基于DRL 的联邦学习节点选择方法
2021-07-16贺文晨郭少勇邱雪松陈连栋张素香
贺文晨,郭少勇,邱雪松,陈连栋,张素香
(1.北京邮电大学网络与交换技术国家重点实验室,北京 100876;2.国网河北信息通信分公司,河北 石家庄 050011;3.国家电网有限公司信息通信分公司,北京 100761)
1 引言
随着边缘智能[1]概念的提出,越来越多的智能化应用将在边缘侧训练和执行。传统的云智能[2]采用将原始数据上传至云中心进行模型训练的方式,存在高传输时延、用户隐私泄露等弊端。为解决这一问题,基于联邦学习(FL,federated learning)的分布式模型训练架构应运而生。
在基于FL 的分布式训练架构下,边缘侧终端设备可以利用自身采集数据在本地执行训练任务,然后将训练好的本地模型参数上传至云服务器进行模型聚合。相比直接上传原始训练数据,该架构选择上传训练之后的模型参数,能有效降低数据传输成本,同时保护用户隐私[3]。然而,终端设备上的数据集大小往往是不同的,数据也可能不满足独立同分布特性,这使本地模型的训练质量存在差异[4]。同时,边缘侧终端设备并不是完全可信的,存在一些恶意节点篡改训练结果,上传错误参数进而降低FL 性能。此外,终端设备多样异构的计算资源和传输时间对FL 的效率也具有较大影响[5]。因此,如何合理选择设备集合参与模型聚合,以提高FL 效率和准确率成为一个亟待解决的问题。
由于能提供有效的隐私保护和高效的模型训练方式,FL 得到了越来越多的关注。Shi 等[6]提出了一种带宽分配和设备调度的联合优化模型,并通过解耦为2 个子问题来提高FL 效率,但该方法仅根据训练时间来选择设备,忽略了设备的本地训练质量。Ren 等[7]设计了一个新的概率调度框架来调度多个边缘设备参与FL 模型聚合,该框架能有效提高模型训练的准确率,但是对设备异质的计算能力和训练时间考虑不足,可能会导致较大的时延。Chen 等[8]构建了一个无线资源分配和节点选择的联合优化问题,并提出了一种依概率选择节点的方法。Wu 等[9]设计了一个多层FL 协议,依概率引入区域松弛因子后完成节点选择。但上述方案依赖概率进行节点选择,忽略了节点本身计算、通信能力等方面的差异。Kang 等[10]引入声誉作为衡量移动设备可靠性和可信度的指标,并设计了一个基于声誉的可靠FL 设备选择方案,从而有效地保证模型精度和可靠性。Lu 等[11]揭示了本地训练方法和不进行节点筛选的FL 训练方法在训练精度和时延等方面的不足,在此基础上提出了一种用于车联网中资源共享的FL 方案,该方案综合考虑训练时间和精度,通过选择精确度高、训练速度快的设备完成模型聚合。但上述方法均忽略了非独立同分布数据带来的影响。Yoshida 等[12]考虑非独立同分布数据对训练性能的影响,设计了启发式算法解决终端设备和数据选择问题,但其节点选择算法的性能还有待改进。此外,由于资源分配和能耗管理也对FL性能有很大影响,有许多针对这方面的研究工作已陆续展开[13-16],通过优化终端设备的无线、计算资源分配和能耗来支撑FL。但上述工作偏向于提高资源利用率及设备节能,难以兼顾FL 本身性能。另一方面,在针对诸如节点选择等NP 问题时,孟洛明等[17]基于禁忌搜索算法进行求解,并在有限时间内获取近似最优解。李枝灵等[18]设计了一种基于免疫算法的接入点选择方法,以提高求解效率。但上述方法缺少学习能力,难以适应复杂且动态变化的边缘网络环境。已有许多文献[19-21]采用如Q 学习、深度Q 网络等深度学习算法进行求解,但这些方法存在学习率确定难、收敛速度慢等问题。因此,在FL 的设备节点选择过程中,仍存在以下问题需要进一步解决:1) 忽略终端设备异构的数据质量及训练能力;2) 面对复杂动态的网络环境,缺乏高效的方法获取最优节点集合。
为解决以上问题,本文主要的研究工作如下。
1) 首先,建立了基于深度强化学习(DRL,deep reinforcement learning)的FL 分布式训练系统架构,实现恶意节点的筛查和异构设备节点的选择。其次,构建面向节点选择的准确率最优化问题模型,该问题以最小化每次FL 迭代过程中参与设备的总体损失函数为目标,并满足包含传输和计算时延的约束。
2) 设计了基于分布式近端策略优化(DPPO,distributed proximal policy optimization)的节点选择算法。将FL 中设备节点选择问题构建为马尔可夫决策过程(MDP,Markov decision process),定义动作、状态空间和奖励函数。基于多线程和PPO 算法思想,设计了基于DPPO 的节点选择算法对优化问题进行求解。
3) 基于多种数据集和多样化训练任务,对所提最优化问题模型和算法进行了仿真实验验证。结果表明,本文所提模型和算法在面对差异化数据质量和设备训练能力时,具有更好的准确率和时延性能,同时有良好的收敛性和稳健性。
2 系统模型
本文构建的系统架构如图1 所示。FL 任务实现流程主要包括模型的本地训练、参数上传、模型聚合以及参数下发。与传统FL 分布式训练架构不同,本文基于DRL 的节点选择对模型聚合模块进行改进,在权值聚合之前,基于DRL 的节点选择能合理选择具备计算能力强、训练质量高的设备参与模型聚合,进而有效提高FL 性能。

