基于改进灰狼优化的复杂网络重要节点识别算法
2021-07-16顾秋阳吴宝孙兆洋池仁勇
顾秋阳,吴宝,孙兆洋,池仁勇
(1.浙江工业大学管理学院,浙江 杭州 310023;2.浙江工业大学中国中小企业研究院,浙江 杭州 310023;3.中国标准化研究院高新技术标准化研究所,北京 100191)
1 引言
随着近年来信息技术的迅速发展,复杂网络节点间的交流、互动形式日趋多样化,由此产生海量的复杂网络数据,其中存在大量节点间的信息交互集。对上述数据进行挖掘,寻找具有影响力的节点,并基于此有效阻止负面信息传播、宣传正面信息、提升推荐效率已成为学术界关注的焦点之一。据中国互联网络信息中心(CNNIC)发布的第47 次《中国互联网发展状况统计报告》,截至2020 年12 月,我国网民规模达9.89 亿,互联网普及率达70.4%,较2020 年3 月增长5.9%;同期,我国网络新闻用户达7.42 亿,占网民整体的75.1%,社交应用使用率高达网民总量的85.5%。2019 年,国家互联网信息办公室发布的《数据安全管理办法》中,对社交网络平台提出了新的要求。网络运营者应采取措施督促提醒用户对自己的网络行为负责、加强自律,对于节点通过网络转发给其他节点制作的信息,应自动标注信息制作者在该社交网络上的账户或节点标识。这往往会选择合适的节点群体进行信息传播,而社交网络庞大的节点群体会使病毒式传播成为在线社交网络中的最大受益者[1-4]。由于进行节点选取和控制的成本有限,因此只能在复杂网络中选择一组有限数量的种子节点,使其在复杂网络中传播信息,最终实现影响力最大化问题[5]。本文需解决的问题为如何有效识别最具影响力的节点,并将其加入种子节点集中,该问题又被称为节点影响力最大化(IM,influence maximization)问题[6-8]。尽管如文献[9-10]所示,在现有的节点影响力最大化算法中,节点的行为和兴趣已被视为信息传播过程的重要因素,但此类信息并非从真实复杂网络中获得的,故只有网络结构信息可用于识别影响力较大的节点。
目前,已有学者提出多种用于复杂网络重要节点识别的扩散模型[11-13],可用于模拟信息扩散过程建模及种子节点影响力。由于节点影响力最大化问题的搜索范围往往很大,故评估所有可能的节点子集以定位最佳种子节点集为NP-hard 问题[14]。而真实复杂网络的辐射范围很广,故利用影响力最大化模型来衡量节点影响力往往较费时。常用于识别影响力最大的节点集的方法是选择中心节点,可采用多种方法来度量复杂网络结构的中心度,如网络度[15]、介数中间性[16]、紧密度[17]、k-shell[18]及改进k-shell[19]。但通过测量网络结构的中心度对影响力最大化节点进行识别通常不是解决此问题的最好方法。另外,有研究认为节点影响力最大化问题属于优化问题,并采用贪婪算法、启发式算法及元启发式算法等来解决该问题。Wang 等[20]提出了改进贪婪算法,以此求得扩散模型的最优解,尽管该算法的精度较高,但其计算过程十分复杂,故在大规模复杂网络中并不实用[21]。而Bao 等[22]针对影响力最大化问题提出的启发式算法的时间复杂度和精度较低,但启发式算法得到的值在可达局部中最优[23]。
为识别一组接近最优的具有最大影响力的节点,首先需要对节点影响力进行度量,然后找到最有影响力的节点集。本文首先使用基于Shannon 熵的指标来衡量节点影响力,并将该问题转化为优化问题,采用一种改进灰狼优化算法解决该问题[24],并利用真实复杂网络数据集进行数值计算。
2 相关工作
