基于机器学习算法术后急性肾损伤风险预测模型建立
2023-08-03孙义竹李雨捷黄家号宋艾璘
梁 浩, 孙义竹, 李雨捷, 黄家号, 宋艾璘, 舒 欣, 易 斌
陆军军医大学第一附属医院 麻醉科,重庆 400038
术后急性肾损伤(postoperative acute kidney injury,PO-AKI)是围术期常见并发症,会导致血浆废物积累及细胞外液容量和电解质失调,与病死率增加及住院时间延长相关[1-2]。有研究报道,PO-AKI的发生率为5%~42%,因研究定义和手术类型而异[3-4]。影响PO-AKI发生的危险因素包括年龄、基线估计肾小球率过滤(esti mated glomerularfiltrationrate,eGFR)、合并症(糖尿病和高血压等)、高危手术、败血症、低白蛋白血症和贫血等。目前,PO-AKI诊断中应用较为广泛的是改善全球肾病预后组织(KDIGO)的诊断标准,但其诊断依赖血清肌酐变化,迟滞于肾功能损害,难以早期及时发现[5]。多个团队收集围术期数据,开发了PO-AKI风险预测模型预测心脏术后AKI[6-9]。Gameiro等[10]开发PO-AKI风险预测模型预测腹部大手术PO-AKI风险,Lee等[11]开发PO-AKI风险预测模型预测肝移植手术术后发生AKI的风险。目前,机器学习被广泛应用于疾病预测[12-13]。有研究报道,机器学习算法在AKI预测方面性能优于传统回归模型[14-18]。但现有的将机器算法应用于PO-AKI预测领域主要局限于心脏手术,尚缺乏全手术类型PO-AKI的风险预测模型。本研究基于机器学习算法,构建预测全手术类型PO-AKI的风险预测模型,并探讨模型效能,同时建立PO-AKI网页预测模型,以期早期识别高危患者,为优化围术期患者管理路径提供参考。现报道如下。
1 对象与方法
1.1 数据来源 本研究数据来源于国内3家不同区域大型综合医院开发的多中心数据库。本研究通过3家医院伦理委员会批准,包括陆军军医大学附属西南医院(2014年1月至2019年6月,伦理审查批件号:KY201936)、四川大学附属华西医院(2019年5月至2020年1月,伦理审查批件号:2021-349)、中山大学附属第一医院(2019年6月至2019年12月,伦理审查批件号:2019-385)。
