改进YOLO5Face 的小鼠行为实时分析方法研究
2023-08-21胡春海
胡春海,姜 昊,刘 斌
(燕山大学 河北省测试计量技术及仪器重点实验室,河北 秦皇岛 066004)
0 引言
动物行为学的发展已经深刻地改变了人类的思维方式,它不仅探索了动物的学习、认知过程,而且还深刻地影响着心理学、教育学等领域[1-2]。动物的行为不仅仅是一种表达情感的方式,而且更多地反映了它们的内在特征,它们的行为受到基因、环境等多种因素的影响,并且反映出它们的整体性格。通过对动物的行为学研究,我们可以深入了解它们的自然状态,并且可以通过在特殊的环境中观察它们的行为,来探索它们的神经系统、心理机制以及对药物的反应[3]。实验动物行为分析在神经生理学、行为药理学等神经科学领域能够反映实验动物整体状态[4]。小鼠和人类同为哺乳动物,基因组与人类非常相似,相似度高达98%。一些特定的行为信息可以对人类医学研究有所帮助,为其他生物学研究提供重要的参考和依据[5-6]。自新冠肺炎疫情爆发后,无论国际还是国内检测试剂及抗体疫苗研制都依赖于动物实验[7]。以小白鼠为实验对象,将计算机视觉技术、视频分析技术和行为识别相结合,实现小鼠探索过程中动作识别和检测,可以更好地帮助研究人员理解和分析动物行为,对促进相关学科的发展具有重要意义[8]。
随着人工观察、传感检测和视频跟踪技术的发展,动物行为分析方法取得了巨大的进步。机器学习与计算机视觉在实验动物行为分析领域发展迅速,在一定程度上实现了自动化与定量化。近年来,利用先进的数字图像处理技术,可以实时追踪和预测动物的行为,从而更好地掌握它们的运动轨迹、运动距离、速度等信息,这已经成为一种先进的研究方法。然而,这种方法仅仅局限于通过观察动物的运动参数来间接分析它们的行为特征,忽略了它们本身的体态变化。事实上,行为是由体态和体态的变化(包括位置)组成的,而体态可以反映出更多的心理因素。因此,准确地识别动物的体态,并对它们的行为进行详细描述,已经成为动物行为学,尤其是啮齿目动物行为研究的一个重要方向。本研究利用实验小鼠运动中不同动作的行为特征特点,从体态和运动两个方面描述小鼠的行为。
基于视频记录行为的图像分析是最常见也是最广泛的使用方法[9-12],但是由于缺乏实时的行为特征变量分析和反馈调节,大多数小鼠研究仍然存在一定的局限性[13]。尽管实验人员可以通过离线视频来观察小鼠的行为,但他们仍然必须不断检测和评估其各种行为特征,以便及早发现问题,并及时采取有效的措施来改善研究结果。现有的小鼠行为实时分析方法具有一些问题,比如需要依赖于强大的GPU 才能达到实时性[14],不适用于大多数动物行为实验场景;或者是特征提取过程满足实时性但是再加上行为识别后就不满足实时性。还有的小鼠行为实时分析方法难以识别小鼠身体各个部位[15-16],只能将小鼠看作质心或者识别出身体局部进行处理,对小鼠体态特征的构造和行为特征细化是不利的。
