基于内-外部互补先验的亚像素分辨率衍射成像算法研究
2023-08-21石保顺吴一凡练秋生
石保顺,吴一凡,练秋生,∗
(1.燕山大学 信息科学与工程学院,河北 秦皇岛 066004;2.燕山大学 河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004)
0 引言
衍射成像作为相位恢复的一个特例,其研究最早可追溯到20 世纪40 年代。Gabor 利用参考信号线性化相位恢复问题,并因此获得了1971 年诺贝尔物理奖。20 世纪 50 年代, Karle 和Hauptman 对二进制原子晶体的衍射成像做出了重大贡献,于1985 年获得了诺贝尔化学奖。Eric Betzig、Stefan W.Hell 和William E.Moerner 为打破衍射极限的高分辨率荧光显微镜的研发做出了重要贡献,于2014 年获得诺贝尔化学奖。高分辨率衍射成像引起了清华大学戴琼海院士课题组[1]、曹良才课题组[2]和深圳大学屈军乐课题组[3]的高度重视。他们的研究成果将高分辨率成像带入了一个新纪元。亚像素分辨率衍射成像(Sub-pixel Resolution Diffraction Imaging,SRDI)旨在利用计算成像技术突破观测设备像素大小对成像分辨率的限制进行高(超)分辨率衍射成像,该技术成为了突破衍射极限分辨率的重要手段。现有亚像素分辨率衍射成像方法可分为以下几大类:传统像素分辨率衍射成像方法[4-9]、基于亚像素间距(Subpixel-pitch)平移的方法[11-12]、基于多波长的波长扫描方法[13-14]、基于多距离衍射成像的方法[15-17]和基于稀疏性的方法[18-24]。
理论上,传统像素分辨率衍射成像算法可通过调整非线性采样算子或建立合适的优化模型用于亚像素分辨率衍射成像。在一些成像领域,例如同轴数字全息成像,亚像素分辨率成像方法首先利用拼接法、内插法或外推法获得高分辨率衍射强度图样[4],然后直接采用像素分辨率衍射成像算法进行高分辨率图像重建。按照不同的模型、数值求解方法及利用先验知识的方式,大致可将现有像素分辨率衍射成像算法分为以下几大类:交替投影方法、基于最小二乘估计的方法及基于正则化的方法。交替投影法, 例如 GS(Gerchberg Saxton)算法[5],通常寻找同时满足测量域约束集合(幅值或强度值约束集合)和图像空域约束集合的交集。该方法简单、有效,但容易陷入停滞状态。基于最小二乘估计的衍射成像算法,例如WF (Wirtinger Flow)算法[6],通常构造最小二乘估计问题,然后利用梯度下降方法对该问题进行求解。基于最小二乘估计的衍射成像算法在理论上有严格的证明保证收敛性,但重建高质量图像所需的衍射强度图样数量多。为解决该问题,基于正则化的衍射成像方法通过正则化模型将图像先验引入到图像重建中[7-11]。该类方法首先融合数据保真项与蕴含图像先验的正则项构建衍射成像优化模型,然后利用优化方法对所对应的问题进行求解。Tillmann 等人[7]利用盲字典学习框架进行衍射成像,重建性能优于未利用任何先验知识的WF 算法。天津师范大学的常慧宾[8]课题组利用全变差(Total Variation,TV)正则化针对被泊松噪声污染的测量数据进行衍射成像,实验表明了TV 正则化模型的有效性。Shi 等人[9]构建了一个可学习实例自适应和空间变化阈值函数的深度收缩对偶框架网络正则化项,并提出了一种用于衍射成像的深度展开方法,实现了低信噪比下高质量重建。同时Shi 等人[10]利用基于加权l1范数的卷积稀疏编码模型以及深度展开技术构建了一个模型架构可解释的先验模块,基于该模块构建了一个模型驱动的相位恢复网络。上述方法虽然给亚像素分辨率衍射成像提供了思路并且可作为亚像素分辨率衍射成像方法的一部分,但并未直接给出具体的亚像素分辨率衍射成像算法。
