云数据中心服务器能耗建模及量化计算
2021-05-06周舟袁余俊明李方敏
周舟 袁余俊明 李方敏


摘 要:构建精确的服务器能耗模型有助于资源提供者预测和优化数据中心的能耗. 针对以往数据中心服务器因未考虑“负载的特征”而导致能耗模型精度低的问题,本文提出一种新的能耗建模及量化计算方法,其主要思路如下:根据数据中心服务器所处理任务特征的不同将其分成三类,分别为计算密集型任务、Web事务型任务和I/O密集型任务;针对每一种类型任务,分析其对服务器各部件能耗的影响;利用“主成分分析法”分析各部件参数对能耗的贡献并选择最具代表性的参数,进而结合多元线性回归和非线性回归方法建立能耗模型. 实验结果表明,本文建立的能耗模型预测精度能达到95%以上;与其它模型相比,精度可提高3%左右.
关键词:云计算;数据中心;能耗模型;任务类型;能效优化
中图分类号:TP311 文献标志码:A
Energy Consumption Modeling and Quantitative
Calculation of Servers in Cloud Data Center
ZHOU Zhou1,2,YUAN Yujunming2,LI Fangmin2
(1. College of Information Science and Engineering,Hunan University,Changsha 410082,China;
2. School of Computer Engineering and Applied Mathematics,Changsha University,Changsha 410022,China)
Abstract:Building an accurate energy-consumption model of servers can assist resource providers in predicting and optimizing energy consumption of data center. To address the problem of low accuracy of energy consumption model caused by the failure to consider "load characteristics" of servers in data center, a new energy consumption model and quantitative calculation method are proposed in this paper. The main ideas are summarized as follows: Firstly, we divide the tasks into three classes: CPU intensive task, transactional web task, and I/O intensive task. Then, energy consumption contributions of all components in a server are analyzed. After that, the dominant component parameters of server energy consumption are chosen by using the Principal Component Analysis (PCA), to build a power model through the multiple linear regression method and non-linear regression method. Experimental results show that the prediction accuracy of the proposed energy consumption model can achieve more than 95%. Compared with other energy consumption models, the accuracy can be improved by around 3%.
Key words:cloud computing;data center;energy consumption model;task types;energy efficiency optimization
隨着云计算数据中心的大量新建,数据中心的能耗问题越来越严重. 近期研究显示[1-2]:全球数据中心的总数已超过300万个,耗电量占全球耗电量的1.1%~1.5%. 我国数据中心也发展迅速,总数已达到40万个,年耗电量已超过500亿千瓦,占全国总耗电量的1.5%. 如果以数据中心的PUE(平均电能使用效率)指数来评测,全球先进数据中心的PUE指数为1.2,而我国的PUE指数大于2.2. 与此同时,大量的报告也显示[3-5]:许多高性能数据中心服务器的利用率却远远低于50%,其原因在于数据中心资源未得到“有效”利用. 因此,节能优化算法的提出有助于提高系统的资源利用率和单位能耗的效用.
能耗模型作为“节能优化算法”的基础[6-7],其准确性直接关系到优化算法的优劣. 一个精确、通用、有效的能耗模型不仅为优化算法提供基础,而且也有利于该模型的扩充. 对于云资源提供者来说,构建精确的能耗模型有助于资源提供者预测和优化数据中心的能耗,提高单位能耗的效用. 因此,对其研究具有十分重要的现实意义.
本文的主要工作如下:
1)基于“任务的特征”构建能耗模型. 不同于其它的能耗模型仅考虑CPU密集型任务,在本文中,基于“任务特征”的不同,任务被划分为三类,分别为计算密集型任务、Web事务型任务和I/O密集型任务.
2)不同于已存在的能耗模型仅考虑CPU和内存部件,而忽略了磁盘和网络接口卡部件,本文所提出的能耗模型考虑了与能耗有关的所有部件如CPU、内存、磁盘和网络接口卡.
3)使用“主成分分析法”分析各部件参数对能耗的贡献并选择最具代表性的参数.
4)运用大量的实验证明了本文所提出能耗模型的精确性和有效性.
1 相关研究
目前,对能耗模型的研究可以分为两类,一类是基于系统利用率的能耗模型[8-12],另一类是基于性能计数器的能耗模型[13-17].
