基于多尺度复合卷积和图像分割融合的车道线检测算法
2023-08-21方遒李伟林梁卓凡陈韬阳
方遒,李伟林,梁卓凡,陈韬阳
(1.厦门理工学院 福建省客车先进设计与制造重点实验室,福建,厦门 361024;2.厦门大学 航空航天学院,福建,厦门 361005)
随着人们对汽车需求的提高和人工智能技术的快速发展,高级驾驶辅助系统(advanced driver assistance system, ADAS)得到了快速的发展[1−2].ADAS 包括了自适应巡航、车道偏移报警、车道保持、碰撞避免等功能[3].车道线检测作为ADAS 获取外界信息的基本步骤之一,在其中发挥着至关重要的作用.一个准确且可靠的车道线检测方法可以帮助轨迹规划[4]、行为决策等其他模块做出正确的决策[5].
当前的车道线检测方法大致可以分为两类:一类是基于传统机器视觉的车道线检测方法,另外一类基于深度学习的车道线检测方法.
传统的方法主要通过提取人为设计的特征来检测车道线.常用的特征有边缘特征[6−8]、颜色特征[9−11]、消失点特征[12−14]等.此外,在车道线模型的选择上也可以分为直线模型[15−16]、曲线模型[17]、混合模型[18−20]等.人为设计的特征和模型作为检测的基础虽然更加符合人类的视觉感受,但是对于以计算机为基础的计算机视觉往往不是最优解.当面对复杂环境比如遮挡、车道线缺失、光照不均匀等时,传统视觉方法往往无法稳定正确地检测出车道线.
基于深度学习的车道线检测方法主要通过卷积神经网络来提取特征并进行识别.不同于传统方法的是,其特征设计是由机器学习得来的,而非人为设计.这样学习得到的特征更容易达到计算机视觉提取信息的目的.
一些学者将机器学习和传统图像处理想结合,希望能够将两者的优点结合.LI 等[21]对图像进行预处理,然后通过CZF-VPGNet 网络检测预处理后图像中的车道线.PIZZATI 等[22]选择ERFNet 作为第一个网络来获得车道线的实例分割图像,然后通过第二个CNN 网络来检测人为设计好的不同大小的描述符来对车道线进行分类.LI 等[23]通过LPU 单元以线路建议作为参考来定位准确的交通曲线,迫使系统学习整个交通线路的全局特征表示.这些方法在使用深度学习进行信息处理的同时保留了部分人为干预在其中,人为设计因素对网络输出结果影响较大.
LaneNet[24]提出将车道线检测问题转化为实例分割问题.通过将车道线检测问题转化为实例分割问题,不仅摆脱了人为设计特征的限制,而且使车道线检测网络可以参考较为成熟的实例分割领域的网络.在其基础上,GUO 等[25]引入双注意力机制来增强车道线特征的表示,ZHANG 等[26]利用ResNeSt 提出的分离注意力机制改进了车道标线的细长和稀疏的特征,可以检测没有数量限制的车道.尽管与其他成熟网络结构相结合带来了车道线检测效果的提升,但是依然无法达到车道线检测的要求.SCNN[27]提出一种新的图像信息传递方式,使信息不仅可以在一般深度学习的层与层之间传递,也可以在行与行、列与列之间传递.该方法网络结构充分考虑了车道线在图像中的特点,但是网络运行速度缓慢,对设备要求严格.PINet[28]结合关键点检测与点云实例分割的方法成功实现了新的车道线处理算法,可适用于任意场景、检测任意数量的车道线.通过统一全部通道数使参数量大大减小,将特征提取模块设计为可选个数的沙漏模块,使其在不同计算能力的设备上可以选择最符合需求的模型.
近年来,相较于同样参数的一般卷积,可以在不增加运算时间的同时根据需求扩大感受野的空洞卷积被大量使用.DING 等[29]以VGG16 网络为基础,通过空洞卷积代替最后三个卷积层提取车道线特征,以计数器池的方式对编码器进行上采样,实现语义分割,最终实现实例分割和虚实识别.LIU 等[30]将空间卷积和空洞卷积组合成信息交换块,增强像素之间的信息传递,更有效地利用垂直空间特征,更好地检测被遮挡的车道线,提高了算法的稳健性.CAI等[31]为解决目标像素数和背景像素数的不平衡的问题,通过合理组合感受野提取特征,避免图像过度分段的同时减少了环境的干扰,并为其提出了专门的评分机制.但是,这些空洞卷积在这些网络中的应用效果并不理想.这是因为,当为了获取更大感受野而选取较大空洞率时,卷积核每个计算点之间的距离会变得过大,从而导致对空间信息的利用效果下降.而在车道线检测中,网络往往需要较大的感受野才能高效率的提取其特征信息.
基于以上情况,提出一种基于多尺度复合卷积和图像分割融合的车道线检测算法.所使用的网络在下采样后使用多尺度复合卷积提取特征并在之后通过图像分割融合模块增强全局特征.结合空洞卷积、全卷积和标准卷积得到的多尺度复合卷积可以在更大感受野上有效地利用图像信息.引入语义分割分支的图像分割融合模块提高实例分割网络的全局信息利用.在CULane 数据集中的实验表明:本文算法相比现有算法做出了一定的改进,评价指标得到提高.
1 本文算法
本节概述了使用多尺度复合卷积获取更大感受野的车道线检测神经网络.网络整体结构如图1 所示,网络整体流程如图2 所示,网络的整体框架由4部分组成,包括下采样模块、多尺度复合卷积模块、图像分割融合模块和解码器模块.下采样模块将图像的特征信息进行压缩,降低后续网络的计算量.网络采用主流方式的下采样方式,即卷积层后接最大池化层的方式.网络一共对图像进行4 次压缩,即采用4 个下采样模块,每个模块按照信息压缩的需求配置不同层数的卷积层和最大池化层.多尺度复合卷积模块对下采样后的图像进行进一步的特征提取,为了进一步提高精度,将2 个复合卷积模块串联.多尺度复合卷积模块有5 个分支,每个分支提取不同大小的特征.图像分割融合模块利用语义分割分支辅助实例分割分支,从而提高最终实例分割的效果.上采用模块采用转置卷积层和普通卷积层结合的方式实现.相比下采样阶段,上采样阶段使用更少的卷积层,以提高网络的运行速度.网络对图像进行实例分割,不仅区分图像中每个像素属于车道线还是背景,而且将每个车道线像素归类到具体每条车道线所属的类别中.根据所使用的数据集的图像标记,本文算法最多同时可检测到4 条车道线,这足够应对大多数行车环境.网络各层输入输出如表1 所示.

