基于增量学习算法的混合课程学生成绩预测模型研究
2021-09-27罗杨洋韩锡斌
罗杨洋 韩锡斌

[摘 要] 基于在線学习行为预测学生成绩可以辅助教师动态掌握学情,制定差异化的教学策略,然而在混合课程中仅仅依据在线数据对学生成绩进行预测难度很大,尚处于探索中。文章选取某高校2018秋季学期和2020春季学期的“高活跃型混合课程”学生在线行为数据,采用增量学习的随机森林算法构建学生成绩预测模型,研究发现:(1)增量学习随机森林算法在混合课程样本最多的数据集中,获得预测结果准确率最高(75.1%);(2)相较于批量学习随机森林算法,增量学习算法在数据样本量较多的数据集中预测结果准确率更高;(3)当样本数量达到一定规模后,预测结果准确率波动减小、稳定性增强。本研究采用增量学习随机森林算法预测混合课程中的学生成绩,不仅取得了较好的预测准确率,而且解决了新增数据后模型的稳定性问题,将有助于模型的迭代优化,提高模型的通用性,以及可持续追踪学生在不同学期的学习行为特征。
[关键词] 学生成绩预测; 混合课程; 增量学习算法; 随机森林算法; 机器学习
[中图分类号] G434 [文献标志码] A
[作者简介] 罗杨洋(1989—),男,四川彭州人。博士研究生,主要从事高等教育和职业教育学习分析。E-mail:yy-luo17@mails.tsinghua.edu.cn。
一、引 言
结合了在线和面授教学优势的混合课程已成为高等教育机构中广为应用的教学形式。使用网络教学平台中记录的学生学习过程数据,预测学生学习成绩,辅助教师分析学情,制定教学策略,预警学生学习状态是近年来混合课程研究领域的热点[1]。然而混合课程的交互机制导致对学生成绩进行预测是一项十分具有挑战性的研究[2]。研究者在混合课程情境下构建学生成绩预测模型涉及预测变量选择、预测变量预处理、机器学习算法选择、训练样本选择等问题[3-4]。虽然已有研究通过收集一门混合课程中学生的在线学习数据,使用机器学习算法构建学习成绩预测模型,并取得了可接受的预测结果准确率[5-7],发现了对学习成绩预测准确率较高的预测变量、预处理方法及机器学习算法。然而这些研究没有讨论训练样本的选择问题。训练样本的数量及特征对机器学习算法,特别是增量学习算法构建的预测模型有显著影响[8]。
另一方面,当前学者们提出的混合课程中学习成绩预测模型都基于批量学习方式构建,这种方法有利于分析整个样本中的整体特征,构建样本的特征变量与结果变量之间的关系,但是得到的模型无法再接受新数据,不利于将已构建好的预测模型应用到其他课程[9]。相对于批量学习,增量学习方式的机器学习算法有望解决上述问题,且在完全在线课程的学习成绩预测研究中已有应用[10]。本文旨在采用增量学习随机森林算法,构建混合课程中的学生成绩预测模型,比较增量学习和批量学习方式分类算法预测结果准确率的差异,分析混合课程中基于增量学习构建模型预测结果的稳定性。
二、文献综述
当前在混合课程情境下对学生成绩的预测研究大多在一门课程中采用批量学习方式的机器学习算法,分析学生学习的整个历史过程数据,构建学生成绩预测模型[5-7]。在应用到实践教学中时,批量学习算法构建的预测模型会因模型无法接收新数据而受到阻碍。虽有少量研究者尝试使用增量学习方法构建学生成绩预测模型,但还局限在完全在线课程中[10-11]。增量学习方法在训练大量非平衡数据时会出现构建的预测模型结果准确率不稳定的问题,虽然已有研究探索了提升增量学习方法训练非平衡样本和大规模样本(样本数量大于1000)所获预测模型结果稳定性和准确率的问题[8,12-13],但数据样本的特征及样本的数量对增量方法构建预测模型产生的影响仍不清楚。本文研究在使用最新的增量学习方式的机器学习算法基础上,分析混合课程情境下,利用学生学习过程数据构建学生成绩预测模型时,学生样本数量和样本特征产生的影响。目前,使用增量学习方式的机器学习算法构建混合课程中的学生成绩预测模型主要涉及两个方面:混合课程学生成绩预测研究和增量学习方式的算法在学生成绩预测研究中的应用。