基于亚像素间距平移的方法是通过对光源或样本进行亚像素间距平移,获取多幅低分辨率衍射强度图样,并利用这些衍射强度图样进行高分辨率成像。该类方法最早可追溯到Ozcan[12]课题组对无透镜片上数字同轴全息成像系统的研究。他们发现全息图并不能无限增大,通过增大全息图提升分辨率的方法受到了限制。为突破该限制,Ozcan 等人利用小孔在二维平面进行亚像素间距平移并记录多幅低分辨率全息图以获取更多关于原始图像的信息。实验表明,通过多幅低分辨率全息图利用像素超分辨率方法能够达到亚微米分辨率成像。Ozcan 课题组首次将亚像素的概念引入到无透镜片上成像系统中,并提出了具体的亚像素分辨率衍射成像方法。基于亚像素间距平移的成像方法[13]通常包含以下几步:记录多幅低分辨率衍射强度图样、重建高分辨率衍射强度图样及图像再现。重建高分辨率衍射强度图样通常融合数据保真项和对高频成分施加约束的惩罚项构建优化模型。该优化模型可直接求解或迭代求解。图像再现步骤通常利用基于角谱、菲涅尔变换的反向传播技术或传统衍射成像方法重建图像。基于多波长的波长扫描方法[14-15]首先通过窄光谱带选择或压缩侧照明获取不同波长的光波,然后利用这些光波多角度依次照明样本并记录多幅衍射强度图样。该方法与基于亚像素间距平移的方法相比,需要较少的测量数据就能够进行高分辨率成像且不需要亚像素间距平移。基于多距离衍射成像的方法是在观测设备和样本的不同距离上记录多幅衍射强度图样,利用亚像素分辨率衍射成像技术重构高分辨率图像[16-18]。该类方法引起了哈尔滨工业大学的刘正君[17-18]课题组的重视,该课题组提出了对噪声鲁棒的亚像素分辨率衍射成像方法。
上述基于亚像素间距平移、多波长、多距离的方法大都通过构建的光学系统记录多幅衍射强度图样以进行亚像素分辨率衍射成像,但并未考虑图像的先验知识,成像质量和成像分辨率仍有提升空间。基于稀疏性的方法利用稀疏先验进行亚像素分辨率衍射成像。Song 等人利用l0伪范数衡量图像的空域稀疏性,在无透镜数字同轴全息系统下实现了超分辨率因子为3 的亚像素分辨率衍射成像。Fournier 等人[19]以l1范数衡量图像空域稀疏性提出了基于反问题求解的亚像素分辨率成像算法,实验结果表明该算法能够重建高分辨率图像且能够减小孪生像及边界效应的影响。上述算法仅利用了图像的空域稀疏性,然而,多数图像本身并不是稀疏的,而是在某种字典或稀疏变换下是稀疏的,故上述算法应用有限。基于变分模型,Vladimir Katkovnik[20-22]课题组利用图像在BM3D ( Block matching and 3D collaborative filtering)框架下的稀疏性提出了亚像素分辨率衍射成像算法SR-SPAR。该方法通过含泊松噪声的相位编码衍射图样交替进行菲涅尔幅值约束和BM3D 滤波,实验证实其重建质量优于SR-GS 算法(根据GS 算法改编的亚像素分辨率成像算法)。