基于粗糙FCA-概念代数的上下文本体建模
2018-04-18安敬民李冠宇
安敬民 李冠宇
(大连海事大学信息科学技术学院 辽宁 大连 116026)
0 引 言
目前随着传感器和计算机技术的高速发展和普及,普适计算时代正在到来。普适计算要求传感器等设备能够感知到用户的上下文信息及其变化[1]。在普适计算的环境中,传感器采集的上下文具有异构、多变和数量大等特点。在对具有这些特点的上下文进行推理时,推理过程中获取信息的不完整性和上下文模型的弱可扩展性是主要的两个问题。推理结果的准确性很大程度上取决于所构建的上下文本体模型的方法。但就目前而言,在现有的上下文建模技术当中主要有基于逻辑[2]的、基于证据论[3]的以及基于本体语言[4]的上下文建模和基于元情景构建本体[5]等,这些方法主要目的都是强调如何提高推理出的知识和信息最后结果的准确性,但是忽略了在获取上下文信息的过程中,对上下文信息是否完整的重视,推理的对象信息不够完整,推理的结果自然会存在不准确性;同时也忽略了对模型推理出新知识后的处理。如何能让模型本体处于不断的学习状态,那就必须保证本体有很好吸纳新知识和信息的能力,即具有好的可扩展性。信息不完整性和模型弱扩展性的致因主要有两个方面:(1) 在收集的上下文信息过程中,遗漏了部分上下文隐含的有用信息,对上下文信息的不确定性处理程度不够;(2) 因为上下文本身由于类型不同,存在异构性,所以无论是从上下文本体模型内部的上下文之间还是内部上下文与外界上下文之间考虑,都具有差协同性的特点,使得模型本身不具备好的可扩展性。
本文针对上述两个问题,提出以下观点:(1) 引入粗糙形式概念分析,对上下文进行粗糙处理,即将获取到的上下文作为形式背景,对形式背景做幂集运算,得到多个隐含的形式背景(上下文),再排除无价值的形式背景,最终得到含有有用信息被隐含的上下文;(2) 引入概念代数,对上下文深度形式化表示,利用概念代数的运算规则(组成运算和关系运算)将深度形式化的上下文构建成概念网,再将其转化为本体模型。概念网具有良好的可扩展性,可实现本体内部的扩展,同时可实现与外界不同本体之间兼容性,可进行通信和互操作。
1 基本概念
1.1 形式背景
设形式背景为一个三元组,为B=(O,A,R),其中O为形式对象,A为属性集合,R为O与A之间的二元关系R⊆O×A[6]。
1.2 形式概念
定义1若二元组C=(M,N)满足:M⊆O,N⊆A,令M={a∈A|∀o∈M,oRa},N={o∈O|∀a∈N,oRa},其中,M是O中所有的对象集,N是A中所有的属性集,则C被称为B中的一个精确形式概念[6]。其中M,N分别被称为C的外延和内涵。
在精确形式概念中,引入上近似外延和下近似外延,进而扩展引出了粗糙形式概念。
定义2若设形式背景B=(O,A,R),若三元组D=(M上,M下,N)满足:M上={o∈O|∃a∈N,oRa},M下={o∈O|∀a∈N,oRa},N={a∈A|∃o∃M上,∀o∈M下,oRa},则D被称为形式背景B的一个粗糙形式概念[7-8]。其中M上、M下、N分别被称为粗糙形式概念的上近似外延、下近似外延和内涵。
