基于聚类与霍夫变换的同型雷达多目标定位算法*
2023-12-25张怡霄王怀习姚云龙
张怡霄,王怀习,姚云龙,常 超,康 凯
(1.国防科技大学 电子对抗学院,合肥 230037;2. 中国人民解放军96816部队,浙江 金华 322100;3.火箭军工程大学 作战保障学院,西安 710025)
0 引 言
随着世界形势变化,新作战理念深刻改变战场态势。美空军以“敏捷战斗部署”为纲领,巧妙利用多基地无人机与战斗机进行灵活编组,航线及行动规律均不确定。同时,雷达技术迅速升级,目标雷达采用大带宽复杂调制信号,频率范围交错,对获取战场电磁态势提出了巨大挑战。
双站测向交叉定位是一种简捷高效、定位概率高的体制。传统方法需预设目标数量,并依次完成侦收参数、分选识别、参数匹配及测向交叉定位。然而,对于机动中的同型、同频段或信号样式近似的多目标,该方法无法有效分选单个雷达信号参数,导致测向数据匹配困难,进而降低定位概率与精度[1-2]。
目前,同型雷达多目标定位研究主要集中于个体识别方向,但该方法需要大量数据样本和复杂运算。在面对数量庞大的非合作目标(如战斗机)时,由于训练样本有限,个体识别难以实现[3-5]。文献[6-7]提出了多目标位置信息场直接定位法,但该方法依赖于多个接收阵元,不适用于传统双站交叉定位条件。文献[8-9]结合网格划分和密度峰值聚类,能排除虚假定位点干扰,但仅适用于固定多雷达目标。文献[10]将霍夫变换应用于单目标航迹检测,筛选非交错直线目标航迹,但难以应用于非规则、交错的多目标航迹。在航迹筛选方面,文献[11]提出了一种基于变换域的局部最优纯方位航迹关联算法,解决同平台多方位线关联问题;文献[12]提出了一种基于模糊逻辑的航迹关联融合方法,用于解决分布式多传感器系统中的多目标跟踪问题。
本文针对双站测向交叉定位下的同型雷达多目标定位及非规则交错航迹分选问题开展研究,提出了一种基于聚类与霍夫变换联合的算法,利用侦获功率和测向参数实现定位与航迹筛选,解决多目标测向参数匹配错误和单目标航迹区分困难的问题。
1 定位模型构建
1.1 测向交叉定位基本原理
本文基于两站测向交叉定位场景开展分析。
测向交叉定位基本原理为基于两个测向站对同一目标的测得到达方向,依据三角公式计算得到目标坐标位置。
如图1所示,设测向站坐标位置分别为P1(x1,y1)与P2(x2,y2),测得的目标示向角分别为θ1和θ2,则示向线的交点T为目标位置T(xt,yt)。

图1 测向交叉定位示意
在平面条件下有
(1)
对方程组(1)进行求解计算,可得到目标位置坐标T(xt,yt)。
两站平均测向误差一致时,目标在两接收站坐标中垂线方向定位误差最小;偏离中垂线角度增大,定位误差迅速增加,两站连线方向为定位盲区[13]。具体推导过程非本文重点,因此不再赘述。
1.2 侦收条件设定
假设有两个具备测向能力的接收站对同侧目标进行侦收。3架搭载同型雷达的战斗机组成编队进入侦察当面后,分别沿不同的曲线轨迹飞行。目标战斗机与接收站的距离R均大于100 km(战斗机高度h≪R,可不考虑目标高度影响)。为便于计算,基于二维平面进行仿真,不考虑地球曲率影响。