1.2 纳入与排除标准 纳入标准:年龄≥18岁;住院手术。排除标准:术前肾小球滤过率(glomerular filtration rate,GFR)轻度以上降低[定义为eGFR≤60 ml/(min·1.73 m2)];手术次数≥2次;住院期间死亡;接受肾移植受体手术;接受局部麻醉或监护麻醉;术前或术后7 d内血肌酐检验值缺失;重要病历资料缺失>30%。按照纳入、排除标准,共筛选出635例AKI患者纳入PO-AKI组。采用病例对照研究设计方案,按阳性∶阴性=1∶3比例倾向匹配同期手术后未发生AKI的1905例患者纳入非PO-AKI组。
1.3 数据收集 收集手术患者常见临床指标。一般资料包括年龄、性别、体质量指数(body mass index,BMI);既往史包括术前肾功能史、吸烟史、饮酒史、过敏史、输血史、高血压史、糖尿病史、心脏病史;手术相关信息包括麻醉方式、手术类型、手术时长和急诊情况。实验室检验包括白细胞计数、红细胞计数、血小板计数、血红蛋白、红细胞比容、淋巴细胞计数、国际标准化比值、活化部分凝血活酶时间、凝血酶时间、白蛋白、谷丙转氨酶、谷草转氨酶、碱性磷酸酶、总蛋白、白球比值、总胆红素、血肌酐、血尿素、血尿酸、血糖、钾离子、钠离子。
1.4 数据预处理 采用多重插补方法对缺失率<30%的指标进行填补。对于连续性变量,用range函数缩放,处理后的数据取值0~1,以消除指标之间不同量纲的影响。对于分类变量,行One-Hot编码,使用N位状态寄存器对N个状态进行编码,每个状态均有独立的寄存器位,使之更符合机器学习计算过程,以提高计算效率。数据处理后,各指标处于同一数量级。将纳入统计的数据按7∶3的比例随机拆分为建模组(n=1 778)和验证组(n=762)。建模组中,采用Smote采样改善数据不平衡情况,使用LASSO方法进行特征选择,以筛选独立且有效的危险因素,从而确定预测指标。
1.5 模型开发 在建模组中,输入预测指标,使用R软件‘caret’包中包含的6种代表性模型算法进行模型训练,模型算法分别为梯度提升模型(gradient boosting model,GBM)、广义线性模型(generalize linear model,GLM)、K-近邻(K-nearest neighbor,KNN)、朴素贝叶斯(naive bayes,NB)、神经网络(neural network,NNET)、支持向量机(support vector machine linear,SVM)。