节点-区域关联度感知的区域数据分发算法
2020-02-27刘志锴潘达儒陈奋超
刘志锴, 宋 晖, 潘达儒, 陈奋超
(华南师范大学物理与电信工程学院, 广州 510006)
随着大量具备短距离通信能力的智能移动终端的更新和普及,对通信多样性和稳定性的需求在不断提升[1]. 在物联网时代[2],特定区域数据采集的实际应用极为普遍,如局部空气质量检测、图书馆区域热度统计和野生动物迁徙追踪等. 如今,越来越多的移动设备嵌入了功能类型丰富且具有计算、通讯能力的传感器,对声光速信息进行着全方位的感知[3]. 由这些智能终端作为节点构成机会网络[4],可以有效地解决在频繁的网络分割状态下的非实时连接的数据传输问题[5],对区域数据的采集和转发体现出更高的实时性和可靠性[6-7].
目前,关于机会网络的数据转发问题已有一些研究结果. 如:构造了节点亲密程度的评价模型,控制节点在相应区域的数据转发[8];提出了一种考虑节点多社区属性的机会网络路由算法[9];通过社区发现过程中的节点博弈收益,按重要度从大到小排列节点进行消息传送[10];计算节点间的余弦相似度,以选择合适的邻居节点进行消息传递[11];将消息传输过程分为社区内及社区间两部分,采用“多拷贝+控制”的传输机制[12];提出了将一个大范围的传输分解成多个小范围区域的机会分发过程的方案[13]. 然而,以上研究主要聚焦于借助社区(或区域)局部数据的转发来寻求更佳的消息中继节点优化传输性能,本质上都只是将消息传送给目的节点,并没有考虑区域数据共享的情况.
熊永平等[14]提出了一个将感知数据限制在有效区域内扩散的传播模型,但仅停留在理论阶段,没有具体的区域数据机会分发算法. 在时空敏感的地图分区路由算法(SSMZ)[15]中,数据分发采用的是“同区即传”的策略:对地图范围进行区域划分,若判定处于相互通信范围内的任意2个节点在同一分区内,则进行数据的转发. 在SSMZ算法中,数据采集转发的判断依据是节点的分区位置信息,没有考虑该节点与其所在分区的关联度.
本文使用区域关联度提出了节点-区域关联度感知的区域数据分发算法(Regional Data Acquisition Algorithm based on Relevance Perception,RDAA-RP):首先,通过将BM25模型[16]引入到社会属性度量模型,将移动节点的区域关联度映射到BM25模型的权值;然后,计算处理节点与区域间的关联度权值并进行判断;最后,将节点权值与设定的最低阈值作比较,若2个节点权值均高于设定的阈值则进行数据的交换分发,否则结束节点间的通信,从而实现区域内数据依据关联度的有效交换.
1 RDAA-RP算法
1.1 节点区域关联度度量思想
在现实生活中,要求对特定时空的区域数据进行有效采集分发的应用场景极为普遍,该场景的特点是区域类型各异、节点数量多且数据量大. 一般地,有效的采集要求绝大部分节点能够共享(获得)本区域的消息数据,并能够减少重要性较低的区域数据的影响,屏蔽关联度低或无关节点数据带来的干扰. 为实现这一目的,算法必须准确量化节点与区域之间的关联度.
在区域特定数据采集分发中,如何萃取节点的区域移动属性并量化为可计算的关联度是一个关键问题. 通过关联度的量化,设置最低阈值为节点通信的限制条件,可以控制关联程度不同的一定数量节点参与数据交换的过程,从而减少较低关联性节点数据所带来的影响.
节点对区域相关性的量化本质上是一个匹配过程:首先,将所有节点循环与各个区域进行匹配比较;然后,借助某种数学模型得到匹配值. 在多个区域间匹配各个节点的过程,类似于在多份文本文档中检索相关词的操作. 在区域数据采集中引入文本检索模型,将节点当作关键词,即可得到对多个可视为文本的区域的关联度数值.
作为搜索引擎的核心组成部分,相关度对最终的算法性能起着关键性作用,不同的检索模型得到的相关度有明显差异. 其中,BM25模型所运用的算法是一种当前最流行使用的基于RSJ概率检索模型的相关度计算算法,引入了查询目标在整个查询集合中的权值及查询目标本身权值,并考虑了经验参数. 本文将BM25模型应用到区域数据采集中,可以有效地计算各节点对于不同区域的关联度属性,将移动节点的区域属性映射到BM25模型中,从而得到节点i关于区域j的权值.
1.2 算法步骤
RDAA-RP算法的核心思想是:将移动节点与区域之间的关联度映射到BM25模型[16]的权值上. 权值的计算综合考虑了区域的相对重要性及节点在区域停留的时间片(即固定时间间隔)数量,有效地描述了节点所携带数据的必要性及重要性. 在算法的实现过程中,会以单个时间片的长度持续刷新节点的区域信息,并同步计算和更新所有节点与不同区域之间的对应权值. 当2个相遇节点满足一定条件,即位于同一区域且与该区域的关联度均大于设定的阈值时,才能互相转发数据. 同时,该算法保留了地图分区算法(SSMZ)[15]的边缘检测机制,对在区域边缘徘徊移动的节点作出了有效的区域划分判定.