本文基于图论对复杂网络图进行建模,其中,节点代表复杂网络节点,边代表节点间存在的关系。首先对一些经典的扩散模型以及用于影响力最大化问题的常见方法进行回顾。扩展模型常用于模拟真实世界中的传播过程,常用的扩散模型包括阈值模型[25]、级联模型[26]和传染病模型[27]。其中,独立级联模型(IC,independent cascading)为现今应用最广泛的扩散模型之一[26],其中每个节点都处于活跃或非活跃模式中。为度量种子节点集S的影响力,将最初放置在种子节点集S中的节点定义为活跃节点,并将所有其他节点定义为非活跃节点。在每个时间段t中,时间段t−1 中被激活的每个节点都有一次机会激活其非活跃的邻节点(激活概率为p),该过程会一直持续到该时间段内没有新节点为止。最后,在此过程迭代多次后得到的激活节点数量即为节点集S的影响范围。
有关节点影响力最大化问题,现有研究可分为两大类。第一类为识别节点影响力并对其进行排序。在多数相关研究中,根据网络结构和节点网络位置,可使用中心性度量法来衡量节点影响力。虽然中心性方法计算较简单,也能较好地确定节点活跃度[28],但这类方法在识别Top-k 影响力节点时精度不高。Bao 等[22]提出了一种优化种子节点集的方法,使其总体影响范围最大化,并在考虑节点影响力的同时,考虑了网络中的节点距离,以进一步提高重要节点识别算法的有效性。第二类节点影响力最大化方法在考虑网络可达性的基础上,将该问题转化为优化问题(如贪婪算法、启发式算法、元启发式算法等)。关于贪婪算法,Kempe 等[25]对含有k个最具影响力的种子节点集S进行识别,并迭代k次,每次迭代时使用扩散模型来估计该集合的影响力。
为改善节点影响力最大化问题优化过程中存在的时间复杂度问题,研究者提出了一系列启发式算法,用于选择节点影响力最大化集合。启发式算法通过使用递归法给每个节点分配一个分数,并选择分数最高的top-k 节点作为种子节点集。Chen 等[29]提出了2 种方法用于选择种子节点集,首先以每个节点度作为影响力指标,并以k次迭代选择种子节点集。在每个步骤中,都可将影响力最大的节点添加到种子节点集中。如节点v加入种子节点集,则其邻节点影响力将会随之降低,且被选为种子节点的概率也会降低。Wang 等[30]所提度惩罚法尝试同样方法来选择种子节点集,将节点v选为种子节点,就需惩罚二跳内的所有邻节点,并降低被选为种子节点的概率。该方法可有效减少网络中种子节点的重叠现象,并增加节点分散性。Guo 等[31]提出了基于距离图对具有适当距离的节点进行识别和分类,以使各组中的节点对间距离都大于阈值。Bao 等[22]提出了启发式聚类算法,确定每对节点间的相似度,并选择各集群中影响力最大的节点作为种子节点,将节点影响最大化问题建模为多目标优化问题。
元启发式算法通常首先定义适应度函数,将节点影响力最大化问题建模为优化问题,并应用各种改进优化算法对该问题进行解决。Jiang 等[32]将种子节点集S的影响定义为预期扩散值(EDV,expected diffusion value)。Gong 等[21]引入改进EDV值,并使用粒子群优化(PSO,particle swarm optimization)算法来优化目标函数。Sun[33]用复制对称平均场理论来解决节点影响力最大化问题。本文首先定义了适应度函数,然后利用灰狼优化算法提出了一种适应度函数对重要节点识别方法进行优化。
3 算法设计
3.1 预备知识
本文首先利用熵的概念定义了适应度函数,并将节点影响力最大化问题设计为优化问题,随后利用改进灰狼优化算法解决该问题。根据Shannon 熵值,如X∈{x1,x2,…,xn},且pi为目标xi被选择的概率,其中,可根据式(1)计算X的熵。