上述方法通过薄透镜和空间光调制器对观测图像进行相位编码,硬件复杂度高。随后,他们舍弃了薄透镜,直接利用空间光调制器对观测图像进行孔径相位编码,并通过角谱变换建模光波传播过程,实现了超分辨率因子为4 的亚像素分辨率成像。在低信噪比情况下,该算法仍然能够高质量成像[22]。SR-SPAR 算法构建的数据保真函数是非平滑的,算法收敛性难以保证。为解决该问题,Bacca 等人[23]对数据保真函数进行了平滑处理,利用TV 正则项构建了成像模型。实验表明,在超分辨率因子为4 时,Bacca 等人的算法成像质量优于SR-SPAR 算法。Gao 等人[24]以WF 框架为基础引入Nesterov 动量用以加速算法收敛,提出了AWFTV 算法,并利用梯度稀疏性重建图像。该算法在保证重建质量的同时减少了测量数据,加快了收敛速度。上述利用稀疏先验进行亚像素分辨率衍射成像的算法是通过解析方法构建的先验模型,难以充分描述所有图像的统计分布信息。为解决该问题,Shi 等人[25]提出了融合深度去噪器先验的稀疏表示正则化模型,有效提高了亚像素分辨率衍射成像的成像质量及分辨率,并通过实验证明了深度去噪器先验在实图像上亚像素分辨率衍射成像的有效性。
为提高亚像素分辨率衍射成像的成像质量及分辨率,现有亚像素分辨率衍射成像方法大多是利用图像固有的先验知识设计或学习正则项来约束重建过程。基于图像内部先验的方法利用待重建图像本身的先验信息,如空域稀疏性、梯度稀疏性及非局部相似性等,忽视了图像之间普遍存在的外部先验信息,即通过外部数据集学习到的先验。基于图像间共有外部先验的方法例如基于深度卷积网络的成像方法,通常需要大量难以获取的高分辨率图像进行训练,且存在泛化能力较差的问题。为弥补这些不足,本文将能够利用图像非局部相似性的BM3D 框架与能够捕获外部先验特征的深度卷积稀疏编码模型相结合,提出了一种面向复图像的亚像素分辨率衍射成像算法,简称SRDI-doubleR。理论上该方法能够利用内部先验与外部先验的互补性进行衍射成像,进而提升重建复图像过程中伪影去除和细节保留能力。与现有亚像素分辨率衍射成像相比,本文提出的算法有望重建出更高分辨率、更高质量且具有更多细节的复图像。
1 亚像素分辨率衍射成像
亚像素分辨率衍射成像旨在从记录的低分辨率衍射图样中恢复高分辨率图像。图1 给出了亚像素分辨率衍射成像的示意图。在物体平面上,连续物体由大小为Δo×Δo的像素离散化。与传感器的固定像素大小Δs×Δs相反,物体的像素大小Δo是可计算的。当Δo<Δs时,从观测数据中恢复具有小像素尺寸的物体,该成像过程称为亚像素分辨率衍射成像。一束相干光照射物体,经光学系统调制后到达传感器平面,此衍射过程可通过角谱法计算的线性变换过程进行建模。入射光到达传感器平面后,入射到同一像素上的所有光子都被转换成单个强度信号,在数学上,强度信号可以被认为是对应子像素信号的加权和。在超分辨率因子为2 的情况下,物体的像素尺寸是传感器像素尺寸的2 倍,物体的像素数是传感器像素数的4 倍,经传感器采样获得低分辨率衍射图案的像素值是对应4 个子像素值的总和。理论上,亚像素分辨率衍射成像采样模型可以建模为

图1 亚像素分辨率衍射成像说明图Fig.1 Subpixel resolution diffraction imaging figure