1.2.1 记录和更新节点的区域属性 对地图进行区域划分时可以采用不同的标准,如区域的功能定义、区域的距离范围. 并且,划分方式的不同将在一定程度上导致网络性能的差异. 本文沿用SSMZ算法的划分方式:
首先,在二维平面的层次上进行地图分区,将地图划分为X2(X≥3N+)个面积相等的区域,并对各个区域按自左上至右下的顺序依次赋予0~X2-1的编码.
然后,以单个时间片的长度作为更新间隔(本算法将其设置为0.1 s),持续刷新节点的地理位置,将从仿真器直接获得的节点坐标转换成对应所在的区域值. 该过程具体为:将节点的横纵向坐标分别与地图区域的长宽进行对比,从而得到横纵向所对应区域的行列数,再以此行列数定位到对应的区域编码中. 例如,将一个长4 500 m、宽3 000 m的地图划分为9个区域,则坐标为(1 200,2 500)的节点对应该地图的第2行第0列,再根据区域自左上至右下的编码规则,则可得到该节点的区域值为6.
以此编码规则,可以建立一个全局的二维数组S,记录移动节点对区域的访问属性. 数组每行对应1个节点,每列对应1个区域,则sij代表了第i个节点对第j个区域的访问频次. 在每次固定间隔的刷新后,所有节点对当前所属区域的时间片数量加1并记录保存在二维数组中,待下一过程计算权值时调用.
1.2.2 计算表征节点-区域关联度的权值 计算权值时引入BM25模型[16]的思想,以节点在区域所停留的时间作为关联度的基本度量单位. 设网络中节点数量为n,地图分成m个区域,定义每个节点的区域位置更新间隔(或称为时间片长度)均为t,节点i(0≤i≤n)在区域j(0≤j≤m)停留的总时间为Tij,节点的时间片数量sij=Tij/t可以反映节点i对于区域j的访问频次,则n行m列的二维矩阵S表示所有节点对不同区域的访问时间片数量. 显然,时间片数量越大,节点对该区域的访问频次越高.

(1)
其中,k1和b均为经验参数,k1取值范围通常为[1,2],b用来调节节点i的时间片比例,取值范围为[0,1].
首先,得到表示区域j在整个地图所有区域中的相对重要性的区域平衡因子:
(2)
其中,n为节点总数;dj代表所有节点中访问区域j的节点数,即区域j的节点密度.
然后,调用二维数组S所记录的节点访问时间片数值,计算得到节点平衡因子
(3)

最后,得到最终的权值,以反映各节点对不同区域的关联度:
wij=Fij*Rj,
(4)
其中,权值wij代表移动节点i对于区域j的关联度. 因为该区域j的节点密度dj较低,所以节点i对区域j的访问时间片数量sij越大,计算得到的权值就越大,对应的关联度也越高;反之则关联度越低.
1.2.3 数据分发 当网络中任意2个节点进入相互的通信范围内时,首先调用2个节点对应的区域值进行比较:若2个区域值相同,则说明2个节点处于同一区域,进入权值判断环节;若2个区域值不同,则进入判断是否修改所属区域值的环节.
在权值判断环节,用2个节点对应的区域值分别与设定的最低阈值作比较. 若2个节点权值均高于设定的阈值,则进行数据的交换分发,否则结束节点间的通信.
若进入通信范围的2个节点被判断为不属于同一区域,则分别将对方节点当前的所属区域分区属性更新为自己的历史区域分区属性,并记录在数组中. 当数组中循环存储的3个历史值均为同一值时,便将该值强制赋给该节点的当前所属区域,表示该节点已经进入最近遇到的节点所在的区域. 若数组中存储的历史值不完全相同,则说明该节点未进入新的区域,不修改自身所属区域分区属性,并因通信节点的所属区域不同而结束通信.
节点间的通信自动结束发生在相遇节点完成消息交换分发后,或是在权值判断不满足限制条件后,或是在边缘检测中节点不修改所属区域后.
具体的算法流程见图1.