(一)混合课程学生成绩预测研究进展
当前混合课程中预测学生的学习成绩方法一般借鉴完全在线课程中的预测方法,即收集学生的历史学习过程数据作为预测变量,收集学生的学习成绩数据作为结果变量,通过机器学习的分类算法建立学习成绩预测模型,进而采用预测模型预测学生未来的学习成绩[4]。许多学者在混合课程中大多都基于随机森林算法,使用一门课程中学生的学习行为数据构建学生成绩预测模型[5-7]。然而这些研究中使用的机器学习算法以批量学习方式处理数据,批量学习是指在构建模型时将所有样本一次性全部输入[14]。这种方法有利于分析整个样本中的整体特征,预测结果准确率较为稳定,而且有大量已实现的机器学习算法使用批量学习的数据处理方式,便于教育研究者直接应用,但是使用批量学习方式得到的预测模型无法再接收新数据[15],从而影响模型的迭代优化。另一方面,一次性输入学生的所有历史学习过程数据构建学生成绩预测模型的研究方式,也无法分析新增学生样本对预测结果带来的影响,不利于将已构建好的预测模型应用到其他课程,也不利于持续追踪学生在不同学期的学习行为特征[9]。学习者在不同混合课程中并不会保持相同的学习行为特征,在本团队以往的研究中发现,学生在不同类型的混合课程中,其学习行为数据对学习成绩的预测准确率具有较大差异[16]。因此要发现一门混合课程中学生群体的个性化行为特征与学习成绩的预测关系,需要使用该混合课程的数据不断训练学习成绩预测模型。为此,当前亟须研究如何以增量学习数据处理方式的机器学习算法,在混合课程情境下构建学习成绩预测模型。增量学习是每当有新的训练数据输入时,机器学习算法便根据新数据调整已构建模型的机器学习方法。与传统学习方法最大的区别是增量学习方法不假设构建模型前就具有完备的训练数据,训练数据会在算法运行过程中随时间推移不断出现[17]。
批量学习与增量学习数据处理方式的机器學习算法构建模型过程差异如图1所示。
综上所述,当前在混合课程中基于学生在线行为预测学习成绩的研究都是基于批量学习数据处理方式的机器学习算法构建预测模型,这种方法便于实现,能获得所有样本的整体特征,预测结果准确率较为稳定。然而这种方法也存在模型无法接收新数据,不利于模型的迭代优化,不利于将已构建好的预测模型应用到其他课程,也不利于持续追踪学生在不同学期的学习行为特征的问题。相对于批量学习方式处理数据的机器学习算法,增量学习的方式有望解决上述问题,构建可持续追踪学生学习过程的成绩预测模型。
(二)增量学习方式在学生成绩预测研究中的应用
增量学习方式的机器学习算法主要包含以下四种特征:(1) 可从新数据中提取知识;(2) 将数据加入到模型中学习时不需构建原始模型的原始数据;(3) 新数据中的知识不会覆盖原始模型的知识;(4) 当新数据中包含的知识与原始模型冲突或超出原始模型时仍可被学习到新模型中[18]。通过增量学习方式生成的模型可根据新加入的训练数据不断扩展,代表了动态学习的技术。有研究者指出,随着学生在各种网络教学平台中产生的学习过程数据不断增长,学习者的学习过程不会中断,无法断言在某一时刻收集的数据能覆盖该学习者的所有特征。批量学习方式的成绩预测模型构建的是学习者在一段时间内,学习过程与学习结果的预测关系。研究者通常难以判断这种预测关系在未来多长时间内有效,当前最成熟学习成绩预测模型应用仍限于危机学生的分辨方面[19]。要充分发挥学生成绩预测模型为师生教学决策带来的辅助作用,构建动态分析学习者学习过程并预测学习结果的模型必不可少。