本研究针对实时性问题提出一种改进YOLO5Face 的小鼠行为实时分析方法。首先通过改进的深度学习关键点检测网络实时获得小鼠身上的四个关键点,然后通过实时检测到的关键点坐标提取体态特征与运动特征,最后放入机器学习实时分类模型进行行为分类。
1 小鼠关键点实时检测
1.1 YOLO5Face 介绍
YOLO5Face[17]的优势分以下两点论述。
1) YOLO5Face 模型架构
YOLO5Face 的模型架构如图 1 所示。YOLO5Face 相对YOLOv5 具体改动为:

图1 YOLO5Face 的模型架构Fig.1 The model architecture of YOLO5Face
a)Stem 模块替代了YOLOv5 网络中原有的Focus 模块,在性能没有下降的同时,提高了网络的泛化能力,降低了计算复杂度。
b)YOLO5Face 网络对SPP 模块进行更新,使用更小的kernel。将原YOLOv5 用的(5,9,13)的SPP kernel 改成(3,5,7)的SPP kernel,使网络更适合人脸检测而且提高了检测精度。
c)YOLO5Face 网络在原YOLOv5 的基础上添加了一个stride=64 的P6 输出块,P6 输出块的特征图大小为10×10,可以提高对大人脸的检测性能。之前的人脸检测模型的重点基本放在检测小人脸上,YOLO5Face 通过提高对大人脸的检测效果从而提升整个网络模型的检测性能。
d)YOLO5Face 网络提出在人脸检测问题中,一些目标检测的数据增广方法不太适合使用,比如上下翻转和Mosaic 数据增广。不使用上下翻转时,模型检测性能可以提高。不使用Mosaic 数据增广时,对小人脸的检测性能变好,但是对中尺度和大尺度人脸来说检测性能一般。导致这种情况发生的原因,可能是由于WiderFace 数据集中的小人脸数据相对较多,不使用Mosaic 数据增广提高了对小人脸的检测性能从而提高了整体的检测性能。另外随机裁剪有助于提高性能。
e)YOLO5Face 的可移植性比较强,从服务器到嵌入式或者移动设备可以根据需要设计不同深度和宽度的网络模型。
2) Wing-Loss
YOLO5Face 是在YOLOv5 的基础上进行改进的。YOLOv5 只是一种基于深度学习的实时目标检测模型,不具备关键点检测功能。YOLO5Face在YOLOv5 网络的基础上添加了5 个人脸关键点回归的代码,对于关键点回归问题使用的损失函数是Wing-loss,其计算公式为
