日本地震的微博热点事件分析
2012-06-29林鸿飞
王 昊,杨 亮,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连 116024)
1 引言
北京时间2011年3月11日在日本东北部海域发生里氏9.0级地震[1]。日本地震后,该话题在新浪微博上掀起了热烈的讨论。根据爬取的新浪微博的语料统计,与日本地震相关的微博占爬取微博总数的68.6%。
微博客是在WEB2.0上兴起的一个基于用户关系的信息分享、传播以及获取平台,用户可以通过WEB、WAP以及各种客户端组建个人社区,以140字左右的文字更新信息,并实现即时分享。新浪微博是由新浪网于2009年8月推出的提供微型博客服务的类Twitter网站,是当前中国用户数最多的微博产品,在新浪公司公布的2011年第二季度财政报表中,新浪官方表示新浪微博用户数已经突破了两亿[2]。
微博具有便捷性、背对脸和原创性三大特点。人们可以使用微博随时随地便捷地发表自己的观点和感受,也可以对某一话题展开讨论。同时,微博的语言由只言片语组成,使用者不需要具有很强的语言编排组织能力,而140个字也限制了人们表达的完整性,所以微博的表达往往是碎片式的,它的表达更加随意和自由,并不遵从传统的语法结构。
目前,已有很多国内外学者针对微博客展开了研究,Akshay Java[3]等人通过对微博拓扑属性和地理属性的研究,介绍了他们对微博领域的观察和理解;Takeshi Sakaki[4]等人提出了在微博上实时检测地震的方法;Bharath Sriram[5]等人研究了在微博这种短文本上高效的分类方法;沈阳在微博上进行了情感分类的工作[6],提出了微博的热度统计公式,并通过他的研究证明了微博具有“小世界”、“异度匹配”等特点[7],同时还会根据舆论的热点发布舆情报告[8];曹鹏等人研究了在微博上重复信息的判别方法[9]。
本文根据微博上随意自由、碎片化的特点,以及受到Bing Liu[10]等人在评价语料上利用HITS抽取属性取得的良好结果的启发,提出了基于情感的HITS算法。主要针对日本地震开始后的一周内(3月11日至17日)的微博客进行事件分析,得出主题的变化。同时对整体语料进行分析,得出在一周内微博客的主题词并计算在这些主题词下网友表现的情感,从而总结网友对日本地震的态度。
