基于归一化点向互信息的低资源平行语料过滤方法*
2022-01-25章浩然
吴 霖,章浩然
(昆明理工大学,云南 昆明 650500)
关键字:神经机器翻译;过滤;归一化点向互信息算法;平行语料;对齐信息
0 引言
神经机器翻译是数据驱动模型,提高平行语料的规模和质量是提升神经机器翻译性能最简单有效的方法。然而,通过非人工方式得到的平行语料,其规模足够但质量不佳。平行语料质量不佳的情况下,提高其规模并不会让模型有较大的性能提升甚至存在性能下降的情况,因此提高平行语料的质量成了提升模型性能的关键,这使得平行语料过滤方法变得越来越重要。
语料过滤方法是从一个大规模的、含有噪声的平行语料中,过滤出一个较高质量的子语料,并以此来提高翻译模型性能的方法。当前,根据句子长度、句子长度比例以及语言标识等来过滤语料的方法较为简单和通用。其中语言标识过滤是过滤掉特定语言对中不属于该语言对的句子,例如在汉泰语料中,只过滤源语言不为汉语且目标语言不为泰语的句子。但是,这些方法只能过滤存在明显错误的句对,难以判别并过滤词翻译错误或句意不一致的句对。利用少量干净的平行语料来提供对齐信息,根据提供的对齐信息来判别每个句对是否为噪声句对的过滤方法也较为常见[1-3],但这些过滤方法都需要有少量干净的平行语料。但在低资源语言对中,可能存在大规模且含有噪声的平行语料,并不存在少量干净的平行语料。
例如OpenSubtitles[4]中的汉泰平行语料就存在大量噪声,致使翻译模型性能不佳,也不存在干净的且领域相同的平行语料提供对齐信息;因此需要从噪声语料或单语语料中寻找对齐信息。而在神经机器翻译领域中,通常采用跨语言预训练模型或多语言预训练模型来提供对齐信息。Ivana 等人[5]利用无监督神经机器翻译生成伪平行语料来提供伪对齐信息,然后利用该伪平行语料微调跨语言模型(Cross-lingual Language Model,XLM)[6],以此来获取多语言句子嵌入信息。该方法可以用于计算句子间的相互翻译程度,从而挖掘和过滤平行语料,但这样的方法需要庞大的单语语料和强大的硬件支持。
为了减少对单语语料和硬件的依赖,从噪声语料中抽取出对齐信息是更为有效的方法。点向互信息(Pointwise Mutual Information,PMI)[7]是一种获取语料中词对共现概率的方法,其词对共现概率是由词对中两个词各自出现的概率和其共同出现概率来得到的。由于噪声语料中,对齐较差的词对不具备规律性,其共同出现的概率低,会被PMI 赋予低共现概率,而对齐较好的词对存在一定的规律性,会被PMI 赋予高共现概率,通过这样的方法可以从噪声语料中抽取出可靠性高的对齐信息。然而,由于PMI 会给予低频词更大的权重,这会导致低频词对具备更大的共现概率,形成噪声,降低对齐信息的质量。因此,本文采用给予低频词对更低权重的归一化点向互信息(Normalized Pointwise Mutual Information,NPMI)[8]来抽取噪声语料中的对齐信息。
本文采用基于NPMI的平行语料过滤方法,该方法直接在噪声语料中抽取出对齐信息,并利用其中可靠性高的对齐信息来过滤噪声语料。本文在OpenSubtitles的泰语—汉语翻译方向上提高了5.8个BLEU 值,汉语—泰语翻译方向上提高了10 个BLEU 值。该方法在2020 年国际机器翻译大赛给出的柬埔寨语—英语单向翻译任务中实验,得到的结果比基线高了0.4 个BLEU 值。
1 相关工作
1.1 平行语料过滤任务
