面向函数型数据的动态互信息特征选择方法*
2019-01-17姜高霞王文剑
马 忱,姜高霞,王文剑
1.山西大学 计算机与信息技术学院,太原 030006
2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006
1 引言
现实中的数据集朝着大规模方向发展,并呈现指数型增长的趋势。这种增长不仅仅是数据量的增长,数据的呈现形式也越来越多样化,函数型数据[1](functional data,FD)正是一种常见的、数据信息量大的数据。它是指在某个连续集(通常指时间、心理空间或物理空间等)上的一组测量,例如按时间记录的经济数据,书写时笔尖的运动轨迹,某个时间段某个地区温度和湿度的变化,青春期人体身高,体重的变化,人体的心电图,语音框架数据等都是函数型数据。一般来说,函数型数据含有更多的数据特征,因此相较于传统离散数据具有较好的分类性能。然而函数型数据特征维数较高,这将导致参数估计的准确率下降,进而直接影响学习算法的性能和效率[2]。此外,与大量数据特征同时存在的还有一些冗余特征和不相关特征,这些特征的存在会影响分类器的性能和分类效果。不仅如此,大量的冗余特征和不相关特征还会显著增加计算的时间复杂度和内存需求,这些不足在数据特征数目较大时尤为突出。为了克服这一问题,特征选择往往是十分必要的。
特征选择的主要目标就是寻找机器学习算法性能优化的最小子集[3]。特征选择可以为机器学习算法带来很多好处[4],如降低测量成本和存储要求,应对由于训练样本集的有限性造成的分类性能下降的问题,降低训练时间,便于数据的可视化和理解。机器学习的不断进步也在推动着特征选择方法的发展,常见的特征选择方法分为3类[5]:封装式(wrapper)特征选择方法、嵌入式(embedded)特征选择方法和过滤器式(filter)特征选择方法。
相较于其他两种特征选择方法,过滤器式特征选择方法不仅能达到多数分类器的分类精度[6],而且计算复杂度较低。这种优势在处理大规模数据或在线数据等时表现明显。通常情况下,过滤器方法主要有相关性度量、距离度量、信息度量[7]和一致性度量[8]等。由于信息度量是借助信息理论中互信息的概念来量化特征间的不确定性程度,故不要求预先假定数据分布是已知的,可以解决变量间的非线性关系,从整体的角度来评估特征间的相关性,剔除无关特征,有效地选出关键特征[9],因此被广泛应用于滤波方法[10]。目前已经提出了许多基于熵作为特征选择模型[11-12]。Lewis[13]提出最基本的基于互信息的信息增益理论,在此基础上,Battiti[14]的互信息特征选择(mutual information for selecting features,MIFS)方法和Peng等人[15]的最大相关最小冗余(max-relevance and min-redundancy,mRMR)方法丰富了互信息理论。随着互信息理论的发展,产生有联合互信息理论[16-19]和条件互信息理论[20-21]指导的特征选择方法。