设定仿真条件:以两个接收站的中点为原点建立xy直角坐标系,两个接收站间隔20 km,坐标分别为(0,-10 m),(0,10 m)。
基于测向交叉定位特性,为避免测向交叉定位的固有误差分布特性对后续的性能分析造成干扰,设定目标运动轨迹接近于两站中垂线方向。
设定3架战斗机的轨迹为3条相交的抛物线,在时间t∈(0,90 s)内,3个目标的轨迹分别满足如下方程:
(2)
直角坐标系下的接收站位置与目标轨迹如图2所示。

图2 接收站与目标轨迹位置关系示意
1.3 参数特征建模
1.3.1 目标信号参数特征
为了还原真实环境下的信号特征,设定3个目标的载频在同频段内捷变,目标均采用120 μs的重复周期,脉宽1 μs,扫描周期为3.6 s,每组脉冲个数为1 000个,脉组间隔为10 000 μs。设第i个目标的雷达信号起始时间为3×(i-1)μs。
由于目标飞行方向及天线指向的随机变化,设定3个目标飞行时间区间相同,每个扫周期内仅随机有30%的脉冲可以被侦获。
1.3.2 侦获方位参数特征
在1.2节设定侦收条件下,取y轴为接收站的0°方向,测得的目标方位角即为脉冲信号发出时目标位置到接收站位置的连线与y轴间的夹角。
当前主流的测向体制包括有比幅测向法、相位法测向、数字波束成形(Digital Beam Forming,DBF)测向法、最大信号法等,相位法测向、DBF测向法可将无干扰条件下的测向精度提升至1°以内。本文假设两个接收站的单站平均测向误差均为0.5°。
1.3.3 侦获功率参数特征
电子支援措施(Electronic Support Measures,ESM)侦察方程为
(3)
式中:PT为目标雷达信号功率;GT为目标雷达天线增益;GR为接收天线增益;λ为雷达信号波长;LR为信号损耗;R为雷达与目标之间距离;PR为接收到的目标雷达信号功率[14-15]。转换为分贝来表示信号功率:
(4)
在多个同型目标侦收时,因目标雷达工作于同频段,故认为波长λ相等。在相同侦收条件下,短时间内可将同型雷达目标的GR和LR视为相等。然而,不同目标的PT和GT存在差异,因此接收站测得的功率参数需独立设定为
Pa=-20lgR+20lgK+α+ε。
(5)
式中:α为接收站在处理信号过程中的衰减;ε为随机误差。
设第i个目标对应的Ki=(28+i)×1000,R的单位为km,α=-5 dB,随机测量误差ε范围为0~0.5 dB。基于上述建模条件,同型雷达多目标信号关联定位及航迹分选问题可转化为在缺乏目标先验数据的情境下,利用两个已知坐标的接收站实时获取的到达时间、到达方位、信号强度3项数据,完成测向参数匹配,进而实现目标定位,并成功筛选出单个目标的航迹。
2 目标定位及航迹筛选算法
2.1 基于密度聚类的初步定位
2.1.1 DBSCAN聚类算法