图1 基于DRL 的FL 架构
2.1 网络架构
网络由终端设备、微基站、宏基站和对应的移动边缘计算(MEC,mobile edge computing)服务器组成。宏基站内的MEC 服务器具有强大的计算和通信资源。令Z表示微基站内MEC 服务器集合,每一个MEC 服务器z∈Z具有一定的计算能力,并通过与其相连的基站来覆盖数个终端设备。终端设备的集合用D表示,令Hz,d={x z,d,yz,d}表示被MEC 服务器z覆盖的终端d的数据集。针对诸如路径选择、图像识别等学习任务i∈I,其目的是从终端设备的数据集合Hz,d={x z,d,yz,d}中学习与任务相关的模型M。本文定义FL 任务i的属性集合为Ωi={Z i,Di,C i,},其中,Zi和iD分别表示与任务i相关的MEC 服务器和终端设备的集合,Ci为该FL 模型计算数据集中一组数据所需的CPU 周期数,为该FL 任务的初始模型。具体系统参数设置如表1 所示。

表1 系统参数
2.2 FL 训练机制
本地训练。对于一个FL 任务i∈I,定义与该任务相关的总数据集为

终端设备d在执行FL 任务i的本地训练时的损失函数(x z,d,y z,d;ωz,d)定义为它在样本数据集Hz,d上的预测值与实际值之差,因此FL 任务i在所有数据集上的损失函数可以定义为

其中,ω表示当前要训练的模型的权值,表示该任务数据集大小。FL 的目的是通过最小化任务的损失函数Li(ω) 来优化全局模型参数,表示为

本文的FL 的参数更新方法为随机梯度下降(SGD,stochastic gradient descent),即每次随机选择数据集中的一条数据{x z,d,yz,d}进行更新。这种方法大大降低了计算量,但由于其随机性使本地模型需要进行足够的本地训练量以保证模型质量。模型参数的更新表示为

其中,η表示参数更新时的学习率,n∈N表示训练的迭代次数。
模型聚合。当上传的本地模型达到一定数量或者迭代次数N后,宏基站处的MEC 服务器将对得到的本地模型执行全局模型聚合,具体的权值聚合表示为