以上方法对传统数据是有效的,但是并不能很好地完成函数型数据的特征选择,将合适的特征选择方法用于函数型数据分析是简化计算和提高数据可分性判据的有效手段,如Gómez-Verdejo等人[22]在Kraskov等人[23]的互信息理论基础上提出一种改进的条件互信息特征选择方法,可以不受概率分布和数据形式的影响,更好地适合于函数型数据的分类问题。然而在特征选择过程中需要用搜索策略和评价函数来共同完成,这就导致了以下两方面问题:一是搜索过程的随机性导致每次特征选择结果的不确定性,使该方法不稳定;二是每次迭代结束后可识别样本对再次计算评价函数的影响,造成特征子集分类精度的降低。因此本文针对这两个问题,提出了关于函数型数据的动态互信息特征选择方法。此外,在动态互信息特征选择方法的基础上,考虑已选特征对待选特征影响,提出一种动态条件互信息特征选择方法。在UCR数据集上的实验结果表明方法的有效性。
2 动态互信息特征选择方法
在特征选择中,最优特征子集是一个与类高度相关,但不互相关联的特征集合,信息论的方法在量化的特征不确定程度度量上有很大的优势。传统的信息论特征选择方法属于过滤器特征选择方法,即选定某一评价函数来对特征进行评价。这一过程往往伴随着特征的遍历过程选择不同的遍历方法可能得到不同的特征子集,使特征选择的结果不具有稳定性,且在每次搜索过程中往往会出现信息的冗余,因而本文提出的动态选择过程避免了信息冗余的出现,分类器的分类结果直接判定每次迭代过程,可以提高特征选择过程的时间效率和特征选择结果的分类精度。
本文所指动态的过程是每个特征所带来的信息对学习器分类的影响,每次缩小样本集,将可以识别的样本去除,不仅避免了可识别样本的信息冗余,同时在样本量高的数据集中可以明显缩短特征选择的时间。
2.1 函数型数据特征矩阵
为保证函数型数据信息的完整性,本文将得到的数据采用以下两种方法进行处理。将采集到的离散数据,先经过B-样条基拟合,转换为函数型数据,再将离散数据采用五阶多项式拟合,通过统计拟合后的各点对应的函数特性,得到函数型数据的特征矩阵。具体过程如下:
(1)将一个序列数为m的函数型数据表示为FD:

(2)在每个数据上取n个采样点,用采样点处的一阶导数、与坐标轴所围成的面积、五阶多项式系数、波动范围和基本统计学信息表示每个样本的特征向量Ai:
其中,fi′(xj)表示fi(x)在xj(j=1,2,…,n)处的一阶导数;S表示与坐标轴围成的面积;C5,C4,…,C0表示五阶多项式系数;μ、σ、κ、β分别表示均值、标准差、峰度和偏度。
(3)得到的函数数据特征矩阵E为:
2.2 动态互信息特征选择
熵(entropy)表达的是某个系统的混乱程度,系统越混乱,其熵值就越高;反之,系统越有序,则其对应的熵值也就越低。信息理论中,熵通常也称作信息熵或Shannon熵。它主要采用数值形式表达随机变量取值的不确定性程度,目的是刻画信息含量的多少。假定X、Y、Z是3个随机变量,X={x1,x2,…,xL},Y={y1,y2,…,yM},Z={z1,z2,…,zN},p(∙)表示变量取值的概率,则X的不确定程度表示为它的信息熵:

条件熵定义为在已知一个变量的条件下,另外一个变量的不确定性程度:

互信息(mutual information)是为了衡量两个变量间相互依赖强弱程度而引入的,它表示两个变量间共同拥有信息的含量。将两个变量之间的互信息定义为:
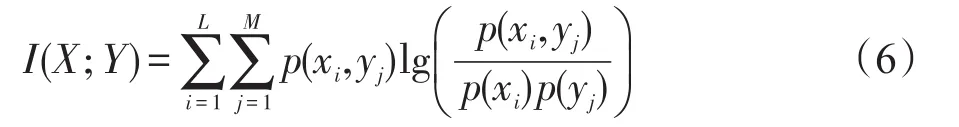
条件互信息是指给定某个随机变量的条件下,其他两个变量之间的相互依赖程度。也就是说,它是表达在已知某种情况发生的情况下,其余事物之间的相互关联程度,即当随机变量Z已知时,变量X和Y关于Z的条件互信息为:

特征选择的目的是尽可能地选择保留原始特征信息的特征子集。基于信息论的特征选择方法分为特征冗余项和特征关联项两部分。无论是线性方法还是非线性方法,通常的标准是最小化特征冗余,同时最大化特征相关度。在基于信息理论的特征选择中,通常选择某一信息量的值作为特征选择的评价函数,通过某一搜索策略进行特征过滤,从而从特征集合中选出当前方法所认为的最优特征子集。
以基本互信息理论为评价函数,计算函数特征矩阵E中的每个特征Ai与类标签Y的互信息:
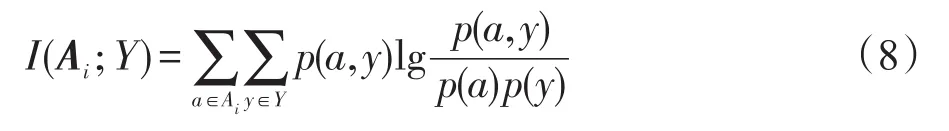
其中,p(∙)为概率值。将得到的每个特征的互信息值进行重新排序,按照值的大小降序排列得到排序的特征矩阵M,这意味着在后续特征选择过程中,互信息值大的特征将被优先考虑加入特征子集中。
从学习算法的角度对数据进行分析,可将样本分为已识别样本和未识别样本两类。将已排序的特征依次加入特征子集,每加入一个新的特征,则重新使用分类器学习并分类,将可以识别的样本从样本集合中去除,达到相应的停止条件则输出最终的特征子集。本文所用的停止条件为:所有的样本都能被正确识别或特征子集的个数已达到用户定义的最大值δ。这意味着当样本集中所有样本都能被已选的特征子集所识别,特征选择过程将结束;或达到了特征子集所能容纳特征的最大数目时,仍有部分样本未能识别,但已超出了用户定义的最大分类特征数,则忽略未能识别的样本,输出当前特征子集;其他情况出现时,则继续执行特征选择过程。通常情况下,函数型数据的特征子集的特征个数不超过10个,因此本文在后续实验中设置特征子集中特征个数最大值δ为10。DMI(dynamic mutual information)算法的主要步骤总结如下。
算法1DMI算法
输入:序列数为m的函数型数据FD。
输出:最优特征子集E′。
(1)将函数型数据按照式(2)和式(3)求得函数型数据的特征矩阵E,初始化空的最优特征子集E′。
(2)计算每个特征与类别之间的互信息,并将特征按照互信息值的大小降序排列,得到排序特征矩阵M。
(3)将特征矩阵M中每一个特征按顺序加入特征子集E′,每次循环过程在LIBSVM分类器中进行学习和分类,每次将可以正确分类的样本去掉,如果所有样本都被正确分类或达到用户定义的特征最大数阈值δ,输出当前特征子集E′。
2.3 动态条件互信息特征选择