本文的组织结构如下,第二节描述涉及的关键技术,包括情感词汇本体,基于情感的HITS算法,以及情感句分类的方法;第三节主要利用关键技术,对日本地震后一周内的微博客进行分析,并且分析网民的主要情感;第四节总结工作并讨论下一步的研究方向。
2 关键技术
2.1 情感词汇本题的构建
本文使用的外部资源是大连理工大学信息检索实验室的情感词汇本体[11](以下简称情感本体),该情感本体将情感分为七大类20小类。具体划分如表1所示。情感词汇本体通过一个三元组来描述:
Lexicon = (B, R, E)
其中B表示词汇的基本信息,主要包括编号、词条、对应英文、词性、录入者和版本信息;R代表词汇之间的同义关系,即表示该词汇与哪些词汇有同义的关系;E代表词汇的情感信息,包括情感类别、情感强度、情感极性,是情感词汇描述框架中比较重要的一部分。
情感词汇本体的基本知识主要来源于现有的一些词典和语义网络。其中词典包括《现代汉语分类词典》、《汉语褒贬义词语用法词典》、《汉语形容词用法词典》、《中华成语大词典》、《汉语熟语词典》、《新世纪汉语新词词典》。语义知识网络有《知网》和WordNet。另外还加入了《汉语情感系统中情感划分的研究》中的部分词汇。
同时,我们通过规范化的操作方法,严格控制词汇情感信息的更新,对词条信息采用多重人工检查的流程保证情感词汇本体的质量。目前,该情感词汇本体收录情感词汇共17 156个,为句子级、段落级和篇章级的情感计算提供了词汇基础和分析依据。
本文主要采用七大类对微博进行情感的分类。
情感词汇本体可以为情感计算提供帮助,同时可以作为一种特征选择的方法来帮助实现热点事件发现。
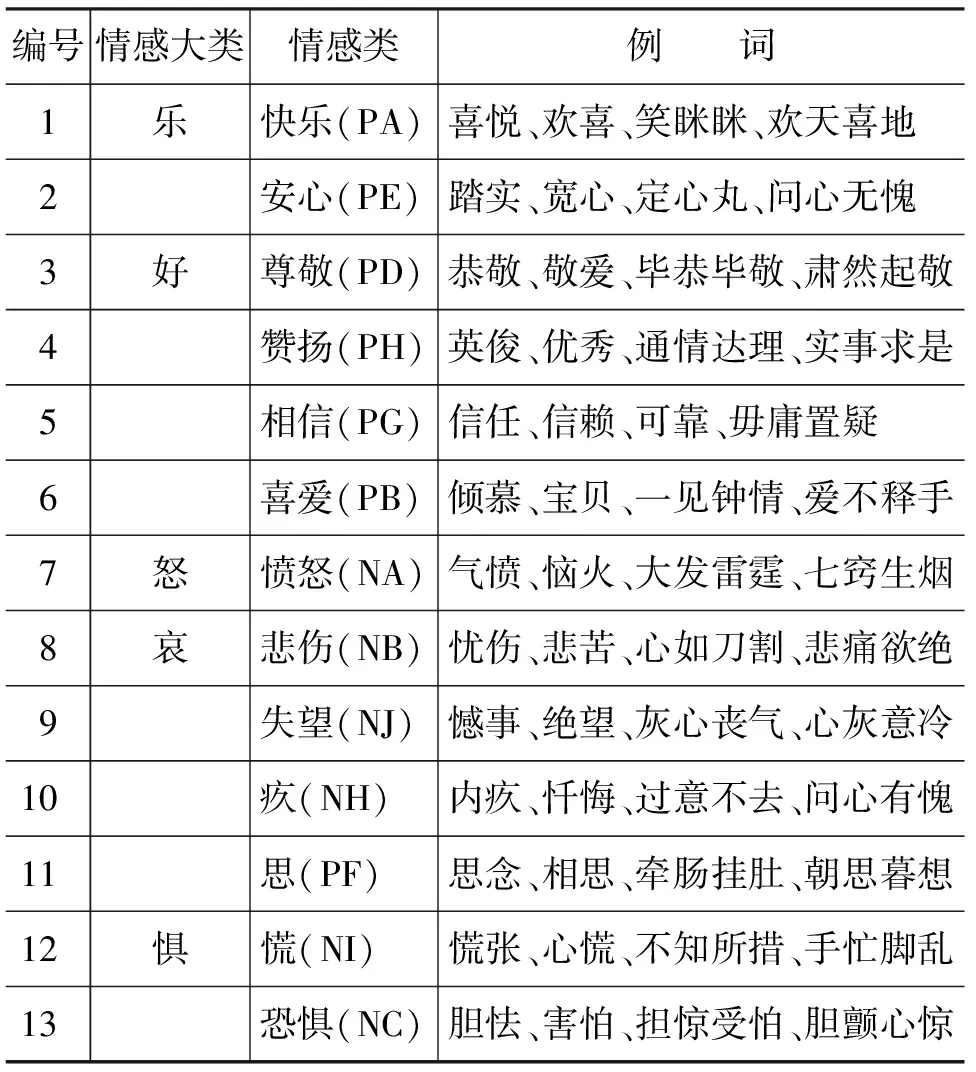
表1 情感分类
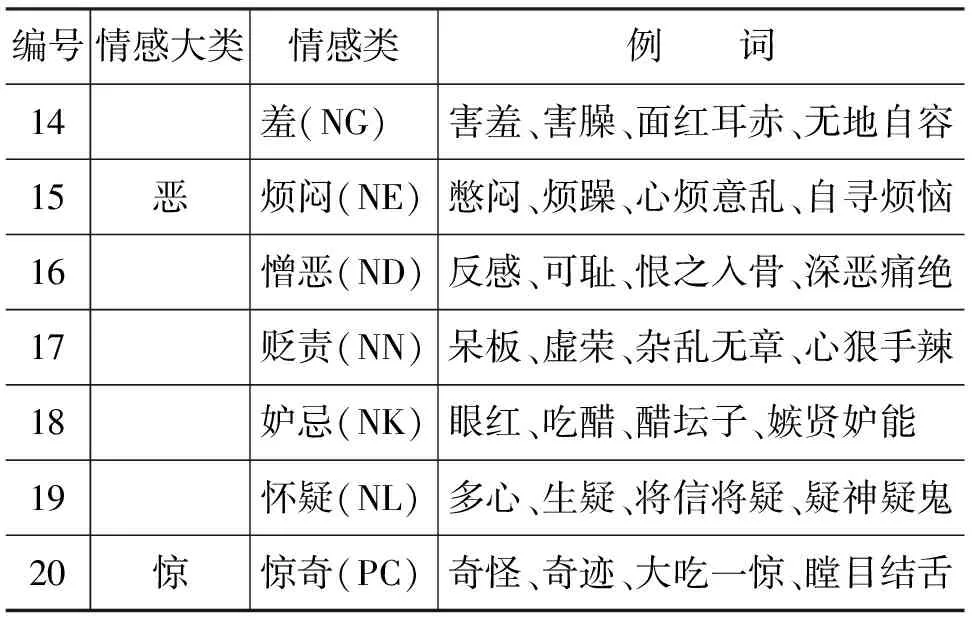
续表
2.2 基于情感的HITS算法
微博上的文本具有短小、不规则、碎片化的特点,这些特点决定了微博难以进行分句处理,难以用规则的语法进行理解。例如,“中国人就是疯狂……抢完奶粉……抢碘盐……现在广州深圳所有超市的盐都被抢购一空……香港澳门的日本奶粉也被抢购一空……!”。在这条微博中,作者的标点和表达都与传统的语法不符合。
