良构子串表在自然语言处理中的程序化应用: 以花园幽径句为例
2012-06-29于屏方杜家利
于屏方,杜家利
(1. 鲁东大学 文学院,山东 烟台 264025; 2. 中国社会科学院 博士后流动站,北京 100732; 3. 中国传媒大学 文学院, 北京 100024; 4. 鲁东大学 外国语学院,山东 烟台 264025)
1 引言
良构子串表(WFST,Well-Formed Substring Table)是自然语言处理(Natural Language Processing)中句法剖析的一种,可用于表示并保存歧义结构。表中每个子串在单一结构上是合格的,故称为“良构”,但由其形成的整体结构具有不确定性(完全、不完全和歧义结构均可表示),所以,常用于保存系统剖析过程中的中间结构,避免剖析浪费[1]。WFST在非确定性自然语言分析器(non-deterministic natural language parsers)中得到广泛应用。
花园幽径句(garden path sentence) 是由语言解码顺序更迭导致的一种特殊语言现象,是句子加工过程中受句法关系影响而产生的行进式错位(processing breakdown)[2]。来自心理[3-5]、语言[6-9]、认知[10-11]、计算机科学[12-14]等领域的研究证实了花园幽径句的系统解读属于由非确定性向确定性的选择性程序范畴。WFST可用于花园幽径句的程序性解读。
2 自然语言处理中的程序化特性分析
自然语言处理是计算机科学与语言学交叉研究的热点,语义理解与计算问题是当前面临的最大挑战[15]。自然语言与程序语言的不同在于歧义的存在性,程序语言的使用可以辨别自然语言中的部分歧义特征。很多方法(如依存树库、文本聚类等)[16-17]对语义理解作出了不可磨灭的贡献。此外,NS流程图和WFST可用于自然语言处理中的程序化特性分析,加深对语义的理解。
2.1 NS流程图的选择算法剖析
NS 流程图由Nassi和 Shneiderman提出,经常用于结构算法的程序性解读。这种IF-THEN-ELSE的算法陈述可形成图1的Boolean表达。三角图示正中表示条件,符合该条件则启动右侧处理框运行,否则系统进入左侧处理框。图1对系统的七种可能选择进行了流程分析。 (1) 非 A; (2) 非A 非 B; (3) 非 A 但 B; (4) A 非 C; (5) A非 C非 D; (6) A 非 C 但 D; (7) A 且 C。
NS 流程图在解读选择特点的自然语言现象(如花园幽径句)时具有直观性,基于该算法的WFST程序更易理解和分析。
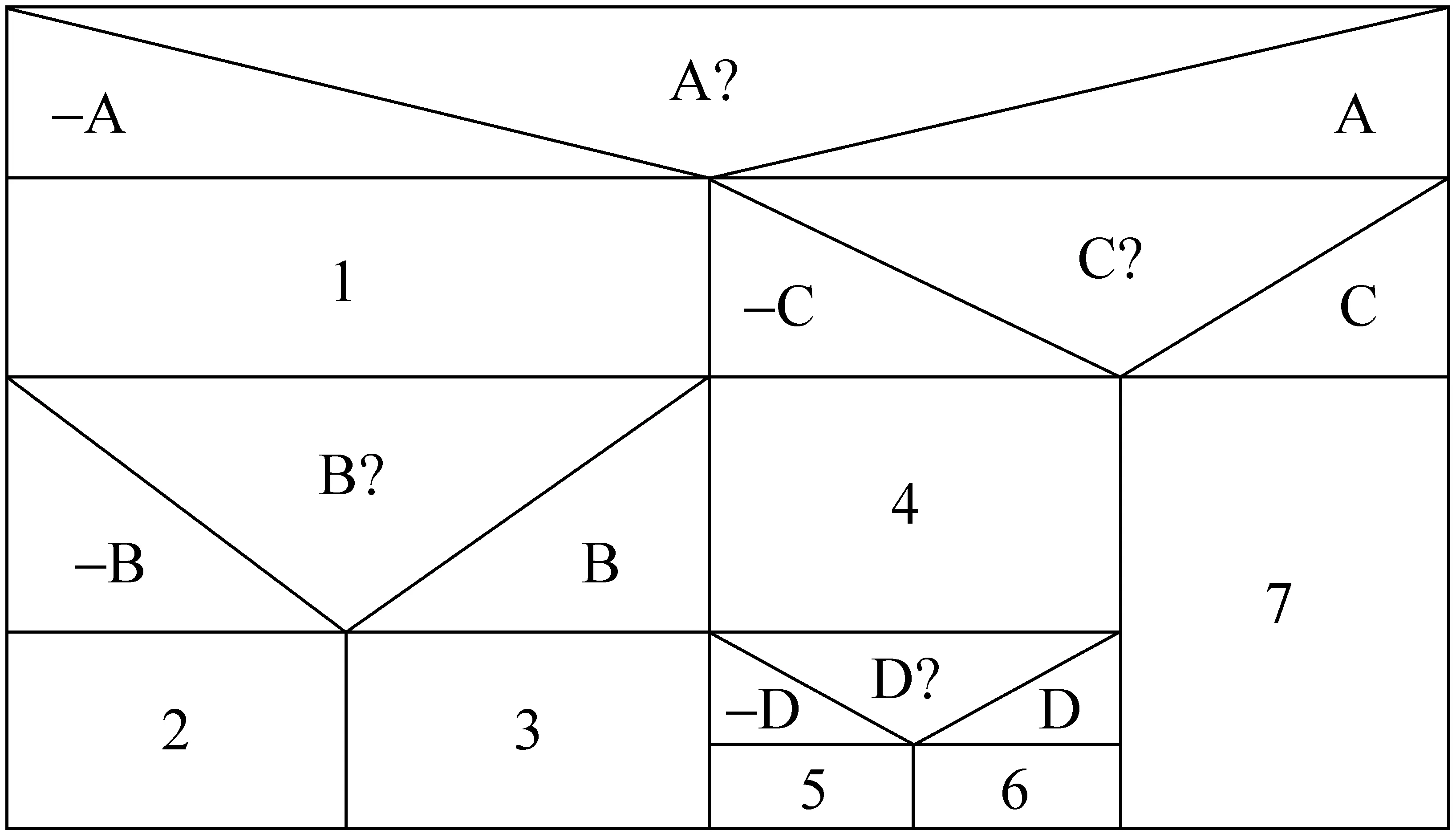
图1 基于NS结构的七项选择流程图
2.2 良构子串表的程序化构建
WFST是高效实用的分析算法,常用于对子成分进行完整的记录解析。其基本模式为: (start, finish, label→found. to find),即(始节点编号,终节点编号,规则范畴→已解读节点. 待解读节点)。
WFST模式由四类符号组成: 数字符号、规则范畴、应用符号和标记符号。
数字符号是指始节点编号和终节点编号由数字组成,代表WFST程序解读的起始和终结。该编号从0开始,编号数量由被解码句子中的子成分数量决定。设句子由n个子成分组成,那么数字符号的数量为n+1。由0至n的初始解码区间平均分配给n个子成分。设定i, j分别为始节点和终节点编号,那么{(i < j), i∈(0, n), j∈(0, n)}。请见下例:

图2 良构子串表初始符号区间
例 1 The old make the young man the boat.
在例1中,句子由8个子成分组成,程序解读中需要的数字符号就是8+1=9个,并且,起始符号是0而不是1。从0到8共有8个解码区间,平均分配后,这些子成分各自取得一个独立等长的解码区间。从0开始的箭头指向数值较大的方向,指示系统解码的初始方向。最大值一端表示终结端,如图2所示。
WFST模式中的规则范畴是指规则由上下文无关文法(CFG,Context-Free Grammar)的非终极符号表示。
在图3的程序P中,左侧部分的代码均属于非终极符号,都可以出现在WFST模式中的规则范畴位置。

图3 基于例1的CFG图
WFST模式中的应用符号包括解码过程中出现的终极和非终极符号。例如,在自底向上剖析的WFST中,图3程序P中右侧的代码都可以出现在应用符号位置,如NP, VP, Det, the, old等。
WFST模式中的标记符号包括四个: 两个用于分隔编号的逗号,指示规则方向的箭头,以及用于区分已解读和待解读节点的分隔号。具体解释如下。
在例1自底向上剖析的WFST 的起始端(0, 0, Det→.the) 中,始节点编号
在剖析的第二步(0, 1, Det→the.) 中,始节点编号
在子成分识别完成之后,系统依据图3中的CFG逐步向上剖析。(0, 2, NP → Det Adj.)表示系统从起始端0到编号2,依据规则(b)NP → Det Adj完成对NP的归约(图5)。