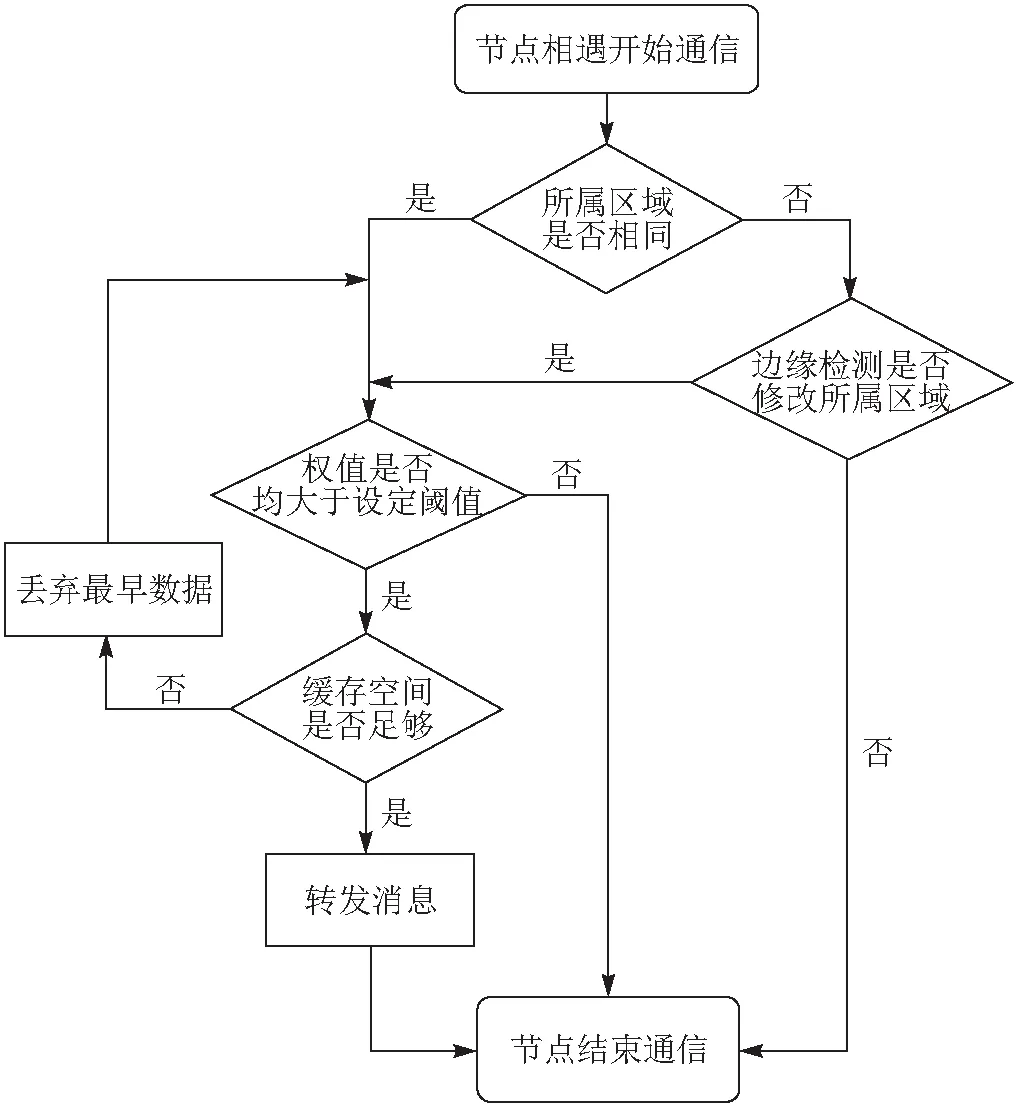
图1 基于BM25模型的区域数据分发算法流程图Figure 1 The flow chart of regional data distribution algorithm based on the BM25 model
2 仿真结果与讨论
在不同经验参数、不同节点缓存大小和不同传输速度的情况下, 对比RDAA-RP算法、SSMZ算法和Epidemic算法[15]的性能. 同时,在保持环境参数设置相同的基础上,对比RDAA-RP算法在不同的转发阈值下的性能.
2.1 仿真场景与性能指标
采用机会网络仿真平台(ONE仿真器)对算法性能进行实验仿真. 仿真实验场景采用ONE自带的典型城市地图,地图面积为4 500 m*3 400 m,场景更新间隔为0.1 s,仿真时间为43 200 s(即24 h). 每25~35 s产生1份消息,生存周期TTL=300 min,数据大小固定为100 kB. 节点类型包括了行人节点、汽车节点以及带有高速接口的轨道列车节点,行人及汽车节点的移动模型为Shortest Path Map Based Movement(SPMBM),轨道列车节点的移动模型为Map Route Movement(MPM),节点参数设置如表1所示. 所有节点中,只有轨道列车节点包括1个蓝牙接口与1个高速接口,其余节点均为蓝牙接口. 蓝牙接口的传输速度为250 KB/s,传输范围为10 m;高速接口的传输速度为10 MB/s,传输范围为1 000 m.
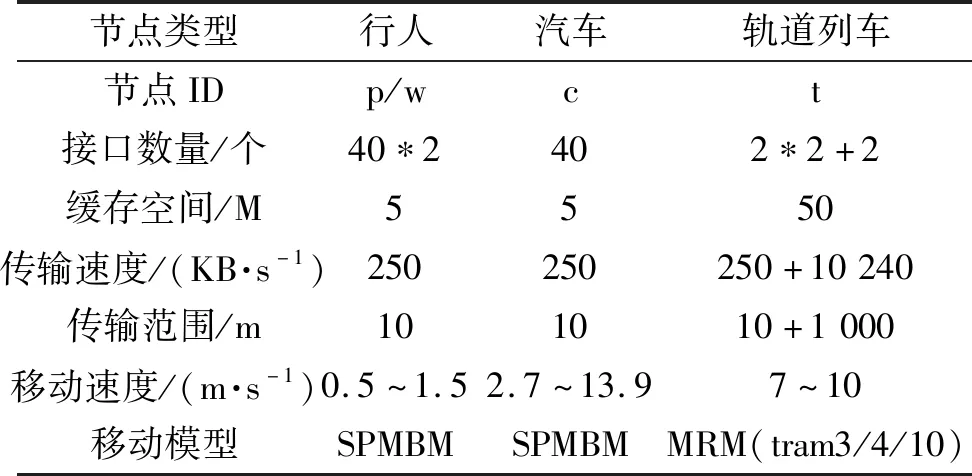
表1 仿真场景设置Table 1 The scene setting for the simulation
为了便于比较,本文采用网络负荷量、平均缓存时间与SSMZ中定义的2个性能参数(消息采集率[15]和采集开销比率[15])来描述区域数据采集的算法性能. 网络负荷量和平均缓存时间的定义如下:
(1)网络负荷量. 该指标表征的是单位时间内,网络上所需负荷的数据量大小:
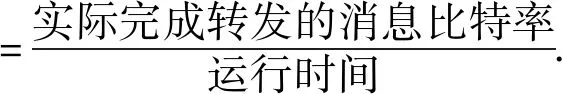
(5)
在一定时间内,消息数量越多,数据空间越大,则网络所需承担的流量越大,由此导致网络拥塞的可能性也越高. 本算法对权值作出转发的阈值限定,可以在一定程度上缓解网络压力.