国际机器翻译大赛(WMT)在2018 年[9]、2019 年[10]、2020 年[11]分别举行了不同语言对的平行语料过滤任务比赛,其中也包括低资源语言对,例如柬埔寨语-英语以及普什图语-英语,这也是目前最有影响力的平行语料过滤任务。在WMT2020的任务中,参赛者根据噪声语料中每个句对的质量进行评分,最终按照每个句对的分数由高到低选取。为了降低平行语料数量的影响,官方规定了过滤后的平行语料中,英语语料的词元(token)数为5百万左右。其评价平行语料质量的方法是在该平行语料上训练一个翻译模型,翻译模型的双语评估替补(Bilingual Evaluation Understudy,BLEU)值越大则代表平行语料质量越好。此外,所有参赛者都使用相同的翻译模型,参数由官方给定。
1.2 平行语料过滤任务
句对的相互翻译程度(以下称之为平行度)的计算是过滤方法的核心。句对平行度的计算可以分为词级和句级,现有的过滤方法也主要以这两个方面为主。因此,如何找到意思表达更精确的词向量或句向量,以及如何找到更为精准的对齐信息是提高过滤性能的关键。
Herold 等人[12]采用glove[13]在每个语言的单语语料上分别学习该语言的词向量,并将两种语言的单语词向量映射到同一向量空间,两种语言句子中每个词对的余弦相似度的总和作为句对平行度,最后实验证明了语言标识检测方法的有效性以及适用范围。除了利用词向量来计算两个语言句子的平行度外,还可以利用多语言预训练模型或跨语言预训练模型,具体是将两种语言的词或句子向量映射到相同向量空间中并在一定程度上将它们进行对齐,以此来保证两种语言的词或句子向量可以进行更为精确的余弦相似度计算。
阿里巴巴团队[14]利用小规模干净的平行语料对语料过滤模型(GPT-2[15])进行了最初的训练;之后利用该过滤模型对噪声语料进行过滤,将高质量的平行语料和干净的平行语料进行合并;最后利用合并后的语料训练一个新版本的过滤模型,并迭代3 次来提高过滤模型的过滤性能。
字节跳动[16]团队利用大规模的单语语料和官方提供的干净平行语料上训练了一个高性能的XLM,并在XLM 上添加一个线性或卷积层来预测每个句对是否平行,最终用4 个参数不同或最后一层不同的XLM 对每个句对进行评分,以它们的平均得分作为最终的质量评分。
评估句对的平行度不仅可以利用余弦相似度,而且可以利用翻译模型的交叉熵损失值。Marcin[1]利用对偶条件交叉熵损失结合语言模型作为过滤条件。其中对偶条件交叉熵损失由两个相反翻译方向的翻译模型计算两个交叉熵损失值的差异得到,用于过滤掉对齐错误的句对;而语言模型分别为一个领域内和领域外的语言模型来计算其领域的相似性得到,用于过滤掉与领域不相关的句对。
1.3 PMI
PMI 是一种在训练语料上构建一个共现矩阵,来对训练语料重新加权的方法。计算方法为:
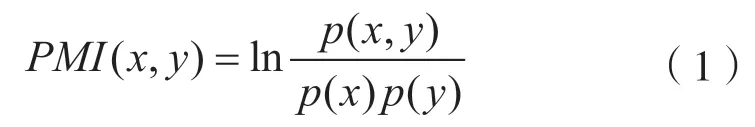
式中:x和y分别为源语言的词和目标语言的词;p(x)和p(y)分别为x和y在语料中出现的概率;p(x,y)为x和y两个词共同出现的概率。
在实践中发现,将词对中的负相关置0,PMI的表现会更好。而NPMI 也是一种在训练语料上构建一个共现矩阵,来对训练语料重新加权的方法。该方法对PMI 进行了规范化,从而缓解了PMI 对低频词对的偏向。计算方法为:
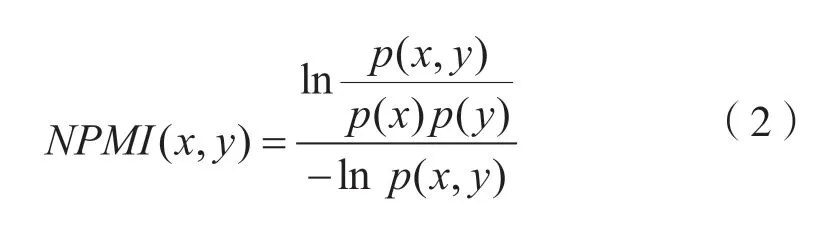
2 方 法
OpenSubtitles 中的汉泰平行语料质量较差,且没有同领域高质量的平行语料作为锚点提供对齐信息。因此本文选择直接在汉泰噪声语料上抽取对齐信息,通过NPMI 来计算每个词对的共现概率,并利用高共现概率的词对来过滤噪声语料。
