基于全局用户意图的评论自动估价方法研究
2012-06-29陆剑江姚建民朱巧明
陆 军,洪 宇,陆剑江,姚建民,朱巧明
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
1 引言
主观性文本主要用于描述个人(或群体)对事物的看法或观点,它包括对商品、新闻的评论、个人博客等。目前,互联网上的主观性文本数量急剧增加,“如何恰当的分析和高效使用这类主观信息?”已经成为信息处理领域的研究热点。
产品评论是一种典型的主观文本,其往往是一种直接且重要的参考性信息。例如,除了商品的广告描述,消费者也可以借助用户的先验性评论,实现对商品属性和价值的认知。然而,由于互联网的开放性,任何用户都可以对商品发表质量迥异的评论。其中,“实用”性评论的内容往往全面丰富且有理有据,对消费者认知和判断商品属性具有较高的辅助作用;相反,“垃圾”评论书写随意,观点偏激,或文不对题,这类评论不仅欠缺参考价值,同时作为“噪声”负面影响消费者对商品的合理认知和正确判断。因此,评论质量的自动评价和低质量评论的自动屏蔽,对现有电子商务和基于用户的信息处理应用技术而言,都具有重要意义。
目前,部分电子商务网站已提供用户参与的评论质量评价机制。例如,Amazon.com购物网站提供了让消费者对评论质量投票的界面,并提供诸如“这篇评论对您有用吗?(Wasthisreviewhelpfultoyou?)”的询问,读者根据对这篇评论的理解判断,投“有用(Yes)”或“没用(No)”票,网站将根据群体给出的投票对评论进行排序。
尽管上述用户参与(即手动投票)的方式有较高准确性,但同时也蕴含较多弊端。首先,针对一条评论的投票分往往需要较长的时间才会趋于稳定(初始参与人数较少,投票的分值偏见性较强),而针对某项商品的多条评论则需要更长的时间才能使投票分值的整体分布趋于稳定。但是,分值及其分布是基于用户参与的评论价值评估及排序的重要依据,尚处于发布初期且投票率变异活跃的评论无法进行合理精确的质量认定。本文的前期工作统计了Amazon.com上1 870种新产品的评论在连续17天内用户参与投票的情况,发现绝大部分商品的所有评论中,在一天内仅有平均2~3个评论被投票,且大部分被投票的评论只获得一次投票。因此,人工参与的方法难以对新生成的评论给予高效快捷的质量评估;其次,不是每一条评论都能获得较多的投票,例如,在Amazon.com网站中,约38%的MP3评论只获得了三个或以下的投票[1],这样产生的投票分值并不可靠。因此,建立一种自动的评论质量评估机制已成为现有电子商务信息处理的重要课题。
目前,国内外对评论质量进行自动分析与判定的研究刚刚起步。其中,大部分研究把评论质量评估界定为一个基于内容的文本分类或排序问题[1-3]。本文认为评论的价值判定是一个较为复杂的问题,影响评论价值认定的因素不仅仅包括评论自身的结构特征,还有评论是否能符合用户的意图和需求等因素。观察发现: “优质”评论往往包含较多用户需要的产品属性信息和作者观点,同时可信度也比较高。比如下列评论*取自www.amazon.com,已翻译为中文。(评论后的数字为投票分):
(1) 我宁愿买尼康的相机。(3/54)
(2) 它比尼康的相机贵。(89/129)
(3) 这款索尼有20倍光学变焦。我甚至可以在照片中看到朋友的汗毛。(125/158)
显然,评论(1)没有提供有价值的参考信息,其价值投票分(3/54,即约为0.06)很低;评论(2)提供了评论者总结的价格信息,有一定价值,因此投票分(0.69)较高;评论(3)不仅有作者对产品的态度,还有对产品某一属性的详细描述,具有一定可信度,因此有更高的投票分(0.79)。上例说明: 用户意图这一因素在判断评论质量时存在一定参考价值。本文中,用户意图主要包含两大方面: 一是用户对产品相关信息的需求,包括产品的属性、使用情况、评价、观点等,往往包含这类信息的评论能够极大满足用户对商品认知过程中的知识获取要求;另一方面是评论的置信度,置信度高对于用户认知真实情况起到正面作用(作为对比,某些虚假广告对用户认知商品存在误导)。
本文探索了用户意图特征对评论价值判定的作用,其动机包含如下两个方面: 1)评论价值(“有用”或“没用”)的投票分直接来自用户的认定,挖掘和应用用户意图进行价值判定是解决该问题最直接的方法;2)用户意图信息与网站无关,只和评论相关,具有较强的通用性。在方法层面,本文同样把评论价值判定问题看成是一个分类问题: 在评论文本结构特征的基础上,考察了商品热门信息、评论情感和观点以及评论可信度等用户意图特征在分类中的作用,最后综合这些特征形成了较为高效的评论价值判定方法。