灰狼优化(GWO,gray wolf optimization)算法[24]是一种基于种群的演化算法,其灵感来源于灰狼的狩猎行为。如图1 所示,灰狼遵循严格的社会等级制度,在社会中主要分为α、β、γ、δ这4 种。α狼、β狼及γ狼在狩猎过程中主要负责攻击,而δ狼在团队中扮演替罪羊的角色。根据不同狼的特征,可将GWO 算法建模如下。首先,随机生成一组解,使得每个解都与一头狼相对应,以表示其位置。其中,适应性排名第一的为α狼,适应性排名第二和第三的分别为β狼和γ狼,剩余则为δ狼。该算法根据α、β、γ狼的位置进行空间搜索,以找到猎物的位置(即最优解)。上述3 种狼可以预测猎物位置,而δ狼则根据另外3 种狼的位置来改变自身位置,从而找到离猎物更近的位置,该算法尝试在迭代过程中找到最优解。在每次迭代过程中,δ狼都会试图根据其他狼群的位置来改变自身位置。在每次迭代t中,δ狼都会根据迭代次数t+1确定自身的新位置,即Xi(t+1),具体如式(2)所示。

其中,每只δ狼都会试图根据Y1、Y2、Y3来确定更优位置,Y∈[Y1,Y2,Y3]值可根据狼的当前位置和α狼的位置计算得到,具体如式(3)所示。

其中,Dα的计算式为
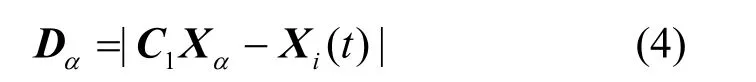
其中,t表示当前迭代次数,Xi(t)表示本次迭代中狼i的位置,而Xα表示α狼的位置。结合β狼和γ狼的当前位置,利用式(5)可计算得到Y2和Y3的值。

其中,Dβ和Dγ的值可由式(6)计算得到。

其中,Xβ和Xγ分别表示β狼和γ狼的位置,A和C分别表示如式(7)所示的系数向量。

其中,r1和r2表示区间[0,1]内的随机值,a值为迭代过程中从2 线性趋近于0 的控制参数。a值在时段t中的计算方法如式(8)所示。

其中,maxt表示重要节点识别算法的迭代次数。在迭代过程中,狼群间的位置矛盾减少,算法逐渐收敛,最后得到α狼最优解,并将其作为最优解决方案。经典灰狼优化算法的执行过程如算法1 所示[25],其中n表示种群规模。
算法1灰狼优化算法
输入狼α,β,,γ δ的位置
输出集合{xα,xβ,xγ,xδ}

本文使用无向图G=(V,E)对复杂网络图进行建模,其中,V={v1,v2,…,v|V|}表示复杂网络节点集,E表示节点间的关系边集。边ei,j∈E表示2 个节点vi和vj间的距离,且这2 个节点为邻节点。N i⊂V表示节点vi的邻居,di=|Ni|表示节点vi的影响力。表示节点vi的二跳邻节点(即邻节点的邻节点)。节点影响力最大化问题的目标是识别具有k个节点的集合S,以启动传播过程,从而使传播影响最大化,即激活节点数量最大化。在本文的其余部分中,S′表示种子节点集S中节点的邻节点或二跳邻节点的节点集合。
3.2 适应度函数
本文选择节点作为种子节点集中的节点,其中每个节点都具有较高影响力,且选择的集合尽可能地覆盖整个网络,以保证信息传播最大化。在传播过程中,节点vj S′∈ 被激活,即接受信息,可使用式(9)进行计算。

其中,pi,j表示信息从vi传播到vj的概率。式(9)可用来计算节点vj收到其邻节点发送信息的概率,且其邻节点都为S集成员。如果节点vj在S集中没有邻节点,则可将其视为零集合。而式(9)等号右边第二项可用来计算节点vj收到其二跳邻节点发送信息的概率,且其二跳邻节点也为S集中的成员。这两部分都根据概率规则进行求和,在传播过程中不同节点不会产生相同影响。如果影响力较大的节点接收到该信息,则其可能会传播至复杂网络的其他领域,各节点v j∈S′值。本文所提基于改进灰狼优化的重要节点识别算法中,适应度函数为。使用本文所提IGW-CNI算法寻找种子节点,以使S′集中的节点数量最大化,且其中所有节点都具有较大影响力。在运用求和运算符后,将S′集中有限的具有较高价值的节点和无价值节点相组合,使适应度函数计算得到的值实现最大化。在此情况下,如果无法将信息传播给有影响力的节点,会导致所选节点的影响力大幅降低。在适应度函数中使用熵来解决此问题,使节点在S′集中的均衡节点能更有效提升集S的影响力。另一方面,熵值随着S值的增大而增大,故需进行归一化。集S的适应度熵值可定义为
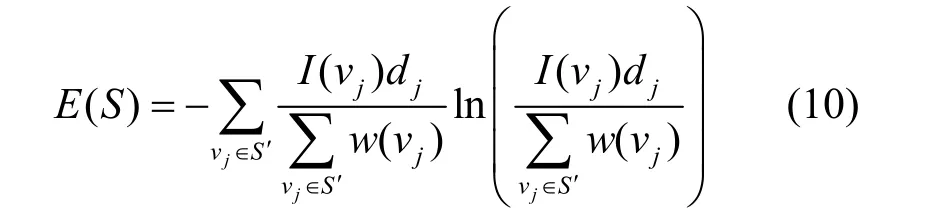
3.3 改进灰狼优化算法
参考文献[34]的结论可知,度为1 的节点被选为种子节点的概率非常低。在许多真实复杂网络中,大部分节点只存在一个邻节点。为有效降低本文所提IGW-CNI 算法的时间复杂度,仅将影响力大于1 的节点选为候选种子节点,并将这些节点表示为。而每只狼(即每个解)都存在2 个属性,即位置和对应的种子节点集。狼i的位置可表示为带有节点|V′| 的向量xi,其中第j个节点表示节点被选为种子节点的概率。狼i对应的种子集为Si,其中包含k个节点,且其值在Xi中最高。
算法2 给出了本文所提IGW-CNI 算法的具体流程。首先,随机生成n个主要解,并利用随机位置函数生成每个随机解;其次,利用式(10)来计算解的适应度值,并根据解的适应度值来选择确定α、β、γ狼。进行maxt次迭代操作,以最大化适应度。在每次迭代过程中,更新δ的位置,并给出更新后的位置。为每只狼i确定种子集Si,而后计算每个子集Si的适应度值,并根据适应度值,将最佳解更新α、β、γ狼;随机更新β、γ狼的位置,避免产生局部最优解。
算法2本文所提IGW-CNI 算法
输入图G=(V,E),种子集规模k,群体规模n,迭代周期maxt
输出集合,不同参数下的种子集S