基于系统利用率的能耗模型的主要思想是利用服务器各主要部件的利用率,构建能耗模型. 文献[8]基于服务器中资源使用情况,结合回归方法建立了线性模型. 文献[9]结合三个参数(%Processor Time,%Memory used,%Page Faults/s)提出了一种CMP (CPU利用率,内存利用率和Pagefaults) 模型,相比较以往的能耗模型,该方法具有一定的优势,但该方法因选择的参数有限且没有考虑到负载的特征,其能耗模型的精度仍有待提高. 在文献[12]中,罗亮等人针对数据中心的单台服务器提出了一种高精度的能耗模型,该模型分析了不同参数对服务器能耗的影响,然后结合多元线性回归和非线性回归的方法建立能耗模型. 同样,文献[11]在线性模型(Linear Model)的基础上提出了一种改进的能耗模型叫Cubic Model,该模型认为服务器的能耗与处理器(CPU)不应是线性关系,而是立方关系. 文献[12]基于能耗和系统资源利用率的关系,提出了一种服务器能耗经验模型(Linear Model). 此类能耗模型的优点是易于实现且能耗模型的精度较高.
基于性能计数器的能耗模型的基本思想可概括為:根据PMC与设备能耗之间的关系,针对不同设备(包括处理器、内存、磁盘、I/O外部设备)筛选出最具代表性的“PMC集合”;然后通过统计分析的方法,建立PMC事件与设备功耗之间的函数关系,这种关系既可以是线性关系、也可以是非线性关系. 在文献[13]中,程华等提出了一种基于细粒度的实时能耗模型,该模型由模型设定、性能计数器参数选取、数据采集、模型求解和性能评估这五个部分组成. 在此文中,作者选择PMC集合(包含二十多个参数)建立系统能耗模型. 文献[14]通过运行负载,在考虑处理器和内存等因素下,基于PMC方法建立服务器的能耗模型. 在文献[15]中,作者在考虑CPU和内存两大因素的条件下,提出了一种Ramon Model. 在文献[16]中,Singh等使用PMC方法构建实时的能耗模型. 在文献[17]中,肖鹏等首先形式化资源利用率与能耗之间的关系,然后基于性能计数器提出了一种新型的能耗模型,最后基于该能耗模型提出了一种虚拟机调度算法. 此类方法因采集到的事件太多,成本相对较高,模型也较为复杂,故不利于该模型扩充.
2 能耗模型的参数选择
数据中心服务器的能耗建模如图1所示. 它包含数据采样、参数的筛选、建立模型和评估模型四个步骤.
1)数据采样. 数据采样是数据中心能耗建模的第一步,这一步的主要工作是采集系统的数据,采样的基本方法有基于性能计数器或者基于系统资源利用率.
2)参数的筛选. 在采样数据之后,就需要对采集到的参数进行筛选. 因为采样的参数有些是与系统能耗相关的,有些是不相关的. 如何筛选这些参数呢?此时可以借助于“主成分分析法”或者“相关系数矩阵法”去筛选.
3)建立模型. 这一步的主要工作是利用前面筛选出的参数,借助于数学中的线性回归或者非线性回归方法(多项式回归,幂回归,指数回归,支持向量机回归)建立能耗模型.
4) 评估模型. 这一步的主要工作是对前面建立起来的能耗模型进行评估,比较所得到能耗预测值与真实值的差别,目的是确定该模型的准确性和有效性.