考虑到在特征选择过程中已经选入特征子集中的特征对未选入特征子集的特征会有一定的影响,将特征选择过程中特征集合的变化分为两类:已选特征集和待选特征集。初始状态时,待选特征子集为所有特征的集合,已选特征子集为空集。随着特征选择过程的进行,在考察每个待选特征时,都考虑每个已选特征对它的影响。因此,本文用J(∙)表示评价函数,用Aj表示已选特征,Ak表示待选特征,Y表示类标签,则已选特征对待选特征的影响表示为它们之间的条件互信息,即:

通过计算每个已选特征对当前待选特征的量化影响值,选出其中的最大值Jmax,将当前最大值Jmax与初始最大值Imax进行比较,如果Jmax>Imax,则说明待选特征在已选特征的影响下,依然带来了较多的信息量,因此将当前待选特征Ak加入已选特征子集,并将Imax的值更新为Jmax;反之,如果Jmax≤Imax,则说明在已选特征的影响下,待选特征不能提供更多的信息量,则认为当前待选特征是冗余的或不能带来新的信息量的,故不将当前特征加入到已选特征子集中。每次特征子集发生变化后,都将当前的特征子集在分类器中重新进行学习和分类,将可以正确分类的样本从样本集合中去除,直到所有的样本都被正确识别或达到用户定义的特征子集的最大个数δ,则停止特征选择过程。DCMI(dynamic conditional mutual information)算法的主要步骤总结如下。
算法2DCMI算法
输入:序列数为m的函数型数据FD。
输出:最优特征子集E′。
(1)将函数型数据按照式(2)和式(3)求得函数型数据的特征矩阵E,初始化空的最优特征子集E′,最大条件互信息值为0。
(2)计算每个特征与类别之间的互信息,并将特征按照互信息值的大小降序排列,得到排序特征矩阵M。
(3)将排序特征矩阵M中前两个特征X1和X2加入已选特征子集E′,将J=I(X2;Y|X1)置为最大值Jmax。
(4)依次向特征子集E′中加入候选特征子集中的特征,并计算J(∙)值,如果所有样本都被正确分类或达到用户定义的特征最大数阈值δ,输出当前特征子集E′。
(5)如果当前J(∙)小于或等于Jmax,则将当前特征从E′中丢弃;如果当前J(∙)大于Jmax,则更新Jmax为当前J(∙)值,使用LIBSVM分类器进行学习和分类,将可以正确分类的样本去掉,返回步骤4。
2.4 时间复杂度分析
对于m×n维函数型数据特征矩阵,m为样本个数,n为特征数,k为特征选择迭代次数,k的最大值为n。
在互信息估值阶段,计算的时间复杂度为O(n2),在迭代计算过程中,时间复杂度为O(kmn)或O(k2mn)。在实际计算过程中,时间复杂度和其他基于互信息理论的特征选择方法相同,需花费较多的时间。
3 实验结果与分析
3.1 实验数据与实验设计
实验数据采集自UCR时序分类数据集(http://www.cs.ucr.edu/~eamonn/time_series_data/),其中二分类数据13组(序号为1~13),多分类数据10组(序号为14~23),由于采集到的数据为离散数据,因此首先将数据经过B样条基拟合,转换为函数型数据,再计算出函数型数据的特征矩阵。实验数据详见表1。数据的平滑、拟合以及实验部分均在Matlab环境下实现,所用计算机环境为Intel®CoreTM2 Duo CPU,2.93 GHz和2.94 GHz,内存8 GB,64位操作系统。