具有噪声的基于密度的聚类算法(Density-based Spatial Clustering of Application with Noise , DBSCAN)是基于密度的空间聚类算法中的典型代表。该算法依据邻域半径Eps、密度阈值MinPts两个参数对数据集D进行分选。设x∈D,
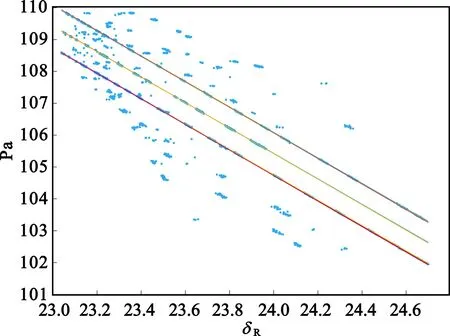
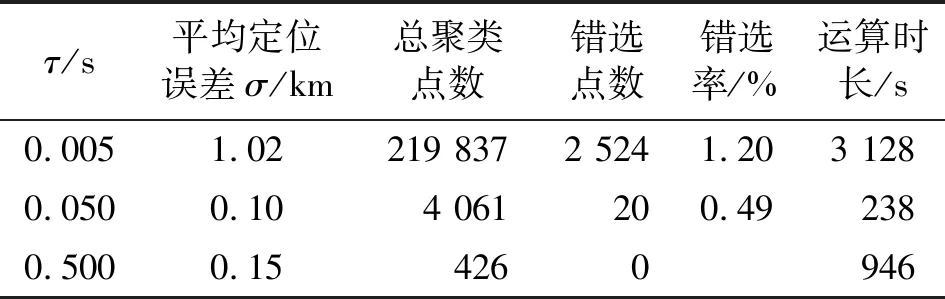
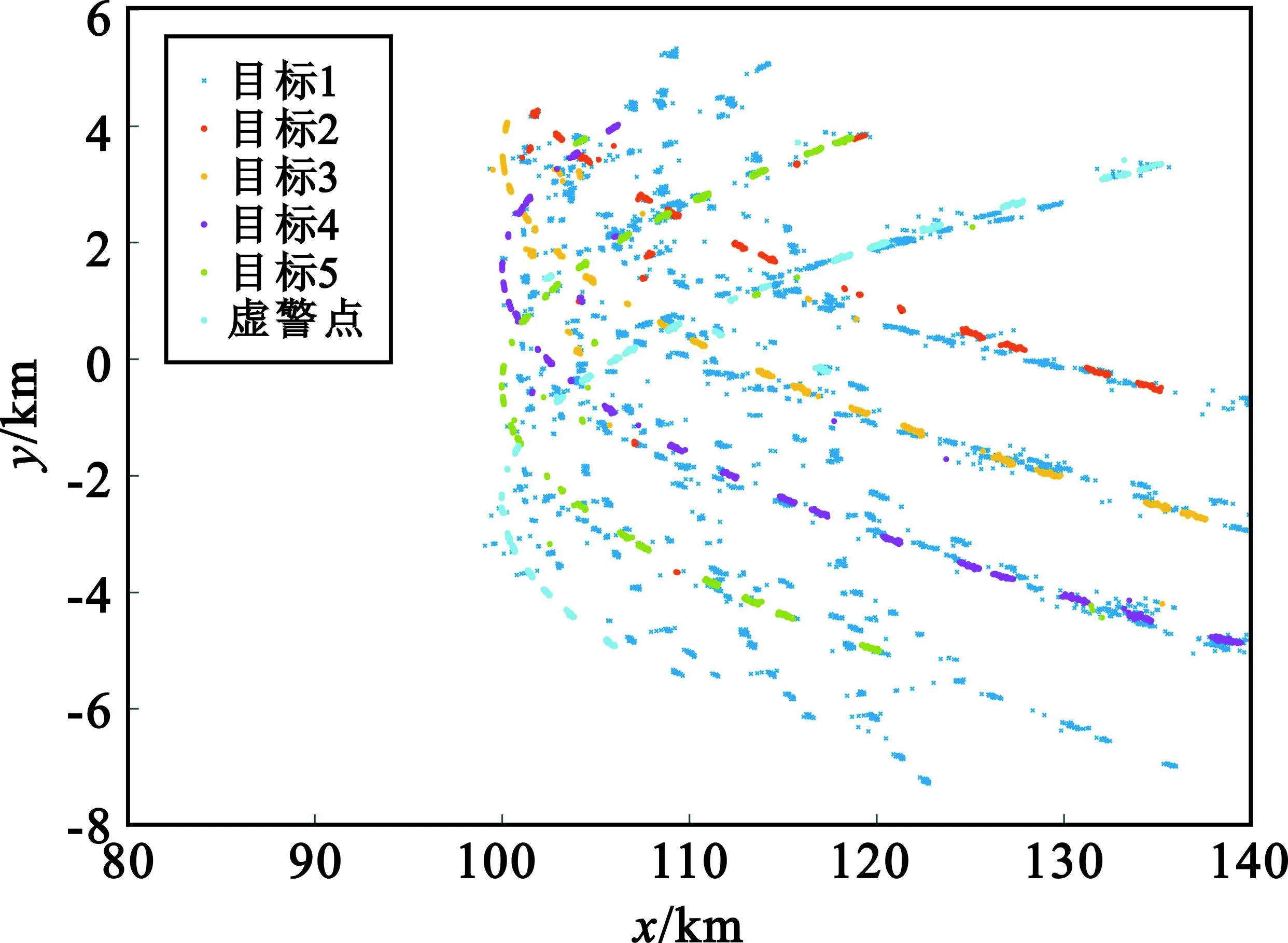
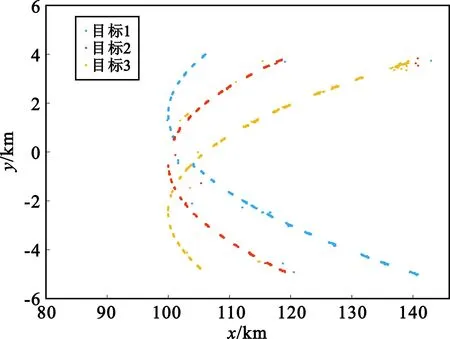
Nε(x)={y∈D:dist(y,x) (6) Nε(x)为x的ε邻域。定义密度 ρ(x)=|Nε(x)|, (7) 若点xi的密度ρ(x)>MinPts,则称该点为核心对象(不是核心对象,但是在某个核心对象的Eps邻域内的点称为边界对象),否则称为非核心对象或噪声[16]。 DBSCAN算法的邻域半径Eps和密度阈值MinPts需手动设定,不当取值会影响聚类准确度。为提高参数设置的合理性,文献[17-18]等提出了自适应判别方法。该方法利用数据集的分布特性生成候选参数列表,并在簇数稳定的参数区间内,基于去噪效果选取合适的Eps和MinPts作为初始密度阈值。 2.1.2 基于密度聚类的初定位流程 结合第1节仿真条件,可见多目标雷达信号参数深度交错,且数据量巨大,在参数与个体之间的匹配关系不明时难以开展有效的交叉定位计算。 针对该问题,本文引入密度聚类方法,基于测得的方位参数Doa和信号功率参数Pa进行聚类分选,实现测向参数的粗匹配与初步定位。基本流程如下: Step1 依据单站侦获参数中的到达时间Toa,将对应的方位参数Doa、功率参数Pa组成数组。两个接收站的参数集分别记为 Step2 由于聚类运算的复杂度随着参数数量的增加而成指数增加,因此,设定一个时间切片值τ,按切片后的时间范围对PDW1和PDW2进行分组,共分为Nτ=t|τ组,记为 Step3 对切片后的单组pdw1i和pdw2i参数进行归一化处理,基于归一化后的数据进行DBSCAN聚类运算。当对应的第i个时间切片内没有PDW数据,即pdw1i或pdw2i为空时,跳过该组数据,对下一个pdw1i和pdw2i非空的数据集进行聚类运算。依据聚类结果将pdw1i和pdw2i拆分为对应的聚类簇,记为C1i(k1)(k1≥1)和C2i(k2)(k2≥1)。 Step4 由于在一个时间切片τ=0.05 s范围内,可包含约0.05/0.01×1 000=5 000个Doa值,对所有Doa进行交叉定位计算显然是不经济的。 设目标速度为1Ma,在时间τ=0.05 s内最大位移为17 m。对于在100 km距离外的接收站,目标的最大角度变化量为0.009 7°,远小于当前主流测向设备的测量误差,因此目标在τ时间内位置、角度变化量对定位结果的影响很小。 在此基础上,为便于计算,取每个聚类簇C中密度ρ(x)值最大的数据点为该聚类簇的中心点,将中心点对应的归一化前的测向参数、功率参数记为C_doa1i(k1),C_pa1i(k1),k1≥1以及C_doa2i(k2),C_pa2i(k2),k2≥1。 