智能网联汽车基于逆强化学习的轨迹规划优化机制研究
2023-08-21彭浩楠唐明环查奇文王聪王伟达
彭浩楠,唐明环,查奇文,王聪,王伟达
(1.中国工业互联网研究院,北京 100102;2.北京理工大学 机械与车辆学院,北京 100081)
轨迹规划模块的作用是为智能网联汽车计算出包含路径和速度信息的安全可行轨迹,规划过程需要考虑车辆行驶安全性、稳定性、舒适性以及行驶效率等[1].目前已有许多关于自动驾驶轨迹规划的研究,典型轨迹规划方法主要可以分为3 类:包括模型预测控制方法、人工势场法等的基于优化计算的轨迹规划;包括栅格法、随机搜索法等的基于搜索的规划方法;基于特定函数的轨迹规划方法[2].近年来,人工智能为自动驾驶规划控制提供了变革性发展契机.基于智能学习算法的轨迹规划方法逐渐成为智能网联汽车决策控制领域的研究热点.
其中,包括各种群类算法如鱼群、蚁群、粒子群,遗传算法,神经网络等[3−4]的智能学习算法可解决非线性规划问题,有不过分依赖物理模型、适用范围广、易于进行移植、收敛速度较快的优点,但同时存在陷入局部最优的弊端.在模仿经验驾驶员的模型预测(model predictive control, MPC)优化轨迹规划方法中,各个优化目标函数的权重系数需要手动反复标定.在不同的复杂动态环境中,权重系数标定是一个重复且繁琐耗时的过程,并且需要丰富的驾驶经验[5].更重要地,基于非线性MPC 的优化轨迹规划方法的求解计算量和预测步长Np成指数关系,即MPC 方法的求解计算量会随着预测步长的升高成指数增长,还要处理各种约束,所以求解计算量非常巨大,实时性很差[6].
随着人工智能技术、大数据以及高算力计算硬件的逐步发展,各种学习类算法也被用于解决轨迹规划问题,主要包括模仿学习算法(imitation learning algorithms, LL)和强化学习算法(reinforcement learning algorithms, RL)两大类.有学者采用深度强化学习算法[7−8]和Q-Learning 强化学习算法[9−10]解决轨迹规划问题,不同类型的学习算法以各自不同的方式学习最优轨迹.但是,一方面,直接模仿学习方法的神经网络训练过程在可解释性和泛化能力上存在不足,另一方面,奖励函数设计是强化学习方法的瓶颈难题.如何使上述学习方法学习后的模型具有强泛化能力,解决当前研究成果在实时性和可解释性上的问题值得深入研究.目前也有很多研究文献聚焦于采用模仿学习算法解决轨迹规划问题,通过以不同的形式学习专家示范轨迹以实现期望轨迹的规划,包括基于神经网络的直接模仿学习方法[11]和基于最大熵原则的逆强化学习算法[12−14]等.
为了解决算法实时性差、目标函数权重系数难以标定优化和模仿学习方法的可解释性不足等问题,本文提出了基于最大熵原则的逆强化学习方法,通过学习专家轨迹的内在优化机制,规划出符合人类驾驶习惯的整体最优的换道轨迹.本文提出的方法通过最大熵原则求出专家轨迹的概率分布模型,再通过极大似然估计得到专家轨迹特征优化权重参数的计算方法,通过迭代求出优化权重参数,达到最终学习轨迹特征与专家轨迹特征相匹配的综合最优效果.
1 双车道交通场景描述与换道动机
1.1 场景描述
本文所研究的交通场景是自动驾驶汽车在城市结构化道路中典型的双车道交通工况,自动驾驶汽车(自车)行驶在双车道的右车道上,在此车道上自车前后方各有前车1 和尾车2 向前行驶,相邻车道上也有前车3 和尾车4 向前行驶.
如图1 所示,左车道为快车道,自车所在车道为慢车道.自车在慢车道上跟随前车1 进行自适应巡航行驶.假设某一时刻慢车道上前车1 突然减速,自车则也会相应地减速行驶,当前车1 减速至速度很低时,自车开始产生自主换道意图,欲换道跟随前车3 从而实现高速巡航行驶.此时自车需要根据当前量测到的场景参数—TTC(碰撞时间)和THW(车头时距),采用贝叶斯概率理论对相邻待换车道和本车道进行安全性风险评估,得到当前场景每个车道的安全性条件概率,然后根据安全效用做出相应的行为决策,选择保持该车道继续行驶或更换车道.如果待换车道很危险,自车选择保持该车道继续行驶,直到待换车道尾车4 超过自车,新的尾车4 出现,此时自车再重新对两个车道进行风险评估.当自车做出更换车道的行为决策,发出换道指令时,自车采用相应的方法进行轨迹规划,得到最优换道轨迹.