每种模型在建立时均使用了10折交叉验证并迭代了5次,以增强模型性能。机器学习数据预处理、模型开发、验证由R软件(4.3.0版本)完成。
1.6 模型评估 在验证组中,采用受试者工作特征曲线下面积(area under the receiver operating characteristic curve,AUC)、敏感度、特异度、准确度和F1分数(精确率和召回率的一种加权平均)评估各模型的预测效能。
1.7 模型网页建立 通过对多个模型的综合评估,确定适合PO-AKI的最佳预测模型,并使用Python软件的‘shinydashboard’包将模型映射到网页,通过输入患者预测指标信息即可出现患PO-AKI的风险概率,从而量化结果风险。
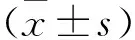
2 结果
2.1 两组患者一般资料比较 两组患者年龄、性别、吸烟史、饮酒史、过敏史、输血史、高血压史、糖尿病史、心脏病史、麻醉方式、手术类型、手术时长、红细胞计数、血小板计数、血红蛋白、红细胞比容、淋巴细胞计数、活化部分凝血活酶时间、血清白蛋白、谷丙转氨酶、谷草转氨酶、碱性磷酸酶、总蛋白、白球比值、血肌酐、血糖、钠离子比较,差异有统计学意义(P<0.05)。见表1。
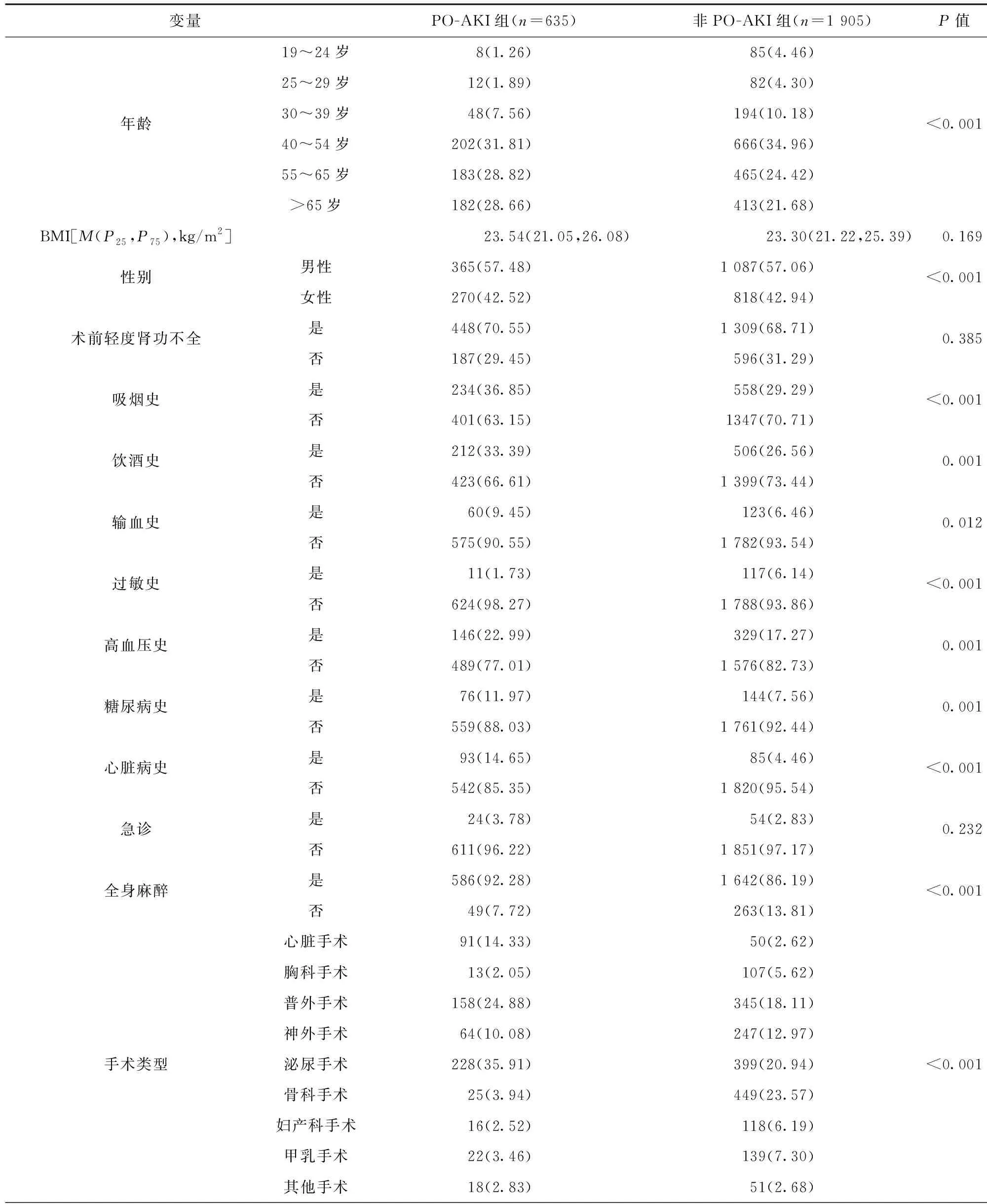
表1 两组患者一般资料比较/例(百分率/%)
2.2 特征变量筛选结果 使用LASSO回归分析选取特征系数在一个方差范围内仍不为0的变量,最终有意义的变量如下。(1)一般信息:年龄、BMI;(2)既往史:慢性肾病1期、吸烟史、饮酒史、输血史、过敏史、糖尿病史、心脏病史;(3)手术相关指标:急诊、手术类型、手术时长;(4)实验室检验:白细胞计数、红细胞计数、血小板计数、淋巴细胞计数、国际标准化比值、活化部分凝血活酶时间、凝血酶时间、谷草转氨酶、碱性磷酸酶、总蛋白、白球比值、总胆红素、血肌酐、血尿素、血尿酸、血糖、钾离子、钠离子、红细胞比容。见表2。