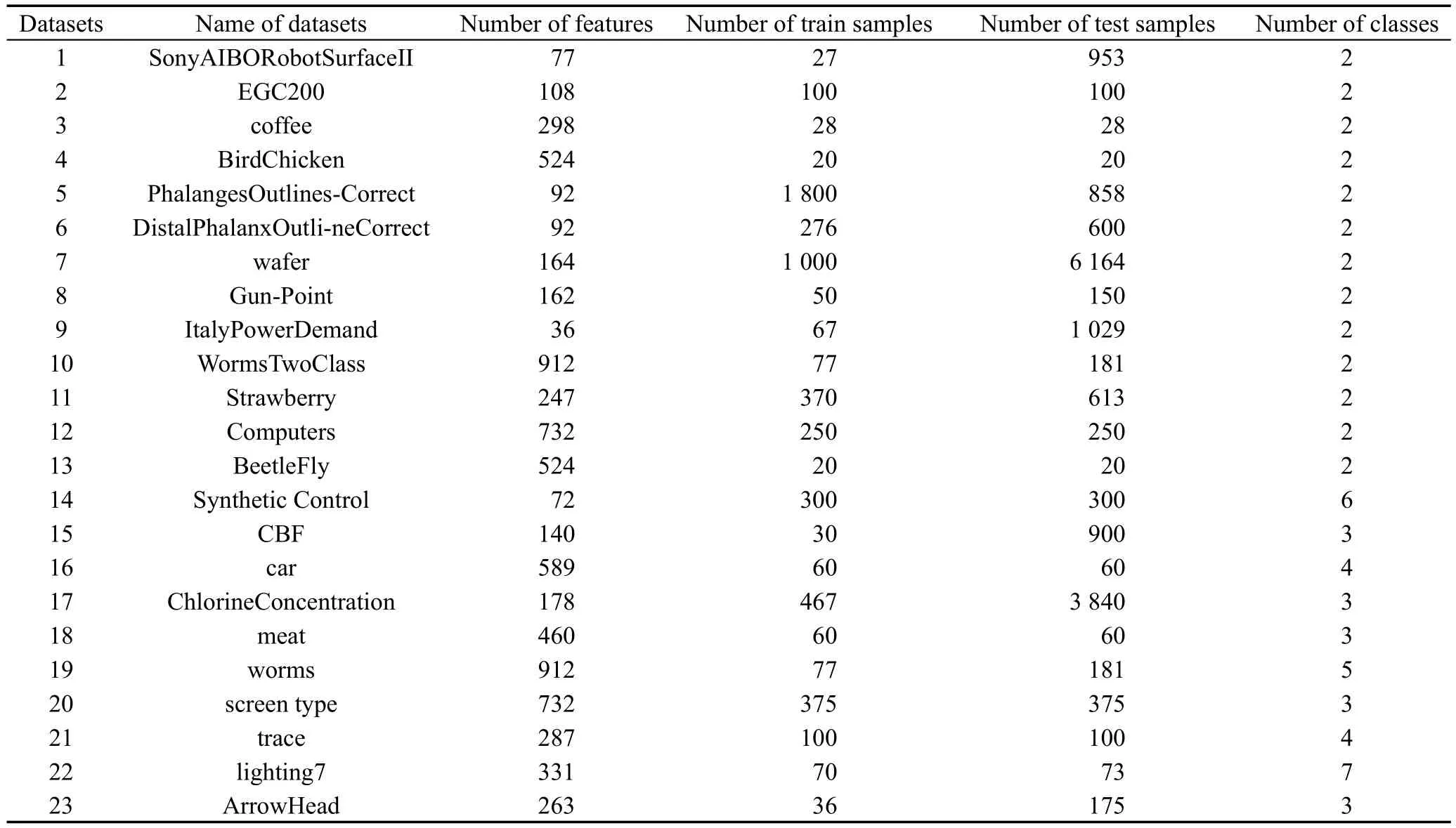
Table 1 Experimental datasets表1 实验数据集
将本文提出的DMI方法和DCMI方法与基于函数型数据的条件互信息CMI(conditional mutual information)[17]特征选择方法、最大相关最小冗余(mRMR)[15]方法和最大条件互信息方法(conditional mutual information maximize,CMIM)[20]进行所选特征子集规模和分类精度的对比,并将上述结果与不进行特征选择而直接进行分类(空白对照FD)的结果进行了比较。此外,文献[24]提出了一种面向函数型数据的快速特征选择方法,本文与此方法也进行了对比,说明本文方法的有效性。
3.2 实验结果及分析
(1)特征子集规模的比较
因为mRMR方法和CMIM方法得到的是特征集合的排序,并未给出确定的特征数目,所以本文只比较了DMI方法和DCMI方法与CMI方法最优特征子集之间的特征规模差异。
每种方法选出的最优特征子集数目如表2和表3所示。表中加粗项为当前数据中所选特征子集数目最小值。从表中可看出,在二分类问题和多分类问题中,3种方法的所选特征子集的特征数目都远小于函数型数据的原始特征集合。在大多数数据集上,特征比例不足10%,只有少数数据集特征比例高于10%,但这种情况出现时原始特征数据也较少(不足100)。在二分类问题中,CMI方法所选特征子集规模最小的情况只出现在一个数据集中,有两个数据集的特征子集规模与DCMI方法相同且达到最小;在多分类问题中,各数据集的最小规模特征子集均出现在DMI方法或DCMI方法中,且在部分数据集上远小于CMI方法。由此可见,DMI方法和DCMI方法的特征子集规模是较小的,在后期的分类计算中具有一定的优势。
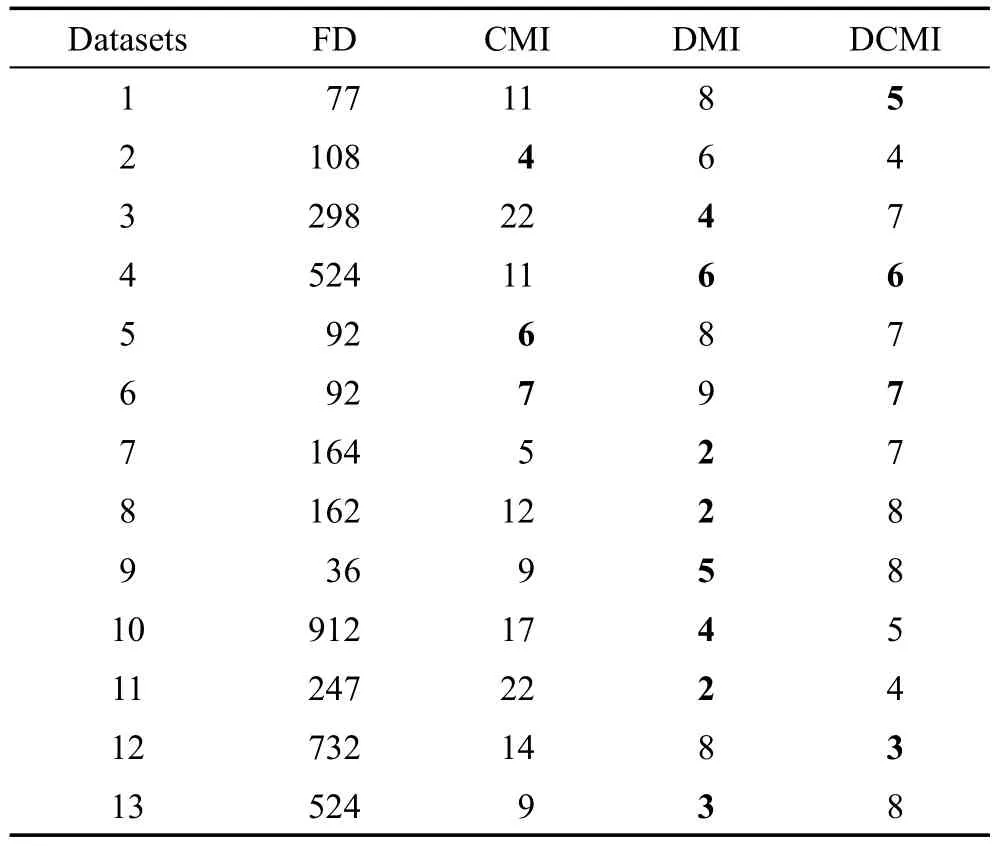
Table 2 Feature number of each method in binary classification表2 二分类特征选择特征数目
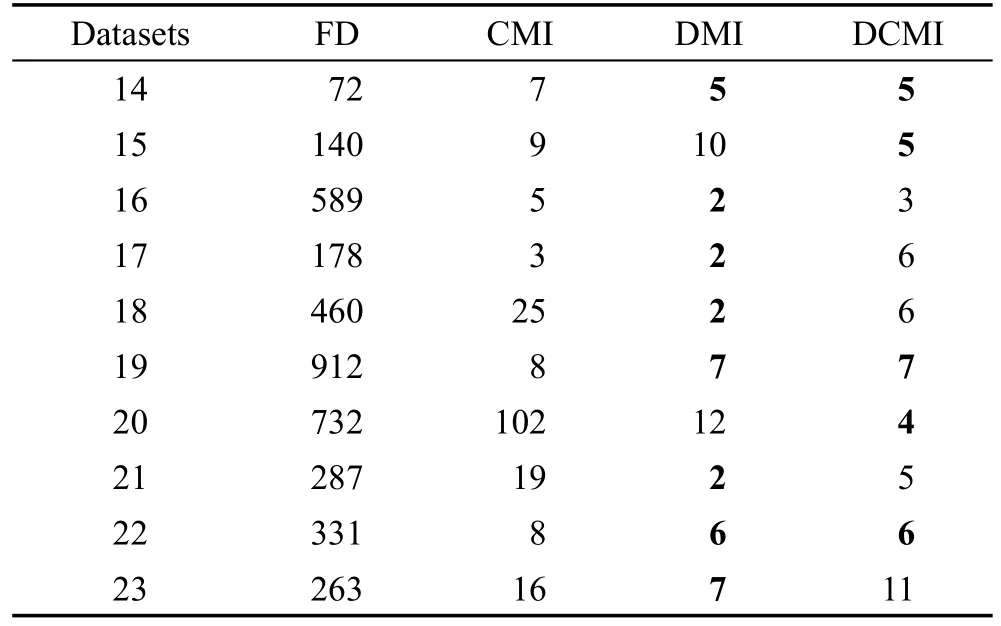
Table 3 Feature number of each method in multi-class classification表3 多分类特征选择特征数目
为了更好地比较特征选择过程所选特征的数目,计算出所选特征数目占总特征的比例,如图1和图2所示。从图中可看出,在二分类问题中,CMI方法所选特征的比例在9组数据上都高于DMI方法和DCMI方法,说明在二分类问题中,DMI方法和DCMI方法都能获得较小的特征子集,对于数据的简化效果明显;DCMI方法在5组数据上特征比例低于DMI方法,说明在二分类问题中DMI方法和DCMI方法在所选特征子集规模方面效果相近。在多分类问题中,CMI方法所选特征的比例在8组数据上都高于DMI方法和DCMI方法,且CMI方法特征数目比DMI方法和DCMI方法多出的特征数目远大于CMI方法比DMI方法和DCMI方法少的情况,同样说明DMI方法和DCMI方法可以获得较小的特征子集即可完成相应的分类问题;DMI方法和DCMI方法选择的特征比例相近,所选特征个数相同的有3组数据,且特征子集规模最大相差为8个特征,说明这两种方法在特征子集的规模上效果相近。