研究者应用增量学习方式开展学生成绩预测在少量完全在线教学案例中有过实践,如Kulkarni & Ade的研究中对比了朴素贝叶斯、K星、IBK和K最邻近算法,发现K最邻近算法的预测结果准确率最高[11]。然而该研究中只对比了增量学习算法之间的预测结果准确率,增量算法与批量算法的预测结果准确率差异没有对比。在Ade & Deshmukh的研究中发现增量学习算法对学生成绩进行预测时结果准确率随样本增加而波动,且不会收敛到固定值,因此分析学生样本特征对增量学习算法建模预测结果的影响也是需要研究的重要问题[20]。还有Sanchez-Santillan等人分析了使用增量学习算法构建了两学期的学生成绩的预测模型,在分别使用两学期数据及两学期数据合并三种数据集训练的预测模型后发现,当其中一学期的预测结果准确率下降时会导致数据合并后的预测结果准确率下降[10]。
然而上述研究均在完全在线课程中开展,当前尚未发现有使用增量学习方式算法,分析混合课程中学生学习过程数据,预测学习成绩的研究。增量学习方式能够满足教学场景中对学生动态、持续建模的需求,但使用增量学习算法预测混合课程中的学生成绩仍面临巨大挑战。主要表现在两个方面:(1)增量学习方式的算法面对非平衡数据时难以取得较好预测结果;(2)增量学习方式的算法存在预测结果准确率不稳定的问题,主要由新加入的数据特征没有被算法识别引起[18]。该问题在近年来随机森林算法的增量学习研究中取得了较大改善,为本研究奠定了基础[8]。在混合课程使用中增量学习方式的算法构建学生成绩预测模型还需分析样本特征对预测结果的影响。
三、研究问题及研究方法
综合前述文献分析结果,提出以下研究问题:
研究问题1:使用增量学习与批量学习方式的算法构建的成绩预测模型结果准确率有何差异?
研究问题2:混合课程中的样本特征对增量学习构建的成绩预测模型结果准确率有何影响?
在本团队以往的研究中,收集了某大学2018年秋季学期的全部混合课程数据,依据学生行为聚类特征进行了混合课程分类,发现只有在“高活跃型混合课程”中使用批量学习方式的算法才可以获得可接受的预测结果准确率[16]。“高活跃型混合课程”的特征是课程有50%以上学生的学习行为数据均值较高,标准差较大,线上学习的个性化水平较高,且每门课程所包含的学生数量大体相似。
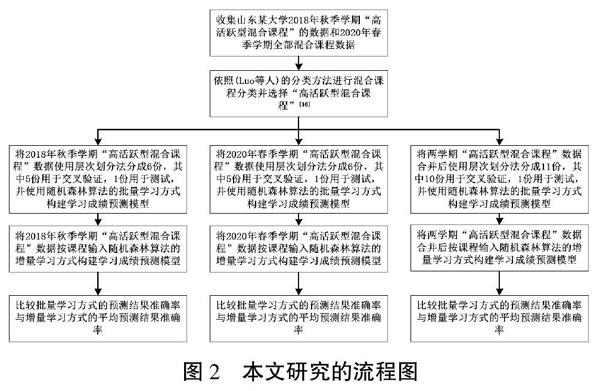
本文在此基础上进一步收集了同一所大学2020年春季学期的全部混合课程数据,依照本团队以往研究的混合课程分类方法进行分类,使用增量学习方式,比较在不同规模数据集时,构建学习成绩预测模型的结果,构建过程中同样只选择“高活跃型混合课程”中的数据进行比较。研究流程如图2所示。
本文在构建模型时采用具有较高预测结果准确率的随机森林算法,该算法批量学习方式的预测结果准确率得到多项研究的验证[5-6,21-22]。为方便比较,同时采用了随机森林的增量学习方式。据Genuer等人的研究,最新的随机森林的增量学习方式OnRF包含了超参数,对非平衡数据可获得较高的预测结果准确率,并且在Python上已被实现,可以直接使用[12]。相较于其他算法的增量学习方式,OnRF随机森林算法近年来经过研究者们的不断优化,在算法鲁棒性、接收数据的非平衡性等方面有了较大提升[23]。
(一)研究对象和场景
根据研究团队以往的数据采集和处理,某高校2018年秋季学期的“高活跃型混合课程中”有22门,包括2348名学生。所有学生采用优慕课R“综合教学平台V9”网络教学平台开展混合学习的线上部分。学生在选课系统中选择混合课程后会被告知注意事项,包括学生使用该平台出现问题,平台支持的混合学习活动形式,平台会记录学生在登录系统后发生的所有操作等。学生在每门混合课程结束后,教师会根据学生的线上、线下学习参与及课程最终测试结果为学生评分。本研究将百分制的学生评分转换成了5个等级,转换规则为学生成绩为90~100分之间时将其划分为A,学生成绩为80~89分之间时将其划分为B,学生成绩为70~79分之间时将其划分为C,学生成绩为60~69分之间时将其划分为D,以及最后学生成绩在60分以下时将其划分为F。