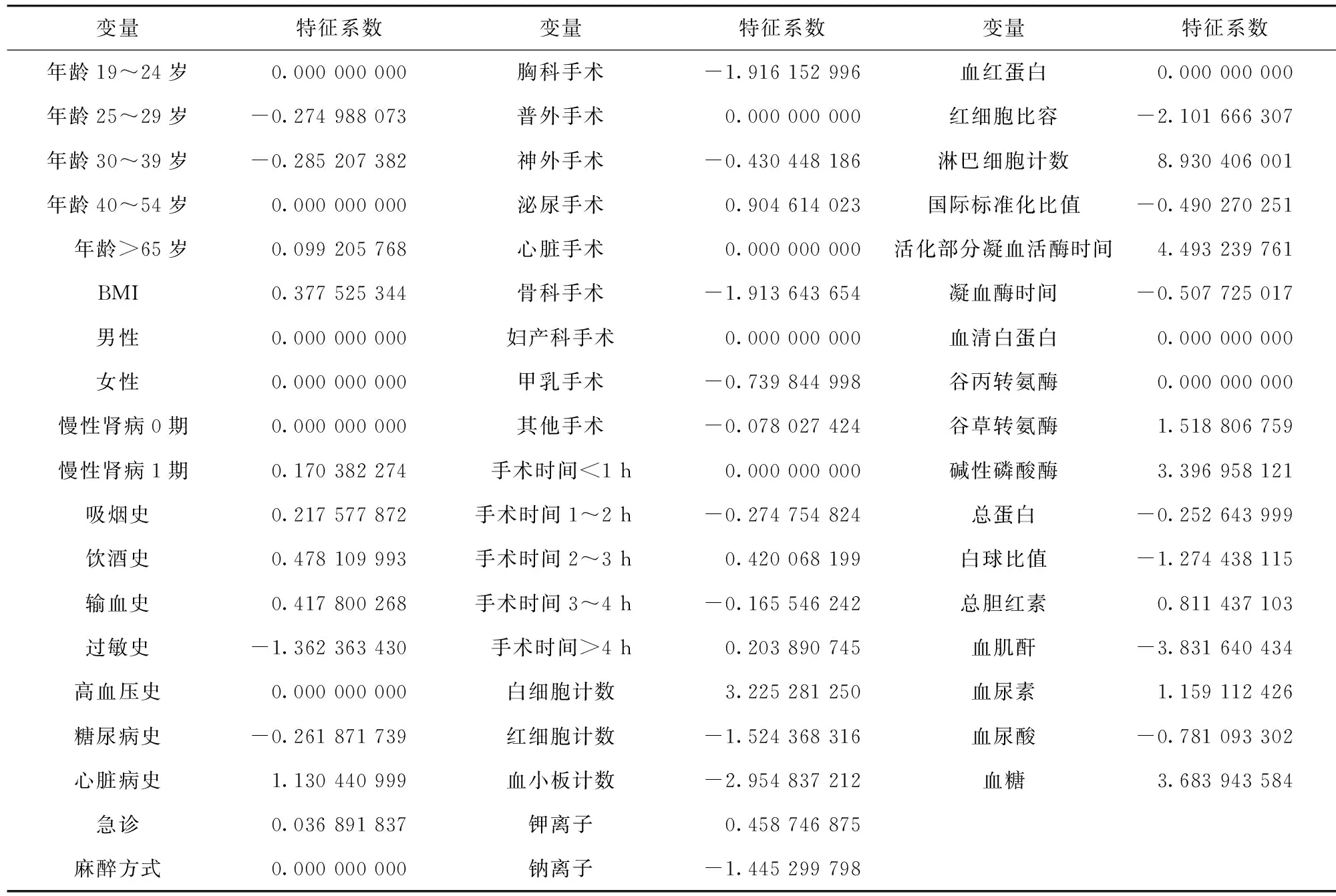
表2 LASSO特征选择结果及系数
2.3 模型预测性能及验证结果 基于NNET算法开发的模型在验证组获得了最佳的鉴别能力(AUC为0.942,95%可信区间0.926~0.958)和最佳的F1分数(0.759)。模型综合性能比较见表3。6种机器学习算法模型在验证组的受试者工作特征曲线见图1。
图1 6种机器学习模型在验证组的受试者工作特征曲线图
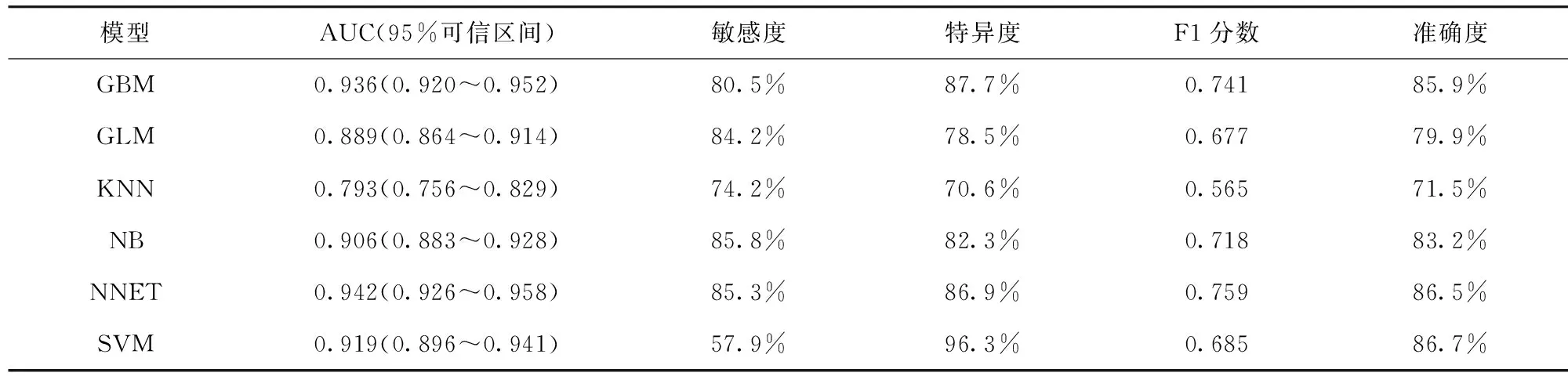
表3 机器学习预测模型综合性能比较
2.4 网页模型建立 基于NNET算法开发的预测模型被映射到网页(https://lh123.shinyapps.io/nnet1poaki/),在预测网页界面输入患者术中特征信息后,点击预测即可出现该患者发生PO-AKI的概率。见图2。
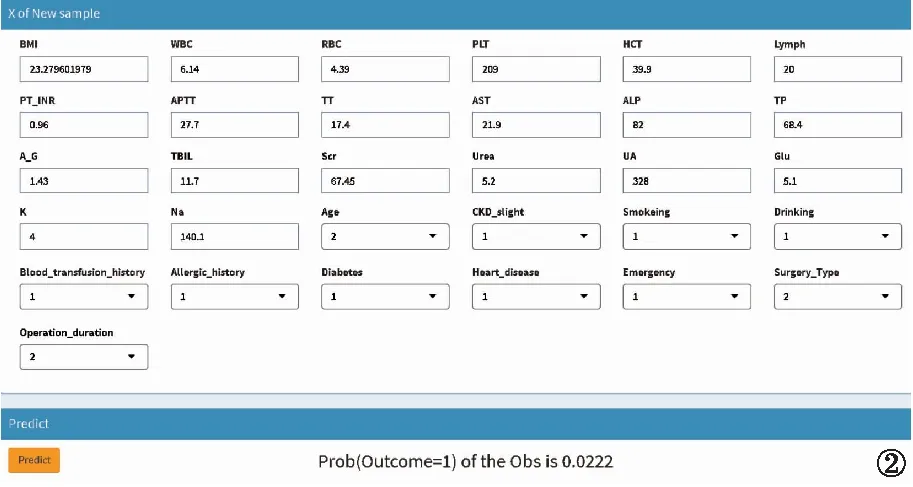
图2 基于NNET模型的PO-AKI预测网页
3 讨论
PO-AKI是常见的围术期并发症,此类患者住院时间更长,医疗费用更高,且更可能进展成为慢性肾病。有研究报道,轻微的PO-AKI与患者的存活率降低有关[19]。PO-AKI病理生理机制复杂,目前尚未完全清楚,已知低灌注、缺血再灌注损伤、神经激素激活、炎症、肾毒素暴露可能与PO-AKI有关[20]。机器学习算法在医学影像、疾病的分类和预测、药物反应和治疗策略等方面被广泛应用[21]。
有研究表明,结合机器学习可以实现早期预测AKI[5]。机器学习算法已经应用于ICU患者[22]、住院患者[23]、烧伤患者[24-25]、肝肾综合征患者[26]、行冠脉造影术患者[27]后等人群AKI风险预测,但仍缺乏全手术类型PO-AKI方面的研究。
本研究基于已发表的国内外文献,筛选出研究相关的指标,再经过LASSO方法进行特征选择并且进行交叉验证,结果发现,年龄、BMI、吸烟史、饮酒史、过敏史、输血史、糖尿病史、心脏病史、慢性肾病1期、手术时长、急诊手术、手术类型、白细胞计数、红细胞计数、血小板计数、红细胞比容、国际标准化比值、活化部分凝血活酶时间、凝血酶时间、谷草转氨酶、碱性磷酸酶、总蛋白、白球比值、总胆红素、血肌酐、血尿素、血尿酸、血糖、钾离子、钠离子可能与PO-AKI的发生有关。