在本文所提IGW-CNI 算法中,利用随机位置函数生成基本解i(狼i的基本位置Xi及其对应的种子节点集Si),该函数的运行机制如文献[13]所提算法所示。其中,给每个节点vj V′∈ 赋随机值Xi,j,并将该随机值作为该节点被选为种子节点的概率,且该概率与节点的影响力成正比。在本文所提IGW-CNI 算法中,根据α、βγ、狼的位置来更新δ狼的位置,以期获得更优位置。故基于此设置了更新位置函数,该函数进程如文献[12]所提算法所示。其中,为更新节点vj在狼i,即Xi,j中的概率,参考了该节点为α、β、γ的位置Xi,可计算Y1、Y2、Y3的值,并相应计算Xi,j(t+1)的值。通过计算每个节点v j∈V'的Xi,j(t+1)值,将迭代周期t+1内狼i的位置更新为Xi(t+1),并更新Xi中的Xi,j,以对每个Xi,j(j∈1,…,|V′|),都在多次迭代中更新狼i的位置,重复此计算可更新每次迭代中狼的位置。
4 数值算例
4.1 数据说明与参数设置
为证明本文所提IGW-CNI 算法的有效性,本文使用4 个真实复杂网络数据集进行数值模拟,以便观察算法对现实情况的适应度(实验中使用的真实复杂网络数据集特征如表1 所示)。其中,激活率为节点激活概率,根据网络图的稀疏性进行设置,并基于网络节点度和二阶度的平均值进行计算。本文使用Python 软件以近期的热点事件“HUAWEI event”和“华为事件”的30 个热点评论节点作为初始节点,分别爬取Facebook、Twitter、新浪微博和豆瓣的复杂网络节点数据集作为仿真实验的基础数据集(爬取时间为2020 年4 月23 日至2020 年11 月16 日)。本文将每个节点作为一个节点,使用节点间的边界表示节点间的关系。本文选择了10 个具有较强影响力的节点及其邻节点列表作为复杂网络初始节点,以此生成了简单复杂网络。实验在MATLAB 2017b 环境下实施,并在Windows10操作系统的服务器(Intel Xeon 处理器(34 GHz)和32 GB 内存)上进行。

表1 复杂网络数据集说明
为评估本文所提IGW-CNI 重要节点识别算法的性能,将其结果与现有较成熟的重要节点识别算法进行比较,其中包括 Node2vec[17]、PageRank 法[28]、度递减搜索策略(DDSE,degree descending search strategy)[23]和模拟退火EDV 值(SADV,simulated annealing EDV)[35]。由于实验中IGW-CNI 重要节点识别算法预测列表在每次运行时的结果都可能不同,故设置评估结果为迭代100 次运行后的平均值,运行的平均标准差为1.524。首先,本文对所提IGW-CNI 算法参数对适应度函数值的影响进行分析,得到了节点规模和迭代周期的最优值。为分析迭代周期的影响,设迭代周期的取值范围为[0,50]。在适应度函数值为[10,20,30,40,50]的情况下,各网络数据集中的实验结果如图1 所示。由图1 可知,当迭代周期超过20 时,适应度值没有显著增加,故在后续实验中将maxt设为20。