名词通常表示了人们描述的主题,而情感词则表达了人们对于主题的态度,因此可以认为名词与情感词之间存在着联系。在上例中,作者就反复提到了“盐”、“碘盐”等名词,同时还有一系列表达情感的词如“理智”、“疯狂”等。
通过以上分析,可以将微博看作一个词袋,通过链接分析从名词中筛选主题词。Bing Liu在2009年将HITS算法应用在评价语料上对候选属性排序[10],获得了较好的效果。
2.2.1 HITS算法
HITS(Hyperlink-induced Topic Search)是一个用于网页排序的链接分析算法[12]。该算法为每一个网页都指派了一个权威度(authority score)和中心度(hub score)。在网页构成的有向图G=(V,E)中,V代表节点的集合,E代表边的集合,HITS算法的流程为:
(a) 将每一个节点i的权威度A(i)和中心度H(i)的初始值设为1。
(b) 求每个节点的中心度和权威度。
得到新的中心度和权威度后,找到在所有节点中最大的中心度和权威度,对所有的中心度和权威度进行归一化处理。
(c) 重复执行步骤(b)直到所有中心度和权威度保持不变,或者所有中心度和权威度都小于某一阈值为止。
2.2.2 基于情感的HITS算法
如前文所述名词与情感词之间存在着联系,但大量的名词会影响HITS算法的效率。本文提出基于情感的HITS算法,就是把情感词归类,达到降维的目的。算法的流程如下。
(1) 在将微博中出现的情感词用该情感词对应的20类情感分类中的类别代替,例如,高兴用“PA”代替。若名词与情感类别在同一子句中共现(这里子句指微博通过“,”“。”“;”“?”“!”切分出的句子),则在它们之间构造边。如图1所示。

图1 候选主题词与情感词构成的二部图
(2) 对已建立的边进行剪枝,频率在一定的阈值下的链接被舍弃。
(3) 对建立的二部图执行HITS算法。
通过把情感词用对应的类别代替,减少了计算的维度,剪枝也会减少噪音。基于共现建立的边会引入噪音,经过实验的验证,这种噪音并不影响最后的结果。
2.2.3 主题词评分