Fig.1 Feature ratio of each method in binary classification图1 二分类各方法特征比例

Fig.2 Feature ratio of each method in multi-class classification图2 多分类各方法特征比例
特征个数和特征比例的平均值如表4所示。从表中可看出CMI方法的特征个数和特征比例都明显大于DMI方法和DCMI方法,故从整体上看,本文提出的方法得到的特征子集规模小于CMI方法。

Table 4 Average of feature number and feature ratio表4 特征个数和特征比例平均值
(2)分类效果的比较
将DMI方法和DCMI方法与3种对比方法CMI、mRMR和CMIM进行分类精度的比较。其中,DMI、DCMI和CMI的最优特征子集与表2和表3相同,参照DMI方法和DCMI方法得到的特征子集规模,将对比方法mRMR方法和CMIM方法的特征子集数目设为10,既保证了这两种方法的分类精度较高,同时保证了参与对比的各方法特征子集规模相近,最大程度上保证了对比的公平性。
每种方法在各个数据集上的分类精度如表5和表6所示。表中详细记录了二分类问题和多分类问题在4种不同情况下进行特征选择的结果所对应的特征子集分类精度,以及各方法在不同数据上的精度平均值。从表中可看出DMI和DCMI方法的精度明显好于其他方法,且在精度的平均值方面得到印证。此外,DCMI方法的分类精度效果也优于DMI方法。在二分类问题中,除个别数据集(数据集6)外,DMI方法具有较好的分类效果,说明DMI方法在一定程度上克服了传统互信息特征选择方法的不足,在特征子集的分类精度上有了一定的提高;DCMI方法在大多数数据集上的分类精度较好,在表现不是最好的数据集上,与分类精度最高的方法差别较小,如数据集4、9和13。在多分类问题中,有7组数据在使用DMI方法和DCMI方法时,分类效果明显好于其他方法,且提高明显,说明DMI方法和DCMI方法在多分类问题中有较高的特征选择效果,较高的分类精度;DCMI方法的分类精度在5个数据集上好于DMI方法,说明这两种方法在分类精度上的差别并不明显,但相较于DMI方法分类精度好于DCMI方法的情况,DCMI方法好于DMI方法时,精度差别更为明显,反映出DCMI方法在多数情况下,能保持较高的分类精度。