本文余下内容组织结构如下: 第二节给出相关工作;第三节对评论价值判定任务做了详细的描述和说明;第四节介绍了各种特征及其抽取方法;第五节检验这些特征的作用,并给出实验结果和分析。第六节进行总结和展望。
2 相关工作
针对本文提出的评论价值自动估计问题,目前的相关研究尚处于起步阶段,本章将对现阶段的主要研究进展进行介绍和分析。
目前,绝大部分工作将评论估价问题视为分类问题,通过提取正例(“有用”)和反例(“无用”)评论的特征,采用机器学习方法建分类模型,然后对评论的价值进行判断。某些研究则在此基础上进行价值层次的细化,借以进行评论的排序(由“优质”至“低质”)。例如,Kim等[1]通过训练SVM回归模型学习估测评论价值的函数,并对影响评论价值的特征进行了测试。通过实验,Kim发现评论的长度、一元词特征(仅针对英文)和评论作者对商品的评价分是最能影响评论价值的内容特征。Liu等[4]提出了信息量、可读性和主观性三个影响评论质量的因素,同样使用分类器来对评论的价值进行判断。Jindal[5]将这个问题看成是一个垃圾过滤问题。Cristian[6]指出评论的价值不仅仅和评论的内容相关,而且受到该评论与其他评论的关系影响。Yue等[7]通过评论者的背景信息和评论者之间的关系来判断评论的价值,其核心假设是: 经常发表“优质”评论的评论者趋向于继续发表“优质”评论,并成为“优秀”评论员,被“优秀”评论员认可的评论者也是优秀评论员,且其提交的评论也必定“优质”等。尽管,Yue的假设具有较高合理性,但关键问题在于大部分现有的电子商务网站并不提供这一假设所必需的信息,例如,评论人与评论人之间的认可关系。尤其,这一假设将“优质”评论的来源收敛于“金字塔”的尖端,中层(“时好时坏”的评论人)和底层(偶发“优质”信息的评论人)发布的“优质”评论往往被这一假设彻底摒弃。
总体上,分类技术已成为现阶段评论质量自动评估的基本处理平台,核心问题转变为如何选择有效区分价值层次的特征。此外,Liu,Cristian和Yue给出的研究成果在一定程度上证明: 自动估计评论的质量不仅仅可以依赖纯粹的文本内容或语义,也可以借助情感分析、认知心理和社会计算等外界干预予以实现。本文即是在这一思想的基础上,提出了融入个性化技术的评论质量分析方法,即基于全局用户意图的评论自动估价方法。其中,用户意图专注于如何挖掘用户关注的产品属性(热度)及其受到外界赋予的观点(情感),以及评论取信于用户的程度(置信度)。“全局用户意图”强调针对特定产品的用户群所具有的信息需求(整体的热度、情感和置信区间)。
3 任务描述
3.1 评论价值的定义
本文的主要工作是自动地判断一条商品评论对于大多数用户(消费者)来说是否有价值。因此,有必要对评论的价值作一些说明: 什么是有用的评论?以Amazon.com的投票分为例,经人工标注发现“对评论有用的投票率达到或超过60%”[2]时,评论具备一定价值。图1显示了Amazon.com 网站上某数码相机的一条评论,在图的顶部可以观查到: “268/272人认为此评论有用(268of272peoplefoundthefollowingreviewhelpful:)”,由此可判定该评论为“有用”评论。本文称上述票率(268/272)为评论价值投票分数(voting rate)。
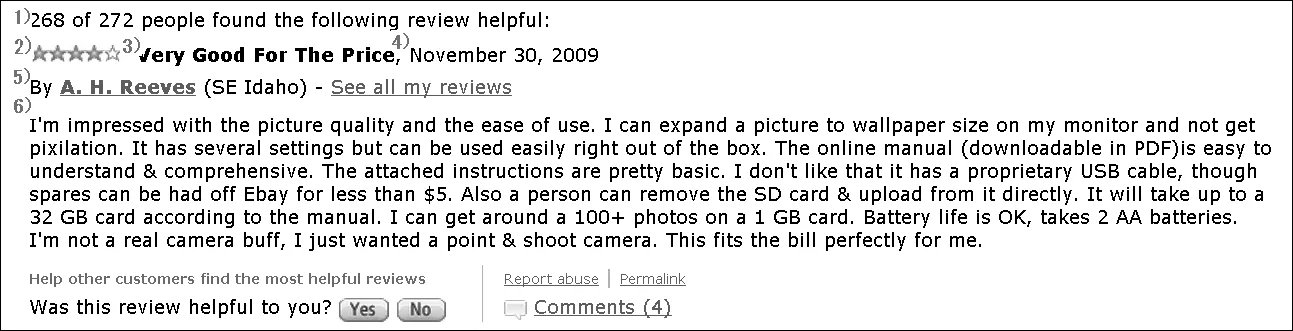
图1 Amazon.com上的一条典型评论
3.2 评论自动估价的基本任务
上述投票分仅仅提供了一种评论的价值分,而没有明确指出影响评论价值的因素。因此,价值投票分可以作为评判评论质量估计和分类系统性能的人工标准: 分值高于0.6的评论划归为“有用”评论,否则为“无用”评论。本文的任务即根据这一人工标准实现评论自动估价系统的测试与性能评价。
夹嘴夹持导线提供摩擦力时要求夹持稳定性能可靠,同时还要保证导线不受损伤,因此卡线器夹嘴不应过短。但是,夹嘴过长容易导致卡线器整体尺寸、质量过大,造成搬运和移动不便。导线的夹紧状态如图3所示。
4.3.3 评论可信度
1) 评论文本的质量。人们一般较容易接受书写规范的评论,而不喜欢书写随意的评论。