1.2 决策方法
针对此双车道交通场景,可采用基于贝叶斯概率理论的风险评估方法和基于安全效用理论的行为决策方法,构建易于扩展到一般复杂场景的风险评估贝叶斯网络和决策图[15].该方法充分考虑了场景输入量测数据的不确定性,对当前交通场景的换道风险等级做出了定量化的概率描述.
2 基于最大熵原则的逆强化学习方法
近年来,随着人工智能技术的发展,利用逆强化学习方法从专家示范数据集中自动学习获取代价函数的研究获得了自动驾驶汽车领域的广泛关注.自动驾驶汽车的轨迹规划必须达到经验驾驶员水平,实现安全决策和规划.如何设计合适奖励函数来指导智能体做出类优秀驾驶员驾驶策略,即强化学习方法中的奖励函数是一项非常有挑战性的问题.因此,本文设计让智能体从优秀驾驶员的驾驶行为里面学习(估计、推导)出一个可以指导智能体收敛到优秀驾驶员的行驶策略的代价函数,即通过逆强化学习方法学出专家轨迹的内在优化机制.
本文采用基于最大熵原则的逆强化学习方法来学习专家轨迹的优化机制,专家轨迹由模仿优秀驾驶员的MPC 优化轨迹规划方法求得,验证逆强化学习方法实现自动驾驶汽车轨迹规划的可行性,为自动驾驶汽车实现轨迹规划提供一个可靠、可理解、可泛化,能够成功实现最优换道轨迹的学习思路,实现采用逆强化学习方法离线学习驾驶员专家轨迹的优化机制,进而构建与场景风险等级成映射关系的专家轨迹优化代价函数库.
利用直接模仿学习方法可以直接学习得出专家示范轨迹的策略函数,即利用神经网络训练环境特征到动作(最优轨迹)的映射.但是由于优化代价函数(奖励函数)未知,黑箱的训练过程无法直观理解,此方法存在可解释性差、无法泛化转移、存在失误率的问题.与直接模仿学习方法相比,逆强化学习方法的优点在于:
① 简洁:通过逆强化学习方法能够获得优化代价函数,此代价函数体现了专家轨迹的优化机制,这一优化机制可以量化且直观得被工程师所理解,所以代价函数是描述智能体理想行为的简洁形式,可解释性强.而策略函数(特征到动作的映射)和代价函数相比则更为复杂,工程师无法直观量化地理解训练过程,可解释性差.
② 鲁棒:通过基于神经网络训练的直接模仿学习方法得到的动作容易受到外部干扰的影响.当外部环境和内部参数发生变化时,特征到动作的映射也会变化,但是代价函数始终不会发生变化,不会受到外部的影响.因此与策略函数相比,逆强化学习方法学出的优化代价函数更具有鲁棒性.
③ 可泛化转移:通过逆强化学习方法学得的优化代价函数,体现了专家轨迹的优化目标,在当前风险等级场景下,优秀驾驶员的优化目标不会发生变化.因此,此优化代价函数可以用于各类车型,是可泛化转移的.
逆强化学习方法试图恢复并获得智能体在专家示范行为背后偏好(优化机制)的过程.这种偏好(优化机制)通常以代价函数或奖励函数的形式表现出来,代价函数与奖励函数将每个系统状态的特征映射为一个状态成本值.逆强化学习中的代价函数与特征之间的映射关系可能是线性、非线性或者神经网络.本节与大多数逆强化学习方法一样,假设特征与代价函数之间成线性映射关系,此线性关系可以表示为
式中:C为优化代价函数;θ ∈Rn是用来参数化代价函数的特征权重向量;fξi∈Rn定义为对给定轨迹的某些抽象信息进行编码量化的相关特征,ξi为某个给定的轨迹.在本文讨论的换道轨迹规划问题中,这种轨迹特征包括目标横向位置、纵向巡航速度、横向速度、纵横向加速度等.基于以上定义,逆强化学习方法的目标可以描述为:给定智能体的专家示范轨迹,找到能够再现与专家示范轨迹相似的轨迹的优化代价函数,即每个轨迹特征的权重系数,与专家示范轨迹相似的轨迹可以通过求解基于权重系数的参数化代价函数的优化问题获得.具体目标为找到智能体所学轨迹的概率分布,使得由此推导出的轨迹特征值与专家示范轨迹的经验特征值相匹配:
2.1 最大熵原则
熵是一个描述物质系统状态很重要的参量.通过研究最大熵原理,斯坦福大学和加州大学伯克利分校学者ZIEBART 等[16]和LIU 等[17]指出,熵最大的概率分布最好地代表了给定的专家示范信息,因为除了特征匹配之外,它没有表现出任何其他额外的偏好.通俗地讲,所学习轨迹的概率分布的熵越大,系统越稳定,熵最大,系统最好.根据定义,关于轨迹概率分布的熵H(p)为
在连续空间中,如本文所考虑的轨迹规划问题,专家选择某条轨迹是随机概率分布事件,极大化系统的熵可以求得期望的专家轨迹概率分布模型p∗(ξi)为
特征匹配是重要的等式约束,如下所示.