2.3 节点选择问题描述
设备节点的选择受诸多因素影响。首先,终端设备差异化的计算和通信能力直接影响本地训练和数据传输时延。其次,终端设备上携带的数据集大小不同,数据也可能不满足独立同分布的特性,这使本地模型的训练质量存在差异。因此,本文构建了面向节点选择的准确率最优问题模型。
准确率。对于一个FL 任务i∈I,其训练质量定义为聚合后的全局模型在测试数据集上的测试准确率,本文使用测试数据集的损失函数之和表示测试准确率,即

时延。FL 每一次模型聚合的总时延包括数据在终端设备上的训练时延和在链路上的传输时延。FL 任务i的参数数据在终端设备与微基站间以及微基站与宏基站间传输速率可分别表示为

其中,Bd和Bz分别表示设备与微基站间以及微基站与宏基站间的可用带宽,Gd和Gz分别表示设备和微基站的信道增益,p d和pz分别表示设备和微基站的发射功率,N0表示噪声功率谱密度。
因此,设备将本地参数上传至模型汇聚服务器的总传输时间为



综上,面向节点选择的准确率最优化问题模型可以表示为

对于一个FL 任务i∈I,节点选择问题可以概括为每次迭代时选择节点集Di∈D,使本次训练的准确率最优,即总损失函数最小,同时将训练和传输时延控制在一定范围内。可以看出,上述问题属于典型的NP 问题。
3 基于DRL 的FL 节点选择方法
3.1 算法机理描述
在复杂多变的边缘网络中,节点选择策略需要随着环境状态信息的变化而发生改变,基于DRL的节点选择框架能通过不断与环境的交互,学习节点选择策略以获得最大回报[22-23]。本文提出的基于DRL 的节点选择框架如图2(a)所示,包括3 个部分:环境、代理和奖励。环境主要包括网络状态、终端设备以及目标模型信息。代理与环境进行交互,从一个状态出发,根据自己的策略分布选择动作,并获得奖励。代理获得的动作、奖励及环境状态组成批量样本来更新演员−评论家(AC,actor-critic)网络。
边缘网络中参与FL 训练的终端设备往往数量众多,在应对节点选择问题时,传统的AC 算法由于学习率难以确定,易导致收敛速度过慢或过早收敛等弊端,同时算法收敛性能也有待提高。因此本文基于多线程与PPO 算法设计的思想,设计了基于DPPO 的节点选择算法,如图2(b)所示。PPO 作为一种基于AC 框架的强化学习算法,通过采用正则项的方式限制策略更新幅度,解决了传统策略梯度更新步长难以确定的问题[24]。为进一步提高收敛速度,基于DPPO的节点选择算法使用多个线程在环境中收集数据,且多个线程共享一个全局PPO 网络。

图2 基于DRL 的FL 节点选择方法
本文首先将FL 节点选择问题表述为一个MDP模型,然后设计了基于DPPO 的节点选择算法对问题进行了求解,具体设计如下。
3.2 MDP 模型
状态空间。t时刻环境状态可由一个四元组表示,其中,Φ i表示FL 任务i的信息,表示终端设备在t时刻可用于FL 任务i的资源,表示终端设备在上一时刻的数据集,表示上一时刻的节点选择方案。
动作空间。在进行每步动作选择时,代理只被允许采用一种节点选择方案,将FL 任务i在t时刻的节点选择方案建模为一个 0-1 二进制向量,其中,表示编号为d的设备在此次节点选择中被选中,反之则表示未被选中。因此,经节点选择后权值聚合表示为
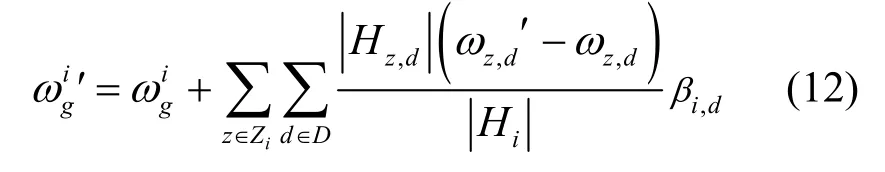
奖励函数。当代理根据某个节点选择策略执行某步动作后,环境信息会随之变化并得到一个用于评价本次行为的奖励值。本文考虑基于FL 的测试准确率设计奖励函数,并设置最大时延作为每步动作选择的约束,奖励函数表示为