Wing-loss 是一个分段复合损失函数,在训练刚开始误差比较大的时候用L1 损失,在训练的后期误差相对比较小的时候,用一个具有偏移量的对数函数。这5 个人脸关键点回归损失称为lossL,在YOLOv5 原本的损失函数lossO中加上lossL,构成总的损失函数loss(s),
其中,λL是关键点回归损失函数的权重因子。
1.2 改进YOLO5Face
本研究的关键点检测算法之所以建立在YOLO5Face 之上,是因为YOLO5Face 关键点检测模型相对以往的基于热力图回归的关键点检测模型更加轻量化,计算量更小,满足本研究要求的实时性要求和精度要求。不选择更新的YOLOv6/7/8 是因为它们只有目标检测功能没有关键点检测功能,YOLO5Face 是既有目标检测又有关键点检测。本研究通过改进YOLO5Face 提出一种可以适用于动物行为学实验中的小鼠关键点检测方法,主要工作有以下几点:
1) 新增了一个更小的检测头来检测更小尺度的物体。
原YOLO5Face 中设定的4 个检测头,分别对应的特征图大小是80×80、40×40、20×20、10×10。其中特征图大小为10×10 的检测头是YOLO5Face相对于YOLOv5 添加的用来提高大目标的检测性能。而对于旷场实验场景,小鼠相对于整个旷场是一个小目标,如图2 所示。故去掉特征图大小为10×10 的检测大目标的检测头,添加一个特征图大小为160×160 的检测小目标的检测头,用来提高小目标的检测准确率,网络结构如图3 所示。

图2 旷场实验图像Fig.2 Open field experiment image

图3 改进的YOLO5Face 的模型架构Fig.3 Improved model architecture for YOLO5Face
2) 主干网络中加入YOLOv8 的C2f 模块[18]。
C2f 模块参考了C3 模块以及ELAN 的思想进行设计,如图4 所示,让模型获得了更加丰富的梯度流信息,大大缩短了训练时间,而且提高了关键点检测精度。
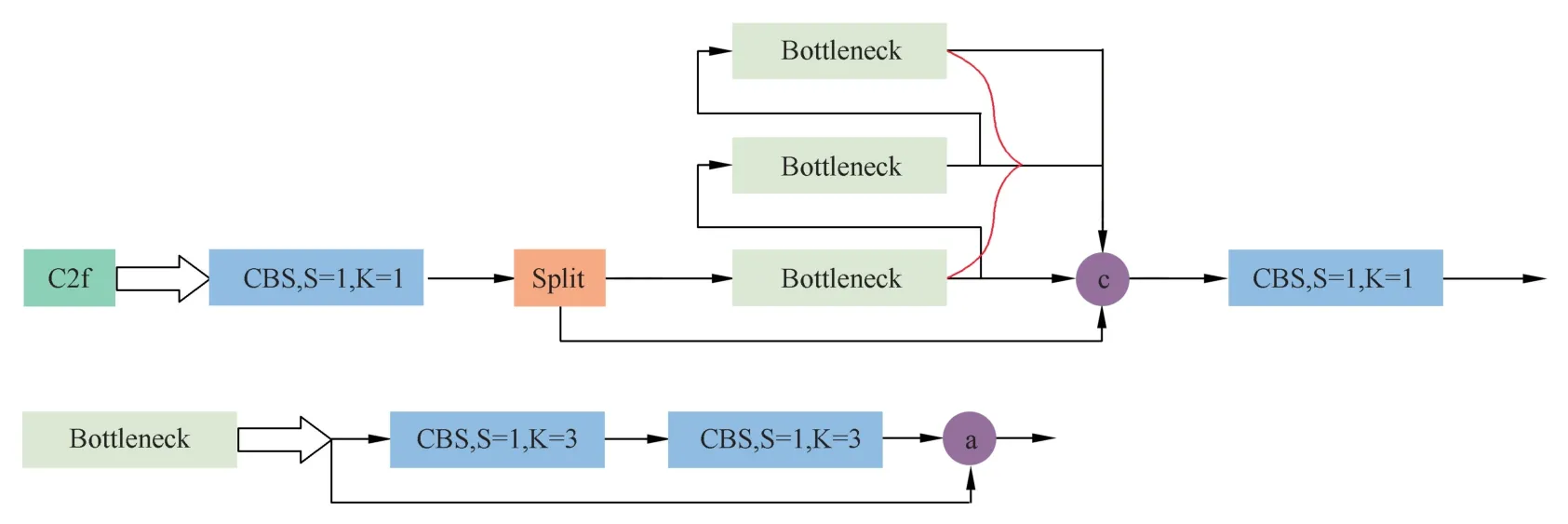
图4 C2f 模块结构图Fig.4 The structure of the C2f module
3) 采用GSConv 和Slim-neck 技术,可以降低模型的复杂度,同时提升精度[19]。
为了同时兼顾精度和检测帧率,采用标准卷积、深度可分离卷积和shuffle 混合卷积进行组合构建为一个新的卷积层:GSConv(结构如图5 所示)。该方法使卷积计算的输出尽可能接近SC,降低了计算量。对于轻量级模型,在搭建网络结构的时候可以直接用GSConv 层替换原始的卷积层,无需额外操作即可获得显著的精度增益。GSConv 可以加快模型预测的速度。

