基于HowNet查询扩展方法的探究
2018-04-18张振梅高玉琢
张振梅 刘 明 毕 利 高玉琢*
1(银川市第二中学信息技术中心 宁夏 银川 750004) 2(北京航空航天大学计算机学院 北京 100191) 3(宁夏大学信息工程学院 宁夏 银川 750021)
0 引 言
信息检索技术是现代社会学习、生产中的一项关键技术,而信息检索的过程既需要高效组织信息又要能理解用户意图[1-2]。经典的信息检索方法[3]将用户的查询和文档转化成向量空间中的向量,用向量之间的余弦相似度度量文本之间的相似度。这种方法基于词条表层形态和词频统计对文本相似性进行度量[3],被称为向量空间模型VSM(Vector Space Model)。其认为文本中含有相同形态的词条越多则越相似,但是在VSM中,词条被视为没有语义涵义的字符,无法真正理解词条的语义涵义,因此这种方法对于歧义词等语义问题无法有效处理。查询扩展技术一定程度上解决了检索系统对词条语义的理解问题。查询扩展技术先利用本体等知识资源获取与检索词最相关的几个词条,扩展原始检索词;然后利用扩展后的检索词进行信息检索,明显提升了检索结果的覆盖范围和命中用户意图的几率。扩展词的相关程度决定了信息检索的质量,查询扩展的相关研究大多集中在检索词的扩展上,查询扩展一般利用本体、关联规则[5]或者语料统计方法[6-7]获取相似的词条作为扩展词。例如,徐博等提出了一种基于语料的查询扩展方法,其首先检索获取可信文本,然后从可信文本中选取词语作为查询扩展词进行二次检索获取检索结果[8]。马斌等针对以上问题,利用外部本体中承载的词条语义关系对基于关键词的信息检索方法进行了扩展[9]。Rekha利用伪相关反馈技术量化文档中的词语权重并扩展查询词[10]。黄承慧等基于外部知识词典度量词语之间的语义相关性进行查询扩展;结合词语相似度以及文本语义相似度计算文档之间的相似度[11]。然而上述方法都基于词袋模型假设。词袋模型将文档视为是词条的无序集合,其独立性假设忽略了文档词条的次序关系和文档的篇章结构,而语序在文本语义表示中有着重要作用。例如:“老师借给我一本书”和“我借给老师一本书”有着相同的词条,在传统的词袋模型中这两个本文是等价的,然而其实际表达的语义是截然相反的。据我们所知,目前几乎没有研究工作在查询扩展中考虑到词语的重要性和词语分布因素。
针对信息检索中词语词序分布和词语语义建模的难题,本文基于查询扩展检索技术,利用中文词义知识库HowNet对检索词进行了语义概念扩展。在文本检索过程中考虑了词序、词条分布和词语语义关系等因素,设计了文本词条顺序和分布表达方式,同时区分表达了不同重要程度的词语。实验表明,我们的方法既考虑了词条语义,又考虑了词条顺序,取得了良好的检索效果。
1 信息检索模型
1.1 向量空间模型
向量空间模型中,每一篇文档和用户查询的信息都被看作空间中的向量,文本被定义为:
V(dj)=((t1,w1j),…,(ti,wij),…,(tn,wnj))i=1,2,…,n
