一种抵抗链接作弊的PageRank改进算法
2012-06-29贺志明王丽宏程学旗
贺志明,王丽宏,张 刚,程学旗
(1. 中国科学院计算技术研究所,北京 100190; 2. 国家计算机网络与信息安全管理中心,北京 100029)
1 引言
据《第28次中国互联网络发展状况统计报告》[1]显示,截至到2011年6月底,我国搜索引擎用户规模为3.86亿,搜索引擎使用率达到 79.6%,成为网民第一大应用。搜索引擎是人们最常用的信息查询工具,为人们提供快速准确的查询结果。如何把对用户最有价值的信息从浩瀚的信息海洋中挖掘出来,是搜索引擎面临的最大挑战。PageRank算法[2]是搜索引擎最常用和最有效的排序算法之一,也是Google公司迅速成功并一直处于搜索引擎领先地位的重要因素之一。
在经济利益的驱使下,有人专门从事搜索引擎作弊来提高作弊网站在搜索结果中的排序位置。搜索引擎作弊是指使用各种各样的手段来欺骗搜索引擎的排序算法,使得一些页面获得比本身实际应得排名更加靠前的排名[3-4]。搜索引擎作弊的方法有很多种[5],总体上可以分为基于内容的作弊、基于链接作弊和基于其他技术的作弊三大类。基于链接的作弊日益严重,作弊形式越来越多样化,这对传统PageRank算法产生了非常大的影响。
本文重点介绍了多种链接作弊方法对传统PageRank算法的影响,对传统PageRank算法进行了若干改进,提出了一种能够抵抗链接作弊的三阶段PageRank算法(TSPageRank算法)。通过实验比较TSPageRank算法和传统PageRank算法的计算结果,证明TSPageRank算法比传统的PageRank算法在效果上提高了59.4%,能够有效地提升重要网页的PageRank值,降低作弊网页的PageRank值。
2 相关研究
2.1 PageRank算法介绍
PageRank算法把网页及其超链接结构看作有向图,把用户浏览行为看成一个Markov随机冲浪模型,并定义每个网页被访问的概率为PageRank值,此PageRank值代表了网页的重要度。Page-Rank 算法是衡量一个网页重要性的指标。Page-Rank 算法是基于“从许多优质的网页链接过来的网页,必定还是优质网页”的回归关系,来确定网页的重要度。当某个网页链接到另一个网页时,它就对该网页“投了一票”,一个网页的得票越多,则它的重要性也就越高。
假设互联网上一共有N个网页,分别为P1,P2,…,PN,d是阻尼因子,通常d=0.85,M(Pj)表示Pj的父网页的集合(即这些网页都指向Pj),L(Pi)表示网页Pi的出度(out-degree)。网页Pj的PageRank值PR(Pj)的计算方法如式(1)所示:
根据式(1),通过多次迭代计算,可以得到每个网页的PageRank值。
2.2 搜索引擎链接作弊
基于链接的搜索引擎作弊的人故意制作大量的链接指向作弊网页来欺骗搜索引擎,打破了搜索结果的公平性和公正性,是各大搜索引擎公司所极力反对的。反搜索引擎作弊[6-9]是近些年来各大搜索引擎公司最重视的领域,也是学术界研究的热点问题。在这里本文主要讨论基于链接结构的搜索引擎作弊方法。基于链接的作弊主要是针对Page-Rank 和Hits[10]等主流的链接分析算法而实施的。
目前最活跃的链接作弊方法是链接农场、交换链接、黄金链以及开源的建站系统等。
链接农场[11]是指由互联网中的一部分网页组成, 这些网页非常密集地互相连接在一起。链接农
场是通过创建一个堆砌大量链接而没有实质内容的网页,这些链接彼此互链,或指向特定网站,以增加被链接网站外部链接数量,由此欺骗排名算法,为目标网站获得更高的链接入度,最终提升搜索引擎排名。
链接农场是互联网强连通效应的实例之一[11],强连通效应对网页的权重的提升有非常大的影响。