主题词的评分根据HITS算法对二部图进行分析得到候选主题词的HITS值,考虑到频率因素,通过式(3)得到候选主题词的最终得分。选择得分前十位,作为主题词。
其中,i为节点(候选主题词)的编号,frequency(i)为节点i的频率。
2.3 基于滑动窗口的情感句分类
在情感分析方面,本文采用了信息检索实验室(DUTIR)在COAE2009[10]的基于滑动窗口的情感句分类方法,采用了情感七大类的分类体系。情感词典通过情感本体的修正与扩充得到。
在该算法中,设置一个长度固定的滑动窗口(本文采用长度为5),从句子起始处不断地向右滑动,直到句子结束。
在滑动窗口中通过考虑否定词、程度副词、转折词,来判断句子情感,通过句子的结构修正情感类别的得分,最后,通过情感类别的得分(式(4))来确定句子的情感向量。
其中,score(emo_word)为在句子中出现的情感词的情感强度向量(本文采用的是七大类,因此该向量为七维)中,αi代表程度副词的放大倍数,k代表在窗口中出现的程度副词个数,T代表否定词修饰下情感类的情感迁移矩阵(表2)。
在score(emo_word)向量中,选取值最大的一维作为该句子的情感。

表2 否定词修饰下情感类的情感迁移表
3 实验分析
本文的实验按照以下流程组织(图2)。首先通过基于情感的HITS算法得分结合语料信息计算候选主题词的得分,将得分前十位作为每一天的主题词,然后通过特征选择,选取对每天更有代表性的主题词进一步显示热点事件发现的结果。第二步: 对于特定的主题词,对含有该词的微博进行情感倾向性分析,从而分析微博上对日本地震的态度。

图2 实验流程图
3.1 语料来源
实验语料来自新浪微博2011年3月11日至3月17日的内容,微博在新浪的微博广场获得,爬取的频率为每个小时爬取一次。2011年3月11日至3月17日爬取微博617 810条。
通过对百度百科的描述分析,选择了关键字“日本、仙台、东京、福岛、地震、海啸、岩手县、宫城县、千叶县、核电站、核辐射、核、盐、实验”等进行布尔搜索。经过统计,含有关键字的微博数量为423 861条。因此可以估算含有日本地震相关信息的微博占微博客总数的68.6%。由此可见,日本地震在实验语料上的关注度很高。
3.2 对比试验结果及分析