表1 网络各层输入输出Tab.1 Input and output of each layer of the network

图1 网络整体结构Fig.1 Overall structure of the network

图2 算法整体流程Fig.2 Overall process of algorithm
1.1 多尺度复合卷积模块
特征金字塔作为一种提取大范围特征信息的手段被许多车道线检测网络使用.在特征金字塔中,通过组合不同空洞率的卷积层来达到获取不同尺度的特征.由于空洞率过大时候容易导致提取信息松散、特征提取差的情况,特征金字塔无法采取太大的空洞率而选择增加卷积层数的方法来提取特征.但这也导致了网络参数增加、网络结构加深,使得网络更加复杂和难以训练.
从特征金字塔的应用可以看出,不同局域之间的局部特征和图像整体的全局特征之间的信息传递有助于实例分割的实现.一个有利于更大范围的局部特征和全局特征融合的网络是有必要的.为了能够在更大范围上应用空洞卷积,而且避免信息的丢失,本文提出一种多尺度复合卷积.此结构不同于特征金字塔,为了拓展特征提取的感知领域,在网络中的多种尺度的空洞卷积后面均再进行额外的卷积.与特征金字塔相比,多尺度复合卷积可以在更大尺度上进行特征提取,有效地收集不同层次的特征信息.
多尺度复合卷积的原理如图3 所示,相较于一般的空洞卷积在扩张后造成卷积位置信息的分散,多尺度复合卷积在空洞卷积后首先通过一次全卷积对不同通道的信息进行整合,然后根据扩张的比例在卷积位置再进行一次标准卷积,弥补空间信息的丢失.在网络的构建中,为了更有效地提取信息并且防止卷积层之间的信息冗余,各个复合卷积层的第一层空洞率和第三层卷积尺寸均有不同的组合.