交换链接是指网站之间人为地互相增加对方网站的链接,是增加外链成本最低和使用最多的一种方法。由于交换链接可以增加网站的外链,提高网站的PageRank值,站长们钟情于做大量的交换链接。交换链接的泛滥,已经严重影响了PageRank算法的公平和公正性。
黄金链,又名众心链、财富链、淘金链等,是近年来刚兴起的一种链接作弊方法,是指一些高权重的网站出售首页的链接给作弊网站,提高作弊网站的PageRank值。
开源建站系统中的大多数网页都是由网页模板生成的,网页模板中含有固定的链接指向一些共同的网页甚至是作弊网页。例如,开源建站系统有discuz、phpwind、dedecms、php168、phpcms等,开源的博客有wordpress等,著名的电子商务网站有阿里巴巴、淘宝网、慧聪网等,这些网站都含有数百万甚至更多的外链,导致他们的PageRank值极高,从而让其他重要的网站的PageRank值与之相比相差甚远而无法获得较高的权值。
3 三阶段PageRank算法
由于受到作弊链接和站内链接的影响,传统PageRank算法计算出来的每个网页的PageRank值(PR值)失去了公正性和可信度。本文对传统PageRank算法进行了改进,降低了作弊网页的PR值。
3.1 搜索引擎链接作弊
三阶段PageRank算法,简称TSPageRank算法,将整个PageRank 的计算过程分成三个阶段完成。基本原理是,首先利用网站之间的链接求出每个网页的PR值,接着求出每个主机的权重;把主机的权重赋予该主机内的每个网页作为初始PR值,再次求出每个网页的PR值和主机的权重;最后利用站内的链接求出每一个网页的PR值。如图1所示。

图1 TSPageRank算法的流程图
3.2 TSPageRank算法详细介绍
TSPageRank算法的第一阶段是在传统Page-Rank 算法的基础上增加两个附加条件: 一、只使用网站之间的链接,不考虑网站内部的链接;二、在一个网页的入链中,对来自同一个外站的PR值由大到小排序,只取最大的PR值。使用改进后的Page-Rank 算法计算得到每个网页的PR值。
主机是指一个域名或者子域名。将网页根据它所在的主机分组,将主机内的网页的PR值由大到小排序,取出最大的前十个PR值,按照式(2)计算得出该主机的权重HostRank。
(2)
其中,HostRank是主机权重;PRTotal表示主机内最大的前十个PR值之和;PRMax1表示主机内最高的PR值;PRMax2表示主机内次高的PR值。
在计算每个主机的HostRank值时,将最高PR值与次高PR值之间的差距考虑进去。这是抵抗链接作弊的有利手段之一。一般来说,链接作弊者只对作弊网站的首页进行作弊,为网站首页引入大量的入链,造成网站首页的PR值非常高,而作弊网站内其他网页的PR值相对很小,这样作弊网站的最大PR值与次大PR值之间的差值比正常网站大很多。根据式(2),作弊网站的主机权重会被大大降低。
同时PRTotal考虑了同一个主机下的最大的前十个PR值之和,一定程度上提高了有多个高PR值网页的主机的权重,削弱了只有一个高PR值网页的主机的权重。这是符合优秀网站的特点的,优秀的网站中会有多个网页被其他网站的网页引用,相应的PRTotal的得分会比较高。反之,一般的作弊网站只有少数网页由于人为的增加外链而使个别PR值增高,但没有作弊的网页的PR值都只有非常低的PR值,相应的PRTotal的得分会被消弱。
TSPageRank算法的第二阶段,为每个网页赋予的初始PR值是它所在主机的HostRank值。重新计算网页的PR值,并根据式(2)再次计算出主机的权重HostRank值。
TSPageRank算法的第三阶段是在得到主机HostRank值的基础上计算每个网页的最终PR值。同样,为每个网页赋予的初始PR值是该网页所在主机的HostRank值,使用站内和站间所有链接进行PageRank计算,求出每个网页的PageRank值。