式(4)和(5)所示为标准的含约束的拉格朗日优化问题.引入拉格朗日乘子 α∗,θ∗,该问题为
其中 θ的维数为轨迹特征的个数.引入拉格朗日函数L(p)为
求解偏导数方程:
则专家轨迹的概率分布模型的表达式为
可以看出,由最大熵原则推导出的概率分布模型中,如果把 θTfξi解释为代价函数,专家轨迹的概率分布模型表达式p(ξi|θ)与相关特征的代价函数的指数成正比.这个概率分布模型中的超参数为 θ.所以根据最大熵原理,这个概率分布模型意味着:代价函数成本值越高的轨迹是更不可能出现的,专家选择的概率越低,随着代价函数成本值升高,概率成指数函数降低,换言之,智能体模仿学习专家轨迹时以指数形式的可能性更倾向于选择代价函数成本值低的轨迹.
又根据式(4),可得
则概率分布模型的分母表达式为
最终,可以得到期望的专家轨迹概率分布模型为
其中,Z(θ)为概率分布模型的归一化(配分)因子.
然后,引入极大似然估计方法来获取上述概率分布模型中超参数的计算表达式.用已有的专家采样数据,即给定的专家示范轨迹进行极大似然估计,极大化专家的似然求出概率分布模型中的超参数 θ.使得专家轨迹的似然最大,也就是使得已有的专家轨迹数据最真实.这样求得的 θ参数值能够保证专家轨迹的出现概率最大.所以,特征匹配下的轨迹分布熵最大化问题就转化为了在上述指数概率分布模型下,专家轨迹的极大似然估计问题.
在轨迹规划问题中,规划出的轨迹是关于横坐标、纵坐标和速度的三维函数,即专家轨迹是蕴含时间信息的.因为轨迹上每一点的速度都是随机的,所以专家轨迹样本集个数为无数条,假设专家轨迹样本集个数为N条,则专家示范轨迹的样本集可以表示为,i=N.为专家示范轨迹样本集中的轨迹.
定义专家轨迹的似然函数,即联合概率密度函数为
式中:l(θ) 为专家轨迹的似然函数;p(D|θ)为专家轨迹的联合概率密度函数.极大化似然函数l(θ),即可求出模型超参数 θˆ值,使得出现该组样本的概率最大.
定义专家轨迹的对数似然函数为W(θˆ),表达式如下.
式(17)中的归一化配分因子Z(θ)也可以采用积分的方式表示.利用专家轨迹样本集试验结果和极大似然估计方法得到的参数值,能够使专家轨迹样本集出现的可能性最大.
2.2 配分因子的近似和优化权重参数的计算
根据上述分析和公式(17))可知,极大化专家轨迹似然的过程中,如何计算归一化(配分)因子Z(θ)是该方法的难点所在.由于所有轨迹在高维空间上积分是不可处理的,即在连续状态下,无法对全轨迹进行积分,因此无法计算得到精确的配分因子Z(θ)[18−19].只能采用二阶泰勒展开/拉布拉斯近似、蒙特卡洛采样和一次轨迹样条代替等方式进行配分因子 的近似计算.基于二阶泰勒展开/拉布拉斯近似的优化权重参数最优解法理论性较强,试图一次性求解出优化权重参数 θ,但此方法的代码实现较为困难,很难一步到位求出最优解.所以本节不采用此种方法求解 θ.
本文采用基于一次轨迹样条近似代替的梯度下降方法,迭代求解出优化权重参数 θ,直至智能体最终的学习轨迹特征与专家轨迹特征相匹配.