图5 GSConv 模块结构Fig.5 The structure of the GSConv module
GSbottleneck 是由两个GSConv 模块和一个DWConv 模块组成,输入分为两个部分,一个部分导入两个GSConv 模块,另一个部分输入一个DWConv 模块,最后将这两部分的输出加起来,如图6(a)所示。VoVGSCSPC(跨级部分网络)模块是在GSbottleneck 的基础上使用一次性聚合方法设计而成的,如图6(b)所示。
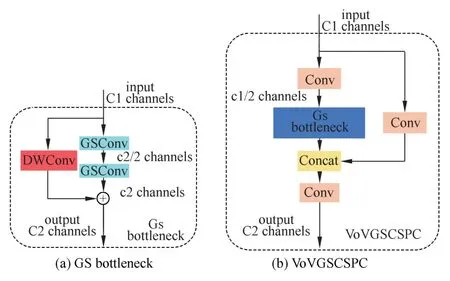
图6 VoVGSCSPC 模块结构Fig.6 The structure of the VoVGSCSPC module
1.3 小鼠关键点检测数据集
通过分析小鼠行为的动作特点,并结合旷场实验[20]中运动参数和行为参数测量的需要,确定以小鼠的鼻尖、左耳、右耳和尾根作为关键点并构造姿态骨架,如图7 所示。小鼠关键点检测数据集的构建,通过对实验场景平台(如图8 所示)获取的视频进行处理,将视频打成图片,使用labelme进行标注(如图9 所示),依次标注包围小鼠的框、鼻尖、左耳、右耳、尾基。之所以要标注框,是因为使用的关键点检测算法YOLO5Face 是基于YOLOv5 算法的,YOLOv5 的数据集是需要标注目标框的。最后制作好的数据集包含1 000 张图片,800 张训练,100 张验证,100 张测试。YOLO5Face原代码预测的关键点数量是5 个,本研究中只用到4 个关键点,所以需要对YOLO5Face 代码进行修改,使其预测4 个关键点坐标。
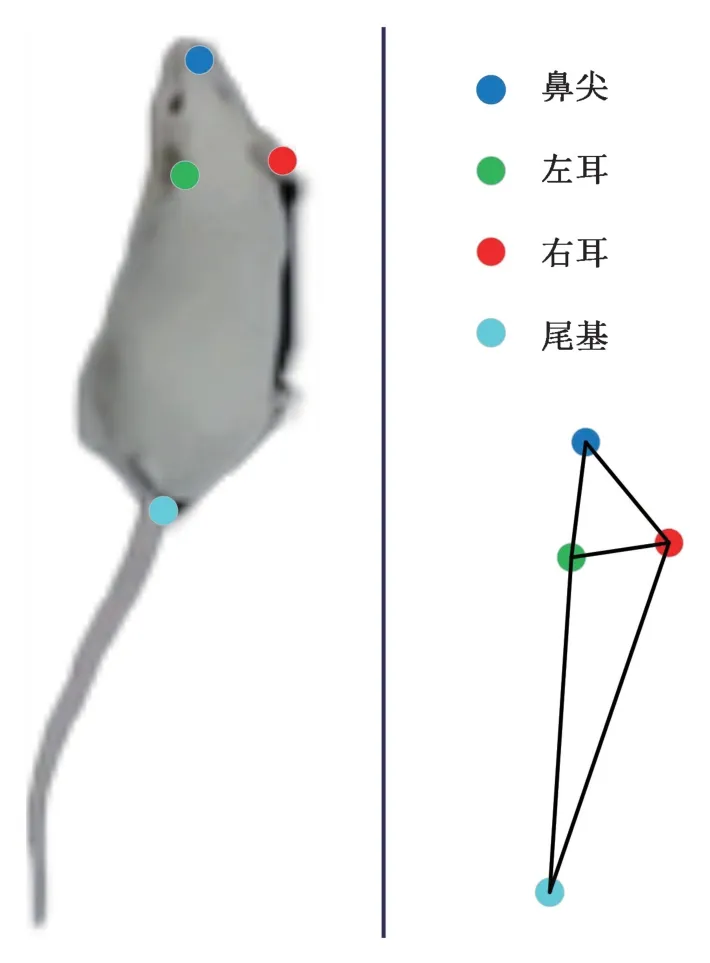
图7 小鼠关键点骨架图Fig.7 Skeleton diagram of mouse key points

图8 实验场景平台Fig.8 Experimental platform
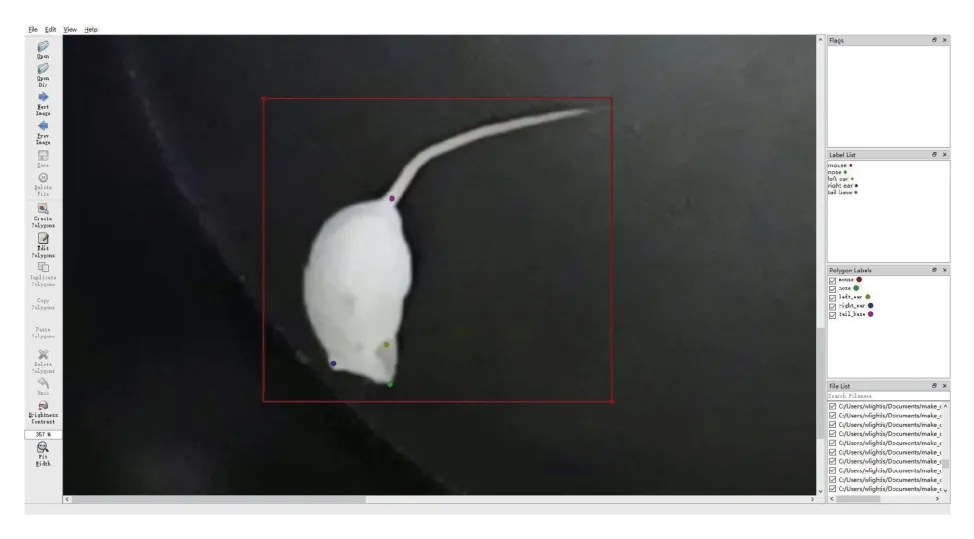
图9 Labelme 标注数据集Fig.9 The dataset annotated by Labelme
1.4 关键点检测评价标准
为了客观合理评价改进的YOLO5face 模型在小鼠关键点检测任务上的性能,本文采用PCK(Percentage of Correct Keypoints)作为小鼠关键点检测准确度的评价标准。PCK[21]定义为正确估计出关键点的比例,计算检测的小鼠关键点与其对应的真值间的归一化距离小于设定阈值的比例。PCK 指标计算公式为