该阶段有一个对传统PageRank算法进行改进的地方是对PR值归一化的过程进行改进。传统的PageRank算法是对所有的网页进行归一化,将所有网页的PR值映射到0~10之间。而本文引入主机的概念,同一个主机内的网页进行单独归一化,每个网页可以得到一个0~HostRank之间的整数值。
TSPageRank算法通过将网页按主机进行分组和在主机内进行归一化两种措施来抵抗链接作弊网页,并抵制类似博客、论坛、电子商务等Web 2.0网站内网页PR值过高的现象,Web 2.0网站由于含有大量的用户产生的网页,这些网页指向一些公共页面,造成公共页面的PR值奇高,在归一化的过程中,使其他重要网站的PR值被相对压低。
4 实验比较和实验结果分析
4.1 实验语料和计算平台
本文实验选用的语料是由人民搜索提供的超过10亿规模的网页集合,该网页集合是在2010年6月到2010年12月期间通过宽度优先方式采集的中文网页。初始的种子网站是DMOZ开放式分类目录中简体中文网站。数据集合覆盖了110多万个网站,覆盖的主机数超过了1 000万个。
本文使用的计算平台是一个由100多台服务器组成的Hadoop平台,计算方法是使用基于Map/Reduce的分布式计算方法,并加入了一些提高计算速度的策略[12-15]。
本文实验中还随机挑选了7 218个网页,并查询了这7 218个网页Google的PR值,作为本文实验结果参照的对象。
4.2 实验设计
本文首先对语料集进行了传统PageRank算法计算,得到每个网页的PR值;然后利用TSPage-Rank 算法对数据集进行计算得到每个网页的PR值。分别取出PR值最大的前20个网页进行比较。
为了客观的评价TSPageRank算法与传统PageRank算法所计算出的PR值的效果,本文引入了第三方的Google PR值作为参照系进行比较。Google的搜索引擎向来以权威和准确著称,其先进的算法和优秀的反搜索引擎作弊能力使Google公司给出的网页的PR值得到搜索引擎行业内的认可。

图2 实验设计
本文随机挑选了7 218个网页,分别取出经过TSPageRank算法与传统PageRank算法计算出来的PR值结果,将两种PR值与该网页的Google PR值进行比较(图2),与Google PR值差值越小,我们认为PR值越客观,效果越好。
本文找了一些参与交换链接和链接农场作弊的网站,分别找出这些网页经过TSPageRank算法和经过传统PageRank算法计算出来的PR值,对两种PR值进行比较,分析两种PR值的变化情况。
4.3 实验结果和分析
首先,本文对经过传统PageRank算法和经过TSPageRank算法计算出来的网页PR值分别取Top10进行比较,如表1所示。
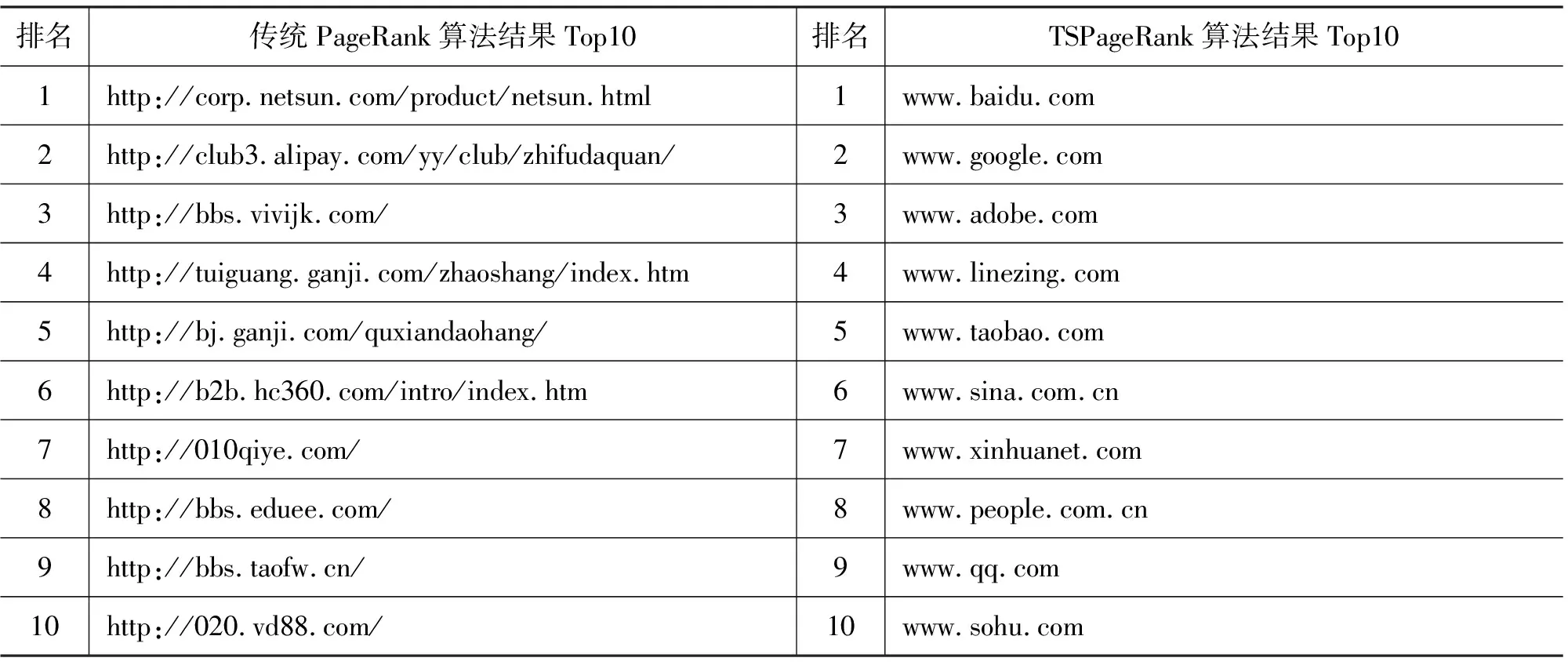
表1 经过传统PageRank算法和TSPageRank算法计算的网页PR值T10
通过观察发现,经过TSPageRank算法计算得到的结果中,PR值排名最高的网页大多是一些知名网站的首页,例如,百度、谷歌、淘宝、新浪、腾讯、网易、搜狐等网站的首页,这些知名网站是人们使用最多的网站,每天的用户访问量巨大,排名也应该最高。
其次,本文随机选取了7 218个网页,分别取出这7 218个网页经过传统PageRank算法计算得到的PR值和经过TSPageRank算法计算得到的PR值,分别与Google给出的PR值进行比较,如图3所示。
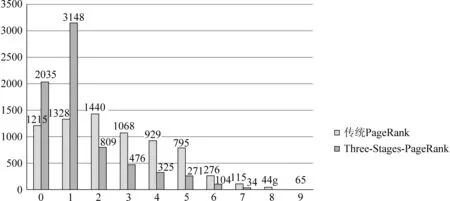
图3 传统PageRank算法和TSPageRank算法的结果比较
在图3中,横坐标表示7 218个网页分别在传统PageRank算法和 TSPageRank算法计算的PR值分别与Google PR值的差值,纵坐标表示网页个数。