图4 基于例1的8个子成分识别

图5 例1 “the old”子串归约分析

图6 基于例1的NS结构性流程图
3 花园幽径句程序解读的可行性分析
花园幽径句解读涉及不同句法结构的选择,可借助NS流程图的结构性选择特点进行分析。例1的系统解码可通过图6程序算法得到直观剖析。
图6中make和man名词和动词两个词性的不同选择决定例1出现了三种不同的句法结构,即NP+VP, NP+NP+NP, NP+S3。其中NP+VP又分解成两种具有不同语义解读的S1和S2。这样形成了四种不同的解码。系统从错误到正确的选择过程可以通过WFST的自动分析展现出来。
4 花园幽径句的良构子串表程序分析
图6的四种句法结构中,右侧两列(即make作为名词出现)不形成正确的句法生成式,系统不能自底向上归约到S,所以比较容易被系统识别为错误选择。左侧两列(即make作为动词出现)都能归约到S, 但生成的语义截然不同,需要背景知识才能区别。下面讨论错误句法结构的系统剖析(NP+NP+NP,NP+S3),语义难以匹配的S1剖析以及系统正确解读的S2剖析。
NP+NP+NP模式解读。图7中,从起始端到终结端共需要27次运行。make和man都被解读为名词。由于生成的NP+NP+NP模式不能继续向上归约,系统不能形成正确、封闭的良构子串表,所以系统解码失败。该剖析过程生成的子串表如图8所示。