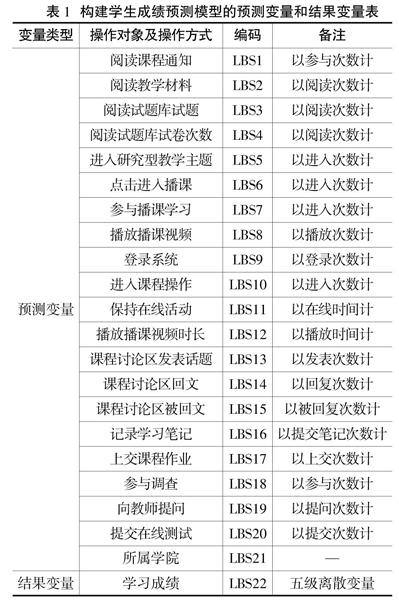
本研究将学生在网络教学平台上的在线学习行为作为学习过程,学生的最终成绩作为学习结果。进而获得用于构建学生成绩预测模型的各变量(见表1)。
(二)研究方法和步骤
为对比增量学习方式在不同规模数据中的预测成效,比较增量学习和批量学习方式的预测结果准确率,本研究对收集的某高校2020年春季学期混合课程数据进行了分类处理,沿用Luo 等人提出的方法[16],获得了51门“高活跃型混合课程”,包含4840名学生(分类方法流程图如图3所示)。
在对2020年春季学期混合课程分类后,本研究对2020年春季学期“高活跃型混合课程”中的学生在线行为数据和学习成绩进行了探索。通过学生在线行为数据预测学习成绩的基础是学生在线行为与学习成绩具有相关关系。当同一课程中存在不同类型学生,但学生成绩没有显著差异时,说明该课程中学生在线行为数据与学习成绩数据没有相关关系。在预处理时删除所有此类课程。另外,结果变量中各等级成绩的分布也会影响预测模型的结果准确率[24]。本文探索了两学期“高活跃型混合课程”中各成绩的学生人数占比(如图4所示)。
从图4中可知,2020年春季学期与2018年秋季学期相比,成绩为A和B的学生人数占比变动较大,其中成绩为A的学生占比上升了18.18%,成绩为B的学生占比下降了10.65%。另外成绩为C的学生占比下降了5.51%,成绩为D和F的学生占比变动并未超过5%。
根据图2所示的研究步骤,本文分别使用批量学习方式的随机森林算法和增量学习方式的随机森林算法对2018年秋季学期、2020年春季学期以及两学期合并后的“高活跃型混合课程”学生数据建立成绩预测模型。在构建预测模型过程中,采用超参数调试(Hyper-parameter Tuning)方法为随机森林的两种学习方法分别设定最优参数。使用交叉验证方法分析随机森林算法的两种模型学习方法分别对三类数据集构建的预测模型。本文所分析的学生成绩是5级定类变量,是一个多分类预测问题。因此,本文采用了适用于多分类预测问题的评价指标,采用指标包括平均准确率(Avg. Accuracy)、權重准确率(Weighted Accuracy)、平均查全率(Avg. Recall)、权重查全率(Weighted Recall),宏F1值以及权重F1值为评价指标[25]。另外,增量学习方式算法的预测准确率随样本输入变化,本文采用平均预测准确率作为评价增量学习方式算法预测结果的指标。预测结果评价的计算公式见表2。
在表2中,i表示学生成绩分类,分别是A、B、C、D、F,当i=A时,TPA表示预测结果为A,实际成绩也为A的学生,TNA表示预测结果为非A时与真实结果也为非A的样本数,FPA表示预测结果为A但真实结果为非A的样本数,FNA表示预测结果为非A但真实结果为A的样本数。最后使用三类数据集的测试集测试预测模型的预测结果准确率。
四、研究结果与讨论
(一)随机森林增量学习与批量学习方式构建的模型预测结果比较
为比较随机森林的批量学习与增量学习方式在不同学期“高活跃型混合课程”中对学生成绩的预测能力,本文记录了两种方式构建预测模型的评价指标和对测试集的预测结果准确率(见表3)。
从表3可知,在2018秋季学期的“高活跃型混合课程”中,批量学习方式随机森林算法构建的学生成绩预测模型结果获得了较高准确率(72.3%),但是在2020春季学期的“高活跃型混合课程”中,其预测结果准确率(68.2%)并不如OnRF得到的预测结果的平均准确率(69.1%)。在两学期数据合并后,OnRF表现出更优异的预测结果平均准确率,达到了75.1%。批量学习方式随机森林算法的预测结果准确率则介于两学期的预测结果准确率之间(70.3%)。可见,OnRF在学生样本数量增加后构建的学生成绩预测模型结果更加准确。
