用户评论中的标签抽取以及排序
2012-06-29李丕绩张冬梅韩晓晖
李丕绩,马 军,张冬梅,韩晓晖
(1. 山东大学 计算机科学与技术学院,山东 济南 250101 2. 山东建筑大学 计算机科学与技术学院,山东 济南 250101)
1 前言
近年来,互联网和电子商务的飞速发展不仅给企业的业务流程带来了巨大的变革,而且对消费者的行为模式也产生了深刻的影响。因此,网络上各种产品的评论数量也在飞速地增长。而且越来越多的证据表明,评论信息影响到消费者的购买决定。但是,随着时间的推移,产品的评论会越来越多,评论列表会变得很长或者分很多页。随着评论数量的积累,评论的质量也会参差不齐。这样,用户在浏览评论的时候就会花费很多的时间和精力,甚至看不到隐藏在网页最深处的而且可能是最有价值的评论信息。
那么,能否从这些成千上万的评论中抽取对这个产品有效准确的简短描述,能够让用户最快时间获得此产品的重要信息呢?
为了解决这个问题,本文提出了一种能够为每个实体*实体: 本文的实体指的是网络中存在的产品、商户或者店铺等。抽取特征标签的方法,并且语义去重,保证标签在语义空间内相互独立。首先,对于每个实体的所有评论,进行中文分词、词性标注,并且做依存句法分析。然后,根据每个句子中的依存关系,抽取关键标签,构成此实体的标签库,并且对标签库进行显式语义去重。在本文中,对关键标签的抽取主要关注对实体某些属性的实际描述词,例如,“味道不错”“价格实惠”等,显式去重是根据预先定义的同义词词典进行初步去重,例如,“口味儿”“味道”都看作“味道”。最后,通过K-Means聚类以及Latent Dirichlet Allocation(LDA)[1]主题模型将每个标签映射到语义独立的主题空间,从每个主题空间中抽取单个标签,再根据每个标签相对该主题的置信度和支持度进行排序。通过以上步骤,可以为每个实体抽取语义独立的N个关键标签描述。实验中,本文通过对返回标签列表的准确性以及语义多样性进行了统计分析,验证了标签抽取方法的可行性和有效性,并且有一定的实际应用价值。
2 相关工作
产品评论挖掘的一个主要任务是需要了解用户对产品的哪些功能、部件和性能进行了评价,因此需要从产品评论中提取出用户评价的对象——产品特征。用户在产品评论中对特征的描述,可能是厂家根本没有考虑到的一些特征,因此挖掘出产品评论中所提及的特征,了解用户对这类产品最关心的功能和性能是具有重要意义的。
产品特征的提取分为人工定义和自动提取两类。在人工定义方面,Kobayashi、Inui和Matsumoto[2]以人工定义方式构建了针对汽车的产品特征,共有287个产品特征,每一个特征使用一个三元组进行表示(
自动提取产品特征的方法,需要使用词性标注、句法分析和文本模式等自然语言处理技术对产品评论中的语句进行分析。自动发现产品特征,由于不需要大量的标注语料库作为训练集,因此具有较好的通用性,并且可以适用于各种产品,可以比较容易地移植到不同产品上,但它最大的缺点就是准确率比较低。Hu和Liu[6]先对评论语料进行词性标注,然后把每个句子中的名词和名词短语提取出来,利用关联规则挖掘方法从评论语料中取出满足最小支持度的名词或名词短语生成transaction file,再使用CBA(Classification Based on Associations)[7]从transaction file中挖掘出频繁项,把频繁项作为产品特征候选集,由于关联规则产生的频繁项不是全都是有用的或真正的特征词,需要进行进一步的筛选,首先去掉了三个词以上的名词短语,然后对候选特征集中的候选特征进行修剪,通过“紧凑修剪”和“冗余词修剪”移除那些很大可能不是产品特征词的名词短语。
