基于丰度约束核非负矩阵分解的高光谱图像非线性解混
2018-09-12智通祥
智通祥,杨 斌,王 斌
(1.复旦大学 电磁波信息科学教育部重点实验室,上海 200433;2.复旦大学 信息科学与工程学院 智慧网络与系统研究中心,上海 200433)
高光谱遥感图像可以获得目标地区的空间分布和详细的光谱信息,其光谱波段多达数百个,在环境监测、地质勘探、军事侦察等方面有广泛的应用[1].但由于传感器空间分辨率的限制,以及地物成分的复杂性,高光谱图像中存在着大量的混合像元,严重影响了定量遥感的发展.为解决这一问题,就需要进行光谱解混,从光谱图像中提取出组成混合像元的纯物质光谱(即端元)和它们在混合像元中所占的比例(即丰度)[2].
在以往的高光谱解混研究中,常采用线性混合模型(Linear Mixing Model, LMM)来描述混合像元现象.这里,假设地物呈棋盘格网状分布,并且光子只与场景中的一种物质发生作用,这样混合像元光谱就可以由端元光谱以不同的比例系数线性组合而成.由于LMM模型简单,物理意义明确,近十年来,基于LMM的线性解混算法一直是国内外学者研究的重点,并日趋成熟[3].但是在许多复杂的自然场景中存在着非线性混合效应,如沙地、矿物地区的紧密混合现象,以及植被覆盖、建筑林立地区的多层次混合现象.基于LMM的线性解混算法在这些非线性混合区域的解混结果会与实际情况存在较大误差.因此,为了更准确地进行高光谱解混,非线性解混算法逐渐受到了学者的关注,多种非线性解混算法被提出,并用于非线性混合场景下的高光谱解混[4-5].
其中,针对沙地、矿物地区存在的紧密混合现象,Hapke模型[6]从辐射传输理论出发,推导出双向反射率可以表示为与场景相关的粒子密度和大小以及单次散射反照率等物理参数的非线性函数,从而描述紧密混合情况下光线在微观尺度上与不同粒子之间的多次散射情况.而植被覆盖、建筑林立的地区则存在多层次混合现象.双线性混合模型(Bilinear Mixing Model, BMM)在LMM的基础上,考虑两两端元间存在的二次散射效应并忽略更高次散射的影响,可以较为简化地描述这种多层次混合现象.BMM主要由线性混合和非线性混合两部分构成,根据后者的不同可分为Nasimento模型(Nasimento Model, NM)[7],Fan模型(Fan Model, FM)[8],广义双线性模型(Generalized Bilinear Model, GBM)[9],多项式后验非线性模型(Polynomial Post-nonlinear Model, PPNM)[10]等.其中,由于GBM概括性强,且模型相对简单,常作为BMM的代表用于非线性解混算法的研究.因此,本文重点关注Hapke模型和GBM这两种不同的非线性混合模型的高光谱解混问题.
对于GBM,传统的线性端元提取算法如顶点成分分析(Vertex Component Analysis, VCA)[11]可以用来提取端元.但是在非线性混合场景下,线性端元提取算法提取端元的不准确性会对非线性解混结果有比较大的影响.而对于Hapke模型,则无法利用线性端元提取算法提取端元.非负矩阵分解(Nonnegative Matrix Factorization, NMF)[12-13]在无监督的高光谱线性解混中得到了广泛应用,它可以在端元未知的情况下,同时对端元和丰度进行计算和求解.在非线性混合情况下,基于核函数的核非负矩阵分解(Kernel NMF, KNMF)[14]不仅可以无监督地非线性解混高光谱数据,而且不需要知道具体的非线性表达形式,这样就避免了Hapke模型和GBM中参数选择的问题,可以适用于不同的非线性混合模型.目前基于核非负矩阵分解的高光谱非线性解混算法,主要包括: 不含纯像元的核非负矩阵分解(non-pure-pixels KNMF, npKNMF)[15],约束的核非负矩阵分解(Constrained KNMF, CKNMF)[16],双目标非负矩阵分解(Bi-objective NMF)[17]等.npKNMF直接利用核非负矩阵分解进行高光谱非线性解混,并没有考虑到实际地物的空间分布特性,容易陷入到局部极小.CKNMF在npKNMF的基础上添加了端元最小体积约束和丰度平滑约束,但是,端元最小体积的特性在高维特征空间中是否成立,是值得怀疑的.并且,它使用了丰度的2范数来实现丰度的平滑约束,这并不能反映丰度的局部平滑特性.Bi-objective NMF同时考虑原始空间和高维特征空间,但是二者所占的权重不确定,且没有添加约束,也容易陷入局部极小.