图1 不同迭代周期下的适应度值
本文还对节点规模与适应度值间的关系进行研究,设迭代周期的取值范围为[0,50],并计算当种群适应度函数值为{10,20,30,40,50}时不同节点规模下的适应度值,结果如图2 所示。由图2 可知,适应度值随着节点规模的增大而增大,但当节点规模大于20 时,适应度值没有显著增加,故将节点规模固定为20。

图2 不同节点规模下的适应度值
4.2 实验结果
本节对所提算法的收敛速度进行了研究,并研究了优化过程中的狼群运动,计算了2 次连续迭代t和t+1 中狼i位置间的欧氏距离。而所有类似的狼在连续2 次迭代t和t+1 中的平均移动(AM,average movement)为

其中,n表示节点规模。实验结果如图3 所示。由图3 可知,在初始迭代中的平均运动增加,随着迭代次数的增加,平均移动次数收敛。尽管在最终迭代中存在振荡行为,避免了算法陷入局部最优解,但所提算法最终会呈收敛趋势。

图3 不同复杂网络中平均移动分析结果
本文对所提IGW-CNI 算法与其他重要节点识别算法的性能进行比较。为此,将种子节点集的规模定义为[0,50],并对种子节点集的影响力进行评价,相关结果如图4 所示。由图4 可知,与其他算法相比,本文所提IGW-CNI 算法具有较好表现,且在种子节点数量相同的情况下影响力较大,这是由于随着种子节点集规模的增加,种子节点间的距离也发挥重要作用,故IGW-CNI 算法比其他算法所选择的种子节点集具有更高的影响力,即本文所提算法在不同种子集规模下都优于其他算法。随着种子集规模的扩大,本文所提算法得到的种子集影响力的增长速度快于其他算法,这是由于IGW-CNI 算法利用改进灰狼优化算法来进行种子集估计并利用随机位置函数生成基本解,因此得到的种子集规模较其他经典算法会具有更快的增长速度。
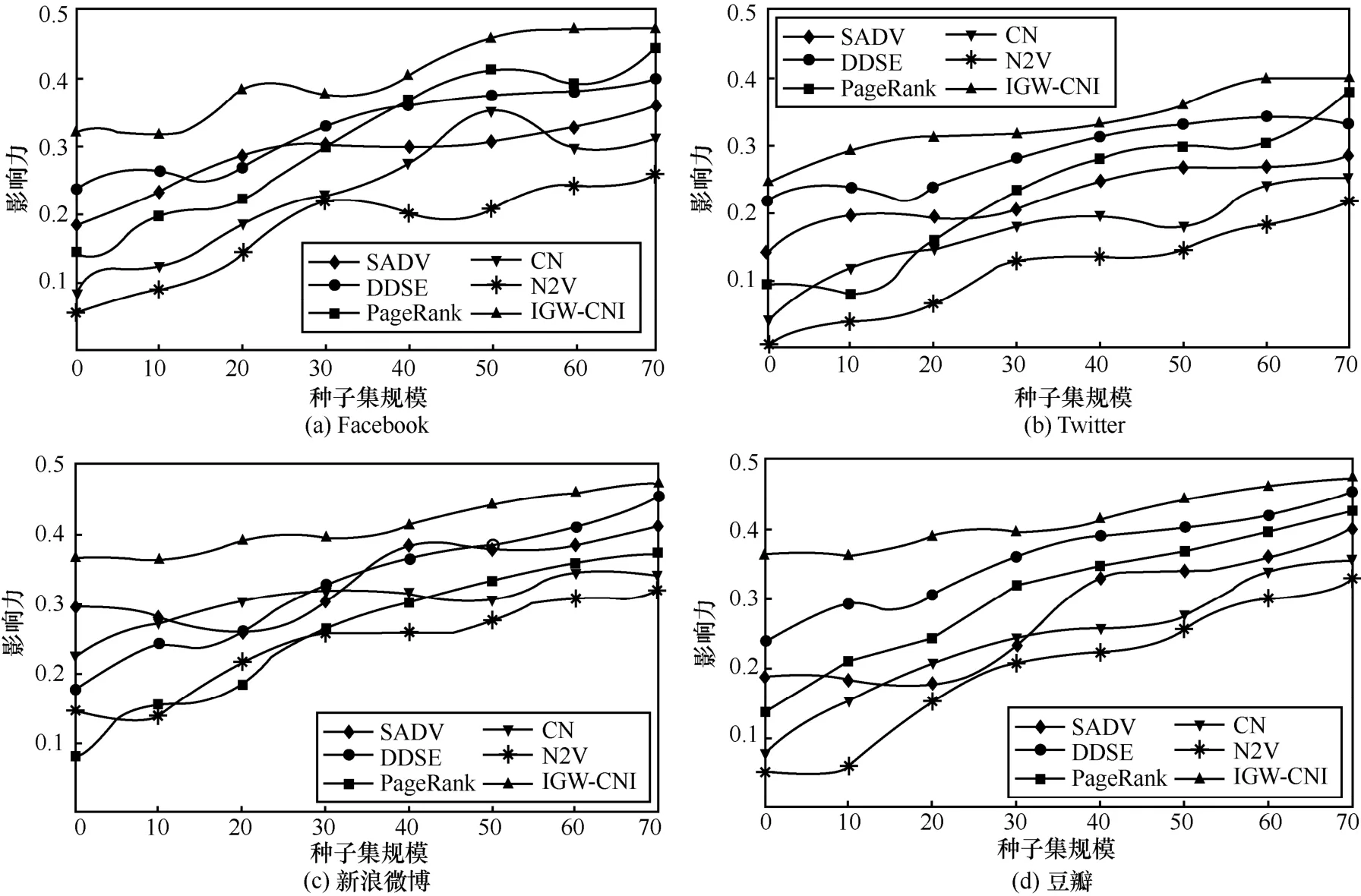
图4 不同复杂网络中种子集规模对影响力的算法比较结果
本文进一步改变IC 模型的激活率以分析其对算法性能的影响。为此,将k值设为30,激活率值设置为区间[0,0.2],间隔为0.005。结果如图5 所示,随着p值的增大,节点集的影响力也随之增加。本文所提IGW-CNI 算法的性能在大多数情形下较其他算法为最优,且随着p值的增大,其优势更加突出。这是由于节点影响力随着p值的增大而增大,而在适应度函数中应用熵函数可使IGW-CNI 算法选择重叠较少的种子集,故本文所提IGW-CNI 算法在激活率较高时方面优于其他算法,即本文所提IGW-CNI 算法在不同p值下都优于其他算法,且随着激活率p值的增大,本文所提算法得到种子集的影响力的增长速度快于其他算法。