2.1 各部件能耗的代表参数
作为云计算数据中心的任何一台服务器,哪些参数应该被选择去构建能耗模型呢?如果参数选择过少,将导致构建出来的能耗模型精度不够,如果参数选择过多,将导致开销增加且不利于该模型的扩展. 因此,选择合适的参数构建能耗模型极其重要. 对于数据中心的任何一台服务器,其总功率主要由其处理器(CPU)、内存、磁盘和网络接口卡的功率决定. 设Psystem是服务器的功率,参数PCPU、Pmemory、Pdisk和 Pnetwork分别代表该服务器的处理器(CPU)、内存、磁盘和网络接口卡功率,则Psystem可以表示如下:
Psystem = PCPU + Pmemory + Pdisk + Pnetwork + σ (1)
式中:参数σ是除CPU、内存、磁盘和网络接口卡之外的其它部件功率,可看作常数. 对于处理器的功率PCPU,可用式(2)表达[18]:
PCPU = (Pmax - Pidle) × U + Pidle (2)
式中:参数Pmax代表该部件最大的功率,Pidle代表该部件空闲时的功率,U代表该部件的CPU利用率. 由于PCPU的值与参数U相关,所以在监控CPU的能耗时,参数“Processor Time”被选作处理器的代表性参数. 参数“Processor Time”指的是系统中所有处理器都处于繁忙状态的时间百分比,即CPU的利用率. 对于Pmemory的值,可以用式(3)表达[18]:
Pmemory = PPRE + PACT + PRD + PWR + PREF (3)
式中:PPRE、PACT、PRD、PWR和 PREF分别代表预充电(PPRE)、活动状态 (PACT)、读状态 (PRD)、写状态 (PWR) 和刷新状态 (PREF)的功率. 由于Pmemory的值与读和写状态有关,因此,在监控Pmemory的能耗时,“Memory Used”和“Page Fault/Sec”被选作内存的代表性参数. “Memory Used”指的是内存的利用率,“Page Fault/Sec”指的是处理器处理错误页的综合速率,单位是错误页数/s. 当处理器请求一个不在其工作集(在物理内存中的空间)内的代码或数据时出现的页错误. 这个错误包括硬错误(那些需要磁盘访问的)和软错误(在物理内存的其它地方找到的错误页). 对于Pdisk的值,可以用式(4)来表示[18]:
Pdisk = PREAD + PWRITE + PIDLE (4)
式中:参数PREAD、PWRITE和PIDLE分别代表磁盘读、写和空闲时的功率. 在监控磁盘的能耗时,“Disk time” 和“Disk Bytes/Sec”被选作磁盘的代表性参数. “Disk time”指的是磁盘驱动器忙于读或写入请求等服务所用的时间百分比,“Disk Bytes/Sec”指的是在进行写入或读取操作时从磁盘上传送或传出的字节速率.
对于Pnetwork的值,可以用式(5)计算[18]:
Pnetwork = C0 + C1 × (5)
式中:参数C0和C1可认为是一个常数,参数S指的是文件大小,单位是MB;参数B指的是带宽,单位是MB/s. 在监视网络接口卡的能耗时,“Bytes Total/Sec”和“Current Bandwidth”被选作网络接口卡的代表性参数. “Bytes Total/Sec”指的是在每个网络适配器上发送和接收字节的速率,包括帧字符在内. “Current Bandwidth”指的是目前带宽.
2.2 计算密集型任务的参数选择
计算密集型任务也叫CPU密集型任务. 全球标准性能评估公司SPEC提供的CPU2006[19-20]数据集就是标准计算密集型任务,该数据集包含“401.bzip2”、“403.gcc”、“429.mcf”、“453.povray”和“450.soplex”等子项. 以DELL PowerEdge R720服务器为例(服务器配置见表1),当它运行“401.bzip2”任务时,其在不同负载下的能耗和相关参数值如表2所示.
从表2得出:当“Processor Time” = 4.23% ,Memory Used = 4.47%,Page Fault/Sec = 512.78,Disk Time = 0.66,Disk Bytes/Sec = 4 102.28,Bytes Total/Sec =562.00和Current Bandwidth = 9.22 × 1018時,此时的能耗为122.49 W. 对于这7个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec和Current Bandwidth),它们是如何影响能耗的呢?哪些与能耗相关?哪些与能耗不相关呢?为解决这个问题,利用SPSS中的“主成分分析法”[21]分析每个参数的贡献(即因子贡献),表3列出了每个因子的贡献.
表3表明:参数“Processor Time”对能耗的贡献是62%,“Disk Bytes/Sec”是19%,“Disk Time”是14%,“Page Fault/Sec”是4%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0. 这些数据说明,“Processor Time”对能耗的贡献最大,而“Bytes Total/Sec”和“Current Bandwidth”对能耗没有贡献. 因此,在下一节能耗建模中,值不为零的5个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”被选中用于实验建模.
2.3 Web事务型任务的参数选择
HP LoadRunner[22-23]是一种典型的Web事务型任务,以DELL PowerEdge R720服务器为例(服务器配置见表1),当它运行“HP LoadRunner”任务,在用户数是3 000时,采用同样的办法可以得到每个参数对能耗的贡献即因子贡献,表4展示了这7个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec和Current Bandwidth)对能耗的贡献.
从表4可以看出,参数“Processor Time”对能耗的贡献是63%,“Disk Bytes/Sec”是21%,“Disk Time”是11%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”是1%,“Current Bandwidth”是0. 这些数据说明,“Processor Time”对能耗的贡献最大,而“Current Bandwidth”为0即表示对能耗没有贡献. 因此,在下一节能耗建模中,值不为零的6个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”被选中用于实验建模.