为了更好地描述每种方法在各个数据集上的分类精度,弱化不同数据集之间分类精度的差异,将每种方法在对应数据集上的分类效果进行排序,每种方法对应排名的频次统计见表7和表8,表中的列表示方法,行表示方法排名,内容为当前方法对应名次的频次。如果两种方法的分类精度相同,本文采取的方法是并列排名。从表中可看出,在二分类问题中,DCMI方法排名第一的频率最高,且没有排名最低的情况,说明DCMI方法在二分类问题的特征选择分类精度优势明显,有较好的分类效果,DMI方法次之。在多分类问题中,DMI方法和DCMI方法的分类精度排名都排在前两位,DCMI方法略好于DMI方法,说明DMI方法和DCMI方法好于其他方法,且效果稳定。
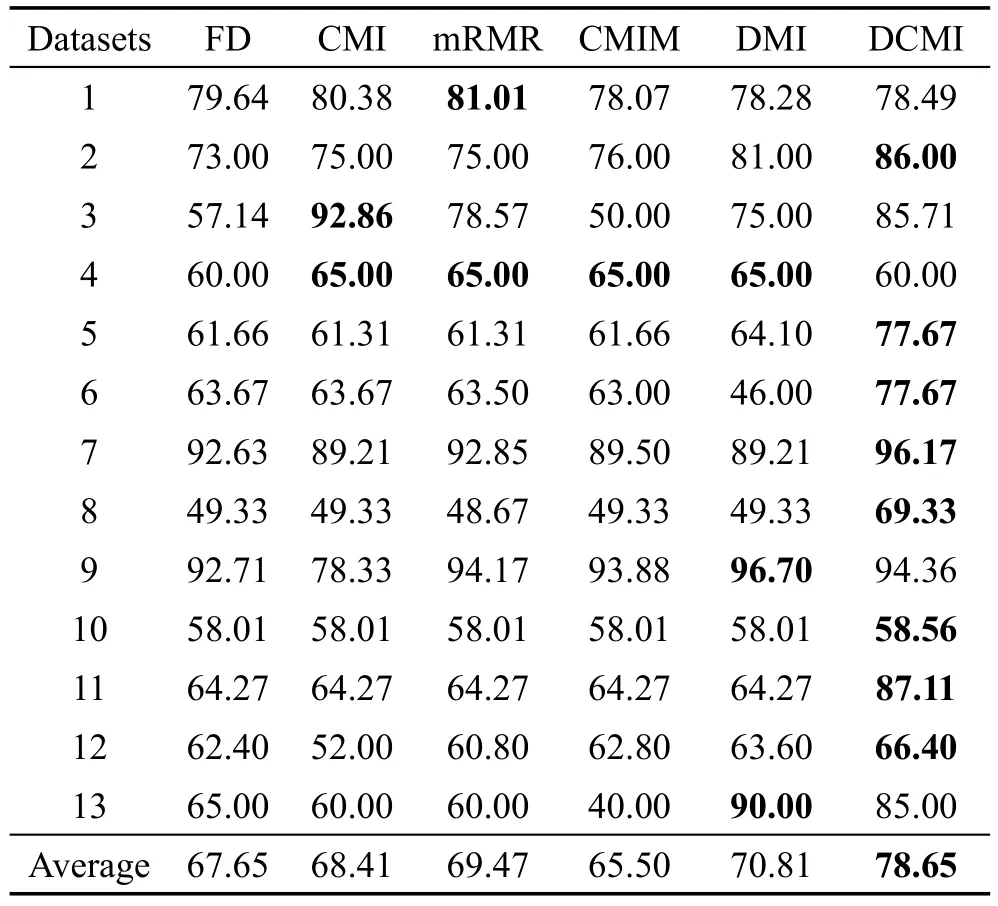
Table 5 Accuracy of each method in binary classification表5 二分类问题各方法精度 %
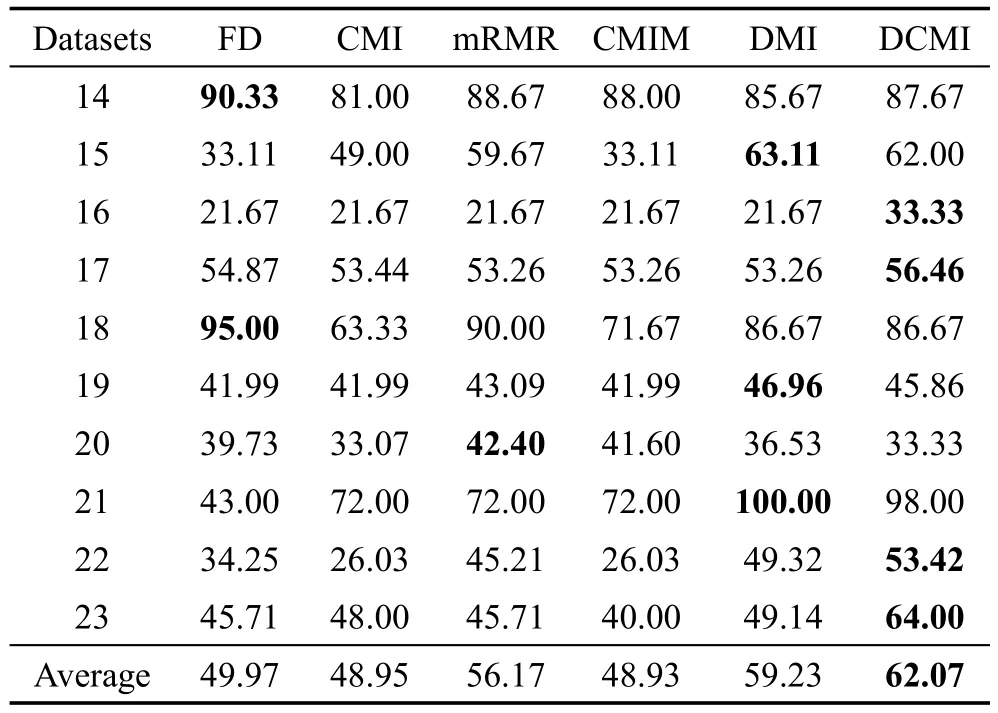
Table 6 Accuracy of each method in multi-class classification表6 多分类问题各方法精度 %
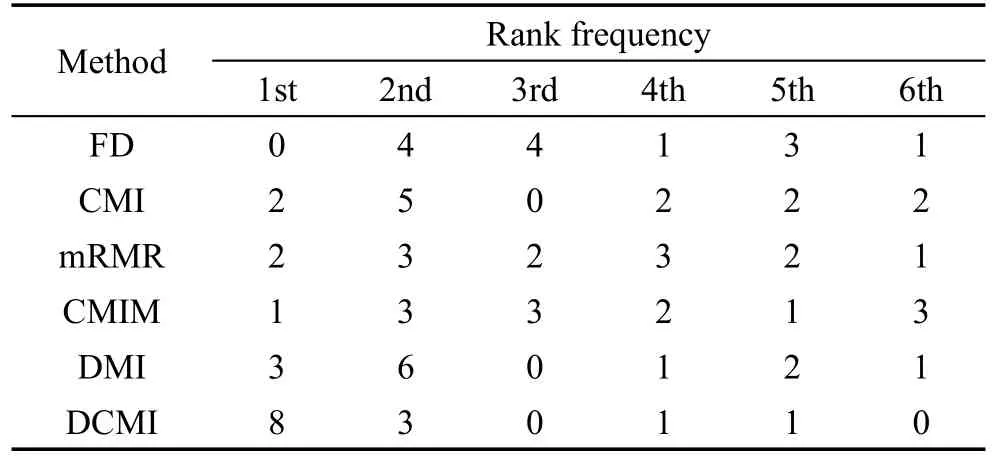
Table 7 Rank frequency of each method in binary classification表7 二分类各方法排名频数
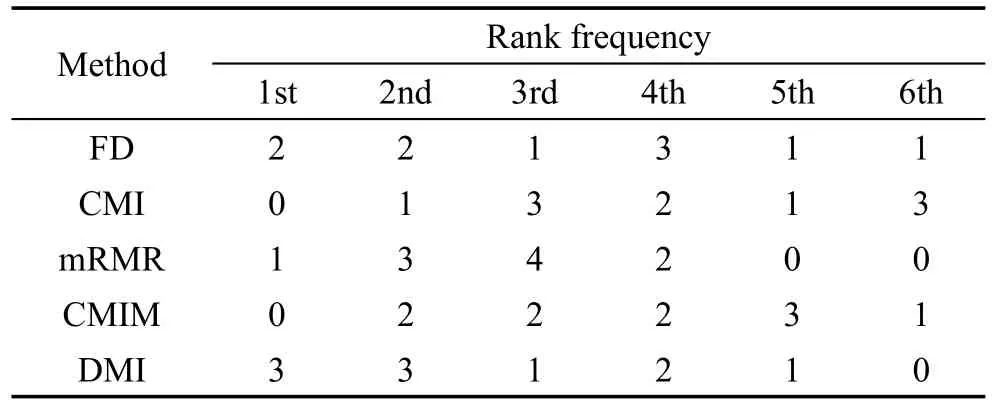
Table 8 Rank frequency of each method in multi-class classification表8 多分类各方法排名频数
(3)与文献[24]中方法的比较
将DMI和DCMI方法与文献[24]中的FFS(fast feature selection)方法进行比较。分别选取FFS方法中二分类和多分类问题排名前五的方法与本文方法进行了特征子集规模、分类精度的比较,以及选取FFS方法中不同维数凸包的特征选择时间与本文方法进行了比较。
将DMI、DCMI方法的所选特征比例与FFS方法在二分类和多分类问题精度排名前五方法进行比较,结果如图3和图4所示。在二分类问题中,FFSF-3和FFS-3方法、FFSF-5和FFS-5方法的特征比例相同,为使数据展示更加清晰,故采用相同的线型;在多分类问题中,FFS-2和FFSF-2方法亦采用这种处理方式。在二分类问题和多分类问题中,DMI方法和DCMI方法的所选特征比例介于二维凸包和三维凸包的FFS方法之间,这三者特征比例差别较小,且选择的特征子集规模较小。由此可见,DMI方法和DCMI方法的所选特征比例与FFS方法中凸包维数较小的方法相近。从图中可明显看出,随着凸包维数的增加,FFS方法的所选特征比例会逐渐增加,且增加的幅度较大,而DMI方法和DCMI方法则不会出现该类问题,这两种方法能够保持较小的特征子集规模。