上述执行动作来源是一个策略π,π是状态空间到动作空间的一个映射,即

MDP 模型的目标是得到一个优化策略,即在相应的状态根据该策略采用相应动作后,使强化学习的目标−累积回报的期望最大,即求解

其中,σt为折扣因子,其值随时间增加而减小。
3.3 基于DPPO 的FL 节点选择算法
全局PPO 网络中包含2 个Actor 网络(Actor1和Actor2)以及一个Critic 网络。Actor1代表当前最新的策略π并负责指导各线程与环境交互。Critic网络根据代理执行节点选择动作后获得的奖励对当前策略进行评判,并通过损失函数的反向传播实现对Critic 网络中的参数进行更新。Actor2代表旧策略πold训练circle 步后,使用Actor1的参数对Actor2进行更新。重复上述过程直至收敛。
相较于传统策略梯度算法,PPO 首先对算法梯度进行改进,策略梯度的原始参数更新方程为

其中,θold和θnew分别表示更新前后的策略参数,α表示学习率,Jθ∇ 表示目标函数梯度。PPO 将新策略的回报函数分解为旧策略对应的回报函数加其他项,为实现回报函数的单调不减,只需保证新策略中的其他项大于或等于0,表示为

其中,J表示当前策略的回报函数,π表示旧策略,表示新策略,表示优势函数。基于上述分析可知[25],PPO 的优化目标是通过对参数θ进行更新以满足
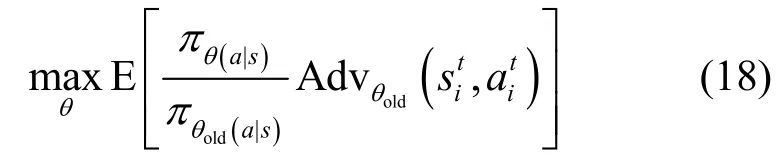
其中,πθ(a|s)为基于策略π在状态s下采取动作a的概率,且表示旧策略参数与新策略参数之间相对熵的最大值,相对熵用于度量θold和θ这2 个参数的概率分布之间的相似度,进而控制策略的更新幅度。

在考虑约束条件后,PPO 中基于拉格朗日乘数法的初始策略更新如上所示。为解决超参数λ难以确定的问题,本文考虑使用t时刻的新策略与旧策略的比值衡量策略的更新幅度,表示为

当策略未发生变化时,ratiot(θ)=1。用裁剪函数clip 对新旧策略之间的更新幅度进行限制,改进后的策略更新方式为

其中,ε∈[0,1]是一个超参数,裁剪函数将ratiot(θ)的值约束在区间[1−ε,1+ε]内。
基于上述对PPO 的分析,结合多线程的思想,提出了基于DPPO 的FL 节点选择算法,主要分为多线程交互和全局网络更新2 个过程。
1)多线程交互
步骤1将初始状态输入Actor1网络中,各线程基于策略πold选择一个动作与环境进行交互,即。
步骤2各线程分别与环境连续交互多次,收集包含动作、状态和奖励的样本,并将批量样本同步传输至全局PPO 网络处。
2)全局网络更新
步骤1全局PPO 网络使用式(22)计算每个时间步的优势函数,即