2) 满足用户意图的程度。用户(消费者)阅读评论通常带有一定的目的,评论中的信息是否满足用户的需求也是一个重要因素。此外,“有用”评论中的信息通常会满足大多数用户的需求,而不是迎合个别少量用户的意图。从另一方面讲,如果采用一般语料标注的方法,让若干(3~5个)用户对一批评论进行价值标注,其标注结果和Amazon.com上的投票分会有较大的差异。原因在于前者标注的结果仅反映了少数用户的需求或意图。相对地,Amazon.com的评论价值投票分来自人数更为众多的群体标注结果(比如图1中272人参与了投票),其反映出了较大群体的共同需求。显然,后者标注的评论价值更为可靠和准确。从这个意义上讲,即使是人工判断也存在一个准确率上限,对评论价值认定的极值很难达到100%。这一现象不仅说明基于纯粹文本内容进行评论价值估测的难度(内容质量高不等于用户一定认可其价值),同时也说明用户认知属性,尤其是个性化特征,在评论质量判定中不可忽视的作用。
3.3 Amazon.com 网站评论简介
本文基于Amazon.com商务网站中的大规模评论资源展开分析与实验,其评论资源的属性及功能具有一定代表性[1,4,8],基于这一资源进行的算法设计和实验可在一定程度上达到通用性。下面对Amazon.com网站的评论格式给予介绍和说明。
综上所述,在京津冀协同发展的背景下,河北省高职院校“校园贷”法律教育引导机制从三个维度构建:“知”:通过加强河北省高职院校学生“校园贷”相关法律理论认识,构建法律意识体系,建立正确的法制观念;“情”:通过深入了解社会主义法制体系,增进学生对我国社会主义核心价值观产生价值认同;“意”:需要通过学以致用的社会实践活动,形成自觉懂法、守法、用法进而践行社会主义核心价值观的理想信念。
Amazon.com是一个大型的B2C购物网站,该网站记录了超过170万条产品评论。图1为Amazon.com 网站中的一条评论样例。如图所示,任意一条评论主要包括以下信息: 1)投票分; 2)星级; 3)评论的标题; 4)评论发表时间; 5)评论作者; 6)评论正文。
如前所述,判断评论的价值是一个复杂的问题,本应充分利用各种信息辅助这一判断。但是,本文的另一目标是使得方法具有较强的通用性,因此必须舍弃评论中的部分特例信息。例如,第2)项信息(星级)是基于人工判断而获得的量化指标,且并非所有的商务网站都存在或利用这类信息。因此,尽管Kim基于Amazon.com的评论资源获得的实验结果验证了“星级”是估测评论质量的有效特征[1],但因其通用性不强且含有人工因素,本文不将其列入自动评估系统的特征采集对象中。另外,第5)项信息(即评论的作者)也是一种非常有效的特征,如第二节所述,Yue通过使用评论者及其关系特征有效改进了评论价值判定的性能。但是,并非每个网站都提供评论者的背景及其在网络中各种行为、状态或关联信息,尤其是国内的绝大部分电子商务网站对网络用户的背景信息控制得更为严格。为此,面向评论自动估价方法的通用性,本研究也舍弃了这类信息。
4 基于全局用户意图的评论价值判定
本文将评论蕴含热门属性的量化指标作为一项重要特征,因此挖掘产品属性,尤其是热门属性,成为构建这一特征的重要步骤。本文通过问答网站(Yahoo! Answers*http://answers.yahoo.com)实现产品热门属性的检测与挖掘。方法的流程如图3所示。首先,从商品标题中抽取品牌名和型号;然后,提交给问答网站进行检索,获取相关问题及其描述;最后,基于问题的文本特征及其分布进行统计分析,获取被频繁提问和回答的产品特征,形成热门产品属性库。该方法的核心思想是: 在问答交互网站中,频繁被用户咨询的产品特征往往是备受关注的属性,具有一定热度。与通用搜索引擎相比,从问答网站获取的资源更符合本研究的要求,且噪声信息较少。下面具体介绍该方法的各个模块。
4.1 基于用户意图的评论估价方法框架
本研究致力于探究基于用户(消费者)意图、需求进行评论价值判定的方法。基于全局用户意图的评论价值估测系统包括如下方面: 1)基本的分类模块; 2)特征抽取模块。如图2所示,分类模块采用SVM分类器,并融入了基本的文本内容特征形成Baseline系统。特征抽取模块获取了基于用户意图的属性热度、可信度以及情感和观点等特征,从而形成最终的评论价值分类系统。其中,属性热度的估计使用了基于问答系统的热门产品属性挖掘技术;而情感和观点抽取模块则使用了简易情感分类器实现情感和观点挖掘。本节后续内容将逐项介绍上述模块的功能及运行机理。

图2 系统框架
4.2 基于文本特征的价值分类系统(Baseline)
基线系统(Baseline)采用SVM分类器对评论进行有用/无用二元分类。参考Kim[1]和O’Mahony[3]的研究工作,该分类系统中使用了两大类的特征: 评论文本的结构特征和可读性特征。Baseline系统的特征融合了多人提出的有效特征,基本可以反映或超出特定工作的性能。