其中,x=|x|exp(j∠x)∈Cn表示观测样本的复透射率即待重建复图像,|x|∈Rn和∠x∈Rn分别表示x的振幅和相位图像。n表示加性高斯白噪声对应的向量,Aℓ∈Cm×n表示L个采样矩阵构成的集合中第ℓ个采样矩阵,yℓ∈Rd表示传感器采集到的衍射强度图样。S∈Rd×m表示传感器像素的下采样算子,其中m=Υd,Υ表示下采样因子。|·|及下文中均表示逐元素运算符。
根据最大后验概率准则,从低分辨率衍射强度图样y中重建观测样本x的优化模型可表示为
式中,第一项为数据保真度项,由于低阶振幅的数据保真度函数更有利于加快算法收敛,且文献[26]验证了利用低阶保真度函数作为亚像素分辨率相位恢复中数据保真度函数的优越性能,本文构建的数据保真度项保证重建振幅图样逼近观测振幅图样。第二项为正则化项,可通过该项引入图像的先验知识,λ为正则化参数用以平衡数据保真项和正则化项的比重。
式(2)定义的优化问题可采用近端梯度算法进行求解,但由于近端梯度算法收敛较慢,AWFTV算法引入Nesterov 动量项加速算法收敛。具体迭代步骤如下(以第t次迭代为例):
其中,∇F(·)为数据保真函数的Wirtinger 梯度,∊为步长。AWFTV 框架根据Nesterov 方法令动量项的参数βt=t/(t+3);u(0)=x(0)。prox(·)为邻近算子,其定义为
其中,TV(·)表示TV正则化项。
当式(6)中λ=0 时,则为AWF 算法。该算法较AWFTV 算法缺少正则项约束,未能利用图像的梯度稀疏先验知识,因此其重建质量通常较低。
2 融合内-外部互补先验的亚像素分辨率衍射成像算法
2.1 基于BM3D 框架的表示模型
BM3D 算法[27]是利用图像自身冗余信息进行去噪的非局部算法,过程主要分为三个步骤:
1) 分组:将输入图像分成大小相同的块,通过块间欧式距离在邻域内搜索参考块的相似块并将参考块与相似块堆叠成三维数组,构造若干三维数组。
2) 协同滤波:对三维数组经变换后的系数矩阵进行硬阈值滤波。
3) 合成:对滤波后的频谱进行反演,计算每个块的估计值并将图像块放回原始位置,利用加权平均值得到最终重建图像。
BM3D 算法的过程可通过框架表示[28],其解析框架表示模型为
其中,w为表示系数,B表示相似块组成的组数。解析算子Ψb定义为
其中,Jb={jb,1,…,jb,K}表示第b组中图像块索引的集合,每组中图像块的总数为K。dj表示1D 块间变换D1的第j列,D2表示1D 块内变换,Bj表示整个图像的取块算子。估计图像由组估计中块的加权平均值获得,权重为gb。与上述推导类似,综合框架模型可表示为
针对实值图像x的去噪问题,BM3D 去噪框架可描述为
其中,Hσ表示阈值为噪声标准差σ的硬阈值算子。
本文根据上述表示模型,利用BM3D 的解析框架构建正则化模型以利用图像的非局部相似性。本文将基于复图像x内部块相似性先验的正则项定义为
其中,λ表示正则化参数。
2.2 基于外部先验的卷积稀疏编码正则化模型
深度展开卷积稀疏编码是将传统卷积稀疏编码迭代过程展开成深度神经网络,其优化模型可表示为
其中,D表示卷积字典,α表示对应的表示系数,γ表示正则化因子。φ(·)表示α的稀疏惩罚函数,通常采用‖·‖0或‖·‖1衡量稀疏性。上式中,,∗表示二维卷积算子,C表示通道数。