Latent Dirichlet Allocation(LDA)模型是Blei等在2003年提出的[9],属于主题模型(Topic Models,是当前文本表示研究的主要范式)的一种。作为一种产生式模型,LDA模型已经在文本聚类、信息检索等诸多文本相关的领域取得了很好的效果。在石晶等人的工作中,平均准确率达到了87.6%[13]。由于没有第三方的数据验证聚类效果,本文以LDA的聚类结果作为评价的标准。
本文对2011年3月11日至3月17日的语料,以LDA聚类结果为答案。分别用基于情感的HITS算法和基于词频的算法进行对比。得到每日的主题词准确率,及平均准确率。准确率计算公式为:
其中,Wc为算法得到的正确的主题词数量。Wsum标准答案中主题词的总数。
LDA的主题词的获得采用石晶等人的方法[13],LDA的聚类个数设置为80,采取每个主题前五个词为主题词,把词所对应的所有主题下的概率相加,得到该词的打分。对所有的词排序,取前十个为当天的主题词,作为标准答案。采取基于词频的算法作为baseline,对外实验结果如表3所示。
结果表明在以LDA的结果为标准答案时,基于情感的HITS算法取得了较高的准确率,证明该方法比词频更有效,而且也具有发现新的主题和潜在语义的能力。
但是该方法得到的主题词与LDA的主题词相似度并不高。这是因为LDA是词袋模型,对所有的事件采取“一视同仁”的态度;而基于情感的HITS算法更注重选取争议性更高的主题词,在HITS算法中与更多种类情感共现的名词得到的HITS值往往更大。所以当事件的争议性比较弱,或者在网上只是以转发叙述为主时,该事件主题词的得分在HITS算法结果中就会偏低。这使得基于情感词的HITS算法与LDA在选取主题词时产生了差异。

表3 2011年3月11日至17日对比实验结果
3.3 热点事件发现
本文利用2.2.3节中提到的主题词发现的方法,对每天微博进行分析,取主题词得分前十位的候选主题词作为该天微博的主题词。表4为2011年3月11日至3月17日的主题词及得分。
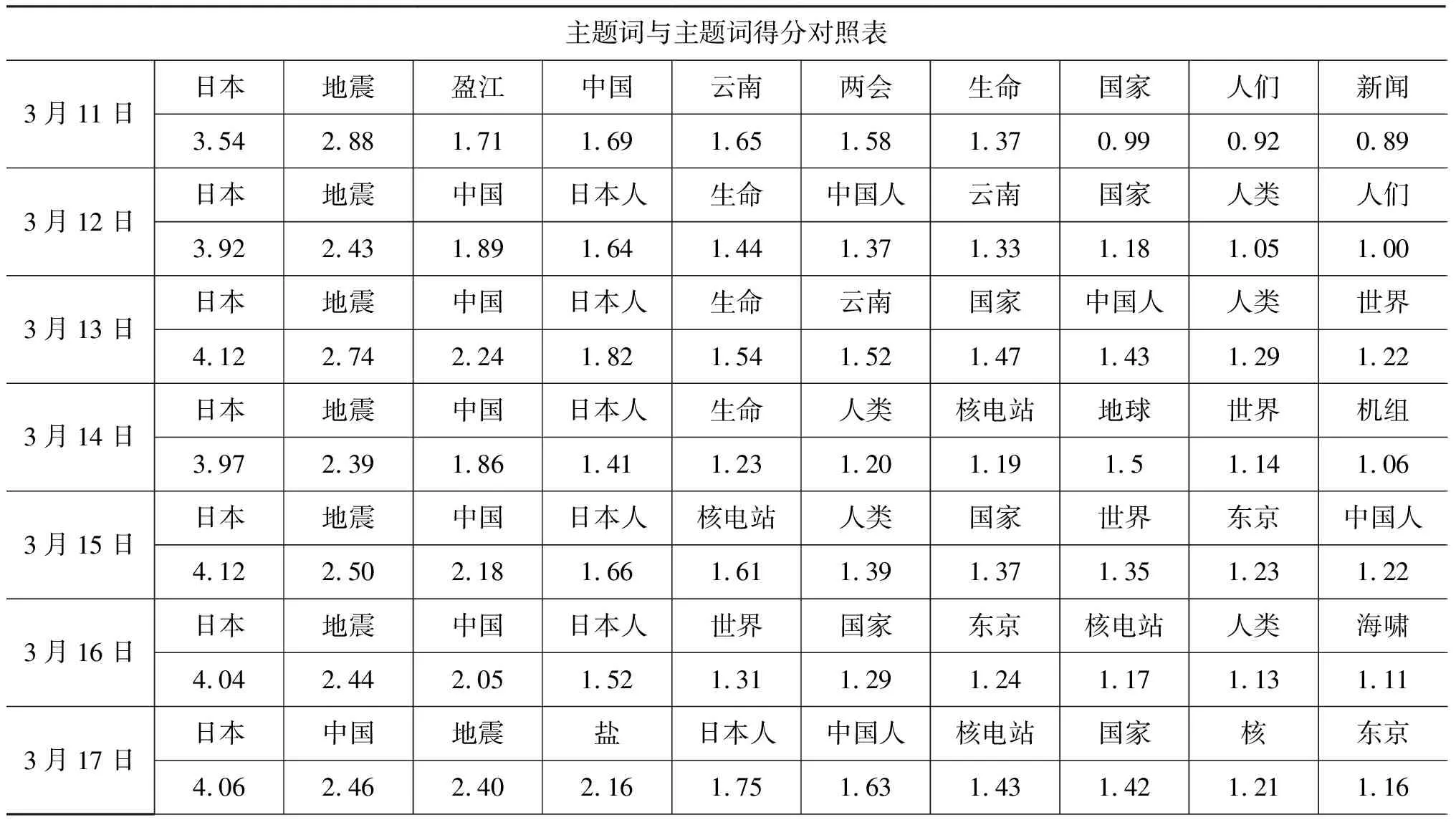
表4 2011年3月11日至17日主题词及得分
通过分析表4数据得到,在一周的数据中主题词“日本”、“地震”得分都很高,这说明日本地震是这一周的主题。