机器翻译领域存在大量一对一的词对,但也存在多对一、一对多甚至多对多的短语对。为了能够获取噪声语料中存在的短语对信息。本文采用快速对齐(fast align)[17]来得到源句子与目标句子中词的对齐信息,以此来构建出源与目标的短语对表,并过滤掉其中低频率的短语对。通过该方法得到的短语表,可以用于简单的过滤。
本文将源语言和目标语言分别用X和Y进行表示,并利用Px和Py代表分别从X和Y中抽取得到的短语。f(X,Y)是根据fast align 从X和Y中获得的词对齐信息,构建出的短语对函数。因此,本文的NPMI 不计算噪声语料中所有可能存在的词对或短语对,只计算短语表中存在的词对或短语对,这样可以减少可靠性低的对齐信息数量,进而提高从噪声语料中提取对齐信息的可靠性。
利用统计机器翻译的fast align 技术,本文可以得到所有可能的短语表(其中包括词对),若将句子中的短语看作为一个词,平行语料中依然以一对一词对为主,因此本文采用与Tu 等人[18]一样的翻译覆盖率来进一步保证两个句子的平行度。本文以整个源句子在目标句子中是否存在相对应的翻译为基础,若源句子中的某个词在目标句子中没有与之相对应的词,则降低源句子的翻译覆盖率。同样判断目标句中的每个词是否可以在源句子中找到相对应的词,如果没有与之对应的词,则降低目标句子的翻译覆盖率。之所以对源句子和目标句子都做翻译覆盖率的调整,原因有二:一是翻译是双向的,需要在汉泰和泰汉两个翻译方向上都训练;二是防止源或目标句子的每个词都指向目标或源中的同一个词,从而避免存在错误的翻译覆盖率。
为了计算噪声语料中对齐信息的可靠性,本文采用NPMI 方法。该方法是对PMI 进行了归一化,防止低频短语对的可靠性太高。同时根据正点向互信息(Positive Pointwise Mutual Information,PPMI)[19](只保留PMI 中大于0的值)的效果好于PMI的效果,本文只使用了NPMI 中大于0的部分。
本文使用了由NPMI 得到的对齐信息和翻译覆盖率(normalized pointwise Mutual Information and Translation Coverage,MITC)来评估源句子与目标句子的平行度,计算方法为:
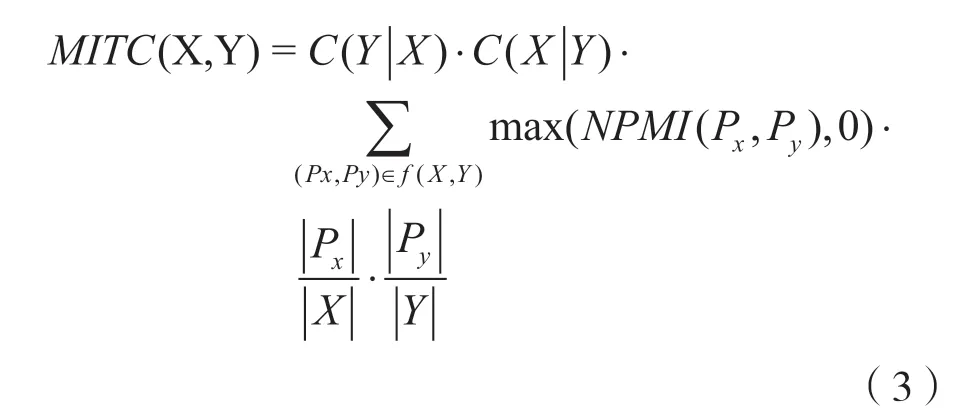
式中:|·|为短语或句子包含的token 个数,用该方法来防止长句子对拥有太高的分数和短句子对拥有太低的分数,尽管短句子对的质量可能高于长句子对的质量;C(Y|X)为X中的所有可以在Y中找到对应翻译的词在整个X中的占比,即X的翻译覆盖率;C(X|Y)为Y的翻译覆盖率。
这里计算源句子和目标句子平行度的依据是:
(1)如果对齐信息(Px,Py)有很高的可靠性,则包含(Px,Py)的句对(X,Y)同样有很高的对齐可靠性,即句对的平行度很高;
(2)如果短语Px或者Py在X或Y整个句子中的占比非常大,则对齐信息(Px,Py)与句对(X,Y)是强关联;
(3)若C(Y|X)和C(X|Y)代表了(X,Y)整体平行度,则翻译覆盖率越高,(X,Y)的整体平行度就越高。
3 实 验
本文在汉泰翻译上采用OpenSubtitles 中的汉泰语料作为训练集,总共有117 万句对,验证集和测试集均为2 000 句对。在柬埔寨语—英语翻译方向上采用WMT2020的平行语料过滤任务的噪声语料过滤后的语料作为训练集,验证集与测试集由WMT2020 官方给出,验证集有2 378 句对,测试集有2 309 句对。
