城市场景中车联网时空数据分析及其通达性方法
2021-07-16程久军原桂远崔杰周爱国吕博李光耀
程久军,原桂远,崔杰,周爱国,吕博,李光耀
(1.同济大学嵌入式系统与服务计算教育部重点实验室,上海 200092;2.安徽大学计算机科学与技术学院,安徽 合肥 230601;3.同济大学机械与能源工程学院,上海 200092;4.上海师范大学天华学院,上海 201815;5.同济大学电子与信息工程学院,上海 200092)
1 引言
车联网是一种可以实现车辆与其他网络通信的动态网络。在车联网中,车辆通过传感器收集自身及周围车辆、道路和环境信息,对采集的时空数据进行分析和发布,为用户提供各种应用服务,例如车辆远程诊断[1]、视频下载[2]、隐私保护[3-4]、数据传输[5-6]等功能。因此,车联网时空数据分析及其通达性至关重要。
随着传感器技术的发展,车辆可以在运动过程中获取自身状态并感知周围环境。同时,车辆可以通过车车通信获取其他车辆的速度、加速度、地理位置等信息。然而,目前缺少统一的车辆数据采集存储标准,不同传感器存储的数据结构可能相差很大。另外,在城市场景中,由于建筑物的遮挡和其他因素干扰,时空数据可能存在噪声和数据丢失的问题。需要有效的车联网时空数据分析方法进行数据的整合、噪声去除和填充,为车联网应用提供数据支持。
按照有无路边基础设施支持,车联网可分为有基础设施的车辆网络和车辆自组织网络。与车辆自组织网络不同,在城市场景中车联网具有路边基础设施支持,车辆之间不仅可以通过车车通信实现连通,也可以跨路边基础设施实现连通。然而,路边基础设施带宽有限,不能为所有车辆提供数据转发服务。因此,需要实时准确地检测车联网中不能通过车车通信实现连通的子网,并通过路边基础设施实现车辆之间的连通,保证拓扑结构发生变化时车联网的通达性。
与高速公路场景下的车联网相比,城市场景中的车联网具有以下特点。1) 车辆运动受到其他车辆和红绿灯的影响,行车环境更加复杂。2) 车辆数量较多,车联网规模较大。同时,由于红绿灯和路网结构的影响,车辆可能存在分布不均匀的现象。3) 由于建筑物的遮挡,距离小于通信范围的车辆之间可能不能直接建立通信链路。同时,受各种干扰因素的影响,车辆之间的通信链路会频繁地断开重连,预估车辆之间在未来一段时间内保持连通的可能性更加困难。因此,高速公路场景下的车联网通达性不完全适用于城市场景中的车联网。
本文提出一种城市场景中车联网时空数据分析及其通达性方法,主要贡献包括以下两点:1) 提出一种车联网时空数据分析方法;2) 提出一种城市场景中车联网通达性方法。
2 相关工作
在车联网时空数据分析方面,文献[7]总结了当前车联网时空数据分析面临的挑战:找到合适的过滤器提取有价值信息;将无用和冗余信息剔除;利用有效的方式对数据进行表示和分析;建立有效的预测模型进行交通管理。当车联网网络负载不足以支撑车辆间数据传输时,文献[8]将路网进行划分,将车辆映射到划分出的格子中,以交通密度、带宽、时延和花费作为指标对车辆的网络接入进行评价,从而对车辆接入传统网络或车联网以及车联网中哪个节点进行决策,最终使车辆获得较好的服务质量。针对传统的关系型数据库和数据库管理系统对给定时间周期和数据维度的查询支持度不够的问题,文献[9]在静态R 树结构上使用希尔伯特曲线和HBase 技术,使模型对范围查询和k 近邻查询都有较好的性能表现。文献[10]分析了车联网的特性,将车联网中的数据流比拟为流体,推导出网络特性描述方程,然后,基于网络特性描述方程推导出车联网网络容量计算模型,该模型分析了网络规模和网络时延对网络容量的影响,得出了网络容量下降的原因。文献[11]提出了一种基于并行数据挖掘的轨迹数据模式发现方法,并构建了知识模型捕捉用户移动行为。该轨迹数据模式发现方法可用于车辆位置预测、旅行推荐、智能交通管理等应用和服务。针对车辆自组织网络中网络拓扑结构多变和时空数据复杂的问题,文献[12]提出了一种基于贝叶斯联盟博弈和学习自动机的车辆节点联合处理时空数据的方法。
车辆快速移动导致车联网拓扑结构频繁变化和节点之间通信链路不稳定,这些特性使车联网通达性面临2 个挑战:构建准确描述车辆运动的模型;基于车辆运动模型构建车联网通信协议实现车辆之间的互联互通。文献[13]研究了高速公路场景中车联网的连通性,分析了在特定路段上车辆之间连通概率与连通集直径、连通集数目、车辆密度和车辆传输距离之间的关系。分析结果表明,当车辆进入高速公路是泊松过程时,车联网中车辆位置满足伽马分布。通过统计道路的交通密度、交叉路口和路段等道路信息,文献[14]提出了一种道路感知路由协议,并研究了路由协议的恢复机制和性能指标。实验结果表明,即使在交通密度较高的情况下,文献[14]协议依然无法避免网络分裂的现象,也不能保证网络整体连通;要达到减少网络分裂的目的,可借助反向运动车辆实现信息转发和增加节点通信距离。文献[15]分析了高速公路场景中车辆之间的连通性,研究了车辆进入高速公路的速率、车辆速度以及车辆离开高速公路的概率等参数对连通性的影响。针对大规模车联网互联互通耦合度低的问题,文献[16]通过一种车联网连通基的网络拓扑结构,提出了分布式连通基构造方法,针对大规模车联网通达性问题,作者结合平滑高斯−半马尔可夫移动模型研究了连通基的内部结构属性和动态特性,对动态环境下车联网的通达性进行评估。在大规模车联网中,连通基可用于转发数据包,进而实现车辆节点之间的连通。针对车辆自组织网络拓扑结构频繁变化导致的连通易变问题,文献[17]提出了一种基于自编码网络和循环神经网络的车辆自组织网络连通预测方法和一种基于连通预测的动态分簇方法,细化了簇内角色,研究了节点之间数据转发的代价,给出了车辆之间连通路径构造方法。
在车联网时空数据分析方面,大多数研究对车联网实时性以及拓扑结构变化快的特性考虑不足。另外,在车联网通达性研究方面,大多数研究集中在网络整体通达性,只总结各个参数对通达性的影响,缺少对节点间通达性的研究。
3 城市场景中车联网时空数据分析
3.1 相关定义
定义1城市场景中的车联网可表示为
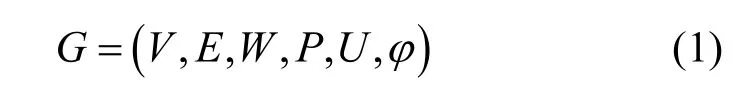
定义2车辆vi在t时刻的特征可表示为

