos A. Heuser, Altigran S. da Silva, et al. An Approach to XML Path Matching. Workshop On Web Information And Data Mana-gement[C]//Proceedings of the 9th annual ACM international workshop on Web information and data management. SESSION: XML and semi-structured data,2007:17-24.