翻译模型采用transformer[20],批次大小为64,嵌入层维度为512,隐藏层维度为512,编码器和解码器的层数均设置为6,注意力头个数设置为8,学习率为0.000 5,丢弃率(dropout)为0.1,解码采用集束搜索,集束宽度设置为4,优化器设置为Adam,最大Epoch 设置为100。训练结束的标志为连续10 个epoch 模型在验证集上的损失值没有超过当前最优损失值就停止训练。词汇表大小设置为50 000,泰语用pythainlp[21]进行分词,汉语利用jieba 进行分词。采用不区分大小写的BLEU-4 来测量BLEU 值。模型利用tensorflow 2.2 进行实现,所有实验均在Nvidia GPU(GTX titan X)上运行。
柬埔寨语—英语实验采用的模型由官方提供。源语言与目标语言共享词嵌入,编码器层与解码器层均为5 层,嵌入层维度为512,隐藏层维度为2 048,注意力头个数均为2,dropout 为0.4,学习率设置为0.001,优化器设置为Adam,最大epoch 设置为100。过滤过程中,柬埔寨语采用KhmerNLP[22]进行分词。
3.1 汉泰OpenSubtitles 实验
3.1.1 预过滤和基线
针对汉泰的OpenSubtitles 语料,为了尽可能提高翻译模型的性能,本文先从句子长度和句子比例进行分析,找到最佳的句子长度和句子长度比例。在以下实验中,本文先对原始的117 万语料按长度比例进行过滤,然后随机抽取20 万作为训练集,此过程重复3 次取它们的平均值。实验结果如表1所示。

表1 句子长度比例对BLEU 值的影响
在不限制句子长度的情况下,本文只利用句对的句子长度比例对语料进行过滤,句子长度比例为1.5 则代表句子长度比例在1.5 以上的句对都将被过滤掉。实验结果证明,句子长度比例为2的时候,最适合该汉泰语料,可以将翻译模型的性能最大化。
本文在句子比例为2的条件下,为了找到能将翻译模型性能最大化的语料,针对句子最大长度进行实验。实验结果如表2 所示。

表2 句子最大长度对BLEU 值的影响
从句子长度来看,最大长度为10的语料可以将翻译模型的性能最大化,这可能是因为OpenSubtitles 上汉泰语料的平均长度在9 个token 左右(泰语语料的每句话的平均长度为9.5 个token,汉语语料的每句话的平均长度为8.1 个token),但该句子长度过短,因此本文选择对翻译模型的性能提升次佳的句子最大长度为30的语料。
句子比例为2 且句子最大长度为10的语料(包含20 万句对)的BLEU 值与用完整原始语料(包含117 万句对)的BLEU 近似,这说明基于规则的语料过滤方法的有效性,也证明了OpenSubtitles的汉泰语料的确存在着大量的噪声。
最后利用常规的langid 工具包过滤掉其中泰语端句子并不属于泰语或者汉语端句子并不属于汉语的句对。基线实验结果如表3 所示。

表3 基线的BLEU 值
基线(20 万)是在原始语料中随机抽取20 万平行语料上训练的模型,而基线(117 万)是在完整的原始语料上训练的模型。在经过句子比例为2、句子长度为30 以及langid 过滤后的语料(本文称之为预过滤语料)上训练的模型与在基线(20 万)上训练的模型相比,在泰汉上高了3.029 个BLEU值,在汉泰上高了2.898 个BLEU 值。而预过滤(20 万)与基线(117 万)相比,在泰汉上高了0.168 个BLEU 值,在汉泰上低了0.663 个BLEU 值,预过滤(20 万)的性能与基线(117 万)的性能相当。实验证明,利用预过滤方法可以有效地提高语料的质量。
3.1.2 基于NPMI的过滤方法
本文先利用fast align 得到短语对表,针对这个短语对表对整个汉泰语料进行了NPMI。从而得到短语对表中每一个短语对的共现概率,并且过滤掉了共现概率低于0.2的短语对。实验结果如表4所示。