式中,i表示小鼠关键点的标签序列号,k表示第k个阈值,Tk表示人工设定的阈值,Tk∈[0:0.01:0.5],p表示小鼠图像序号,dpi表示第p幅图像中标签序列号为i的姿态关键点预测值与人工标注真值的像素距离,为数据集中第p幅图像的尺度因子。小鼠两只耳朵的位置相对稳定,不会因为姿态的不同出现较大的变化,适合作为尺度因子。所以本文采用每幅图中检测的左耳坐标到右耳坐标的欧式长度作为归一化参考距离。δ表示如果条件成立则为1,否则为0。是对所有关键点计算取平均:
另外使用帧速和模型大小对模型进行评价,帧速表示模型每秒能处理多少帧图像,即模型实时帧率,单位是f/s;模型大小指保存的模型大小,单位是MB。帧速越高表示模型实时性能越好,模型大小越小表示模型越轻量化。
1.5 消融实验
为了验证上述添加的改进模块对关键点检测精度的有效性,进行消融实验结果如表1 所示。消融实验得出结论:同时加入C2f、smaller head 和GSConv_Slim-neck,训练得到最佳模型,测试集精度相对于Baseline 提高了2.25%,从95.25%提升到97.5%。注:表中同名但是末尾带有(∗)的模型,表示训练了更长时间。
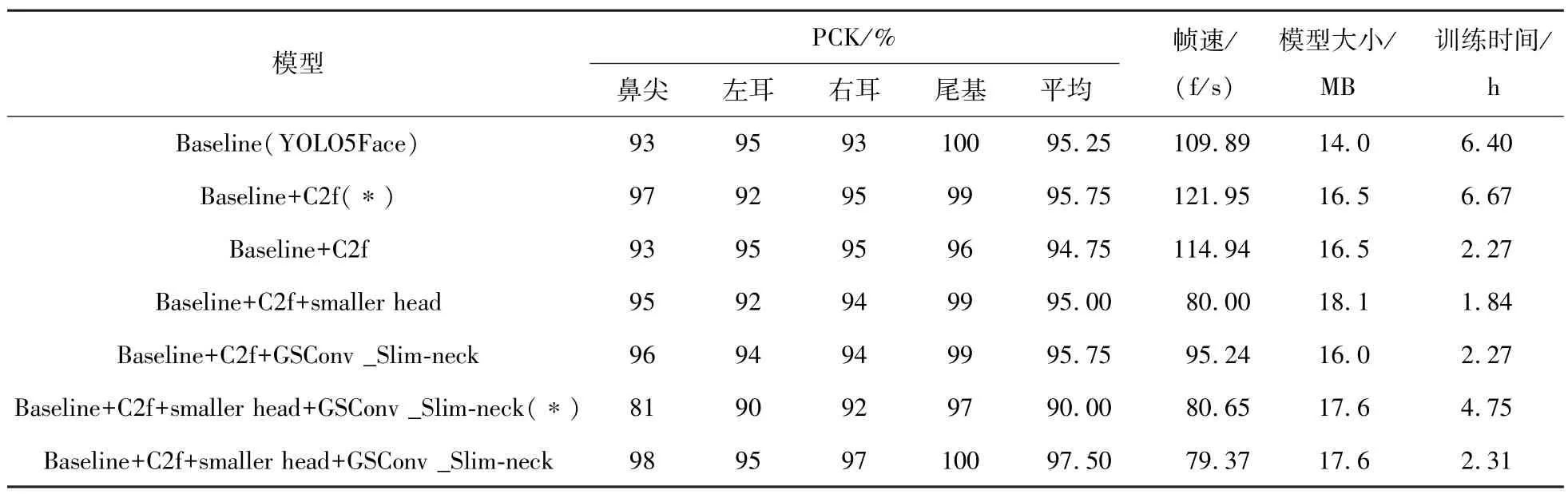
表1 消融实验结果Tab.1 Ablation results
1.6 不同模型间的实验结果与分析
为了保持实验结果的客观一致性,实验环境统一使用如下配置:CPU:Intel Core i7-12700H 2.70 GHz;GPU:NVIDIA GeForce RTX 3080 Ti;内存:16G;操作系统:Windows 11。
在获得最佳的权重之后,与基于深度学习的动物姿态估计方法DeepLabCut[22]进行实验结果对比,结果如表2 所示。从PCK 指标、帧速和模型大小三方面进行评价。结论:本文模型在精度上相对于 DeepLabCut 有 2% 的提升, 帧速是DeepLabCut 的3 倍,模型大小是DeepLabCut 的1/5。本文算法在实时关键点检测问题上已经完全胜任。

表2 不同模型的比较结果Tab.2 The results of the comparison of different models
2 小鼠行为实时识别
2.1 小鼠行为识别数据集
本文的小鼠行为识别数据集由经验丰富的观察员进行数据标注,行为是一个过程,由一系列连续帧组成,包括行为的开始、中间和结束过程,单独一张图片是很难判断这是什么行为,所以在数据标注时一个行为的所有过程都要被标注。结合旷场实验中的具体要求,本文将小鼠行为分为梳洗、直立、静止和行走四种,每类行为标注500 张,其中训练集和测试集的比例是7 ∶3,数据集一共2 000 张,训练集1 400 张,测试集600 张。