(2)平均缓存时间. 该指标表征了消息在节点中的平均留存时间,在本文中节点缓存及消息数据大小均固定的条件下,平均缓存时间反映了节点携带消息的能力:
平均缓存时间=
(6)
平均缓存时间越大,消息留存越久,节点间完成数据互传的概率就越高,区域数据采集的性能则更优.
2.2 经验参数确定
由于RDAA-RP算法引入了BM25模型作为节点区域关联度的度量模型,其中包括了2个调节平衡的经验参数(k1和b). 不同经验参数的取值作用到节点平衡因子,将使最终得到的权值wij存在差异,一定程度上影响算法的性能指标. 因此,在对算法性能进行仿真测试前,需要先确定经验参数的值.
当k1[1,2],b[0,1]时,选取k1、b的若干值进行组合,在所有参数设置保持相同的条件下,获取大量数据并取平均值,观察不同的经验参数取值对消息传输率及采集开销比率的影响. 由图2及图3可知:当k1=1.75,b=0.75时,消息采集率最高,采集开销比率则相应地可以获得最低值,BM25模型对区域数据分发算法具有最佳性能效果. 因此,本文仿真实验中的经验参数采用k1=1.75,b=0.75.
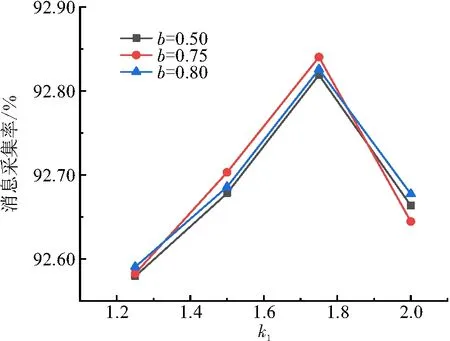
图2 不同经验参数对消息采集率的影响Figure 2 The effect of different empirical parameters on me-ssage collection ratio
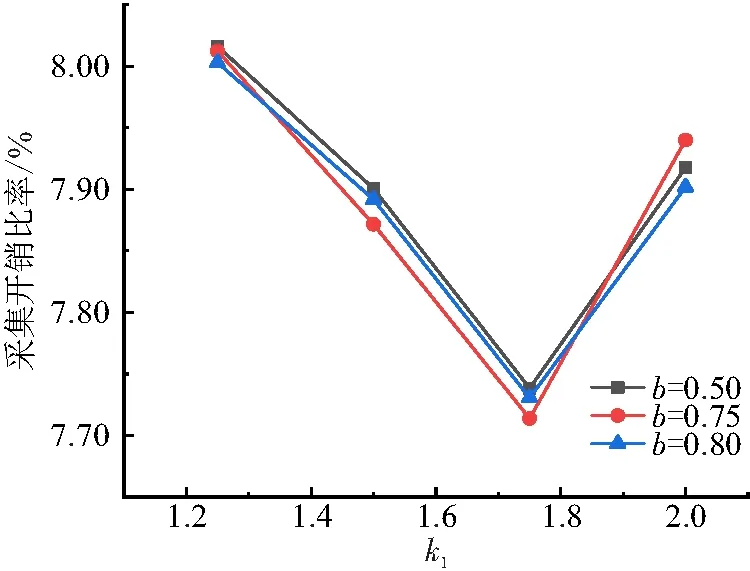
图3 不同经验参数对采集开销比率的影响Figure 3 The effect of different empirical parameters on the acquisition overhead ratio
2.3 RDAA-RP与Epidemic、SSMZ算法的性能比较
2.3.1 不同缓存条件下算法性能对比 不同的节点缓存大小设置将导致算法性能的差异. 在保持其他环境参数设置均相同的基础上,固定阈值为3,修改不同的节点缓存值进行仿真,得到各缓存情况下多种区域划分方式的平均结果,然后对比缓存大小对不同算法性能的影响. 其中,区域数目按照自然数X的平方进行划分,分别划分为9、16、25、36分区.
参照表1的仿真环境设置(除了固定缓存),得到Epidemic、SSMZ、RDAA-RP算法的消息采集率及采集开销比率(图4、图5).