主题词的变化反映了主题的变化。2011年3月11日之前,云南盈江地震是人们主要关注的对象,所以在3月11日,盈江仍是主题词,11日后,盈江的关注度下降,盈江不再是主题词。在3月14日,核电站成为新的主题词,它代表了人们开始讨论福岛核电站核泄漏的影响。3月15日开始,东京作为主题词开始出现是由于核辐射的影响已经波及到了东京,民众很关心东京的情况。在3月17日,盐一跃成为排名很高的主题词,这正体现了3月17日在网络上热烈讨论的抢盐风波。
对上述的主题词采用互信息的特征选择方法,得到新的一组主题词“中国人、日本人、生命、盈江、云南、核电站、东京、盐”,通过它们的得分变化趋势进一步显示主题变化。如图3所示。
分析图3可以得到,“中国人”、 “日本人”在地震刚刚开始的2011年3月11日谈论得比较少,随着新闻的传播与话题的展开,随后六天它们成为谈论的主题之一。“生命”一直被谈论的比较多,但是随着时间的流逝以及事件的发展,“生命”的关注度逐渐下降。与之相反,随着事件的发展,尤其是核泄露事件之后,对“东京”的关注不断增加。
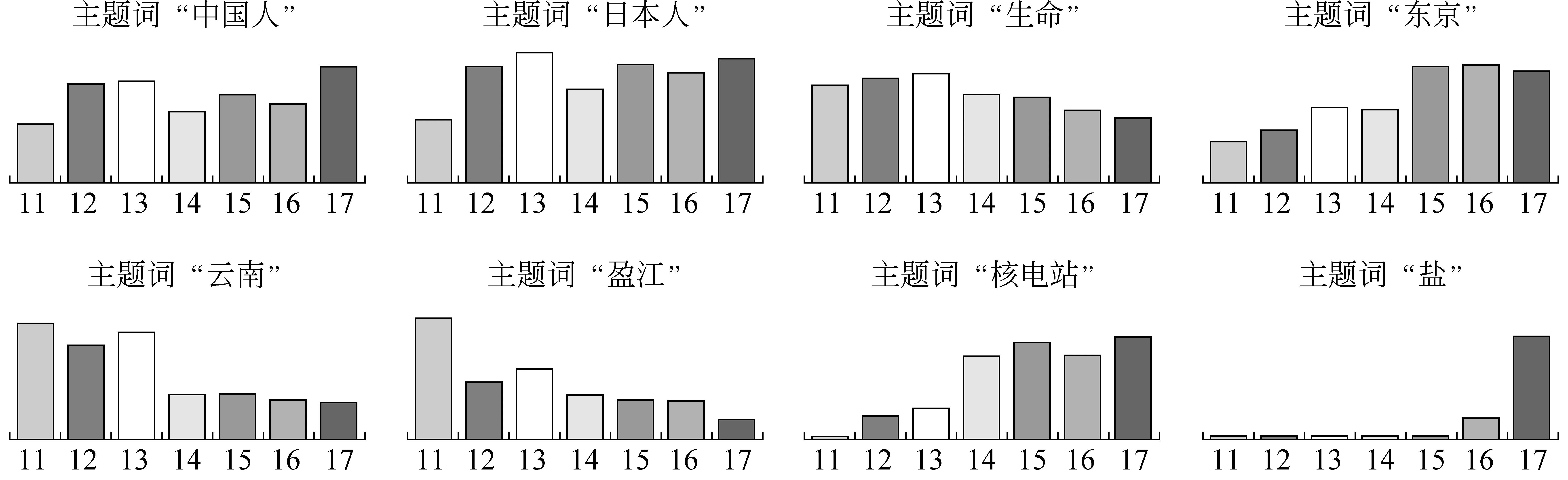
图3 主题词得分变化趋势
日本地震刚刚发生时,主题词“云南”“盈江”在日本地震时被大量地谈论着,随着时间的推移,尤其是在核电站成为主题之后,它们的得分逐渐降低。“核电站”在地震开始时几乎没有被讨论,随着新闻报道了核泄漏的事件,核电站的谈论次数在逐渐增加,并在地震的后续几天成为主题。主题词“盐”的趋势,体现了事件的突发性,在前几天谈论盐的并不多,但是忽然在16、17日激增,这刚好体现了16的谣言和17日大家出现抢盐的情况。
同时可以发现,在八组实验当中,12、13日的主题词的得分很相近,14与15日的主题词的得分很相近,除了在主题词盐这一突发事件,16、17日的主题词得分也很相近。我们可以初步得到结论,在本文的实验语料中话题一般以两天为一个单位。
3.4 情感分析结果
在得到主题词后,本文针对一些网民比较关注的热点词进行了情感分析。本文选取了四个主题词进行分析,分别是“日本人”、 “中国人”、 “地震”、 “核电站”。