(1)
式中:ti代表文本中的特征词,wij是ti在文本dj中的权重。两个文本的相似性可以利用向量之间的余弦相似性获得,如图1所示。
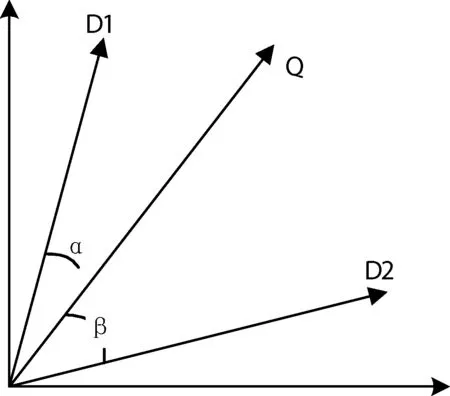
图1 向量空间模型
1.2 文本相似度的计算
目前信息检索方法是Lucene[13]在VSM基础上形成的相似度计算方法。特征量化方法如公式:
lengthNorm(t)}
(2)
式中:tf因子不再是传统的特征词频率,而是特征词真实频率的平方根值;Idf因子取传统反文档频率的对数;t.getBoost是针对每个索引域的激励因子;lengthNorm是长度因子,与字段内的特征词个数有关,一个字段内的特征词个数越多,其长度因子越小。
在信息检索时,Lucene计算用户查询q与文档d的相似度,并按照相似程度将将文档呈现给用户,如公式:
Score(q,d)=Coord(q,d)×queryNorm(q)×
W(t,d)
(3)
利用式(2)代入即得:
Score(q,d)=Coord(q,d)×queryNorm(q)×
t.getBoost()×lengthNorm(t,d)}
(4)
式中:q代表query,d代表document,t代表term。Coord(q,d)的值表示文档d中包含q的数目。t.getBoost()是针对每个索引域的激励因子。tf(tind)所搜项t在文档d中出现的频率,queryNorm(q)是q的归一化因子,保证不同检索结果评分是有可比性的。
1.3 基于本体的查询扩展
本体承载了概念的语义关系,可用于对的检索词进行扩展。例如,当用户输入的检索词“计算机”,可以被扩展为“PC,电脑,笔记本电脑”;利用语义本体获得与查询词最相关的词语作为扩展词,利用扩展词对搜索引擎进行检索会返回包含更多信息的页面,命中用户意图的概率也会更高。而概念之间的相似度可由图2所示的义原层次树获得。对于不同的义原,义原节点在树中的最短距离越长,其相似度越低[14]。可以使用式(5)获取与检索词最相近的一组概念。
(5)
式中:dis(Oi,Oj)是义原Oi和Oj在义原层次树中的最短路径长度,a是可调参数,通常取1。我们对检索展词的选取采用排序与阈值结合的方式,将用户输入的每个检索词输入HowNet,获取跟输入检索词语义相似度排序前3,并且语义相识度大于0.5的词语作为该检索词的扩展词,完成语义相似度的扩展。图3展示了查询扩展检索与传统检索的区别。
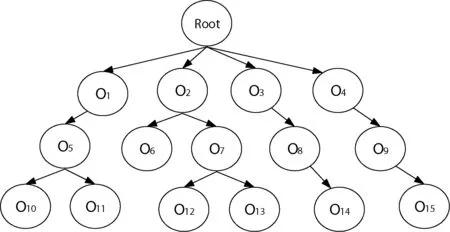
图2 义原层次树
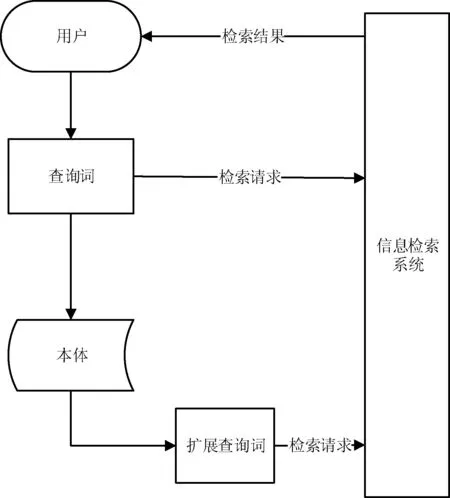
图3 查询扩展检索原理图
1.4 存在的缺陷
目前的查询扩展研究都集中在利用知识库、用户日志或者统计方法获取检索扩展词,再将扩展词输入到搜索引擎获取的检索结果,目前检索方法存在以下问题:
(1) 无法反映检索词语的重要程度,原始输入词语和查询扩展词语在重要程度和语义上存在一定的差别,传统的方法无法体现这种差别。
(2) 没有考虑检索词的分布情况,不同信息在文档中占据的比例不同,而用户感兴趣的内容应该是文档的主要内容。如果用户检索词分布在文档中仅仅占据很少比例,这样的文档不应该是首选的文档。
(3) 没有考虑词序、词距等因素。当用户输入的查询词包含多个词条时,不同的词语序列会导致完全不同的文档含义,传统方法忽略了词语的序列信息。
2 查询扩展检索方法
2.1 扩展词的衰减
通常情况下,扩展词对文档的相似性贡献往往低于用户输入的原始检索词对文档的相似性贡献,因此扩展词的权重也应该较初始检索词的权重低。基于这样的直觉,本文在计算相似性过程中引入了扩展词权重衰减因子来解决这个问题。我们初始检索词权重保持不变,针对扩展词进行了权重衰减,具体计算方式如公式:
distance(q)×decrease×lengthNorm(t,d)}
(6)
式中:TF-IDF因子是通过式(2)计算出的结果,保留了TF-IDF权重对特征词分布、特征词权重以及特征词数量比重的依赖。decrease是我们引入的扩展词的权重衰减因子,衰减因子的大小是初始检索词与扩展词在WordNet中的语义相似度。如果是t用户输入的初始检索词,则权重为1;如果是扩展检索词,则设定为0.5。LengthNorm是我们引入的词语分布因子度量因子。
2.2 词序的表达
词袋模型无法衡量文本的词语顺序,词语顺序的不同也会导致文本语义的不同。用户输入检索词的顺序反映了用户的检索意图,当用户输入多个检索词时,多个检索词的顺序也可以作为一项重要检索特征。检索词在文档中出现的次序与用户输入的检索次序越一致,则文档越契合用户意图。因此我们设计了检索序列向量表示用户查询序列,构造了最长检索一致向量表示文档的词语序列的一致性,两者共同构成词语序列因子来衡量文档和检索的序列相关性:
(7)
式中:Nq是用户输入的查询词的个数,V(Qterms)是用户输入的查询词向量,该向量里面每一维代表一个检索词,其顺序按照用户输入的顺序,数值均为1。V(Dterms)表示文档中出现的检索词的最大查询一致序列,其每一维度代表的含义与V(Qterms)相同。考虑到查询词在文档中可以多次出现,我们利用查询词在文档中首次出现位置来标定文档中的检索词序列。文档中出现的检索词会形成许多与检索序列一致的候选检索词序列,V(Dterms)则是用来表示文档中出现的候选检索词序列中最长的一致检索词序列。对于V(Dterms)中的每一维度,若文档的最长一致检索词序列包含该词条,则该维度特征值为1;反之,不包含的检索词条对应维度特征值为0。
例如,初始检索Q为四个检索词“计算机”、“辅助”、“设计”、“图片”,用户输入顺序为:
“计算机—辅助—设计—图片”