Step5 利用同一切片时间对应的C_doa1i和C_doa2i包含值分别进行测向交叉定位,得到初始定位点坐标集合,记为Tc。 由于在同一切片时间内可能存在的不同目标的方位值的错误匹配,造成了在初始定位点中存在部分与真实轨迹不符的虚警点。因此,在初步定位的基础上还需要有效地区分出虚警点,再筛选出单个目标轨迹。 霍夫变换(Hough Transform)是图像处理中的一种特征提取技术,运用笛卡尔坐标系向极坐标系的变换将在一个空间中具有相同形状的曲线或直线映射到另一个坐标空间的一个点上形成峰值,从而把特定形状的问题转化为统计峰值问题,常用于检测图像中的直线[19]。 由式(5)可知,单个目标的功率参数Pa与目标距离R之间有如下关系: Pai(t)=-20lg(Ri(t))+20lg(Ki)+α+ε。 (8) 令 δRi=lgRi, (9) 则有 (10) 即单个目标的功率参数Pa与距离参数变量δR之间存在近似线性关系,其中ε为随机误差。 本文借鉴霍夫变换直线检测算法,基于2.2节获得的初始定位结果,检测计算Pa与δR之间的线性关系,基本流程如下: Step1 计算出初始定位点迹到单个接收站的距离Ri,并计算出对应的δRi。依据到达时间,将对应的δR和Pa组成数组。 Step2 对数组[δR,Pa]进行霍夫变换。首先创建霍夫空间,即极坐标θ和ρ的二维矩阵,其中θ在0~180°之间取值。令 ρ=δRicosθ+Paisinθ, (11) 计算单个数组[δR,Pa]对应的ρ。 霍夫变换的原理是,在霍夫空间中,同一直线上的点在θ和ρ上具有相同值。每出现一组相同的θ和ρ,就对该组合投一票。超过特定阈值的θ和ρ组合被视为存在直线,记作(θT,ρT)。然而,在测向交叉定位中,随机测向误差和功率参数的随机测量误差会导致定位误差。这使得δR与Pa之间存在近似线性关系,(θ,ρ)不会完全一致。因此,无法仅通过点数阈值筛选直线对应的(θT,ρT)。 考虑到测向误差和功率参数为随机误差,投票点数n在θρ平面上应在正确(θT,ρT)周边呈现二维正态分布。基于这一特性,我们改进了(θT,ρT)的提取方法:首先,设定基础筛选阈值,排除n低于阈值的(θ,ρ,n)点,避免局部干扰(阈值应结合θ步进值、目标数量上限及干扰数据占比来设定);其次,从筛选后的数据中,提取n为极大值处的(θ,ρ),即得(θT,ρT)。 为实现投票,需设定ρ的投票精度,并四舍五入计算得到的ρ值,再进行累计投票。设定θ步进值与ρ的投票精度时,要考虑运算时长、数据分布特性及实现便利性。根据这些要求和初定位点数量级,后续仿真中取θ步进值为0.01°,ρ的投票精度为0.01,以确保数据呈现分布特性,同时保持运算时长可接受。 Step3 依据提取到Nh组(θT,ρT)线性参数,分别分选出落在单一直线,即满足式(12)的[δR,Pa]数据点: (12) 式中:εmax为容差范围。