根据研究[23],动物行为学指标可以划分为两大类:运动特征和体态特征。通过结合多种行为学指标来识别小鼠的行为,可以更加准确、全面地评估其行为特征,因此本研究将同时考虑这两类行为指标。
运动特征是反映小鼠行走等行为的显著指标。本文的小鼠关键点检测模型能同时检测到小鼠身体的4 个关键点分别为鼻尖、左耳、右耳和尾基,另外取左耳关键点和右耳关键点连线中心点作为第5 个点。小鼠的运动特征就是分别计算这5 个点的帧间运动距离。帧间运动特征反映了上下帧之间小鼠行为的连续性。以往,基于运动参数的行为学指标假设小鼠被视为一个质点,并以其身体区域的质心来描述它的位置。本文中使用5 个关键点坐标,即是将小鼠的身体部位看作多个目标,每个目标的运动距离都作为一个运动特征,这样做的目的是细分小鼠的运动特征,在一些只有身体部分区域发生变化的行为发生时(比如直立行为,尾基基本没有运动距离,但是鼻尖有大幅度的运动距离)能够作为一个显著特征进行行为识别。运动距离指的是小鼠在连续两帧间移动的距离,计算方法如下:
体态特征是根据小鼠骨架模型(如图7 所示)来计算的。鼻尖、左耳、右耳及尾基4 个关键点构成四点骨架,骨架的每一条边作为一个向量,图中共有5 个向量。计算所有向量的长度、两两之间的夹角以及围成的四边形面积作为体态特征。
总结:数据以视频序列输入小鼠关键点检测模型进行预测小鼠关键点在图像中的位置,利用关键点检测模型输出小鼠关键点的坐标进行计算行为运动特征和体态特征共27 个特征建立行为识别数据集(特征1 到特征27 分别表示根据小鼠骨架计算的距离、角度、面积以及帧间位移特征)。共2 000 个数据展示其中一部分,最后一列是标签,如表3 所示。
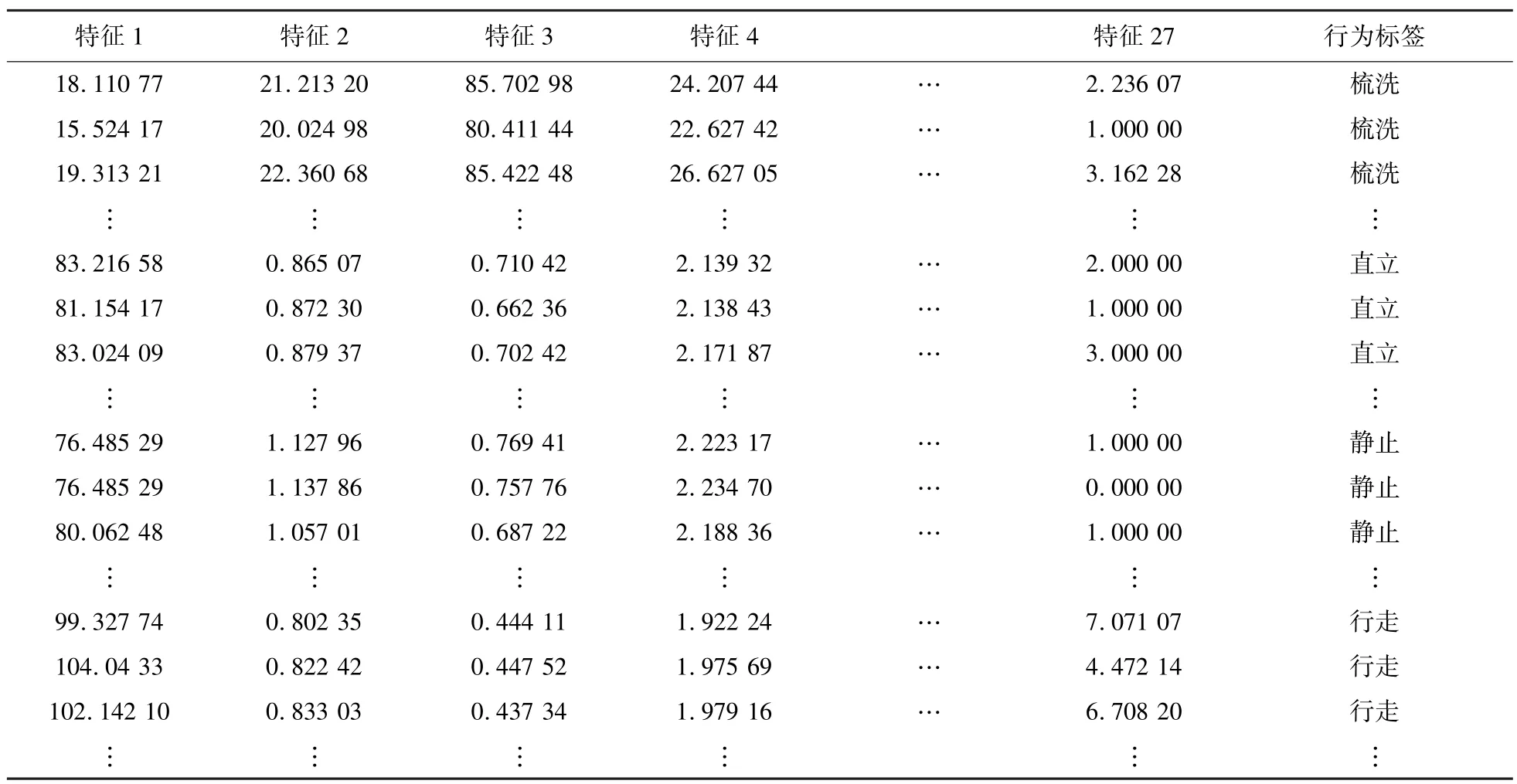
表3 行为识别数据集(部分)Tab.3 Behavior recognition dataset (part)
2.2 行为分类模型
2.2.1 SVM 模型
SVM[24]是一种二分类模型,它通过寻找特征空间中间隔最大的分离超平面来实现对数据的有效二分类。加了核函数之后,SVM 变成一个非线性模型。因为本文要构造一个实时模型,而SVM模型计算量小,故决定在此基础上设计一个实时分类模型。
2.2.2 SVM 实时分类
为了实现实时性,将SVM 训练和测试的代码分开。SVM 运行时间如表4 所示。训练加测试的总时间是1.418 s,约等于0.705 f/s。这个结果远远达不到实时性,因为这还仅仅是行为分类的帧数,如果再加上小鼠关键点检测需要的时间,总帧数连0.705 f/s 都达不到。但是从结果中看到SVM 训练完成得到权重之后,跑测试集的时间只有0.029 s,约等于34.72 f/s,这个帧率完全满足实时性。