为了解决上述非线性解混算法中存在的问题,本文提出一种基于丰度约束核非负矩阵分解的非线性光谱解混算法(Abundance Sparseness and Smoothness Constrained KNMF, ASSKNMF).该算法主要由核非负矩阵分解和丰度约束两部分组成.首先,利用核非负矩阵分解将原始数据映射到高维空间进行无监督的高光谱解混.在无监督解混的基础上,依据地物分布的空间特性,对丰度添加稀疏约束和局部平滑约束,使陷入局部极小的概率变小.实验结果表明,所提出的算法可以提高Hapke模型和GBM这两种非线性混合模型的解混精度.
1 问题描述
对于高光谱数据X=[x1,x2,…,xN]∈L×N,其每列xj∈L×1(j=1,2,…,N)都对应一个具有L个波段的像元向量,共有N个这样的像元.以A=[a1,a2,…,aP]∈L×P表示端元矩阵(P是端元数),sij是端元ai在像元xj中的丰度,ej是噪声误差.LMM假设下的像元向量是端元光谱的线性组合,考虑到实际的物理意义,丰度需满足非负与“和为一”的约束条件[2]:
(1)
1.1 Hapke混合模型
在沙地、矿物紧密混合地区的遥感图像数据中,依据辐射传输理论[6],在粒子为球形且各向散射同性,表面反照比低的假设下,地物介质表面双向反射率r可以简化地表示为:
(2)
其中:μ0,μ分别是光线入射角和出射角的余弦值;ω是单次散射反照率;H是多项散射函数,表达式是:
(3)
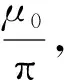
(4)
根据式(4),可以在已知反射率x的情况下推导出单次散射反照率ω,R-1表示反函数:
(5)
根据Hapke模型,将像元的反射率x非线性映射到单次反照率ω后,可以用端元单次反照率的线性组合来表示:
(6)
其中:ωi是端元的单次散射反照率;sij是对应的丰度系数.端元在单次反照率按丰度系数线性组合后,经过非线性映射变为高光谱数据中的反射率.
1.2 GBM混合模型
针对植被覆盖、建筑林立地区的非线性混和现象,GBM在LMM的基础上考虑了两两端元间的二次散射项作为非线性效应,它的表达式如下:
(7)
其中:ai·ak=[i,1ak,1,ai,2ak,2,…,ai,Lak,L]T是端元之间的Hadamard乘积,用来描述光线在两种端元物质间发生的二次散射;参数γi,k,j用于控制非线性程度,使得GBM可以更加灵活的描述非线性混合效应.
1.3 非负矩阵分解
非负矩阵分解在模式识别和机器学习等方面取得了广泛的应用[12],它可以从给定的非负矩阵中分解出两个非负矩阵,使得两个非负矩阵的乘积与给定矩阵尽量保持一致.沿用高光谱数据的表示符号,非负矩阵分解将矩阵X∈L×N分解为A∈L×P和S∈P×N,P是矩阵A和S的秩,它的目标函数是基于欧式距离构造的:
(8)
通过最小化该目标函数,可以求得矩阵A和S.Lee和Seung提出了一种迭乘算法来对A和S进行求解[18]:
A←A.*(XST)./(ASS),
(9)
S←S.*(ATX)./(ATAS).
(10)
其中: 矩阵A是端元矩阵,每列对应于一个端元光谱;矩阵S是丰度矩阵,每列对应于一个像元的丰度;.*和./分别对应于矩阵的点乘和点除.
2 方法描述
本文利用丰度约束的核非负矩阵分解进行无监督的高光谱非线性解混.首先,利用核方法将原始高光谱数据映射到高维特征空间,在高维空间中用非负矩阵分解进行线性解混,同时根据实际地物的分布特性,在丰度上添加稀疏和平滑约束,更好地改善解混效果.
2.1 核方法
考虑非线性映射:
φ:x∈L→φ(x)∈CM.