表4 不同条件下NPMI 过滤效果的对比
在该实验中,表中“短语对N”代表在短语对数量大于等于N的语料上训练的模型,MITC 代表着在NPMI 和翻译覆盖率过滤后的语料上进行训练的模型。本文不做短语对数量为4 及以上的实验的原因是过滤后的平行语料数量不到12 万,而其他方法的数量均在20 万以上,且随机抽取20 万语料进行实验。实验证明,在共现短语对数量上,共现短语对3的效果优于共现短语对2的效果,因此拥有更多共现短语对的句子对具备更高的相互翻译程度。但单纯地利用共现短语对个数进行判定的方法,也会导致在长句子上具有更大的优势,因此采用翻译覆盖率来降低语料中长句子的优势。实验表明,利用共现短语对在句对中的翻译覆盖率来进行过滤是更佳的选择,比起在共现短语对数量为3 个以上语料上训练的模型,在搭配翻译覆盖率语料(MITC)上训练的模型,在泰汉上提高了1.61 个BLEU,在汉泰上提高了2.42 个BLEU。将在MITC 上训练的模型与在预过滤语料上训练的模型相比,在泰汉上提高了5.884 个BLEU 值,在汉泰上提高了10 个BLEU 值。
3.1.3 NPMI 对生成式伪平行语料的过滤效果
本文除了在抽取式方法得到的平行语料上进行实验,也在生成式方法得到的平行语料上进行实验。
本文利用在基线(117 万)语料上训练的模型和在MITC 过滤后的语料上训练的模型来生成伪平行语料。以此来探索NPMI 在对伪平行语料过滤的有效性。
将在117 万和MITC 语料上训练的两个翻译模型生成的伪平行语料(数量均为117 万),与MITC的训练语料进行混合。这是为了比较两个翻译模型生成的伪平行语料质量,同时保证存在高质量的平行语料,防止NPMI 被回译生成的伪平行语料干扰,影响过滤效果。之后利用混合后的语料,分别在不进行NPMI 过滤和进行NPMI 过滤的情况下,重新训练翻译模型。实验结果如表5 所示。

表5 NPMI 对生成式伪平行语料的过滤效果
表5 中,基线(117 万)代表在原始语料上训练的模型;MITC 代表在经过NPMI 和翻译覆盖率过滤后的语料上训练的模型;117 万(未过滤)代表在基线(117 万)生成的伪平行语料和经过NPMI和翻译覆盖率过滤后的语料上训练的模型;117 万(过滤)代表在117 万(未过滤)所用语料的基础上,进行了NPMI 和翻译覆盖率过滤后的语料上训练的模型;MITC(未过滤)代表在MITC 生成的伪平行语料和经过NPMI 和翻译覆盖率过滤后的语料上训练的模型;MITC(过滤)代表在MITC(未过滤)所用语料的基础上,进行了NPMI 和翻译覆盖率过滤后的语料上训练的模型。
从117 万(未过滤)模型和MITC(未过滤)模型的性能上可以看出,利用回译生成伪平行语料的质量依赖于翻译模型的性能。在性能上,基线(117万)模型性能比MITC 模型在泰汉上低了6.052 个BLEU 值,而在汉泰上低了9.356 个BLEU 值。这个差异在各自生成的伪平行语料的质量上得到了体现。117 万(未过滤)模型与MITC(未过滤)模型相比,在泰汉上低了4.12 个BLEU 值,而汉泰上则低了6.83 个BLEU 值。
在分别对两个语料做NPMI 过滤后,双方的混合语料规模均出现了下降,117 万(过滤)模型训练集数量在泰汉和汉泰两个方向均为57 万左右,而MITC(过滤)模型训练集数量在泰汉上有79 万左右,但是汉泰上不到76 万。经过过滤后存在的数量差异也表明了双方生成的伪平行语料在质量上存在差异。此外,117 万(过滤)模型与117 万(未过滤)模型相比,在泰汉和汉泰两个翻译方向上分别提高了1.44 和1.42 个BLEU 值;MITC(过滤)模型与MITC(未过滤)模型相比,在泰汉和汉泰两个翻译方向上分别提高了1.42和1.11个BLEU值。这证明了NPMI 过滤方法确实可以过滤掉生成式伪平行语料中的低质量句对。