其中,血肌酐水平是PO-AKI的诊断指标,也是AKI程度的分期标准,可用于指导AKI治疗[28]。多项研究表明,年龄、BMI、手术时长、急诊是AKI的独立危险因素[29-31]。有研究表明,糖尿病、基线eGFR是PO-AKI的危险因素[30]。吸烟史、心脏病史、红细胞计数、血尿酸与AKI的关系也有相关研究阐明[31-33]。
本研究基于GBM、GLM、KNN、NB、NNET及SVM算法构建了住院手术PO-AKI的风险预测模型,并比较了这6种模型的预测效能。目前,这6种算法是应用较为广泛的集成学习算法。GBM能精确地找到分割点,但数据对计算机空间的消耗大;GLM可解释性较强,但当某些特征相关性较强时,其他特征的重要性将被削弱;KNN理论简单,新数据可以直接加入数据集而不必进行重新训练,但在样本不平衡时,预测偏差较大;NB在处理大规模的训练集时能有效选出相对较少的特征数,但在样本属性有关联时其效果较差;NNET分类准确度高,学习能力极强,但在学习过程中无法观察中间结果,存在黑盒效应;SVM在处理非线性、小样本及二分类数据时有优势,但是对缺失数据敏感且在大规模样本中难以实施[21,34-35]。本研究中,KNN模型AUC为0.793,敏感度为74.2%,特异度为70.6%,F1分数为0.565,准确度为71.5%,在6种模型中预测效能最差;而NNET模型AUC为0.942,敏感度为85.3%,特异度为86.9%,F1分数为0.759,准确度为86.5%,该模型区分度好。本研究存在局限性:首先,数据集虽然来自3家国内大型综合医院,但均为回顾性信息;其次,本研究使用了31个特征指标构建模型和预测网页,应用于临床时不够简便;最后,由于病例资料丢失,未纳入美国麻醉医师协会分级、术中尿量、手术失血量、术中血压等特征。因此,后续应开展前瞻性、筛选指标数量精简且纳入更多术中相关特征的研究。
综上所述,本研究采用AKI最新定义(KDIGO标准)基于多个机器学习算法用多中心数据开发PO-AKI预测模型,综合比较了各模型的预测性能和临床实用性,最终筛选出了基于NNET算法开发的最佳预测模型,搭建预测网页,以量化PO-AKI风险,对手术患者进行早期风险分层,为指导围术期AKI评估和预防性治疗提供可能。