虽然本文中使用的OnRF方法预测结果准确率落后于Kulkarni & Ade所用的四种增量方法的准确率,但该研究中所用数据是完全在线课程数据,且其使用的数据特征包含学生的期中成绩,因此该研究对学生成绩的预测结果准确率都达到了89%以上[11]。在两学期数据合并后的较多样本中,本研究的预测结果准确率比Sanchez-Santillan等人的结果平均准确率提高了2.28%[10]。
相比同样在混合课程情境下,使用批量学习方式随机森林算法构建模型,预测学生成绩的研究。本文选用的OnRF在使用单一学期的混合课程样本数据构建预测模型时,预测结果准确率较低,但在样本数据量增加后,预测结果准确率高于武法提等人所得结果准确率[5]。在模型应用和优化方面,本文使用的增量学习方式优于武法提等、Wu等研究者采用的批量学习方式随机森林算法[5-6]。当不再有新数据出现时,增量学习方式可停止构建模型,并使用当前模型进行预测。因此,相较于批量学习方式的算法,在院校层面,增量学习方式更适用于构建过程性的学生学情监测系统,随时分析学生学习状态。在教师层面,增量学习方式构建的模型可帮助教师积累学生学习数据,为教师持续优化教学设计、教学方法和教学策略。在学生层面,增量学习方式更适于实现精准的过程性学生评价,分析学生在不同学习阶段的特征,为学生变更学习策略、学习路径持续提供帮助。
(二)样本特征对增量学习方式构建的成绩预测模型结果准确率影响
为分析在增量学习方式构建模型过程中对样本的预测准确率变化,研究记录了增量学习方式模型数据输入后得到的预测结果准确率变化(如图5所示)。增量学习方式算法在使用2018秋季学期的22门课程中学生样本构建的预测模型得到的平均预测结果准确率较低(参考表3和图4的结果),且对每门课程的预测结果准确率波动较大,直至22门课程的数据全部输入也未能显示出收敛的趋势(预测准确率标准差为0.104)(如图5所示)。
增量学习方式对2020年春季学期混合课程构建的预测模型不但平均准确率略高于批量学习方式(参考表3和图4的结果),且在第41门课程数据输入后预测准确率波动下降。经统计,前40门课程增量学习方式预测结果准确率标准差为0.077,最后11门课程预测结果准确率标准差为0.025。
为进一步分析增量学习方式输入41门课程数据后预测结果准确率的变化情况,记录了两学期数据合并后(73门课程)使用增量学习方式所得预测结果准确率的变化(如图5所示),结果发现前40门课程数据输入时预测结果准确率标准差为0.087,后33门课程数据输入时预测结果准确率标准差为0.018。可见在本文研究中,超过41门课程数据输入后,可大幅降低增量学习方式的预测结果准确率波动。
Kulkarni & Ade的研究中,虽然获得了较高的平均预测结果准确率,但是所有的增量学习方式的预测结果准确率都会随样本数量增加而逐步降低[11]。本文所得结果发现,当数据样本量达到一定规模后,预测结果准确率逐步上升。Ade & Deshmukh的研究发现增量学习方式的预测结果准确率不会收敛到固定值[20]。本文结果同样证实了该发现,且本文结果还发现在超过41门混合课程的數据后,预测结果准确率的波动会大幅度减小。另外相比Sanchez-Santillan 等人的研究[10],在本文分析的三类混合课程数据中,样本数量最大的预测模型取得了最好的预测结果准确率。