图3 各卷积原理图Fig.3 Schematic diagram of each convolution
如图3(a)所示,一个标准3×3 卷积具有3×3 的感受野和9 个参数.如图3(b)所示,一个尺寸为3×3、空洞率为4 的空洞卷积具有9×9 的感受野和9 个参数.当空洞率为1 时,空洞卷积退化为标准卷积.如图3(c)所示,一个全卷积具有1×1 的感受野和1 个参数.感受野计算公式如式(1)所示
式中:W和H分别为卷积核的宽和高;R为空洞率.W和H一般取相同的数值,这样方便计算且更加符合人们的直观感受.
多尺度复合卷积效果如图4 所示,在图像进行空洞卷积之后再进行一次全卷积和标准卷积.由于第一次卷积后的每个像素实际上提取了卷积前3×3像素的信息,全卷积不改变信息范围,因此进行第三次卷积时,感受野相对于卷积前图像为11×11.在获取相同11×11 感受野的情况下,空洞卷积的卷积核尺寸为3×3、空洞率为5,虽然相比多尺度复合卷积计算更快,但是提取到的信息密度大幅度下降;标准卷积的卷积核尺寸为11×11,具有最高的信息密度,但是其参数量和计算量远远大于多尺度复合卷积.本文网络多尺度复合卷积模块的参数如图5 所示,其中每个分支采用不同空洞卷积和标准卷积的组合,空洞卷积的空洞率和标志卷积的尺寸决定提取特征的大小和主要效果,空洞卷积的尺寸均为3×3.网络使用两个多尺度复合卷积模块提高效率.