本文主要对DMS/RS进出库复合作业路径问题进行优化,今后将对大型DMS/RS的货架参数、资源配置及系统能耗等进行更深入的研究,在最大程度提高仓储运行效率的同时,合理规划仓储设施,降低投资成本,为企业建仓初期提供决策依据。
结构特征: 结构特征在评论价值估计中主要体现为文本的浅层统计信息。在本研究中,下列统计信息被作为特征用于分类: 评论文本的长度,即单词总数、句子总数、段落总数、句子的平均长度、段落内的平均句子数。
① 如果评论中的观点与主流观点相差很大,那么这类评论很可能为“无用”评论;
4.3 全局用户意图信息
“消费者在阅读评论时希望获取什么信息?”是基于用户意图的核心问题。观察发现: 对于大多数消费者而言,阅读产品评论是为了获得相关商品属性的认知。另外,如前所述,根据Amazon.com网站上投票分数产生的机制,这些信息必须满足大部分消费者的意图和需求。本文将上述信息称为全局用户意图信息,并细分为三个方面: 商品热门属性信息、评论中的观点情感、评论的可信度。下面分别详细介绍这三种信息及其抽取方法。
水生态文明建设是解决石羊河流域生态问题的必要途径……………………………………………………… 王 浩(5.19)
医院单纯追求费用控制,降低成本,会导致对医疗质量的影响,削弱临床医疗效果,易造成医患关系矛盾突出,不利于医院管理部门对医生的医疗活动的监管,不利于提高医院管理水平。针对这种情况,要将成本控制的内涵,延伸、扩展到医院的管理之中,让成本控制在日常工作中持续应用和发展,完善预算执行和成本核算的考核体系,建立健全完整有效的成本控制系统。
产品热门信息主要是产品的相关热门属性。显然,获取和认知产品的属性是大部分用户浏览评论的主要目的,从而,评论包含较多产品属性的介绍、分析等文字时,往往能够满足大部分用户的需求。例如,图1所示的评论蕴含大量产品属性的描述,如图像质量(picture quality)、设置(setting)、在线手册(online manual)等。其中,被众多用户关注的属性称为热门属性,而受关注的程度称为热度。
本文继承了基于分类技术的评论价值评估策略,使用投票分0.6作为“有用/无用”评论的划分标准。本节后续内容侧重介绍基于用户意图的评论估价系统框架及特征选择方法。

图3 商品热门属性的获取
1) 品牌和型号的提取: 其目标是形成有效的查询,并获取对应产品的最相关问题及其描述。品牌和型号可以唯一确定一个商品,因此,本文将商品的品牌和型号作为检索词。实验通过启发式规则,从Amazon.com网站提供的商品标题中抽取品牌和型号。例如,某数码相机的标题为: “NikonCOOLPIXL24 14MPDigitalCamerawith3.6xNIKKOROpticalZoomLensand3-InchLCD(Red)”。统计发现,大多数相机的标题皆具有同样格式:
[品牌][型号][像素值][Digital Camera][其他信息]
借助这一标题格式,可以抽取绝大部分数码相机的品牌和型号。对于其他类别的商品也有相对应的描述格式,用同样的方法可以获得相应的品牌和型号。
2) 检索相关问答对: 将商品的品牌和型号作为检索词在Yahoo! Answers问答网站中搜索,每个商品选取500个最相关的问题(即前500个检索结果)作为热门属性抽取的资源。
3) 热门属性提取: 对于某个商品,提取过程将获取到的问题看作独立文档,通过文档频率选出高频的关键词和短语*短语提取使用工具: OpenNLP,http://incubator.apache.org/opennlp,且只保留名词和动词以及相关短语。最终,对于每个商品,提取频度最高的200个关键词或短语,并假设其为当前商品的热门属性描述。
根据统计,属性信息提取的准确率为75%。另外,本文方法使用了热门属性,在评价属性是否热门时,需要人工参与评价。通过人工标注与观测,在四类产品的800个热门属性中,召回率可以达到90.03%。
基于热门属性的评论质量划分将特定评论蕴含热门属性的程度作为分类特征。为此,本文采用评论内容对热门属性的覆盖率计算这一特征值,如式(1)所示:
其中,S表示在步骤3)中获得的产品热门关键词或短语集合;TF(f,r)表示关键词或短语f在评论r中出现的次数,即词频;Len(r)表示评论r的长度。
4.3.2 评论情感和观点
评论中另一种非常重要的信息是评论者的观点。用户通过评论中的情感和观点可以更加了解商品整体质量的优劣。换言之,评论包含产品属性能够提供用户认知产品的局部对象,而针对属性的情感表述和观点描述,往往能够透视出这一对象的价值,其对于用户感知产品的潜在价值更为重要。例如,“像素”为“数码相机”的某一属性,其提供了用户认知产品的某一局部对象,而针对“像素”的“高”、“中”、“低”、“好”、“坏”等用户情感或观点,往往能够提供更为具体的属性感知度。本文从两方面考察评论者的观点。