式(13)中第一项为图像在卷积字典下的表示误差,第二项是对表示系数进行稀疏约束的正则项。传统方法通常通过交替优化方法求解上述优化问题,即卷积稀疏编码步骤和卷积字典更新步骤交替进行。深度卷积稀疏编码将上述交替迭代的过程展开成网络,卷积字典和超参数均通过端到端的方式进行学习。学习过程中,代表N个训练样本对,xi代表噪声图像,代表干净图像。式(13)可表示为双层优化问题
其中,L(:,:)表示损失函数,σi表示xi的噪声水平。式(14)约束项定义的优化问题可以通过ISTA 迭代求解:
其中,S表示收缩(Shrinkage)函数,λ,η表示超参数,rot180(D)表示D旋转180°。现有的深度展开方法通过两个DNN 模块来参数化α和D以构建网络架构。然而参数化两个独立的卷积模型违反了数学约束(rot180(D)和D满足转置约束),背离了卷积字典的物理意义。此外,参数化一个通用字典D来表示所有图像,削弱了图像表示的灵活性。为解决上述深度展开卷积稀疏编码的局限性,文献[29]提出了一种新的深度展开框架,即DCDicL 算法。该算法针对每张图像采用自适应的字典,从大量数据中学习字典D并求解表示系数α,其优化模型为
将上式转化为双层优化问题
DCDicL 方法通过求解式(17)的约束项对应的优化问题,并将求解的迭代过程展开成网络。网络训练过程中,损失函数定义为式(17)中所对应的代价函数, 并采用基于梯度的 ADAM(Adaptive moment estimation)方法[30]对待学习的网络参数θ进行更新。为分离式为求解式(17)中的约束项对应的优化问题,引入辅助变量D′和α′,转化为求解以下两个优化问题:
展开的每个阶段中数据项α′和D′的子问题通过闭式解求得,将先验项α和D的子问题看作两个邻近算子,通过两个网络近似求解,最终自适应的获得每个图像的α和D估计。
根据上述深度展开卷积稀疏编码模型,本文采用经DCDicL 算法事先训练好的深度展开的卷积字典表示图像,并将复图像基于深度展开卷积稀疏编码的正则化项表示为
其中,α1和α2表示振幅和相位图像的表示系数,β表示控制振幅图像和相位图像表示误差比重的正则化参数,γ1和γ2用以控制稀疏正则项的比重。
2.3 优化模型
为提升亚像素分辨率衍射成像的重建质量,充分挖掘图像固有先验,本文结合基于BM3D 框架的内部先验与基于深度展开卷积稀疏编码模型的外部先验,构建能够融合内部和外部先验的优化模型
其中,λ1和β1表示控制内部先验和外部先验比重的正则化参数。式中第一项为用以保证重建图像与测量数据相匹配的数据保真项,第二项和第三项分别表示基于BM3D 算法框架与基于深度展开卷积稀疏编码模型的正则化项,二者的结合以充分挖掘图像固有先验信息。
2.4 模型求解
由于式(21)中每一项均包含变量x,引入辅助变量u,v用以去耦合,将其转化为
采用半二次分裂方法对上式进行求解,即
具体迭代步骤如下(对于第t次迭代)
1) 更新图像x
采用梯度下降方法对式(24)定义的优化问题进行求解,代价函数的Wirtinger 梯度可表示为
因此式(24)中复图像x(t)更新为
其中,τ表示步长。
2) 更新辅助变量u
其中λ2=λ1λ。求解过程在将复图像x,u的振幅和相位视为单独变量,式(27)可分解为以下两个优化问题
上述两个优化问题在数学上难于精确求解,本文中将式(28)~(29)看作两个邻近算子采用BM3D 去噪器进行近似求解[22],即
其中,σ1,σ2分别表示输入的振幅和相位图像的噪声标准差。
3) 更新变量α1,α2,v
固定变量x(t)、u(t),更新辅助变量α1,α2,v的优化问题为