其中,V为状态值函数,φ为Critic 网络参数。
步骤2利用计算Critic 网络的损失函数,并反向传播更新Critic网络参数φ。
步骤3利用LCLIP(θ) 与优势函数对Actor1网络的参数进行更新。
步骤4circle 步后使用Actor1中的网络参数更新Actor2的参数。
步骤5循环步骤1~步骤4,直至模型收敛。
全局网络模型收敛后,可指导代理根据不同的环境状态得出相应的动作,进而选择合理的节点集合参与FL 聚合。详细过程如算法1 所示。
算法1基于DPPO 的节点选择算法
输入网络的初始状态、FL 任务信息
输出节点选择方案
4 仿真分析
4.1 实验设置
本文在Python 3.8和TensorFlow 2.3.1环境下对算法进行了仿真验证。实验模拟了MEC 环境中,多类终端设备进行分布式FL 训练的场景。场景包含一个汇聚服务器、10 个MEC 服务器以及每个MEC 服务器下10~80 台的终端设备。MEC 场景中的终端设备用处理器为AMD Ryzen 7 4800U、配置为8 核16 GB 的计算机来模拟。为体现终端差异化计算能力,实验中采用虚拟化docker 技术随机分配计算机中[10%,100%]的核数用于模型训练。
实验首先选择MNIST 数据集作为训练数据。将数据集分割为每组100~2 000 个,并分配给终端节点作为本地数据集。采用卷积神经网络作为FL 的训练模型,并将模型结构设置为2 层卷积层和4 层全连接层。每经过5 次本地迭代或者本地迭代时间超过最大允许本地迭代时间时,系统进行一次全局参数合成。为体现所提方法的稳健性,实验中设置了恶意节点来模拟训练质量差的设备,该类节点可能不训练模型,而是随机生成模型参数并将其上传,实验中把这个概率随机设置在80%~100%。通过节点上独立同分布数据的比例来表征数据质量,该比例在[80%,100%]随机设置。此外,本文还选取CIFAR 数据集,并将卷积神经网络改为5 层卷积层和3 层全连接层,对算法进行了验证。
DPPO 算法中使用4 个线程与外部环境进行交互,奖励折扣系数设置为0.9。Actor 网络和Critic 网络的学习率分别设置为0.000 1、0.000 2,且每当代理训练100 个回合就使用Actor1中的参数对Actor2进行更新。为实现对策略更新幅度的控制,clip()中的超参数设为0.2。具体实验参数的设置如表2 所示。

表2 仿真参数设置
选取2 个算法作为本文所提算法(FL-DPPO)的对比。1) FL-Greedy:该算法在FL 每次迭代训练中选择全部设备节点进行模型汇聚。2) Local Training:不采用FL 机制,仅在本地设备上进行模型训练。
4.2 结果分析
实验从准确率、损失函数、时延等多个角度对3 种算法进行了分析。MNIST 数据集属于分类问题,因此实验中的准确率可定义为分类正确的数量占总样本数的比例。
图3 给出了每个MEC 下有10%的恶意设备节点时3 种算法准确率的变化情况。从图3 中可以看出,3 种机制在训练初期得到的模型准确率较低,这说明模型的训练精度需要足够的训练次数来保证。当迭代次数达到10 次时,3 种机制训练得到的模型准确率趋于稳定,FL-DPPO、FL-Greedy 和Local Training 的准确率分别稳定在0.94、0.87 和0.7附近。FL-DPPO 算法在应对少量恶意节点和差异化数据质量时仍能保持较好的训练性能,而Local Training 很难保证训练质量。

图3 准确率对比(恶意设备节点占10%)
图4 是每个MEC 下有10%的恶意设备节点时3 种算法损失函数的变化情况。FL-DPPO 算法相较于另外2 种算法能更快地收敛,且损失函数值最小。Local Training 由于未采用FL 机制,其损失函数始终无法收敛且明显高于FL-DPPO 和FL-Greedy。

图4 损失函数对比(恶意设备节点占10%)
图5 给出了每个MEC 下有40%的恶意设备节点时3 种算法准确率的变化情况。从图5 中可以看出,在应对较多恶意节点时,FL-DPPO 仍能快速收敛至最高的准确率(0.92)。FL-Greedy 受恶意节点的影响,获得的模型质量明显下降,保持在0.71 左右,与Local Training 的训练性能接近。本文所提FL 机制具有兼顾数据质量和设备训练的能力,并可有效保证模型质量。

图5 准确率对比(恶意设备节点占40%)
图6 是每个MEC 下有40%的恶意设备节点时3 种算法损失函数的变化情况。与准确率的收敛情况类似,FL-DPPO 算法相较于另外2 种算法能更快地收敛,且损失函数值最小。FL-Greedy 和Local Training 由于恶意节点的存在,损失函数值始终较高。