图4 复合卷积原理图Fig.4 Composite convolution schematic diagram
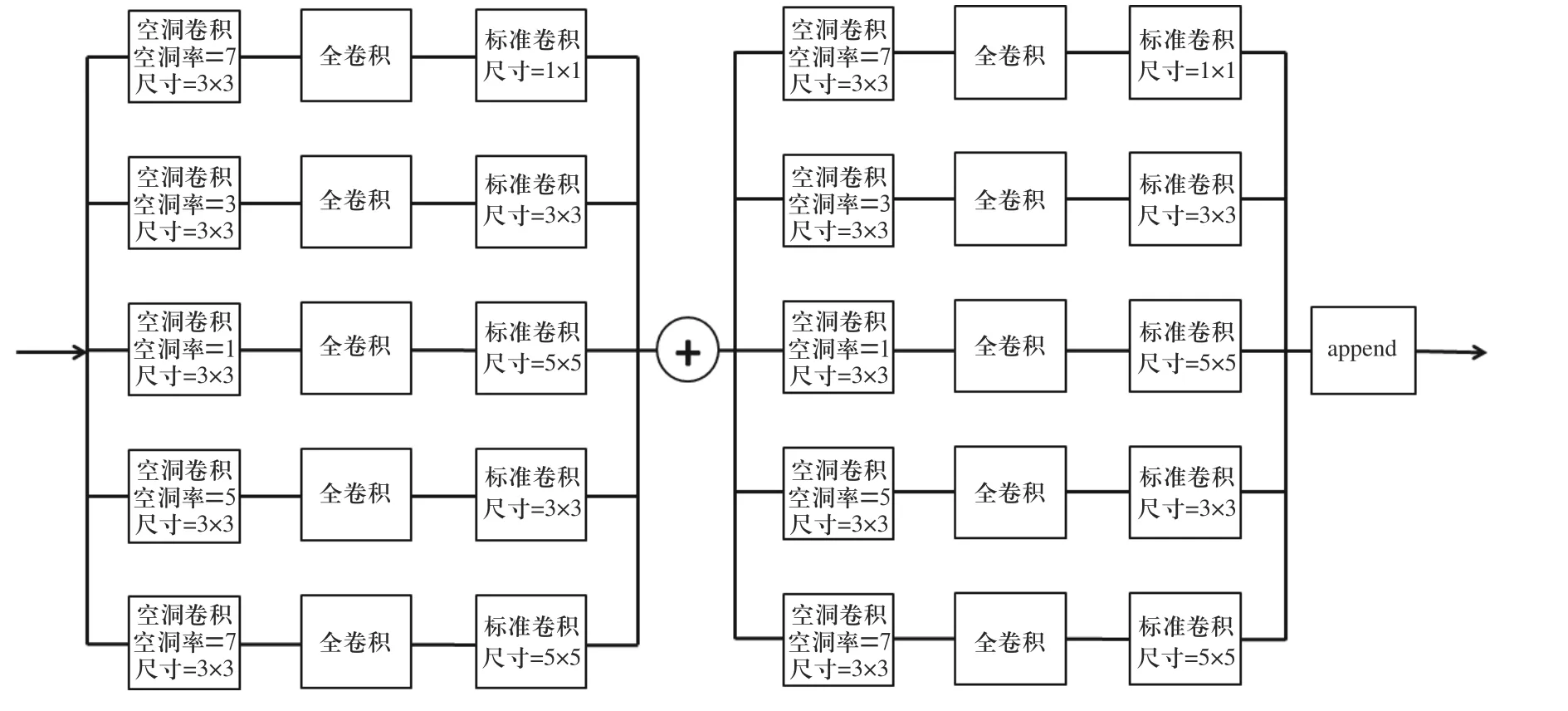
图5 多尺度复合卷积模块Fig.5 Multiscale composite convolution module
1.2 图像分割融合模块
在文献[31] 中,将车道线检测任务分为语义分割任务和实例分割任务,并由网络分别输出两者的检测结果.这是因为相比实例分割而言,将图像视为语义分割任务(车道线和背景)更为简单,并且容易取得良好的效果.但是这样人为的将检测任务分为两个不同的任务反而加大网络的训练难度.因此,在文献[32]中,将车道线检测任务直接视为实例分割任务,并将每个输出通道视为一类.这样设计网络简化了解码器结构,但是将一个输出通道视为一个类别使得每个通道更加关心自己的所属类别而减少了对全局信息的关注,这对车道线检测来说是不利的.
图像分割融合模块结构如图6 所示.全连接层对多尺度复合卷积模块输出的图像特征信息进行分类后分别给出实例分割分支和语义分割分支的特征图像,两者与跳跃分支拼接后输入解码器中.实例分割分支和语义分割分支的特征图像分别经过一次双线性插值调整到与真值图相同尺寸,并各自通过一次卷积调整通道后计算损失函数.在车道线检测中,漏检和误检往往是由于在解码器初始阶段全局信息的缺失,引入的语义分割图像相比实例分割图像更加注重全局特征,可以有效改善该情况.