图5 不同复杂网络中激活率对影响力的算法比较结果
本文使用如式(12)所示精度计算方法进一步进行算法比较。

其中,真正例(TP,true positive)表示正确预测链接的数量,真负例(TN,true negative)表示正确的未预测链接的数量,假正例(FP,false positive)表示错误预测链接的数量,假负例(FN,false negative)表示错误的未预测链接的数量。
算法精度比较结果如表2 所示。由表2 可知,本文所提IGW-CNI 算法在不同数据集中都优于其他重要节点识别算法,这是由于本文将影响最大化问题建模为具有成本函数的优化问题,并采用改进灰狼优化算法加以解决,有效提升了算法精度。在Facebook 数据集中,PageRank 与DDSE法的性能仅次于本文所提IGW-CNI 法,这是由于在聚类系数较高、激活率较低的情况下,PageRank 与DDSE 法都考虑了入链数量的变化,故计算精度相对较高;在 Twitter 数据集中,SADV 法的性能仅次于本文所提IGW-CNI 法,这是由于在平均度与激活率较高的情况下模拟退火算法可更好地加速收敛过程,因此可以得到相对较优的计算精度结果;在新浪微博数据集中,N2V 和 CN 法的性能仅次于本文所提IGW-CNI 法,这是由于在平均路径较大的情况下,基于网络图最短路径进行邻节点度计算可有效提升算法计算精度。
4.3 统计检验
本文在此对测试算法性能的统计显著性差异进行进一步分析。为取得统计显著性,进行了Friedman检验,使用Bonferroni法来校正实验结果[36],并设置可信度分数为α=0.05,这表明如果p<0.05,则存在差异显著。表3 中,本文所提IGW-CNI 算法将成本函数表示为节点影响力及其间的距离,并使用Shannon 熵对节点影响力进行度量的优势较其他经典算法会充分体现。Friedman 检验对AUC 的观察检验值Ff为54.142,均大于相应的χ2值(即χ2(αc,Df))。当置信区间α=0.05、自由度Df=8时,χ2值为15.51,故拒绝零假设。

