基于不同时频掩模神经网络语音增强的研究
2020-02-22邵榕梓富晓乾田爱生蒲俞姣陈凯
邵榕梓 富晓乾 田爱生 蒲俞姣 陈凯

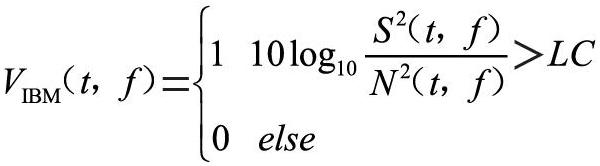
摘 要:在基于时频掩模的深度神经网络语音增强系统中,学习目标的选择对于整体语音增强性能的影响极大,文章针对目前最常用的学习目标——理想二值掩模和理想浮值掩模在语音增强中的效果进行了研究,为验证不同时频掩消除噪声模性能的好坏,设计了多组对比实验,为以后深度学习训练过程中直接选择学习目标提供依据。仿真结果表明:在不同信噪比和不同噪声条件下,理想浮值掩模的性能均好过理想二值掩模。
关键词:语音增强;学习目标;理想二值掩模;理想浮值掩模
中图分类号:TN912.3 文献标识码:A 文章编号:2096-4706(2020)18-0084-03
Abstract:In the deep neural network speech enhancement system based on time-frequency mask,the choice of learning target has a great influence on the overall speech enhancement performance. The article studies the effects of the most commonly used learning goals——ideal binary mask and ideal floating mask in speech enhancement. In order to verify the performance of different time-frequency masks to eliminate noise modes,multiple sets of comparative experiments were designed to provide a basis for direct selection of learning targets in the subsequent deep learning training process. The simulation results show that the performance of the ideal float mask is better than the ideal binary mask under different signal to noise ratio and different noise conditions.
Keywords:speech enhancement;learning goals;ideal binary mask;ideal floating mask
0 引 言
在我们的周围,有这样一个特殊人群,他们外表看起来和正常人一样,但是却听不到我们的声音,无法和人们进行正常的交流。此外,随着我国人口老龄化,老年人口增多,老人们的听觉也多数存在着问题,他们选择佩戴助听器来提高听力。这对于当前的医学水平来说,确实是最直接的方法之一,但是,助听器也存在着很多的不足,例如当人们处于嘈杂的环境中时,助听器把噪声也放大传入人的耳朵,使得助听器的性能被严重影响,导致听力障碍的人们无法听清。因此,我们迫切需要一种可以弥补这一不足的方法来帮助我们的患者,而基于深度神经网络的语音增强就是一种比较有价值的研究方向。
基于深度神经网络的语音增强技术作为解决助听器在嘈雜环境中性能下降这一缺点的关键技术,在保证语音不失真的条件下,能够尽可能减少或消除有噪声语音中的噪声干扰,以获得清晰高质量的增强语音。语音增强技术作为一种基本的信号处理方法得到了广泛的研究,其还可以应用在语音识别、音视频会议以及其他领域,目的就是为了提高语音的质量和可懂度。近几十年来已经出现了许多传统的基于单通道语音增强的算法,其中最具代表性的主要是谱减法[1]、Wiener滤波[2]等,它们通过信号统计信息进行降噪,但当噪声是非平稳信号时,传统算法增强效果差。随着深度学习的发展,人们又提出了几种在机器学习领域中通过有效训练深层神经网络的深度学习算法[3],这一算法在一定程度上提高了深度神经网络语音增强的性能。由于语音信号的时空结构和非线性关系十分明显,传统的语音增强方法无法有效地挖掘语音谱的非线性结构[4],而深度神经网络则通过逐层训练和反向微调,自动学习语音信号的高阶统计信息,因此,基于深度神经网络的语音增强技术成为语音增强技术新的研究热点[5]。
在基于深度神经网络(Deep Neural Network,DNN)的语音增强中,提高人耳对带噪语音的可懂度和感知质量依赖于学习目标的选择。Wang等人提出以理想二值掩蔽(Ideal Binary Mask,IBM)为目标的语噪分离方法[6]。随后,Wang等人在语音分离这一任务中分析对比了一系列基于时频掩蔽的训练目标[7],包括目标IBM、理想浮值掩蔽(Ideal Ratio Mask,IRM)等验证其增强效果。