1.3 概念代数
定义3上下文是含有语义的情景(语境),可形式化表示为Θ=(O1,A1,R1),其中O1为全部对象集,A1为全部属性或状态集,R1为对象和属性之间的关系集[9]。形式背景的形式化定义如1.1节所述,二者在形式化定义上的结构是同构的且元素是相似的,本文提出Θ→B。
定义4根据Wille的形式概念分析[6],形式背景可以用形式概念分析处理为一个形式概念为二元组(O,A),对其进行扩展,在概念代数中一个语义环境的形式概念C表示为一个五元组C=(M,N,Rc,Ri,Ro)[9-11],其中M⊆O是对象集,N⊆A是属性集合;Rc⊆M×N,表示对象与属性之间的关系,Ri⊆N×N1(N1是其他概念C1的内涵),表示概念C与C1的输入关系(这里的关系是从人类认知角度出发的,是指脑内部与外部的关系,本文将概念视作脑内知识,其他均为脑外概念),其中N1⊆O且N1⊄N,也即从其他概念到概念C的关系;Rc恰与Ri相反,是输出关系[9-12]。
定义5一个语义环境B下的概念代数CA定义为一个三元组,CA=(C,OP,B)=({O,A,Rc,Ri,Ro},{OPr,OPc},B)[9-11],其中OPr、OPc分别表示关系运算集和组合运算集,具体含义如下所述:
关系运算集OPr={↔,↔/,,≻,=,≅,~}[9-11]。集合中的元素分别表示概念之间的相关和不相关,若C1↔C2则A1∩A2≠φ,反之A1∩A2=φ,则C1↔/C2;子概念与超概念,C1C2,即A2⊂A1,则C1为C2的子概念,C2为C1的超概念以及等价,(C1=C2)(A2=A1)∧(O1=O2),则C1与C2等价;一致,(C1≅C2)(C1C2)∨(C1≻C2)和类比,(C1~C2)( #(A1∩A2)/#(A1∪A2),即内涵交集与并集的比值,比值在0到1之间,如果值为1,则是等价关系。还包括因果关系(—∘)和行为关系(do:?),C1—∘C2表示C1是C2的因,C1do?C2表示C2是C1的一种行为的被作用对象(?表示to do)[12]。
利用概念的关系运算,可判断概念之间的关系,进而对概念进行关联组合。

上述概念代数相关的运算规则,在本体实际应用中,文献[12]上已经得到了较好的验证,所以合理使用这些规则构建上下文本体是可行的。而且,上述各规则与已经在本体中经常使用的形式概念中的关系有着天然的对应关系。如继承关系对应kind-of关系;组合与分解对应part-of关系;泛化和特化对应kind-of关系;实例化对应instance-of关系[12]。
定义6概念网CN是使用概念代数规则构成的,CN形式化表示为:CN={a|P→Q,R}。其中,P,Q分别表示n个概念的集合,R是上述综述的概念代数运算规则;也即表示规则R下P集合对Q集合的映射所构成的集合CN。
1.4 上下文及本体