如上所述,采用最大熵原理推导出专家轨迹的指数概率分布模型之后,可以采用极大似然估计方法得到概率分布模型中的超参数:
专家轨迹的似然函数关于优化权重参数 θ的梯度可以被推导为
所以专家轨迹的似然函数关于优化权重参数θ的梯度表达式为
式中:fD为专家示范轨迹特征值的均值,fD≜[fξˆd1+fξˆd2+···+fξˆdN]/N.ξ˜i为专家用当前的优化权重参数 θ在优化一个代价函数得到一条当前最有可能出现的最优轨迹.
与文献[20]类似,利用逆最优控制的思想:专家用当前自己的优化权重参数 θ在刻意优化一个代价函数得到一条当前最有可能出现的最优轨迹 ξ˜i(此时专家不是在概率分布模型中随机采样),假设此条轨迹的概率近似为1.通过计算当前这条最有可能出现的轨迹的特征值来近似代替期望特征值,即用一次轨迹样条进行近似代替,而不是计算采样出的有限条轨迹的特征值.利用一次轨迹样条方法进行近似代替可以表示为
因此,用一次轨迹样条方法进行近似代替后的专家轨迹似然函数关于优化权重参数的梯度表达式就变成了
f′即为最有可能出现的轨迹的特征值.当然,如前所述,本文假设智能体模仿专家选择的轨迹实际上是通过最小化当前的代价函数而产生的,而不是假设专家选择的轨迹是从概率分布中抽样的.所以,基于一次轨迹样条近似代替的优化权重参数梯度下降迭代公式为
式 中:θk+1为 迭代更新 后 的优化权重 参 数值;θk为专家当前的优化权重参数值;α为学习参数值:梯度下降速度.
每次梯度下降迭代后,都会得到一个新的优化权重参数向量,之后即可得到新的优化代价函数,得到的由优化权重参数构成的优化代价函数能够让工程师直观地、量化地理解当前的内在优化机制和原则,即在换道场景中专家轨迹究竟更在意哪些优化目标,在意到什么程度.逆强化学习方法的内层一定要有一个优化的过程,所以得到新的优化权重参数和优化代价函数之后,需要求解这个很简单的最优问题.通过求解此优化代价函数,得到几个优化的学习轨迹离散点坐标(本文为6 个),也可以说是,通过优化几个轨迹离散点的坐标使优化代价函数极小化.
2.3 三次样条插值方法和特征的提取
求解由当前优化权重参数构成的优化代价函数,得到时间间隔T/5的6 个最优离散点坐标,假定被学习的专家轨迹总的时间间隔为T.为了提取学习轨迹的相关特征,在本文中,对6 个优化后的等时间间距离散坐标点采用3 次样条插值方法进行插值获得轨迹的3 次样条函数.本文用3 次样条函数来表示随时间t变化的换道轨迹横向位置y和纵向位置x.
采用3 次样条插值法得到轨迹的3 次样条函数之后,即可提取当前轨迹的相关特征,当前的这条轨迹为智能体用迭代更新得到的当前优化权重参数 θ,极小化相应的优化代价函数得到的轨迹.本文提取一些典型的轨迹特征,这些特征能够反映换道轨迹的相关重要特性,包括汽车期望横向位置特征(式(24))ftar(ξ)、汽车 期 望 纵向巡航速度 特 征(式(25))fvx(ξ)、以及汽车横向速度(式(26))、纵向加速度(式(27))和横向加速度(式(28))等高阶动力学特征fvy(ξ)、fax(ξ)、fay(ξ).
式中:ytarget为目标车道中心线的横向位置;vxdes为换道结束后跟随快车道上的前车的期望巡航纵向速度.最后的轨迹特征fξi可以通过组合以上这些子特征得到.本文从当前轨迹中提取这5 个特征,与从专家轨迹中提取的这5 个特征做匹配、做比较,分别判断当前轨迹的5个特征是否和专家轨迹的5个特征近似相同,ε为特征差阈值常数.如果两者不匹配、不相同,则根据公式(23)迭代更新求出横向或纵向的每个特征对应的新的优化权重参数 θ1,θ2,θ3和θ4,θ5,构成新的优化代价函数,如式(29)所示,优化求解出新的轨迹,提取新的轨迹特征,重复以上过程,直至智能体当前轨迹的特征与专家轨迹的特征相匹配,即近似相同,最终迭代求出的此时的优化权重参数 θ*为可以复现专家轨迹的最优优化权重参数.