本文通过基于DNN的语音增强算法,提取语音信号的梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients,MFCC),来探讨在不同信噪比条件下,IRM和IBM对语音增强性能的影响。首先提取带噪语音的特征参数,在此基础上,获得信号的训练目标,即IRM和IBM。通过比较不同信噪比条件下主观语音质量(Perceptual Evaluation of Speech Quality,PESQ)和短时客观可懂度(Short Term Objective Intelligibility,STOI)值的大小,验证IRM和IBM在不同信噪比条件下性能的差异,以便在不同的环境下直接使用合适的学习目标,不同的训练目标增强效果不同,验证需要花费大量的时间和精力,本研究为以后研究者的工作节省了时间。
1 不同时频掩蔽的深度神经网络的语音增强
1.1 深度神经网络结构
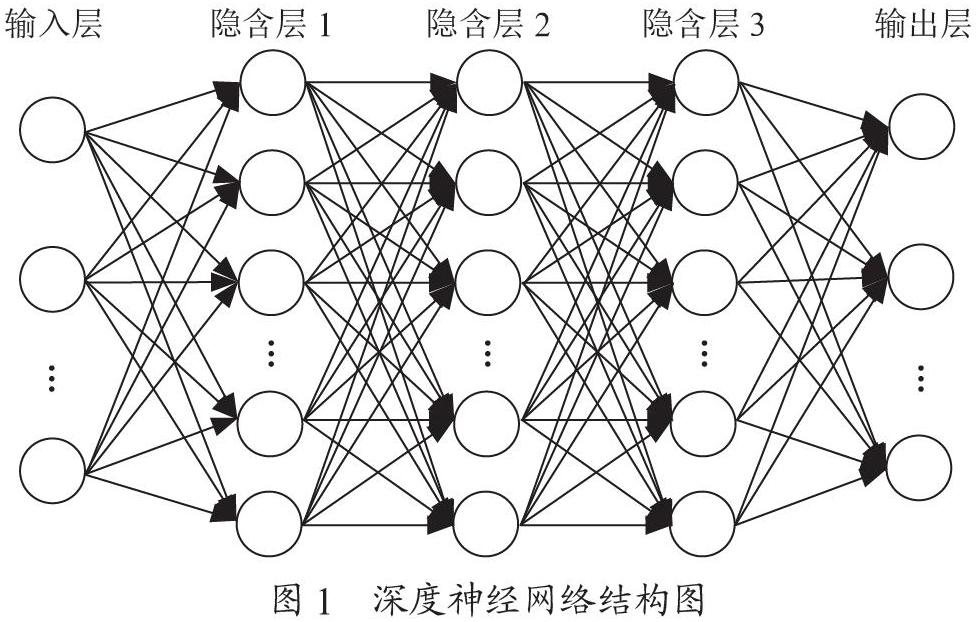
深度神经网络结构主要包括输入层、隐含层和输出层。其中输入层仅负责接收数据,而隐含层将输入数据从原特征空间经过一定转换,转换到适合处理信号的特征空间,促使模型学习数据规律,从而预测数据更加容易。最后将处理完毕后的数据传递至输出层。图1所示为深度神经网络结构图。
1.2 提取MFCC特征
提取的语音特征MFCC,基于人耳听觉感知缩放原理,将感觉到的纯音的频率或音高与其实际测量的频率相关联。与高频时相比,人类在分辨低频时音调的细微变化方面要好得多,此时转换成梅尔(Mel)标度使人听到的声音与实际语音更加匹配。图2所示为MFCC特征提取框图[8]。首先,将信号进行预处理,傅里叶变换并取绝对值。然后,将其通过Mel滤波器组映射得到相应的Mel频谱。最后,对Mel频谱取对数并通过离散余弦变换(Discrete Cosine Transform,DCT)[8],即可获得MFCC特征。
1.3 时频掩模
在基于时频掩模的DNN语音增强系统中,对于整体语音增强性能的影响较大的是学习目标的选择,其直接影响到去除含噪语音中噪声时的语音失真程度或者残留噪声的数量。目前最常用的学习目标包括理想二值掩模和理想浮值掩模等。
1.3.1 理想二值掩模
IBM是基于DNN语音增强方法中的最早使用的学习目标。IBM不仅适用于为具有正常听力的听众,而且适用于听力受损的听众。IBM是由预混语音信号和噪声构成的时频掩模。对于每个时频单元,将IBM定义为:
式中,S2(t,f)和N2(t,f)分别表示第t帧、第f频带的语音能量和噪声能量。对于每个时频单元,如果其局部信噪比大于设置的阈值LC,则将相应的掩模值设置为1,否则将其设置为0。LC的选择对语音清晰度有显著影响,通常将LC设置为比带噪语音信噪比低5 dB,避免丢失语音信息。例如,当带噪语音信噪比为0 dB时,则相应的LC设置为-5 dB。IBM结果中的非零值代表纯净语音占比重较大的时频单元。
1.3.2 理想浮值掩模
IRM是目前基于时频掩模的DNN语音增强中最广泛应用的学习目标,它代表目标纯净语音能量在带噪语音能量中所占的比重,也可看作是一个自适应的IBM,其值在0~1的范围内变化,是一个软判决。IRM的计算表达式为:
式中,(·)χ表示用于缩放掩模值的可调参数,χ可调。
VIRM的取值介于0和1之间,仔细观察发现,在公式的计算形式上IRM与频域维纳滤波器极为相似。当取0.5时,形式上与维纳滤波器的平方根估计类似,是功率谱的最优估计。根据文献[9]中的多次尝试,证明其取0.5是最佳的选择。
2 实验与结果分析
2.1 实验数据
在实验中,从IEEE数据库[10]中随机选择20条纯净的语音数据,选取NoiseX-92噪声库[10]中的Babble、White、Pink、Factory四种噪声,且信噪比从-15 dB到15 dB,步长间隔为5 dB,合成对应的560条带噪语音。选取其中280条作为训练语音,其余280条为测试语音,信号的采样率为16 kHz。
2.2 网络参数
在实验过程中,我们主要的设计思路是保证每次运行时采集的数字必须是随机的,然后在通过采取随机初始化的设计方法和步骤来进行设定预训练的模型参数信息和数据。这次设置学习率的数据信息为0.004(当学习率过大就会导致迭代不收敛,当学习效率太小则会造成收敛速度变得过慢);调优阶段的迭代次数信息为30,学习动量的系数为0.5,迭代前的5次动量设置都为0.5,之后就会设定增到0.9。
2.3 评价语音的标准
文中选用的语音评价标准包括:SNR、PESQ和STOI。其中PESQ近似平均主观意见得分(Mean Opinion Score,MOS),用来评价语音的主观试听效果,PESQ评分范围为0.5~4.5,对应于从低到高的语音质量。STOI是一种较新的可懂度评估方法,STOI的评价度会更加精确、更加客观,并且与语音的实际可懂度高度相关,如果STOI数值越高则表示可懂的程度越高。
2.4 实验比对与结果分析