图6 图像分割融合模块Fig.6 Image segmentation fusion module
1.3 损失函数的设计
网络的训练就是根据损失函数对预测结果和真值的差距对参数进行更新,因此损失函数的选择对网络的训练至关重要.本文网络将车道线检测任务视为实例分割任务,因此选择实例分割任务中常用的交叉熵作为损失函数.
在网络的预测图像中,每个像素包含5 个通道,分别代表该像素属于背景和4 条车道线的置信度.为了得到每个像素上预测的类别序号,首先对预测图像使用softmax 函数使像素各类别的置信度归一化到区间[0,1] 且和为1,然后对该维度进行max 运算选取置信度最大的类别序号作为预测类别
式中:Ti为某个输出分支的真值图的像素:Ci为该分支置信度图像的像素;yi为像素所属类别.
在许多网络设计中,往往单独计算解码器最终输出的预测图像和真值图像之间的损失函数.然而,这无法对解码器其他尺寸的预测图像进行有效的反馈,使得网络在其他同尺寸上对车道线的预测偏离真值.为了提高网络对各尺度车道线的预测效果并对图像分割融合模块进行监督.本文选择一个权值交叉熵损失函数
式中:wi和li分别为各实例分割分支的权值和交叉熵损失;wc和lc分别为语义分割分支的权值和交叉熵损失;lall为网络总的交叉熵损失.该方法可以有效地提高反卷积层对车道线的复现能力,并充分考虑语义分割分支所体现的全局特征信息,特别是在第一层反卷积层中更好地定位到各条车道线的位置,降低了小尺度上的特征遗漏导致的最终车道线的漏检率和过度拟合导致的误检率.
2 实验结果
2.1 数据集
车道线检测常用到的公开数据集有TuSimple 数据集和CULane 数据集.其中TuSimple 数据集包括3 626 张带注释的训练图片和2 782 张测试图片.这些图片是在交通量很少且车道标记透明的受限场景下拍摄的,且未标记磨损和被阻挡的车道线.同时由于图片数量的限制,其区分不同网络性能的能力不足.因此本文选择数据量更大,更富有挑战性的CULane 数据集.
CULane 数据集由安装在6 辆由北京不同驾驶员驾驶的不同车辆上的摄像头收集的.其收集了超过55 h 的视频,并提取了133 235 帧.数据集分为88 880张训练集图片,9 675 张验证集图片和34 680 张测试集图片,分为Noramal 和8 个具有挑战性的类别:Crowd、Dazzle、Shadow、No Line、Arrow、Curve、Cross和Night,每个场景的比例如图7 所示.对于每一帧,CULane 数据集使用三次样条曲线手动注释行车道,当车道标记被车辆遮挡或看不见时,会根据上下文将车道线从消失位置一直标记到图像最下方.数据集默认图片分辨率为1 640×590,这样扁长的图片来源于车载的广角摄像头,但这对于深度学习是不利的.因此,本文在将图片输入网络前,对图片进行了尺寸的调整和像素数值的归一化.

图7 CULane 数据集比例Fig.7 CULane dataset scale
2.2 评价标准
在车道线检测中,车道线的漏检和误检是造成事故的重要原因,也是人们关心的算法指标.通常在目标检测任务中,采用准确率和召回率作为评价车道线检测模型的指标.在车道线检测任务中,准确率反映了漏检车道线的占比,召回率反映了误检车道线的占比,但是这些单个指标不能综合地体现出模型的好坏.因此,为了更好地对我们的模型做出评价,并方便与其他研究者的工作进行对比,本文选择CULane 官方提供的评价标准F1measure.另外,为了提高最终的评价指标,LaneNet 通过传统图像算法对网络输出的图像进行后续处理[24].但是,这样不能客观地评价网络的性能,因此在后续性能比较中,本文网络输出的图像不进行后续处理.
式中:T/F表示真/假,表示预测是否正确;P/N表示正/负,表示预测结果为正或负;γ的值设置为1.当预测图像与真值图像的交并比(intersection over union,IOU)大于阈值时,判断为TP,否则为FP.IOU 阈值通常选取0.3 或0.5.
2.3 本文算法不同性能指标
选取更大的IOU 阈值可以获取质量更好的预测图像,但是也容易将图像判定为假.如图8 所示,图中用不同颜色标记了检测到的车道线,当选取IOU阈值为0.5 时,黄色车道线由于被前车遮挡导致检测效果不佳而被判为FP,而当选取IOU 阈值为0.3 时,其依然可以判为TP.从表2 可以看出,当选取0.3 作为阈值时,本文算法的整体F1measure高于选取0.5 作为阈值.但是为了获取更高的图像质量和方便与其他算法进行比较,后续实验均选取0.5 作为阈值.