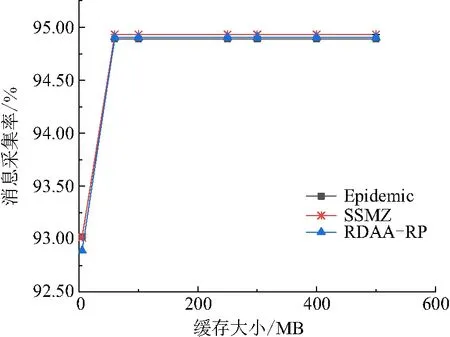
图4 不同缓存下的3种算法的消息采集率Figure 4 The message collection rates of three algorithms under different caches

图5 不同缓存下的3种算法的采集开销比率Figure 5 The acquisition overhead ratios of three algorithms under different caches
由图4可知:当节点缓存大小低于50 MB时,3种算法的消息采集率随着缓存的增大而提升,在缓存大小增加到50 MB之后趋于平稳,且RDAA-RP算法的消息采集率与SSMZ、Epidemic算法基本相当. 由图5可知:(1)3种算法的采集开销比率随着缓存的增大而降低,在缓存大小增加到50 MB之后也同样趋于平稳. (2)RDAA-RP算法的采集开销比率近似于SSMZ算法与Epidemic算法. 这是由于节点缓存的增大,导致因缓存溢出而丢弃的数据包数量减少,成功交换的数据包数量增加,从而提升消息的采集率. 当消息大小固定,节点的缓存空间越小,其所能携带的数据包数量就越少,对“存储-携带”过程的限制程度就越高. 当缓存小于50 MB时,随着缓存的增大,节点携带消息在数量方面的能力增强,整个网络的交付能力提升,因而消息采集率随之增大;综上所述,适当地增大节点缓存能够有效提升消息的采集率,但当超过50 MB之后,缓存的增大已经不能带来更好的作用.
参照表1的仿真环境设置(除了固定缓存),得到Epidemic、SSMZ、RDAA-RP算法的网络负荷量和平均缓存时间(图6、图7).
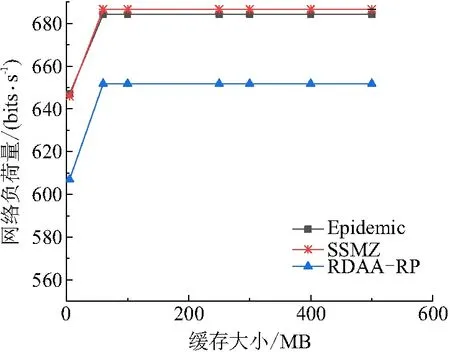
图6 不同缓存下的网络负荷量差异Figure 6 The network load differences under different caches

图7 不同缓存下的平均缓存时间差异Figure 7 The average cache time differences under different caches
由图6可知:(1)随着节点缓存的增大, 3种算法的网络负荷量与缓存大小呈正相关关系;而当缓存超过50 MB并增大到一定程度时,网络负荷量趋于平稳. (2)RDAA算法的网络负荷量始终低于SSMZ算法和Epidemic算法,体现了RDAA算法的优越性. RDAA-RP算法的曲线变化原因为:(1)在一定程度内,节点缓存增大,将增强节点在携带数据包数量方面的能力,从而提升单位时间内网络的交付能力. (2)数据交换频次总数越大,导致网络的负荷量越高. 而在超过了一定值后,由于节点缓存空间充足,携带了网络中一定数量的数据包,则对未拥有的消息的交换要求降低,单位时间内数据流总量趋于不变,网络所负荷的比特数也会持续不变. 因此,RDAA-RP算法在涉及节点缓存时,需要考虑参数设置对于网络压力的影响,在消息采集率、网络负荷量和平均缓存时间等性能指标综合下选择符合实际应用场景的缓存参数设置.
由图7可知:(1)在缓存小于50 MB时,随着节点缓存的增大,3种算法的消息的平均缓存时间均明显提高;而当缓存增大至50 MB时,平均缓存时间均趋于平稳值. 这是因为在固定消息大小的前提下,消息的平均缓存时间与节点缓存大小呈正相关性:缓存越大,节点所能携带的消息数量越多,旧数据包被更新替换的频率变低,因此消息的平均缓存时间更长. 而当缓存增大到一定程度时,充足的空间保证了节点携带了网络中绝大部分消息,数据交换更新频率变得极低,消息的平均缓存时间也趋向于一个平稳值. (2)RDAA-RP算法的平均缓存时间始终略低于其他2种算法,体现了RDAA-RP算法的优越性.
2.3.2 不同传输速率条件下算法性能对比 在无线网络中运用不同的传输技术将得到不同的消息传输速率,从而体现算法的性能差异. 在保持其他环境参数设置均相同的基础上,固定阈值为3,节点缓存大小设置为60 MB,选择不同的节点传输速率进行仿真,得到各传输速率情况下多种区域划分方式得出的平均结果,然后对比传输速率大小设置对RDAA-RP算法性能的作用效果. 其中,区域数目按照自然数X的平方进行划分,本文采用了9、16、25、36分区. 设置传输速率为:采用ZigBee通信协议的250 KB/s,采用3G通信协议的350 KB/s与450 KB/s,采用蓝牙2.0或3.0/4.0通信的1 MB/s与3 MB/s,以及采用4G通信协议的6.25 MB/s与12.5 MB/s. 其中3G通信速度为300~1 024 KB/s,4G通信速度为10~100 MB/s.