其中,s表示vi的速度,a表示vi的加速度,p表示vi的位置,ρ表示vi所处的路段,u表示vi关联的路边基础设施。
3.2 基于噪声去除和数据填充的时空数据处理
3.2.1 噪声去除
假设vi在t时刻的位置为p,在时刻的位置为,如果vi的速度与加速度方向相同,则

然而,车辆的加速度与速度之间可能存在夹角,式(3)估计的车辆位置可能不够准确。为了判断传感器采集的车辆位置是否准确,给出车辆位置可信区域。可信区域的4 个顶点的坐标为

其中,p1、p2、p3、p4分别表示可信区域的左下角、左上角、右下角、右上角坐标,θ表示s与a之间的夹角,ι表示车辆在t时刻与时刻位置之间的距离。
若位置传感器采集的车辆位置位于可信区域内,则保留数据;否则判定采集的数据为噪声,将其去除。
3.2.2 时间性自相关数据填充
本文针对噪声去除导致少量数据丢失的问题,从时间角度分析车辆的数据,对丢失数据进行估计,进而达到数据填充的目的。传统的指数平滑方法[18]在进行数据填充时仅考虑过去一段时间传感器的采样值,没有考虑未来一段时间传感器的采样值。为此,本文改进了指数平滑方法,将其用来填充车联网数据,填充时不仅考虑填充时间前传感器采集的数据,而且考虑数据丢失时间后传感器采集的数据。本文将该数据填充方法定义为时间性自相关数据填充,即