从图3的实验结果可以看出TSPageRank算法比传统PageRank算法计算出来的PageRank值更加接近于真实的Google PageRank值。经过TSPageRank算法的计算,在随机抽出的7 218个网页中PR值与Google PR值相等的网页的数量是2 035个,与Google PR值相差为1的网页有3 148个;而经过传统PageRank算法的计算,与Google PR值相等的网页有1 215个,与Google PR值相差为1的网页有1 328个;TSPageRank算法分别提高了67.4%和137.0%。
经过传统PageRank算法的计算,7 218个网页的PR值与Google PR值平均差值为3.085 342 2,而经过TSPageRank算法的计算,这些网页与Google PR值的平均差值只有1.250 761 98,差距减少了59.4%,因此本文认为TSPageRank算法比传统PageRank算法在效果上提升了59.4%。
最后,本文通过人工找出了632个参与交换链接和链接农场作弊的网页,比较它们在经过传统PageRank算法计算的PR值(用PR1表示)与经过TSPageRank算法计算的PR值人工(用PR2表示),比较结果如图4所示。

图4 链接作弊网页的PR值变化
在图4中,横坐标表示作弊网页的PR值的变化值,即经过TSPageRank算法计算的结果PR2减去经过传统PageRank算法计算的结果PR1。纵坐标表示网页个数。
实验结果表明,作弊网页PR值降低的网页数为448个,占总网页数的70.8%;PR值总和变化是降低1 069,平均每个作弊网页PR值降低了 1.691 455。由此表明TSPageRank算法对链接作弊网页具有一定的抑制作用。
5 结论
本文基于真实互联网环境中的网页之间的链接关系,对传统PageRank算法进行了改进,提出了一种抵抗链接作弊的三阶段PageRank算法(TSPage-Rank算法)。在TSPageRank算法中加入每个主机的权重HostRank值的计算,HostRank值有效地抵制了作弊网页对整体网页PR值分布的影响。实验结果表明了TSPageRank算法的有效性,能够提高重要网页的PageRank值,降低和抵制不重要的网页和作弊网页的PageRank值。
[1] 第28次中国互联网络发展状况统计报告[R]. 中国互联网络信息中心,2011年7月.
[2] S. Brin, L. Page. The anatomy of a large-scale hypertextual Web search engine[J].Computer Networks and ISDN Systems, 1998, 30: 107-117.
[3] B. Wu.Finding and Fighting Search Engine Spam[D].PhD thesis, Department of Computer Science and Engineering, Lehigh University, 2007.
[4] Baoning Wu.Finding and Fighting Search Engine Spare[D].Lehigh Univ.2007.
[5] Gyöngyi Z., Garcia-Molina H.Web spam taxonomy[C]//Proceedings of First International Workshop on Adversarial Information Retrieval on the Web, 2005: 39-47.
[6] Zoltan Gyongyi, Pavel Berkhin, Hector Garcia-Molina, et al. Link Spam Detection Based on Mass Estimation[C]//Proceedings of Technical Report. 2006.