表4 SVM 运行时间Tab.4 SVM run time
故使用SVM 进行行为识别的时候进行如下设计:调用SVM 时,先进行判断,如果没有已经训练好的权重不存在,就进行训练然后将权重保存下来,然后去预测;后面再调用SVM 时每次进行判断,如果已经存在训练好的权重,加载此权重去预测,省去每次都要训练的时间。
在本文自建的小鼠行为识别数据集上SVM的测试结果(如表5)可看出,核函数选择为高斯径向基函数时,SVM 分类模型识别率最高,因此核函数选择为RBF 进行下一步操作。测试集平均精度为91.93%,梳洗、直立、静止以及行走行为的测试集精度分别为96.89%、86.88%、94.67%、89.29%,如表6 所示。
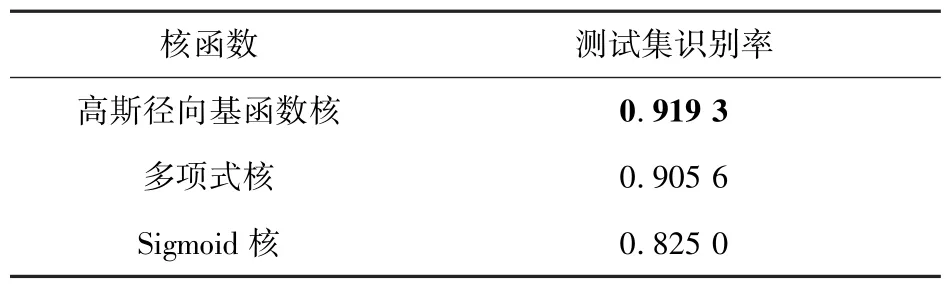
表5 不同核函数SVM 训练模型识别率Tab.5 Recognition rate of SVM training models with different kernel functions
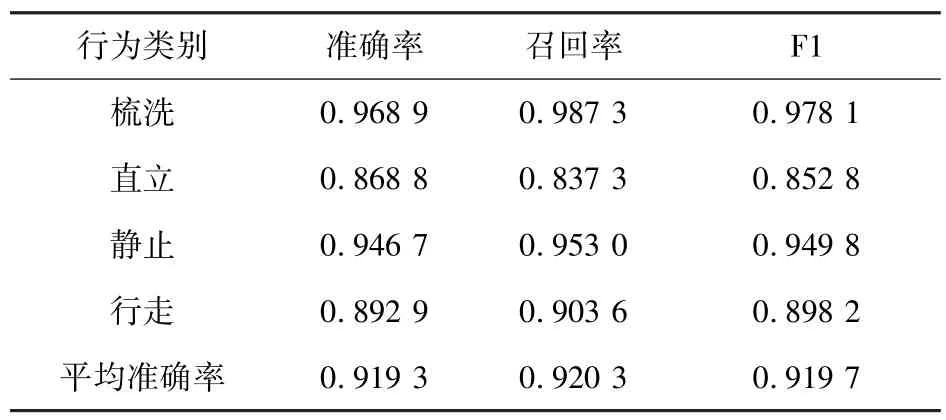
表6 SVM 分类结果Tab.6 SVM classification result
2.2.3 机器学习算法对比实验结果及分析
机器学习常用的分类算法除了SVM 还包括决策树、随机森林、朴素贝叶斯分类器、KNN、逻辑回归分类、集成算法(AdaBoost、GBDT、XGBoost、LightGBM)。下面用这9 种机器学习算法在本文自建的小鼠行为识别数据集上进行对比实验,分类结果如表7 所示。
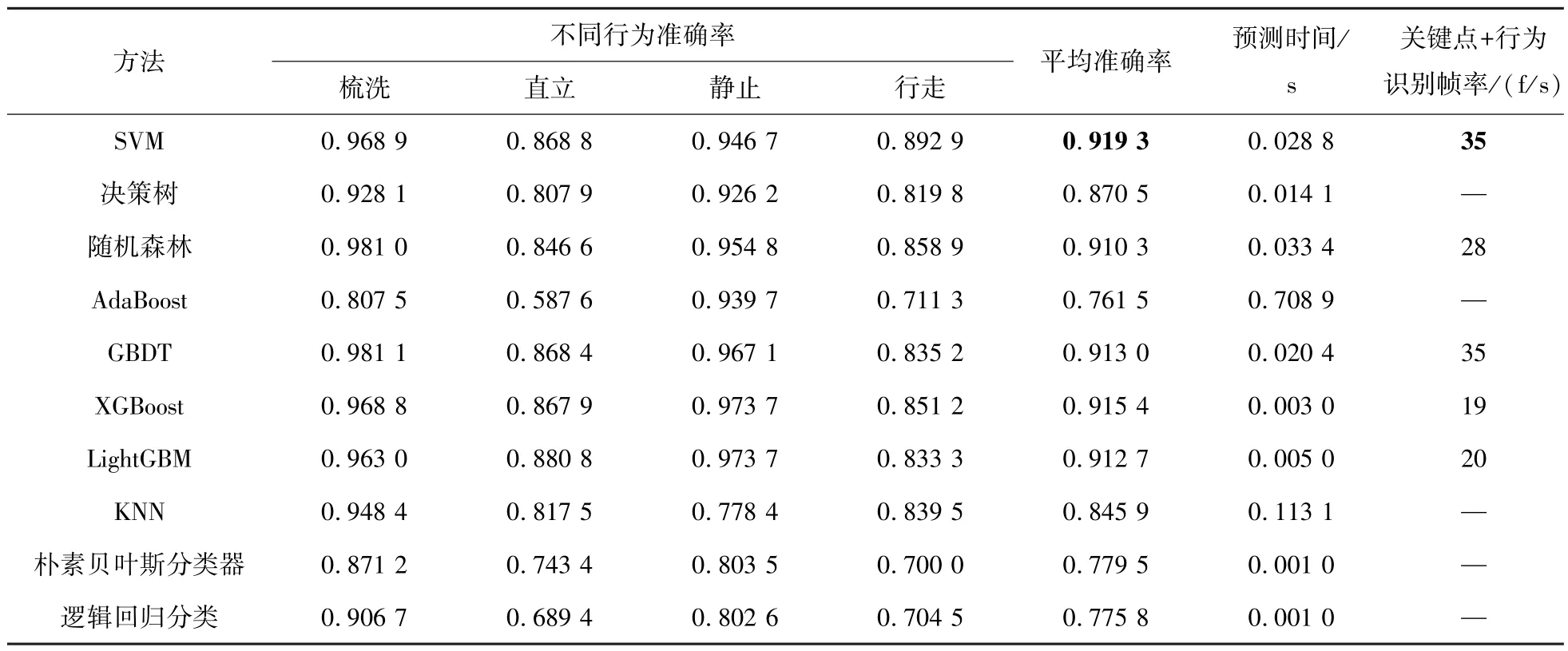
表7 行为识别实验的对比实验结果Tab.7 Comparison of experimental results of behavior recognition experiments
从平均准确率来看,SVM、随机森林、GBDT、XGBoost、LightGBM 基本在同一水平,准确率比较高,其他的算法精度比较低。从预测时间来看,上述几个算法中LightGBM 只有0.005 s,相当于200 f/s; XGBoost 更是只有0.003 s, 相当于333 f/s。单从这个结果上来看,如果将小鼠行为实时识别模型中的行为分类算法使用这两个算法中的一个,实时性就能大幅度提高。于是本文使用XGBoost 和LightGBM 算法都搭建了小鼠行为实时识别模型,使用XGBoost 的模型帧速只有19 f/s,使用LightGBM 的模型帧速只有20 f/s,均达不到SVM 的35 f/s。