εmax需要与Pa测量误差相符合,设置过大会使准确率下降,在轨迹交会处出现筛选错误;设置过小会导致部分真实定位点错误标记为虚警点。 找出满足式(12)的[δR,Pa]数据点对应的坐标点集合,记为Ti: (13) Step4 将[δR,Pa]不符合任一组(θi,ρi)对应线性关系的点对应的坐标集合标记为虚警点集合NT,在筛选结果中剔除。 NT={(x,y):|Pa-Pa′(i)|>εmax,(x,y)∈Tc,i∈(0,Nh)} 。 (14) 至此,完成虚警点去除和单个目标轨迹的分选。 综上所述,基于聚类与霍夫变换的同型雷达多目标定位及航迹筛选算法流程如下: 1)依据到达时间,将两站分别侦收到的[Toa,Doa,Pa]参数组成数组PDW1和PDW2。 2)以时间值τ对整体的侦收时间进行切片,按时间范围对PDW1和PDW2进行分组,记为Pdw1(i)和Pdw2(i)。 3)对切片后的单组Pdw1(i)和Pdw2(i)参数进行归一化处理,进行DBSCAN聚类。 4)依据聚类结果,取每个聚类簇C中密度ρ(x)值最大的数据点为该聚类簇的中心点,将中心点对应的归一化前的测向参数记为C_doa1i(k1)(k1≥1)和C_doa2i(k2)(k2≥1),将中心点的功率参数记为C_pa1i(k1)(k1≥1)和C_pa2i(k2)(k2≥1)。 5)利用同一切片时间对应的C_doa1i和C_doa2i包含值分别进行测向交叉定位,得到初始定位点坐标集合,记为Tc。 6)计算出初始定位点Tc到单个接收站的距离Ri,依据到达时间,将对应的距离参数δR、功率参数Pa。 7)对[δR,Pa]进行霍夫变换,取投票点数的极大值处对应的[θT,ρT]参数。 8)分别分选出落在单组[θT(i),ρT(i)]参数对应直线附近的数据点对应的坐标点集合Ti。 9)将[δR,Pa]不符合任一组线性关系的点对应的坐标集合标记为虚警点NT,剔除。 最终获得的目标定位点集合Ti分别对应单个目标的轨迹。 本文使用Matlab开展仿真实验,仿真条件与第1节构建模型相同,仿真参数如表1所示。 表1 仿真参数 3.1.1 单时间切片内的密度聚类与交叉定位 基于第1节构建模型,令时间切片τ=0.5 s,取聚类参数Eps=0.003,MinPts=5,在时间切片45.45~45.5 s范围内的pdw1和pdw2聚类效果如图3所示。 (a)pdw1 可见,通过聚类运算,将时间切片范围内的数据清晰的分为2个聚类簇。对每个聚类簇中的测向参数取平均值,得C_doa1(1)=84.510°,C_doa1(2)=84.736°,C_doa2(1)=95.931°,C_doa2(2)=95.701°。再利用两个C_doa1值与两个C_doa2值分别进行测向交叉定位,可得到4个坐标点,分别为(100.001,-0.388)km,(102.072,-0.189)km,(102.034,-0.599)km,(104.191,-0.401)km。这4个坐标点即为在时间切片45.0~45.5 s内的初始定位点,其中包含至少两个虚警点(将不同目标的测向参数错误匹配造成)。 