2.4 I/O密集型任务的参数选择
Iozone[24-25]是一种典型的I/O密集型任务,以DELL PowerEdge R720服务器为例(服务器配置见表1),当它运行Iozone数据集时,采用同样的办法可得到每个参数对能耗的贡献即因子贡献,表5展示了这7个参数(Processor Time,Memory Used,Page Fault/Sec,Disk Time,Disk Bytes/Sec,Bytes Total/Sec和Current Bandwidth)对能耗的贡献. 从表5可以看出,参数“Processor Time”对能耗的贡献是53%,“Disk Bytes/Sec”是27%,“Disk Time”是15%,“Page Fault/Sec”是3%,“Memory Used”是1%,“Bytes Total/Sec”和“Current Bandwidth”都是0. 這些数据说明,“Processor Time”对能耗的贡献最大,而“Bytes Total/Sec”和“Current Bandwidth”都为0即表示对能耗没有贡献. 因此,在下一节能耗建模中,值不为零的五个参数“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”都被选中用于实验建模.
3 能耗建模
对于不同的任务类型,第二节已确定有那些参数被选中用于能耗建模. 在这一节中将使用EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型. 对于多元线性回归法,其包含m个因变量的回归模型如下:
y = β0 + β1 x1 + β2 x2 + … + βm xm + ε (6)
式中:变量y是观测到的真实能耗; β0,β1,β2,…,βm是回归系数;ε是随机误差. 对于幂回归法,其包含m个因变量的回归模型如下:
y = b0 xb11·xb22·xb33 … xbmm + ε (7)
式中:变量y是观测到的真实值;b0,b1,b2,…,bm是回归系数;ε是随机误差. 对于指数回归法,其包含m个变量的回归模型如下:
y = β0 e + ε (8)
式中:变量y是观测到的真实值;β0,β1,β2,…,βm是回归系数;ε是随机误差. 对于多项式回归,其包含m个变量的回归模型如下:
y = β0 + β1 (x1)2 + β2 x2 + … + βm xm + ε (9)
式中:变量y是观测到的真实值;β0,β1,β2,…,βm是回归系数;ε是随机误差.
为方便3.1~3.3节中所述内容的说明,表6列出了常用的参数及其代表的含义.
3.1 计算密集型任务的能耗模型
对于计算密集型任务CPU2006[19-20]数据集,结合2.2节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(10)~(13):
y=102.916 9+1.967 511x1-1.37×10-05x2 -
0.001 408x3+1.29×10-05x4+2.528 892x5
(10)
y = e4.840 775×(x1)0.219 818×(x2)-0.056 527×(x3)0.067 893×
(x4)0.000 708×(x5)0.096 609 (11)
y=111.459 8+0.151 606(x1)2-1.83×10-05x2 +
0.420 755x3+1.08×10-07x4+1.816 320x5
(13)
式中:参数y,x1,x2,x3,x4,x5分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
3.2 Web事务型任务的能耗模型
对于Web事务型任务HP LoadRunner[22-23],在用户数3 000情况下,结合2.3节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(14)~(17):
y=-869.7-14.28x1-8.68×10-05x2+22.92x3+
0.002 449x4+234.233 9x5-0.067 755x6
(14)
y = e8.920 533×(x1)0.198 811×(x2)-0.008 926×(x3)-0.028 378×
(x4)-0.016 527×(x5)-2.920 025×(x6)-0.014 455 (15)
(16)
y=-334.156 9-0.115 852(x1)2-6.70×10-05x2 +
16.867x3+0.000 406x4+102.1x5-0.079 7x6
(17)
式中:参数y,x1,x2,x3,x4,x5,x6分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”,“Memory Used”和“Bytes Total/Sec”.
3.3 I/O密集型任务的能耗模型
对于I/O密集型任务Iozone[24-25],结合2.4节的代表性参数和EViews 8.0[26]软件,分别用多元线性回归法、幂回归法、指数回归法和多项式回归法建立能耗模型,见公式(18)~(21):
y=111.594 3+9.173 805x1-1.51×10-06x2 +
2.037 900x3-0.000 781x4-19.462 70x5
(18)
y = e5.626 638 × (x1)0.038 072 × (x2)-0.000 339 × (x3)-0.054 210 ×
(x4)-0.010 081 × (x5)-0.751 834 (19)
y=78.997 36+1.459 156(x1)2-1.51×10-06x2+
2.667 544x3-0.000 969x4-12.175 60x5 (21)
式中:参数y,x1,x2,x3,x4,x5分别代表能耗“Processor Time”,“Disk Bytes/Sec”,“Disk Time”,“Page Fault/Sec”和“Memory Used”.