参照表1的仿真环境设置(除了固定传输速率),得到Epidemic、SSMZ、RDAA-RP算法的消息采集率及采集开销比率(图8、图9).
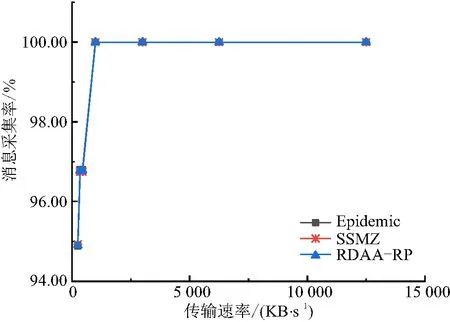
图8 不同传输速率下的消息采集率Figure 8 The message collection rates at different transmission rates

图9 不同传输速率下的采集开销比率Figure 9 The acquisition overhead ratios at transmission rates
由图8可知:(1)当传输速率低于1 000 KB/s时,3种算法的消息采集率随着传输速率的增大而提升,在传输速率增加到1 000 KB/s之后趋于平稳,且RDAA-RP算法的消息采集率与SSMZ、Epidemic算法基本相当. (2)消息采集率并不是随着每一个单独的传输速率的改变而改变,而是以分段区间的形式进行阶段式变化,同属一个区间的传输速率改变并不会带来影响. 比如,图中350 KB/s和450 KB/s是同一个变化区间,1 000 KB/s之后属于另一个变化区间. 而由图9可以看出采集开销比率的变化趋势与图8的消息采集率走向完全相反.
产生以上差异的主要原因为:(1)传输速率的增大,使得消息数据以更短的时长、更高的效率完成了转发. 在小于1 000 KB/s之前,随着速率的增大,消息采集率不断提高,说明在理论上,可以尽可能地提高传输速率以得到更佳的RDAA-RP算法采集率. 但是在1 000 KB/s之后,消息采集率已经高达99%,区域内部节点的数据采集已达到较为饱和的程度,这时继续提高传输速率已经无法对消息采集率产生有效的优化作用. (2)RDAA-RP算法引入了节点和区域间的关联度,并设置了最低转发阈值,以此控制了参与数据采集过程的节点数量. 在仿真过程中采用了阈值的中间值3, 将相当一部分的节点排除在消息交换的范围之外. 网络中的节点总数得到了限制,传输速率的改变所带来的影响将减小,所以消息采集率和采集开销比率在区间范围内产生阶段式的变化.
因此,在实际中使用RDAA-RP算法进行区域数据采集时,为了保证较好的算法性能,应该在成本允许的条件下尽可能选择更高的传输速率.
参照表1的仿真环境设置(除了固定传输速率),得到Epidemic、SSMZ、RDAA-RP算法的网络负荷量和平均缓存时间(图10、图11).

图10 不同传输速率下的网络负荷量差异Figure 10 The network load differences at different transmission rates
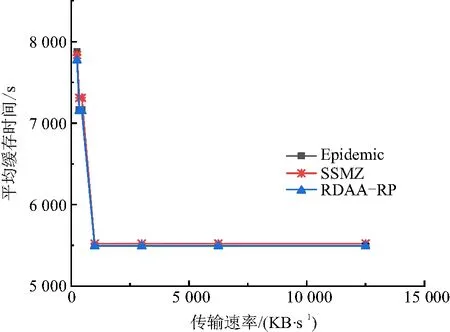
图11 不同传输速率下的平均缓存时间差异Figure 11 The average cache time differences at different transmission rates
由图10可以发现:(1)RDAA-RP算法的网络负荷量与传输速率正相关,但不随着速率的增长而单调增长,而是阶段式增长. 比如,图中350~450 KB/s是一个变化阶段,1 000 KB/s之后是另一个变化阶段. (2)RDAA-RP算法的网络负荷量远低于SSMZ算法和Epidemic算法,体现了该算法的优越性. 这是因为在消息数据包大小及节点缓存固定的前提下,传输速率越快,则完成一次消息交换的时长越短,单位时间内网络所需承载的消息传输数据总流量就越大,表现为网络负荷量的增大. 因此,在具体使用场合中,传输速率的选择也一定程度上受到了网络负荷量的限制,在选择RDAA-RP算法的消息传输速率时,需要考虑所在网络的最大负荷能力,避免发生网络拥堵,影响区域数据采集的过程.
由图11可以看出RDAA-RP算法的优越性:(1)RDAA-RP算法的平均缓存时间随着传输速率的增大呈现总体减小的趋势,且同样地是随着传输速率的区间范围变化而改变,而非跟着传输速率单点变动. 这是因为在固定消息大小及缓存空间的前提下,消息的平均缓存时间与传输速率负相关. 传输速率越大,节点以更高效率完成了数据包转发,节点内缓存的内容更新速度也变快,单个消息的停留时间变短,故平均缓存时间变小. (2)RDAA-RP算法的平均缓存时间始终略低于其他2种算法.