(11)
将原始的高光谱数据映射到高维空间中,使得数据在高维空间中变得线性可分.但通常情况下,非线性映射φ是很复杂和难以求得的,可以通过核函数的方法来避免这个问题[19].两个向量在高维空间中的内积可以用核函数的形式表示:
k(x,z)=〈φ(x),φ(z)〉x,z∈L.
(12)
根据式(12)可以定义核矩阵,对于一个向量集{x1,x2,…,xl},核矩阵K定义为一个l×l的矩阵,它的矩阵元素为Kij=〈φ(xi),φ(xj)〉=k(xi,xj),是一个对称矩阵.一般情况下,满足Mercer定理或正定性的函数可以作为核函数,本文采用RBF函数[20]:
(13)
其中σ是核参数.
2.2 核非负矩阵分解
针对本文前面所提及的Hapke模型和GBM两种不同的非线性混合模型,使用核非负矩阵分解将原始高光谱数据映射到高维空间,再利用非负矩阵分解进行无监督解混,而不需要考虑具体的非线性表达形式.核非负矩阵分解的表达形式是:
(14)
其中:Xφ=[(x1),φ(x2),…,φ(xN)];Aφ=[(a1),φ(a2),…,φ(aP)].通过非线性映射分别将像元和端元映射到特征空间,而丰度矩阵S反应真实地物分布,保持不变.根据式(12)和核矩阵的定义,式(14)可以表示为:
(15)
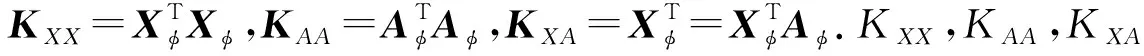
2.3 丰度约束
除了利用核非负矩阵分解处理非线性混合效应外,还应该考虑实际情况中地物的空间分布特性,如其所具有的稀疏特性和平滑特性,通过添加适当的约束使陷入局部极小的概率变小.在实际的高光谱图像中,单个像元xj一般情况下只由所有端元中的几个端元混合而成,体现在丰度向量上就是sj只有少数元素不为0,这就具有稀疏的性质.钱沄涛等人提出的1/2范数约束[21]可以很好地表达这一性质,它的表达式是:
(16)
表示丰度矩阵中每个元素的平方根的和.除了稀疏性质之外,丰度还具有局部平滑的性质,是因为在真实的场景中,局部区域内地物的分布具有连续性,体现在丰度上就是具有一定的空间平滑性,在文献[22]中,通过最小化像素和其邻域像素丰度的差值来体现局部平滑性.其表达式如下:
(17)
其中:Spk是第p个端元在第k个像素的丰度值;Npk表示它的邻域.将该端元的丰度向量转换为二维图像形式;I和J是图像的尺寸,满足N=I×J;Sijp是转换后对应的丰度值;Nijp是对应的邻域,通过函数g(x)来衡量丰度值的差异:
(18)
其中: e是自然常数;x的绝对值越小,g(x)的函数值越小.g(x)函数值的最小化等价于中心像素和邻域像素丰度差值的最小化,可以起到局部平滑约束的目的.
2.4 ASSKNMF算法
综合核非负矩阵分解和丰度约束,ASSKNMF算法的目标函数可以表示为:
(19)
与式(8)中的问题类似,式(19)可以分为两个子问题:
(21)
其中k是迭代次数.由于核函数的存在,式(20)中端元矩阵A的更新不能使用式(9)中的迭乘方法,本文中采用投影梯度法(Projected Gradient, PG)[23]对端元矩阵A进行更新,它的表达式是:
Ak+1=max(Ak-ηk)Af(Ak,Sk,0),
(22)
(23)
尺度因子ηk的计算采用非负矩阵分解中用到的回溯Armoji搜索法[24],在每个迭代过程中,目标函数值都满足一定的下降:
f(Ak+1,Sk)-f(Ak,Sk)≤γηkvec(Af(Ak,Sk))Tvec(Ak+1-Ak),
(24)
(25)
其中: vec(g)是将矩阵转为向量;γ是下降程度,通常设为0.01.