为了证明IBM和IRM性能的好坏,表1、表2分别给出在不同信噪比和不同噪声条件下基于IBM和IRM的神经网络语音增强算法的PESQ和STOI值,以此分析不同时域掩模的效果。
从表1和表2可以看出:在MFCC特征下,IBM和IRM均对语音有增强的效果,增强的程度不同,IRM对语音增强的效果更好一些;在不同SNR下IRM的STOI值和PESQ值更高,说明经过IRM处理的语音可懂度和舒适度更高。
3 结 论
通过实验,我们得出下面结论:在不同信噪比条件下,基于IRM软判决的神经网络的语音增强算法和基于IBM软判决神经网络的语音增强相比,前者的方法会相对更好一些。之所以IBM的性能较差,其原因主要有两点:第一,IBM对处理信号进行幅度调制的力度更大或者能忽略相位的影响;第二,IRM对参数的估计误差具有鲁棒性。以上两点原因可以归结于IRM能够更好地保留目标信号包络线。如果对参数的估计存在误差,那么IBM就会完全忽略潜在必要的時间频率区域,而IRM对这些区域的处理方式是缩放这些区域。所以,在以后的相关研究中,可以首先考虑使用IRM学习目标,或者将两者结合使用,这样可以为深度学习语音增强算法的训练节约时间。
参考文献:
[1] BOLL S. Suppression of acoustic noise in speech using spectral subtraction [J]. Acoustics,Speech and Signal Processing,IEEE Transactions on,1979,27(2):113-120.
[2] LIM J S,OPPENHEIM A V. All-pole modeling of degraded speech [J]. Acoustics Speech & Signal Processing IEEE Transactions on,1978,26(3):197-210.
[3] HINTON G E,OSINDERO S,TEH Y W. A Fast Learning Algorithm for Deep Belief Nets [J]. Neural Computation,2006,18(7):1527-1554.
[4] 戴礼荣,张仕良.深度语音信号与信息处理:研究进展与展望 [J].数据采集与处理,2014,29(2):171-179.
[5] 韩伟,张雄伟,闵刚,等.基于感知掩蔽深度神经网络的单通道语音增强方法 [J].自动化学报,2017,43(2):248-258.
[6] WANG Y X,WANG D L. Towards Scaling Up Classification-Based Speech Separation [J]. IEEE Transactions on Audio Speech & Language Processing,2013,21(7):1381-1390.
[7] WANG Y X,NARAYANAN A,WANG D L. On Training Targets for Supervised Speech Separation [J]. IEEE/ACM transactions on audio,speech,and language processing,2014,22(12):1849-1858.
[8] KANG T G,SHIN J W,KIM N S. DNN-based monaural speech enhancement with temporal and spectral variations equalization [J]. Digital Signal Processing,2018,74:102-110.
[9] NARAYANAN A,WANG D L. Ideal ratio mask estimation using deep neural networks for robust speech recognition [C]//IEEE International Conference on Acoustics. IEEE,2013:7092-7096.
[10] ROTHAUSER E H ,CHAPMAN W D ,GUTTMAN N,et al. IEEE Recommended Pratice for Speech Quality Measurements [J]. IEEE Transactions on Audio and Electroacoustics,1969,17(3):225-246.
作者简介:邵榕梓(1997—),女,汉族,山西太原人,本科,
研究方向:电子信息工程;富晓乾(1996—),男,汉族,山西天
镇人,本科,研究方向:电子信息工程;田爱生(1973—),男,
汉族,山西榆社人,本科,研究方向:语音信號处理;蒲俞姣(1998—),女,汉族,山西霍州人,本科,研究方向:通信工程;陈凯(1997—),男,汉族,山西晋中人,本科,研究方向:通信工程。
