基于深度学习的FPL 报文航路纠错研究
2021-07-09郭舒言
郭舒言
(四川大学视觉合成图形图像技术国防重点学科实验室,成都 610065)
0 引言
航空固定电信网(Aeronautical Fixed Telecommuni⁃cation Network,AFTN)格式电报供空中交通管制部门使用,共包括16 类,领航计划报(Filed Light Plan Mes⁃sage,FPL)是其中使用频率最高的报文,由空中交通服务单位根据航空器运营人或代理人提交的飞行计划数据,拍发给沿航路所有相关空中交通服务单位。FPL报对于保证飞行安全和提高工作效率有着十分重要的意义,也由此对其正确性提出较高要求。但由于报文是由人工进行编写和拍发,实际工作中难免出现错漏,收报单位在解析航路时,若发现航路中存在系统无法识别的航路点或发现某航路点偏离航路,需将报文发送至人工席等待处理[1]。本文设计的FPL 报文自动纠错方法旨在报文发送端识别错误航路并给出修正提示,从而节省人力、物力资源,在实际工作场景中具有一定的应用价值[1]。
目前对于报文的处理多集中于报文解析[3]和格式层面[4]的纠错,本文则针对报文航路内容层面进行纠错,将报文看作一种具有特殊规则的语言,把报文纠错任务视为文本纠错任务,引入基于深度学习的自然语言处理技术。Transformer 模型是Google 于2017 年提出的一种新型网络结构[5],其在保持经典的“编码器-解码器”结构的同时,抛弃传统的循环神经网络和卷积神经网络,仅使用注意力机制,并行结构提升了训练效率,且获得了较高的准确度。本文通过实验验证了Transformer 模型在报文纠错上的有效性,同时根据报文特点提出一种基于N-Gram 思想的结果修正机制,通过片段共现词打分的方法对修改进行取舍,进一步提高了报文纠错的正确率。
1 背景
文本纠错任务是指通过分析输入句子成分之间的依赖性和逻辑性,对其中出现的多词、少词、错词或搭配不当等错误进行识别并自动修正,从而获得更流利的句子[6],该任务多以自然语言为研究主体。传统的文本纠错任务研究方法主要包括:①基于规则的方法,利用语言学知识针对特定错误进行纠正[7];②基于统计的方法,如数据驱动的传统机器学习[8]和分析利用上下文信息的N-Gram 模型[9-10]。
将文本纠错任务看作翻译任务,即把纠错过程看作将错误文本改成正确文本的翻译过程,为纠错任务的研究提供了新思路。Brockett 等人[11]首先采用该方法,并提出了一个基于短语统计的机器翻译纠错模型。Ehsan 等人[12]针对上下文敏感错误检测,提出了一种基于规则和统计机器翻译相结合的方法。随着深度学习的发展,基于端到端的深度神经网络的机器翻译方法兴起[13-14],也被应用到文本纠错任务中。Chollam⁃patt 等人[15]结合N-Gram 信息,提出一种基于多层卷积的端到端神经网络的改进语法自动校正方法。郝亚男等人[16]提出一种基于BiGRU 和注意力机制的中文文本校对方法,能较好地捕捉词间语义逻辑关系。黄浩洋[17]提出一种结合预训练方法获得语义信息嵌入的堆叠深度神经网络模型。周旺[18]提出一种反馈过滤算法,结合Seq2Seq 模型构建了英语语法纠错模型。
2 FPL报文说明
根据《民航飞行动态固定格式电报管理规定》,一条完整的FPL 报文应包括9 个编组,如下所示,“(”代表报文开始,“)”代表报文结束,各编组间用“-”隔开,编组内有多个数据项的用空格或“/”隔开。
FPL 报文构成说明