丰度矩阵的求解依然采用式(10)中使用的迭乘更新法,不同的是需要在高维特征空间中进行,并且考虑稀疏约束和平滑约束:
(26)
其中: 矩阵Aφ和Xφ是端元矩阵和像元矩阵在高维空间的映射,矩阵S是丰度矩阵;.*和./分别对应于矩阵的点乘和点除,h(S-SN),g′(S-SN)的形式与g(S-SN)相似,具体如下:
(27)
(28)
综合端元矩阵A和丰度矩阵S的求解过程,整个算法的流程图如表1所示:

表1 ASSKNMF算法流程
关于端元矩阵A和丰度矩阵S的初始化问题,本文中A的初始化采用基于光谱信息散度(Spectral Information Dirergence, SID)[25]的方法.光谱信息散度SID的定义如下:
(29)
其中:xi和xj是任意两个像元,它们归一化的形式是:
(30)
其中L是波段数.
端元初始化的具体步骤是:
a) 随机从图像中选取一个像元作第一个端元;
b) 计算第一个端元和其他像元的SID值,本文中SID的阈值设为0.05,第一个满足阈值的像元作第二个端元;
c) 计算剩余像元和第一、第二个端元的SID,第一个满足阈值的像元选作第三个端元,依次类推,找出所有端元.
考虑到初始值对非负矩阵分解的结果有较大影响这个因素,SID的阈值取为0.05,使得初始化的端元之间具有一定的不相似性,丰度矩阵S的初始化采用FCLS算法[26].
3 实验结果与分析
本节将提出的ASSKNMF算法与基于高斯核的核非负矩阵分解算法npKNMF[15],端元和丰度约束的核非负矩阵分解算法CKNMF[16],双目标非负矩阵分解算法Bi-objective NMF[17]进行性能比较,同时将本文所用的稀疏约束和平滑约束与非负矩阵分解结合作为一种线性方法,记为CNMF. Bi-objective NMF中涉及到一个权重系数θ,这里选取0.2,0.5,0.8三种情况作为比较.评价指标主要有端元的光谱角距离(Spectral Angle Distance)DSA和丰度的均方根误差(Root Mean Square Error)ERMS:
(31)
(32)
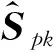
3.1 模拟数据实验
从美国地质调查局(United States Geological Survey, USGS)光谱库中选取了6种不同地物的光谱作为端元生成模拟数据,该光谱库中地物光谱的波长在0.38~2.5μm之间,分辨率10nm,共有224个波段,图1显示了这6种端元的光谱曲线.针对Hapke和GBM这两种非线性混合模型生成数据的方式如下: 1) 首先生成丰度,丰度生成方式和文献[21]中类似,将36×36大小的图像分割为互不重叠的大小为6×6的正方形块,并将这些块随机分配给不同的端元;用7×7的低通滤波器对地物的丰度进行滤波,产生混合像元;丰度值超过纯像元程度时,该像元的丰度值由所有端元平均.图2显示了6个端元对应的丰度图.2) 生成Hapke模型数据时,先将端元光谱反射率按照式(5)转为单次散射反照率,然后与1)中产生的丰度相乘得到混合的单次散射反照率,再按式(4)变为混合光谱反射率数据.3) 生成GBM数据时,将1)中产生的丰度值带入式(7)产生双线性数据,参数γ在[0,1]中随机取值.生成模拟数据后,再添加不同信噪比的高斯白噪声.