上下文表示事物的状态或属性,可以是过去的状态,也可以是现在的状态[13]。而形式背景定义为一个三元组,形如B=(O,A,R),其中O为对象,A属性或状态,R为对象和属性之间的某种关系,所以根据对应关系,可以把上下文视为一个形式背景,可以用形式概念分析(FCA)处理,在本文定义3中已经提出。
Studer[14]提出的本体概念中,包含四部分:概念模型,是指领域的主要概念;明确的,是指概念有明确定义;形式化,是指本体中的数据、信息以及概念计算机可读; 共享,是指领域内共识。
2 基于RFCA的上下文抽取方法
2.1 属性集幂集
定义7令f(S)={x|x⊆S},S是任意一个集合,则称f(S)为S的幂集[15]。若集合S中有n个元素,则它的幂集个数为2n个,如S={a,b},那么它的幂集f(S)={{a},{b},{a,b},{}}。
一个集合的幂集就是包括了所有它的子集,所以属性集的幂集包括了它的所有属性可能的组合,不仅保留了原属性集还补充了一些隐含的属性集合,这样保证了形式背景概念抽取的完整性[7],进而可以较好地处理概念的不确定性。
2.2 RFCA抽取属性集合幂集方法
粗糙形式概念可以由三元组D表示,如D=(M上,M下,N),其中M上上近似外延和M下下近似外延组成其外延部分;上近似外延和下近似外延需要通过从形式背景中抽取其属性(内涵)来计算得出,本文利用王丹等[7]提出的方法,构造了粗糙形式概念抽取方法框架图,如图1所示。
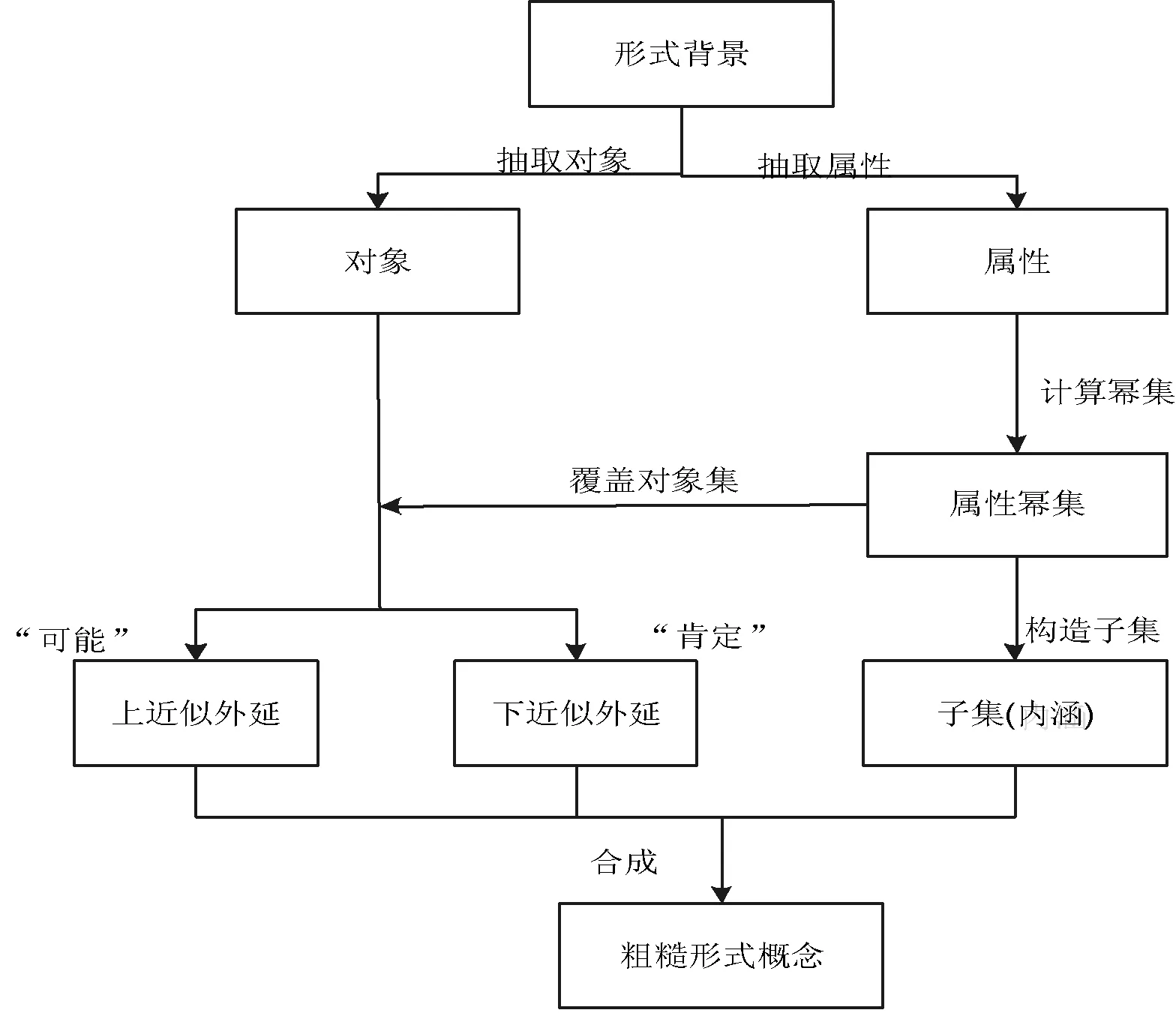
图1 粗糙形式概念抽取方法框架图
2.3 实 例
如将一个上下文作为一个形式背景,抽取出对象集O={1,2},属性集A={a,b},将形式背景用二维表表示,如表1所示。
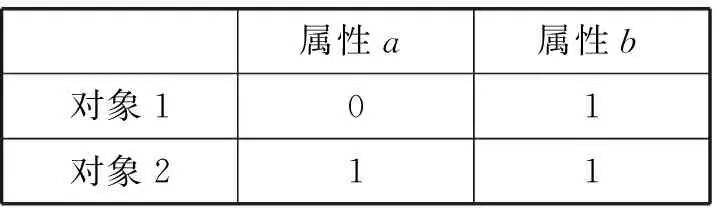
表1 形式背景
由属性集可求得幂集P(A)={{a},{b},{a,b},{}},再求的上近似外延和下近似外延,如表2所示。
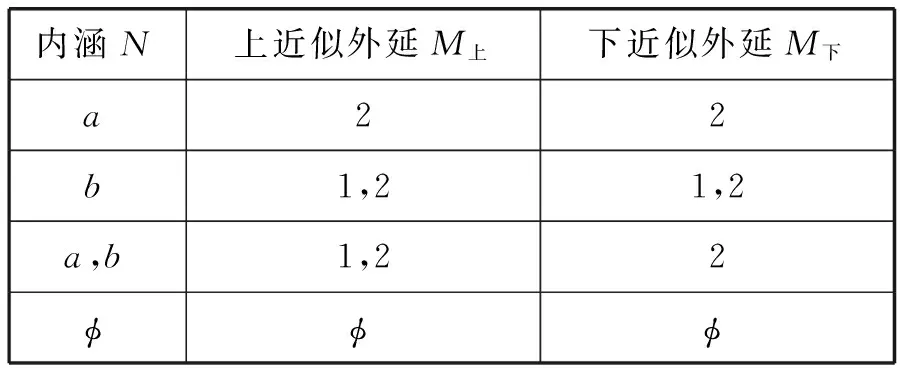
表2 内涵与上近似外延和下近似外延计算表
然后合成粗糙形式概念,除去空集(无意义),得到三种定义良好的粗糙形式概念,具体如表3所示。
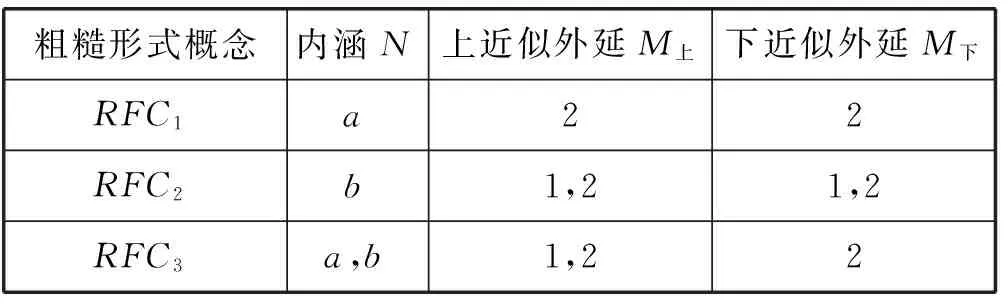
表3 形式背景对应的粗糙形式概念
表3中具有良好定义的粗糙形式概念RFC1、RFC2及RFC3都可以将其作为一条上下文。其中,RFC3是初始得到的上下文,RFC1及RFC2是隐含的上下文。
2.4 上下文抽取方法
基于RFCA的上下文抽取的关键步骤如下:
(1) 发现新的上下文,从上下文库提出将新的上下文写入库申请;将该上下文从申请队列中取出做准备。
(2) 上下文库中的启发性知识对该上下文进行判断,若不满足一致性,则直接删除该上下文;否则,将该上下文交到形式背景处理模块,执行(3)。