其中,β2=β1β。
对复图像v的振幅和相位分别进行求解,将式(32)分解为以下两个优化问题:
式(33)~(34)求解过程类似,为简化推导,以式(33)为例。将式(33)分解为优化α1和|v|的两个优化模型
求解式(35)是典型的卷积稀疏编码问题,本文采用DCDicL 算法训练好的深度卷积字典进行卷积稀疏编码,的求解过程采用DCDicL 算法中表示系数的求解方法。要获得式(36)的最优解,∠x(t)与∠v(t-1)需相等,因此将该式化简为
对式(37)代价函数中|v|求导,并令其导数为零,最终获得|v(t)|的闭式解为
更新辅助变量v的相位∠v过程与更新振幅|v|的过程同理,∠v(t)的闭式解为
通过交替更新图像x、辅助变量u、表示系数α1,α2和辅助变量v求解式(21)定义的优化问题能够获得满意解。SRDI-doubleR 算法具体实现步骤如下:
输入:测试数据y,循环迭代次数Iiter,每次循环中梯度下降迭代次数kk
1:初始化xinit
2:fort=1:Iiter
3: fork=1:kk
4: 根据x(t,k)=x(t-1,k)-τ∇f(x(t-1,k))更新复图像x
5: end
6:根据|u(t)| =ΨBM3D(|x(t)|,σ1) 和∠u(t)=ΨBM3D(∠x(t),σ2) ,利用BM3D 去噪器更新辅助变量u
7:利用DCDicL 算法训练好的深度卷积字典更新α1和α2
8:根据式(38)、(39)关于|v(t)|和∠v(t)的闭式解更新辅助变量v
10:end
输出:重建振幅图像|x|和相位图像∠x
3 结果与讨论
本文采用文献[26]中基于相位调制分集的全息成像系统,其采样模型yℓ=S|Aℓx|2+n中采样矩阵Aℓ=QHMℓ,Mℓ∈Cn×n表示通过SLM 仅进行相位调制的算子、H∈Cn×n表示自由空间传播算子和Q∈Cm×n表示图像裁剪算子,用以模拟传感器空间大小的约束过程。所有实验均采用随机初始值,随机种子固定。本文采用峰值信噪比(Peak Signal to Noise Ratio, PSNR)、结构相似性(Structure Similarity Index Measure, SSIM)和均方根误差(Root Mean Square Error, RMSE)作为客观指标。PSNR 值越高,说明图像重建质量越高;SSIM 值越高,说明两幅图像相似程度越高;RMSE值越低,说明重建图像与原始图像偏差越小。所有实验均在Intel Core i9-10850K@3.60 GHz、内存64GB、NVIDIA GTX 3080 Ti GPU 平台运行。
3.1 仿真实验

图2 测试图像Fig.2 Test images
3.1.1 内-外部先验对重建结果影响分析
为验证内-外部先验融合的有效性,本节利用SRDI-doubleR、SRDI-BM3D 和SRDI-DCDicL 算法进行亚像素分辨率衍射成像实验并对比其实验结果。图3 给出了测试图像在L=8,Υ=2×2 情况下三种算法重建复图像的平均PSNR 和SSIM 值的比较,从图中可以看出SRDI-doubleR 算法的平均PSNR 和SSIM 值在振幅和相位图像上均高于基于内部先验的SRDI-BM3D 算法和基于外部先验的SRDI-DCDicL 算法,说明了本文算法融合内部和外部先验的有效性。