表3 对AUROC 值的Friedman 统计检验结果
4.4 大数据集实验
为检验本文所提IGW-CNI 算法在极限条件下的适用性,本节使用规模更大的 MovieLens 20M、DatingT 和Netflix 等复杂网络数据集对上述重要节点识别算法进行对比实验,以进一步分析本文所提算法在大数据集中的适用性(其中MovieLens 20M 和Netflix 数据集常用于推荐算法研究,且呈现包含节点和目标2 种节点的二部图网络结构,但本文所提算法更加重视在网络环境下的应用,故在上述2 种数据集中只采用节点以进行大数据集实验。这也从另一角度对本文所提IGW-CNI 重要节点识别算法在二部网络图中的适用性进行分析,进一步证实了本文所提算法的普适性)。其中,MovieLens20M 被国内外学者认为是最稳定的基准数据集之一,其包含139 428 个节点对27 493 部影片的20 351 902 条评分;DatingT 数据集包括136 739 名男性和179 332 名女性组成的18 293 016 条交友记录;Netflix 数据集中包括480 189 个节点对17 770 部电影的100 480 507 条评分记录。图6 给出了同等参数条件下上述3 种大数据集中的算法比较结果。由图6 可知,在体量更大的数据集中的实验结果基本与图5 中的实验结果一致。此外,本文还使用上述3 种大数据集作为对照组重复进行了精度与效率等方面的实验,结论与前文一致,故在此不再赘述。
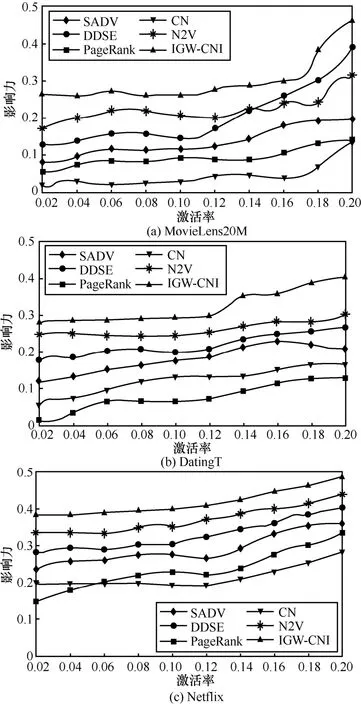
图6 不同大规模复杂网络中激活率对影响力的算法比较结果
4.5 时间复杂度
最后,本文对所提IGW-CNI 算法的计算时间复杂度效率进行了分析,并对算法的平均运行时间进行了比较,结果如表4 所示。由表4 可知,本文所提IGW-CNI 法的效率高于其他算法,且获得的种子节点集的影响力性能更优。

表4 时间复杂度实验结果
5 结束语
复杂网络中的重要节点识别对电子商务、网络营销等多个领域都有很大影响。在预算有限的情况下,网络营销所面临的一个主要挑战是识别少数具有影响力的重要节点集,即种子节点集,以期通过将信息传递给种子节点集在复杂网络中获得较大影响力,故可将此问题转化为节点影响最大化问题。本文将影响最大化问题建模为具有成本函数的优化问题,并采用改进灰狼优化算法解决此问题。最后基于真实复杂网络数据集进行比较实验,结果表明,本文所提IGW-CNI 算法优于其他影响力最大化算法,不仅效率更高,计算时间也短。
尽管本文已提出了上述具有重要意义的发现,但还具有一定局限性,其中一些可能会为未来的进一步研究指明方向。首先,本文所提改进灰狼优化算法为基于种群的优化算法,仍可能存在局部最小值,可考虑引入随机梯度等方法避免出现局部最小值。其次,可结合社会化调查法和计算实验等研究框架对所提重要节点识别算法进行进一步佐证。最后,可尝试使用如自编码器等深度学习方法进一步提升重要节点识别算法的效率和精度。