1) 评论中情感词所占的比例
这一数值表明了评论者观点的多少。对于优质的评论,情感词比例往往在一个合适的范围。其基本假设是: 情感词过少表示观点少,体现为“欠缺主见”;相反,情感词过多则过分强调主观性,往往缺少以属性为载体的依据,体现为“站不住脚”的评论。理想情况是在描述了商品某一属性后,对其给予适当观点和情感描述。本文采用评论中情感词比例来量化这一特征,即情感词数量与评论中名词或名词短语数量的比值。本工作使用了MPQA*情感词词典: http://www.cs.pitt.edu/mpqa/#subj_lex icon情感语料库中的情感词词典,通过简单匹配来识别情感词。
2) 情感倾向
通过对语料的观察和统计发现: 相对于负面的评论,用户更加认同正面的评论。图4是在语料中对星级和价值投票分数关系的统计,从图中可以观测到如下现象: 评论者的情感倾向越是趋向正面,其评论越可能有用。
当代艺术强调的是强烈的视觉性,当代公共艺术更是将这种视觉形式强化成与地域、人文、场域、环境等因素相适应的具有在地性的公共文化消费。它主张的是面向公众的艺术展示和具有前沿艺术观念的呈现方式,是一种与当代社会普遍价值相联系的艺术存在。所以,对于这次具有特殊意义的艺术行动,我们打破常规,在文化上强调以沙漠人文为依托;在方式上主张以景观性、互动性为主导;在艺术上选择以抽象与具象性相结合。为了与沙漠的人文地理相呼应,我们在作品的体量、高度、材质以及空间布局上面制定出一个选择标准。为此,为了体现公正、公平的竞争原则,选拔出适合于本次活动的优秀作品,艺委会向全球征稿。

图4 每一星级评论的平均价值
Amazon.com网站中的每一条评论都有显式情感倾向(星级),但面向通用性,本研究舍弃了星级这一特征。相对本文采用一个简单的情感倾向分类器实现倾向的自动识别,其在一定程度上继承了星级特征的优势,并且利用评论自身内容实现倾向自动识别,具有一定通用性。该情感倾向分类器仍然使用SVM分类器,并利用了如下两个特征:
① 评论标题中的正面情感词与负面情感词的数量差,计算公式如式(2):
4.3.1 产品热门信息
其中,Npos、Nneg分别表示标题中正面和负面情感词的个数。
测试阶段,对于每个商品,除了用于构建主流观点的评论,其他全部评论作为价值估测系统的输入进行自动价值划分。
② 评论正文中正面单词与负面单词的差,计算公式如式(3):
其中,Npos、Nneg、Nword分别表示评论正文中正面、负面情感词个数和总的单词数。
推荐理由:明代版画谱规模蔚为壮观,其不乏文、图、刻三者俱佳的精美刻本,经历时代拣选和文脉承传,成为明代文化中一颗熠熠生辉的明珠。《唐诗画谱》《宋词画谱》《竹谱详录》《方氏墨谱》便是其中内容广为传颂、书写萧散简远、刻画洗练精致的善本。为此,我们特遴选珍贵范本,进行整理翻印,并作了详尽注释。希望帮助读者轻松读懂唐诗、宋词、竹话、墨语,使这份珍贵的文化遗产走进寻常百姓家。
本文前期实验中,对上述情感分类器进行了测试,测试过程将其作为二元分类器实现褒/贬的二元划分(在价值判定中输出-1~1的实数来表明情感倾向)。前期实验使用的语料同样来自Amazon.com。实验舍弃了星级为三的评论,将星级为四、五的评论标记为正面评论,其余为负面评论。此分类器的性能如图5所示。结果显示,该情感分类器的性能均值高于80%,基本达到了作为系统中间步骤所需要的精确性。同时实验结果显示了这一分类器稳定性较高的特点: 对训练集规模不敏感,在训练集数据量变化较大的情况下性能比较稳定。因此,价值判定系统中不需要为该分类器提供大规模的训练数据。

图5 情感分类器性能与训练数据规模的关系
如上所述,投票分是一种人工给定的评论质量的界定指标,而自动估计评论质量的过程必须在规避这一因素的基础上探索新的途径。换言之,估计评论质量的关键在于分析和挖掘影响评论价值的本原因素或特征,本文认为影响评论价值的因素应包括如下方面。
将评论可信度作为特征源自如下假设: 不可信的评论难以得到用户的认可,并且往往作为噪声误导用户。但通常难以对评论可信度进行度量,原因在于多种因素都能造成评论置信度低,例如,“虚假广告”、“毫无商品使用经验的评论人”和“恶意诽谤”等。本文前期工作中,通过对大规模数据的人工观测,获得了如下两种普遍影响置信度的特征。