为清楚地表示二分类问题和多分类问题中FFS各方法和DMI方法、DCMI方法特征选择结果之间的分类精度差异,将比较结果描述为箱线图,如图5和图6所示。图中符号“+”表示当前方法在不同数据上的平均分类精度,箱中横线表示中值,线端表示当前方法的最值,箱端表示上、下四分位数。从图中可看出,在二分类问题中,各方法在不同数据集上所能达到的最大分类精度相差较小,DMI方法和DCMI方法的平均分类精度均好于FFS方法,且DCMI方法优势明显,具体表现为:(1)均值和中值均优于其他方法,说明DCMI方法在多数数据集上的分类精度较好,且不受异常值影响;(2)在分类精度最差的数据集上表现明显优于其他方法。在多分类问题中,DMI方法和DCMI方法的平均分类精度略逊色于FFS方法中效果最好的方法,但这个差距并不明显;DMI方法的表现不稳定,受数据集的影响较大;DCMI方法可达到与其他方法相近的精度,且中值大于其他方法,说明在多数数据上有较好的分类结果。由此说明,本文提出的方法在二分类数据的特征选择问题中有较明显的优势。
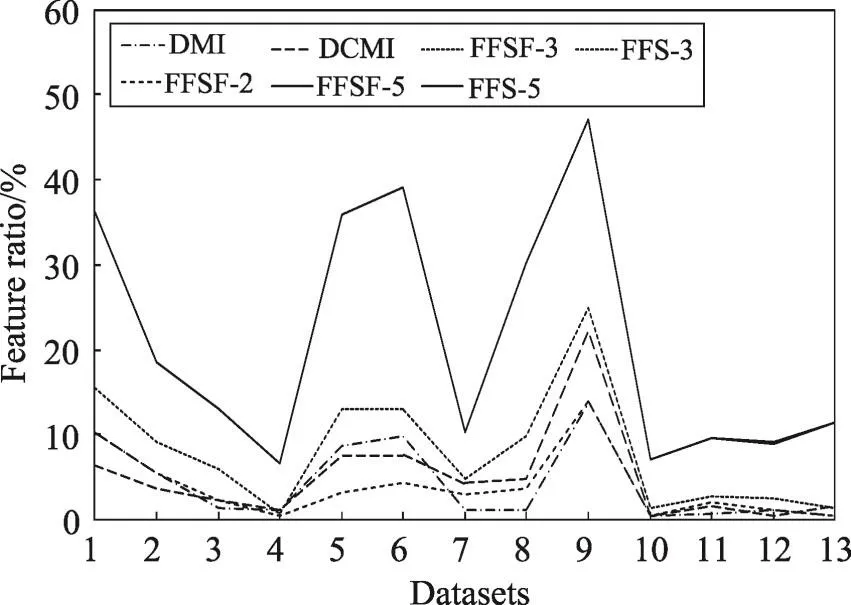
Fig.3 Feature ratio of FFS&DMI in binary classification图3 FFS和DMI方法二分类方法特征比例

Fig.4 Feature ratio of FFS&DMI in multi-class classification图4 FFS和DMI方法多分类方法特征比例

Fig.5 Accuracy of FFS&DMI in binary classification图5 FFS和DMI方法二分类问题分类精度比较

Fig.6 Accuracy of FFS&DMI in multi-class classification图6 FFS和DMI方法多分类问题分类精度比较
FFS方法的优势就是特征选择的时间较短,因此本文也比较了在特征选择时间上二者的差异。由于在二分类问题和多分类问题中该特性有相似的表现,故本文只比较了二分类问题中FFS方法在2、3、5、8维凸包上的特征选择时间与DMI、DCMI方法的特征选择时间,如图7所示。因时间差别较大,故图中采用以10为底数的对数坐标轴。从图中明显看出,FFS方法在各维数的凸包中的特征选择时间均明显少于DMI方法和DCMI方法。

Fig.7 Time cost of FFS&DMI in binary classification图7 FFS和DMI方法二分类方法特征选择时间
综上所述,DMI方法和DCMI方法能达到较好分类精度,且能选择更少的特征个数,这在后期简化分类器计算中有较大的应用价值。然而这两种方法也存在现有互信息方法共有的缺点,即特征选择过程中时间代价较大。因此,这也是本文今后需改进的方向。
4 总结
综合考虑特征选择过程中特征组合变化对样本的影响,本文提出了一种动态互信息特征选择方法,将该方法与分类器结合,最终给出特征选择的特征子集和特征子集对应的特征分类精度。此外,考虑到特征选择过程中已选特征对待选特征的影响,本文提出了动态条件互信息特征选择方法,优先考虑待选特征是否在已选特征的影响下,为数据带来了新的数据信息。实验结果表明,这两种方法明显好于已有的互信息特征选择方法,且DCMI方法在特征子集的分类精度和特征子集的规模上较好于DMI方法。
因互信息特征选择方法在特征选择中会花费较多的时间代价,故优化算法以提高特征选择效率将是未来工作的重要内容。