2.4 不同阈值限制下RDAA-RP算法的性能测试
本节在保持环境参数设置相同的基础上,修改不同的阈值进行仿真,得到各阈值限制下多种区域划分方式产生的平均结果,然后对比阈值大小的设置对RDAA-RP算法性能的作用效果. 其中,区域数目按照自然数X的平方进行划分,本文采用了9、16、25、36分区. 消息转发的关联度阈值范围为[0,5.5],本文设置阈值间隔为0.5.
参照表1的环境设置,得到消息采集率对比结果(图12). 由图可知:随着阈值设置的增大,RDAA-RP算法的消息采集率呈现先减小再增大,然后继续减小的变化趋势. 当阈值小于4时,消息采集率与权值之间表现为负相关性;阈值在4~4.5时,采集率随阈值增大而明显提升,甚至达到了最高值,优于图4所示的Epidemic算法的结果;而当阈值在4.5之后,消息采集率减小.
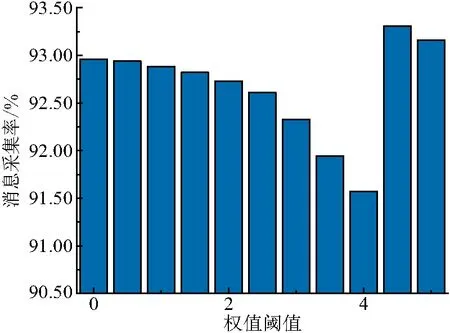
图12 不同阈值选择的消息采集率Figure 12 The message collection rates for different threshold selections
由图13可知:随着阈值设置的增大,RDAA-RP算法的采集开销比率呈现先增大再减小,然后继续增大的变化趋势. 当阈值小于4时,采集开销比率与权值之间表现为正相关性;阈值在4~4.5时,采集开销比率随阈值增大而明显降低,甚至达到了最低值;当阈值大于4.5后,采集开销比率增大.
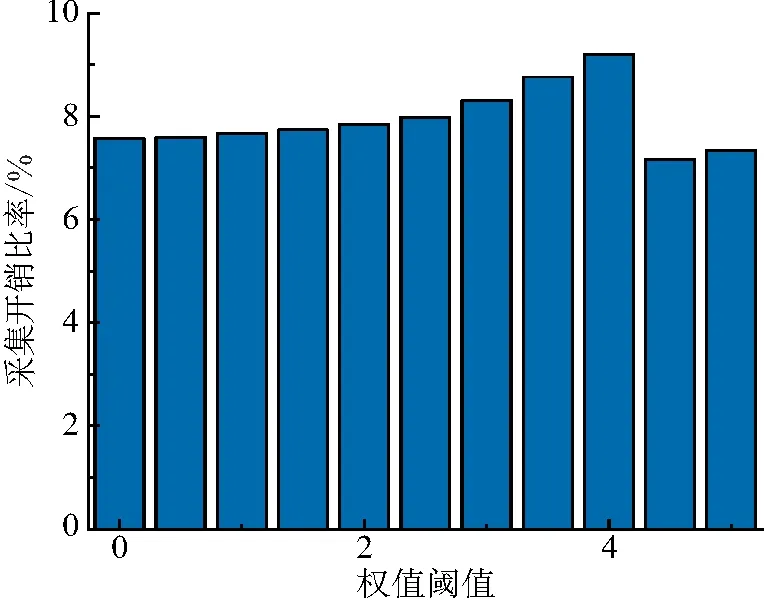
图13 不同阈值选择的采集开销比率Figure 13 The collection overhead ratios for different threshold selections
产生以上差异的主要原因为:(1)当阈值低于4时,所有类型的节点(行人、汽车、轨道列车)均参与数据交换,而影响消息采集率大小的主要因素是节点数量. 阈值越高,则满足限制条件的节点越少,单位时间内网络上所进行转发的数据总量变少,表现为消息采集率的降低. (2)阈值在4~4.5时,节点的主要类型比例发生变化,在多个区域间游走移动的节点被摒弃,具备高关联度、高缓存、高传输速率以及高通信范围特质的列车节点在符合通信要求的节点中占了更多的比例. 在一定程度上,缓存空间充足、传输速率快能够保证消息成功转发的概率更高,通信质量更优. 因此,在阈值设置的这一小范围区间内,消息采集率呈现上升的趋势,且取得最高值. (3)当阈值增大到4.5之后,消息采集率与权值阈值呈现负相关关系. 此现象的原因与阈值低于4时相同,是节点数量变化后产生的结果. 此时的阈值较高,满足筛选条件的节点类型基本固定在少部分节点中间,消息中止或丢弃对最终的采集率削减的影响程度会更高.
通过上述分析可以看出,在不同采集关联度要求的情况下, 应该对阈值设置不同的参考值:需要采集区域中关联度极高的节点数据时,阈值可设置为4.5;当关联程度要求一般时,可以设置为2;对区域节点相关性要求不高的数据采集场景,阈值可设置为0.5. 在实际场景中采用RDAA-RP算法时,需要对区域节点类型和关联度重要性进行事先调查与计划,再综合确定相关参数的设定,选择恰当的消息转发限定阈值.
参照仿真环境设置,得到RDAA-RP算法的网络负荷量和平均缓存时间(图14、图15).