1) 评论中过去式、过去分词的比例。观察发现: 通常评论用语中较多出现表述过去事件的词语时,其置信度较高。解释这一现象的一种假设是: 过去式往往印证了评论人已对商品具备自身体验,由此,其对商品的评论具有一定真实性和可靠性,从而可信度较高。
2) 评论中观点倾向与主流观点的一致性。每条评论都具有评论者对相应商品的情感倾向。同时,每项商品也具有主流的评价观点(通常反映出这个商品的真实质量评价)。假设:
可读性特征: 可读性反映文本易于阅读和理解的程度和性质,Ghose[2]和O’Mahony[3]的研究表明评论的可读性可以用于评论价值的判断。下列可读性计算方法较为常用且被认为可以较好地度量文本的可读性[9],因此被引入本文的分类系统中: 1)自动化可读性指数 (Automated Readability Index, ARI); 2)柯尔曼—刘指数 (Coleman Liau Index); 3)佛莱士易读度 (Flesch Reading Ease); 4)佛莱士—金凯德年级水平(Flesch-Kincaid Grade Le-vel); 5)甘宁灰雾指数(Gunning Fog Index); 6)SMOG指数 (SMOG Index)。
② “有用”评论的情感倾向往往比较可靠且和主流观点一致。
上述假设基本上拟合了Amazon.com语料上的统计规律。计算评论中观点与主流观点的一致性分两步: 首先,获取评论的情感倾向(用4.3.2节的情感分类器实现);其次,获得相应商品的主流观点倾向,方法如下。
步骤一: 建立评论价值分类器,分类算法仍然为SVM,特征为上文提到的所有特征。
2.3.2 土壤质量评价因子最小数据集的确定 在筛选的7项候选指标中,进一步相关分析表明(表4):各指标间存在显著的相关性,其中,碱解氮、速效磷、速效钾分别与pH和有机质呈显著相关,而pH与有机质间无明显相关性,故确定pH和有机质为评价指标;有效镁与pH,以及水溶性氯与碱解氮间呈极显著的相关性,而有效镁和水溶性氯与其他指标无明显相关性,信息相对独立,确定有效镁、水溶性氯为评价指标。综上所述,昌宁基地单元植烟土壤质量评价因子最小数据集为pH、有机质、有效镁、水溶性氯。
步骤二: 对于每个商品,使用步骤一中的分类器找出K个 “有用”评论。
步骤三: 通过调整K值,使得分类器对该K个评论价值的判断准确率最高。
步骤四: 利用步骤二和步骤三获得的K个评论的观点倾向构建主流观点,计算公式如式(4):
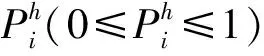
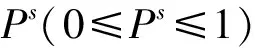
传统理论认为法律趋同有两种方式:一种是被动地接受其他国家的法律,又称移植,对应上文法律的强行趋同;另一种是主动地接受其他国家的法律,又称继受,对应上文法律的自发趋同。该理论同时主张,不论是移植还是继受,都是经济落后国家对经济发达国家法律制度的趋同。并且,不同法律体系的移植和继受都从法律制度的改变开始,该制度可以脱离一国的法律文化而产生,但要使制度有稳定性和适应性则需要由该法律制度所表征的法律文化与本土原先的法律文化消解冲突并相互融合,最终才能在新产生的法律文化上彰显制度的生命力。[注]参见米健:《当今与未来世界法律体系》,第14-19页。
田朵接过她为小宁点的那份套餐时,才想起来她忘了备注免辣。小宁受伤住在医院,医生说得忌辣,伤口才能好得快一些,可是她给忘了。这要是放在过去,她和小宁肯定免不了为此吵上一架,说不定还会把外卖给摔了。好在现在俩人都收敛了,田朵默默地拿着筷子往外夹辣椒,小宁连说没事,没那么矫情。这样的一派和谐,让田朵心生感慨,唉,如果以前她能懂得夫妻之间要互相包容和忍耐,小宁也就不会受伤住院了,两个人也不会差点闹到离婚的地步。
5 实验结果与分析
5.1 语料及评价标准
本研究语料来自Amazon.com网站,收集了2011年5月间部分电子产品的所有评论信息。按商品类型划分,评论语料共有四类: 手机、数码相机、计算机和电视机。如第三节所述,本文将投票分高于0.6的评论划分为“有用”评论类别,否则为“无用”评论。此外,实验中的所有语料都来自Amazon.com网站中热门产品的评论,借以保证语料中评论的新颖性及时效性;同时,语料中票数少于五的评论已被舍弃,借以保证语料中各评论的投票分都具有饱满的基数,并生成可靠性较高的投票分,使评价标准规范化。
(4)Under the new international and national circumstances,transformation of economic growth model is a must for us.