V(Qterms)={1,1,1,1},V(Qterms)中的四个维度依次代表“计算机”、“辅助”、“设计”、“图片”四个检索词。文档A中顺序出现了“辅助”、“设计”两个检索词,则V(Dterms)={0,1,1,0}。文档B中顺序出现了“设计”、“辅助”两个检索词。则其V(Dterms)={0,0,1,0}。文档C中顺序出现了“设计”、“计算机”、“辅助”、“图片”四个检索词,则文档C中产生了如下三个的检索一致序列:
“设计—图片”
“计算机—辅助—图片”
“辅助—图片”
我们取其最长的序列组合“计算机—辅助—图片”构建V(Bterms)={1,1,0,1}。通过order(q,d)因子我们可以计算得出用户检索Q与文档A的序列因子为1/2,用户检索Q与文档B的序列因子为1/4,用户检索Q与文档C的序列因子为3/4,可以保证检索词语序列与文档中分布的词语序列越一致,词序因子越大。
2.3 词语的分布
用户输入或者查询扩展的多个检索词是紧密相关的。我们假定多个检索词在文章中分布的篇幅越广,文档将用户检索相关的信息作为主要内容的概率越大,从而越契合用户的检索意图。检索词占据整篇文章的篇幅比例可以作为衡量检索词分布的一个标准,因此我们定义如下词语距离因子来衡量:
(8)
式中:Qterm.last表示检索词在文档最后出现的位置,Qterm.first表示检索词首次出现的位置。
综上所述,基于Lucene中用户查询与文档相似度的改进计算方式改进后计算方式如下:
Score(q,d)=Coord(q,d)×queryNorm(q)×
order(q,d)×w(t,d)
(9)
展开即:
Score(q,d)=Coord(q,d)×queryNorm(q)×
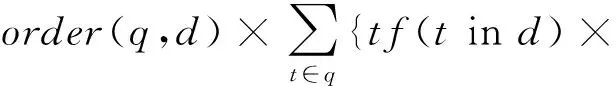
idf2(t)×t.getBoost×distance(q)×
decrease×lengthNorm(t,d)}
(10)
3 实验结果分析
本文方法用Java语言实现,实验采用DELL Optiplex 990型号的机器,内存8 GB,操作系统是Windows7专业版,JDK1.7版本。本实验中共50类科技文献,其核心元数据总数目达593 425条。为了能够全面、准确、有效地反映系统的性能。考虑到用户最关心的往往是前5页的内容,因此,本实验统计了每次检索的前50条返回结果。
实验由两部分组成,第一部分比较了我们的方法在检索词扩展与不进行检索词扩展的检索结果;第二部分比较我们的方法与传统检索方法查询扩展的比较。
3.1 扩展查询对检索性能的影响
从表1和图4中,我们可以看出,通过对检索词进行扩展查询,系统的查全率显著提高,查准率也略有提高。为了确定衰减因子decrease的最优值,我们设置其值由0.1逐步增加至1.0,随着decrease值的增加,检索系统的性能也逐步提高,当decrease=0.5时,系统性能达到最高。随后系统的性能逐步降低,我们确定0.5作为扩展词权重因子。
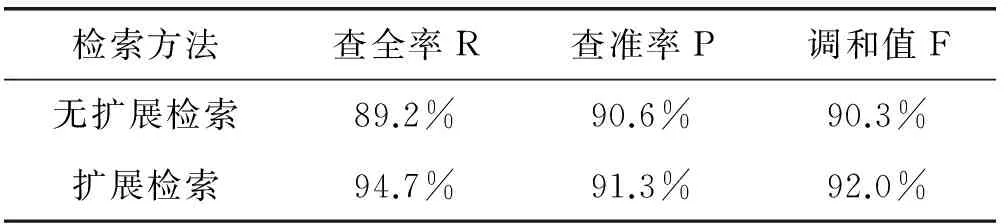
表1 扩展查询和不扩展查询比较