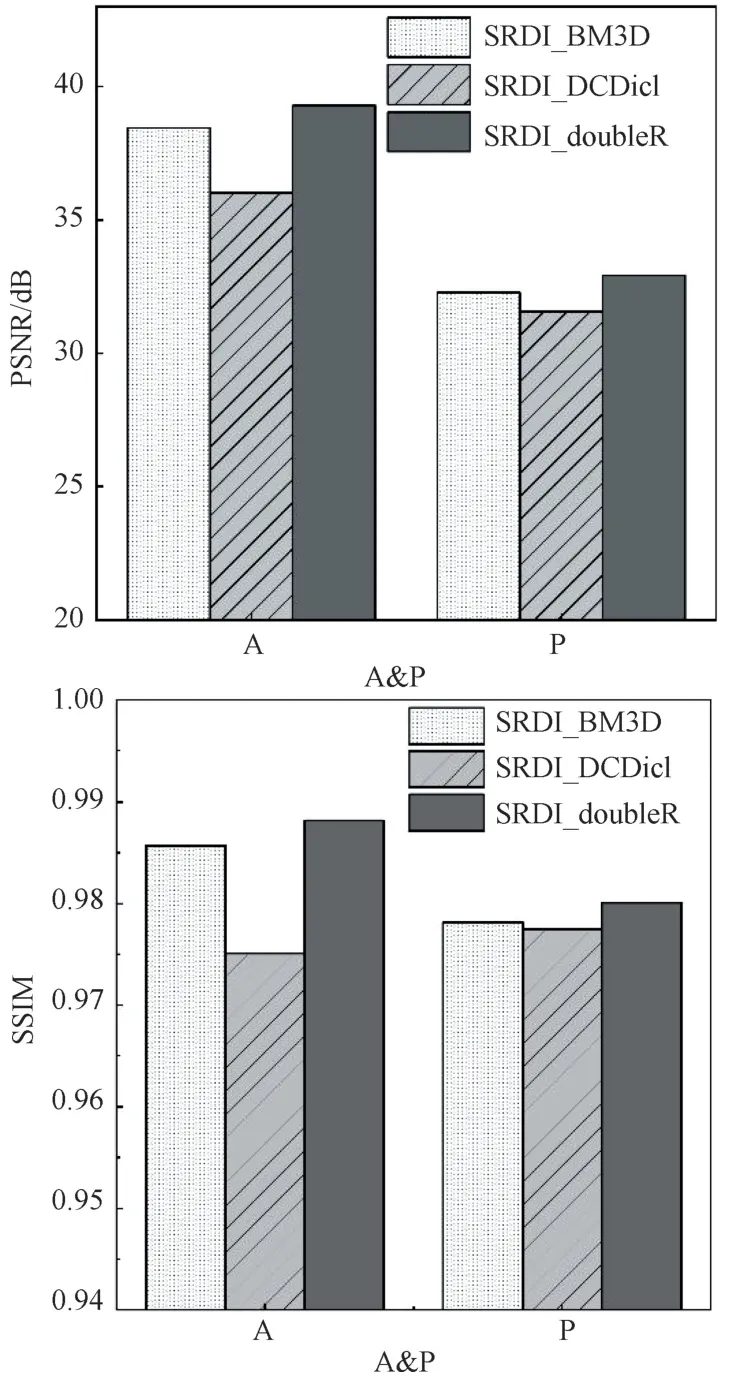
图3 L=8,Υ=2×2 情况下不同算法平均PSNR 和SSIM 值比较Fig.3 Comparison of average PSNR and SSIM values for different algorithms in the case of L=8,Υ=2×2
3.1.2 不同采样因子重建结果对比
为验证本文算法的有效性,本节针对不同采样因子情况,比较本文SRDI-doubleR 算法与AWF、AWFTV[24]、DIPTV[31]、PatchNRTV[32]算法重建复图像的性能。针对不同采样因子SRDIdoubleR 算法的参数通过经验调整设置,迭代次数设置为300 次,每次迭代中梯度下降次数设为10次,其他参数设置如表1 所示。本文通过小波域估计算法[33]对噪声标准差进行估计,采用与文献[20]输入噪声标准差相同的计算方式,即估计标准差乘以常数,CA和CP分别表示振幅和相位图像估计标准差所乘常数。

表1 SRDI-doubleR 算法参数设置Tab.1 Parameter settings of the SRDI-doubleR algorithm
表2 中给出了不同算法在Υ=2×2 及Υ=4×4两种情况下重建三组复图像的振幅和相位图像的PSNR、SSIM 和RMES 值。由表2 可知,本文所提出算法在不同采样因子下PSNR、SSIM 和RMSE值均明显高于对比算法。AWF 算法未能充分利用图像固有先验信息,重建性能较差,AWFTV 算法较AWF 算法充分利用了图像的梯度稀疏先验,重建性能具有显著提升。DIPTV 和PatchNRTV 算法属于无监督方法,重建性能比AWFTV 算法较差。本文算法通过融合内部与外部互补先验知识,充分挖掘编码衍射强度图样中的信息,重建复图像的性能较AWFTV 算法具有显著提升。
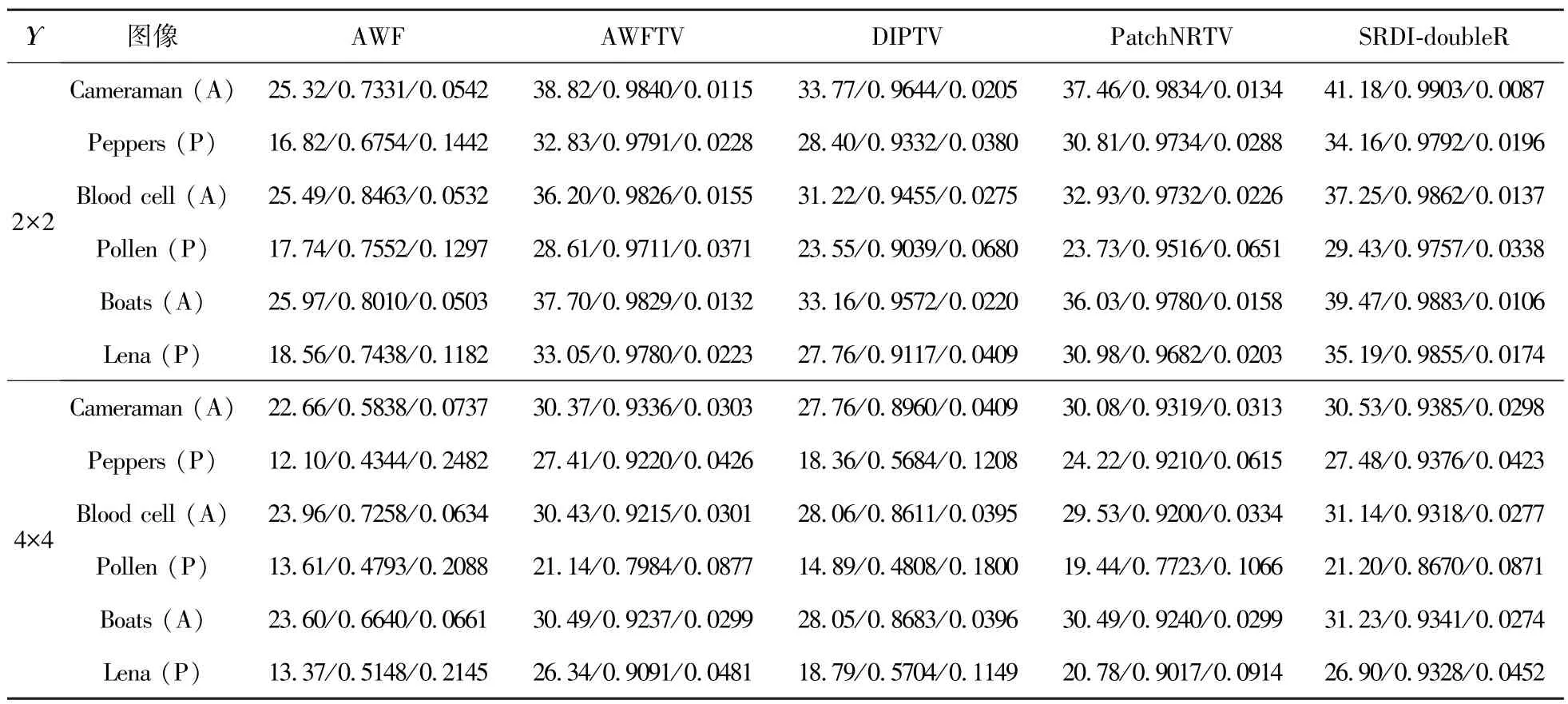
表2 Υ=2×2 和Υ=4×4 情况下不同算法重建图像PSNR、SSIM 和RMSE 值的比较Tab.2 Comparison of PSNR,SSIM and RMSE values of images reconstructed by different algorithms in the case of Υ=2×2 and Υ=4×4
为进一步说明算法的有效性,图4 展示了采样因子Υ= 4×4 时,不同算法重建Cameraman-Peppers 复图像的视觉效果及部分放大效果图。由重建图像及放大部分可以看出,AWF 算法重建效果较差,重构的振幅及相位图像均存在大量伪影并且细节大量缺失,重建的Peppers 图像伪影和模糊较为明显;DIPTV 算法也存在较多的伪影,在重建的相位图像中伪影较多;PatchNRTV 算法重建的复图像存在少量伪影,去伪影能力优于AWF算法和DIPTV 算法,但在重建过程中仍缺失部分细节信息;AWFTV 算法重建复图像整体效果优于AWF、DIPTV 和PatchNRTV 算法,但也存在少量的伪影及细节信息的缺失;本文提出的SRDIdoubleR 算法重建复图像视觉效果较好,能够消除伪影并且重建出了更多的细节信息。

