使用机器学习算法分类P2P流量的方法研究
2022-02-16罗远军
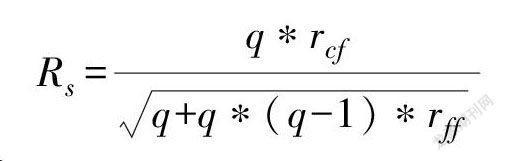
关键词:机器学习算法;算法分类;P2P流量;智能算法;研究分析
中图法分类号:TP181 文献标识码:A
1 P2P流的定义和特征产生概述
1.1 P2P流的定义和表示
本文将互联网上P2P通信节点之间产生的流量依据协议通信的五元组(IP、源Prot、目的IP、目的Prot及IP协议)定位为流。
1.2流特征的产生
我们将流的特征主要分为两种,分别是前向和后向的双向特征,前向流和后向流的定义如下——前向流:源节点→目的节点;后向流:目的节点→源节点。
经过均方差的计算和分析之后可以发现,双向报文的个数、长度等可以形成36个候选特征,对于本文进行的机器学习算法分类P2P流量方面的研究具有重要的意义和作用。
2基于ReliefF?CFS方法的流的特征选择
流的特征选择对于最终的研究成果会产生直接影响。所谓的特征选择,需要相关工作人员去掉相关度不高或者是冗余特征,进而实现最优的特征得以脱颖而出。后续依据评估函数与分类器之间的联系,将特征选择方法主要分为两种模式,分别是过滤器模式和封装器模式,其中过滤器模式评估函数与分类器无关,而封装器模式主要采用分类错误率或者是正确率作为评价函数,选择的速度比较慢,同时还需要交叉认证和大量的计算资源。因此,于流的特征选择方面需要采用过滤器模式,并且使用基于ReliefF算法和基于相关性的方法结合的方式选择特征子集,这就是所谓的ReliefF?CFS方法,能够取得很好的效果和作用。
2.1基于ReliefF?CFS方法的初步P2P特征选择方法
ReliefF其实是一种有监督特征的算则算法,是传统Relief算法的一种改进算法,其能够在多类特征分类中进行对应的运用,并且可以取得很好的效果和作用。基于ReliefF?CFS方法的初步P2P特征选择基本思想为:需要从每一个不同的类别流样本集合中选择G个最近邻样本流,并且相关工作人员需要对每一个样本流的特征权重进行对应的计算,经过计算就能够得到流的不同特征与类别的相关性情况。其中,选择相关性比较大的特征就能够作为流量分类的特征。后续经过基于ReliefF?CFS方法所得到的按权值还需要按照从大到小的顺序进行排列,同时设定一个阈值,其中大于阈值的特征被选为基于相关性的特征选择方法的初始特征集。
2.2基于CFS方法的特征选择
前文提及,由于ReliefF算法只考虑特征与类别的相关性,而没有考虑特征自身具备的相关性,因此经过ReliefF算法选择的特征相关性可能存在一定的缺失。因此需要在经过ReliefF算法选择得到初步的流的特征子集之后,在原有的基础之上通过相关性特征选择方法继续进行特征的选择,以此提升特征的相关性,相关性的计算公式如下所示。
在上式中,s表示含有q个特征的特征子集,Rs则是对特征子集相关度的一个评估结果。从上述公式中也可以看出,当分类与特征之间的相关度越高,而特征与特征之间的相关度比较小的情况下,特征子集的分类效果就会越好。在本文进行的研究中,主要采取BestFirst搜索策略结合正向搜索方向的方式,搜索得到结果优化程度比较高的特征子集,并且将其作为最后的特征选择结果。
3基于机器学习算法的P2P流量分类器
机器学习是人工智能技术中最为重要的一个分支,也是一个最重要的研究方向。在研究和分析的过程中,主要需要从样本中寻找一定的规律,并且利用这一规律对未知的数据信息进行对应的预测工作。目前来看,机器学习过程主要由以下两个部分组成,分别是分类模型的建立和分类。相关工作人员首先需要利用训练数据建立起分类模型,并且在建立好的模型基础之上,产生一个分类器,针对物质数据信息进行分类处理。本文主要应用基于支持向量机、C4.5决策树以及K?最邻近单中机器学习算法的分类器。
3.1基于支持向量机的P2P网络流量分类器
支持向量机是由Boser等人在统计学习原理和结构风险最小化原则基础之上提出的一种机器学习算法。基于支持向量机的P2P网络流量分类器主要是针对两类分类问题而提出的,其主要原理是运用分类超平面实现空间中两类样本点的正确分割,并且保持两类样本的间隔最大。
而且,如果处于线性不可分的情况下,可以通过选择好的非线性映射函数,也就是所谓的核函数选择,将训练样本流映射到一个高维特征空间中,并且在这一空间中构造线性判别函数,进而实现原空间中非线性判别函数,这样有利于确保机器具备比较好的推广能力,同时在核函数的作用下,可以解决原本存在的维数灾难问题,其算法的复杂程度与样本维数无关。另外,对网络中的P2P流量进行识别,接着对经典1?vs?all多分类SVM算法进行改进,我们提出了一个新的基于MC?SVM(多分类支持向量机)的分类判别方法,用来把之前所识别出的未知具体应用层分类的P2P流量进行应用层分类,最后通过真实的网络流量数据实验,证明其可行性。
3.2基于C4.5决策树的P2P网络流量分类器
决策树模型是一种比较简单同时适用性也比较强的非参数分类器,其不仅不需要对数据进行假设,同时还可以在分类过程中具备比较强的计算速度,分类结果的稳健性也较强。基于C4.5决策树的P2P网络流量分类器,其中每一个分支所代表的都是一个测试输出,而每一个叶节点代表的是类别,而且C4.5算法还是D3算法的一种拓展,有利于分类达到较好的效果和作用。
并且在生成决策树之后,可以采用剪枝技术进行优化和完善,使得纠正过度的拟合问题可以得到有效的处理。简单来说,剪枝技术是剪去树中不能提高预测准确率的分,进而提升分类结果的科学合理性。此外,相关工作人员还需要通过每个叶节点最少实例数设置的方式,进而对决策树的规模進行有效控制,而置信因子的设置则用来确定树的修建程序。
4结论
从文中阐述内容中不难看出,基于ReliefF?CFS的特征选择方法与传统特征选择具有较大的区别。本文提出的几种使用机器学习算法分类P2P流量分类器能够取得很好的效果和作用,同时其优势在于实时流的分类应用,因此后续也可以着重进行这一方面的持续优化和完善,这对于国内网络通信领域的发展具有重要的现实意义,需要予以高度重视。
作者简介:
罗远军(1971—),硕士,讲师,研究方向:移动互联网、大数据、网络体系结构。