4 实验结果及分析
本文所用的服务器是DELL PowerEdge R720服务器(见表1),CPU频率是2.0 GHz(2×6核),内存是DDR2 20 G,磁盘是2×1 TB,网络接口卡是Intel quad‐port Gigabit network adapter. 实验测量能耗的工具是北电仪表公司所生产的Power Bay-SSM. 计算密集型任务使用的是“403.gcc”,“429.mcf”,“401.bzip2”,“453.povray”和“450.soplex”数据集[19-20]. 对于“Web事务型任务”和“I/O密集型任务”,则分别使用“LoadRunner”[22-23]和“Iozone”数据集[24-25],这两个数据集每次产生任务都是“随机生成”.
为评价本文所建模型的精度,采用式(22)计算每个模型的相对误差:
式中:Powerpredict表示能耗的预测值;Powertrue表示能耗的真实值;Powererror表示能耗的相对误差.
为评价能耗模型的好坏,选择Linear Model[12],Cubic Model[11]和Ramon Model[15]能耗模型作对比.
4.1 计算密集型任务的实验结果及分析
利用3.1节所建立的能耗模型,运行计算密集型任务CPU2006[19-20]数据集,得到预测值和真实值的相对误差,如图2和图3所示.
图2和图3分别展示了这7种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model和Ramon Model)的能耗和相对误差. 这4种模型(多元线性回归、幂回归、指数回归和多项式回归)优于Ramon Model,原因在于两方面:第一,这4种模型在建模时考虑了处理器(CPU)、内存、磁盘和网络接口卡因素,而Ramon Model仅考虑处理器(CPU)和内存因素. 第二,这4种模型(多元线性回归、幂回归、指数回归和多项式回归)考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度. Ramon Model优于Linear Model和Cubic Model,原因在于其考虑了处理器(CPU)和内存两个因素,而Linear Model和Cubic Model仅考虑CPU因素.
4.2 Web事务型任务的实验结果及分析
利用3.2节所建立的能耗模型,运行Web事务型任务HP LoadRunner[22-23],在用户数3 000情况下,得到预测值和真实值的相对误差,如图4和图5所示.
图4和图5分别展示了这7种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model和Ramon Model)的能耗和相对误差. 这4种模型(多元线性回归、幂回归、指数回归和多项式回归)相比较Ramon Model,其能耗精度提高1%以上,其原因可归结为两方面:第一,Web事务型任务的特点决定了该类任务对内存和网络的访问较为频繁,Ramon Model只考慮了CPU和内存因素,而这4种能耗模型考虑了处理器、内存、磁盘和网络接口卡这4个因素. 第二,这4种模型考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度.
4.3 I/O密集型任务的实验结果及分析
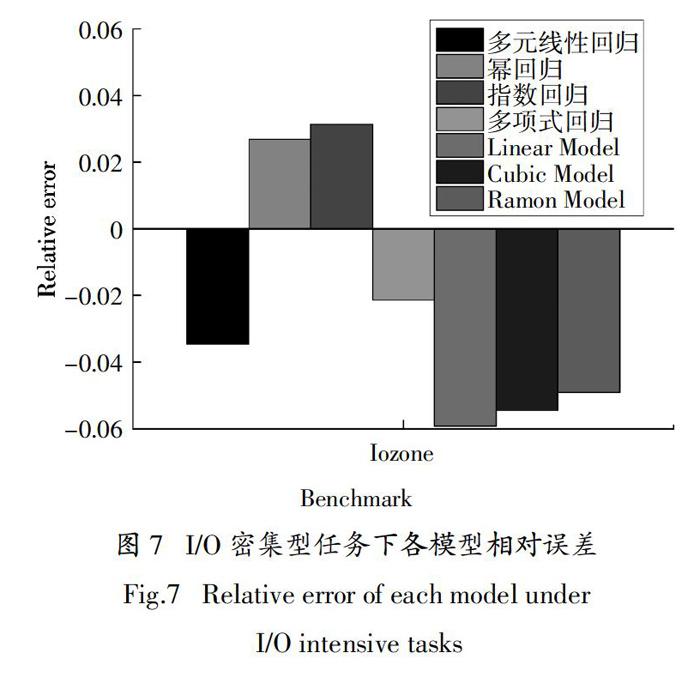
利用3.3节所建立的能耗模型,运行I/O密集型任务Iozone[24-25]数据集,得到预测值和真实值的相对误差,如图6和图7所示.