对于每一个主题词,首先提取含有主题词的所有微博,对所有微博进行情感句分类;其次,采用 2.2 节中建立主题词与情感词的边的方法,发现与主题词共现次数最多的情感词。图4为对四个关键词进行情感分类的结果。
在“日本人”的主题词下,情感种类主要是“恶”和“好”, “幸灾乐祸”是高频词。“幸灾乐祸”的高频代表了一些网友对幸灾乐祸的人的不满, 属于贬责类情感,体现了主要的情感“恶”。同时,“佩服”的高频出现也从另一个角度证明了,情感“好”是微博中表现的主要情感之一。同样的,在主题词“中国人”中,“漠视”与“善良”的高频出现,对应着在情感分类中的“好”和“恶”。

图4 主题词情感信息
在主题词“核电站”中,情感“恶”出现次数最多,这说明了大家对核的恐惧以及对事态的担心之情。同时“坚守”的高频出现,与情感“好”的高比例对应,说明了大家对坚守人员的赞扬之情。
在主题词“盐”中,高频词汇为“哄抬”和“疯狂”,同时,在含有“盐”的微博中,“恶”的情感占总数的36%,36%也是在四组实验中最高的比例。充分说明了网民在微博上对抢盐和哄抬物价的表示不满。
通过高频情感词与情感分类的相互验证,本文的情感分析大体上体现了网络上的主流情感。同时,在四个主题词下,“好”和“恶”都是主要的情感,这说明在日本地震后,相比于同情与悲伤,中国的网民倾向于表现出赞扬和贬责这类体现争论的情感。
4 总结
本文提出了基于情感的HITS算法,并在实验中证明了该方法对简单的词频统计是有优势的,并且通过与LDA的相似性证明了该方法的可行性。同时利用该方法,对日本地震期间(2011年3月11日至3月17日)的微博语料进行了事件分析,并且通过情感分类进一步地阐述了事件,发现了在实验语料中话题以两天为一个单位。
在微博中存在这样一种情况,含有关键词“日本”的微博,描述的不一定是日本。同理,本文在提取主题词与情感词的时候并没有采用评价对象的抽取机制,这些会给主题词的选取引入噪音,这需要在以后的工作中研究改进。同时,情感词汇本体也需要进行进一步完善以适合微博语料。
[1] 彭晖.新浪2011第二季度财报[OL].[ 2011年8月18日]. http://tech.sina.com.cn/i/2011-08-18/05295944929.shtml.