在逆强化学习方法中,采用基于一次轨迹样条近似代替的梯度下降迭代法求解最优优化权重参数θˆ的算法过程可用以下伪代码表示.轨迹的3 个横向相关特征和两个纵向相关特征对应的优化权重参数分别按照以下过程进行求解.
算法1 逆强化学习方法(基于一次轨迹样条代替近似的梯度下降迭代法)

其中,Ω为轨迹支撑点的集合,grad为特征差梯度.基于一次轨迹样条近似代替的梯度下降迭代方法按照“优化一次、插值一次、匹配一次、迭代一次”4 步的总体思路实现逆强化学习方法的过程,直至求出最终的优化权重参数与相应的轨迹,此方法可操作性强,选用此方法复现专家轨迹.
3 专家轨迹逆强化学习仿真结果
MPC 优化轨迹规划方法的优化机制符合人类驾驶经验和习惯[21−22].本文将利用模仿优秀驾驶员的MPC 优化轨迹规划方法求出的一般风险场景和高风险场景的自车最优换道轨迹作为一般风险场景和高风险场景两个场景的专家示范轨迹.一般风险场景和高风险场景的自车最优换道轨迹,即文献[15]在一般风险场景和高风险场景中采用非线性MPC 优化轨迹规划方法求解出的最优轨迹.模仿优秀驾驶员的基于非线性MPC 的优化轨迹规划方法的软约束为优化目标势场函数,考虑了自车换道位置准确性、安全性、动力性、舒适性等优化目标,硬约束包含等式约束—二自由度汽车运动学方程和防碰撞安全域不等式约束.在汽车运动学方程模型中,汽车的轴距为1.8 m.
一般风险场景中,周车1 和2 的车速都为15 m/s,自车和周车4 的车速都为16 m/s,周车3 的车速为20 m/s.以自车的起始位置为纵向坐标原点,自车纵向坐标为0 m.周车1 和周车3 的起始位置坐标为100 m,周车2 和周车4 的起始位置坐标为−80 m.在高风险场景中,周车1 和2 的车速都为15 m/s,周车3 和周车4 的车速分别为20 m/s 和17 m/s,自车的车速为16 m/s.以自车的起始位置为纵向坐标原点.周车1 和周车3 的起始位置坐标为100 m,周车2 和周车4 的起始位置坐标分别为−80 m 和−58 m.一般风险场景和高风险场景的区别在于自车相邻车道上的尾车4 的速度和起始位置不同.尾车4 的车速越高,与自车的纵向距离越近,自车的换道风险越高;反之,尾车4 的车速越低,与自车的纵向距离越远,自车的换道风险越低.
通过基于MATLAB 的仿真,验证所提出的逆强化学习方法学习两个场景中专家轨迹的能力.
3.1 一般风险场景专家轨迹的逆强化学习结果
为学习此一般风险场景的专家轨迹,选取初始优化权重参数 θ0,期望横向位置、横向速度、横向加速度、期望纵向巡航速度、纵向加速度这5 个特征的初始值依次为:0.01、1、10、20、1.图2 为自车期望横向位置、横向速度、横向加速度的逆强化学习结果.图3(a) 为逆强化学习过程中智能体学习得到的每条轨迹的横向相关特征值与专家轨迹横向相关特征值之差范数的迭代演化,如式(30)所示.
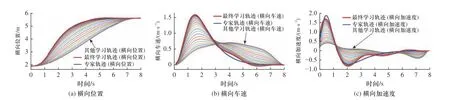
图2 一般风险场景期望横向位置、速度、加速度的逆强化学习结果Fig.2 IRL results of lateral position, speed, and acceleration in the general-risk scenario
从图3 可以看出,在一般风险场景中,初始优化权重参数经优化插值生成的横向学习轨迹(自车的横向位置坐标、横向速度和横向加速度3 组曲线)与横向专家轨迹差别较大,初始轨迹的横向相关特征值与专家轨迹横向相关特征值之差的范数比较大(不到500),初始轨迹横向位置特征值与专家轨迹横向位置特征值之差稍大于20,横向速度特征值之差也存在.智能体按照基于一次轨迹样条代替近似的梯度下降迭代方法进行逆强化学习,不断迭代更新优化权重参数,共迭代了60 次,智能体每次学习得到的轨迹也和专家轨迹越来越相似,智能体学习得到的轨迹横向相关特征值与专家轨迹横向相关特征值的差值也逐渐减小,迭代至20 次时,特征差基本收敛至0.优化参数迭代更新至60 次时,经优化插值生成的轨迹为横向最终学习轨迹,即3 组横向学习轨迹曲线中的最终一条曲线,它与横向专家轨迹很相近,特别是横向位置与横向速度.迭代最终的横向位置、横向速度和横向加速度优化权重参数为0.880 3、0.089 7、0.360 4,量化地表达了与横向最终学习轨迹相近的横向专家轨迹的内在优化机制,即专家在换道过程中对不同横向目标的不同重视程度.