本文所用增量学习方式改进了采用混合课程学生样本构建预测模型时,样本数量增长引起预测结果不稳定的问题,与在完全在线课程中的研究结果类似,即数据量越多,预测结果准确率越高[8]。另外,本文中使用的三类数据集都是“高活跃型混合课程”,这类课程中学生的行为模式较为相似。Yang 等人指出,在增量学习过程中,局部数据集与整体数据集的相似性有助于增量学习方式的决策树算法构建更准确的预测模型[26]。因此,可以认为本团队以往对混合课程的提前分类使每门混合课程的学生行为数据特征都较为相似,提升了增量学习方式构建预测模型所得结果的平均准确率,减小了每次增加数据时所得预测结果准确率的波动。
五、研究结论及局限性
在混合课程中,持续分析学生的学习过程,预测学生学习成绩并在不同学习阶段为学生提供精准的个性化学习支持是混合教学研究中的重要问题。本文分析了在混合课程情境下,增量学习随机森林算法与批量学习随机森林算法在不同数量混合课程学生样本中构建的预测结果准确率及预测结果准确率变化。研究发现:(1)增量学习随机森林算法在混合课程样本最多的数据集中可获得最高预测结果准确率(75.1%)。(2)相较于批量学习随机森林算法,增量学习随机森林算法在数据样本量较多的情况下预测结果准确率高于批量学习算法。(3)当样本数量达到一定规模后,预测结果准确率波动减小,且每门混合课程的学生行为数据较为相似,也为提升预测结果平均准确率、减小预测结果准确率波动提供了帮助。
本研究中使用增量学习随机森林算法在不同学生样本数量规模中构建了学生成绩预测模型,并且比较了增量学习与批量学习两种方式构建学生成绩预测模型的结果准确率。结果发现增量学习随机森林算法在样本数量较多时,预测结果准确率高于批量学习的随机森林算法,且该方法可随时接收新数据,不断迭代和优化预测模型,相比批量学习方式在预测模型应用和对教学过程的持续分析有更大优势。但是要使用增量学习方式构建预测结果准确率较稳定的模型需要使用更多的数据进行训练,且数据样本的局部特征需要与整体特征相似。
本研究结论从随机森林算法和一所学校的混合课程中获得,是否还存在结果更优的增量学习算法,更大数量规模的学生样本中能否获得收敛的预测结果准确率还有待进一步验证。
[参考文献]
[1] 孙众,宋洁,骆力明.混合课程动态设计研究[J].电化教育研究,2017,38(7):85-90,116.
[2] 田阳,陈鹏,黄荣怀,曾海军.面向混合学习的多模态交互分析机制及优化策略[J].电化教育研究,2019,40(9):67-74.
[3] BAKER R S. Challenges for the future of educational data mining: the baker learning analytics prizes[J]. Journal of educational data mining, 2019, 11(1): 1-17.
[4] ROMERO C, VENTURA S. Educational data mining and learning analytics: an updated survey[J]. Wiley interdisciplinary reviews: data mining and knowledge discovery, 2020, 10(3): e1355.
[5] 武法提,田浩.挖掘有意义学习行为特征:学习结果预测框架[J].开放教育研究,2019,25(6):75-82.
[6] WU M, ZHAO H, YAN X, et al. Student achievement analysis and prediction based on the whole learning process[C]// 2020 15th International Conference on Computer Science & Education (ICCSE). Delft: IEEE, 2020: 123-128.