(3) 将满足一致性的上下文作为形式背景,使用2.2节所述的方法,将形式背景中的对象和属性抽取出来,对属性进行幂集计算,计算出上近似外延和下近似外延,最后合成粗糙形式概念。
(4) 将合成的粗糙形式概念逐一转换成上下文的格。
至此,一次上下文更新或者对一个新的上下文处理就完成了。
算法1基于RFCA上下文抽取算法
输入:一个语义情景(上下文)
输出:一个或多个粗糙形式概念
1.Begin:
2.(O,A)=f_constructFormalContext(O,A,R);
3.objectSet=f_construct(O);
4.attributeSet=f_construct(A);
5.A_powerSet=f_constructPowerSet(attribute);
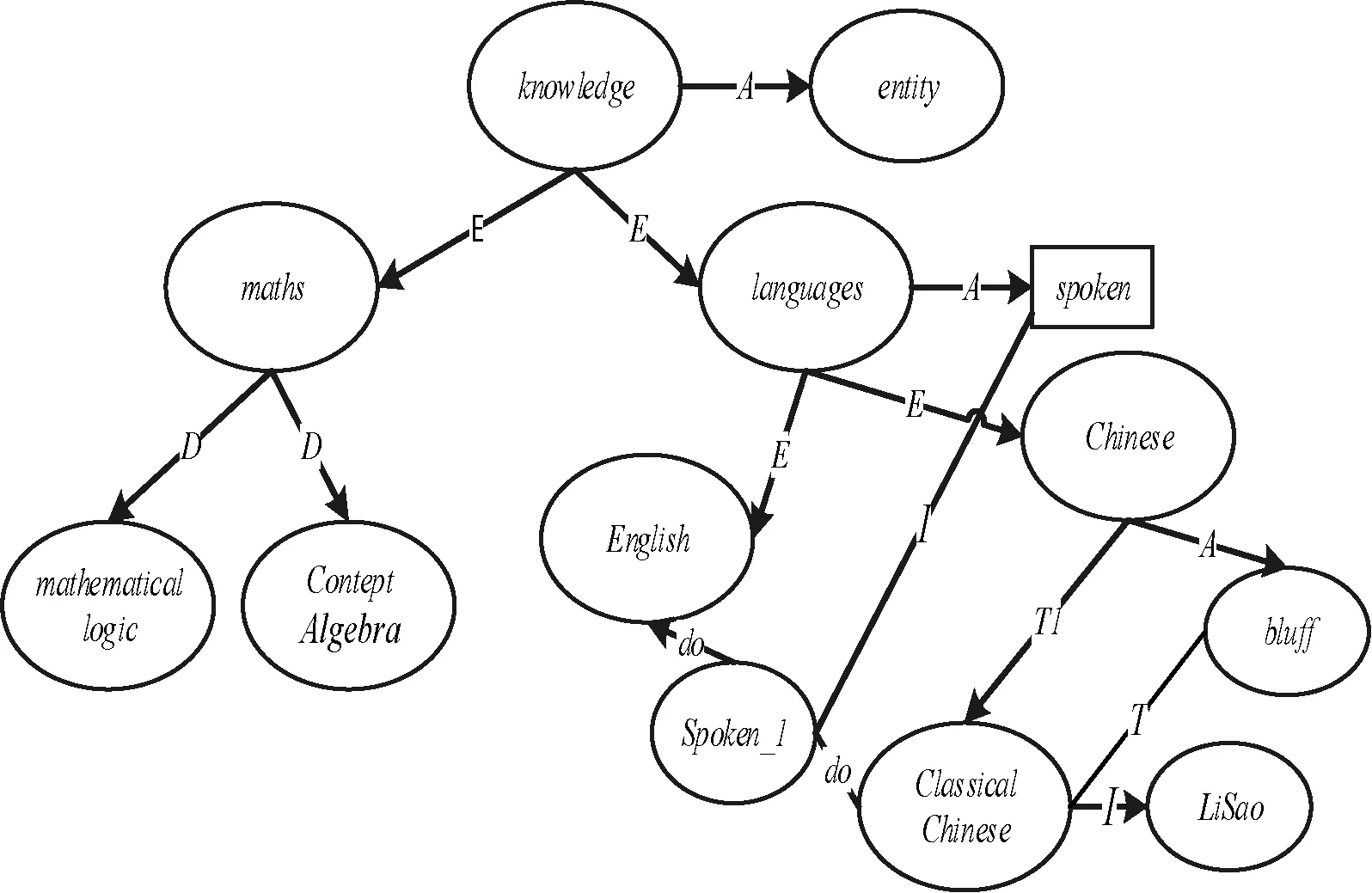
6.for(i=1;i 7. { M= objectSet[i]; N= A_powerSet[i]; 8. if(DKE(M,N)==1) 9. { down_extention=M; 10. connotation =N; } 11. else if(DKE(M,N)==0) 12. { up_extention=M; connotation =N; } 13. else loop; } 14 .End 算法1中,输入一个上下文,使用函数f_constructFormalContext()将该上下文的三元组中的对象和属性抽取出来,然后利用构造函数f_constructPowerSet()对属性集进行幂集计算;将对象集以及属性集的幂集做笛卡尔积运算(DKE()),判断是部分相关还是完全相关,进而得到对象的上近似集(up_extention)和对象的下近似集(down_extention)),最后输出一个或多个粗糙形式概念(M上/下,N)。 上述是概念代数中的运算规则,本文将其引入到上下文本体建模当中,将一个上下文视为一个形式背景,利用概念代数对形式背景进行深度形式化(深度形式化表示的上下文是一个概念)和利用运算规则进行复杂计算(含有语境)。将一个概念作为起点,将与其有关联关系(上述提到的7+9=16种运算关系)的外部概念联系起来,并做概念的语法和语义冲突处理。从一个独立的概念不断扩展成多个概念的关系集合,最后成为一个概念网(CN)-本体。如图2所示。 图2 基于概念代数的上下文本体建模框架图 利用上下文存储库中的启发性知识判断上下文是否满足一致性[1],若不满足一致性需要则直接删除,对于满足一致性的上下文,使用Jena对其解析,得到OWL表示的对象集,属性集和对象与属性的关系集。将上述得到的结果构建形式背景,其对应关系如表4所示。对得到的形式背景使用概念代数CA进行扩展和深度形式化。 表4 上下文与形式背景对应关系 对由上下文抽象化(如3.1节所述)得到的形式背景,使用概念代数对其运算,得到形式背景的概念代数表示,与初始概念关联合并,借用WordNet知识库对概念进一步判断概念间关系,如有冲突,需要使用WordNet或者领域专家进行处理,否则合成构建概念网。 