图4 为自车期望纵向巡航速度、纵向加速度的逆强化学习结果.图5(a)为逆强化学习过程中智能体学习得到的每条轨迹的纵向相关特征值与专家轨迹纵向相关特征值之差范数的迭代演化,如式(30)所示.
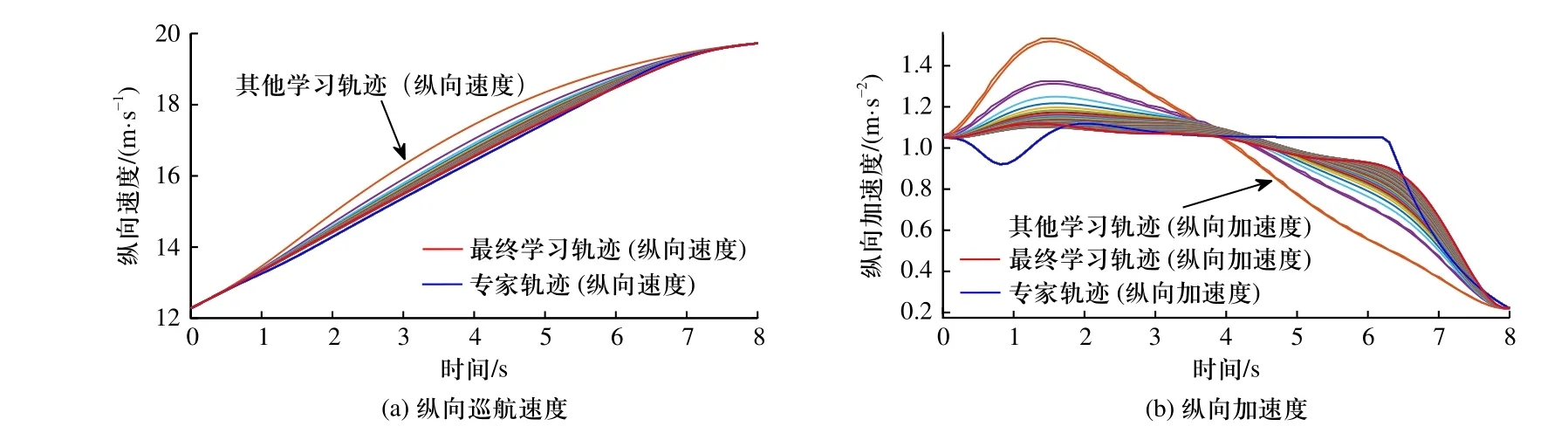
图4 一般风险场景下期望纵向速度、加速度的逆强化学习结果Fig.4 IRL results of longitudinal speed and acceleration in the general-risk scenario

图5 一般风险场景期望纵向轨迹关键参数结果Fig.5 IRL results of key parameters of longitudinal trajectories in the general-risk scenario
图5(b)为逆强化学习过程中自车期望纵向巡航速度和纵向加速度两个特征梯度的迭代演化.图5(c)为逆强化学习过程中,自车期望纵向巡航速度和纵向加速度两个特征相对应的优化权重参数 θ4和 θ5的迭代演化.
从图5 可以看出,在一般风险场景中,初始优化参数经优化插值生成的纵向学习轨迹(自车的纵向巡航速度和纵向加速度两组曲线)与纵向专家轨迹存在一定的差距,初始轨迹的纵向相关特征值与专家轨迹纵向相关特征值之差的范数很大(接近800),初始轨迹纵向巡航速度特征值与专家轨迹纵向巡航速度特征值之差不到30,纵向加速度特征值之差稍大于5.智能体按照基于一次轨迹样条近似代替的梯度下降迭代方法进行逆强化学习,不断迭代更新优化权重参数,共迭代了60 次,智能体每次学习得到的轨迹和专家轨迹越来越相似,智能体学习得到的轨迹纵向相关特征值与专家轨迹纵向相关特征值的差值也逐渐减小,迭代至60 次时,特征差基本收敛至0.优化权重参数迭代更新至60 次时,经优化插值生成的轨迹为纵向最终学习轨迹,即两组纵向学习轨迹曲线中的最终一条曲线,它与纵向专家轨迹很相近,特别是纵向巡航速度.迭代最终的纵向巡航速度和纵向加速度优化权重参数为4.673 3×10−7和5.226×10−7,量化地表达了与纵向最终学习轨迹相近的纵向专家轨迹的内在优化机制,也就是专家在换道过程中对两个纵向相关目标的各自的重视程度.