其中,Δt表示传感器采样的时间间隔,η表示数据填充窗口的大小,α(α∈(0,1))表示平滑系数,f(vi,t−jΔt)表示数据丢失时间t之前传感器采集的数据,f(vi,t+jΔt)表示数据丢失时间t之后传感器采集的数据。
3.2.3 时空性协同过滤数据填充
路网匹配[19]将前后轨迹数据映射到路网中,对可能的轨迹进行评价,从而选取概率最大的一条作为填充数据,但存在对应时间点的参数预测困难的问题。虽然节点状态变化频繁,拓扑结构每时每刻都在更新,但由于路网的存在,最佳路线选取的策略几乎一致,在某时间点连通的两辆车在过去和未来都可能存在相似的轨迹和状态。尤其是在高速路段以及工作日早晚高峰,车辆的目的地极其相近,所以可以借助这些轨迹相似的车辆对目标车辆的空值数据段进行填充。协同过滤[20]的核心思想是用向量描述用户的历史信息,然后计算用户之间的相似性,再通过与目标用户相似性较高的邻居对其产品的评价,从而得到目标用户对特定产品的潜在需求程度,系统根据计算到的结果进行针对性推荐。将协同过滤的思想用到车联网数据填充上,关键是对车辆之间的相似性进行计算。针对传感器故障等问题导致大量数据丢失的问题,本文提出一种基于路网匹配的时空性协同过滤数据填充方法。
假设vi在t到之间的特征需要进行填充,时刻vi的邻近节点集为

vi与在时刻的相似度为

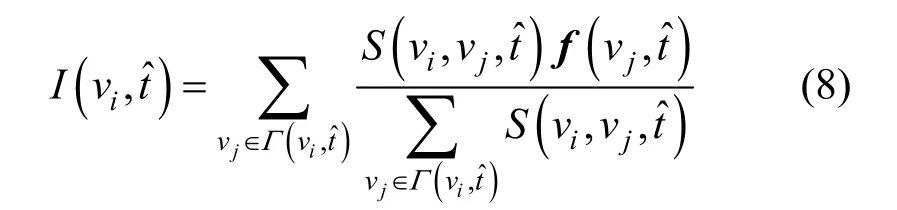
3.3 基于特征压缩的时空数据降维
1) 特征无量纲转化
假设f(vi,t)中的第j个特征为fj(vi,t),使用max-min 方法将fj(vi,t)缩放至[0,1],即

2) 基于主成分分析的特征降维
假设所有车辆在t时刻的特征为,其协方差矩阵为


将车辆特征向量与协方差矩阵特征向量相乘后,选择值最大的m个维度作为车辆的特征向量,即可实现特征降维。
3.4 基于张量因子聚合的神经网络构建
张量神经网络[21]结合了单层模型和潜在因子模型,是一种将两者特点结合在一起扩展产生的模型。数据抽取过程及基于张量因子聚合的神经网络结构如图1 所示。
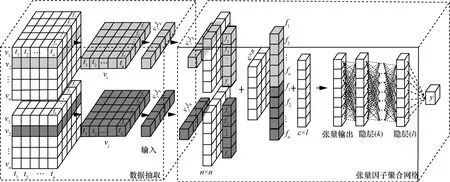
图1 数据抽取过程及基于张量因子聚合的神经网络结构
通过改进张量神经网络,给出适用于车联网的张量因子聚合层,张量因子聚合的输出为

基于张量因子聚合构建神经网络,用于预测车辆之间的连通强度,其目标函数为

对时空数据去噪、填充和降维后,整合存储为训练数据集。使用训练数据集和梯度下降优化目标函数,通过梯度下降迭代求解目标函数,得到最小化的目标函数和基于张量因子聚合的神经网络的参数值。
4 城市场景中车联网通达性
4.1 相关定义
定义3一个路边基础设施ul覆盖范围内的车联网可表示为