同时,本文为进一步探索NPMI 在生成式伪平行语料上过滤的效果。采用MITC(过滤)语料训练的翻译模型来再次生成伪平行语料,生成的语料会与最初训练的语料进行混合。实验结果如表6 所示。

表6 NPMI 对第二次生成的伪平行语料的过滤效果
在该实验中,表中“短语对N”代表在短语对数量大于等于N的语料上训练的模型,MITC 代表在MITC 过滤后的语料进行训练的模型。本文使用所有符合筛选条件的语料作为训练集,泰汉实验中,短语对数量为3 以上的语料有87 万,短语对数量为4 以上的语料有66 万,短语对数量为5 以上的语料有49 万;在汉泰实验中,短语对数量为3 以上的语料有86 万,短语对数量为4 以上的语料有65 万,短语对数量为5 以上的语料有47 万;经过MITC 过滤的语料在泰汉和汉泰上均为99 万。在泰汉上,短语对3 和短语对4 模型的性能高于在未过滤语料上训练出来的模型性能,这表明在泰汉上NPMI 具备过滤第二次生成的伪平行语料的能力,但在汉泰上,没有在任何过滤后语料上训练的模型性能高于在未过滤语料上训练的模型性能。本文猜想,NPMI 在泰汉上有过滤效果,但在汉泰上没有过滤效果,是由于泰汉翻译模型(表5 中的MITC泰汉模型)生成的伪平行语料中依然存在对模型性能只造成负面影响的噪声,但汉泰翻译模型(表5中的MITC 汉泰模型)生成的伪平行语料中的极大部分语料已经不是简单的噪声语料,都是对模型的性能有正面影响也有负面影响的句对。而NPMI 直接对平行语料进行过滤,会直接将这样的语料过滤掉导致模型缺乏部分必要的语义信息,致使模型性能降低。在该实验的汉泰中也体现了这一情况,语料规模的下降会导致模型性能的下降,性能最高的MITC 模型也是汉泰语料最多的模型,训练语料高达99 万。
3.2 柬埔寨语—英语WMT20 实验
为了证明本文方法的有效性,本文在WMT2020的柬埔寨语—英语的平行语料过滤任务中也做了实验。
在WMT2020的平行语料过滤任务中,官方提供了带有噪声的柬埔寨语—英语的平行语料。参与者只需要提供过滤后的平行语料,其余的由官方提供,包括参数一致的翻译模型,共同的验证集和测试集。
柬埔寨语—英语同样是低资源语言对,现有的干净平行语料稀少,过滤过程中无法采用干净的平行语料作为锚点对噪声语料进行过滤。虽然官方提供了少量的干净平行语料,但本文为了实验的一致性并没有使用该平行语料,依然采用NPMI 直接从噪声语料提取对齐信息,之后利用可靠性高的对齐信息进行过滤。
对比实验使用的数据都是英语token 数量为2百万的语料。实验结果如表7 所示。

表7 柬英上不同过滤方法的对比
实验表明,NPMI的过滤在验证集和测试集上均比LASER 低了0.2 个BLEU 值,但将NPMI 和LASER 进行联合过滤之后,在验证集上比LASER 高了0.8个BLEU值,而在测试集上高了0.4个BLEU值。
4 结语
针对非人工方式得到的平行语料的规模足够但质量不佳的问题,提出了基于NPMI的平行语料过滤方法。该方法在不使用任何单语语料和干净平行语料而只使用噪声语料的情况下,可以直接抽取出噪声语料中可靠性高的对齐信息,并利用该对齐信息对噪声语料进行过滤。在抽取式的平行语料上,过滤效果良好,在只生成一次的伪平行语料上,NPMI 也可以提高伪平行语料的质量,但在二次生成的伪平行语料上,过滤效果不佳。如何改进NPMI 在多次生成的伪平行语料的过滤效果是笔者未来的研究方向。