根据上述条件获得的语料并不平衡。其中,“有用”评论数量约为“无用”评论的四倍。为了更均衡地度量本文方法的性能,实验随机去除部分“有用”评论,使得“有用”和“无用”评论数量大致相当。由此,实验只需使用精确率指标即可度量本文方法的性能,即是否正确判定评论的有用性(无论评论的真实价值为“有用”或是“无用”,只要系统给出判定符合人工认定的结果,即为正确)。最终,实验使用的语料包括1 335个商品的28 231个评论,具体统计数据如表1所示。
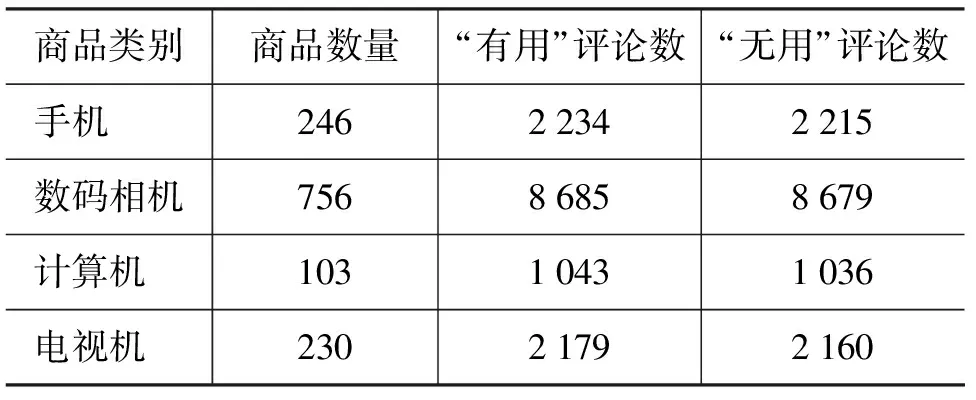
表1 语料分布情况
5.2 实验结果与分析
本研究使用分类器作为系统的框架,除Baseline系统所使用的特征外(评论结构特征和可读性特征),实验重点测试了三种用户意图信息的作用。另外,在4.2.2节中,情感分类也使用了分类器。本文中分类算法都选择为SVM,使用了LIBSVM[10]工具,核函数为RBF,其余参数都为默认值。由于系统基于二元分类器,且使用了平衡语料,因此仅使用精确率(分类正确实例数占所有被分类实例的百分比)对分类性能进行度量。
另外,为了得到稳定可靠的结果,所有分类实验采用了五倍交叉验证。新加入的用户意图特征包括产品热门信息、评论情感观点和评论可信度,如在4.2.3节所述,计算评论可信度时需要确定参数K,K值选择对评论质量判定的性能具有较大影响。因此,实验基于训练语料,通过调整K值并观测其中“有用”评论百分比的方式对其进行训练。图6显示了K在不同取值下,有用评论所占的比例的平均值,从图中可以发现当K取3时,平均准确率达到最大。在后续的实验中,K始终取值为3。
(3)基坑开挖过程中,桩间土体流坍。现场踏勘情况表明,隧道下部地层为中砂,在基坑开挖中有桩间土体流失现象发生,致使隧道侧面及基底地层损失和漏空,进一步影响了隧道结构的受力状态。

图6 K值的训练结果
5.2.1 全局用户意图信息的测试
本文提出了三种全局用户意图特征。首先,实验分别单独考察上述三种特征对判定评论价值的效果。实验结果如表2所示。其中,Baseline表示4.1节中介绍的基于评论内容结构化特征的评论自动估价系统,Pattr表示融入产品属性热度这一特征(product attribute)的估价系统,Ropn表示融入评论观点信息(review opinion)的估价系统,Rcrd 表示评论可信度(review credibility)。如表2所示,在Baseline系统的基础上,每种用户意图特征都有助于评论的价值分类。三种用户意图信息中,评论情感和观点信息对价值的判断作用最大,评论可信度其次,作用最小的是产品热门信息特征,仅在Baseline系统上提高了1.2%。

表2 各个特征对评论价值分类的性能
通过观察实验中间数据发现: 影响产品属性热度对评论质量估测发挥作用的主要原因是: 通过问答网站获取的某些热门属性过于泛化,换言之,这类属性往往表述产品的基本性质或构成,其作为评论对象的频率较高,并以近似的概率出现于“有用”和“无用”评论中。这类属性有悖于热度特征的基本假设,即高频出现于用户提问则备受用户关注(具有较高热度),其仅仅是论述某一产品时必不可少的基本成分。比如,对于所有产品而言,“价格”和“包装”等属性即为泛化属性,尽管高频出现,具有一定热度,但对于区分不同产品及其评论质量却并不奏效。相对地,诸如“高像素”、“画面清晰”和“自动成像”等属性则具有相对较强的区分力,且在“相机”类产品的问答对中高频出现。如何对属性特征的泛化与热度指标进行区分和应用,将作为本文未来工作的重要组成部分。
1级(轻度静脉炎):一种炎症症状或体征(不包括条索状硬化或脓液流出);2级(中度静脉炎):出现两种炎症症状或体征(不包括条索状硬化或脓液流出);3级(重度静脉炎):出现条索状硬化和/或脓液流出和/或更多炎症症状或体征)。
5.2.2 用户意图特征的组合效果
以上对三种用户意图特征进行了单独测试,在此基础上,实验将上述三种特征进行组合,共同用于评论价值的判断和测试。同时,实验分别在四种商品类别上进行了测试,实验结果如表3所示。
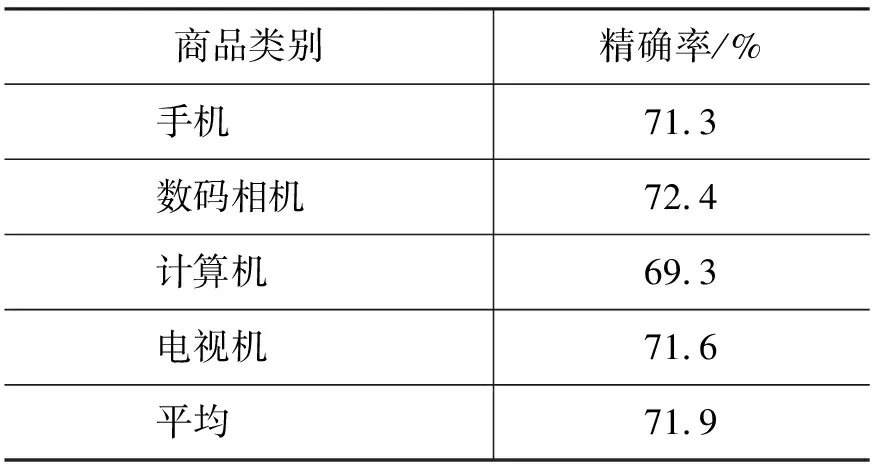
表3 所有特征对不同类商品评论价值分类的性能
表3中,平均性能是根据每类商品的评论数目的加权平均性能,计算公式如式(6):
其中,N是所有评论的数目,ni表示第i类商品的评论数,pi为第i类商品的准确率。由表3可知,借助用户意图特征的组合,评论质量估测系统性能获得了进一步提高,其加权平均精确率可达到71.9%,从而说明用户意图信息对判断评论质量的有效性。
6 总结与展望
本文致力于讨论如何自动估测评论的价值,并尝试从用户意图角度考虑影响评论价值判定的因素及其挖掘方法。基于用户意图的特点,本文提出了三种影响评论价值的特征: 产品热门信息、可信度以及评论的情感和观点,同时尝试对这三方面的信息进行挖掘和应用。实验表明,上述三种特征对评论价值的判断具有较好效果,尤其当组合使用这三类特征时获得了约11.5%的性能提高。