定义4的拉普拉斯矩阵为

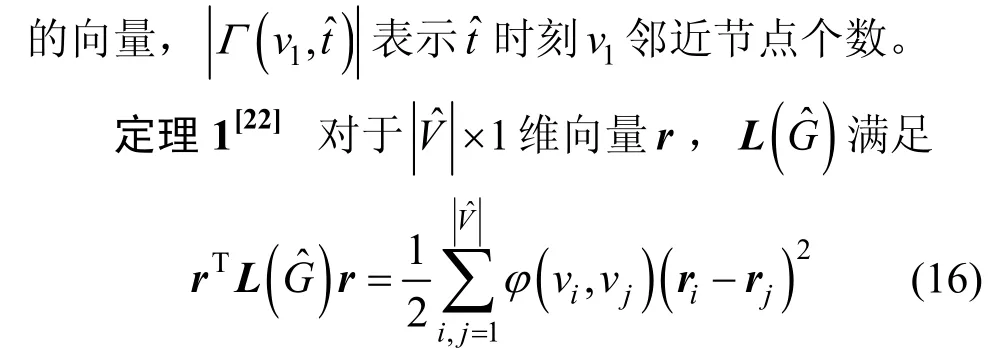
4.2 基于拉普拉斯矩阵的弱连接检测

所以,最小化特征值z并找到其对应的特征向量即可找到车联网中的弱连接。根据之前提到的性质,的最小特征值z对应特征向量为→。根据Rayleign-Ritz 理论[22],不符合→条件,故取第二小特征值。如果将划分为l组,则变成取前l个特征值及其特征向量。
小班化教学给实践活动提供了极大的便利,教师要在实践活动中关注学困生,通过实践活动磨炼学困生的意志,陶冶学困生的情操,为学困生的成长提供广阔的天地。很多学困生虽然学习成绩不佳,但是他们的实践能力较强,在实践活动中十分活跃。教师应缩短与学困生的心理距离,鼓励他们积极参与实践活动,在潜移默化中向学生渗透学习思想和道德品质等。联系生活实际,讲述学科知识在实际生活中的应用,为学困生创设与教学资料有关的情境,引发他们的好奇与思考。同时,分层活动是帮助学困生体验成功的有效方法,可开展分层学科竞赛,达到人人都有发展的目的。
4.3 连通候选节点集构建
弱连接检测可以发现车联网中容易断开的边。为了解决弱连接检测的边断开而导致整个网络出现不连通的问题,本文提出一种连通候选节点集构建方法。首先,给出当前不连通的2 个车辆在未来时刻可能连通的度量方法,即

其中,Γmax表示车辆邻近节点的最大个数。
在弱连接检测的边断开后,一个路边基础设施下的车联网划分为若干不连通的子网,从不连通的子网中选择最大的2 个节点作为连通候选节点。
4.4 基于启发式搜索的通达性算法
本节给出一种基于启发式搜索的通达性(HA,heuristic-search-based accessibility)算法,在通达性路径搜索过程中,消耗函数、未完成度函数和评价函数分别为

其中,C(P) 表示消耗函数,B(P) 表示未完成度函数,K(P) 表示评价函数,P表示连通路径,表示连通路径的最后一个路段与数据接收节点所处路段之间的距离。
HA 算法的具体过程如算法1 所示。首先,遍历数据发送节点周围的连通候选节点,若它周围没有连通候选节点,则使用路边基础设施进行数据转发(步骤5)~步骤6));否则,将连通候选节点加入连通路径集合(步骤7)~步骤8))。然后,重复选择连通路径集合中的节点,使用评价函数选择连通路径的下一跳节点(步骤11)~步骤21))。最后,基于连通路径集合构建发送节点到接收节点的连通路径(步骤23)~步骤26))。
算法1HA 算法
输入发送节点v1,接收节点v2