Popescu[8]把评论挖掘分成四个主要子任务: (1)识别产品特征;(2)识别产品特征对应的观点词;(3)判断观点词的极性;(4)根据观点的强度排序。他们在KnowItAll[9]网络信息抽取系统基础之上建立了一个无监督的信息挖掘系统OPINE。在产品特征识别方面,Popescu建立的OPINE系统将产品特征分成显式特征和隐式特征,其中显式特征又分为五类,分别为“properties、parts、features of productparts、related concepts、parts and properties of related concepts”。用OPINE来挖掘产品特征的准确率比Hu[12]挖掘结果高出了近22%,而召回率仅下降了3%。
在本文中,由于目标是要用三至五个关键词对商户进行特征的描述,所以本文在基于句法分析的基础上,提出了基于K-Means[10]和基于Latent Dirichlet Allocation (LDA)[1]的两种关键词抽取方法,经过试验,效果十分理想。
3 方法
假设已经得到了某个实体的所有评论信息,算法由此开始,可以分为四个子模块: 词法句法分析、候选标签的挖掘抽取、标签去重和语义独立、代表标签的选取以及排序。
3.1 词法句法分析
为了能够后续步骤中的候选标签抽取,需要对每个评论的每个句子进行词法和句法分析。将句子分词,并且进行词性标注,而且需要将词与词之间的修饰关系描述出来。
本文中我们使用依存句法分析来确定词之间的关系。例如,评论: “服务员很漂亮。饭菜很好吃,味道不错。”进行句法分析之后的结果如图1所示。

图1 依存句法分析例子
依存句法分析之后,就可以将有用的三元组<主题词,ADVs,修饰词>提取出来,作为描述此实体的一个标签。
3.2 候选标签抽取
将每个实体的所有评论的句子进行了词法句法分析之后,就可以进行候选标签的抽取,同时,根据初始词典进行显式语义去重。本文主要分析<主题词(n),(ADVs),修饰语(a)>三元组,也就是主要是考虑用形容词来修饰名词的标签信息。例如,“服务员很漂亮”“价格很便宜”等。
通过句法分析得到了依存关系,对每个商户s,就可以挖掘其候选标签集合O,
(1)
其中n为商户s评论的数目,Oi为第i个评论所产生的标签候选。
为了在后续的语义去重中更加准确,这里对于每个新的标签oi,都要进行显式去重。意思就是将重复的oi过滤,并且根据初始的词典将显式语义进行合并。例如,“口味儿”“味道”的主题标签都用“味道”的主题标签代替。
3.3 标签语义去重
对于商户s和其所有候选标签集合O,怎么进行标签语义去重和保证相互独立呢?这是最重要的算法模块,本文提出了两种解决方法,并比较了两种方法的结果: (1)K-Means主题聚类;(2)LDA主题分析。
3.3.1 基于K-Means主题聚类
假设主题数目是K。由于用户评论的相对稀疏性,所以K一般选择较小的值,例如,10。将O中的每个候选标签oi看作一个单独的文档,然后对这|O|个文档进行K聚类。
在聚类过程中,一个关键的问题是标签oi和标签oj的相似度计算,以及标签oi和聚类ci的距离,由于本文把每个标签看作一个文档,所以如果使用tf-idf等向量空间模型表示将会十分稀疏。为了避免这种稀疏性,一种方法是文档表示用基于字的1-gram表示成向量空间模型,这种方式在基于LDA的主题建模用到了。另一种方法把一个标签oi看作一个字符串处理。
既然是看作字符串,那么计算距离的时候本文采用 Levenshtein Distance[11]来衡量字符串之间的距离。为了更准确地达到主题聚类和消除语义重复的作用,只用标签的主题词t(oi)代替标签计算距离LD。
用这种方法,就无法计算聚类的中心。所以计算一个文档oi到聚类ci的距离,就近似用到这个聚类中所有文档的距离的均值才衡量。
试验中迭代20次之内便会收敛。这样每一个聚类就可以看作描述某一个主题的标签的集合。
3.3.2 基于LDA主题模型