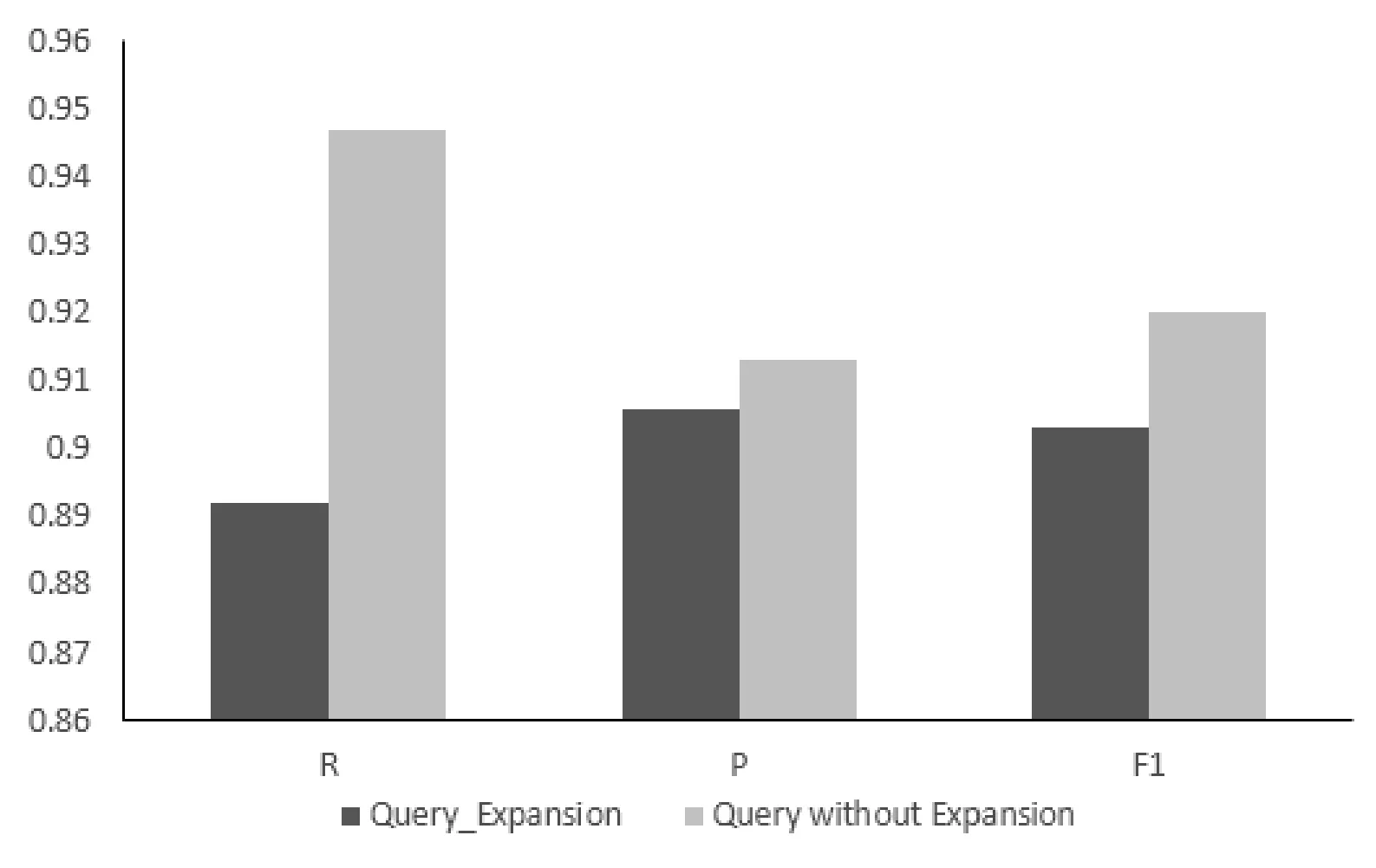
图4 扩展查询和不扩展查询结果比较
3.2 检索算法性能比较
为了准确地对比文中方法与传统方法的性能,我们用30组检索词分别对50类资源进行了检索,实验先后利用HowNet对检索词进行扩展,并使用TF-IDF和Lucene的两种算法对扩展的检索词进行检索实验。
此外,文献[8]和文献[10]中的方法被选基线对比方法,这两种方法可以从语料中获取扩展词语,相比基于知识库进行检索词扩展的方法,提高了检索词的覆盖范围。文献[8]中首先检索获取可信文本,然后从可信文本中选取词语作为查询扩展词进行二次检索获取检索结果,本实验中我们将该方法命名为Rank_Method。 文献[10]利用伪相关反馈技术量化文档中的词语权重并扩展查询词,我们将其命名为Rekha_Method。考虑到检索结果的返回数量较多,并且用户最关心的往往是前5页的内容,实验统计了每次检索的前50条返回页面来衡量检索结果,平均实验结果如表2和图5所示。

表2 检索方法性能对比
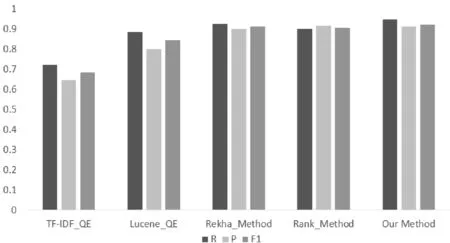
图5 查询扩展的性能对比
由表2和图5可以看出,我们提出的考虑了词语序列和扩展词衰减的方法具有明显的优越性,能够提高检索系统的查全率和召回率,同时整体性能也有了明显提升,能更好地命中用户的查询意图。
4 结 语
针对传统的查询扩展方法存在的问题,本文将多个检索词之间的词序、词距、扩展词权重变化等因素纳入词语权重计算过程进行了更细致的检索,主要工作有:1) 提出了一种改进的文本检索方法,本文在查询扩展过程中,设计扩展词衰减因子以区分不同检索词语的重要程度;2) 针对词袋模型中的词语无序性问题,构建了词序一致因子表征文本中词序的序列关系,有效提升了文档的语义一致性;3) 在检索过程中,引入了词语距离因子,一定程度上表达了用户需求信息在目标文本中的信息重要程度。实验证明,相比现有方法,我们方法能够提高检索系统的查全率和查准率。将来的工作中,我们将考虑利用资源数量分布、检索词条和用户点击数据对其中的衰减因子的自动学习进行研究,同时我们考虑根据用户偏好来解决多类别文本检索结果的合并排序问题。
[1] Eickhoff C,Collins-Thompson K,Bennett P N,et al.Personalizing atypical web search sessions[C]//ACM International Conference on Web Search and Data Mining.ACM,2013:285-294.
[2] 胡妙,戴牡红,陈浩.一种基于用户配置文件的个性化检索方法[J].计算机应用研究,2016,33(2):417-420.
[3] Salton G,Wong A,Yang C S.A vector space model for automatic indexing[J].Communications of the Acm,1974,18(11):613-620.