图6和图7分别展示了这7种能耗模型(多元线性回归、幂回归、指数回归、多项式回归、Linear Model、Cubic Model和Ramon Model)的能耗和相对误差. 图7表明,这4种能耗模型(多元线性回归、幂回归、指数回归和多项式回归)相比较Linear Model,Cubic Model和Ramon Model,其能耗精度提高3%左右,其原因可归纳为以下两个方面:第一,I/O密集型任务的特点是对磁盘的访问较为频繁,因此在建模时应该考虑处理器、内存和磁盘多个因素. 这4种能耗模型考虑了处理器、内存、磁盘和网络接口卡这4个因素. 第二,这4种模型考虑了任务的特征并利用“主成分分析法”提高了能耗模型的精度.
4.4 4种模型的对比
根据4.1、4.2和4.3节中的实验结果和分析,不管何种任务类型(计算密集型任务、Web事务型任务和I/O密集型任务),幂回归模型精确度最高,多元线性回归模型一般,指数回归模型和多项式回归模型较差. 因此,在以后的能耗建模中,推荐使用幂回归模型进行能耗建模.
5 总 结
针对数据中心服务器能耗模型精度低的问题,本文根据“任务的特征”结合“主成分分析法”构建了新型的能耗模型. 与其它的能耗模型对比,本文所构建的能耗模型在精度方面提高了3%,其原因可归结为:1)本文所构建的能耗模型考虑了“任务的特征”;2)在能耗模型的构建过程中,考虑了CPU、内存、磁盘和网络接口卡多个因素;3)利用“主成分分析法”筛选出了与能耗有关的部件.
本文所提出的模型有望用于云计算数据中心,为数据中心服务器能耗的“量化”提供理论和实践依据. 同时,本文所提出的模型也可用于评估节能算法的优劣,有助于资源提供者预测和优化数据中心的能耗.
参考文献
[1] RAHIMI M R,VENKATASUBRAMANIAN N,MEHROTRA S,et al. On optimal and fair service allocation in mobile cloud computing [J]. IEEE Transactions on Cloud Computing,2018,6(3):815—828.
[2] 周伏秋,邓良辰,冯升波,等. 综合能源服务发展前景与趋势[J]. 中国能源,2019,37(1):4—8.
ZHOU F Q,DENG L C,FENG S B,et al. Development prospect and trend of integrated energy service [J]. Energy of China,2019,37(1):4—8. (In Chinese)
[3] LIU C,LI K,LI K. A game approach to multi-servers load balancing with load-dependent server availability consideration [J]. IEEE Transactions on Cloud Computing,2018. DOI:10.1109/TCC.2018.2790404.
[4] 邓晓衡,关培源,万志文,等. 基于综合信任的边缘计算资源协同研究[J].计算机研究与发展,2018,55(3):449—477.
DENG X H,GUAN P Y,WAN Z W,et al. Integrated trust based resource cooperation in edge computing [J]. Journal of Computer Research and Development,2018,55(3):449—477. (In Chinese)
[5] JING M,KENLI L,KEQIN L. Profit maximization for cloud brokers in cloud computing [J]. IEEE Transactions on Parallel and Distributed Systems,2019,30(1):190—203.
[6] 林伟伟,吴文泰.面向云计算环境的能耗测量和管理方法[J]. 软件学报,2016,27(4):1026—1041.
LIN W W,WU W T. Energy consumption measurement and management in cloud computing environment[J]. Journal of Software,2016,27(4):1026—1041. (In Chinese)
[7] CHEN Y, LI K, YANG W, et al. Performance-aware model for sparse matrix-matrix multiplication on the sunway TaihuLight supercomputer [J]. IEEE Transactions on Parallel & Distributed Systems,2019,30(4):923—938.
[8] GARG S K,VERSTEEG S,BUYYA R. A framework for ranking of cloud computing services [J]. Future Generation Computer Systems,2013,29(4):1012—1023.