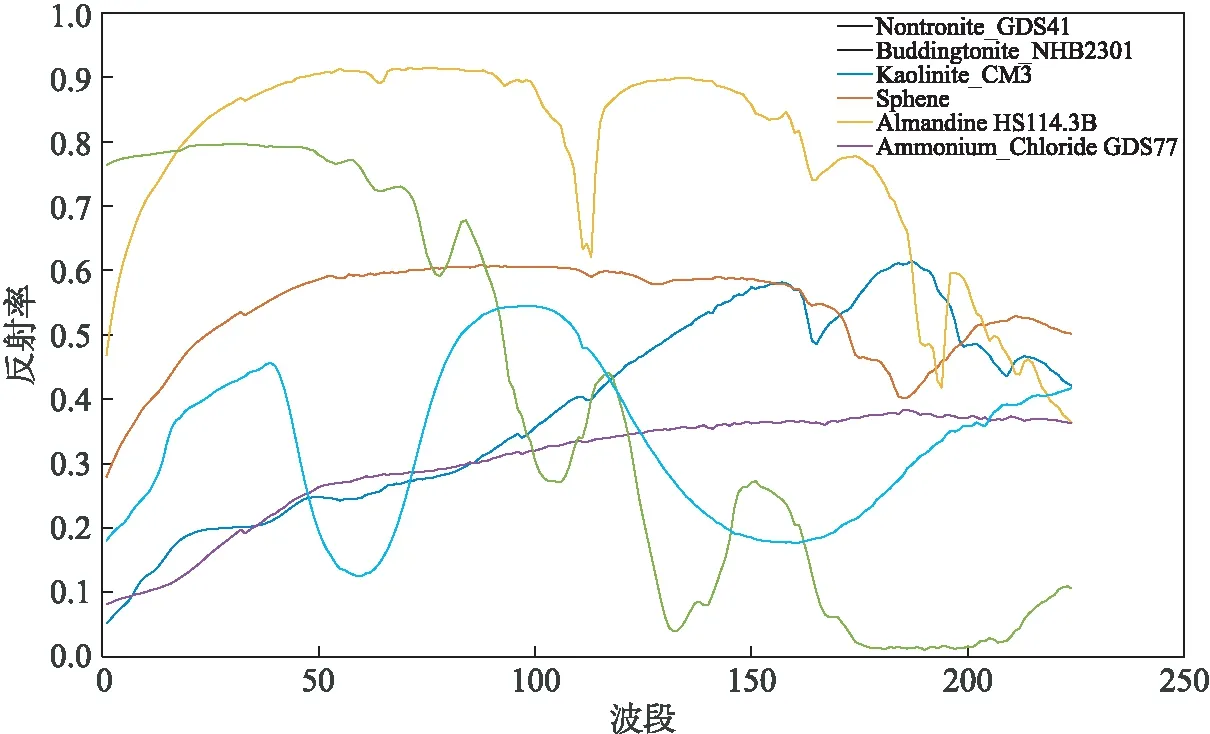
图1 USGS光谱库中的6条光谱Fig.1 Six endmember spectra from USGS spectral library

图2 6个端元的丰度图Fig.2 Abundance maps of six endmembers
实验1参数确定实验: 本文提出的算法中主要有稀疏约束正则参数α,平滑约束正则参数β,核参数σ以及平滑程度参数γm.其中平滑程度参数γm按照文献[22]的取法取0.5,剩余3个参数的选取通过实验来决定.第一步固定核参数σ=6,变化α和β来观察结果.图像大小是36×36,6个端元,纯像元程度为0.8,加入40dB的高斯白噪声,分别针对Hapke模型和GBM进行实验,取10次试验的平均结果.图3显示了α和β对Hapke模型和GBM结果的影响.从图上可以看出,在两种不同的非线性模型下,α和β分别取0.001和0.1,可以使DSA和ERMS达到比较好的结果.第二步固定α和β的值,变化σ来观察结果.实验设置不变,取10次试验的平均结果.
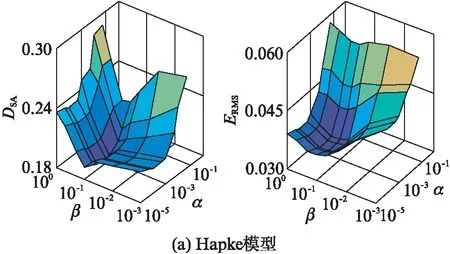
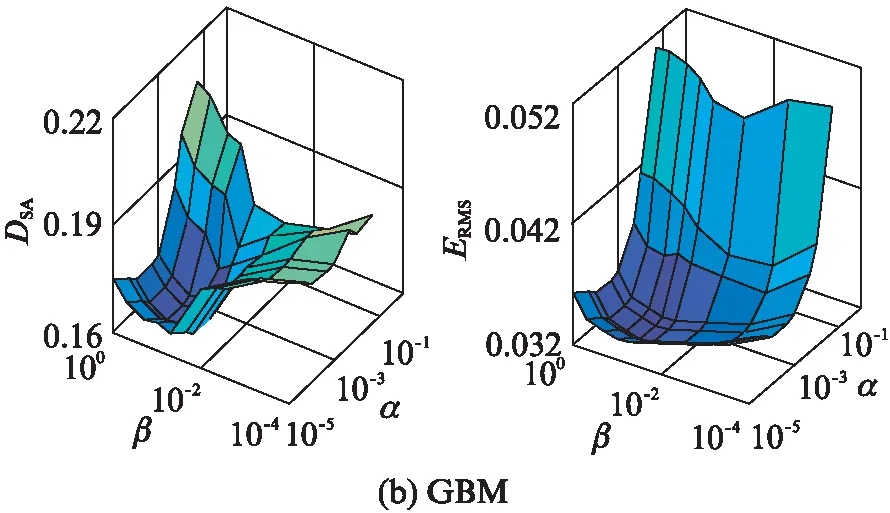
图3 α和β对结果的影响
图4显示了σ对两个模型结果的影响,可以看出σ在区间[3,10]上时结果比较好,经过权衡后,最终σ选定为4.