关于概念网中概念间相互关联的关联规则[12]如下: 规则1:根据WordNet判断概念之间(内部概念和外部概念)关系,以当前概念为核心,若其他概念为上位词,利用泛化表示;若为下位词,用继承(扩展、裁剪或替换)表示。 规则2:对整体和局部关系,以当前概念网为核心,若为上位词,利用组合表示;若为下位词利用分解表示。 规则3:对于概念之间的属性关系,需要进一步判断,是属于因果关系还是行为关系(do:?,一个对象作用于另一个对象)。 以上概念之间的关联规则在文献[12]中用于原有本体之间的合并(以一个本体为核心);而本文目的在于构建新的本体,所以本文以一个概念为核心构建概念网表示的本体。提出适用本文方法的形式背景概念代数表示-概念与内部概念构成概念网(CN)算法描述如下: (1) 初始化概念网L,初始化内部概念C1,以为C1中心。 (2) 对上下文抽象化,得到对象,属性以及其之间的关系,构建形式背景B。 (3) 对B进行概念代数运算,深度形式化,记为Ci(i=2,3,4,…)。 (4) 将Ci加入到概念网L中,与C1或者已有的概念网进行关联。 (5) 根据WordNet判断新加入的概念与L中已有的概念是否关联,如果不相关,删除此概念,不加入到概念网L中转到执行(2);如果相关执行(6)。 (6) 新概念节点加入到概念网L中,根据概念网L原有的概念之间关系(局部概念网)以及WordNet,依据人的常识以及领域专家的知识判断新节点与原有节点的关联关系(上述第1节所述的概念代数运算规则)。 (7) 运用概念代数的组成运算和关系运算对概念节点进行运算并关联。 (8) 转到执行(2);上下文存储库没有新的上下文,结束。 算法2基于概念代数的上下文本体建模算法 输入:内部概念C;上下文存储库ContextDB 输出:概念网CN 1.Begin: 2. N=relate(C2,C1); 3. i=3; 4. while(ContextDB[i]>0) 5.{ If( hasrealitionWordNet(Ci,N)) 6. { If( hasrealitionWordNet(Ci,N) .equals(enqivalent)) 7. N=relate(N,Ci); 8. else i++; continue;} 9. else loop:i++;} 10.End 算法2中,输入内部概念与ContextDB,以已有的内部概念C1和C2为核心,在上下文存储库中有新的上下文(ContextDB[i]>0)时,先后判断与原有概念网是否相关,具体与哪个结点相关;利用函数relate()(该函数是使用上述概念代数的关系运算和组成运算定义的复合函数)将现有的概念与原概念网关联,最后输出加入新节点的概念网。 利用上述构建本体算法以及第1节介绍的概念代数的关系运算和组成运算规则给出以Knowledge这个概念为内部概念(核心)的一个概念网(局部),如图3所示。 