5 仿真实验与结果分析
5.1 仿真实验环境
仿真实验采用NGSIM 项目采集的数据集[23]。该数据收集位于美国加利福尼亚州洛杉矶的Lankershim Boulevard 路段的车辆行驶轨迹数据。仿真实验使用2005 年6 月16 日8:28—8:45 时间段的车辆及道路信息。仿真实验参数如表1 所示。

表1 仿真实验参数
5.2 时空数据分析仿真实验结果
为了评价车联网时空数据分析方法,本文对比了使用原始数据与处理后数据的网络性能。从传统反向传播(BP,back propagation)神经网络和基于张量因子聚合的神经网络的数据体积、平均错误率、训练速度3 个指标进行评价,结果分别如图2和图3 所示。与使用原始数据相比,BP 神经网络使用处理后的数据可以降低18%的数据体积和21%的平均错误率。在对比神经网络训练速度时,保持网络的优化方法、学习率、批处理规模等参数不变,对比神经网络使用原始数据与处理后数据的训练速度。由图2 可知,BP 神经网络使用处理后的数据可以提高12%的训练速度。与使用原始数据相比,基于张量因子聚合的神经网络使用处理后的数据可以降低20%的数据体积和30%的平均错误率,可以提高40%的训练速度。

图2 时空数据处理前后BP 神经网络的性能对比

图3 时空数据处理前后基于张量因子聚合的神经网络的性能对比
基于张量因子聚合的神经网络输出2 个车辆之间的连通强度,1 000 对车辆的误差分布如图4 所示。横坐标表示连通强度预测值与实际样本值的误差,纵坐标表示落在相应误差范围内的样本占比。可以看出,基于张量因子聚合的神经网络在测试集实验结果中,有81%的输出结果误差在10%内,90%的结果误差小于20%。

图4 误差分布
5.3 车联网通达性方法仿真实验结果
图5 展示了路段划分方法。图6 展示了路网中车辆数目变化情况,横坐标为时间,纵坐标为车辆数目。由图6 可知,车辆数目在30~100 辆波动。图7 展示了不同路段车辆数目变化。由图7可知,不同路段之间车辆分布不均匀,同一路段不同时刻的车辆数目变化也非常大。图8 展示了不同路段车辆密度变化。由图8 可知,车辆分布是不均匀的。

图5 Lankershim Boulevard 路段

图6 路网中车辆数目变化

图7 不同路段车辆数目变化

图8 不同路段车辆密度变化
为了评价本文所提出的车联网通达性方法,本节对比了贪婪周边无状态路由(GPSR,greedy perimeter stateless routing)算法[24-26]和路边基础设施转发(RT,RSU transmission)算法。在RT 算法中,一个路边基础设施负责转发其覆盖范围内车辆的数据,而车辆间不直接通信。
仿真实验选取路段3 车辆数目变化最频繁的200 s 数据。弱连接检测的准确性如图9 所示。不同时间的车辆连通数目如图10 所示。3 种通达性算法中车辆之间的平均时延如图11 所示。

图9 弱连接检测准确率

图10 连通数目

图11 平均时延
HA 算法的弱连接检测准确率和平均时延成反相关,即弱连接检测准确率越高,平均时延越低。弱连接检测后连通候选节点集构建可以减少由于连接断开导致网络割裂,进而解决车辆依赖路边基础设施进行数据中转导致时延上升的问题。
由图10 和图11 可知,HA 算法和GPSR 算法的平均时延在某些情况下高于直接利用路边基础设施转发的RT 算法。然而,路边基础设施带宽有限,当车辆所需带宽大于路边基础设施带宽时,路边基础设施不能为所有车辆提供数据转发服务。因为HA 算法考虑了车辆之间的连通强度,能够检测弱连接并构建连通候选节点集,避免了因为车辆间连接断开所造成的路边基础设施重新调度及通信带来的时延,因此HA 算法效果要优于GPSR 算法。
6 结束语
本文研究了城市场景中车联网时空数据分析及其通达性方法,提出了基于噪声去除和数据填充的时空数据分析方法,构建了基于张量因子聚合的神经网络预测车辆之间的连通强度;提出了基于连通强度预测的车联网通达性方法。仿真结果表明,本文所提出的车联网时空数据分析及其通达性方法具有较好的性能。