图4 σ对结果的影响Fig.4 Results with respect to σ
实验2端元数目和信噪比的影响分析: 在该实验中比较了各算法在不同端元数目和信噪比下解混的精度.图像大小是36×36,纯像元程度是0.8,端元数目取3、4、5、6.在端元数目固定的情况下,分别对Hapke模型和GBM数据进行解混,信噪比取40dB和20dB.表2~表5(见第436~437页)分别显示了端元数目为3、4、5、6情况下各算法的解混结果.从表中的数据可以看出,在端元提取方面: 随着端元数目的增加,非线性程度越复杂,各算法端元提取的精度会逐渐下降,本文提出的ASSKNMF算法和其他算法相比一直保持最优的结果.仅利用核非负矩阵分解的npKNMF的解混精度随着端元数目的增多下降很明显,线性的CNMF的解混结果在端元数目为3时还尚可,端元数目增多后也不理想.CKNMF端元提取的结果并不理想,这也间接证明了其添加的端元最小体积约束并不能提高解混精度.
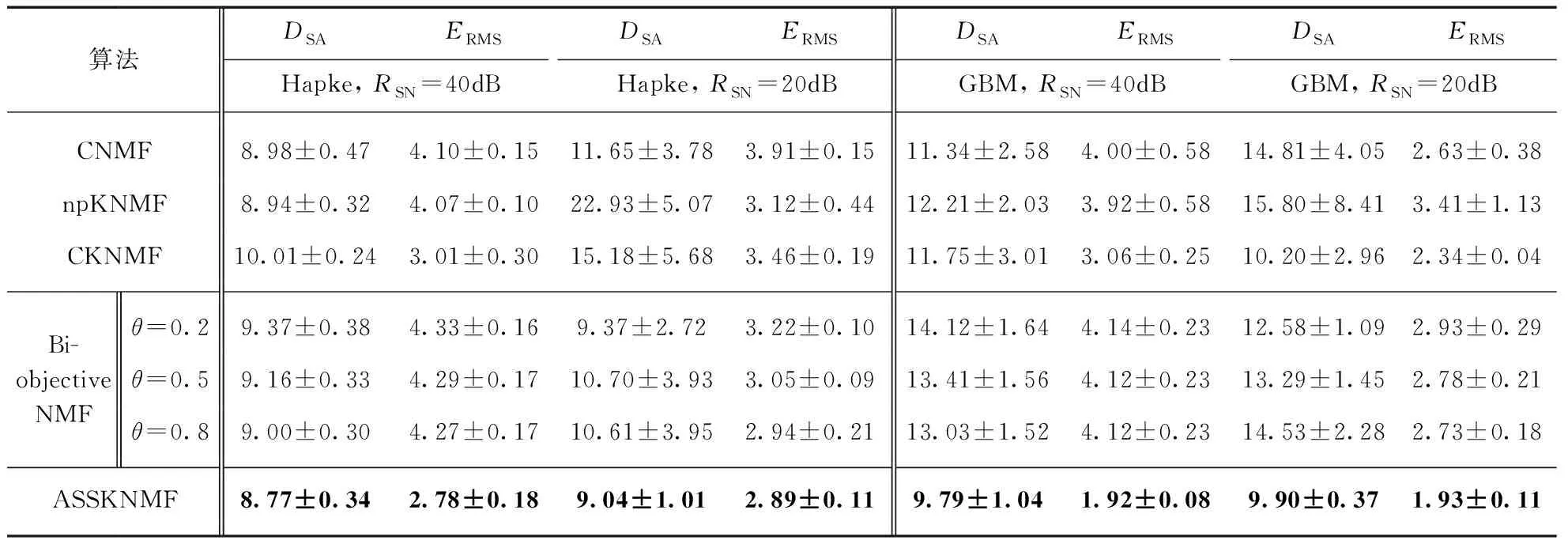
表2 端元数目为3时各算法结果比较(×10-2)
注: 每种评价指标的最优结果由粗体标出.