[2] 维基百科.2011年日本太平洋近海地震[OL].[ 2012年3月12日]. http://zh.wikipedia.org/wiki/2011%E5%B9%B4%E6%97%A5%E6%9C%AC%E4%B8%9C%E5%8C%97%E5%9C%B0%E6%96%B9%E5%A4%AA%E5%B9%B3%E6%B4%8B%E8%BF%91%E6%B5%B7%E5%9C%B0%E9%9C%87.
[3] Akshay Java,Xiaodan Song,Tim Finin. Why we Twitter :Understanding Microblogging Usage and Communities[C]//Proceedings of Association for Computing Machinery’2007,San Jose, California , USA,2007:56-65.
[4] Takeshi Sakaki,Makoto Okazaki,Yutaka Matsuo. Earthquake Shakes Twitter Users: Real-time Event Detection by Social Sensors[C]//Proceedings of World Wide Web Conference’2010,Raleigh,North Carolina,USA,2010:851-860.
[5] Bharath Sriram,David Fuhry,Engin Demir,et al. Short Text Classification in Twitter to Improve Information Filtering[C]//Proceedings of Special Interest Group on Information Retrieval’10,Geneva,Switzerland,July 2010:841-842.
[6] Yang Shen,Shuchen Li,Ling Zheng,et al. Emotion mining research on micro-blog[C]//Proceedings of the 1st IEEE Symposium on Web Society,Lanzhou,China,2009: 71-75.
[7] 沈阳,田晨耕,李舒晨,等. 闲言碎语中的宏大信息流: 微博客研究[C]//第六届全国搜索引擎和网上信息挖掘学术研讨会,大连,中国,2009.
[8] 沈阳.本拉登死亡事件报道[OL].[2011年5月5日].http://www.fanpq.com./pdf/bld.pdf.
[9] 曹鹏,李静远,满彤,等. Twitter中近似重复消息的判定方法研究[C]//第六届全国信息检索学术会议,牡丹江,哈尔滨,2010:32-39.
[10] Lei Zhang,Bing Liu,Suk Hwan Lim,et al. Extracting and ranking product features in opinion documents[C]//Proceedings of International Conference on Computational Linguistics ’10,Beijing,2010: 10-31.
[11] 徐琳宏,林鸿飞,潘宇,等. 情感词汇本体的构造[J]. 情报学报,2008,27(2): 180-185.
[12] Kleinberg Jon. Authoritative sources in hyperlinked environment[J]. Journal of the Association for Computing Machinery,1999,46(5): 604-632.
[13] 石晶,李万龙. 基于 LDA 模型的主题词抽取方法[J]. 计算机工程,2010,36(19): 81-83.
[14] 许洪波,姚天昉,黄萱菁. 第二届中文倾向性分析评测[C]. 上海,2009: 107-116.
[15] D. Blei, A. Ng, M. Jordan. Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, January 2003,3: 993-1022.