对整体时间范围0~90 s按照τ=0.05 s进行时间切片、聚类运算、交叉定位,获得的整体初始定位点坐标Tc如图4所示。 图4 初始定位点坐标 将图4与图2对比可见,初定位点中包含有部分明显区别于目标轨迹的错误坐标点。 3.1.2 基于霍夫变换的单目标定位航迹筛选 在获得的初始定位点的基础上,计算所有初始定位点坐标Tc到接收站1的距离R1,同时记录每个初始定位点对应的接收站1侦获功率参数C_Pa1。 将R1代入式(9),算得距离参数变量集合δR1。 设定θ步进值为0.01°,ρ的投票精度为0.01,设定排除干扰点的筛选阈值为200,对数组[δR1,C_Pa1]进行霍夫变换,效果如图5所示。 图5 霍夫变换效果图 图5中,θ和ρ在[14.03,49],[14.06,48.85],[14.1,48.69]三处取得明显的极大值。3组(θT,ρT)参数对应的直线与[δR1,C_Pa1]数据集的对比如图6所示。可见,经过霍夫变换成功提取出[δR1,C_Pa1]数据集中的隐藏线性关系。 图6 提取直线与参数对比图 取εmax=0.5,此时的分选效果如图7所示。 图7 定位轨迹分选结果 将分选结果图7与原始轨迹图2对比可见,该算法有效剔除了初始定位中的虚警点,并清晰地区分出了单个目标轨迹。 为了验证本文算法的定位准确性、对多目标筛选可靠性和计算效率三个方面性能,通过平均定位误差、定位点错选率和运算时长三个参数来综合评价算法性能。 平均定位误差定义为 (15) 式中:I为目标个数;Ni为第i个目标对应的数据点总数;yi(t)与xi(t)为满足式(2)的正确目标坐标;yi′(t)与xi′(t)为依据算法定位筛选出的目标坐标。 错选率为错误分选至目标轨迹的点数占应有定位点总数的百分比。 运算时长为Matlab工具完成参数聚类、初始定位及分选运算的用时时长之和。 3.2.1 仿真2:不同τ取值条件的性能对比 在仿真1的基础上,本小节针对不同τ取值条件进行仿真,统计性能参数。不同τ取值条件下的算法性能如表2所示。 表2 不同参数条件下的算法性能 从验证结果来看,本文所提算法有较高的定位精度与筛选准确率。 同时,结合仿真结果分析,τ取值对算法性能的具体影响关系如表3所示。 切片时长τ过大或过小都会导致运算时长增加,导致定位效果不理想。因此,需结合实际数据量和时间跨度合理设置。 3.2.2 仿真3:不同目标数的定位效果对比 在仿真2的基础上,分别将符合式(2)轨迹特征的目标个数增加到5个和10个,得到定位及航迹筛选结果如图8所示。 (a)5个目标 对算法性能统计结果如表4所示。 表4 多目标条件下的计算结果 根据仿真结果可见,虽然目标数量增多会导致初定位中的虚警点数量上升,但当目标数量增加到10时,仍能保证定位误差、错选率不恶化。同时,仿真结果显示运算时长的增加与目标个数之间是非线性的。这是因为在目标个数增加后,使在单一时间切片内的聚类簇个数增加,而单一时间切片内的初始定位点数是聚类簇个数的平方。