LDA(Latent Dirichlet Allocation)[1]是一个多层的产生式概率模型。它有词、主题、文档三层结构。LDA 将每个文档表示为一个主题混合,而每个主题是固定词表上的一个多项式分布。本文中,由于把每个标签看作每个文档,为了解决稀疏性,用基于字的1-gram建立向量空间模型。经过估计和推断之后,对于每个商户,有了所有的文档—主题分布“θ”,这样就将所有的标签映射到不同的主题z上,再从主题z中选择有代表性的标签作为代表输出即可。
3.4 代表标签选择及排序
本文以相互比较和互补的形式提供了三种选择代表标签的策略: K-Means Topic Clustering(KM-TC)、LDA Max Topic(LDA-MT)和LDA Topic Clustering(LDA-TC)。下面详细描述每种方法。
3.4.1 K-Means Topic Clustering(KM-TC)
第一步,为每一个聚类c选择一个代表性的标签o;
第二步,对选择出的K个标签o进行排序输出;
这样,就需要每一个标签有一个分数值Score(o),聚类ci中的标签的分数,
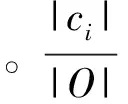
每个聚类c选择出一个score最大的标签o作为代表,那么就会得到K个标签。
并且按照score做了排序,score(o1)≥socre(o2)≥...≥score(o|K|)。
3.4.2 LDA Max Topic(LDA-MT)
LDA主题模型将每个候选标签都映射到主题分布空间中,为了将某个候选标签od赋予某个主题zi,采取了一种贪婪的策略:
实际上是将概率最大主题zi作为标签od所属于的主题。
和第一种方法类似,也需要有个打分函数:
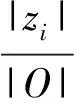
3.4.3 LDA Topic Clustering(LDA-TC)
主题模型最终将文档映射到主题分布P(zi|oi),可以将分布P(zi|oi)看作一个主题维K的描述此标签信息的特征向量,这也可以看作一个由词典维映射到主题维的降维过程,那么有了特征描述,可以继续进行聚类,将相同潜在主题的标签映射到相同的主题上。
聚类中距离的计算我们采用欧氏距离:
Distance(oi,oj)=ED[P(zi|oi),P(zj|oj)]
(8)
代表标签选择和排序的过程也和KM-TC方法类似。
4 实验
4.1 数据集以及实现
为了验证方法的有效性,我们从大众点评网(www.dianping.com )上抓取了近1 000个商户的信息,所有商户的评论近130 000条。
在实现中,词法句法分析我们使用的哈尔滨工业大学的开源语言技术平台(Language Technology Platform,LTP)[12]*http://ir.hit.edu.cn/ltp/。LDA主题模型我们使用的开源的Java版的JGibbLDA*http://jgibblda.sourceforge.net/。
4.2 评测标准
本文的目的是要为每个商户抽取语义独立的标签进行准确描述,所以主要从准确性、语义多样性以及标签质量三个方面对结果进行了评测。准确性采用信息检索中常用到P@n和MAP作为评价指标。
4.2.1 D@n(语义多样性@n)
因为标签抽取中保证语义独立性非常重要,所以本文用语义多样性来度量,可以如下进行计算:
其中NRreln表示前n个准确的标签中语义独立的标签的数量,Nreln表示前n个标签中准确描述的数量。
4.2.2 AQ(平均质量)
对于质量的度量,一般意义来说,标签的长度越长,包含的字数越多,可能隐含的语义和信息就更加完整,质量较高,所以可以用标签的平均长度进行度量。
其中length(oi)表示标签oi的长度,用MaxLength(O)进行归一化。