图3 “knowledge”概念网-本体(局部)图 图3中: E:extensionT1:tailoringobjectT:tailoring,A:attribute-ofD:decomposionI:instance-of,do:表示行为。 对图3给出的概念网,给出其形式化表示,如下: classicalChinesedo:spokeninEnglish; 在上下文本体建模过程中,利用R-FCA将获取到的上下文进行粗糙处理是构建模型的基础,所以它的实用性决定了构建的上下文本体的性能。 本文根据上述所提出方法的原理以及算法,结合文献[3] 给出的数据集,分为6组测试用例,分别为100,300,…,900,1 000个上下文(文献[3]与文献[16]已经做过对比实验,本文只给出与文献[3]的对比实验)。先对其进行上下文隐含概念的抽取,并使用Jena推理机解析得到具体可用的上下文(现实中存在的符合人的逻辑思维的对象与属性的组合)。再使用文献[3]提出的上下文推理方法(由于本文是对用于构建本体的上下文做处理来提高原有推理方法的准确率,所以只选择文献[3]的推理方法进行对比实验,以证实本文提出方法的有效性),对二者进行推理准确率统计,实验结果如图4所示。 图4 推理结果实验分析 本体的可扩展性对比实验,根据对本体中的原有概念结点在新加入概念之后,各个节点的变化情况做统计,利用式(1),计算出本体结构的改变率,改变率越小说明可扩展性越好,如图5所示。 图5 本体扩展性对比实验 (1) 式中:p(i)是本体结构第i次实验改变率,M是第i次在新加入概念节点后本体中原概念结点结构发生变化个数,N是第i次实验之前本体中概念结点总数。 如图4所示,由实验发现,文献[3]中是将得来的数据直接用于推理;本文提出先对上下文进行粗糙形式概念处理得到隐含而有用的粗糙上下文再进行推理。从实验结果上,当数据集为100时,二者准确率差值近似为0,但是当测试用例数量为300时,准确率差值1%,随着用例不断加大,为500,…,900甚至1 000时,二者准确率相差了5%,说明本文的方法在原方法上准确率提高5%。通过因果分析,可以发现,由于不同的上下文含有的对象个数和属性个数不同,属性个数多的上下文通过粗糙处理后得到的隐含上下文信息就多(如:一个上下文中含有n个属性,通过粗糙处理可得到2n个上下文),而且经过Jena解析之后虽然会去除一些没有价值的上下文,但是有用的上下文个数仍然很多。 根据本文的数据集,经过实验得到有价值的上下文分别为248、525、923、1 346、1 921和2 298,所以使用本文的方法处理上下文再进行推理时,信息源明显增大,推理的准确率自然变高。当构建上下文本体时,如果对含有属性较多的上下文不做粗糙处理,那么丢失上下文中那些有用信息的数量就非常巨大,而且直接对后继的模型推理造成推理结果不全面和不完整。从实验效果上看,采用本文所提的方法获取隐含的上下文信息是可行的、有效的。 