基于Spark的大数据计算模型
2016-08-19王磊时亚文
王磊++时亚文
摘要:作为第三代机器学习工具,spark被视为替换Hadoop的下一代数据处理解决方案.包括了迭代计算、批处理计算、内存计算、流式计算、数据查询分析计算及图计算,提供了强大的内存计算引擎.Spark有望成为下一代大数据热门框架.研究分析了Spark组件生态圈和Lambda架构.最后介绍了Spark应用于机器学习领域.
关键词:机器学习;spark;Hadoop
中图分类号:TP301 文献标识码:A 文章编号:1009-3044(2016)20-0007-02
Abstract:As the third generation of machine learning tools, spark is considered as the next generation of data processing solution to replace Hadoop, including the iterative calculation, batch calculation, memory computing, flow calculation, data query analysis and graph calculation. It provides a powerful memory computing engine.Spark, which is the next generation of big data popular framework.
Key words:Machine learning; spark; Hadoop
大数据通常分为批量数据流及实时数据流。两种流类型都有各自解决方案,前者通常采用MPI、OpenMP及Hadoop等并行模型进行集群计算,后者采用流数据模型进行处理,如
Storm、S4及Spark Streaming。IBM研究院Sun[1]等认为MapReduce计算模型在倒排索引、kNN分类等批量处理的数据挖掘或统计机器学习算法中有较好效果,K-Means、高斯混合、PageRank、LDA等需要多次迭代的算法用MapReduce模型也有较好效果,缺陷是MapReduce计算模型在大量数据同步的算法如SVM中效果不佳,因此Spark集群计算平台应运而生。
1 Spark模型介绍[2]
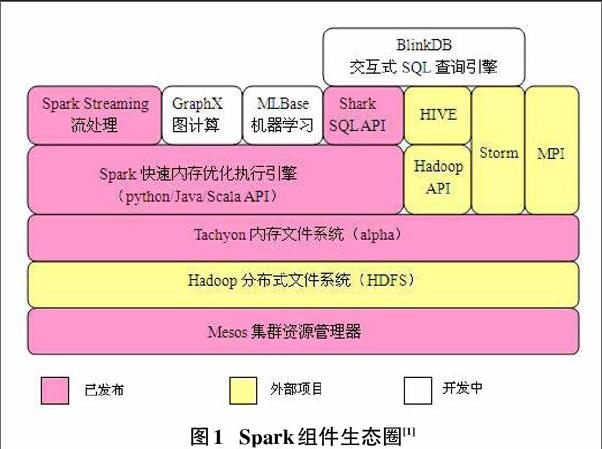
Spark是UC Berkeley AMP lab开发的开源集群计算平台,是以内存计算为基础的集群计算框架。Hadoop模型中的MapReduce模式的缺陷是运行速度慢,比较适合离线的任务分解,运行程序时需要复制额外的信息,序列化和磁盘I/0所带来的时间空间开销代价也比较大,Spark模型基于内存计算而且执行作业是基于构建的Stage有向无环图,Spark模型运行速度快的主要原因是算子融合和有向无环图,Spark模型设计和内核处理模式较适合进行大规模信息处理。Spark组件生态圈如图1。
2 Spark在RDD中的编程模型[3,5]
RDD(Resilient Distributed Datasets)弹性分布式数据集是分布式内存的一个抽象概念,RDD设计了一种高度受限的共享内存模型,通过在其他弹性分布式数据集执行确定的转换操作而创建,这些限制使得容错实现的开销代价降低。
Spark的设计思想是在任务和数据的容错方式基础上,设计出一种全新的容错方式模型,能够减少网络流量及磁盘输入输出开销。RDD是一种只读数据块,可以通过从存储系统上读取数据或者进行其他RDD操作。RDD数据的只读特性表示如果对一个RDD数据块进行了操作,那么结果将会是一个新的RDD,这种情况放在代码情景下,假设变换前后都是使用同一个变量表示这一RDD,RDD里面的数据意义并不是真实的数据,而是一些元数据信息。
Spark提供多种计算方式,使其他成为高效的数据流水线,提供了复杂查询,流式计算、机器学习、图计算等功能。Spark支持scala、python和java评议,提供了shell,方便与用户交互。Spark可以运行在Hadoop数据源上,如HDFS、Hive、HBase等,这样的一种特征,可以让Spark开发者及用户轻易地从原系统迁移到Spark系统上来。
3 Spark架构思路[1,7]
Spark计算模型采用Lambda Architecture架构处理批量及实时流数据,Lambda Architecture架构分为三层:包括Batch Layer批处理层、Serving Layer服务层以及Speed Layer速度层。
其中批处理层设计基于Hadoop计算模型,在Spark平台上开发的图计算框架GraphX和机器学习库Mllib可作为批量数据分析。服务层可以接收外部ad-hoc查询请求,利用Shark等索引服务对批量处理层的结果进行索引,完成准实时的SQL查询任务。速度层采用Spark Streaming分布式的流处理平台实时处理数据成查询处理。
4 Spark实现机器学习算法[3,8]
4.1 Spark中的逻辑回归算法
JavaHdfsLR是逻辑回归分类算法的Spark实现,采用渐进梯度下降模型。使用SGD加上诸如牛顿-拉普森的近似法来预测似然函数。输入数据集及输出结果都是Hadoop分布式文件系统中的文件。
4.2 Spark中的支持向量机
使用SVMModel的内部类来表示训练过程中返回的模型对象以及SVMWithSGD。支持向量机的工作流:
1)创建Spark上下文。
2)加载已标记的输入训练数据,SVM中用到的标记必须是{0,1}。
3)使用由{label,features}对及其他输入参数组成的RDD输入来训练模型。
4)使用输入数据来创建一个类型为SVMWithSGD的对象。
5)调用GenerallizedLinearModel重写后的run()方法,它会使用预配置的参数在输入RDD的LabeledPoint上运行算法,并对所有输入特征的初始权重进行处理。
6)获得一个SVM模型对象。
7)终止Spark上下文。
5 总结
作为第三代机器学习工具,spark被视为替换Hadoop的下一代数据处理解决方案.包括了迭代计算、批处理计算、内存计算、流式计算、数据查询分析计算及图计算,提供了强大的内存计算引擎.Spark有望成为下一代大数据热门框架.研究分析了Spark组件生态圈和Lambda架构.最后介绍了Spark应用于机器学习领域。
参考文献:
[1] 唐振坤.基于Spark的机器学习平台设计与实现[D].厦门大学,2011.
[2]http://baike.baidu.com/link?url=NjUeVoyTiUBYebTHNOyw3 9VNZ1Yn9OMPz-SMujvalpeDTbcwuYNOQS5xRQttjvtXa3mO O5QdAI3Ho_H4dgsg8tywKzdDg_w3ZURoiHOCYK7百度学科
[3] Vijay Srinivas Agneeswaran.颠覆大数据分析:基于Storm、Spark等Hadoop替代技术的实时应用[M]. 吴京润,黄经业,译.中国工信出版集团,电子工业出版社,2015.
[4]胡俊.基于Spark的大数据混合计算模型[J].计算机系统应用2015,24(4):214-218.
[5]杨志伟.基于Spark平台推荐系统研究[D].中国科学技术大学,2015.
[6]李爽.基于Spark的数据处理分析系统的设计与实现[D].北京交通大学,2015.
[7] 梁彦.基于分布式平台Spark和YARN的数据挖掘算法的并行化研究[D].中山大学.2014
[8]Nathan Marz, James Warren.Big Data: Principles and Best Practices of Scalable Realtime Data Systems.2015.