因此,目标个数增加导致了初始定位点总数以及虚警点个数的非线性增加,从而导致了整体运算时长的非线性增加。针对该问题,结合3.2.1节中对切片时长τ的影响分析,可通过在目标个数增加时适当减少τ取值来减少初定位中的虚警点个数,改善整体运算效率。 本文所提算法实现简单,基于一般设备能够采集的脉冲描述字即可实现,相较于目标个体识别,对设备性能、数据量的需求更小。相较于直接定位法,本文仅需要两个接收天线,不需要更改设备,更符合实用场景。 3.3.1 仿真4:定位精度对比分析 本文算法通过时间切片与聚类使定位精度明显改善。为了对比验证提升效果,设定对比仿真算法。侦获测向参数与各目标之间的对应关系已知。直接匹配两站接收时间|Toa1-Toa2|<1 μs的同一目标Doa值,以测向交叉定位算法实现定位。 目标个数为3,目标轨迹、侦收条件、侦收误差与仿真2相同。以τ=0.05 s在时间t∈(0,90 s) 上取均匀分布的数据点。仿真2与仿真3的定位效果对比如图9所示,定位精度对比如表5所示。 表5 定位精度对比 (a)本文算法定位轨迹 对比可见,本文算法能够有效降低随机测量误差造成的干扰,使目标定位轨迹收敛,明显提升定位精度。 3.3.2 仿真5:筛选精度对比分析 为了验证本文算法在航迹筛选方面的优势,本文在完成基于时间切片与聚类的初定位之后,以文献[10]所提算法作为对比。 仿真条件同仿真2。对已获取的定位点集合进行霍夫变换,提取出其中的直线航迹,认为单一的直线航迹对应一个单独目标。 依据霍夫变换结果对航迹进行筛选后,仿真2与仿真4的对比效果如图10所示,筛选精度对比如表6所示。 表6 筛选精度对比 (a)本文算法筛选轨迹 可见,对比算法基于霍夫变换把近似于直线的部分筛选为单个目标,在目标航迹接近直线部分能够适用,但在目标轨迹不规则后就无法正确筛选,适用范围有限。而本文所提算法能够解决不规则交错运动的多个同型雷达目标航迹筛选问题,适用场景更为丰富灵活。 本文深入研究了在双站测向交叉定位条件下的同型雷达多目标定位及非规则交错航迹分选问题,提出了一种基于DBSCAN聚类和霍夫变换的有效算法来应对这一挑战。通过仿真验证,该算法展现出优异的定位精度和筛选准确率。即使面对目标数量增至10个的情况,该算法仍能确保定位误差和错选率维持在可接受范围内,不会出现明显恶化。此外,该算法实现简便,基于常规设备采集的脉冲描述字数据即可运行,无需额外的设备改动,使其更符合实际应用场景的需求。更为重要的是,该算法能有效降低随机测量误差对定位的干扰,促使目标定位轨迹收敛,并显著提升定位精度。因此,它能够有效处理非规则交错运动下的多同型雷达目标航迹筛选问题,展示了广阔且灵活的适用场景,并为相关领域的研究提供了宝贵参考。 下一步将针对本文算法与与速度门限筛选、跟踪滤波算法的融合开展研究,进一步完善和提升定位效果,使本文算法可契合更多实际使用场景。2.2 基于改进霍夫变换的单目标定位航迹筛选
2.3 算法流程
3 仿真验证与性能分析

3.1 仿真1:算法流程仿真验证




3.2 算法性能分析

3.3 对比分析



4 结束语