如图5所示,本文对文献[3,5]中构建的上下文本体与本文提出的基于粗糙FCA-概念代数的上下文本体进行了本体可扩展性对比实验,并用式(1)分别计算出文献[3,5]和本文的方法的本体结构改变率。数据集共分为6组,为100,200,…,600(个RDF),具体实验结果如表5所示。 表5 本体结构改变率实验对比结果表 表5各组实验数据的结果表明,本文提出的方法 的本体结构改变率明显低于文献[3]和文献[5],所以在本体可扩展性方面要优于前二者。本文使用概念代数构建本体,利用数学运算计算概念间的关联关系,并改变概念网的结构,使得本体每次只需局部变化而非整体变化,致使本体具有较好的可扩展性。 粗糙形式概念分析对形式背景进行幂集计算,可以将上下文中隐含的有用信息提取出来,得出多个有用上下文;概念代数将形式背景高度形式化,再将已经高度形式化的概念,以网状形式进行构建,进而直接得到本体且具有较好的可扩展性和协同性。本文将粗糙形式概念分析和概念代数二者结合来构建上下文本体,目的是从收集上下文到构建上下文本体的过程中,对上下文都做不完整性处理,使得所得到的上下文本体含有更多有用和有效的上下文,进而提高本体推理的正确性,使本体可以提供更全面和准确的服务。通过本文理论和实验验证,证实将二者结合是可行的和有效的。同时本文为构建本体前期和后期的处理方法提供了新的视角。本文存在的不足是未在该方法的效率上进行验证分析。 [1] 张慧,李冠宇,王元刚.语用网驱动的上下文感知系统设计[J].计算机应用研究,2015,32(5):1412-1416. [2] 胡博,王智学,董庆超,等.基于描述逻辑的上下文知识获取与推理方法[J].计算机科学,2013,40(4):199-203. [3] 李艳娜,乔秀全,李晓峰.基于证据理论的上下文本体建模以及不确定性推理方法[J].电子与信息学报,2010,32(8):1806-1811. [4] Hervás R,Bravo J,Fontecha J.A Context Model based on Ontological Languages:a Proposal for Information Visualization[J].Journal of Universal Computerence,2010,16(16):1539-1555. [5] Lu Z J,Li G Y,Pan Y.A Method of Meta-Context Ontology Modeling and Uncertainty Reasoning in SWoT[C]//International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery.IEEE,2017:128-135. [6] 甘特尔,威尔.形式概念分析[M].马垣,译.科学出版社,2007. [7] 王丹,黄映辉,李冠宇.粗糙形式概念抽取的属性集合幂集方法[J].