图7 基于例1NP+NP+NP模式的程序分析
NP+S3模式解读。在子串归约中,系统将make和man分别解码为名词和动词,根据图3中的规则(d) NP→Det Adj N和规则(a) S →NP VP,系统归约为NP+S3。
比较图8和图9可知,man词性的不同产生不同的归约子串。按照朗文公司在线免费使用的英英词典Longman Dictionary of Contemporary English中的释义(http://www.ldoceonline.com/search/?q=man),man具有三个词性: 名词、动词和感叹词。由于感叹词通常作为插入语而不作为句子成分(如Man, that was a lucky escape),不在本文讨论之列。动词man具有“给配置人员、使用、操作系统(to work at, use, or operate a system, piece of equipment etc)”等动词释义,所以,man就成为具有名词和动词两种词性释义的动名兼类词,这相应地增加了计算机对man精确释义的难度。
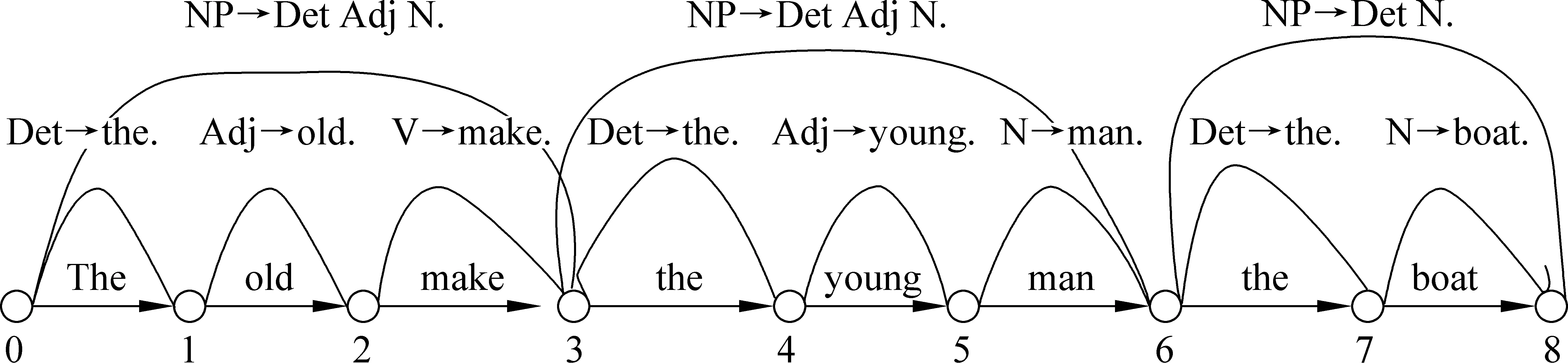
图8 “the old make(n) the young man(n) the boat”的子串归约分析
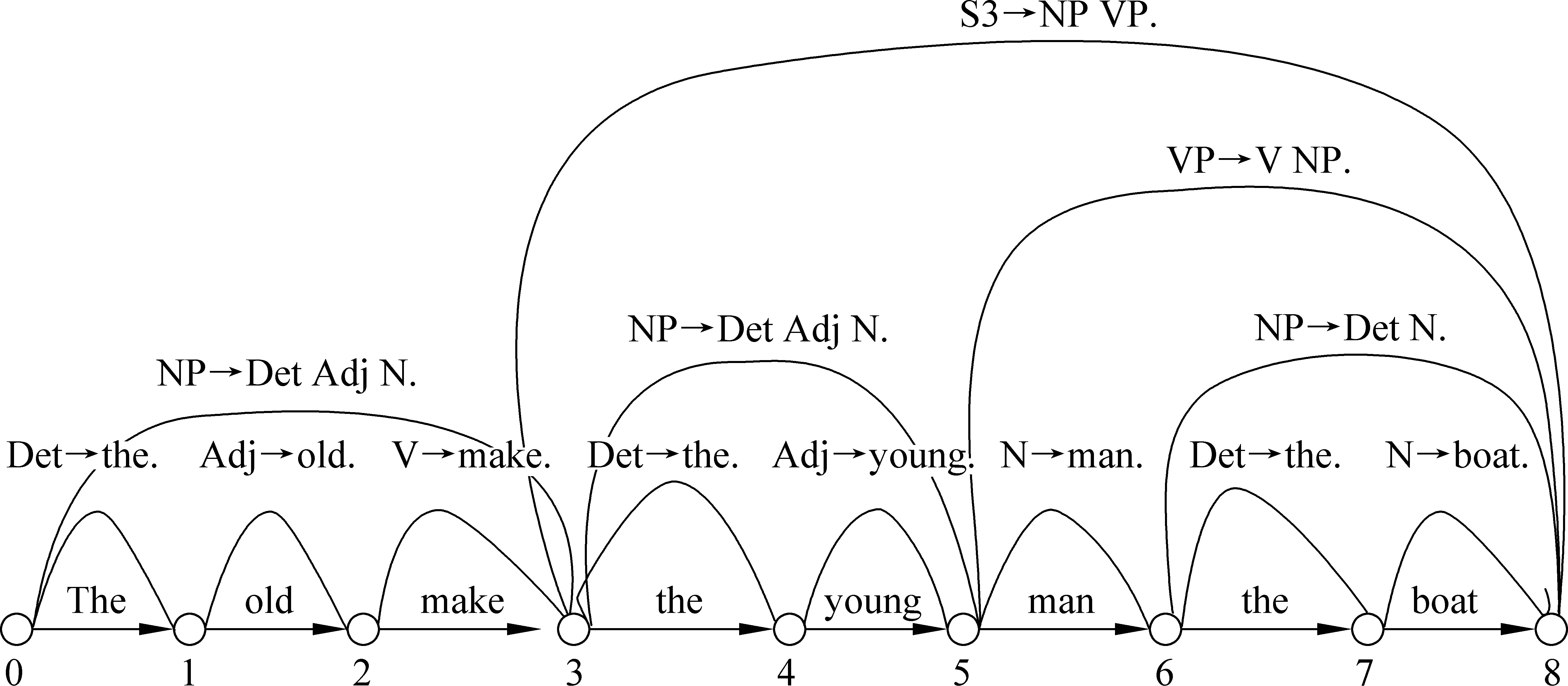
图9 “the old make(n) the young man(v) the boat”的子串归约分析
图8中the young man(n)按照图3规则(d)NP → Det Adj N归约为NP, 而图9中man(v) the boat按照规则(g)VP → V NP归约为VP, 之后又按照规则(a) S →NP VP归约为S3。
S1模式解读。在系统生成S1过程中,make首先被选择为动词。在第二次选择时,系统将man解读为名词,生成了正确、封闭的良构子串表。图2、图4和图5是系统解读的初始状态,是S1生成的前三步,man的名词选择是第四步,根据图3规则(d) NP → Det Adj N, "the young man(n)"的子串归约为NP(图10)。
第五步是“the boat”的子串归约。根据图3的规则(c) NP → Det N, 其归约为NP(图11)。
第六步是“make(v) the young man(n) the boat”的子串归约,根据图3的规则(e) VP →V NP NP, 其归约为VP(图12)。