图6 损失函数对比(恶意设备节点占40%)
对比上述2 组仿真结果可以看出,相比于FL-Greedy 和Local Training,FL-DPPO 在面对不同数量的恶意节点时,始终能快速收敛至最高的准确率,因此可以得出本文所提方法具有良好的稳健性。
3 种算法的时延对比如图7 所示。从图7 中可以看出,FL-DPPO 算法在应对多种节点数目时都能保证较低的时延,这是由于该算法能有效选择训练质量高的设备节点进行模型汇聚。以节点数目40为例,3 种算法的时延值分别为7.3 s、8.1 s 和10 s,FL-DPPO 算法分别比FL-Greedy 和Local Training降低了9.9%和27%。这说明本文所提算法能高效地完成FL 训练。

图7 时延对比
图8 是3 种算法在不同的节点数目情况下获得的模型准确率。FL-DPPO 算法在应对多个节点数目时都能获得最高的准确率。以40 个节点为例,3 种算法的准确率分别为0.95、0.78 和0.23,FL-DPPO 算法的准确率分别比 FL-Greedy 和Local Training 提高了17.9%和75.8%。2 组数据同时说明本文所提方法在节点规模方面有着良好的扩展性能。

图8 准确率对比
图9 表示FL-DPPO 算法的收敛特性。从图9 中可以看出,准确率随着DRL 训练步数的增加逐渐变大,当Episode=40 时,算法在150 步左右收敛得到最大准确率。当Episode=1 时,算法也能在500 步左右收敛。这说明FL-DPPO 算法具有良好的收敛性能,在应对复杂的状态环境和高维的动作空间时有良好的表现。

图9 算法收敛性
接下来,采用CIFAR 数据集对3 种算法进行了对比和验证。图10 给出了每个MEC 下有20%的恶意设备节点时3 种算法准确率的变化情况。从图10中可以看出,相比于MNIST 数据集,CIFAR 数据集的训练次数明显增多。当迭代次数达到60 次时,3 种机制训练得到的模型准确率趋于稳定,FL-DPPO、FL-Greedy 和Local Training 的准确率分别稳定在0.75、0.62 及0.55。FL-DPPO 算法在应对恶意节点和差异化数据质量时仍能保持较好的训练性能,而Local Training 很难保证训练质量。

图10 准确率对比
图11 是每个MEC 下有20%的恶意设备节点时3 种算法损失函数的变化情况。FL-DPPO 算法相较于另外2 种算法能更快地收敛,且损失函数值最小。Local Training 由于未采用FL 机制,其损失函数始终无法收敛且高于另外两者。
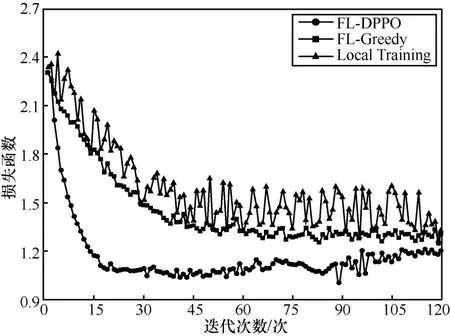
图11 损失函数对比
5 结束语
基于深度强化学习方法,本文提出了FL 系统中设备节点选择方法,在兼顾设备训练能力和数据质量的情况下,有效提高了FL 学习的效率和性能。首先,根据FL 特点,提出基于DRL 的节点选择系统模型。其次,考虑设备训练时延、模型传输时延和准确率等因素,构建面向节点选择的准确率最优化问题模型。最后,将问题模型构建为MDP 模型,并设计基于分布近端策略优化的节点选择算法,在每次训练迭代前选择合理的设备集合完成模型聚合。仿真实验结果表明,所提方法显著提高了FL 的准确率和训练速度,且具有良好的收敛性和稳健性,为在网络边缘侧执行FL 提供了一种有效的解决方案。