4.3 实验结果
试验中我们对每个商户都生成了若干个语义独立的标签进行描述,由于最终的结果需要专家进行评测,所以我们随机的选择了50个商户分别求其各个衡量指标,最后求均值得到最后的评测结果。经过试验,发现当LDA主题数目以及聚类数目K=15左右,效果较好。所以在试验中我们令K=15,文章不再对K进行讨论。
如图2所示,方法KM-TC和LDA-MT在描述的准确率方面相差不大,因为都是相当于对于不同的主题词以及不同的主题进行了处理,并且选择代表性的标签,所以错误率小;但是方法LDA-TC的结果却不甚理想,理论上该方法应该会胜于前两种方法。经过分析发现由于在LDA-TC中K-Means聚类时候使用了欧氏距离,没有处理数据的稀疏性带来的巨大影响,并且没有对标签的长度进行加权,所以结果会逊色。
图3的左图是结果的MAP值, 因为MAP与P@n 有一定的关系,所以产生的结果也在预想之中,方法KM-TC和LDA-MT要优于LDA-TC方法。但是考虑到标签的质量问题,如图3的右图所示,发现第二种方法LDA-MT的质量要明显高于其他两种方法,而LDA-TC方法的质量变得非常差。分析其原因,由于LDA-MT对于每个文档是选择了其概率最大的主题作为其聚类的主题,所以如果该标签长度较长,含有的信息较多,那么其对于某个主题的贡献就越大,所以根据打分函数,得分也会较高。而方法LDA-TC的标签多为字数最少的标签,所以结果会很差。
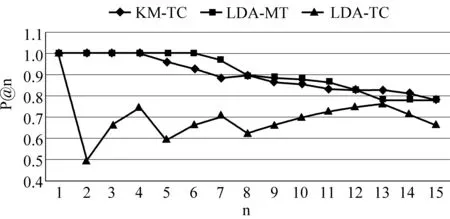
图2 标签准确率

图3 左: 平均准确率MAP;右: 平均质量AQ
对于这种情况的解决办法可以对标签的长度进行加权。一般来说,标签越长,含有的描述信息就越具体,越全面。
本文一个重要的问题是语义独立的问题,本文用语义多样性的指标进行衡量,结果如图4所示。LDA-MT因为标签的长度较长,含有的信息较全面,那么标签之间独立的可能性就比较大,所以其语义多样性会高于其他方法。但是方法KM-TC方法的语义多样性下降较大。分析其原因是因为在进行K-Means聚类的时候对标签使用了LD编辑距离,那么这其实是一种显式语义独立方法,但是不能揭示隐含的语义信息,例如,“苹果”和“电脑”的语义距离的计算。解决方法可以使用其他的语料库或者wordnet等来代替LD计算标签之间的语义距离。
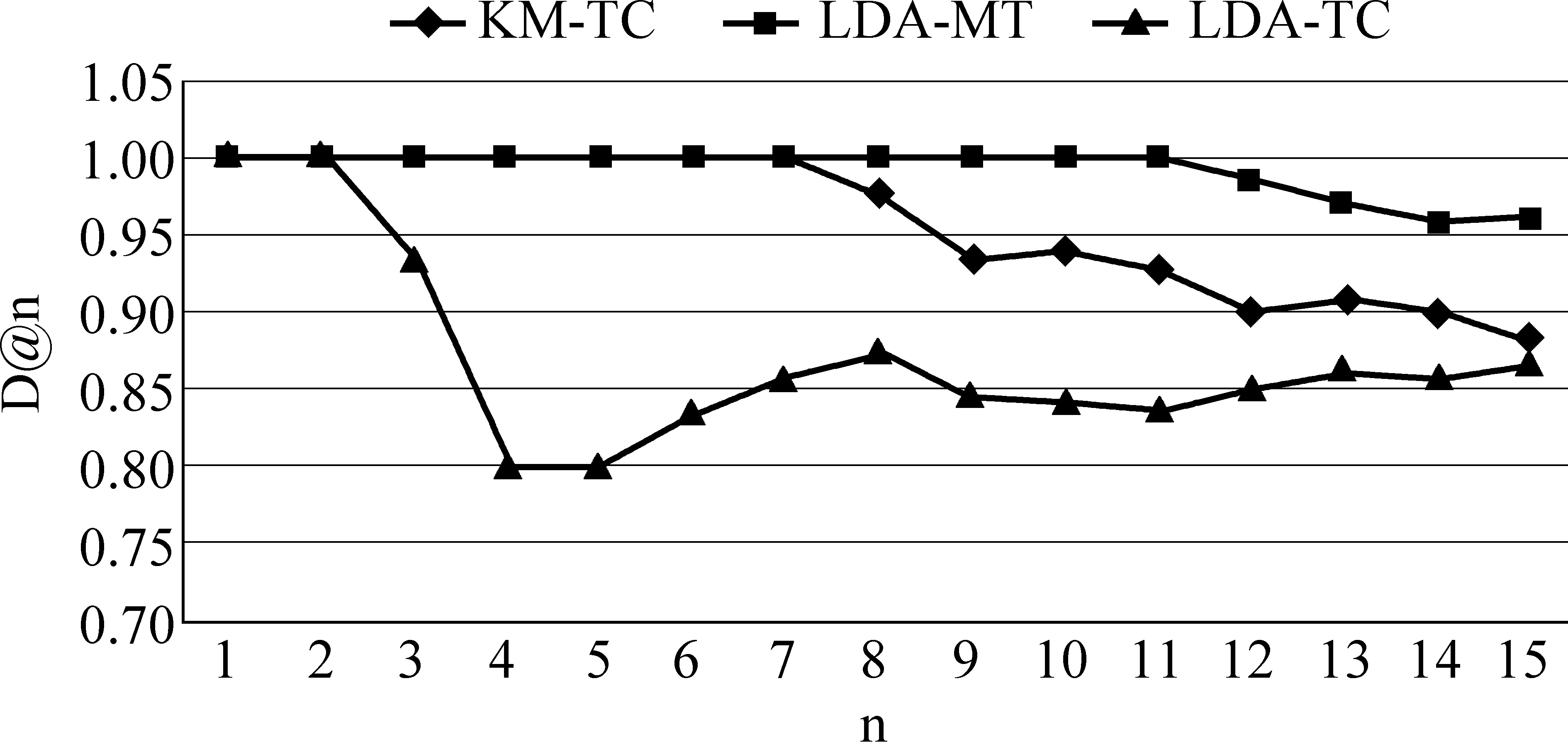
图4 语义多样性D@n
表1中我们给出了几个商户的三种方法的标签结果,由于版面原因我们只给出两个,另外我们还开发了一个标签抽取系统,以验证在实际应用中的可行性。

表1 最终结果举例
5 总结
本文提出了为产品或者商户生成语义相关描述标签的方法。通过K-Means聚类以及Latent Dirichlet Allocation(LDA)主题模型将每个标签映射到语义独立的主题空间,再根据每个标签相对该主题的置信度进行排序。实验可以看出,该种方法能够解决一定的实际问题。
在未来的工作中,需要继续考虑在聚类过程中语义距离的度量问题。此外,还需要考虑在时间维度上的动态主题迁移问题。
另外,对于目前社交网络中的用户对于产品或者商户的评价,可以将用户的信息以及其社交信息考虑到模型当中,进一步提高结果的准确性。
[1] Blei D.M., A.Y. Ng, M.I. Jordan. Latent dirichlet allocation[J]. The Journal of Machine Learning Research, 2003. 3: 993-1022.
[2] Kobayashi N., K. Inui, Y. Matsumoto, et al. Collecting evaluative expressions for opinion extraction[C]//Proceedings of Natural Language Processing-IJCNLP 2004, 2005: 596-605.