这里特意说明,使用XGBoost、LightGBM 进行小鼠行为实时识别的时候,都是将训练和测试过程分开的,如果检测到已经训练好的权重,就直接加载进行模型推理。XGBoost、LightGBM 只能跑到19 f/s、20 f/s 的原因应该是模型比较复杂,加载的慢,虽然推理的快,但是加载慢同样会使整体实时性下降。接下来将平均准确率比较高的几个算法都以同样的测试方法放进小鼠行为实时识别模型,测得随机森林是28 f/s,GBDT 是35 f/s。SVM 和GBDT 在帧率都是35 f/s 的前提下,SVM 的准确率以0.63%的微弱优势胜过GBDT。综上所述,在本研究实验场景下SVM 的性能超过其他机器学习算法,所以小鼠行为实时识别模型基于SVM 搭建。
2.3 小鼠行为实时识别流程
小鼠行为实时识别就是将小鼠关键点检测模型与基于SVM 的小鼠行为实时识别模型拼接在一起,行为识别流程图如图10 所示。摄像头实时获得小鼠图像,关键点检测模型实时获得小鼠的鼻尖、左耳、右耳和尾基的坐标,并保留上一帧的这4 个点的坐标(第一帧帧间运动距离为0)。然后利用当前帧和上一帧的坐标计算运动特征和体态特征共27 个特征。SVM 根据小鼠行为识别数据集已经训练好的权重,只运行推理过程,对获得的特征进行实时分类,完成小鼠行为实时识别流程。

图10 行为识别流程图Fig.10 Behavior recognition process
完成的小鼠实时行为识别截图如图11 所示,左上角显示的“Pred”指的是预测的当前帧的行为,“FPS”指的是实时帧率,下面的数字“18.34”指的是两耳中心点相对于上一帧的运动距离。

图11 小鼠实时行为识别Fig.11 Mouse real-time behavior recognition
3 结论
针对当前大部分动物行为分析方法由于计算量大、模型复杂导致不能做到实时分析的问题,本文提出了一种改进YOLO5Face 的小鼠行为实时分析方法。本文提出的方法分为两个步骤:小鼠关键点实时检测和小鼠行为实时识别。针对小鼠关键点实时检测,在深度学习网络YOLO5Face 的基础上改进,新增了一个更小的检测头、加入C2f 模块以及引入GSConv 和Slim-neck,改进后的模型测试集精度达到了97.5%,推理速度为79 f/s,精度和实时帧率均高于DeepLabCut 模型的性能。针对小鼠行为实时识别:在本文改进的关键点检测模型的基础上,将体态特征与运动特征相结合构建小鼠行为识别数据集,使用训练和推理过程分开的机器学习算法SVM 进行实时行为分类,对梳洗、直立、静止、行走四种基本行为的平均识别准确率达到了91.93%。将关键点检测代码与行为识别代码拼接之后,整个模型运行的实时帧率可以达到35 f/s。