图4 Υ=4×4 情况下不同算法重建Cameraman (A)-Peppers (P)图像的对比Fig.4 Comparison of different algorithms to reconstruct Cameraman (A)-Peppers (P) images in the case of Υ=4×4
3.1.3 不同编码衍射图样数量重建结果对比
本文针对不同编码衍射图样数量情况,将本文SRDI-doubleR 算法与AWFTV 算法重建复图像的性能进行比较。图5 给出了两种算法在下采样因子Υ=2×2 为时L分别为4、8、16、32 情况下重建复图像的PSNR 值曲线图。从图中可以明显看出两种算法重建振幅图像和相位图像时随着编码衍射图样数量的增加,重建效果显著增强。在Cameraman-Peppers 和Boats-Lena 两组复图像的重建过程中,SRDI-doubleR 算法重建的振幅图像和相位图像的PSNR 值均比AWFTV 算法高2~3 dB左右,Blood cell-Pollen 复图像在L= 4、8、16 情况下SRDI-doubleR 算法重建的振幅和相位图像的PSNR 值高于AWFTV 算法的PSNR 值,在L= 32时AWFTV 算法重建的振幅和相位图像的PSNR值略优于SRDI-doubleR 算法。

图5 不同L 情况下SRDI-doubleR 与AWFTV 算法重建复图像PSNR 值比较Fig.5 Comparison the PSNR values of complex images reconstructions with the SRDI-doubleR and AWFTV algorithms under different L conditions
3.2 物理实验
为验证算法在实际数据中的性能,本文采用由全息成像系统[24]获得的实际低分辨率衍射强度图样测试本文算法,系统配置的详细描述可参考文献[34]。上采样率设置为Υ=2×2,分别选取张编码强度图样,图6 给出了AWF、AWFTV 及SRDI-doubleR 算法重建相位型鉴别率板实际数据的效果图。由于成像系统建模误差不可避免,且实验发现算法在实际数据中更容易收敛,因此上述三种算法的循环迭代次数较仿真实验均减少10倍。从图6 中可以看出随着编码衍射强度图样数量的增加重建质量不断提升,SRDI-doubleR 算法较AWF 和AWFTV 算法伪影减少,重建出了更多的高频细节信息。在光学实验中,伪影不仅源于测量噪声,而且源于成像系统的建模误差,这些误差在实际应用中是不可避免的[24]。
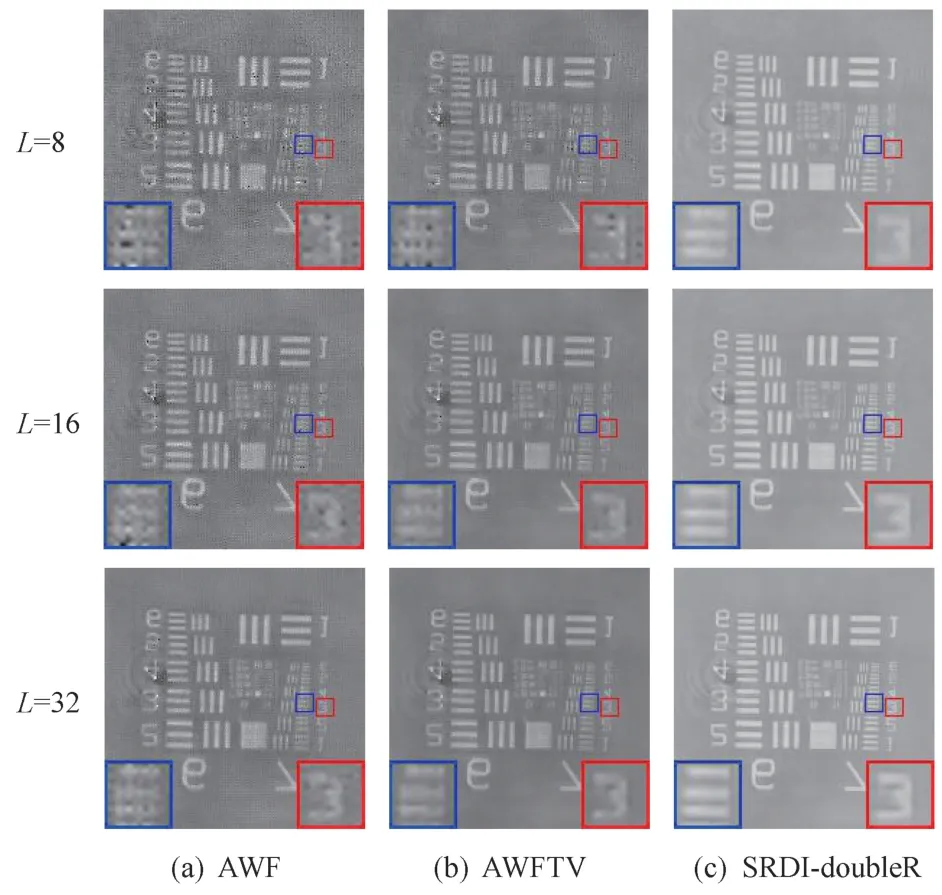
图6 重建相位型鉴别率板实际数据的效果图对比.Fig.6 Comparison of renderings reconstructed the actual data about the phase type discrimination rate plate
4 结论
本文利用基于内部先验的BM3D 框架与基于外部先验的深度展开卷积稀疏编码模型构建了一种能融合内-外部互补先验的正则化模型,并将其用于亚像素分辨率衍射成像。该算法能够有效融合内部与外部互补先验知识,利用少量编码衍射图像对复图像进行重建,实验结果表明该算法在仿真数据中重建复图像的质量优于现有亚像素分辨率衍射成像。将该算法用于无透镜片上显微镜的实际数据中,该算法较利用梯度稀疏性的AWFTV 算法能够重建出更多的高频细节信息。