3.2 高风险场景专家轨迹的逆强化学习结果
为学习此高风险场景的专家轨迹,选取初始优化权重参数 θ0,期望横向位置、横向速度、横向加速度、期望纵向巡航速度、纵向加速度这5 个特征的初始权重参数依次为:0.01、1、10、0.01、1.图6 为高风险场景中自车期望横向位置、横向速度、横向加速度的逆强化学习结果.图7(a)为逆强化学习过程中智能体学习得到的每条轨迹的横向相关特征值与专家轨迹横向相关特征值之差范数的迭代演化.图7(b)为高风险场景中自车期望横向位置、横向速度、横向加速度3 个特征梯度的迭代演化.图7(c)为在此高风险场景的逆强化学习过程中,自车期望横向位置、横向速度、横向加速度3 个特征相对应的优化权重参数 θ1、θ2、θ3的迭代演化.

图6 高风险场景期望横向位置、速度、加速度的逆强化学习结果Fig.6 IRL results of lateral position, speed, and acceleration in the high-risk scenario

图7 高风险场景期望横向轨迹关键参数结果Fig.7 IRL results of key parameters of lateral trajectories in the high-risk scenario
从图7 可以看出,在高风险场景中,初始优化权重参数生成的横向学习轨迹(自车的横向位置坐标、横向速度和横向加速度3 组曲线)与横向专家轨迹相差甚远,初始轨迹的横向相关特征值与专家轨迹横向相关特征值之差的范数也很大(900 左右),初始轨迹横向位置特征值与专家轨迹横向位置特征值之差不到30,横向速度特征值之差在−5 左右,横向加速度特征值之差稍小于−10.智能体按照基于一次轨迹样条近似代替的梯度下降迭代方法进行逆强化学习,不断迭代更新优化权重参数,共迭代了60 次,智能体学习得到的轨迹和专家轨迹越来越接近,智能体学习得到的轨迹横向相关特征值与专家轨迹横向相关特征值的差值也逐渐减小,迭代至50 次时,特征差基本收敛至0.优化权重参数迭代更新至60 次时,经优化插值生成的轨迹为横向最终学习轨迹,即3 组横向学习轨迹曲线中的最终一条曲线,它与横向专家轨迹很相近,特别是横向位置与横向速度,尽管横向速度与横向加速度最终学习轨迹后期有微小波动.迭代最终的横向位置、横向速度和横向加速度优化权重参数为5.967 6,0.081 0,0.503 9.可见,与一般风险场景相比,专家轨迹的横向位置优化权重系数明显升高,所以在高风险场景换道专家轨迹的内在优化机制中,大大加强了对期望横向位置这个横向目标的重视程度,明显超过了对控制横向速度和横向加速度不要过大的重视程度.此换道场景中,专家最在意让自车尽早到达期望横向位置,完成自主换道.
图8 为高风险场景中,自车期望纵向巡航速度、纵向加速度的逆强化学习结果.图8(a)为逆强化学习过程中智能体学习得到的每条轨迹的纵向相关特征值与专家轨迹纵向相关特征值之差范数的迭代演化.图8(b)为高风险场景中自车期望纵向巡航速度和纵向加速度两个特征梯度的迭代演化.图8(c)为在高风险场景的逆强化学习过程中,自车期望纵向巡航速度和纵向加速度两个特征相对应的优化权重参数 θ4和 θ5的迭代演化.