图10 例1 “the young man(n)”的子串归约分析

图11 例1 “the boat”的子串归约分析

图12 例1“make(v) the young man(n) the boat”的子串归约分析
第七步是“the old make(v) the young man(n) the boat”的子串归约,根据图3的规则(a) S →NP VP, 其归约为S1。
图13的WFST中,make为动词,man为名词,其意义类似于The old people make the young person (be) the boat。在缺少语境支持的情况下,the young people不可能成为the boat,语义得不到匹配,所以系统剖析失败。
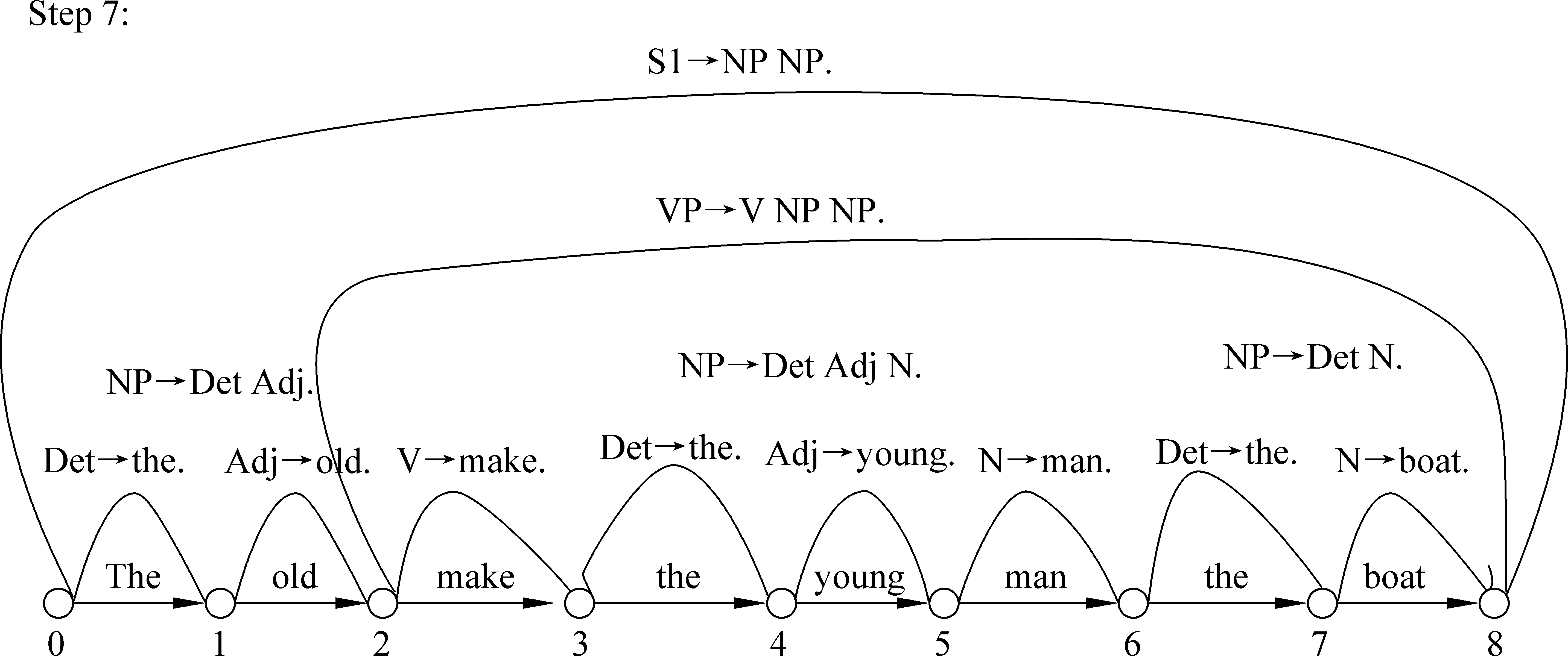
图13 “the old make(v) the young man(n) the boat”的子串归约分析