本文中,只提取每条FPL 报文中编组13 的起飞机场代码、编组15 的航点(线)代码以及编组16 的目的机场代码,组成一条完整的训练所需数据。
3 算法实现
3.1 基于Transformer模型的航路纠错
Transformer 模型由编码器和解码器组成,整体结构如图1 所示。输入序列经编码器被映射成相同长度高维向量,再由解码器解码生成输出序列。其中,编码器端的输入为待纠错文本,解码器端的输入需区分训练阶段与测试阶段,训练阶段解码器端输入与待纠错文本相对应的正确文本,测试阶段则输入解码器前一时刻的输出。解码器输出经过Linear 层和Softmax 层得到输出词概率,概率最大的词确定为该时刻输出,每一时刻输出的词拼接为最终输出序列。

图1 Transformer模型结构
因为模型不包含循环和卷积,为了利用序列的位置信息,在词嵌入的基础上加入位置向量(Positional Encoding),计算方法如式(1)~(2)所示:

其中,pos指该词在序列中的位置,i指第i维,dmodel为模型隐层维度。
编码器共N 层,每层包含两个子层,分别为多头注意力(Multi-Head Attention)层和全连接的前馈网络(Feed Forward)层。每个子层后有一个残差连接及归一化结构,残差连接避免梯度消失,归一化。多头注意力使用点积注意力,计算如式(3)~(5)所示。
其中,Q、K、V为三个向量矩阵,Q为查询矩阵(query matrix),K为键矩阵(key matrix),V为值矩阵(value matrix);dk为隐层维度分别为对应的权重矩阵。Multi-Head 的注意力由多个head拼接而成,可以并行计算,提高模型训练效率。前馈网络层计算如式(6)所示,包含两个线性变换和一个Re⁃LU 激活:

其中,W1、b1和W2、b2分别为两次线性变换对应的权重和偏置。
解码器也为N层,每层包含三个子层。第一个子层掩码多头注意力(Masked Multi-Head Attention)层,掩码的作用是避免解码器在训练时读到后续位置的信息,使预测只依赖当前时刻已知输出。解码器的多头注意力层接受来自编码器的Q、K和来自上一子层的V。
3.2 基于N-Gram的结果修正机制
与自然语言文本的流利性判断相类似,仅从航路文本本身出发,一条航路的正确性判断主要依据其中每个点与前后点的连续组合的可行性。根据航路文本特性,本文设计了一种基于N-Gram 思想的结果修正算法,以词为最小单位,对航路进行大小为n的滑动窗口操作,获得长度为n的共现词信息。本文利用正确航路组成的语料库,使n取2、3,建立二元和三元的共现词表。如航路片段“TOL A470 DOTMI DCT”,进行n为2 的滑动窗口操作得到“TOL A470,A470 DOTMI,DOTMI DCT”,进行n为3 的滑动窗口操作得到“TOL A470 DOTMI,DOTMI DCT”。在航路纠错中,只考虑多元词的正确性,不考虑其出现的概率。针对待分析片段使用同样大小的滑动窗口,将得到的所有二元词和三元词在共现词表中进行查找,找到的记1 分,否则计0 分。所有共现词的得分相加,用该片段总共现词数进行归一化,得到该片段的得分S,如式(7)所示:

其中CB、CT分别为子片段经滑动窗口获得的二元词、三元词个数,Bi、Ti分别为相应二元词、三元词的查表后的得分。Bi,Ti∈{0,1};S∈[0,1]。当S=1 时,认为该片段是正确的。
每当Transformer 模型对输入进行一处修改,都会得到一对输入、输出中对应的相异子片段。以原始输入为基准,与Transformer 模型输出进行比较,对于两条航路中不一致的子片段分别进行打分,以决定修改的保留或还原。若片段得分相同,考虑到实际工作中会遇到新增但未被收录的航路,则还原原始输入的子片段;若Transformer 模型输出航路子片段得分高于原始航路子片段,则进行片段替换,保留模型修改。修正后的航路即为最终输出结果。
3.3 评估标准
本文使用查准率P、查全率R和F0.5值作为评价指标,定义如式(8)~(10)所示。查准率衡量模型对航路的修改是否正确,查全率衡量模型的修改是否有遗漏。使用F0.5作为评价指标与F0.1的区别在于将查准率的权重定为查全率的两倍,其原因在于,对于纠错模型,更看重模型编辑的准确性而非编辑的数量。
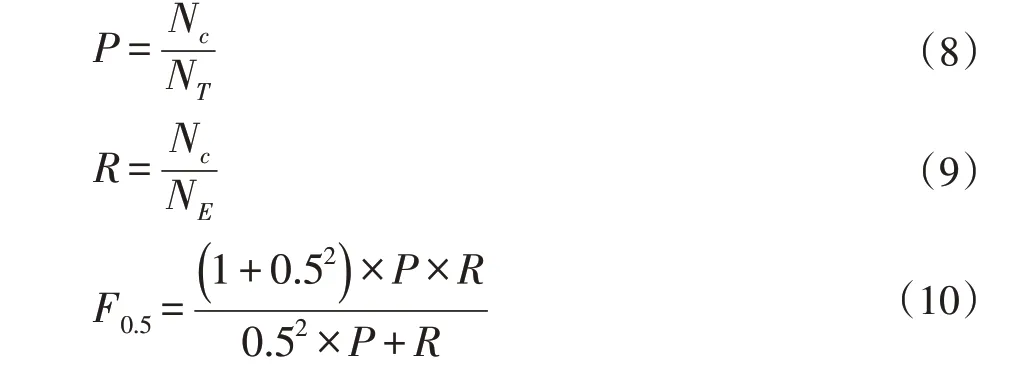
其中Nc指修改正确的错误样本数,NT指发生修改的样本数,NE指语料中含有的错误样本数。
4 实验
4.1 实验数据
本文收集了2019 年8 月的全国FPL 报文数据453910 条,从中提取并整理得到正确且无重复的航路10348 条,以此建立训练词表并制作数据集,数据集统计如表1 所示,以训练集中的正确样本统计制作二元词和三元词的共现词表作为修正算法依据。错误样本为人工在正确样本的基础上进行多轮造错得到,每条航路随机添加1~3 处错误,错误类型包括多词、少词、错词,词类型为词表中出现过的任意已知词和未登录词

表1 数据集统计
4.2 实验结果与分析
本文设置Transformer 模型编码器与解码器层数为6,隐层维度为128,head 数为8;使用Adam 优化算法[19],learning_rate 设为0.0003;dropout 设为0.1。利用上述训练集训练Transformer 模型,并用测试集测试。同时,与基于LSTM 的Seq2Seq 模型、添加了Attention 机制的基于BiLSTM 的Seq2Seq 模型进行比较,并对结果使用基于N-Gram 的修正算法进行修正。最终实验结果如表2 所示。

表2 航路纠错实验结果
实验结果表明,深度学习模型可以有效纠正FPL报文航路中的错误,同时,经由N-Gram 修正算法修正后的结果在P值、R值、F0.5值三个指标中均有所提升。Transformer 与N-Gram 修正算法的组合在三个指标上取得最佳结果。
表3 中给出纠错实例。该错误样本共有2 处错误,用斜体加粗标示错误位置,“(…)”表示信息缺失。“IKATA A470”之间多了“LG Z17”,“A1 UBL W1”中“UBL”缺失。经过Transformer 模型纠错,上述2 处错误已得到纠正,但出现了一处新错误,“W597 IKATA”之间多了“BINUS W597”。可以看出,Transformer 模型共对错误样本做出了3 处修改,分别对输入、输出中这3 对不一致的子片段进行N-Gram 修正,最终保留了2处修改,还原1 处修改,得到最终纠错结果。

表3 纠错实例
5 结语
本文将基于深度学习的自然语言处理技术引入FPL 报文航路纠错工作,实验验证了Transformer 模型能对航路中出现的多处错误进行有效修改。同时,本文基于N-Gram 思想并结合航路文本特征,提出了一种共现词得分的结果修正算法,分段对Transformer 模型做出的修改进行取舍,提高了纠错模型的正确率。本文的工作还有很大的提升空间,后续模型的优化、在更大数据集上的验证以及针对实际应用场景中的改良都有待进一步研究。