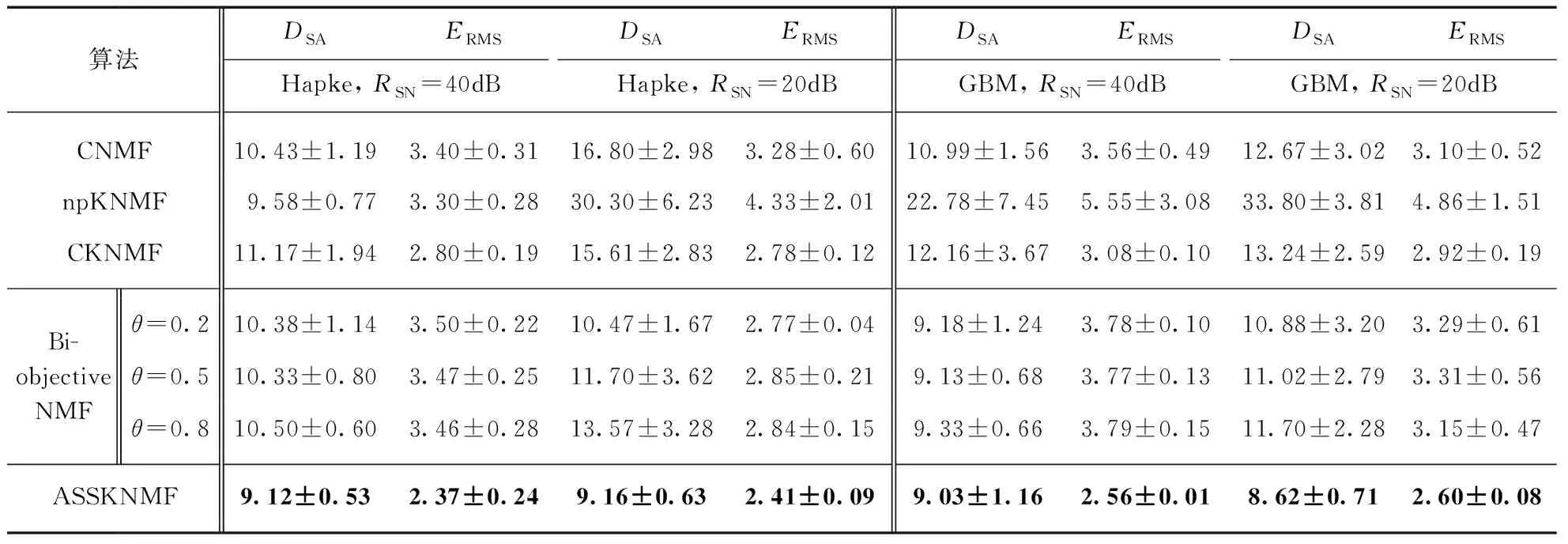
表3 端元数目为4时各算法结果比较(×10-2)
注: 每种评价指标的最优结果由粗体标出.
表4 端元数目为5时各算法结果比较(×10-2)
注: 每种评价指标的最优结果由粗体标出.

表5 端元数目为6时各算法结果比较(×10-2)
注: 每种评价指标的最优结果由粗体标出.
Bi-objective NMF通过结合线性和非线性,结果总体上比CNMF,npKNMF和CKNMF要好,但是和权重因子的取值有较大的关系.在丰度估计方面: 从数据上可以看出没有添加丰度约束的npKNMF和Bi-objective NMF的丰度估计精度要低于添加丰度约束的CNMF,CKNMF和ASSKNMF.CKNMF丰度估计的结果虽比CNMF要好,但是其使用的2范数约束是从整体上平滑丰度,在空间分辨率低时会模糊化丰度图,这与实际地物分布时存在的局部平滑特性是矛盾的,而本文提出的ASSKNMF既考虑了丰度分布的稀疏特性,又考虑了丰度分布的局部平滑特性,使得最后估计的丰度更接近于真实值.