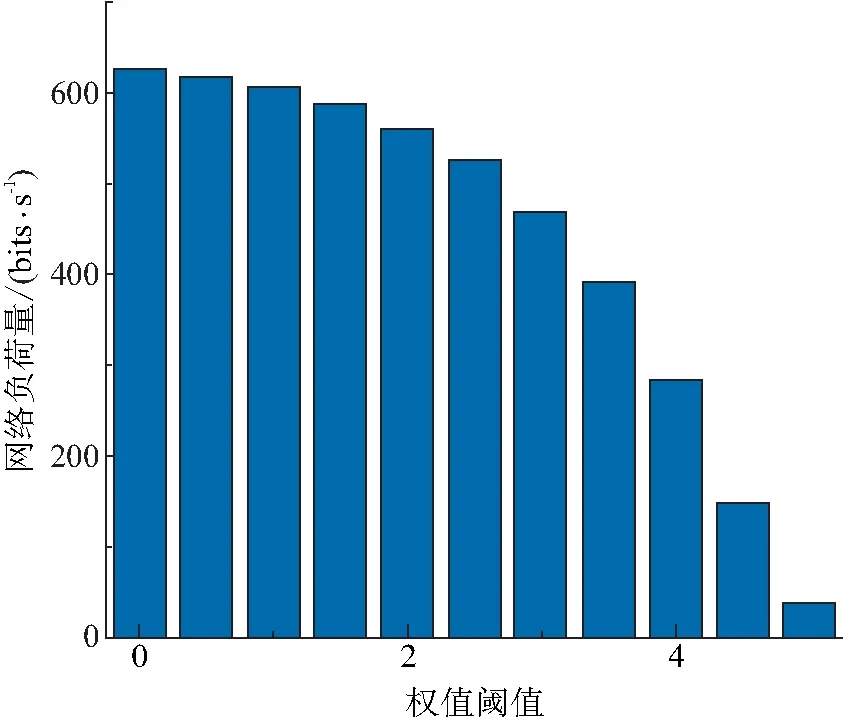
图14 不同阈值选择的网络负荷量差异Figure 14 The network load differences for different threshold selections
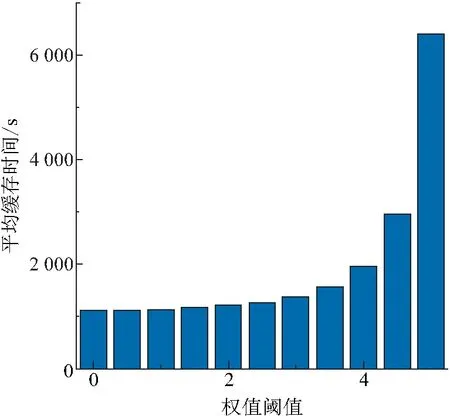
图15 不同阈值选择的平均缓存时间差异Figure 15 The average cache time differences for different threshold selections
由图14可知:(1)随着权值阈值设定的增大,网络负荷量逐渐降低,且在较高值和较低值间存在明显差距. (2)由于权值的引入,所有节点对不同区域的关联度有了度量标准,消息分发最低阈值的设置,将部分节点摒弃在区域数据采集的过程之外. 权值阈值越高,则要求关联度越高,导致参与数据分发的节点数目越少. 节点缓存空间以及消息数据大小固定的前提下,节点数量将直接影响网络负荷量的大小. 节点越少,则单位时间内网络上的数据流量越低,网络所负荷的比特数也越少. 所以,RDAA-RP算法在选择阈值时,应选择更高的参数,以使网络的压力相对缓和. 而当采集区域对节点关联度要求不高时,需避免选择了过低参数而使得网络负荷量偏大、发生网络拥堵的风险系数过高. 实际应用中,不同网络的带宽、负载能力和信噪比等多种因素会使网络的最大负荷量有所不同,所以对阈值的设置也应有所差异.
由图15可知:权值阈值越大,消息的平均缓存时间也越大,两者呈正相关性. 这是因为阈值的增大,使得参与消息转发的节点数变少,节点所携带消息的更新丢弃频率变低,故数据包在节点中的留存时间得到延长,即平均缓存时间增大.
综上所述,作为一个为区域数据采集应用场景服务的数据转发策略,RDAA-RP策略可以在消息采集率性能与Epidemic、SSMZ算法基本相当的情况下,较大程度地优化网络负荷量及消息平均缓存时间这2个性能指标, 提供可靠的区域数据共享分发功能,并能通过不同关联度阈值设置满足节点不同程度相关性的要求.
3 结语
本文围绕区域数据采集分发的场景,并考虑节点所携带消息的相关性,引入BM25模型作为节点区域关联度的度量模型,设计了基于该模型的区域数据分发算法(RDAA-RP). 该算法在转发环节添加了区域属性及节点关联度最低阈值作为限制条件,能够实现区域数据的采集和共享,同时具备了节点相关性筛选控制功能. 仿真结果表明:与Epidemic、SSMZ算法相比,在消息采集率基本相当的情况下,RDAA-RP算法能够较大程度地优化网络负荷量及消息平均缓存时间这2个性能指标. 此外,该算法对不同的转发关联度阈值设置体现了性能上的差异,能够满足选择控制节点不同程度相关性的要求.