[3] 姚天昉, 聂青阳, 李建超, 等. 一个用于汉语汽车评论的意见挖掘系统[C]//中文信息处理前沿进展——中国中文信息学会二十五周年学术会议,北京:清华大学出版社,2006: 260-281.
[4] 姚天昉, 程希文, 徐飞玉, 等. 文本意见挖掘综述[J]. 中文信息学报, 2008,22(3): 71-80.
[5] Zhuang L., F. Jing, X.Y. Zhu, et al. Movie review mining and summarization[C]//Proceedings of the 15th ACM International Conference on Information and Knowledge Management 2006: 43-50.
[6] Hu, M., B. Liu. Mining opinion features in customer reviews[C]//Proceedings of 19th National Conference on Artificial Intelligence: Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999.2004: 755-760.
[7] Ma B.L.W.H.Y. Integrating classification and association rule mining[C]//Proceedings of In Knowledge Discovery and Data Mining,1998.
[8] Popescu A.M., O. Etzioni. Extracting product features and opinions from reviews[C]//Proceedings of HLT-Demo ’05 HLT/EMNLP on Interactive Demonstrations Association for Computational Linguistics.2005: 339-346.
[9] Etzioni O., M. Cafarella, D. Downey, et al. Unsupervised named-entity extraction from the web: An experimental study[C]//Proceedings of Artificial Intelligence, 2005: 165(1): 91-134.
[10] MacQueen J. Some methods for classification and analysis of multivariate observations[C]//Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. California, USA,1967: 14.
[11] Levenshtein Distance[OL]. http://en.wikipedia.org/wiki/Levenshtein_distance.
[12] Che W., Z. Li, T. Liu. Ltp: A chinese language technology platform[C]//Proceedings of Coling 2010, Demonstrations: Association for Computational Linguistics.2010: 13-16.