未来工作将进一步探索和研究反映用户意图的特征。本文所应用的用户意图特征仍然较为粗糙,还可进一步细化。例如,对于观点特征而言,用户往往并不仅仅关注评论中表层的观点,而是更为倾向获取支持特定观点的理由和证据(一种深层的观点)。现阶段,针对这一深层观点及其关系挖掘的工作在国内外尚属空白,从而将其应用于评论价值估测中具有一定难度。对于这一问题,一种有待尝试的方法是利用事件抽取技术实现观点主干信息的提取,并在此基础上利用指代消解技术进行观点主干与相关外围论述的关系挖掘,形成{观点特征,关系特征}的模板,构建观点及相关论证内容的关系和概率模型,并将其应用于评论价值估测。此外,未来工作的另一项重点内容是细化评论质量的层次,超越现有“优质”和“低质”的二元层次,实现基于价值层次的评论排序。
致谢
感谢苏州大学朱巧明教授和姚建民教授对本研究的长期支持与资助。感谢洪宇老师对本文工作的悉心指导。
[1] Kim S M, Pantel P, Chklovski T, et al. Automatically assessing review helpfulness[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing. 2006: 423-430.
[2] Ghose A, Ipeirotis P G. Estimating the helpfulness and economic impact of product reviews: mining text and reviewer characteristics[J]. IEEE Transactions on Knowledge and Data Engineering, 2010.
[3] O’Mahony M P, Smyth B. Using readability tests to predict helpful product reviews[C]//Proceedings of Adaptivity, Personalization and Fusion of Heterogeneous Information. 2010: 164-167.
[4] Liu J, Cao Y, Lin C Y, et al. Low-quality product review detection in opinion summarization[C]//Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL). 2007: 334-342.
[5] Jindal N, Liu B. Opinion spam and analysis[C]//Proceedings of the International Conference on Web Search and Web Data Mining. 2008: 219-230.
[6] Danescu-Niculescu-Mizil C, Kossinets G, Kleinberg J, et al. How opinions are received by online communities: a case study on amazon.com helpfulness votes[C]//Proceedings of the 18th International Conference on World Wide Web. 2009: 141-150.
[7] Lu Y, Tsaparas P, Ntoulas A, et al. Exploiting social context for review quality prediction[C]//Proceedings of the 19th International Conference on World Wide Web. 2010: 691-700.
[8] Paltoglou G, Thelwall M. A study of information retrieval weighting schemes for sentiment analysis[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. 2010: 1386-1395.
[9] DuBay W H. The principles of readability[J]. Impact Information, 2004: 1-76.
[10] Chang C C, Lin C J. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2011, 2(3): 27.