[7] Baoning Wu, Brian D. Davison. Identifying link farm spam pages[C]//Proceedings of Special Interest Tracks and Posters of the 14th International Conference on World Wide Web, Japan, Chiba, May, 2005, 10-14.
[8] B. Wu. Finding and Fighting Search Engine Spam[D].PhD thesis, Department of Computer Science and Engineering, Lehigh University, 2007.
[9] Y. Wang, Z. Qin, B. Tong, et al. Link Farm Spam Detection Based on Its Properties[C]//Proceedings of the 2008 International Conference on Calculational Intelligence and Security. 2008: 477-480.
[10] Allan Borodin, Gareth O. Roberts, Jeffrey S. Rosenthal, et al. Finding authorities and hubs from link structures on the World Wide Web[C]//Proceedings of the 10th International Conference on World Wide Web, May 01-05, 2001: 415-429.
[11] G. O. Roberts, J. S. Rosenthal. Downweighting tightly knit communities in World Wide Web rankings[J]. Advances and Applications in Statistics, Dec. 2003, 3(3):199-216.
[12] W. Gang, Y. Wei. A Power-Arnoldi Algorithm for Computing PageRank [J].Numeric Linear Algebra Applications. 2007, 14:521-546.
[13] Jeffrey Dean, Sanjay Ghemawat. MapReduce: simplified data processing on large clusters[C]//Procee-dings of the 6th Conference on Symposium on Opera-ting Systems Design & Implementation, San Francisco, CA, December 06-08, 2004: 10-10.
[14] S. D. Kamvar, T. H. Haveliwala, C. D. Manning et al. Exploiting the Block Structure of the Web for Computing PageRank [C]//Proceedings of the 12th International World Wide Web Conference. 2003.
[15] 刘松彬,都云程,施水才. 基于分解转移矩阵的Page-Rank迭代计算方法[J]. 中文信息学报, 2007, 21(5): 41-45.