表2 算法不同性能指标Tab.2 Different performance indicators of the algorithm

图8 算法检测结果Fig.8 Algorithm detection results
2.4 算法整体检测结果比较
本文提出的算法通过与其他算法比较在CULane 数据集上的F1measure值来验证其有效性.表3 展现了本文算法与LaneNet[24]、DeepLabV2[33]、ResNet-101[34]、Res34-VP[35]、Res101-SAD[36]和SCNN[27]算 法的比较结果[32−36].实验结果表明,本文算法在整体性能上优于其他比较算法.在多种路况中,由于引入多尺度复合卷积和图像分割融合模块提取更大范围的信息,检测结果有明显提升,整体的F1measure达到74.9%,运行时间达到22.3 ms.在Noramal、Crowd、Dazzle、No Line、Cross 场景和Total 中均优于其他对比算法.

表3 算法整体比较结果Tab.3 Overall comparison results of algorithms
2.5 不同场景检测结果比较
图9 给出了在多种困难场景下网络的检测结果,图中用4 种颜色标记了检测到的车道线,图片每行按照Normal、Crowd、Dazzle、Shadow、No Line、Arrow、Curve、Cross 和Night 顺序排列,第1 列为输入图像,第2 列为预测图像,第3 列为真值图像.以上测试结果可以看出,本文算法在多种困难场景下均可有效检测出图片中的车道线,无论是Noramal 场景中还是在挑战性条件下.本文提出的车道线检测算法在Dazzle、Shadow 和Arrow 等带有强烈环境干扰的场景中可以克服环境的干扰,在图像中提取和识别到车道线的正确特征并检测出正确的车道线位置.在Crowd、No Line 和Night 等车道线缺失、被遮挡等场景中可以做出一定的逻辑推理,准确找到图像中待检车道线的位置.在需要检测曲线段的Curve 场景中,网络可以将斜率较大部分视为曲线进行检测,将斜率较小的部分仍然视为直线,最终检测出车道线的正确位置.在没有车道线的Arrow 场景中,虽然图像中经常会出现明显的线段(比如人行横道等),但是该线段并非需要检测的车道线类别,需要网络对其进行判断.从图中可知,本文提出的车道线检测网络在Arrow 场景中可以正确地将错误线段排除出车道线类别,没有在图片中误检出车道线.

图9 不同场景检测结果比较Fig.9 Comparison of detection results in different scenarios
2.6 各分支输出分析
图10 分别列出了输入图像(图10(a))、真值图像(图10(b))、语义分割图像(图10(c))和各实例分割图像(图10(d)~图10(h),各已转换为概率灰度图方便显示.由图10 可知,第一张实例分割图像(图10(d))更加注重车道线的局部特征,但也因此减少了对全局信息的关注而容易误检.语义分割图像(图10(c))相比实例分割图像更加注重车道线整体与背景的关系.图像分割融合模块(图10(e))将两者和跳跃分支的信息融合,后续上采样模块结合跳跃分支给出的信息逐步提高预测图像的分辨率和准确率,最终输出网络预测的车道线实例分割图像.

图10 各分支输出分析Fig.10 Output analysis of each branch
3 结 论
在本文中,为了扩大网络的感受野和弥补大空洞率造成的信息丢失,提出了一种多尺度复合卷积;为了进一步加强全局信息的利用设计了语义分割和实例分割信息融合的图像分割融合模块;为了在不同尺度上拟合真值图像,并对各分支进行训练,提出了一个权值交叉熵损失函数.
实验结果表明,在CULane 数据集上,本文算法无论是在整体性能上,还是在单独一个场景中相比其他算法均有不错的表现.数据集整体F1measure达到74.9%,在多个场景应用中相比其他对比算法取得最优表现.因此,本文提出的方法可以为车道线检测的应用提供参考.
在未来的工作中,希望可以采用更好的设备来提高网络的训练速度和优化网络的参数,以达到提升车道线检测准确性和速度的目的.同时探索更大的空洞率的可能性及其对网络造成的影响.