[4] Landauer T K,Foltz P W,Laham D.An introduction to latent semantic analysis[J].Discourse Processes,1998,25(2-3):259-284.
[5] Carpineto C,Romano G.A survey of automatic query expansion in information retrieval[J].ACM Computing Surveys (CSUR),2012,44(1):1-50.
[6] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003,3:993-1022.
[7] Goldberg Y,Levy O.word2vec Explained:deriving Mikolov et al.’s negative-sampling word-embedding method[J].arXiv preprint arXiv:1402.3722,2014.
[8] 徐博,林鸿飞,林原,等.一种基于排序学习方法的查询扩展技术[J].中文信息学报,2015,29(3):155-161.
[9] 马斌,王金虹,闫娟娟,等.基于本体的智能语义检索模型设计与研究[J].情报科学,2015(2):46-49,71.
[10] Vaidyanathan R,Das S,Srivastava N.Query Expansion Strategy based on Pseudo Relevance Feedback and Term Weight Scheme for Monolingual Retrieval[J].International Journal of Computer Applications,2015,105(8):1-6.
[11] 黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.
[12] Niu S,Guo J,Lan Y,et al.Top-k learning to rank:labeling,ranking and evaluation[C]//International ACM SIGIR Conference on Research and Development in Information Retrieval.ACM,2012:751-760.
[13] Apache Lucene.Lucenejava5.3.0[EB/OL].[2011-11-18].http://lucene.apache.org/.
[14] 刘群,李素建.基于《知网》 的词汇语义相似度计算[J].中文计算语言学,2002.