[7] VAN GOIDSENHOVEN S, BOGDANOVA D, DEEVA G, et al. Predicting student success in a blended learning environment[C]// Proceedings of the Tenth International Conference on Learning Analytics & Knowledge. New York: ACM, 2020: 17-25.
[8] ZHONG Y, YANG H, ZHANG Y, et al. Online random forests regression with memories[J]. Knowledge-based systems, 2020(201): 106058.
[9] KOTSIANTIS S, PATRIARCHEAS K, XENOS M. A combinational incremental ensemble of classifiers as a technique for predicting students' performance in distance education[J]. Knowledge-based systems, 2010, 23(6): 529-535.
[10] SANCHEZ-SANTILLAN M, PAULE-RUIZ M P, CEREZO R, et al. Predicting students' performance: incremental interaction classifiers[C]// Proceedings of the Third (2016) ACM Conference on Learning@ Scale. New York: ACM, 2016: 217-220.
[11] KULKARNI P, ADE R. Prediction of student's performance based on incremental learning[J]. International journal of computer applications, 2014, 99(14): 10-16.
[12] GENUER R, POGGI J M, TULEAU-MALOT C, et al. Random forests for big data[J]. Big data research, 2017, 9: 28-46.
[13] WU Y, CHEN Y, WANG L, et al. Large scale incremental learning[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach: IEEE, 2019: 374-382.
[14] ZHENG S, LU J J, GHASEMZADEH N, et al. Effective information extraction framework for heterogeneous clinical reports using online machine learning and controlled vocabularies[J]. JMIR medical informatics, 2017, 5(2): e12.
[15] BORN A. Predicting students' assignment performance to personalize blended learning[D]. Munich:Ludwig Maximilian University of Munich,2017.
[16] LUO Y, CHEN N, HAN X. Students' online behavior patterns impact on final grades prediction in blended courses[C]// 2020 Ninth International Conference of Educational Innovation through Technology (EITT). Porto: IEEE, 2020: 154-158.
[17] GENG X, SMITH-MILES K. Incremental Learning[J]. Encylopedia of biometrics, 2009(1): 730-737
[18] POLIKAR R, UPDA L, UPDA S S, et al. Learn++: an incremental learning algorithm for supervised neural networks[J]. IEEE transactions on systems, man, and cybernetics, part C (applications and reviews), 2001, 31(4): 497-508.
[19] ASIAH M, ZULKARNAEN K N, SAFAAI D, et al. A review on predictive modeling technique for student academic performance monitoring[C]// MATEC Web of Conferences. Sibiu: EDP Sciences, 2019, 255: 03004.
[20] ADE R, DESHMUKH P R. Instance-based vs batch-based incremental learning approach for students classification[J]. International journal of computer applications, 2014, 106(3).
[21] SHAHIRI A M, HUSAIN W. A review on predicting student's performance using data mining techniques[J]. Procedia computer science, 2015(72): 414-422.
[22] NESPEREIRA C G, ELHARIRI E, EL-BENDARY N, et al. Machine learning based classification approach for predicting students performance in blended learning[C]// The 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), November 28-30, 2015, Beni Suef: Springer, Cham, 2016: 47-56.
[23] JIAN Y, YE M, MIN Y, et al. FORF-S: a novel classification technique for class imbalance problem[J]. IEEE access, 2020(8): 218720-218728.
[24] RASCHKA S. Model evaluation, model selection, and algorithm selection in machine learning[EB/OL].(2018-11-10)[2021-05-20].https://sebastianraschka.com/blog/2018/model-evaluation-selection-part4.html.
[25] SHMUELI B. Multiclass metrics made simple, part I: precision and recall[EB/OL]. (2019-07-02)[2021-05-20]. https://towardsdatascience.com/multi-class-metrics-made-simple-part-i-precision-and-recall-9250280bddc2.
[26] YANG Q, GU Y, WU D. Survey of incremental learning[C]// 2019 Chinese Control And Decision Conference (CCDC). Nanchang: IEEE, 2019: 399-404.