计算机工程与设计,2011,32(9):3162-3165. [8] 曲开社,翟岩慧,梁吉业,等.形式概念分析对粗糙集理论的表示及扩展[J].软件学报,2007,18(9):2174-2182. [9] Wang Y.On concept algebra:A denotational mathematical structure for knowledge and software modeling[J].International Journal of Cognitive Informatics and Natural Intelligence (IJCINI),2008,2(2):1-19. [10] Wang Y.On concept algebra and knowledge representation[C]//Cognitive Informatics,2006.ICCI 2006.5th IEEE International Conference on.IEEE,2006,1:320-331. [11] Tian Y,Wang Y,Hu K.A knowledge representation tool for autonomous machine learning based on concept algebra[M]//Transactions on Computational Science V.Springer Berlin Heidelberg,2009:143-160. [12] 韩国栓,李冠宇,王元刚.概念代数在本体合并中的应用[J].计算机应用与软件,2014,31(10):53-57. [13] Delbru R,Tummarello G,Polleres A.Context-dependent owl reasoning in sindice-experiences and lessons learnt[C]//International Conference on Web Reasoning and Rule Systems.Springer Berlin Heidelberg,2011:46-60. [14] Staab S,Studer R,Schnurr H P,et al.Knowledge processes and ontologies[J].IEEE Intelligent systems,2001,16(1):26-34. [15] 苏北.Z规格说明中幂集算子自动求精的研究与实现[D].沈阳:沈阳工业大学,2006. [16] Jousselme A L,Grenier D,Bossé é.A new distance between two bodies of evidence[J].Information fusion,2001,2(2):91-101.3 基于CA的上下文本体建模

3.1 上下文深度抽象化

3.2 上下文本体模型

4 实验验证与分析



5 结 语