图14 “the old make(v) the young man(v) the boat”的子串归约分析
S2模式解读。这是系统最终的正确解码,其中make和man都作为动词出现。形成的子串表是封闭的良构子串表。
比较图13和图14可知,由于man的词性不同,系统的子串归约依据图3中不同的规则运行。图13中the young man(n)按照规则(d)NP → Det Adj N归约为NP, 而图14中man(v) the boat按照规则(g)VP → V NP归约为VP, 这样形成了两个不同的WFST。
系统对S2模式剖析的运行程序如图15所示。
由此可知,系统经过了36次运行,依次将make和man解读为动词,并向上逐步归约为S2, 完成了基于WFST的自动分析。
S2模式的语义匹配如图16所示。man和make在《朗文当代高级英语辞典》(LongmanDictionaryofContemporaryEnglish)中词条具有不对称性。系统通过采用逐一匹配、顺次构建的语义获取原则,优选出最适合例1良构子串表的语义分析。即例1可释义为“The old people force the young people sail the boat."
据此,系统根据句法规则排除NP+NP+NP和NP+S3模式,根据语义匹配排除S1模式, 最后S2作为系统最优选择得以输出。

图15 例1良构子串表的最优程序分析

图16 例1最优良构子串表的语义分析
5 结语
自然语言处理属于计算机科学、语言学、语义学等多学科交叉研究领域。适用于计算机科学的NS 流程图和良构子串表具有程序化分析自然语言的特性,因此可用于对自然语言中的特殊现象进行结构性解读。
花园幽径句是句法加工过程中能产生行进式错位且对前期模式破旧立新的特殊句式。通过借助具有选择算法剖析的NS 流程图和对剖析过程具有结构保存特性的良构子串表,本文以实例验证了算法和程序对句法分析的重要性,便于语言工作者从过程中分析不同句式生成的根本原因,最终从计算机科学领域推动语言学研究的发展。
[1] 冯志伟. 自然语言的计算机处理[M]. 上海外语教育出版社,1996: 255-256.
[2] Pritchett B. L. Garden path phenomena and the grammatical basis of language processing [J]. Language, 1988 (64): 539-576.
[3] 顾琦一,程秀苹. 中国英语学习者的花园幽径句理解——与工作记忆容量和语言水平的相关研究[J]. 现代外语,2010(3).
[4] Malaia E., R. B. Wilbur C. Weber-Fox. ERP evidence for telicity effects on syntactic processing in garden-path sentences[J]. Brain and Language, 2009, 108(3): 145-158.
[5] Patson N. D., et al. Lingering misinterpretations in garden-path sentences: evidence from a paraphrasing task [J]. Journal of Experimental Psychology: Learning, Memory, and Cognition, 2009, 35(1): 280-285.
[6] Choi Youngon, John C. Trueswell. Children’s inability to recover from garden paths in a verb-final language: Evidence for developing control in sentence processing [J]. Journal of Experimental Child Psychology, 2010, 106(1): 41-61.
[7] Bailey K. G. D., F. Ferreira. Disfluencies affect the parsing of garden-path sentences [J]. Journal of Memory and Language, 2003(49): 183-200.
[8] 黄国营. 现代汉语的歧义短语[J]. 语言研究,1985,(1).
[9] Dominey P. F., T. Inui, et al. Neural network processing of natural language: Towards a unified model of corticostriatal function in learning sentence comprehension and non-linguistic sequencing[J]. Brain and Language, 2009,(109): 80-92.
[10] Maxfield N. D., J. M. Lyon, et al. Disfluencies along the garden path: Brain electrophysiological evidence of disrupted sentence processing[J]. Brain and Language, 2009, 111(2): 86-100.
[11] Frazier L., et al. Scale structure: processing minimum standard and maximum standard scalar adjectives [J]. Cognition, 2008,(106): 299-324.
[12] Bateman J. A., J. Hois, et al. A linguistic ontology of space for natural language processing[J]. Artificial Intelligence, 2010(06).
[13] 冯志伟. 花园幽径句的自动分析算法[J]. 当代语言学,2003,(4):55-65,96.
[14] 杜家利, 于屏方. NLES对句层“花园幽径现象”的规避类型研究: 基于NV互动型的探讨[J]. 计算机工程与应用, 2008,(25):140-143,236.
[15] 宗成庆,曹右琦,俞士汶. 中文信息处理60年[J]. 语言文字应用, 2009, (4):55-63.
[16] 刘海涛. 汉语语义网络的统计特性[J]. 科学通报,2009,(14).
[17] 高松,冯志伟. 基于依存树库的文本聚类研究[J]. 中文信息学报,2011,25(3):59-63.