3.2 实际数据实验
本文采用两个实际地区的高光谱数据来分析和评价各算法的解混结果.第一个数据是机载可见光/红外成像光谱仪(Airborne Visible/Infrared Imaging Spectrometer, AVIRIS)获取的美国内华达州Cuprite矿物地区的高光谱图像,图像大小是250×191(如图5(a)所示),有224个波段,解混前需剔除掉信噪比低和水吸收波段(1~2,104~113,148~167,221~224),还剩余188个波段.第二个数据是HYDICE华盛顿国家广场Washington DC Mall图像(如图5(b)所示),图像大小是1280×307,有210个波段,解混前同样剔除掉信噪比低和水吸收波段(1~4,76,87,101~111,136~153,198~210),还剩余162个波段.Cuprite地区富含多种矿物质,会存在紧密混合现象,HYDICE地区有建筑、草地、树木,会存在多层次混合现象,且这两个场景有详细的地物真实调查参考[27]同时以往也经常被用作解混研究的数据.

图5 真实高光谱遥感图像Fig.5 Real hyperspectral remote sensing images
从第一幅Cuprite图像中截取大小为50×40的子区域作为测试数据,如图5(a)所示. 根据研究和实际调查结果[27]可知,该子区域中主要包括钙铁榴石,高岭石和蒙脱石3种物质.表6中列出了各算法对该区域解混的DSA值,从数据可以看出,CKNMF的解混结果劣于其他所有方法,证明其使用的端元约束的正确性有待考究.npKNMF和Bi-objective NMF两种非线性方法的结果要优于线性的CNMF,而本文提出的算法兼顾考虑了非线性效应和地物分布特性,得出的结果要优于其余的方法.图6中列出了本文算法求解的3种端元对应的丰度图,能够比较真实的反映地物分布.

表6 不同算法在Cuprite数据上的端元提取结果与参考光谱的光谱角距离比较
注: 评价指标的最优结果由粗体标出.
对于第二幅HYDICE图像,从中截取大小为100×100的子区域用来测试算法的性能,如图5(b)所示.该地区主要有5种地物: 树木,屋顶,水体,道路和草地.表7中列出了各算法对该区域5种地物解混的DSA值.从结果可以看出,本文提出的方法ASSKNMF在屋顶,道路和草地上结果最好,树木是Bi-objective方法最好,水体是CNMF最好,平均结果上本文方法是最好的.同时可以发现端元数为5时,CKNMF结果最不好且下降明显,Bi-objective NMF要优于CNMF,ASSKNMF算法端元提取的结果最好.根据以往用作高光谱解混的研究结果[22]可知,图7中列出的5种端元对应的丰度图更接近实际地物分布.

图6 Cuprite数据ASSKNMF算法提取的3种端元的丰度图Fig.6 Abundance maps of three endmembers extracted by ASSKNMF of Cuprite data set
算法DSA树木屋顶水体道路草地平均CNMF0.07780.12120.08020.15560.30820.1486CKNMF0.10060.33560.71090.42750.16060.3470Bi-objectiveNMFθ=0.20.03690.16080.27780.10880.05740.1283θ=0.50.02920.14070.18050.15660.11500.1244θ=0.80.04660.13790.10610.17020.16180.1245ASSKNMF0.05960.11820.14970.09240.05530.0950
注: 评价指标的最优结果由粗体标出.
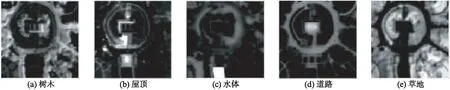
图7 HYDICE数据ASSKNMF算法提取的5种端元的丰度图Fig.7 Abundance maps of five endmembers extracted by ASSKNMF of HYDICE data set
4 结 论
提出了一种基于丰度约束核非负矩阵分解的高光谱非线性解混算法.与现有的基于核非负矩阵分解的算法相比,本算法先利用核方法将原始高光谱数据投影到高维特征空间,在特征空间中利用非负矩阵分解进行解混,同时考虑到实际地物的分布特性,在丰度上添加稀疏约束和平滑约束,使陷入局部极小值的概率变小.由于非负矩阵分解的使用,无需考虑具体的非线性表达形式,对紧密混合情况下的Hapke模型和多层次混合下的GBM都可以适用.模拟数据和真实遥感图像的实验结果表明,本文提出的算法与其他相关方法相比,可以提高非线性混合情况下光谱解混的精度.