图8 高风险场景下期望纵向速度、加速度的逆强化学习结果Fig.8 IRL results of longitudinal speed and acceleration in the high-risk scenario
从图8 可以看出,在高风险场景中,初始优化权重参数生成的纵向学习轨迹(自车的纵向巡航速度和纵向加速度两组曲线)与纵向专家轨迹存在一些差距,初始轨迹的纵向相关特征值与专家轨迹纵向相关特征值之差的范数比较大(接近300),初始轨迹纵向巡航速度特征值与专家轨迹纵向巡航速度特征值之差大于15,纵向加速度特征值之差稍大于−5.智能体按照基于一次轨迹样条近似代替的梯度下降迭代方法进行逆强化学习,不断迭代更新优化权重参数,共迭代了60 次,智能体每次学习得到的轨迹和专家轨迹的相似程度越来越高,智能体学习得到的轨迹纵向相关特征值与专家轨迹纵向相关特征值的差值也逐渐减小,迭代至30 次时,特征差基本收敛至0.优化权重参数迭代更新至60 次时,经优化插值生成的轨迹为纵向最终学习轨迹,即两组纵向学习轨迹曲线中的最终一条曲线,它与纵向专家轨迹很相近,特别是纵向巡航速度.虽然纵向加速度最终学习曲线和纵向加速度专家轨迹曲线不完全吻合,但两者变化趋势一致.迭代最终的纵向巡航速度和纵向加速度优化权重参数为0.422 和0.002.可见,与一般风险场景相比,专家轨迹的纵向巡航速度优化权重系数有所升高,所以在高风险场景换道专家轨迹的内在优化机制中,加强了对期望纵向巡航速度这个纵向目标的重视程度,并且其超过了对舒适性(控制纵向加速度不要过大)的重视程度.此换道场景中,专家意图让自车的纵向巡航速度快速升高.
仿真结果可知,与一般风险场景通过逆强化学习方法得到的专家轨迹优化代价函数相比,在高风险场景的优化代价函数中,期望横向位置和期望纵向巡航速度目标的优化权重系数更大,二者中,期望横向位置的权重系数明显升高.高风险场景中,学习专家轨迹的智能体更加重视和在意期望横向位置和期望纵向巡航速度这两个优化目标,相对来讲,此时的智能体不非常重视舒适性和经济性,即不再着重较多地限制高阶动力学特性响应过大,而是希望自车快速到达期望横向位置,且快速升高车速以跟随车速较高的前车巡航行驶.这充分证明了所提出的逆强化学习方法成功地学习了优秀驾驶员(仿优秀驾驶员的MPC 方法)换道过程的优化机制,这一优化机制可以量化且直观得被工程师所理解,具有可解释、可转移和可泛化到其他智能体的特点.
从两个场景的专家轨迹逆强化学习示例中可以得出结论,此逆强化学习方法有能力通过学习专家轨迹的内在优化机制(专家轨迹优化代价函数的权重系数)从而成功复现换道的横纵向专家轨迹,即通过逆强化学习方法学习优秀驾驶员换道的优化机制,复现专家轨迹是完全可行的.此可行性结论为未来利用逆强化学习方法大量离线学习优秀驾驶员在不同风险场景的专家轨迹的优化机制,构建与场景风险等级成映射关系的专家轨迹优化代价函数库奠定了理论和方法基础.以逆强化学习方法学习得出的优化代价函数作为目标函数,通过求解基于此目标函数的优化问题,可以实现自动驾驶汽车的轨迹规划功能.
4 结论与展望
本文提出了基于最大熵原则的逆强化学习方法,通过学习专家轨迹的内在优化机制来复现换道的专家轨迹.首先,根据最大熵原则推导出专家轨迹的指数型概率分布模型,再由极大似然估计方法得到专家轨迹特征的优化权重参数的计算方法.然后通过基于一次轨迹样条近似代替的梯度下降方法,迭代求出优化权重参数,最后实现智能体轨迹的特征与专家轨迹的特征相匹配.利用MPC 方法求出的自车换道轨迹作为一般风险场景和高风险场景的专家轨迹,从两个典型场景的逆强化学习结果得出,逆强化学习方法学习专家轨迹的内在优化机制进而实现换道轨迹规划是完全可行的.该方法学习到的优化机制具有鲁棒、可量化、可转移泛化、直观、强解释性的优点.
本文验证了逆强化学习方法通过学习专家轨迹的优化机制复现专家轨迹的可行性,为通过大量离线学习建立专家轨迹优化代价函数库提供必要的理论基础.本文研究旨在通过学习驾驶专家轨迹的内在优化机制,实现符合人类驾驶习惯的优化换道轨迹规划.此外,不同驾驶者或乘员都有各自的驾驶风格和乘坐偏好,因此将个性化学习纳入智能驾驶决策规划过程是另一项亟需解决的课题.本文研究工作在一般风险场景和高风险场景的学习结果表明本方法具有适应个性化驾驶学习的潜力,因此未来工作将聚焦于驾驶风格个性化的智能驾驶轨迹规划学习方法研究.