[9] 于俊洋,胡志剛,周舟,等. 计算机系统能耗估量模型研究[J]. 电子科技大学学报(自然科学版),2015,44(3):422—427.
YU J Y,HU Z G,ZHOU Z,et al. A CMP energy consumption estimate model for computer systems[J]. Journal of University of Electronic Science and Technology of China(Natural Sciences),2015,44(3):422—427. (In Chinese)
[10] ZHOU Z,HU Z,YU J,et al. Energy-efficient virtual machine consolidation algorithm in cloud data centers [J]. Journal of Central South University,2017,24(10):2331—2341.
[11] ZHANG X,LU J J,QIN X,et al. A high-level energy consumption model for heterogeneous data centers[J]. Simulation Modelling Practice and Theory,2013,39(2):41—55.
[12] 羅亮,吴文峻,张飞. 面向云计算数据中心的能耗建模方法 [J]. 软件学报,2014,25(7):1371—1387.
LUO L,WU W J,ZHANG F. Energy modeling based on cloud data center [J]. Journal of Software,2014,25(7):1371—1387. (In Chinese)
[13] 程华,陈左宁,孙凝晖,等. 一种基于细粒度性能计数器建立系统实时功耗模型的方法[J]. 计算机学报,2014,37(3):687—699.
CHENG H,CHEN Z N,SUN N H,et al. Build real-time power consumption model of a computer system based on fine-grained performance counters [J]. Chinese Journal of Computers,2014,37(3):687—699. (In Chinese)
[14] BIRCHER W L,JOHN L K. Complete system power estimation using processor performance events[J]. IEEE Transactions on Computers,2012,61(4):563—577.
[15] BERTRAN R,BECERRA Y,CARRERA D,et al. Energy accounting for shared virtualized environments under DVFS using PMC-based power models[J]. Future Generation Computer Systems,2012,28(2):457—468.
[16] SINGH K,BHADAURIA M,MCKEE S A. Real time power estimation and thread scheduling via performance counters [J]. ACM Sigarch Computer Architecture News,2009,37(2):46—55.
[17] XIAO P,HU Z,LIU D,et al. Virtual machine power measuring technique with bounded error in cloud environments[J]. Journal of Network & Computer Applications,2013,36(2):818—828.
[18] CASTANE G G,NUNEZ A,LLOPIS P,et al. E-mc 2:A formal framework for energy modelling in cloud computing[J]. Simulation Modelling Practice and Theory,2013,39(39):56—75.
[19] FANG Y,CHEN Q,XIONG N. A multi-factor monitoring fault tolerance model based on a GPU cluster for big data processing[J]. Information Sciences,2019,496(1):300—316.
[20] The Standard Performance Evaluation Corporation. SPEC cpu2006 Users Guide[EB/OL]. (2006-08-24). https://www.spec.org/cpu2006/.
[21] KANG X,DUAN P,LI S. Hyperspectral image visualization with edge-preserving filtering and principal component analysis[J]. Information Fusion,2020,57(1):130—143.
[22] FAN G,CHEN L,YU H,et al. Formally modeling and analyzing cost-aware job scheduling for cloud data center[J]. Software Practice & Experience,2018,48(9):1536—1559.
[23] HEWLETT P. HP Software Division. HP Load Runner [EB/OL]. [2014-03-02]. http://en.wikipedia.org/wiki/ HP_LoadRunner.
[24] SUYYAGH A,ZILIC Z. Energy and task-aware partitioning on single-ISA clustered heterogeneous processors[J]. IEEE Transactions on Parallel and Distributed Systems,2019,30(10):1—12.
[25] WILLIAM D. Norcott. Iozone File System Benchm Ark[EB/OL]. (2006-10-26). http://www.iozone.org/.
[26] BRO R,SMILDE A K. Principal component analysis [J]. Analytical Methods,2014,6(9):2812—2831.
收稿日期:2020-05-17
基金項目:国家自然科学基金资助项目(61772088,61872403),National Natural Science Foundation of China(61772088,61872403);湖南省重点实验室项目(2019TP1011),Key Laboratory Project of Hunan Province(2019TP1011);大学生创新创业项目(S201911077005),Undergraduate Innovation and Entrepreneurship Program(S201911077005)
作者简介:周舟(1983—),男,湖南衡阳人,湖南大学博士后,长沙学院副教授,博士
通信联系人,E-mail:lifangmin@whut.edu.cn
